
1. Übersicht
Aufgaben in diesem Lab:
- Verwaltetes Dataset erstellen
- Daten aus einem Google Cloud Storage-Bucket importieren
- Spaltenmetadaten für die Verwendung mit AutoML aktualisieren
- Modell mit Optionen wie Budget und Optimierungsziel trainieren
- Online-Batchvorhersagen treffen
2. Daten ansehen
In diesem Lab werden Daten aus dem Dataset „Iowa Liquor Sales“ aus öffentlichen BigQuery-Datasets verwendet. Dieses Dataset enthält Daten zu Großhandelskäufen von Spirituosen im US-Bundesstaat Iowa seit 2012.
Wenn Sie sich die ursprünglichen Rohdaten ansehen möchten, wählen Sie Dataset ansehen aus. Um auf die Tabelle zuzugreifen, rufen Sie in der linken Navigationsleiste das Projekt bigquery-public-datasets, dann das Dataset iowa_liquor_sales und schließlich die Tabelle sales auf. Wenn Sie eine Auswahl von Zeilen aus dem Dataset sehen möchten, wählen Sie Vorschau aus.
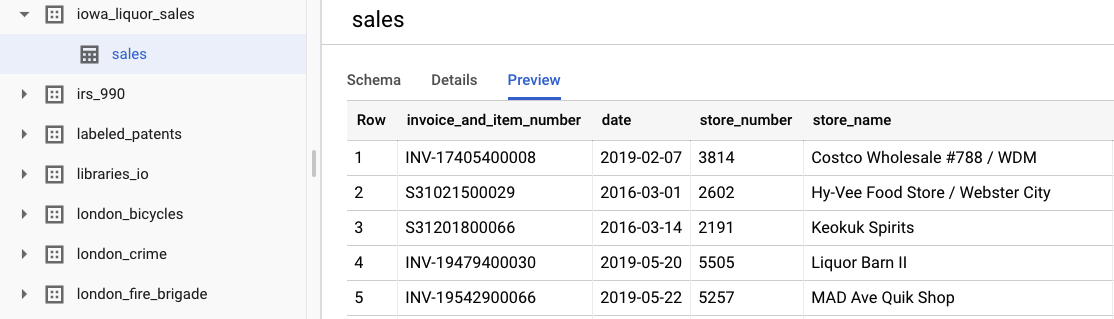
Für dieses Lab haben wir bereits eine grundlegende Datenvorverarbeitung durchgeführt, um die Käufe nach Tag zu gruppieren. Wir verwenden einen CSV-Auszug aus der BigQuery-Tabelle. Die Spalten in der CSV-Datei sind:
- ds: Das Datum
- y: Die Summe aller Käufe an diesem Tag in Dollar
- holiday: Ein boolescher Wert, der angibt, ob das Datum ein Feiertag in den USA ist.
- id: Eine Zeitachsenkennzeichnung zur Unterstützung mehrerer Zeitachsen, z.B. nach Geschäft oder Produkt. In diesem Fall prognostizieren wir einfach die Gesamtkäufe in einer Zeitachse. Daher wird „id“ für jede Zeile auf 0 gesetzt.
3. Daten importieren
Schritt 1: Zu Vertex AI-Datasets navigieren
Rufen Sie Datasets im Menü Vertex AI über die linke Navigationsleiste der Cloud Console auf.
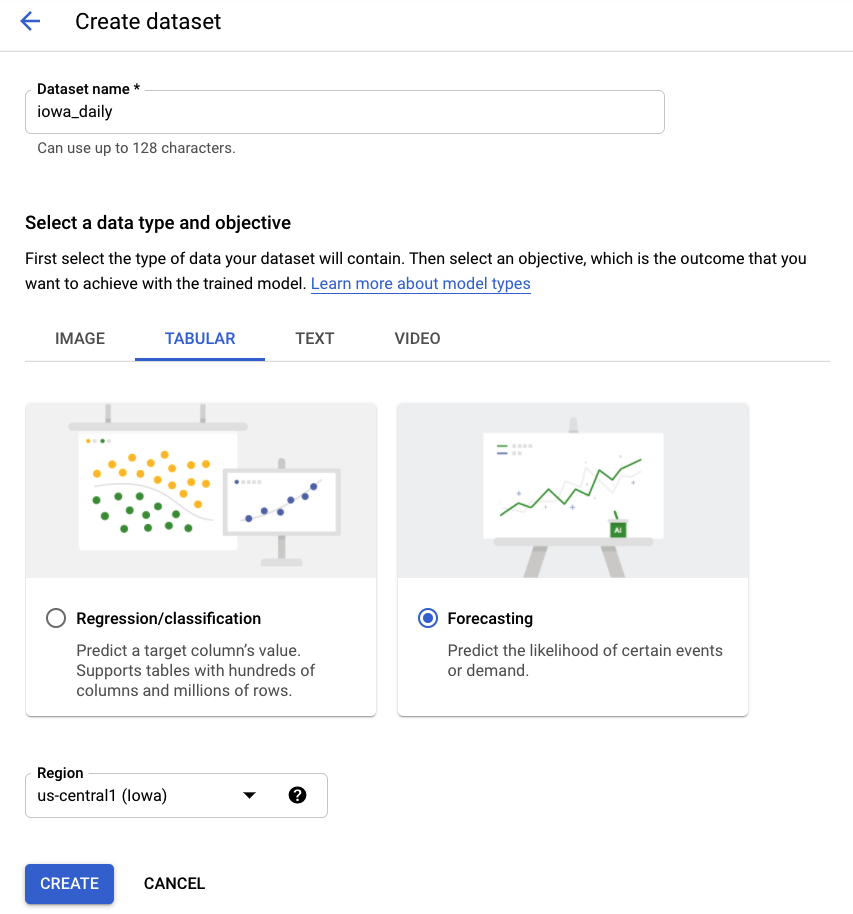
Schritt 2: Dataset erstellen
Erstellen Sie ein neues Dataset, indem Sie Tabellendaten und dann den Problemtyp Prognose auswählen. Wählen Sie den Namen „iowa_daily“ oder einen anderen Namen aus.
Schritt 3: Daten importieren
Im nächsten Schritt importieren Sie Daten in das Dataset. Wählen Sie die Option zum Auswählen einer CSV-Datei aus Cloud Storage aus. Rufen Sie dann die CSV-Datei im Bucket „AutoML Demo Alpha“ auf und fügen Sie automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv ein.
4. Modell trainieren
Schritt 1: Modellfunktionen konfigurieren
Nach einigen Minuten werden Sie von AutoML benachrichtigt, dass der Import abgeschlossen ist. An diesem Punkt können Sie die Modellfunktionen konfigurieren.
- Wählen Sie als Spalte für Zeitreihenkennzeichnung die Spalte id aus. Da unser Dataset nur eine Zeitreihe enthält, ist dies nur eine Formalität.
- Wählen Sie die Zeitspalte aus, die ds sein soll.
Wählen Sie dann Statistiken generieren aus. Nach Abschluss des Vorgangs werden die Statistiken Fehlende % und Eindeutige Werte angezeigt. Dieser Vorgang kann einige Minuten dauern. Sie können in der Zwischenzeit mit dem nächsten Schritt fortfahren.
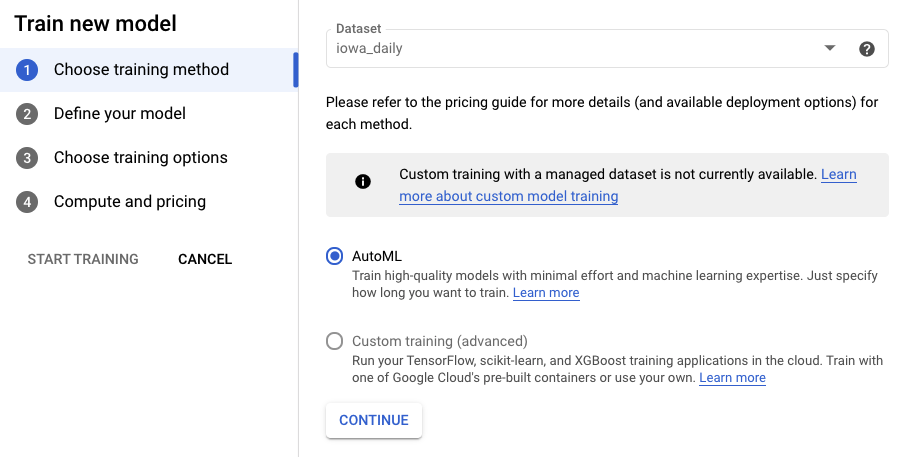
Schritt 2: Modell trainieren
Wählen Sie Modell trainieren aus, um den Trainingsprozess zu starten. Achten Sie darauf, dass AutoML ausgewählt ist, und klicken Sie auf Weiter.
Schritt 3: Modell definieren
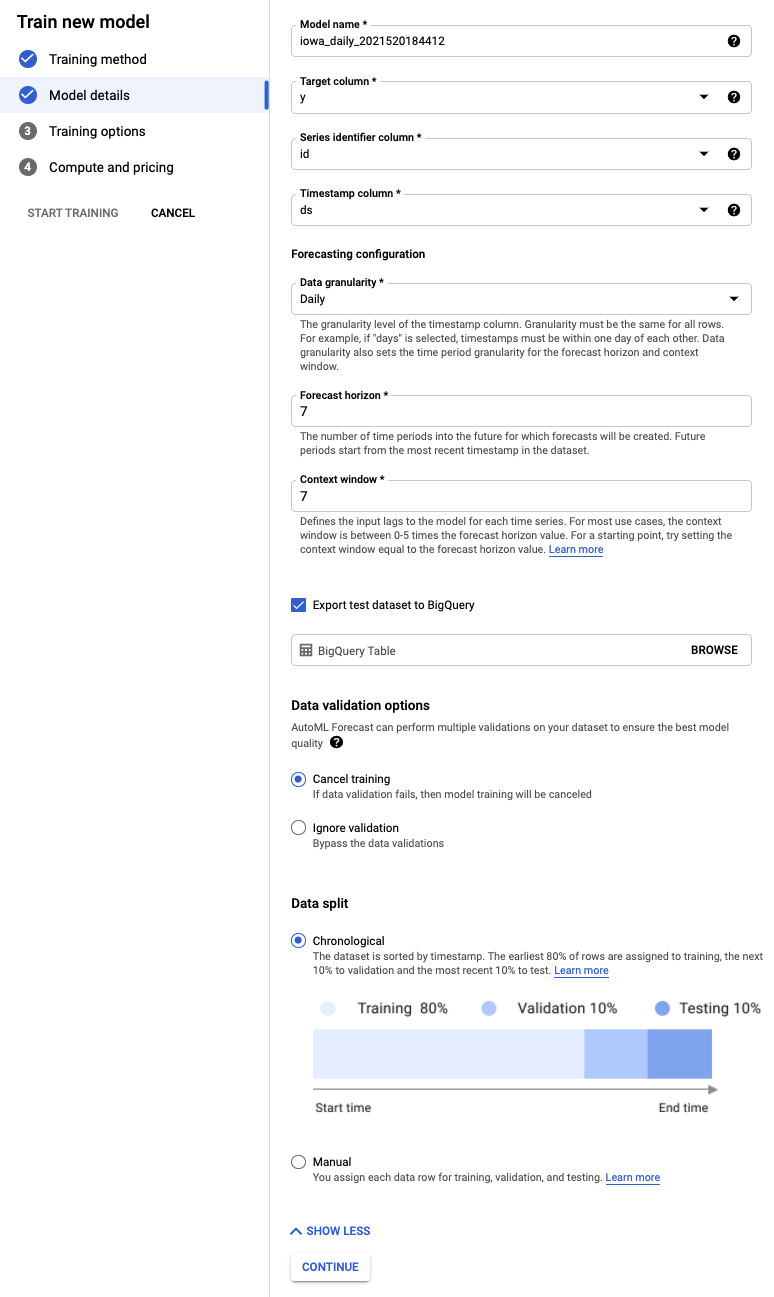
- Wählen Sie y als Zielspalte aus. Das ist der Wert, den wir vorhersagen.
- Wenn Sie die Spalte Achsenkennzeichnung nicht bereits festgelegt haben, legen Sie sie auf id und die Zeitstempelspalte auf ds fest.
- Legen Sie den Detaillierungsgrad der Daten auf Tage und den Prognosezeitraum auf 7 fest. In diesem Feld wird die Anzahl der Zeiträume angegeben, für die das Modell Vorhersagen treffen kann.
- Legen Sie den Kontextfenster auf 7 Tage fest. Das Modell verwendet Daten aus den letzten 30 Tagen, um eine Vorhersage zu treffen. Es gibt Kompromisse zwischen kürzeren und längeren Zeiträumen. Im Allgemeinen wird empfohlen, einen Wert zwischen dem 1- und 10-Fachen des Prognosezeitraums auszuwählen.
- Klicken Sie das Kästchen Test-Dataset nach BigQuery exportieren an. Sie können das Feld leer lassen. In diesem Fall werden automatisch ein Dataset und eine Tabelle in Ihrem Projekt erstellt. Alternativ können Sie einen beliebigen Speicherort angeben.
- Wählen Sie Weiter aus.
Schritt 4: Trainingsoptionen festlegen
In diesem Schritt können Sie weitere Details zum Training des Modells angeben.
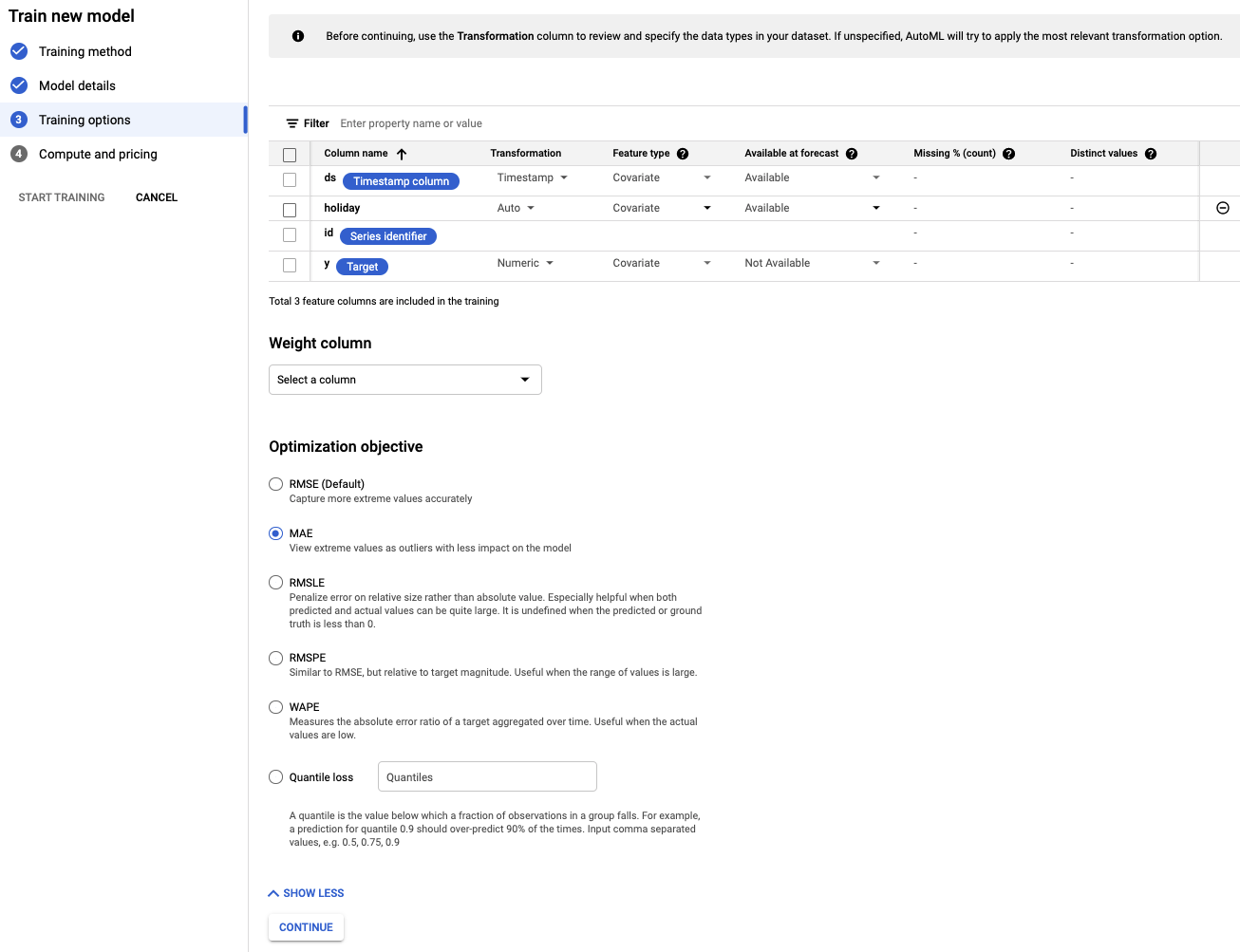
- Legen Sie für die Spalte holiday (Feiertag) den Wert Available (Verfügbar) für die Vorhersage fest, da wir im Voraus wissen, ob ein bestimmtes Datum ein Feiertag ist.
- Ändern Sie das Optimierungsziel in MAE. Der MAE (Mean Absolute Error, mittlerer absoluter Fehler) ist im Vergleich zum MSE (Mean Squared Error, mittlerer quadratischer Fehler) robuster gegenüber Ausreißern. Da wir mit täglichen Kaufdaten arbeiten, die starken Schwankungen unterliegen können, ist MAE eine geeignete Messgröße.
- Wählen Sie Weiter aus.
Schritt 5: Training starten
Legen Sie ein Budget Ihrer Wahl fest. In diesem Fall reicht 1 Knotenstunde aus, um das Modell zu trainieren. Beginnen Sie dann mit dem Training.
Schritt 6: Modell bewerten
Der Trainingsprozess kann ein bis zwei Stunden dauern (einschließlich zusätzlicher Einrichtungszeit). Sobald das Training abgeschlossen ist, erhalten Sie eine E‑Mail. Wenn es fertig ist, können Sie die Genauigkeit des erstellten Modells ansehen.
5. Vorhersagen
Schritt 1: Vorhersagen für Testdaten prüfen
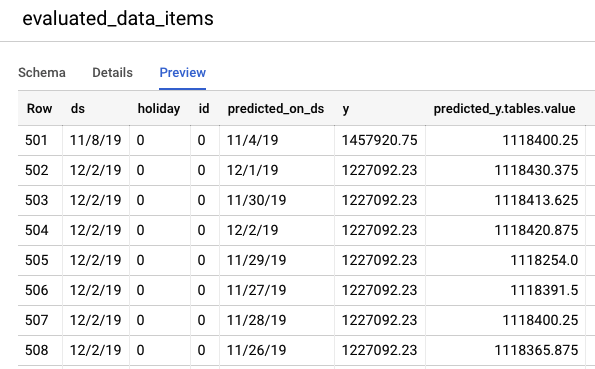
Rufen Sie die BigQuery-Konsole auf, um die Vorhersagen für Testdaten anzusehen. In Ihrem Projekt wird automatisch ein neuer Datenpool mit dem Namensschema export_evaluated_data_items + <Modellname> + <Zeitstempel> erstellt. In diesem Datenpool finden Sie die Tabelle evaluated_data_items, in der Sie die Vorhersagen überprüfen können.
Diese Tabelle enthält einige neue Spalten:
- predicted_on_[date column]: Das Datum, an dem die Vorhersage erstellt wurde. Wenn predicted_on_ds beispielsweise der 4. November und ds der 8. November ist, wird 4 Tage im Voraus prognostiziert.
- predicted_[target column].tables.value: Der vorhergesagte Wert
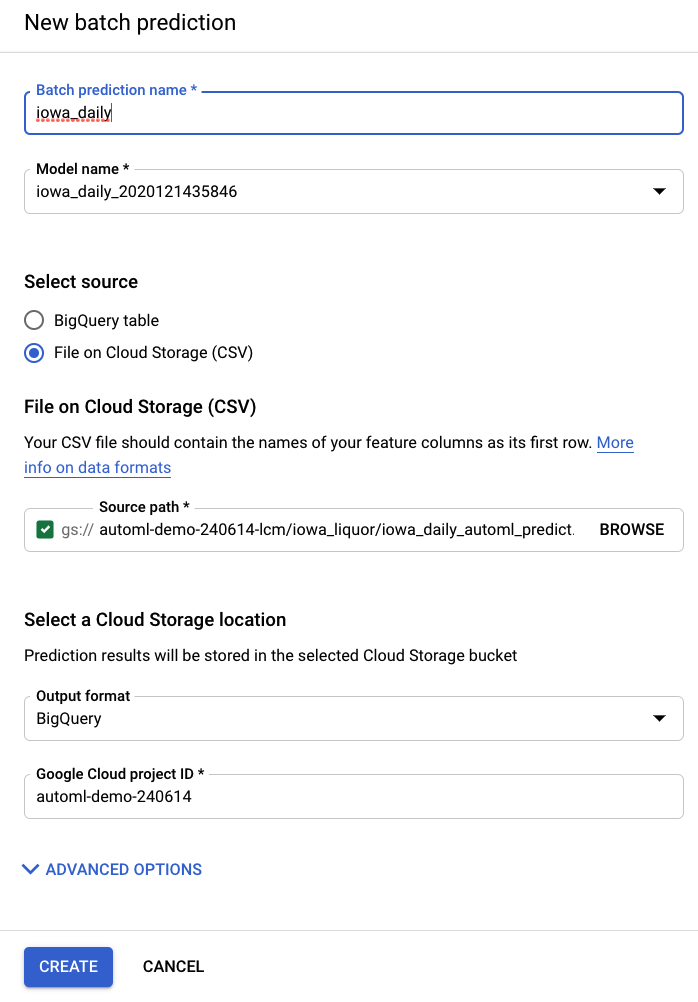
Schritt 2: Batchvorhersagen ausführen
Schließlich möchten Sie Ihr Modell für Vorhersagen verwenden.
Die Eingabedatei enthält leere Werte für die vorherzusagenden Daten sowie bisherige Daten:
ds | Feiertag | id | y |
15.05.2020 | 0 | 0 | 1751315.43 |
16.05.2020 | 0 | 0 | 0 |
17.05.2020 | 0 | 0 | 0 |
18.05.2020 | 0 | 0 | 1612066.43 |
19.05.2020 | 0 | 0 | 1.773.885,17 |
20.05.2020 | 0 | 0 | 1487270.92 |
21.05.2020 | 0 | 0 | 1024051.76 |
22.05.2020 | 0 | 0 | 1471736.31 |
23.05.2020 | 0 | 0 | <empty> |
24.05.2020 | 0 | 0 | <empty> |
25.05.2020 | 1 | 0 | <empty> |
26.05.2020 | 0 | 0 | <empty> |
27.05.2020 | 0 | 0 | <empty> |
28.05.2020 | 0 | 0 | <empty> |
29.05.2020 | 0 | 0 | <empty> |
Über das Element Batchvorhersagen in der linken Navigationsleiste von AI Platform (Unified) können Sie eine neue Batchvorhersage erstellen.
Eine Beispiel-Eingabedatei wird für Sie in einem Speicher-Bucket erstellt: automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv
Sie können diesen Speicherort der Quelldatei angeben. Anschließend können Sie Ihre Vorhersagen entweder als CSV in einen Cloud Storage-Speicherort oder in BigQuery exportieren. Wählen Sie für dieses Lab BigQuery und dann Ihre Google Cloud-Projekt-ID aus.
Der Batchvorhersageprozess dauert einige Minuten. Nach Abschluss des Jobs können Sie auf den Batchvorhersagejob klicken, um die Details, einschließlich des Exportspeicherorts, aufzurufen. In BigQuery müssen Sie in der linken Navigationsleiste zum Projekt, Dataset oder zur Tabelle navigieren, um auf die Vorhersagen zuzugreifen.
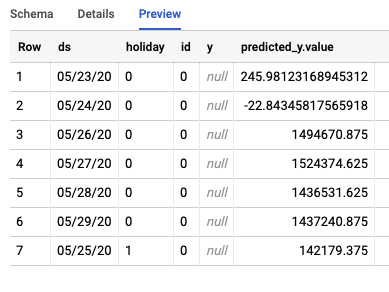
Mit dem Job werden zwei verschiedene Tabellen in BigQuery erstellt. Eine enthält alle Zeilen mit Fehlern und die andere die Vorhersagen. Hier ein Beispiel für die Ausgabe der Tabelle „Vorhersagen“:
Schritt 3: Fazit
Sie haben erfolgreich ein Prognosemodell mit AutoML erstellt und trainiert. In diesem Lab haben wir uns mit dem Importieren von Daten, dem Erstellen von Modellen und dem Treffen von Vorhersagen beschäftigt.
Sie können jetzt Ihr eigenes Prognosemodell erstellen.