
이 Codelab 정보
1. 소개
Google Sheets를 사용한 Apps Script 기본사항 Codelab 재생목록의 세 번째 파트에 오신 것을 환영합니다.
이 Codelab을 완료하면 Apps Script에서 데이터 조작, 맞춤 메뉴, 공개 API 데이터 가져오기를 사용하여 Sheets 환경을 개선하는 방법을 알아볼 수 있습니다. 이 재생목록의 이전 Codelab에서 소개한 SpreadsheetApp, Spreadsheet, Sheet, Range 클래스를 계속 사용합니다.
학습할 내용
- Drive의 개인 또는 공유 스프레드시트에서 데이터를 가져오는 방법
onOpen()함수로 맞춤 메뉴를 만드는 방법- Google Sheets 셀에서 문자열 데이터 값을 파싱하고 조작하는 방법
- 공개 API 소스에서 JSON 객체 데이터를 가져오고 조작하는 방법
시작하기 전에
이 Codelab은 Google Sheets를 사용한 Apps Script 기본사항 재생목록의 세 번째 Codelab입니다. 이 Codelab을 시작하기 전에 이전 Codelab을 완료해야 합니다.
필요한 항목
- 이 재생목록의 이전 Codelab에서 살펴본 기본 Apps Script 주제를 이해해야 합니다.
- Apps Script 편집기에 대한 기본적인 지식
- Google Sheets에 관한 기본 지식
- Sheets A1 표기법을 읽을 수 있음
- JavaScript 및 해당
String클래스에 관한 기본 지식
2. 설정
이 Codelab의 연습에는 작업할 스프레드시트가 필요합니다. 이 연습에서 사용할 스프레드시트를 만들려면 다음 단계를 따르세요.
- Google Drive에 스프레드시트를 만듭니다. Drive 인터페이스에서 새로 만들기 > Google Sheets를 선택하여 이 작업을 수행할 수 있습니다. 그러면 새 스프레드시트가 생성되고 열립니다. 파일이 Drive 폴더에 저장됩니다.
- 스프레드시트 제목을 클릭하고 '제목 없는 스프레드시트'에서 '데이터 조작 및 맞춤 메뉴'로 변경합니다. 시트는 다음과 같이 표시됩니다.
- 스크립트 편집기를 열려면 확장 프로그램> Apps Script를 클릭합니다.
- Apps Script 프로젝트 제목을 클릭하고 '제목 없는 프로젝트'에서 '데이터 조작 및 맞춤 메뉴'로 변경합니다. 이름 바꾸기를 클릭하여 제목 변경사항을 저장합니다.
빈 스프레드시트와 프로젝트가 있으면 실습을 시작할 수 있습니다. 다음 섹션으로 이동하여 맞춤 메뉴에 대해 알아보세요.
3. 개요: 맞춤 메뉴 항목으로 데이터 가져오기
Apps Script를 사용하면 Google Sheets에 표시될 수 있는 맞춤 메뉴를 정의할 수 있습니다. Google Docs, Google Slides, Google Forms에서 맞춤 메뉴를 사용할 수도 있습니다. 맞춤 메뉴 항목을 정의할 때는 텍스트 라벨을 만들고 스크립트 프로젝트의 Apps Script 함수에 연결합니다. 그런 다음 메뉴를 UI에 추가하여 Google Sheets에 표시할 수 있습니다.

사용자가 맞춤 메뉴 항목을 클릭하면 연결된 Apps Script 함수가 실행됩니다. 스크립트 편집기를 열지 않고도 Apps Script 함수를 실행할 수 있는 빠른 방법입니다. 또한 스프레드시트의 다른 사용자가 코드 또는 Apps Script의 작동 방식을 알지 못해도 코드를 실행할 수 있습니다. 이들에게는 또 다른 메뉴 항목일 뿐입니다.
맞춤 메뉴 항목은 다음 섹션에서 알아볼 onOpen() 간단한 트리거 함수에서 정의됩니다.
4. onOpen() 함수
Apps Script의 단순 트리거는 특정 조건이나 이벤트에 대한 응답으로 특정 Apps Script 코드를 실행하는 방법을 제공합니다. 트리거를 만들 때 트리거가 실행되도록 하는 이벤트를 정의하고 이벤트에 대해 실행되는 Apps Script 함수를 제공합니다.
onOpen()은 간단한 트리거의 예입니다. 설정하기 쉽습니다. onOpen()라는 Apps Script 함수를 작성하기만 하면 연결된 스프레드시트가 열리거나 다시 로드될 때마다 Apps Script가 이를 실행합니다.
/**
* A special function that runs when the spreadsheet is first
* opened or reloaded. onOpen() is used to add custom menu
* items to the spreadsheet.
*/
function onOpen() {
/* ... */
}
구현
맞춤 메뉴를 만들어 보겠습니다.
- 스크립트 프로젝트의 코드를 다음으로 바꿉니다.
/**
* A special function that runs when the spreadsheet is first
* opened or reloaded. onOpen() is used to add custom menu
* items to the spreadsheet.
*/
function onOpen() {
var ui = SpreadsheetApp.getUi();
ui.createMenu('Book-list')
.addItem('Load Book-list', 'loadBookList')
.addToUi();
}
- 스크립트 프로젝트를 저장합니다.
코드 검토
이 코드를 검토하여 작동 방식을 알아보겠습니다. onOpen()에서 첫 번째 줄은 getUi() 메서드를 사용하여 이 스크립트가 바인드된 활성 스프레드시트의 사용자 인터페이스를 나타내는 Ui 객체를 획득합니다.
다음 세 줄은 메뉴 (Book-list)를 만들고, 해당 메뉴에 메뉴 항목 (Load Book-list)을 추가한 다음, 메뉴를 스프레드시트의 인터페이스에 추가합니다. 이 작업은 각각 createMenu(caption), addItem(caption, functionName), addToUi() 메서드를 통해 실행됩니다.
addItem(caption, functionName) 메서드는 메뉴 항목 라벨과 메뉴 항목이 선택될 때 실행되는 Apps Script 함수 간의 연결을 만듭니다. 이 경우 Load Book-list 메뉴 항목을 선택하면 Sheets에서 아직 존재하지 않는 loadBookList() 함수를 실행하려고 시도합니다.
결과
이제 이 함수를 실행하여 작동하는지 확인합니다.
- Google Sheets에서 스프레드시트를 새로고침합니다. 참고: 이렇게 하면 일반적으로 스크립트 편집기가 있는 탭이 닫힙니다.
- 도구 > 스크립트 편집기를 선택하여 스크립트 편집기를 다시 엽니다.
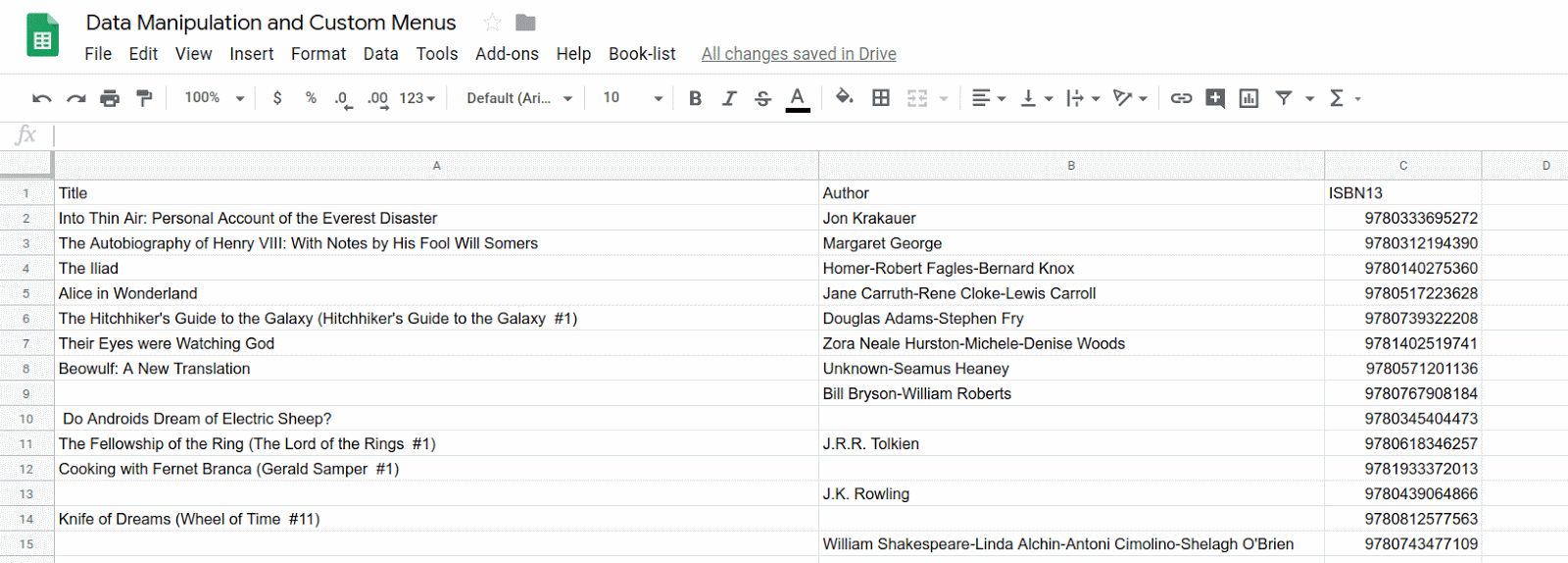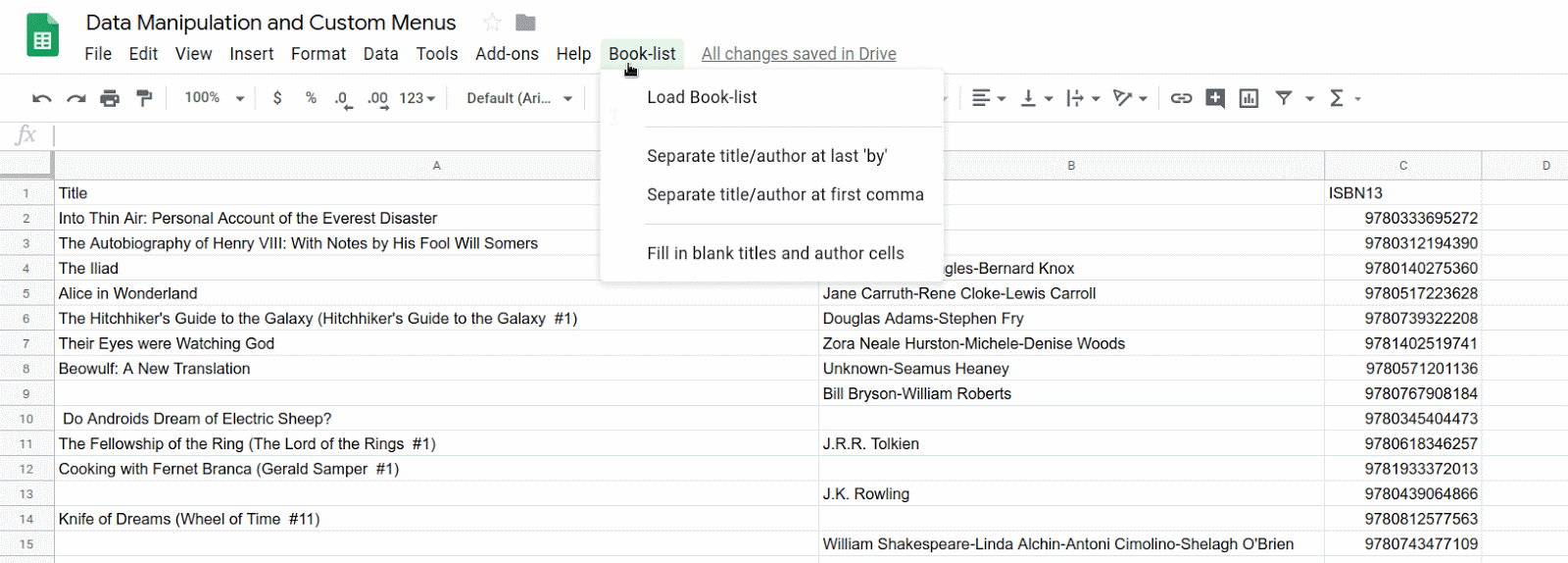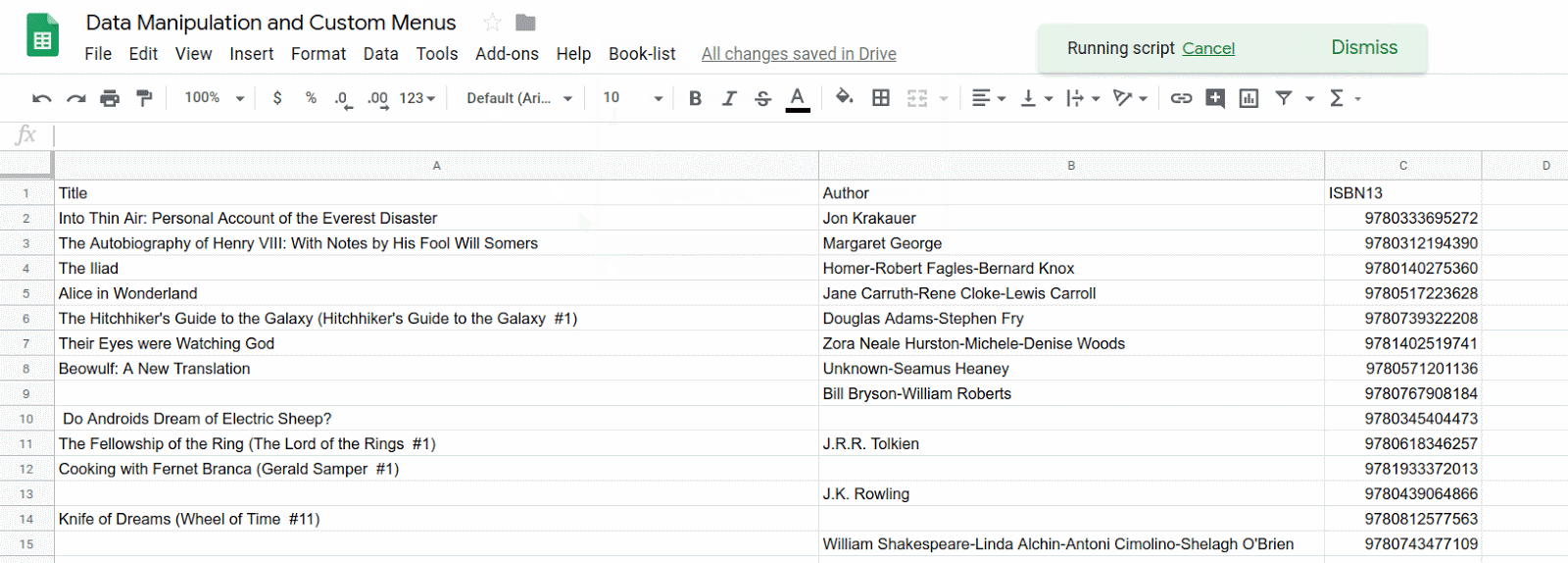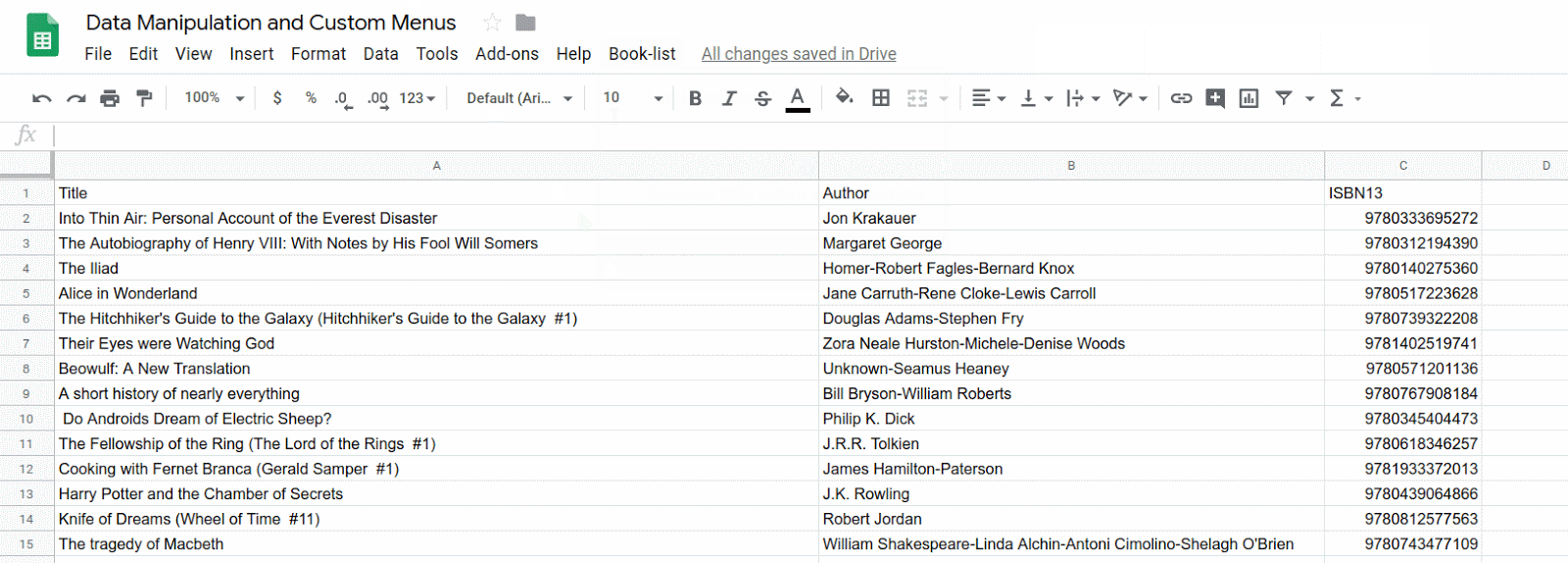
스프레드시트가 새로고침되면 메뉴 바에 새 Book-list 메뉴가 표시됩니다.

도서 목록을 클릭하면 다음과 같은 메뉴가 표시됩니다.

다음 섹션에서는 loadBookList() 함수의 코드를 만들고 Apps Script에서 데이터와 상호작용하는 한 가지 방법인 다른 스프레드시트 읽기를 소개합니다.
5. 스프레드시트 데이터 가져오기
맞춤 메뉴를 만들었으므로 메뉴 항목을 클릭하여 실행할 수 있는 함수를 만들 수 있습니다.
현재 맞춤 메뉴 Book-list에는 Load Book-list.이라는 메뉴 항목이 하나 있습니다. Load Book-list 메뉴 항목을 선택할 때 호출되는 함수 loadBookList(),이 스크립트에 없으므로 Book-list > Load Book-list를 선택하면 오류가 발생합니다.

loadBookList() 함수를 구현하여 이 오류를 해결할 수 있습니다.
구현
새 메뉴 항목이 작업할 데이터로 스프레드시트를 채우도록 하려면 loadBookList()를 구현하여 다른 스프레드시트에서 책 데이터를 읽고 이 스프레드시트로 복사합니다.
onOpen()아래의 스크립트에 다음 코드를 추가합니다.
/**
* Creates a template book list based on the
* provided 'codelab-book-list' sheet.
*/
function loadBookList(){
// Gets the active sheet.
var sheet = SpreadsheetApp.getActiveSheet();
// Gets a different spreadsheet from Drive using
// the spreadsheet's ID.
var bookSS = SpreadsheetApp.openById(
"1c0GvbVUDeBmhTpq_A3vJh2xsebtLuwGwpBYqcOBqGvo"
);
// Gets the sheet, data range, and values of the
// spreadsheet stored in bookSS.
var bookSheet = bookSS.getSheetByName("codelab-book-list");
var bookRange = bookSheet.getDataRange();
var bookListValues = bookRange.getValues();
// Add those values to the active sheet in the current
// spreadsheet. This overwrites any values already there.
sheet.getRange(1, 1, bookRange.getHeight(), bookRange.getWidth())
.setValues(bookListValues);
// Rename the destination sheet and resize the data
// columns for easier reading.
sheet.setName("Book-list");
sheet.autoResizeColumns(1, 3);
}
- 스크립트 프로젝트를 저장합니다.
코드 검토
이 기능은 어떻게 작동하나요? loadBookList() 함수는 이전 Codelab에서 소개한 Spreadsheet, Sheet, Range 클래스의 메서드를 주로 사용합니다. 이러한 개념을 염두에 두고 loadBookList() 코드를 다음 네 섹션으로 나눌 수 있습니다.
1: 대상 시트 식별
첫 번째 줄에서는 SpreadsheetApp.getActiveSheet()를 사용하여 현재 시트 객체에 대한 참조를 가져와 변수 sheet에 저장합니다. 데이터가 복사될 시트입니다.
2: 소스 데이터 식별
다음 몇 줄은 가져오는 소스 데이터를 참조하는 네 개의 변수를 설정합니다.
bookSS은 코드가 데이터를 읽어오는 스프레드시트에 대한 참조를 저장합니다. 코드는 스프레드시트 ID로 스프레드시트를 찾습니다. 이 예에서는 읽어올 소스 스프레드시트의 ID를 제공하고SpreadsheetApp.openById(id)메서드를 사용하여 스프레드시트를 엽니다.bookSheet는 원하는 데이터가 포함된bookSS내 시트의 참조를 저장합니다. 이 코드는 이름(codelab-book-list)으로 읽을 시트를 식별합니다.bookRange는bookSheet의 데이터 범위에 대한 참조를 저장합니다.Sheet.getDataRange()메서드는 시트의 비어 있지 않은 모든 셀을 포함하는 범위를 반환합니다. 빈 행과 열을 포함하지 않고 시트의 모든 데이터를 포함하는 범위를 지정하는 간단한 방법입니다.bookListValues는bookRange의 셀에서 가져온 모든 값을 포함하는 2D 배열입니다.Range.getValues()메서드는 소스 시트에서 데이터를 읽어 이 배열을 생성합니다.
3: 소스에서 대상으로 데이터 복사
다음 코드 섹션은 bookListValues 데이터를 sheet에 복사한 후 시트의 이름도 바꿉니다.
Sheet.getRange(row, column, numRows, numColumns)은sheet에서 데이터를 복사할 위치를 식별하는 데 사용됩니다.Range.getHeight()및Range.getWidth()메서드는 데이터 크기를 측정하고 동일한 측정기준의 대상 범위를 정의하는 데 사용됩니다.Range.setValues(values)는bookListValues의 2D 배열을 대상 범위에 복사하여 이미 있는 데이터를 덮어씁니다.
4: 대상 시트 서식 지정하기
Sheet.setName(name)은 대상 시트 이름을 Book-list로 변경하는 데 사용됩니다. 함수의 마지막 줄은 Sheet.autoResizeColumns(startColumn, numColumns)를 사용하여 대상 시트의 처음 세 열의 크기를 조정하므로 새 데이터를 더 쉽게 읽을 수 있습니다.
결과
이 함수가 작동하는 것을 확인할 수 있습니다. Google Sheets에서 도서 목록 > 도서 목록 로드를 선택하여 스프레드시트를 채우는 함수를 실행합니다.
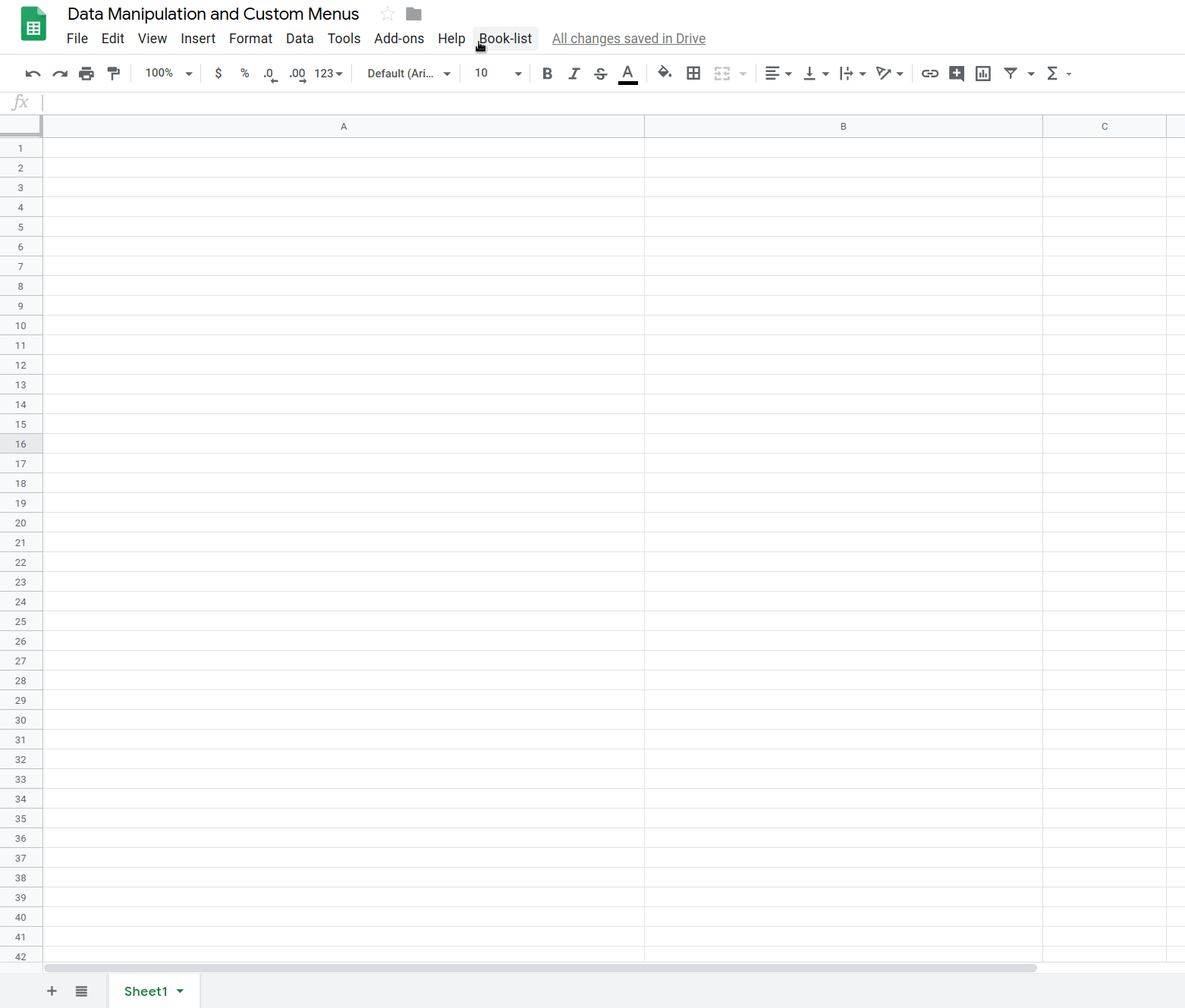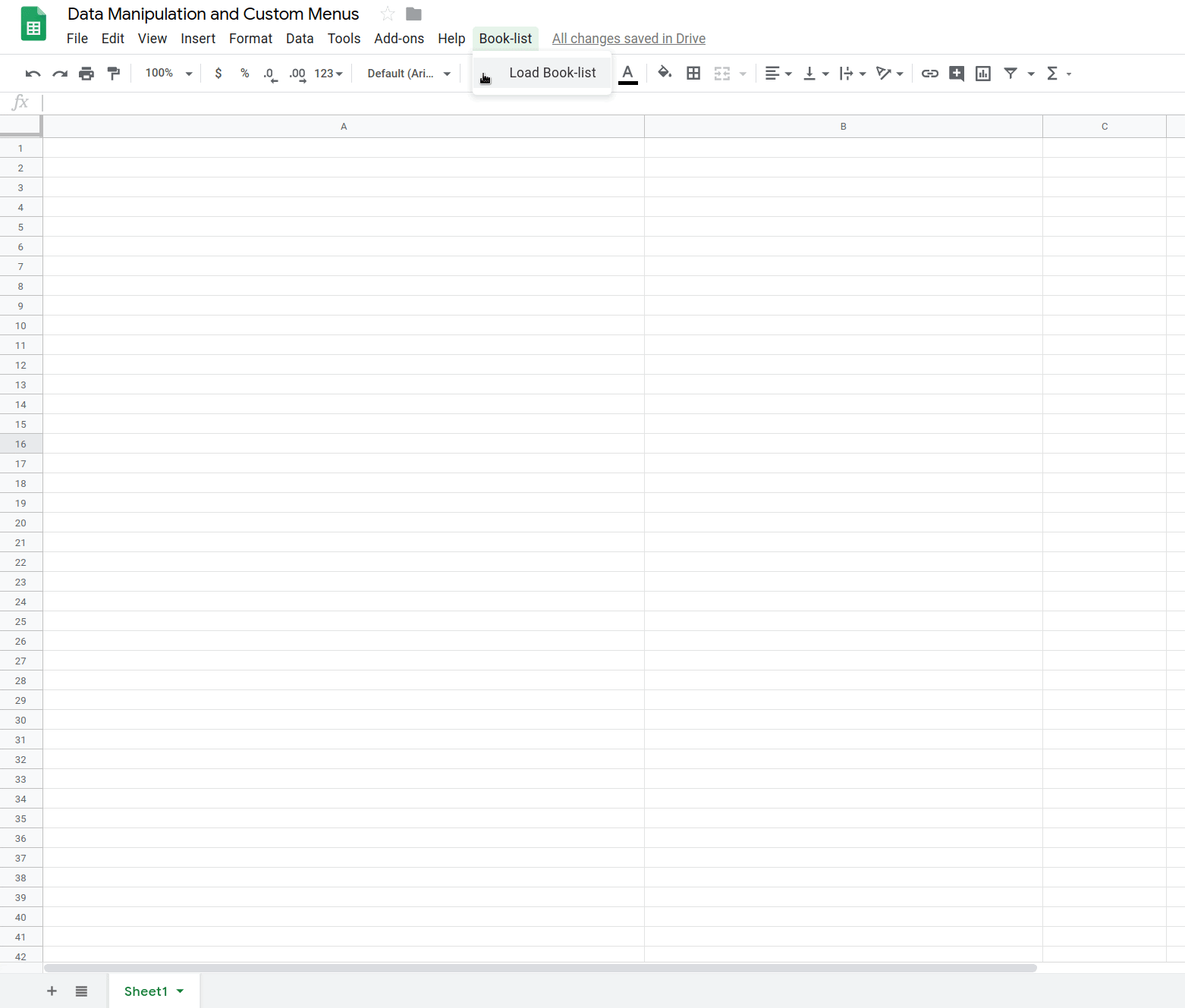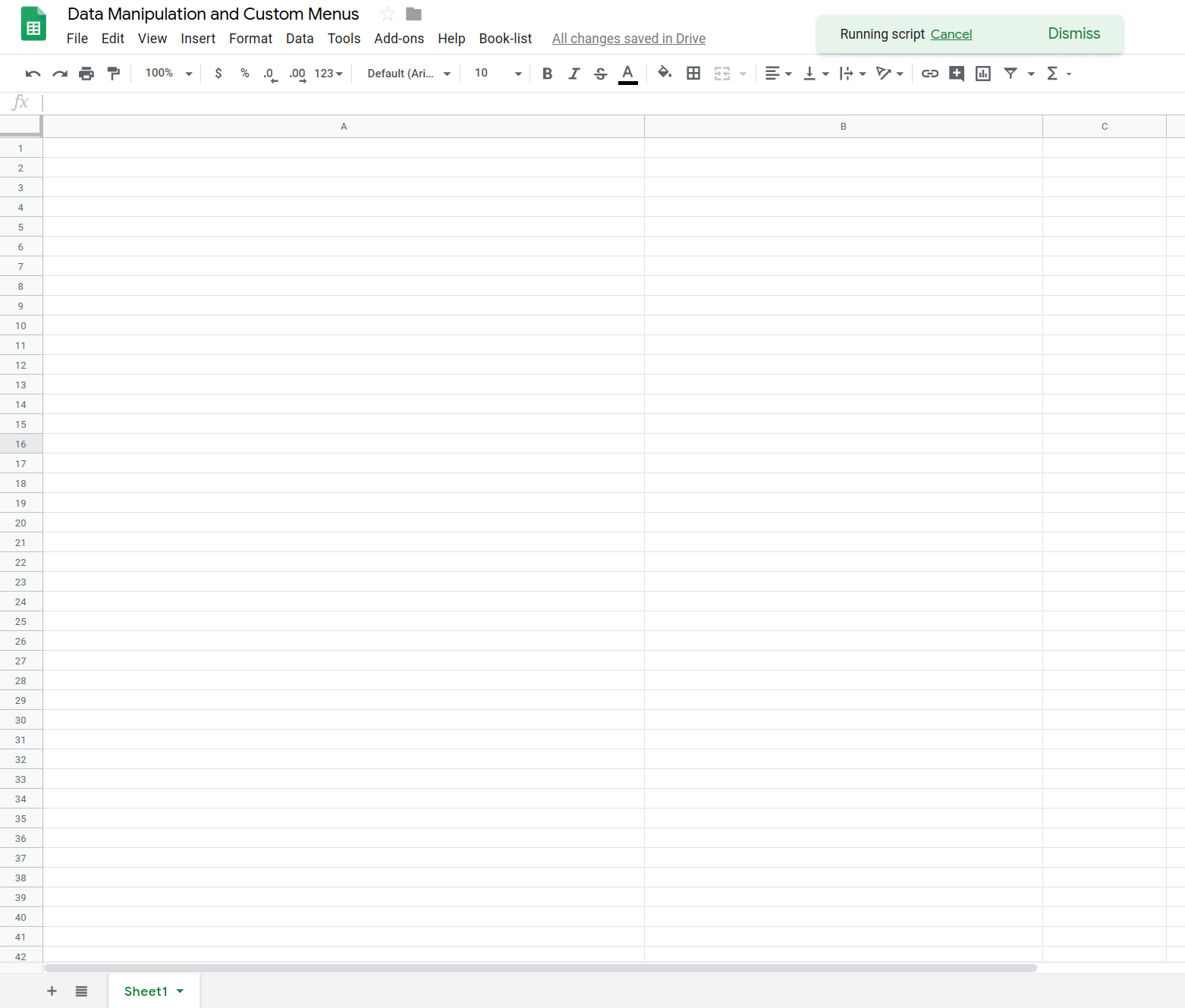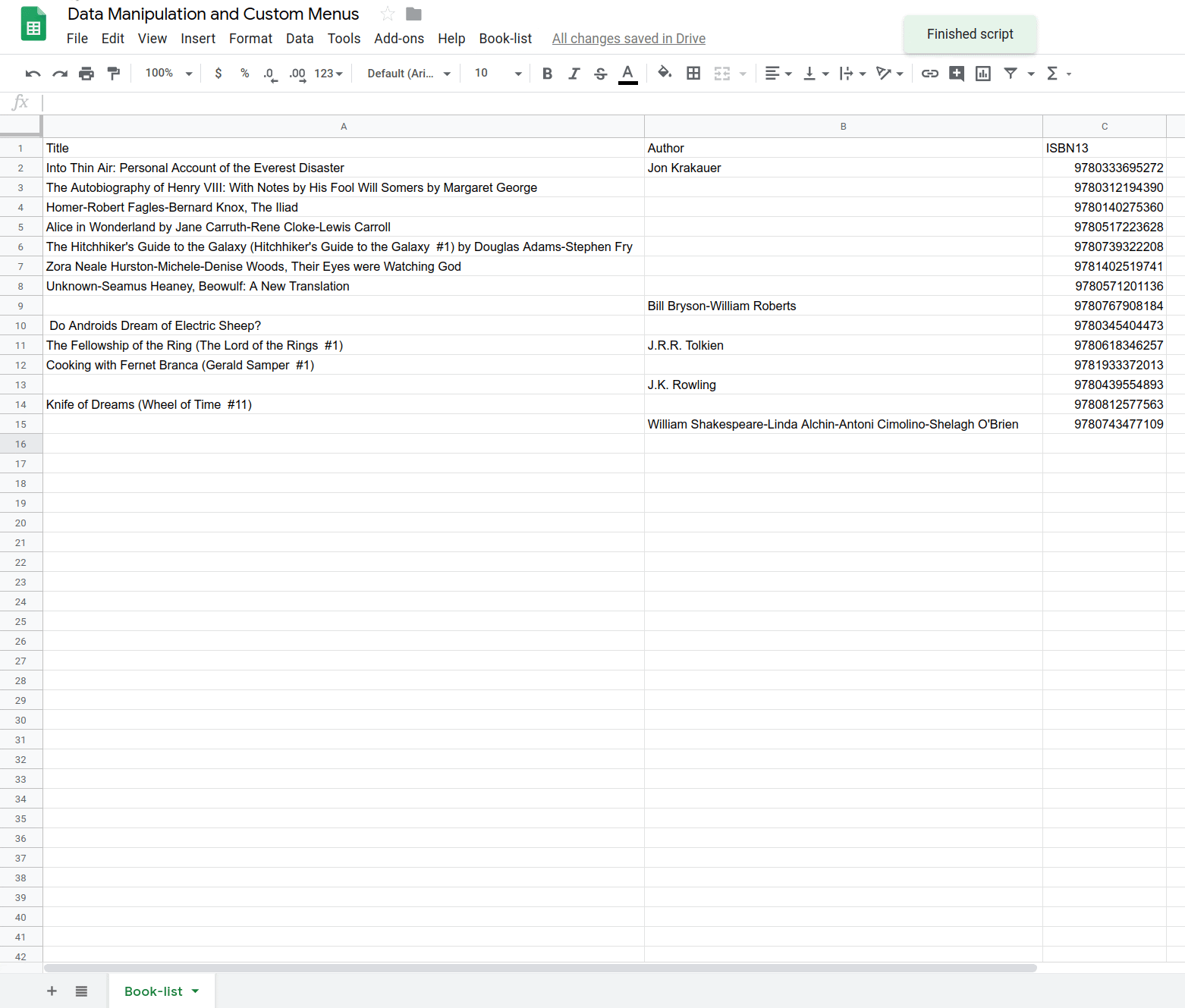
이제 도서 제목, 저자, 13자리 ISBN 번호 목록이 포함된 시트가 있습니다. 다음 섹션에서는 문자열 조작 및 맞춤 메뉴를 사용하여 이 도서 목록의 데이터를 수정하고 업데이트하는 방법을 알아봅니다.
6. 개요: 스프레드시트 데이터 정리
이제 시트에 도서 정보가 표시됩니다. 각 행은 특정 도서를 나타내며 제목, 저자, ISBN 번호가 별도의 열에 나열됩니다. 하지만 이 원시 데이터에는 다음과 같은 문제도 있습니다.
- 일부 행의 경우 제목과 저자가 제목 열에 함께 배치되며 쉼표 또는 ' by ' 문자열로 연결됩니다.
- 일부 행에 책 제목 또는 저자가 누락되어 있습니다.
다음 섹션에서는 데이터를 정리하여 이러한 문제를 수정합니다. 첫 번째 문제의 경우 제목 열을 읽고 쉼표 또는 ' by ' 구분자가 발견될 때마다 텍스트를 분할하여 해당 저자와 제목 하위 문자열을 올바른 열에 배치하는 함수를 만듭니다. 두 번째 문제의 경우 외부 API를 사용하여 누락된 도서 정보를 자동으로 검색하고 해당 정보를 시트에 추가하는 코드를 작성합니다.
7. 메뉴 항목 추가
구현할 데이터 정리 작업을 제어하는 메뉴 항목 3개를 만들어야 합니다.
구현
필요한 추가 메뉴 항목을 포함하도록 onOpen()을 업데이트하겠습니다. 다음 단계를 따르세요.
- 스크립트 프로젝트에서 다음 코드와 일치하도록
onOpen()코드를 업데이트합니다.
/**
* A special function that runs when the spreadsheet is first
* opened or reloaded. onOpen() is used to add custom menu
* items to the spreadsheet.
*/
function onOpen() {
var ui = SpreadsheetApp.getUi();
ui.createMenu('Book-list')
.addItem('Load Book-list', 'loadBookList')
.addSeparator()
.addItem(
'Separate title/author at first comma', 'splitAtFirstComma')
.addItem(
'Separate title/author at last "by"', 'splitAtLastBy')
.addSeparator()
.addItem(
'Fill in blank titles and author cells', 'fillInTheBlanks')
.addToUi();
}
- 스크립트 프로젝트를 저장합니다.
- 스크립트 편집기에서 함수 목록에서
onOpen를 선택하고 실행을 클릭합니다. 이렇게 하면onOpen()가 실행되어 스프레드시트 메뉴가 다시 빌드되므로 스프레드시트를 새로고침하지 않아도 됩니다.
이 새 코드에서 Menu.addSeparator() 메서드는 관련 메뉴 항목 그룹을 시각적으로 정리하기 위해 메뉴에 가로 구분선을 만듭니다. 그러면 새 메뉴 항목이 아래에 추가되고 라벨은 Separate title/author at first comma, Separate title/author at last "by", Fill in blank titles and author cells가 됩니다.
결과
스프레드시트에서 Book-list 메뉴를 클릭하여 새 메뉴 항목을 확인합니다.
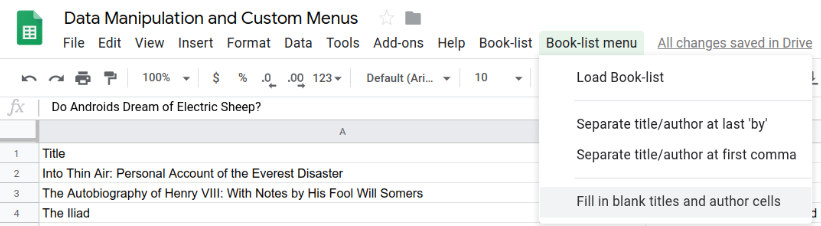
해당 기능을 구현하지 않았으므로 이러한 새 항목을 클릭하면 오류가 발생합니다. 다음 단계에서 이를 구현해 보겠습니다.
8. 쉼표 구분 기호로 텍스트 분할
스프레드시트로 가져온 데이터 세트에는 작성자와 제목이 쉼표를 사용하여 하나의 셀에 잘못 결합된 셀이 몇 개 있습니다.
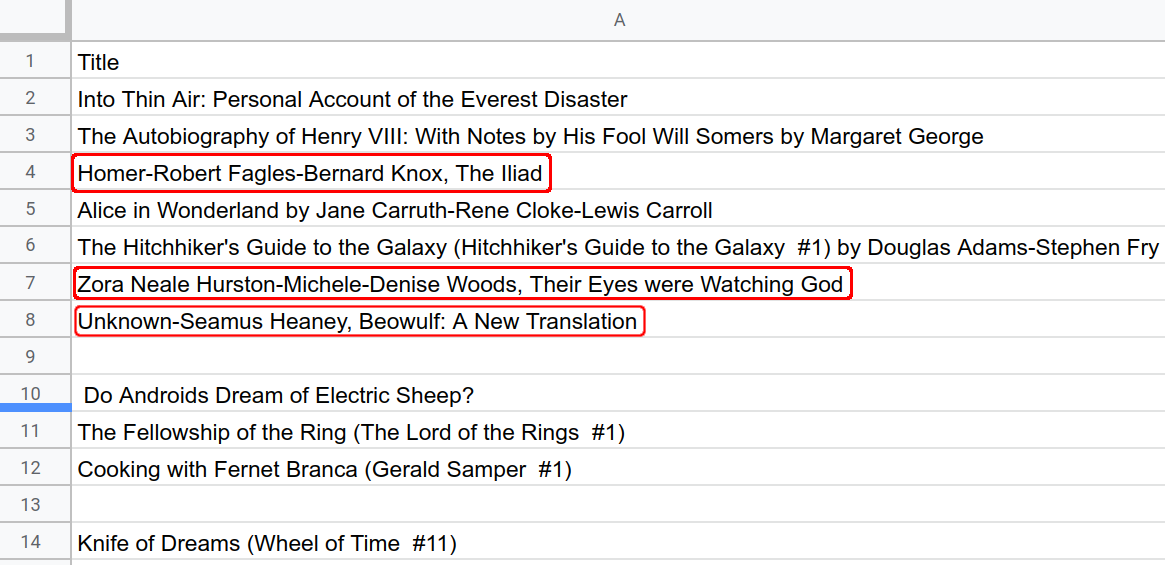
텍스트 문자열을 별도의 열로 분할하는 것은 일반적인 스프레드시트 작업입니다. Google Sheets는 문자열을 열로 나누는 SPLIT() 함수를 제공합니다. 하지만 데이터 세트에는 Sheets의 내장 함수로 쉽게 해결할 수 없는 문제가 있는 경우가 많습니다. 이러한 경우 Apps Script 코드를 작성하여 데이터를 정리하고 구성하는 데 필요한 복잡한 작업을 실행할 수 있습니다.
먼저 쉼표가 발견되면 저자와 제목을 각각의 셀로 나누는 splitAtFirstComma()라는 함수를 구현하여 데이터를 정리합니다.
splitAtFirstComma() 함수는 다음 단계를 따라야 합니다.
- 현재 선택된 셀을 나타내는 범위를 가져옵니다.
- 범위의 셀에 쉼표가 있는지 확인합니다.
- 쉼표가 발견되면 첫 번째 쉼표 위치에서 문자열을 두 개의 하위 문자열로 분할합니다 (두 개만). 간단하게 하기 위해 쉼표는 '[authors], [title]' 문자열 패턴을 나타낸다고 가정할 수 있습니다. 셀에 쉼표가 여러 개 표시되면 문자열의 첫 번째 쉼표를 기준으로 분할하는 것이 적절하다고 가정할 수도 있습니다.
- 부분 문자열을 각 제목 및 저자 셀의 새 콘텐츠로 설정합니다.
구현
이 단계를 구현하려면 이전에 사용한 것과 동일한 스프레드시트 서비스 메서드를 사용하지만 JavaScript를 사용하여 문자열 데이터를 조작해야 합니다. 다음 단계를 따릅니다.
- Apps Script 편집기에서 스크립트 프로젝트 끝에 다음 함수를 추가합니다.
/**
* Reformats title and author columns by splitting the title column
* at the first comma, if present.
*/
function splitAtFirstComma(){
// Get the active (currently highlighted) range.
var activeRange = SpreadsheetApp.getActiveRange();
var titleAuthorRange = activeRange.offset(
0, 0, activeRange.getHeight(), activeRange.getWidth() + 1);
// Get the current values of the selected title column cells.
// This is a 2D array.
var titleAuthorValues = titleAuthorRange.getValues();
// Update values where commas are found. Assumes the presence
// of a comma indicates an "authors, title" pattern.
for (var row = 0; row < titleAuthorValues.length; row++){
var indexOfFirstComma =
titleAuthorValues[row][0].indexOf(", ");
if(indexOfFirstComma >= 0){
// Found a comma, so split and update the values in
// the values array.
var titlesAndAuthors = titleAuthorValues[row][0];
// Update the title value in the array.
titleAuthorValues[row][0] =
titlesAndAuthors.slice(indexOfFirstComma + 2);
// Update the author value in the array.
titleAuthorValues[row][1] =
titlesAndAuthors.slice(0, indexOfFirstComma);
}
}
// Put the updated values back into the spreadsheet.
titleAuthorRange.setValues(titleAuthorValues);
}
- 스크립트 프로젝트를 저장합니다.
코드 검토
세 가지 주요 섹션으로 구성된 새 코드를 검토해 보겠습니다.
1: 강조 표시된 제목 값 가져오기
처음 세 줄은 시트의 현재 데이터를 참조하는 세 개의 변수를 설정합니다.
activeRange은splitAtFirstComma()함수가 호출될 때 사용자가 현재 강조 표시한 범위를 나타냅니다. 이 연습을 간단하게 유지하기 위해 사용자가 A열의 셀을 강조 표시할 때만 이 작업을 수행한다고 가정할 수 있습니다.titleAuthorRange는activeRange와 동일한 셀을 포함하지만 오른쪽에 열이 하나 더 포함된 새 범위를 나타냅니다.titleAuthorRange는Range.offset(rowOffset, columnOffset, numRows, numColumns)메서드를 사용하여 생성됩니다. 코드는 제목 열에서 찾은 저자를 배치할 공간이 필요하므로 이 확장된 범위가 필요합니다.titleAuthorValues는Range.getValues()를 사용하여titleAuthorRange에서 추출한 데이터의 2D 배열입니다.
2: 각 제목을 검사하고 첫 번째 쉼표 구분자를 기준으로 분할
다음 섹션에서는 titleAuthorValues의 값을 검사하여 쉼표를 찾습니다. JavaScript For Loop은 titleAuthorValues의 첫 번째 열에 있는 모든 값을 검사하는 데 사용됩니다. JavaScript String indexOf() 메서드를 사용하여 쉼표 하위 문자열(", ")이 발견되면 코드는 다음 작업을 실행합니다.
- 셀 문자열 값이
titlesAndAuthors변수에 복사됩니다. - 쉼표 위치는 JavaScript String indexOf() 메서드를 사용하여 결정됩니다.
- JavaScript String slice() 메서드는 쉼표 구분자 앞의 하위 문자열과 구분자 뒤의 하위 문자열을 가져오기 위해 두 번 호출됩니다.
- 부분 문자열은 titleAuthorValues 2D 배열에 다시 복사되어 해당 위치의 기존 값을 덮어씁니다. '[authors], [title]' 패턴을 가정하므로 두 하위 문자열의 순서가 반전되어 제목이 첫 번째 열에, 저자가 두 번째 열에 배치됩니다.
참고: 코드가 쉼표를 찾지 못하면 행의 데이터가 변경되지 않습니다.
3: 새 값을 시트에 다시 복사
모든 제목 셀 값을 검사한 후 업데이트된 titleAuthorValues 2D 배열이 Range.setValues(values) 메서드를 사용하여 스프레드시트로 다시 복사됩니다.
결과
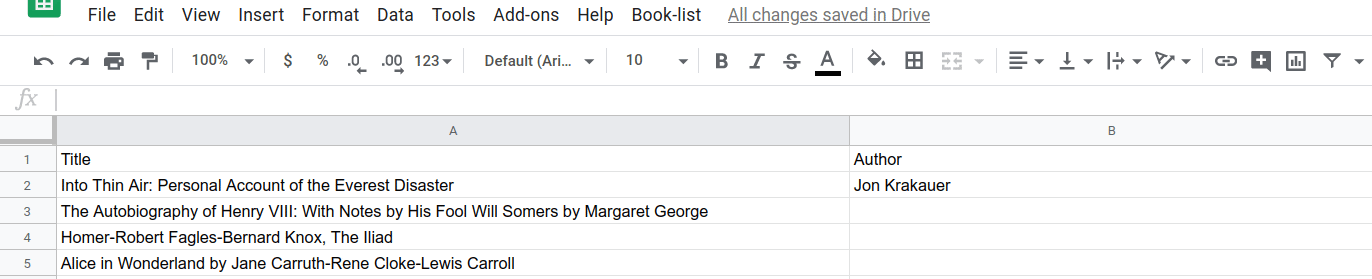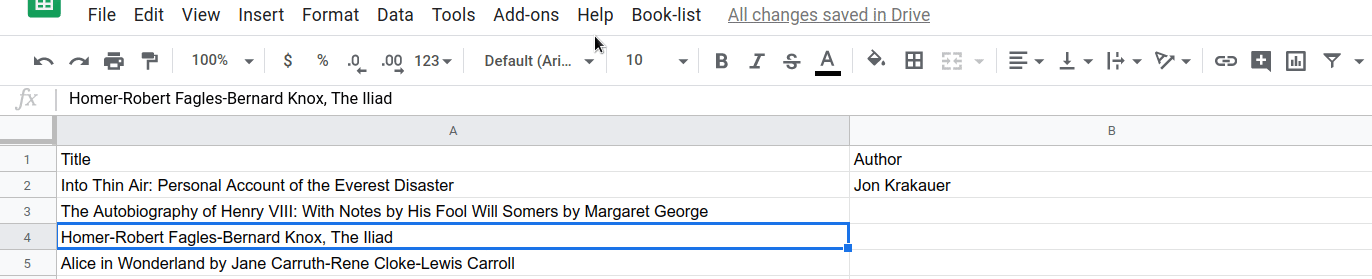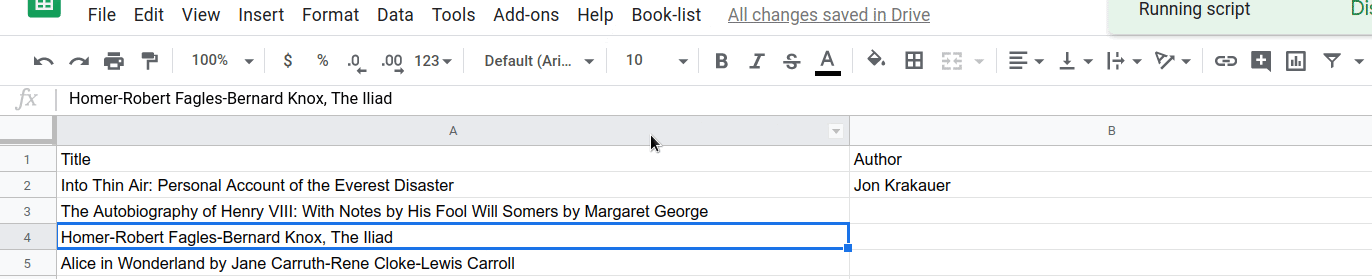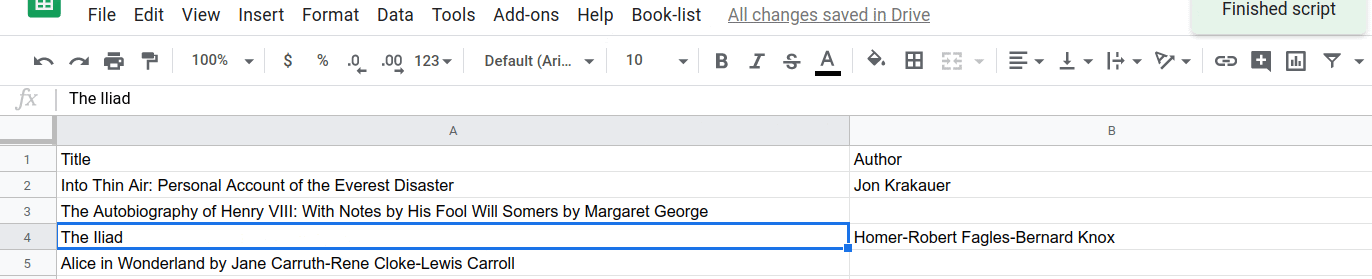
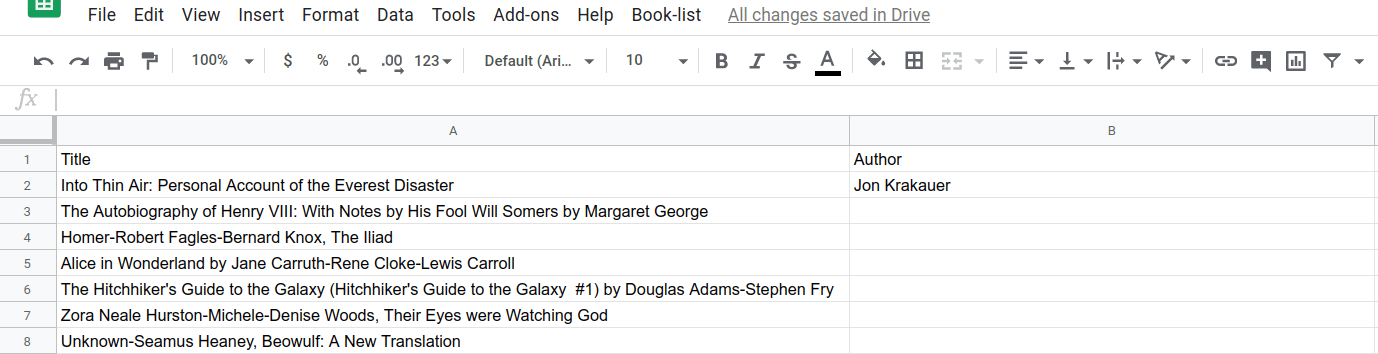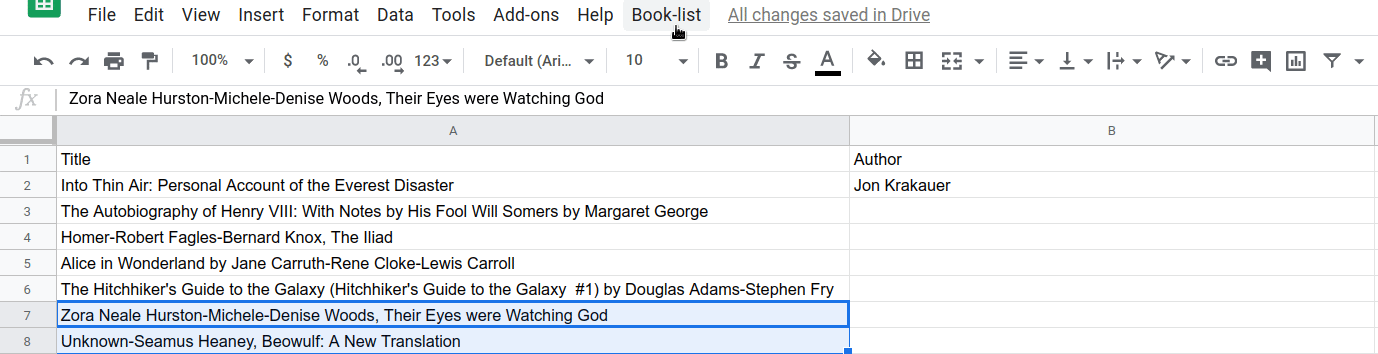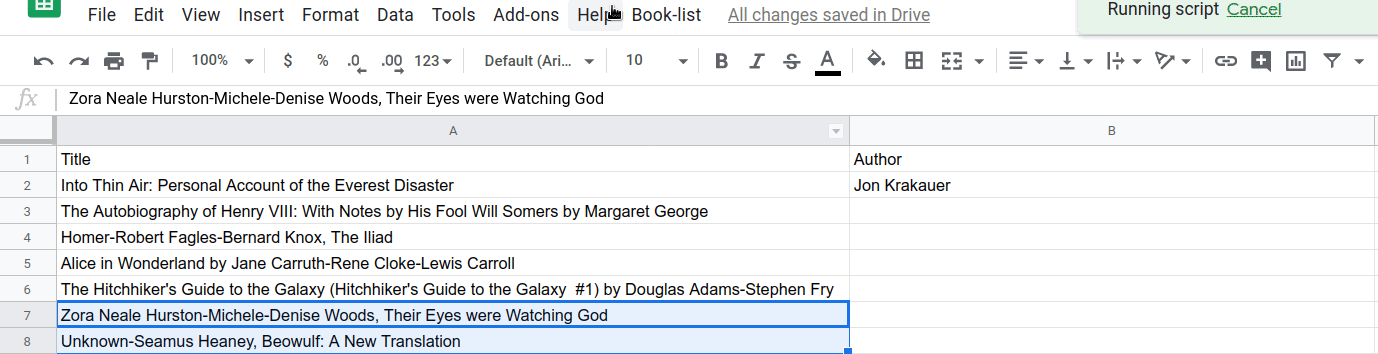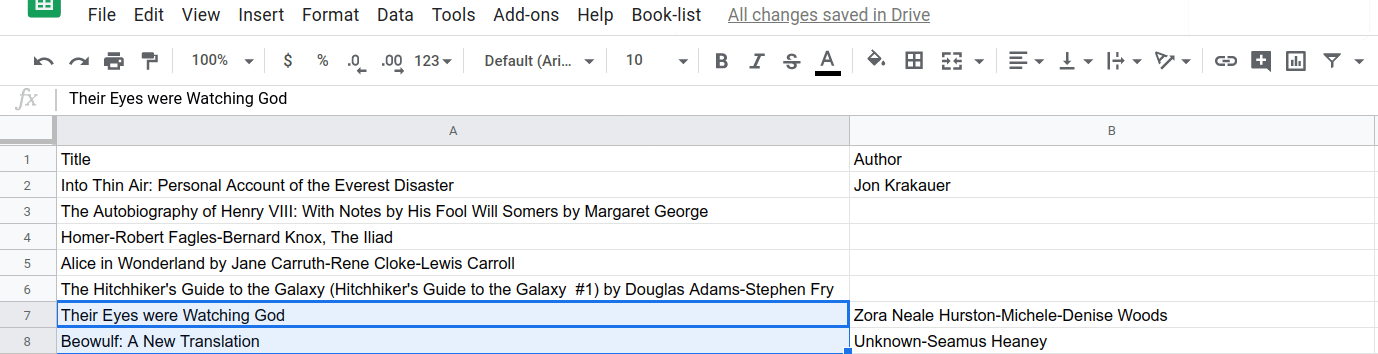
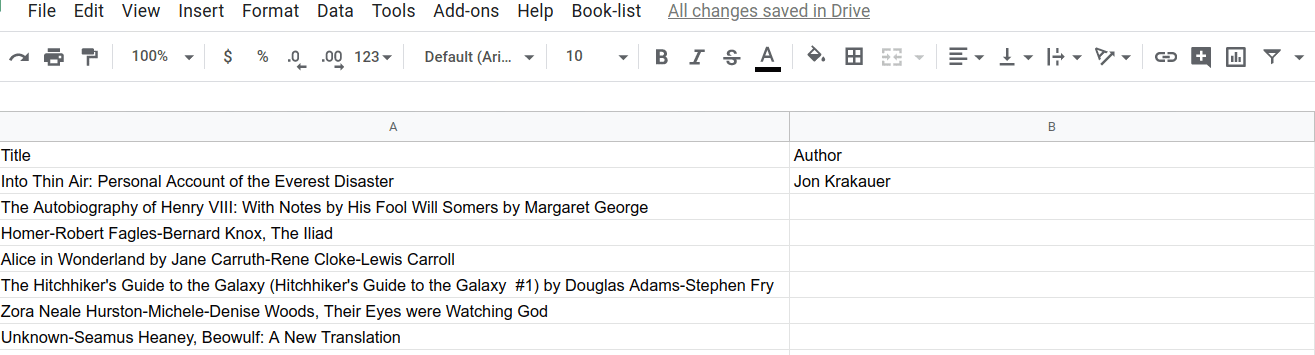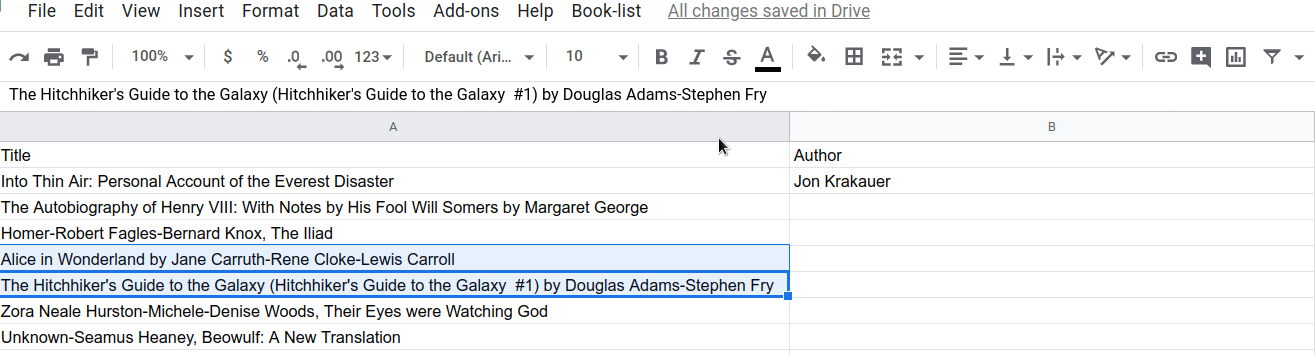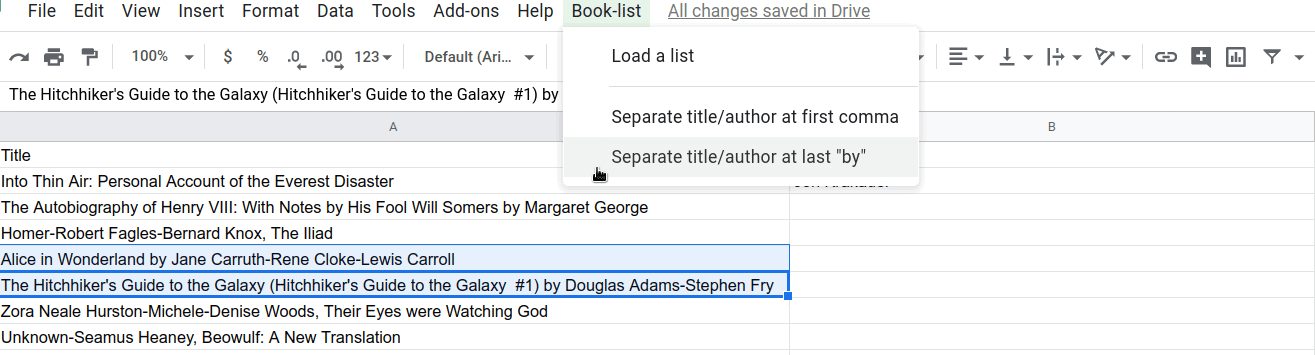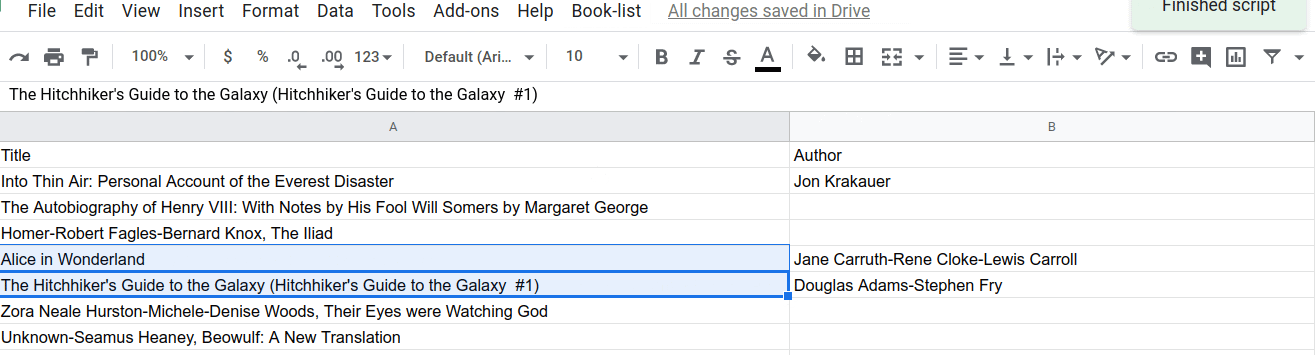
이제 splitAtFirstComma() 함수가 작동하는 효과를 확인할 수 있습니다. 선택한 후 첫 번째 쉼표에서 제목/저자 분리 메뉴 항목을 선택하여 실행해 보세요.
...한 셀:
...또는 여러 셀:
이제 Sheets 데이터를 처리하는 Apps Script 함수를 빌드했습니다. 다음으로 두 번째 스플리터 함수를 구현합니다.
9. 'by' 구분 기호로 텍스트 분할
원본 데이터를 보면 또 다른 문제가 있습니다. 일부 데이터 형식은 제목과 저자를 단일 셀에 '[authors], [title]'로 지정하는 반면 다른 셀은 저자와 제목을 '[title] by [authors]'로 지정합니다.
구현
이전 섹션과 동일한 기법을 사용하여 splitAtLastBy()라는 함수를 만들어 이 문제를 해결할 수 있습니다. 이 함수는 splitAtFirstComma()와 비슷한 작업을 수행합니다. 유일한 실제 차이점은 약간 다른 텍스트 패턴을 검색한다는 점입니다. 다음과 같이 이 함수를 구현합니다.
- Apps Script 편집기에서 스크립트 프로젝트 끝에 다음 함수를 추가합니다.
/**
* Reformats title and author columns by splitting the title column
* at the last instance of the string " by ", if present.
*/
function splitAtLastBy(){
// Get the active (currently highlighted) range.
var activeRange = SpreadsheetApp.getActiveRange();
var titleAuthorRange = activeRange.offset(
0, 0, activeRange.getHeight(), activeRange.getWidth() + 1);
// Get the current values of the selected title column cells.
// This is a 2D array.
var titleAuthorValues = titleAuthorRange.getValues();
// Update values where " by " substrings are found. Assumes
// the presence of a " by " indicates a "title by authors"
// pattern.
for(var row = 0; row < titleAuthorValues.length; row++){
var indexOfLastBy =
titleAuthorValues[row][0].lastIndexOf(" by ");
if(indexOfLastBy >= 0){
// Found a " by ", so split and update the values in
// the values array.
var titlesAndAuthors = titleAuthorValues[row][0];
// Update the title value in the array.
titleAuthorValues[row][0] =
titlesAndAuthors.slice(0, indexOfLastBy);
// Update the author value in the array.
titleAuthorValues[row][1] =
titlesAndAuthors.slice(indexOfLastBy + 4);
}
}
// Put the updated values back into the spreadsheet.
titleAuthorRange.setValues(titleAuthorValues);
}
- 스크립트 프로젝트를 저장합니다.
코드 검토
이 코드와 splitAtFirstComma() 사이에는 몇 가지 주요 차이점이 있습니다.
- '
,' 대신 'by' 하위 문자열이 문자열 구분 기호로 사용됩니다. - 여기서는 JavaScript
String.lastIndexOf(substring)메서드가String.indexOf(substring)대신 사용됩니다. 즉, 초기 문자열에 'by' 하위 문자열이 여러 개 있는 경우 마지막 'by'을 제외한 모든 하위 문자열이 제목의 일부로 간주됩니다. - 문자열을 분할한 후 첫 번째 하위 문자열은 제목으로 설정되고 두 번째 하위 문자열은 저자로 설정됩니다 (
splitAtFirstComma()와 반대 순서임).
결과
이제 splitAtLastBy() 함수가 작동하는 효과를 확인할 수 있습니다. 선택한 후 마지막 'by'에서 제목/저자 분리 메뉴 항목을 선택하여 실행해 보세요.
...한 셀:
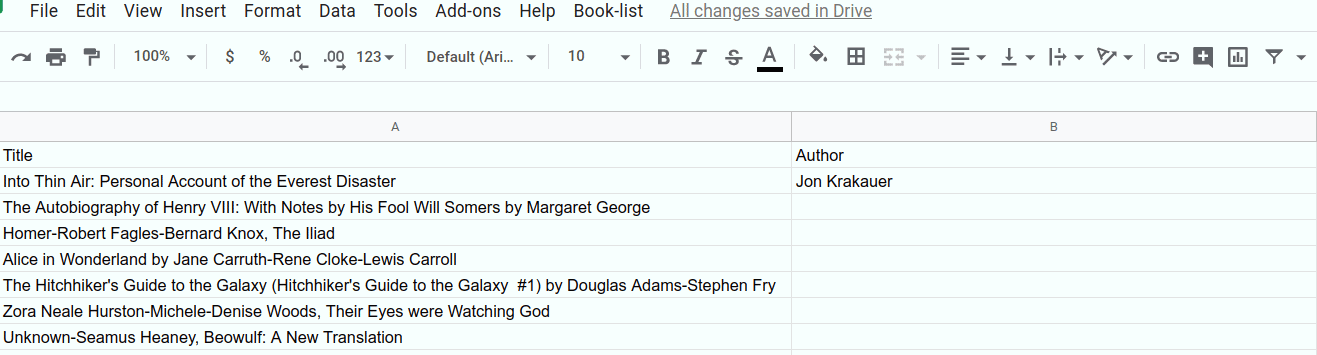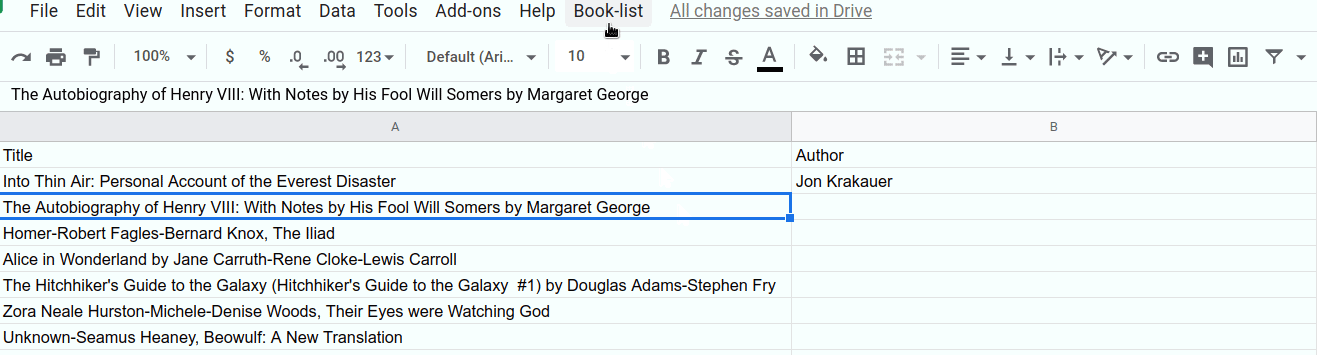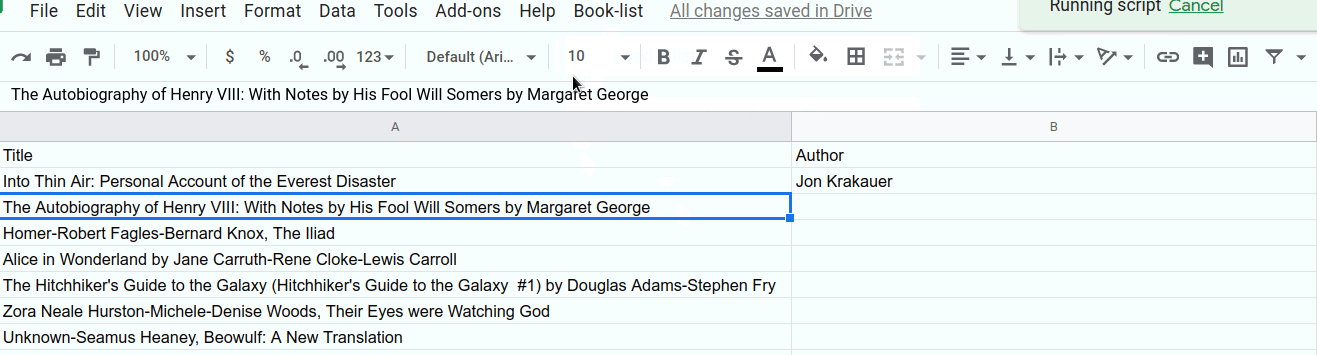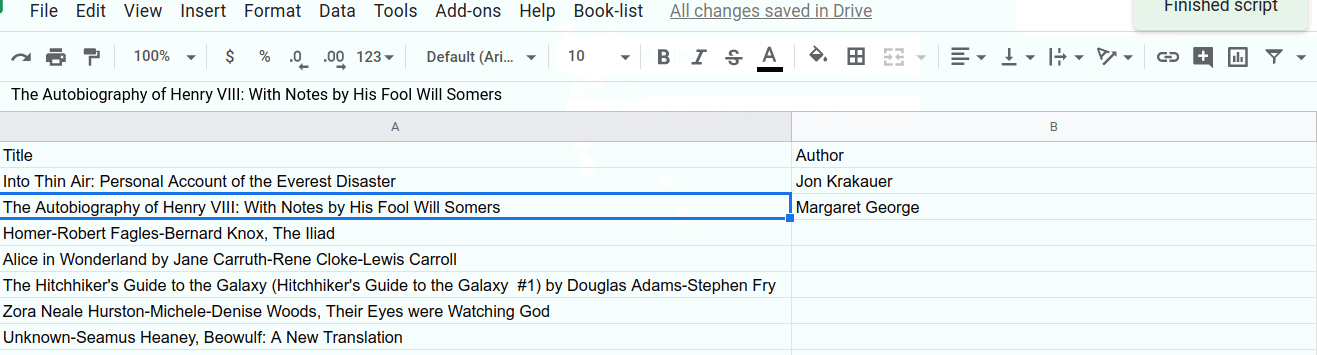
...또는 여러 셀:
Codelab의 이 섹션을 완료했습니다. 이제 Apps Script를 사용하여 시트에서 문자열 데이터를 읽고 수정할 수 있으며, 맞춤 메뉴를 사용하여 다양한 Apps Script 명령어를 실행할 수 있습니다.
다음 섹션에서는 공개 API에서 가져온 데이터로 빈 셀을 채워 이 데이터 세트를 추가로 개선하는 방법을 알아봅니다.
10. 개요: 공개 API에서 데이터 가져오기
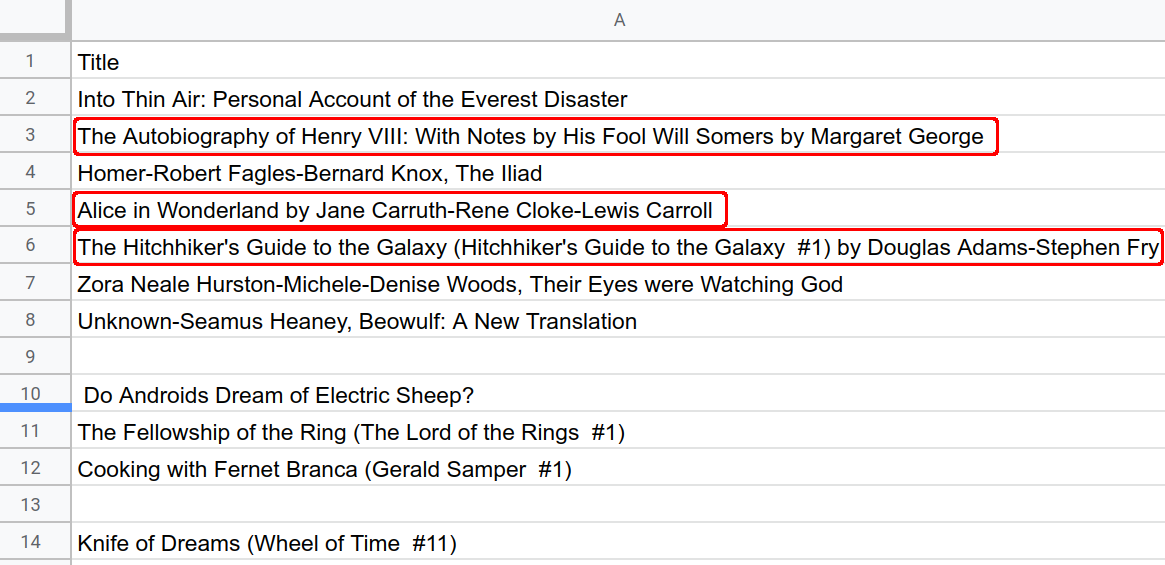
지금까지 데이터 세트를 수정하여 제목 및 저자 형식 문제를 해결했지만, 아래 셀에 강조 표시된 것처럼 데이터 세트에 아직 누락된 정보가 있습니다.
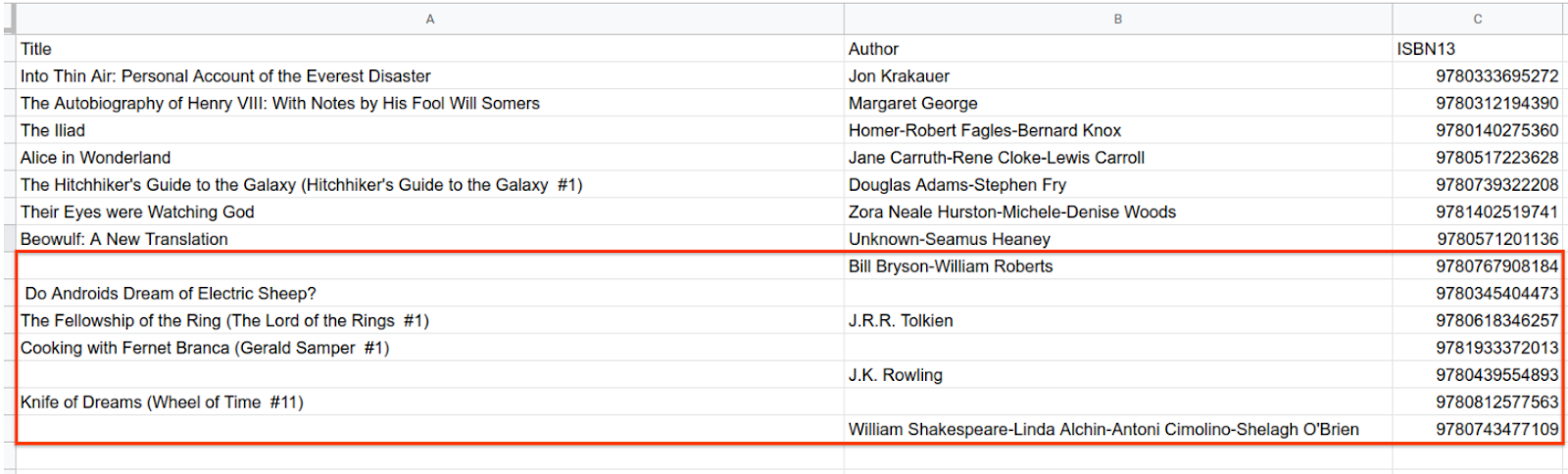
현재 보유한 데이터에 문자열 작업을 사용하여 누락된 데이터를 가져올 수는 없습니다. 대신 다른 소스에서 누락된 데이터를 가져와야 합니다. 추가 데이터를 제공할 수 있는 외부 API에서 정보를 요청하여 Apps Script에서 이 작업을 수행할 수 있습니다.
API는 애플리케이션 프로그래밍 인터페이스입니다. 일반적인 용어이지만 기본적으로 프로그램과 스크립트가 정보를 요청하거나 특정 작업을 실행하기 위해 호출할 수 있는 서비스입니다. 이 섹션에서는 공개적으로 제공되는 API를 호출하여 시트의 빈 셀에 삽입할 수 있는 도서 정보를 요청합니다.
이 섹션에서는 다음 방법을 설명합니다.
- 외부 API 소스에서 도서 데이터를 요청합니다.
- 반환된 데이터에서 제목과 저자 정보를 추출하여 스프레드시트에 작성합니다.
11. UrlFetch로 외부 데이터 가져오기
스프레드시트와 직접 작동하는 코드를 자세히 살펴보기 전에 공개 Open Library API에서 도서 정보를 요청하기 위한 도우미 함수를 만들어 Apps Script에서 외부 API를 사용하는 방법을 알아볼 수 있습니다.
헬퍼 함수 fetchBookData_(ISBN)는 도서의 13자리 ISBN 번호를 매개변수로 가져와 해당 도서에 관한 데이터를 반환합니다. Open Library API에 연결하여 정보를 가져온 다음 반환된 JSON 객체를 파싱합니다.
구현
다음을 실행하여 이 도우미 함수를 구현합니다.
- Apps Script 편집기에서 스크립트 끝에 다음 코드를 추가합니다.
/**
* Helper function to retrieve book data from the Open Library
* public API.
*
* @param {number} ISBN - The ISBN number of the book to find.
* @return {object} The book's data, in JSON format.
*/
function fetchBookData_(ISBN){
// Connect to the public API.
var url = "https://openlibrary.org/api/books?bibkeys=ISBN:"
+ ISBN + "&jscmd=details&format=json";
var response = UrlFetchApp.fetch(
url, {'muteHttpExceptions': true});
// Make request to API and get response before this point.
var json = response.getContentText();
var bookData = JSON.parse(json);
// Return only the data we're interested in.
return bookData['ISBN:' + ISBN];
}
- 스크립트 프로젝트를 저장합니다.
코드 검토
이 코드는 두 가지 주요 섹션으로 나뉩니다.
1: API 요청
처음 두 줄에서 fetchBookData_(ISBN)는 API의 URL 엔드포인트와 Apps Script의 URL 가져오기 서비스를 사용하여 공개 Open Library API에 연결됩니다.
url 변수는 웹 주소와 같은 URL 문자열일 뿐입니다. Open Library 서버의 위치를 가리킵니다. 또한 Open Library 서버에 요청하는 정보와 응답을 구성하는 방법을 알려주는 세 개의 매개변수 (bibkeys, jscmd, format)도 포함되어 있습니다. 이 경우 책의 ISBN 번호를 제공하고 자세한 정보를 JSON 형식으로 반환해 달라고 요청합니다.
URL 문자열을 빌드하면 코드가 위치에 요청을 보내고 응답을 수신합니다. 이 작업은 UrlFetchApp.fetch(url, params) 메서드를 통해 수행됩니다. 제공된 외부 URL로 정보 요청을 전송하고 결과 응답을 response 변수에 저장합니다. 이 코드는 URL 외에도 선택적 매개변수 muteHttpExceptions을 true로 설정합니다. 이 설정은 요청으로 인해 API 오류가 발생해도 코드가 중지되지 않음을 의미합니다. 대신 오류 응답이 반환됩니다.
요청은 response 변수에 저장된 HTTPResponse 객체를 반환합니다. HTTP 응답에는 응답 코드, HTTP 헤더, 기본 응답 콘텐츠가 포함됩니다. 여기서 관심 있는 정보는 기본 JSON 콘텐츠이므로 코드는 이를 추출한 다음 JSON을 파싱하여 원하는 정보를 찾아 반환해야 합니다.
2: API 응답 파싱 및 관심 정보 반환
마지막 세 줄의 코드에서 HTTPResponse.getContentText() 메서드는 응답의 기본 콘텐츠를 문자열로 반환합니다. 이 문자열은 JSON 형식으로 되어 있지만 Open Library API에서 정확한 콘텐츠와 형식을 정의합니다. JSON.parse(jsonString) 메서드는 JSON 문자열을 JavaScript 객체로 변환하므로 데이터의 여러 부분을 쉽게 추출할 수 있습니다. 마지막으로 함수는 도서의 ISBN 번호에 해당하는 데이터를 반환합니다.
결과
이제 fetchBookData_(ISBN)를 구현했으므로 코드의 다른 함수가 ISBN 번호를 사용하여 도서 정보를 찾을 수 있습니다. 이 함수를 사용하여 스프레드시트의 셀을 채웁니다.
12. 스프레드시트에 API 데이터 쓰기
이제 다음 작업을 실행하는 fillInTheBlanks() 함수를 구현할 수 있습니다.
- 활성 데이터 범위 내에서 누락된 제목 및 저자 데이터를 식별합니다.
fetchBookData_(ISBN)도우미 메서드를 사용하여 Open Library API를 호출하여 특정 도서의 누락된 데이터를 가져옵니다.- 누락된 제목 또는 저자 값을 해당 셀에 업데이트합니다.
구현
다음과 같이 이 새 함수를 구현합니다.
- Apps Script 편집기에서 스크립트 프로젝트 끝에 다음 코드를 추가합니다.
/**
* Fills in missing title and author data using Open Library API
* calls.
*/
function fillInTheBlanks(){
// Constants that identify the index of the title, author,
// and ISBN columns (in the 2D bookValues array below).
var TITLE_COLUMN = 0;
var AUTHOR_COLUMN = 1;
var ISBN_COLUMN = 2;
// Get the existing book information in the active sheet. The data
// is placed into a 2D array.
var dataRange = SpreadsheetApp.getActiveSpreadsheet()
.getDataRange();
var bookValues = dataRange.getValues();
// Examine each row of the data (excluding the header row).
// If an ISBN is present, and a title or author is missing,
// use the fetchBookData_(isbn) method to retrieve the
// missing data from the Open Library API. Fill in the
// missing titles or authors when they're found.
for(var row = 1; row < bookValues.length; row++){
var isbn = bookValues[row][ISBN_COLUMN];
var title = bookValues[row][TITLE_COLUMN];
var author = bookValues[row][AUTHOR_COLUMN];
if(isbn != "" && (title === "" || author === "") ){
// Only call the API if you have an ISBN number and
// either the title or author is missing.
var bookData = fetchBookData_(isbn);
// Sometimes the API doesn't return the information needed.
// In those cases, don't attempt to update the row.
if (!bookData || !bookData.details) {
continue;
}
// The API might not return a title, so only fill it in
// if the response has one and if the title is blank in
// the sheet.
if(title === "" && bookData.details.title){
bookValues[row][TITLE_COLUMN] = bookData.details.title;
}
// The API might not return an author name, so only fill it in
// if the response has one and if the author is blank in
// the sheet.
if(author === "" && bookData.details.authors
&& bookData.details.authors[0].name){
bookValues[row][AUTHOR_COLUMN] =
bookData.details.authors[0].name;
}
}
}
// Insert the updated book data values into the spreadsheet.
dataRange.setValues(bookValues);
}
- 스크립트 프로젝트를 저장합니다.
코드 검토
이 코드는 세 부분으로 나뉩니다.
1: 기존 도서 정보 읽기
함수의 처음 세 줄은 코드를 더 읽기 쉽게 만드는 데 도움이 되는 상수를 정의합니다. 다음 두 줄에서는 bookValues 변수를 사용하여 시트의 책 정보의 로컬 사본을 유지합니다. 코드는 bookValues에서 정보를 읽고, API를 사용하여 누락된 정보를 입력하고, 이러한 값을 스프레드시트에 다시 씁니다.
2: 도우미 함수를 사용하여 누락된 정보 가져오기
이 코드는 bookValues의 각 행을 루프하여 누락된 제목이나 저자를 찾습니다. 효율성을 개선하면서 API 호출 수를 줄이기 위해 코드는 다음 조건이 충족되는 경우에만 API를 호출합니다.
- 행의 ISBN 열에 값이 있습니다.
- 행의 제목 또는 저자 셀이 비어 있습니다.
조건이 참이면 코드는 이전에 구현한 fetchBookData_(isbn) 도우미 함수를 사용하여 API를 호출하고 결과를 bookData 변수에 저장합니다. 이제 시트에 삽입하려는 누락된 정보가 포함되어야 합니다.
이제 스프레드시트에 bookData 정보를 추가하기만 하면 됩니다. 하지만 주의할 점이 있습니다. Open Library Book API와 같은 공개 API에는 요청한 정보가 없거나 정보를 제공하지 못하도록 하는 다른 문제가 있는 경우가 있습니다. 모든 API 요청이 성공한다고 가정하면 예기치 않은 오류를 처리할 만큼 코드가 견고하지 않습니다.
코드가 API 오류를 처리할 수 있도록 하려면 코드가 API 응답을 사용하기 전에 유효한지 확인해야 합니다. 코드가 bookData되면 bookData 및 bookData.details에서 읽기를 시도하기 전에 간단한 검사를 실행하여 bookData 및 bookData.details가 있는지 확인합니다. 둘 중 하나라도 누락되었다면 API에 원하는 데이터가 없다는 의미입니다. 이 경우 continue 명령은 코드에 해당 행을 건너뛰라고 지시합니다. 누락된 셀을 채울 수는 없지만 스크립트가 비정상 종료되지는 않습니다.
3: 업데이트된 정보를 시트에 다시 작성
코드의 마지막 부분에는 API가 제목과 저자 정보를 반환했는지 확인하는 유사한 검사가 있습니다. 코드는 원래 제목 또는 저자 셀이 비어 있고 API가 여기에 배치할 수 있는 값을 반환한 경우에만 bookValues 배열을 업데이트합니다.
시트의 모든 행이 검사되면 루프가 종료됩니다. 마지막 단계는 이제 업데이트된 bookValues 배열을 Range.setValues(values)를 사용하여 스프레드시트에 다시 쓰는 것입니다.
결과
이제 도서 데이터 정리를 완료할 수 있습니다. 다음 단계를 따르세요.
- 아직 하지 않았다면 시트에서 A2:A15 범위를 강조 표시하고 도서 목록 > 첫 번째 쉼표에서 제목/저자 분리를 선택하여 쉼표 문제를 정리합니다.
- 아직 하지 않았다면 시트에서 A2:A15 범위를 강조 표시하고 도서 목록 > 마지막 'by'에서 제목/저자 분리를 선택하여 'by' 문제를 정리합니다.
- 나머지 셀을 모두 채우려면 도서 목록 > 빈 제목 및 저자 셀 채우기를 선택합니다.
13. 결론
이 Codelab을 완료하셨습니다. Apps Script 코드의 여러 부분을 활성화하는 맞춤 메뉴를 만드는 방법을 알아봤습니다. 또한 Apps Script 서비스와 공개 API를 사용하여 Google Sheets로 데이터를 가져오는 방법도 살펴보았습니다. 이는 스프레드시트 처리에서 흔히 사용되는 작업이며, Apps Script를 사용하면 다양한 소스에서 데이터를 가져올 수 있습니다. 마지막으로 Apps Script 서비스와 JavaScript를 사용하여 스프레드시트 데이터를 읽고, 처리하고, 삽입하는 방법을 살펴봤습니다.
이 Codelab이 도움이 되었나요?
학습한 내용
- Google 스프레드시트에서 데이터를 가져오는 방법
onOpen()함수에서 맞춤 메뉴를 만드는 방법- 문자열 데이터 값을 파싱하고 조작하는 방법
- URL Fetch Service를 사용하여 공개 API를 호출하는 방법
- 공개 API 소스에서 가져온 JSON 객체 데이터를 파싱하는 방법
다음 단계
이 재생목록의 다음 Codelab에서는 스프레드시트 내에서 데이터를 포맷하는 방법을 자세히 설명합니다.
다음 Codelab은 데이터 형식 지정에서 확인할 수 있습니다.