
1. Descripción general
En este lab, aprenderás a hacer lo siguiente:
- Crea un conjunto de datos administrado
- Importa datos desde un bucket de Google Cloud Storage
- Actualiza los metadatos de la columna para que se usen de forma adecuada con AutoML
- Entrena un modelo con opciones como un presupuesto y un objetivo de optimización
- Haz predicciones por lotes en línea
2. Revisa los datos
En este lab, se usan datos del conjunto de datos de ventas de licor de Iowa de los conjuntos de datos públicos de BigQuery. Este conjunto de datos contiene las compras mayoristas de bebidas alcohólicas en el estado de Iowa, EE.UU., desde 2012.
Para ver los datos sin procesar originales, selecciona Ver conjunto de datos. Para acceder a la tabla, navega en la barra de navegación de la izquierda hasta el proyecto bigquery-public-datasets, luego el conjunto de datos iowa_liquor_sales y, por último, la tabla sales. Puedes seleccionar Vista previa para ver una selección de filas del conjunto de datos.
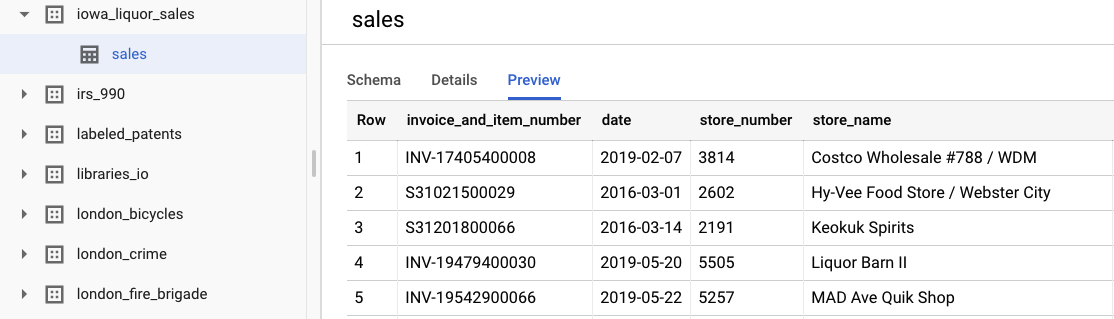
Para los fines de este lab, ya realizamos un preprocesamiento básico de los datos para agrupar las compras por día. Usaremos una extracción CSV de la tabla de BigQuery. Las columnas del archivo CSV son las siguientes:
- ds: La fecha
- y: Suma de todas las compras de ese día en dólares
- holiday: Es un valor booleano que indica si la fecha es un día feriado en EE.UU.
- id: Es un identificador de serie temporal (para admitir varias series temporales, p.ej., por tienda o por producto). En este caso, simplemente predeciremos las compras generales en una serie temporal, por lo que el ID se establece en 0 para cada fila.
3. Importar datos
Paso 1: Navega a Conjuntos de datos de Vertex AI
Accede a Conjuntos de datos en el menú Vertex AI de la barra de navegación izquierda de la consola de Cloud.
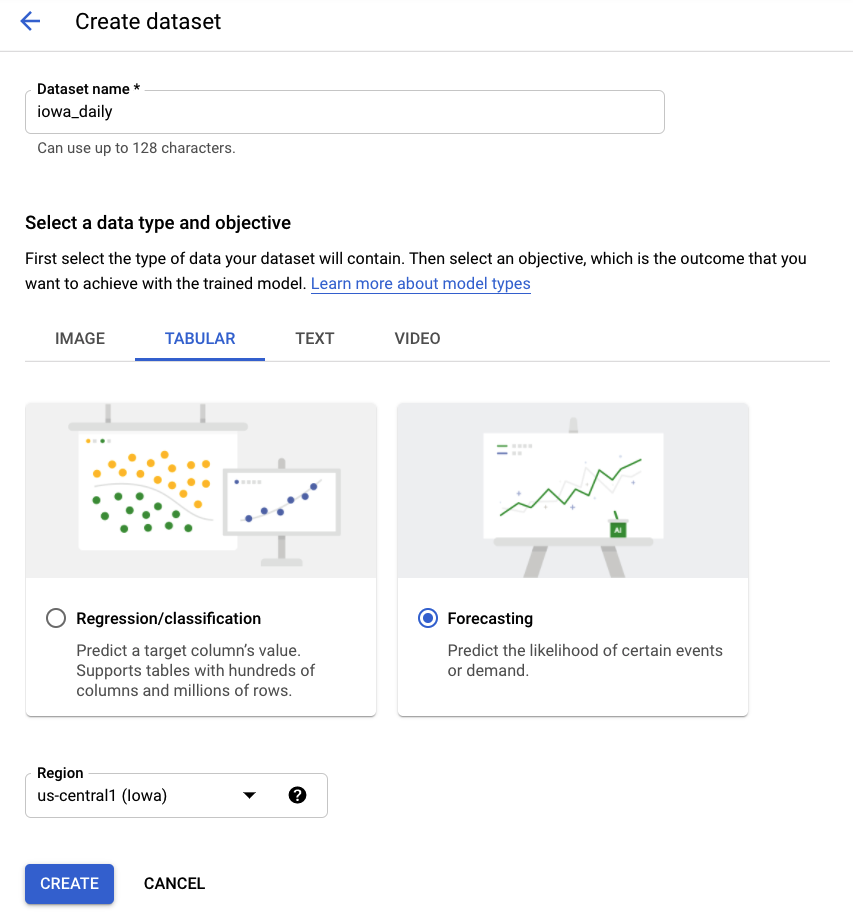
Paso 2: Crea un conjunto de datos
Crea un nuevo conjunto de datos, selecciona Datos tabulares y, luego, el tipo de problema Previsión. Elige el nombre iowa_daily o el que prefieras.
Paso 3: Importa datos
El siguiente paso es importar datos al conjunto de datos. Elige la opción para seleccionar un archivo CSV de Cloud Storage. Luego, navega al archivo CSV en el bucket de la versión alfa de AutoML Demo y pega automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv.
4. Entrenar modelo
Paso 1: Configura los atributos del modelo
Después de unos minutos, AutoML te notificará que se completó la importación. En ese punto, puedes configurar las funciones del modelo.
- Selecciona la columna de identificador de serie temporal como id. Solo tenemos una serie temporal en nuestro conjunto de datos, por lo que esto es una formalidad.
- Selecciona la columna de tiempo que será ds.
Luego, selecciona Generar estadísticas. Una vez que se complete el proceso, verás las estadísticas de Porcentaje de faltantes y Valores distintos. Este proceso puede tardar unos minutos, así que puedes continuar con el siguiente paso si lo deseas.
Paso 2: Entrena el modelo
Selecciona Entrenar el modelo para comenzar el proceso de entrenamiento. Asegúrate de que AutoML esté seleccionado y haz clic en Continuar.
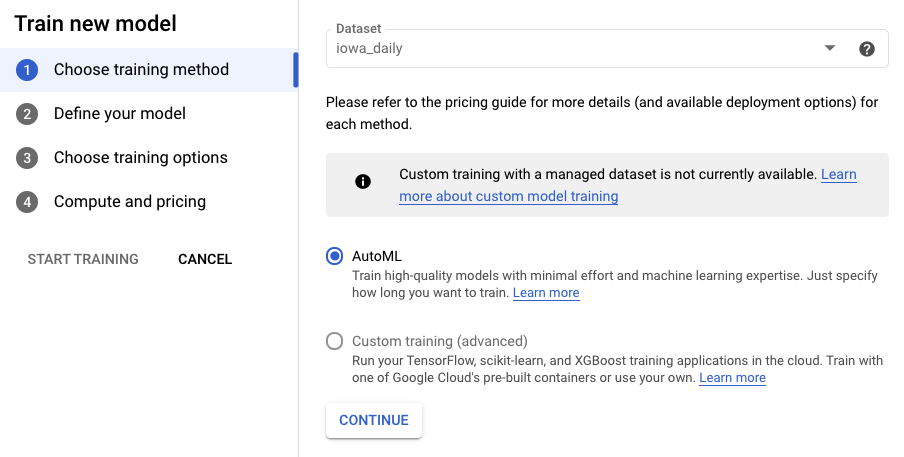
Paso 3: Define el modelo
- Selecciona la columna objetivo como Y. Ese es el valor que predecimos.
- Si no se configuraron antes, establece la columna Identificador de la serie en id y la columna Marca de tiempo en ds.
- Establece el Nivel de detalle de los datos en Días y el Horizonte de previsión en 7. En este campo, se especifica la cantidad de períodos futuros para los que el modelo puede generar predicciones.
- Establece la ventana de contexto en 7 días. El modelo usará datos de los últimos 30 días para realizar una predicción. Existen ventajas y desventajas entre las ventanas más cortas y las más largas, y, en general, se recomienda seleccionar un valor entre 1 y 10 veces el horizonte de previsión.
- Marca la casilla para exportar el conjunto de datos de prueba a BigQuery. Puedes dejarlo en blanco y se crearán automáticamente un conjunto de datos y una tabla en tu proyecto (o especificar la ubicación que elijas).
- Selecciona Continuar.
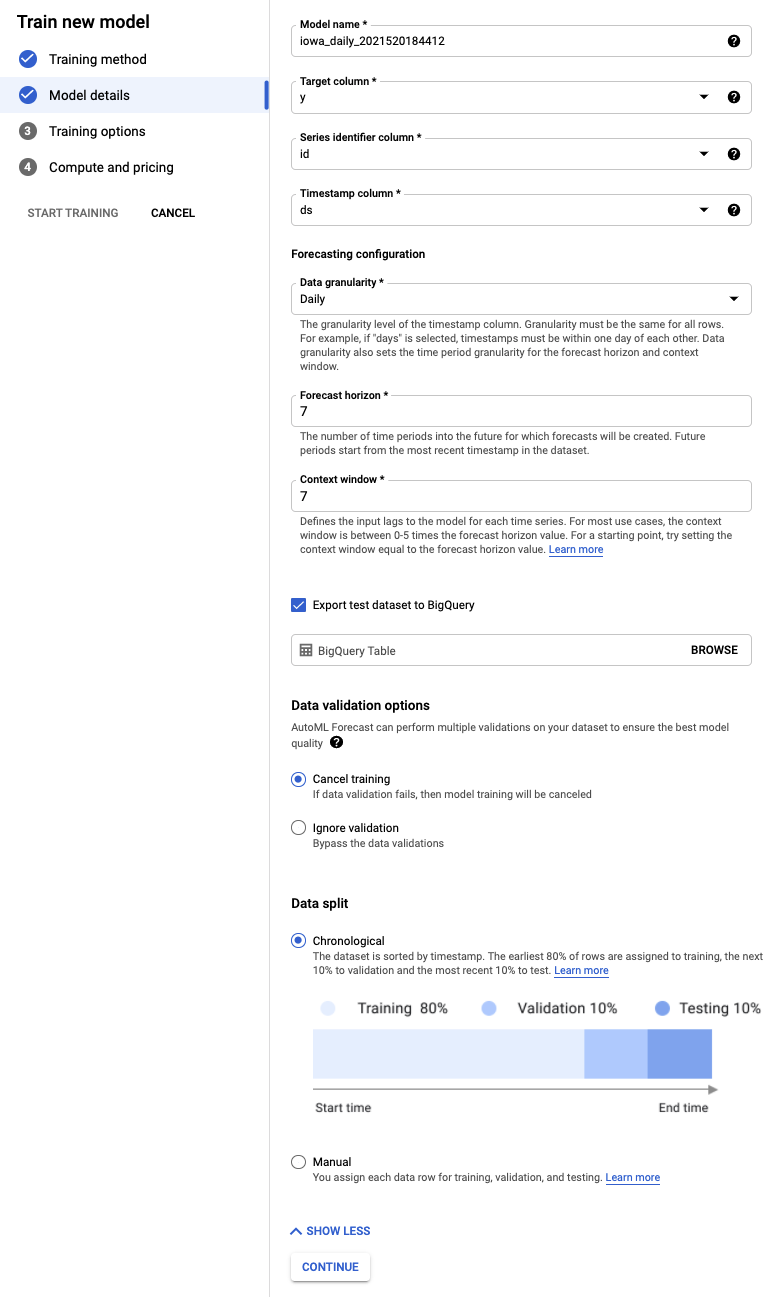
Paso 4: Configura las opciones de entrenamiento
En este paso, puedes especificar más detalles sobre cómo deseas entrenar el modelo.
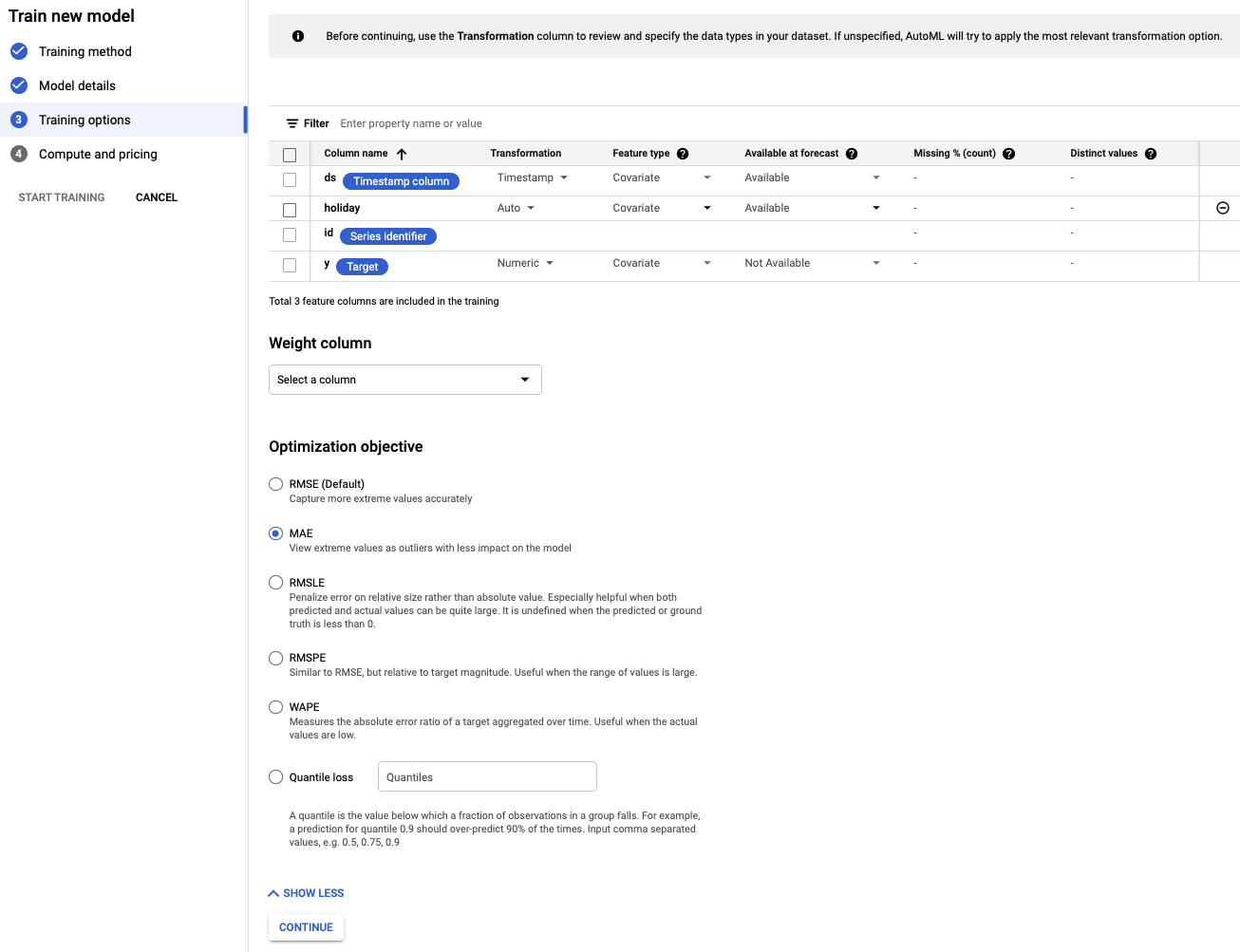
- Establece la columna holiday como Available en la predicción, ya que sabemos si una fecha determinada es un día festivo con anticipación.
- Cambia el objetivo de optimización a MAE. El MAE, o error promedio absoluto, es más resistente a los valores atípicos en relación con el error cuadrático medio. Dado que trabajamos con datos de compras diarias que pueden tener fluctuaciones significativas, el MAE es una métrica adecuada para usar.
- Selecciona Continuar.
Paso 5: Inicia el entrenamiento
Establece el presupuesto que desees. En este caso, 1 hora de nodo es suficiente para entrenar el modelo. Luego, comienza el proceso de entrenamiento.
Paso 6: Evalúa el modelo
El proceso de entrenamiento puede tardar entre 1 y 2 horas en completarse (incluido el tiempo de configuración adicional). Recibirás un correo electrónico cuando se complete el entrenamiento. Cuando esté listo, podrás ver la precisión del modelo que creaste.
5. Predecir
Paso 1: Revisa las predicciones sobre los datos de prueba
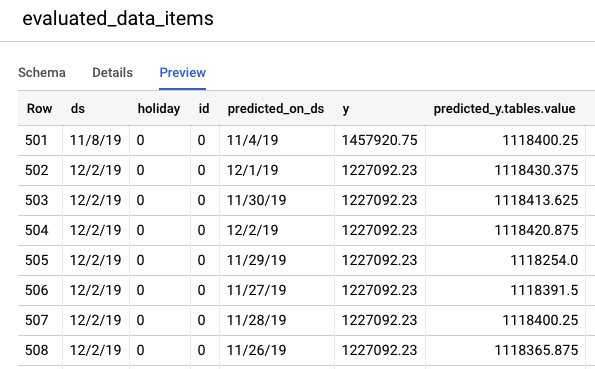
Navega a la consola de BigQuery para ver las predicciones sobre los datos de prueba. Dentro de tu proyecto, se crea automáticamente un nuevo conjunto de datos con el esquema de nombres: export_evaluated_data_items + <nombre del modelo> + <marca de tiempo>. Dentro de ese conjunto de datos, encontrarás la tabla evaluated_data_items para revisar las predicciones.
Esta tabla tiene algunas columnas nuevas:
- predicted_on_[columna de fecha]: Es la fecha en la que se realizó la predicción. Por ejemplo, si predicted_on_ds es el 4/11 y ds es el 8/11, estamos realizando una predicción con 4 días de anticipación.
- predicted_[target column].tables.value: Es el valor predicho.
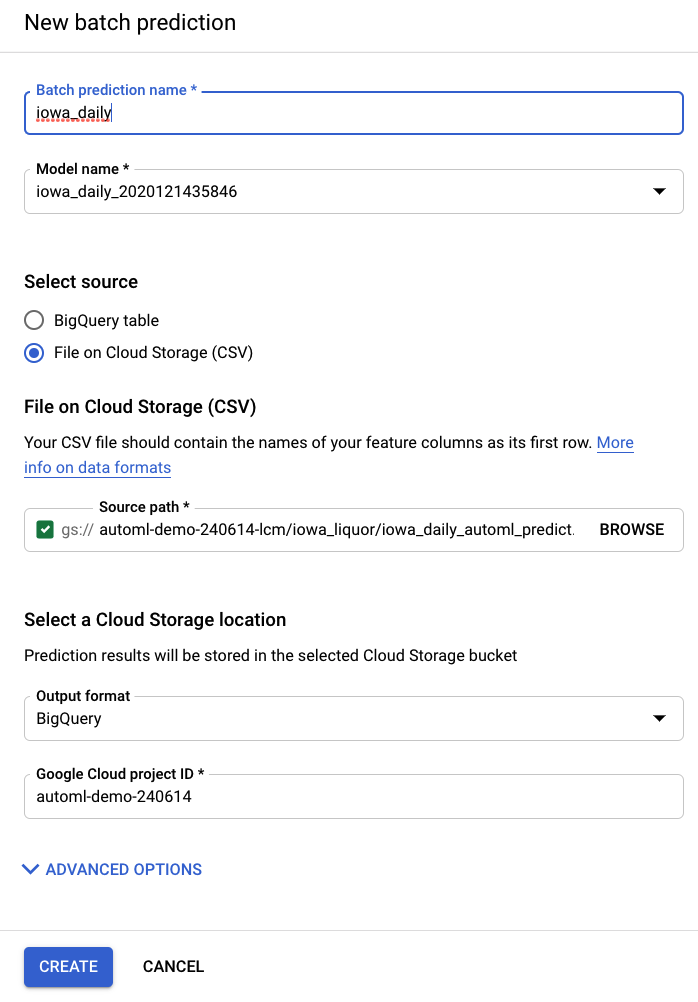
Paso 2: Realiza predicciones por lotes
Por último, querrás usar tu modelo para hacer predicciones.
El archivo de entrada contiene valores vacíos para las fechas que se predecirán, junto con datos históricos:
ds | feriado | id | y |
15/5/20 | 0 | 0 | 1751315.43 |
16/5/20 | 0 | 0 | 0 |
17/5/20 | 0 | 0 | 0 |
18/5/20 | 0 | 0 | 1612066.43 |
19/5/20 | 0 | 0 | 1773885.17 |
20/5/20 | 0 | 0 | 1487270.92 |
21/5/20 | 0 | 0 | 1024051.76 |
22/5/20 | 0 | 0 | 1471736.31 |
23/5/20 | 0 | 0 | <empty> |
24/5/20 | 0 | 0 | <empty> |
25/5/20 | 1 | 0 | <empty> |
26/5/20 | 0 | 0 | <empty> |
27/5/20 | 0 | 0 | <empty> |
28/5/20 | 0 | 0 | <empty> |
29/5/20 | 0 | 0 | <empty> |
En el elemento Predicciones por lotes de la barra de navegación izquierda de AI Platform (unificado), puedes crear una predicción por lotes nueva.
Aquí se crea un archivo de entrada de ejemplo en un bucket de almacenamiento: automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv
Puedes proporcionar la ubicación de este archivo fuente. Luego, puedes elegir exportar tus predicciones a una ubicación de almacenamiento en la nube como un archivo CSV o a BigQuery. Para los fines de este lab, selecciona BigQuery y elige el ID de tu proyecto de Google Cloud.
El proceso de predicción por lotes tardará varios minutos. Una vez que se complete, puedes hacer clic en el trabajo de predicción por lotes para ver los detalles, incluida la Ubicación de exportación. En BigQuery, deberás navegar al proyecto, el conjunto de datos o la tabla en la barra de navegación izquierda para acceder a las predicciones.
El trabajo creará dos tablas diferentes en BigQuery. Uno contendrá las filas con errores y el otro, las predicciones. Este es un ejemplo del resultado de la tabla Predictions:
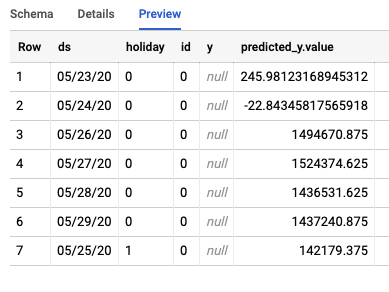
Paso 3: Conclusión
¡Felicitaciones! Creaste y entrenaste correctamente un modelo de previsión con AutoML. En este lab, vimos cómo importar datos, compilar modelos y realizar predicciones.
Ya puedes crear tu propio modelo de previsión.