
1. סקירה כללית
בשיעור ה-Lab הזה:
- יצירה של מערך נתונים מנוהל
- ייבוא נתונים מקטגוריה של Google Cloud Storage
- עדכון המטא-נתונים של העמודה לשימוש מתאים ב-AutoML
- אימון מודל באמצעות אפשרויות כמו תקציב ויעד אופטימיזציה
- ביצוע חיזויים אונליין באצווה
2. בדיקת הנתונים
בשיעור ה-Lab הזה משתמשים בנתונים ממערך הנתונים של מכירות משקאות חריפים באיווה מתוך מערכי נתונים ציבוריים של BigQuery. מערך הנתונים הזה כולל רכישות של אלכוהול בכמויות גדולות במדינת איווה בארה"ב מאז 2012.
כדי לראות את הנתונים הגולמיים המקוריים, בוחרים באפשרות הצגת מערך הנתונים. כדי לגשת לטבלה, עוברים בסרגל הניווט הימני לפרויקט bigquery-public-datasets, ואז למערך הנתונים iowa_liquor_sales, ואז לטבלה sales. אפשר ללחוץ על תצוגה מקדימה כדי לראות מבחר של שורות מקבוצת הנתונים.
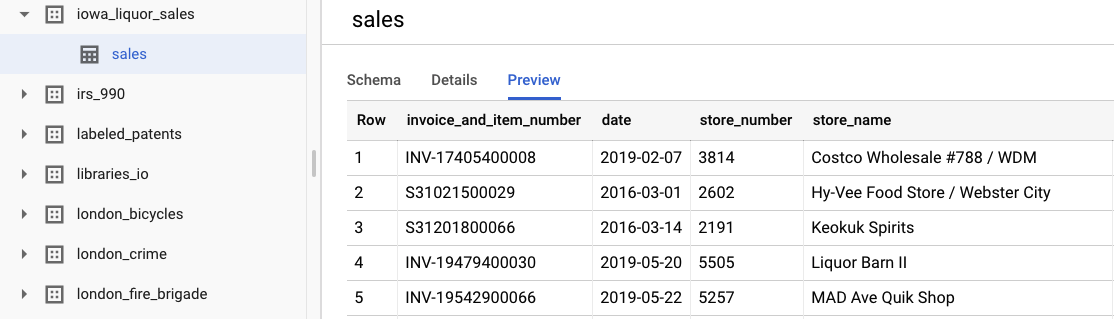
לצורך שיעור ה-Lab הזה, כבר ביצענו עיבוד מקדים בסיסי של הנתונים כדי לקבץ את הרכישות לפי יום. נשתמש בחילוץ CSV מטבלת BigQuery. העמודות בקובץ ה-CSV הן:
- ds: התאריך
- y: סכום כל הרכישות באותו יום בדולרים
- holiday: ערך בוליאני שמציין אם התאריך הוא חג בארה"ב
- id: מזהה של סדרת נתונים עיתיים (כדי לתמוך בכמה סדרות נתונים עיתיים, למשל לפי חנות או לפי מוצר). במקרה הזה, אנחנו פשוט נחזה את סך הרכישות בסדרת זמן אחת, ולכן הערך של id מוגדר כ-0 בכל שורה.
3. ייבוא נתונים
שלב 1: עוברים אל Vertex AI Datasets
בתפריט Vertex AI בסרגל הניווט הימני של מסוף Cloud, לוחצים על מערכי נתונים.
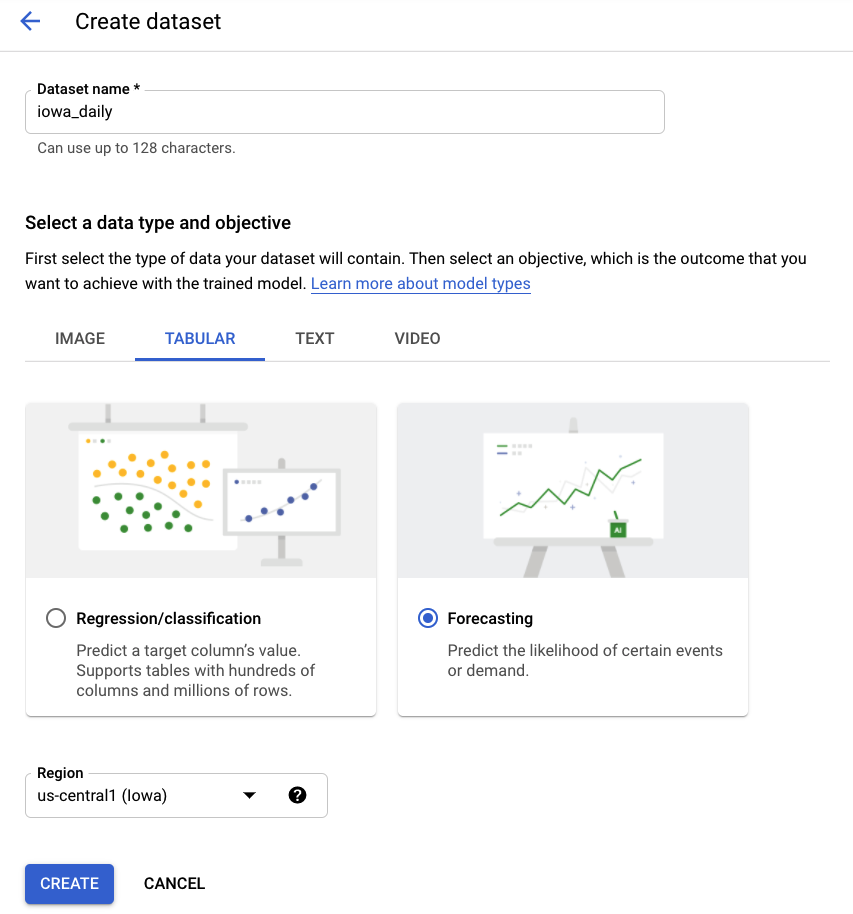
שלב 2: יצירת מערך נתונים
יוצרים מערך נתונים חדש, בוחרים באפשרות Tabular Data (נתונים בטבלה) ואז בסוג הבעיה Forecasting (תחזיות). בוחרים את השם iowa_daily או שם אחר שרוצים.
שלב 3: ייבוא נתונים
השלב הבא הוא לייבא נתונים למערך הנתונים. בוחרים באפשרות 'בחירת קובץ CSV מ-Cloud Storage'. לאחר מכן, עוברים לקובץ ה-CSV בדלי של AutoML Demo Alpha ומדביקים את automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv.
4. מודל רכבת
שלב 1: הגדרת תכונות המודל
אחרי כמה דקות, AutoML ישלח לכם הודעה שהייבוא הסתיים. בשלב הזה, אפשר להגדיר את התכונות של המודל.
- בוחרים את עמודת המזהה של סדרת הזמן ומשנים אותה ל-id. יש לנו רק סדרת זמן אחת במערך הנתונים, אז זה רק עניין פורמלי.
- בוחרים את עמודת השעה ומשנים את הפורמט ל-ds.
לאחר מכן, בוחרים באפשרות יצירת נתונים סטטיסטיים. בסיום התהליך יוצגו הנתונים הסטטיסטיים Missing % ו-Distinct values. התהליך הזה עשוי להימשך כמה דקות, לכן אפשר להמשיך לשלב הבא.
שלב 2: אימון המודל
לוחצים על אימון המודל כדי להתחיל בתהליך האימון. מוודאים שהאפשרות AutoML נבחרה ולוחצים על המשך.
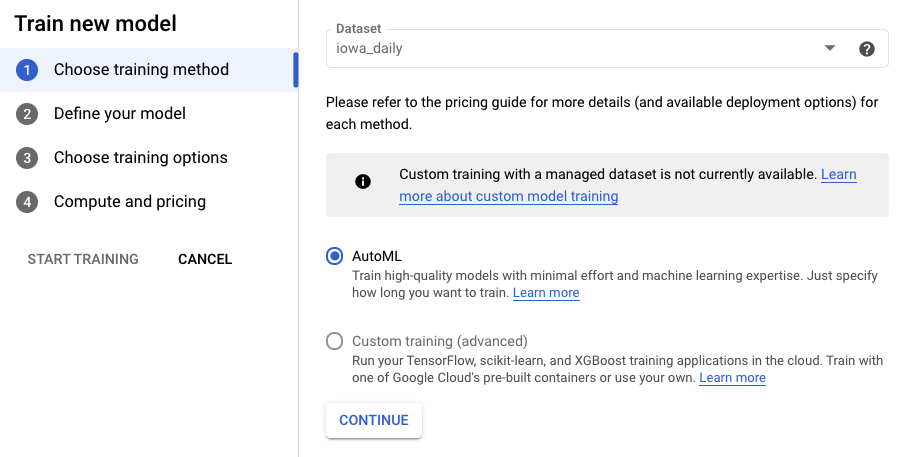
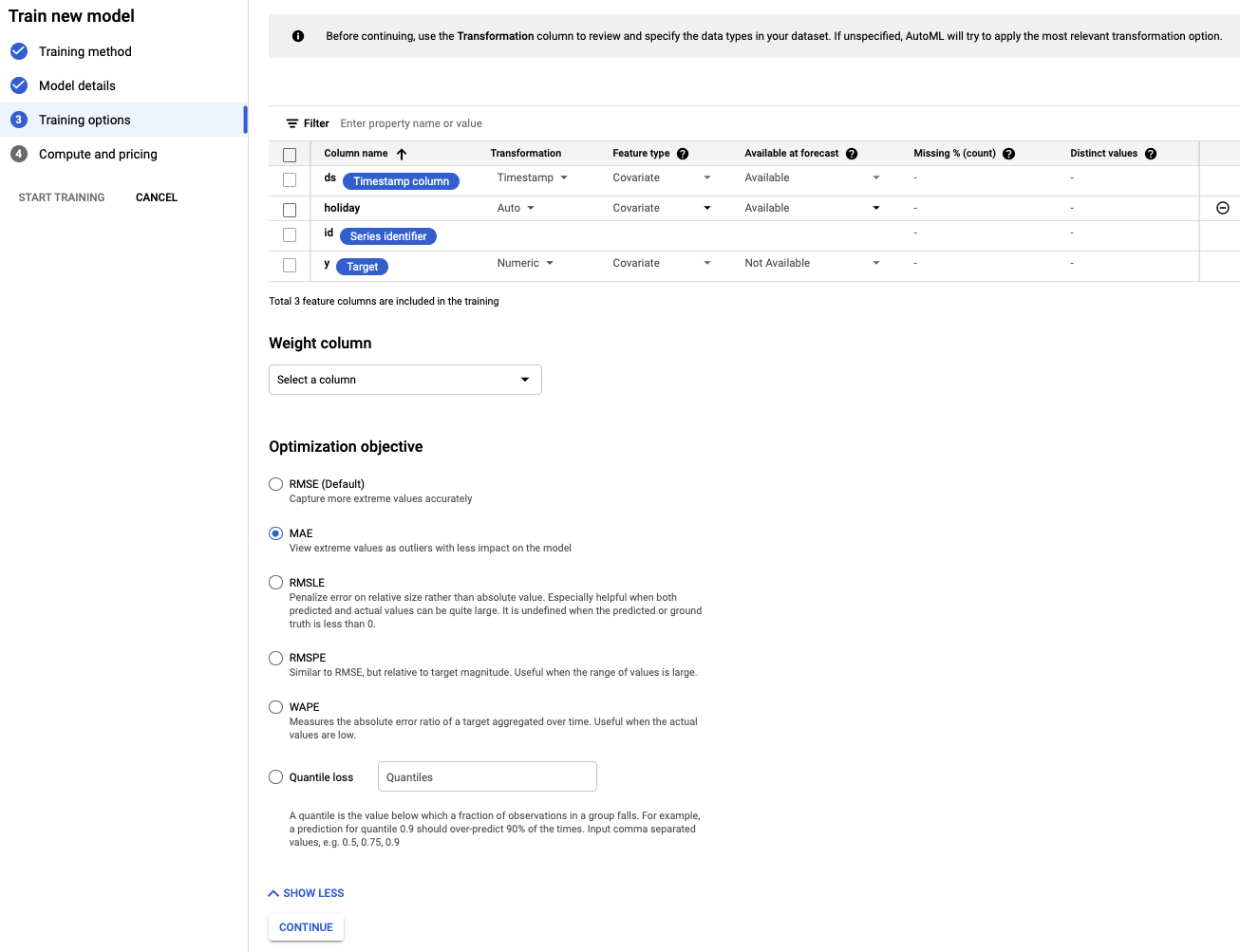
שלב 3: הגדרת המודל
- בוחרים את עמודת היעד שרוצים להגדיר כ-y. זה הערך שאנחנו מנסים לחזות.
- אם לא הגדרתם את העמודה Series identifier (מזהה הסדרה) לערך id ואת Timestamp column (עמודת חותמת הזמן) לערך ds בשלב מוקדם יותר, עכשיו צריך לעשות זאת.
- מגדירים את רזולוציית הנתונים לערך ימים ואת טווח התחזית לערך 7. בשדה הזה מצוין מספר התקופות שהמודל יכול לחזות לגבי העתיד.
- מגדירים את חלון ההקשר ל-7 ימים. המודל ישתמש בנתונים מ-30 הימים הקודמים כדי ליצור תחזית. יש יתרונות וחסרונות לחלונות קצרים יותר ולחלונות ארוכים יותר, ובדרך כלל מומלץ לבחור ערך שהוא בין פי 1 לפי 10 מאופק התחזית.
- מסמנים את התיבה Export test dataset to BigQuery (ייצוא מערך נתוני בדיקה ל-BigQuery). אפשר להשאיר את השדה הזה ריק, ואז המערכת תיצור אוטומטית מערך נתונים וטבלה בפרויקט (או לציין מיקום לבחירתכם).
- לוחצים על המשך.
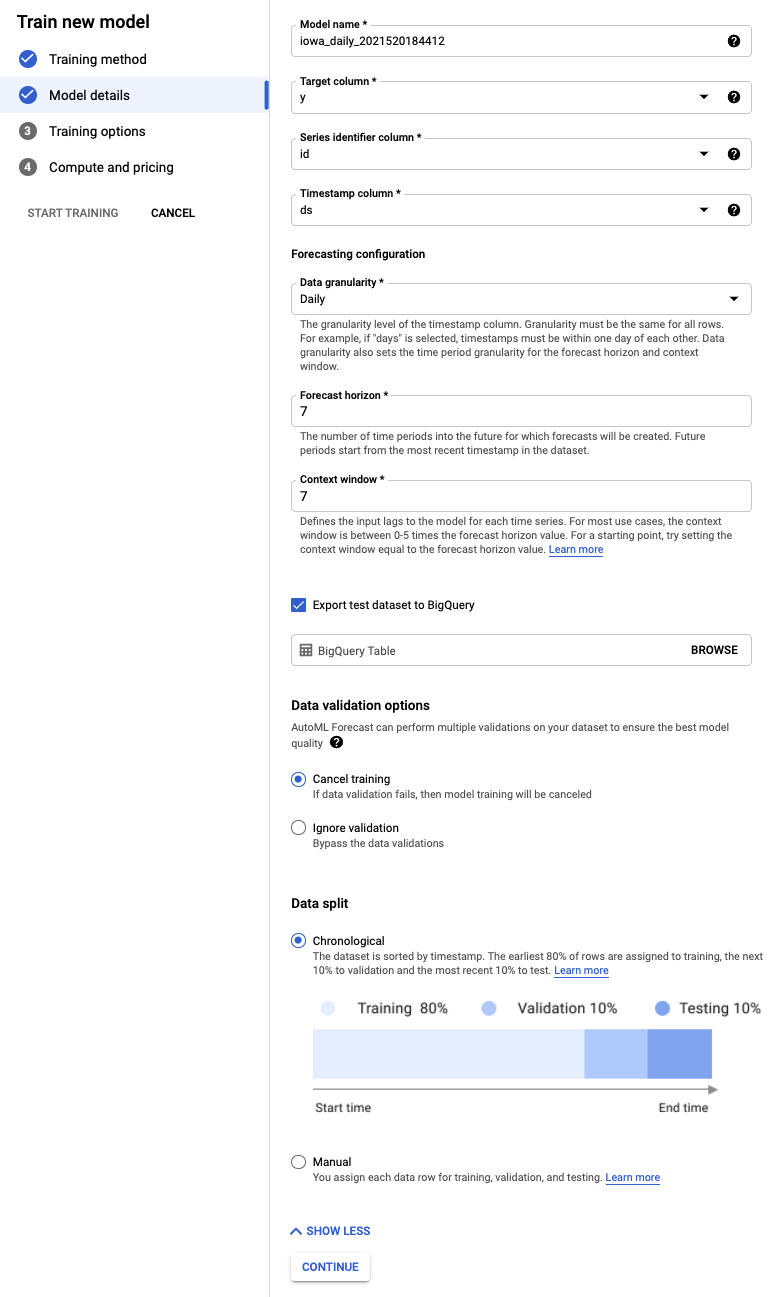
שלב 4: הגדרת אפשרויות ההדרכה
בשלב הזה אפשר לציין פרטים נוספים לגבי אופן האימון של המודל.
- הגדירו את העמודה holiday כ-Available בתחזית, כי אנחנו יודעים אם תאריך מסוים הוא חג מראש.
- משנים את יעד האופטימיזציה להגדלת מספר המשתמשים הפעילים. המדד MAE, או שגיאה ממוצעת, עמיד יותר לערכים חריגים בהשוואה לשגיאה ממוצעת ריבועית. אנחנו עובדים עם נתוני רכישות יומיים שיכולים להשתנות באופן קיצוני, ולכן MAE הוא מדד מתאים לשימוש.
- לוחצים על המשך.
שלב 5: התחלת האימון
מגדירים תקציב לפי בחירה. במקרה הזה, שעת שימוש אחת בצומת מספיקה לאימון המודל. לאחר מכן, מתחילים את תהליך האימון.
שלב 6: הערכת המודל
תהליך ההדרכה עשוי להימשך שעה עד שעתיים (כולל זמן ההגדרה הנוסף). נשלח לכם אימייל כשהאימון יסתיים. כשהמודל יהיה מוכן, תוכלו לראות את רמת הדיוק שלו.
5. חיזוי
שלב 1: בדיקת התחזיות לגבי נתוני הבדיקה
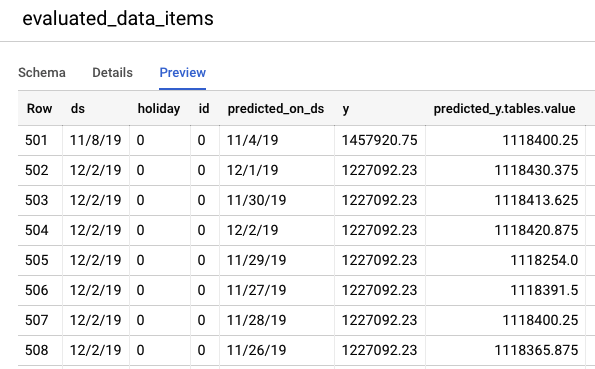
עוברים אל מסוף BigQuery כדי לראות את התחזיות לגבי נתוני הבדיקה. בתוך הפרויקט, נוצר באופן אוטומטי מערך נתונים חדש עם סכמת השמות: export_evaluated_data_items + <שם המודל> + <חותמת זמן>. בתוך מערך הנתונים הזה, נמצאת הטבלה evaluated_data_items שבה אפשר לבדוק את התחזיות.
בטבלה הזו יש כמה עמודות חדשות:
- predicted_on_[date column]: התאריך שבו בוצע החיזוי. לדוגמה, אם predicted_on_ds הוא 11/4 ו-ds הוא 11/8, אנחנו חוזים 4 ימים קדימה.
- predicted_[target column].tables.value: הערך החזוי
שלב 2: ביצוע חיזויים רבים בבת אחת
לבסוף, כדאי להשתמש במודל כדי ליצור תחזיות.
קובץ הקלט מכיל ערכים ריקים לתאריכים שרוצים לחזות, יחד עם נתונים היסטוריים:
ds | holiday | id | y |
15/5/20 | 0 | 0 | 1751315.43 |
16/05/20 | 0 | 0 | 0 |
17/05/20 | 0 | 0 | 0 |
18.05.20 | 0 | 0 | 1612066.43 |
19/05/20 | 0 | 0 | 1773885.17 |
20/05/20 | 0 | 0 | 1487270.92 |
21/5/20 | 0 | 0 | 1024051.76 |
22/05/20 | 0 | 0 | 1471736.31 |
23/05/20 | 0 | 0 | <empty> |
24/05/20 | 0 | 0 | <empty> |
25/05/20 | 1 | 0 | <empty> |
26/05/20 | 0 | 0 | <empty> |
27.05.2020 | 0 | 0 | <empty> |
28/05/20 | 0 | 0 | <empty> |
29/05/20 | 0 | 0 | <empty> |
אפשר ליצור תחזית חדשה של נתונים בכמות גדולה מהפריט תחזיות של נתונים בכמות גדולה בסרגל הניווט הימני של AI Platform (מאוחד).
קובץ קלט לדוגמה נוצר בשבילכם כאן בקטגוריית אחסון: automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv
אתם יכולים לספק את המיקום של קובץ המקור. אחרי זה תוכלו לייצא את התחזיות למיקום אחסון בענן כקובץ CSV, או ל-BigQuery. לצורך שיעור ה-Lab הזה, בוחרים באפשרות BigQuery ומזינים את מזהה הפרויקט ב-Google Cloud.
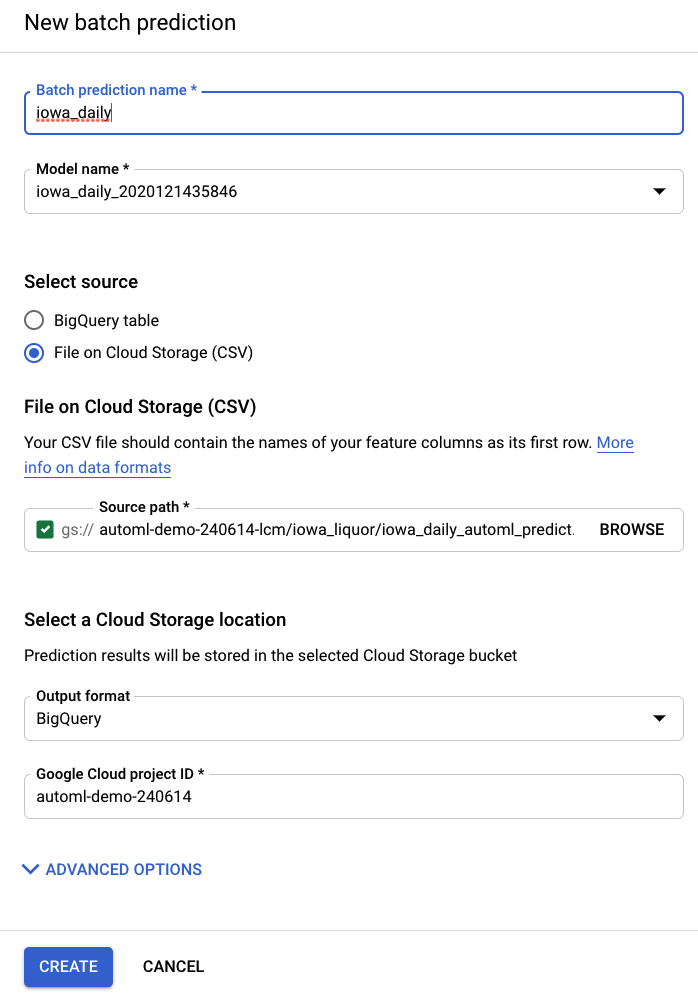
תהליך החיזוי של הקבוצה יימשך כמה דקות. אחרי שהעבודה מסתיימת, אפשר ללחוץ על עבודת החיזוי באצווה כדי לראות את הפרטים, כולל מיקום הייצוא. כדי לגשת לתחזיות ב-BigQuery, צריך לנווט אל הפרויקט, מערך הנתונים או הטבלה בסרגל הניווט השמאלי.
המשימה תיצור שתי טבלאות שונות ב-BigQuery. אחד מהם יכיל את כל השורות עם שגיאות, והשני יכיל את התחזיות. דוגמה לפלט מטבלת התחזיות:
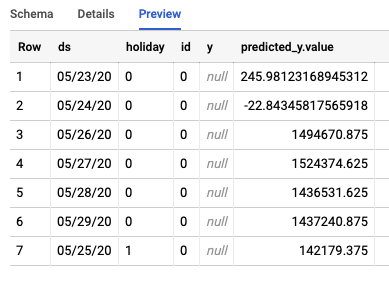
שלב 3: סיכום
כל הכבוד, הצלחתם לבנות ולאמן מודל חיזוי באמצעות AutoML. בשיעור ה-Lab הזה למדנו על ייבוא נתונים, בניית מודלים וביצוע חיזויים.
עכשיו אפשר ליצור מודל חיזוי משלכם.