
1. खास जानकारी
इस लैब में, आपको ये काम करने होंगे:
- मैनेज किया गया डेटासेट बनाना
- Google Cloud Storage बकेट से डेटा इंपोर्ट करना
- AutoML के साथ सही तरीके से इस्तेमाल करने के लिए, कॉलम का मेटाडेटा अपडेट करना
- बजट और ऑप्टिमाइज़ेशन के लक्ष्य जैसे विकल्पों का इस्तेमाल करके मॉडल को ट्रेन करना
- डेटा के बैच के लिए ऑनलाइन अनुमान लगाना
2. डेटा की समीक्षा करना
इस लैब में, BigQuery के सार्वजनिक डेटासेट से Iowa Liquor Sales dataset का डेटा इस्तेमाल किया जाता है. इस डेटासेट में, अमेरिका के आयोवा राज्य में साल 2012 से थोक में शराब की खरीदारी से जुड़ा डेटा शामिल है.
डेटासेट देखें को चुनकर, ओरिजनल रॉ डेटा देखा जा सकता है. टेबल को ऐक्सेस करने के लिए, बाईं ओर मौजूद नेविगेशन बार में bigquery-public-datasets प्रोजेक्ट पर जाएं. इसके बाद, iowa_liquor_sales डेटासेट और फिर sales टेबल पर जाएं. डेटासेट की कुछ लाइनें देखने के लिए, झलक को चुना जा सकता है.
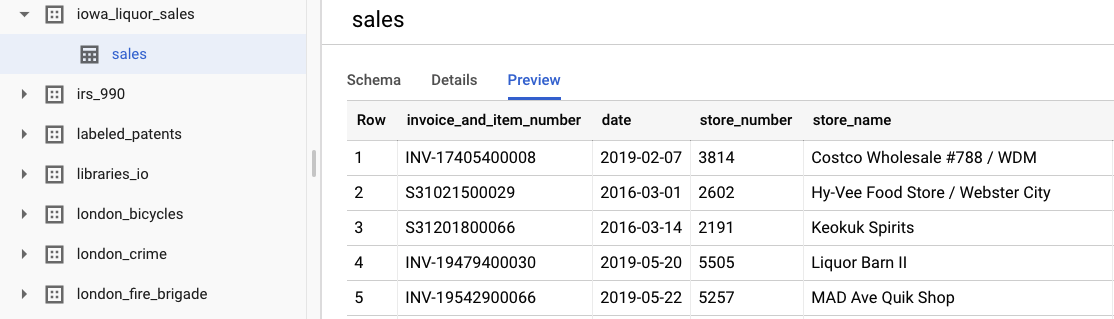
इस लैब के लिए, हमने पहले से ही कुछ बुनियादी डेटा प्री-प्रोसेसिंग की है, ताकि खरीदारी को दिन के हिसाब से ग्रुप किया जा सके. हम BigQuery टेबल से निकाले गए CSV फ़ाइल का इस्तेमाल करेंगे. CSV फ़ाइल में ये कॉलम होते हैं:
- ds: तारीख
- y: उस दिन की गई सभी खरीदारी का कुल योग, डॉलर में
- holiday: यह बूलियन वैल्यू है. इससे पता चलता है कि तारीख अमेरिका में छुट्टी की है या नहीं
- id: टाइम-सीरीज़ आइडेंटिफ़ायर.इसका इस्तेमाल एक से ज़्यादा टाइम-सीरीज़ को सपोर्ट करने के लिए किया जाता है. जैसे, स्टोर या प्रॉडक्ट के हिसाब से. इस मामले में, हम सिर्फ़ एक टाइम-सीरीज़ में कुल खरीदारी का पूर्वानुमान लगाने जा रहे हैं. इसलिए, हर लाइन के लिए आईडी को 0 पर सेट किया गया है.
3. इंपोर्ट डेटा
पहला चरण: Vertex AI Datasets पर जाएं
Cloud Console की बाईं ओर मौजूद नेविगेशन बार में, Vertex AI मेन्यू में जाकर डेटासेट ऐक्सेस करें.
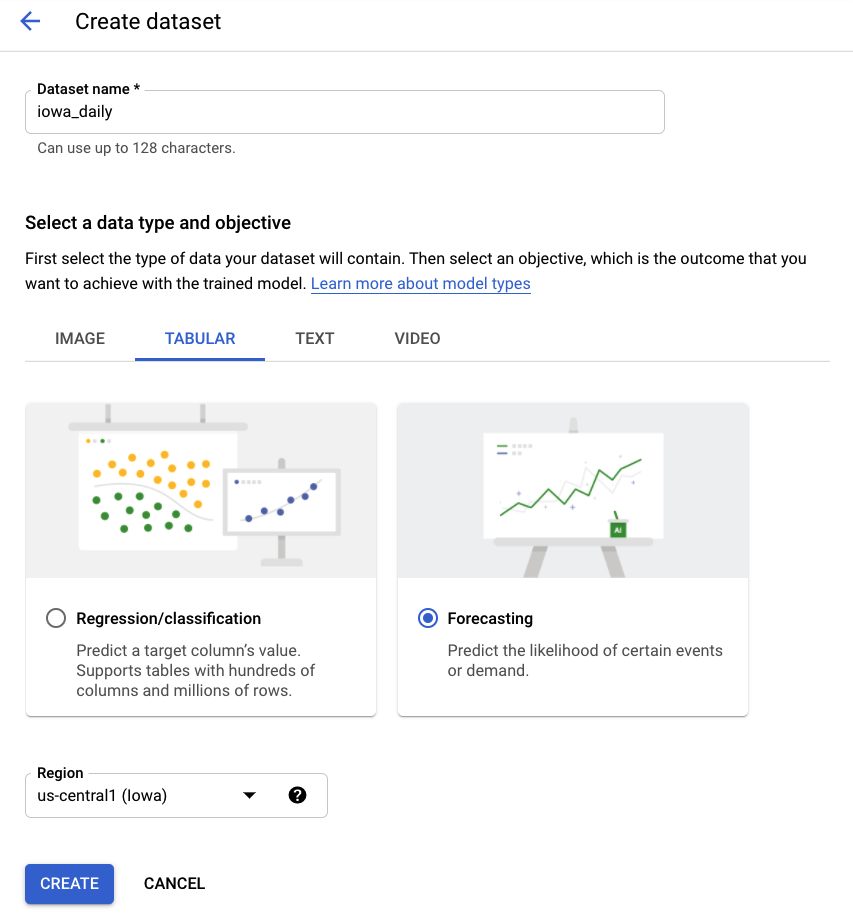
दूसरा चरण: डेटासेट बनाना
टेबल वाला डेटा और फिर पूर्वानुमान समस्या का टाइप चुनकर, एक नया डेटासेट बनाएं. iowa_daily नाम चुनें या अपनी पसंद का कोई दूसरा नाम चुनें.
तीसरा चरण: डेटा इंपोर्ट करना
अगला चरण, डेटासेट में डेटा इंपोर्ट करना है. Cloud Storage से CSV फ़ाइल चुनने का विकल्प चुनें. इसके बाद, AutoML Demo Alpha बकेट में मौजूद CSV फ़ाइल पर जाएं और automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv में चिपकाएं.
4. ट्रेन का मॉडल
पहला चरण: मॉडल की सुविधाएं कॉन्फ़िगर करना
कुछ मिनटों के बाद, AutoML आपको सूचना देगा कि डेटा इंपोर्ट हो गया है. इसके बाद, मॉडल की सुविधाओं को कॉन्फ़िगर किया जा सकता है.
- टाइम सीरीज़ आइडेंटिफ़ायर कॉलम को id के तौर पर चुनें. हमारे डेटासेट में सिर्फ़ एक टाइम-सीरीज़ है. इसलिए, यह एक फ़ॉर्मेलिटी है.
- समय का कॉलम चुनें, जिसे ds करना है.
इसके बाद, आंकड़े जनरेट करें को चुनें. प्रोसेस पूरी होने के बाद, आपको मौजूद न होने का प्रतिशत और अलग-अलग वैल्यू के आंकड़े दिखेंगे. इस प्रोसेस में कुछ मिनट लग सकते हैं. इसलिए, अगर आपको अगले चरण पर जाना है, तो आगे बढ़ें.
दूसरा चरण: मॉडल को ट्रेन करना
ट्रेनिंग की प्रोसेस शुरू करने के लिए, मॉडल को ट्रेन करें चुनें. पक्का करें कि AutoML चुना गया हो. इसके बाद, जारी रखें पर क्लिक करें.
तीसरा चरण: मॉडल तय करना
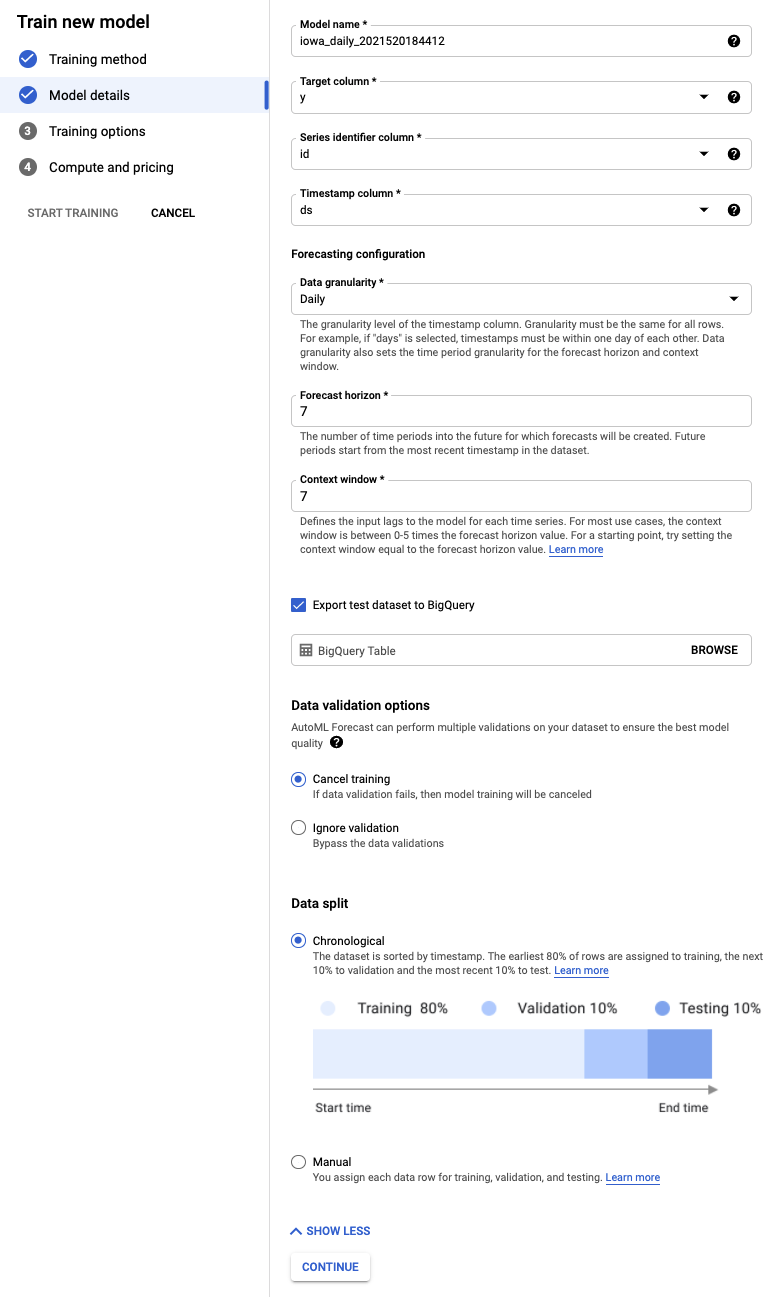
- टारगेट कॉलम को y के तौर पर चुनें. यह वह वैल्यू है जिसका हम अनुमान लगा रहे हैं.
- अगर आपने पहले से सेट नहीं किया है, तो सीरीज़ आइडेंटिफ़ायर कॉलम को id और टाइमस्टैंप कॉलम को ds पर सेट करें.
- डेटा की जानकारी का लेवल को दिन और अनुमान की अवधि को 7 पर सेट करें. इस फ़ील्ड से पता चलता है कि मॉडल, आने वाले समय के लिए कितनी अवधियों का अनुमान लगा सकता है.
- कॉन्टेक्स्ट विंडो को सात दिन पर सेट करें. यह मॉडल, अनुमान लगाने के लिए पिछले 30 दिनों के डेटा का इस्तेमाल करेगा. छोटी और लंबी अवधि के बीच कुछ समझौते करने पड़ते हैं. आम तौर पर, अनुमानित अवधि के 1 से 10 गुना के बीच की वैल्यू चुनने का सुझाव दिया जाता है.
- टेस्ट डेटासेट को BigQuery में एक्सपोर्ट करें बॉक्स पर सही का निशान लगाएं. इसे खाली छोड़ा जा सकता है. ऐसा करने पर, आपके प्रोजेक्ट में डेटासेट और टेबल अपने-आप बन जाएगी. इसके अलावा, अपनी पसंद की कोई जगह भी तय की जा सकती है.
- जारी रखें चुनें.
चौथा चरण: ट्रेनिंग के विकल्प सेट करना
इस चरण में, मॉडल को ट्रेन करने के तरीके के बारे में ज़्यादा जानकारी दी जा सकती है.
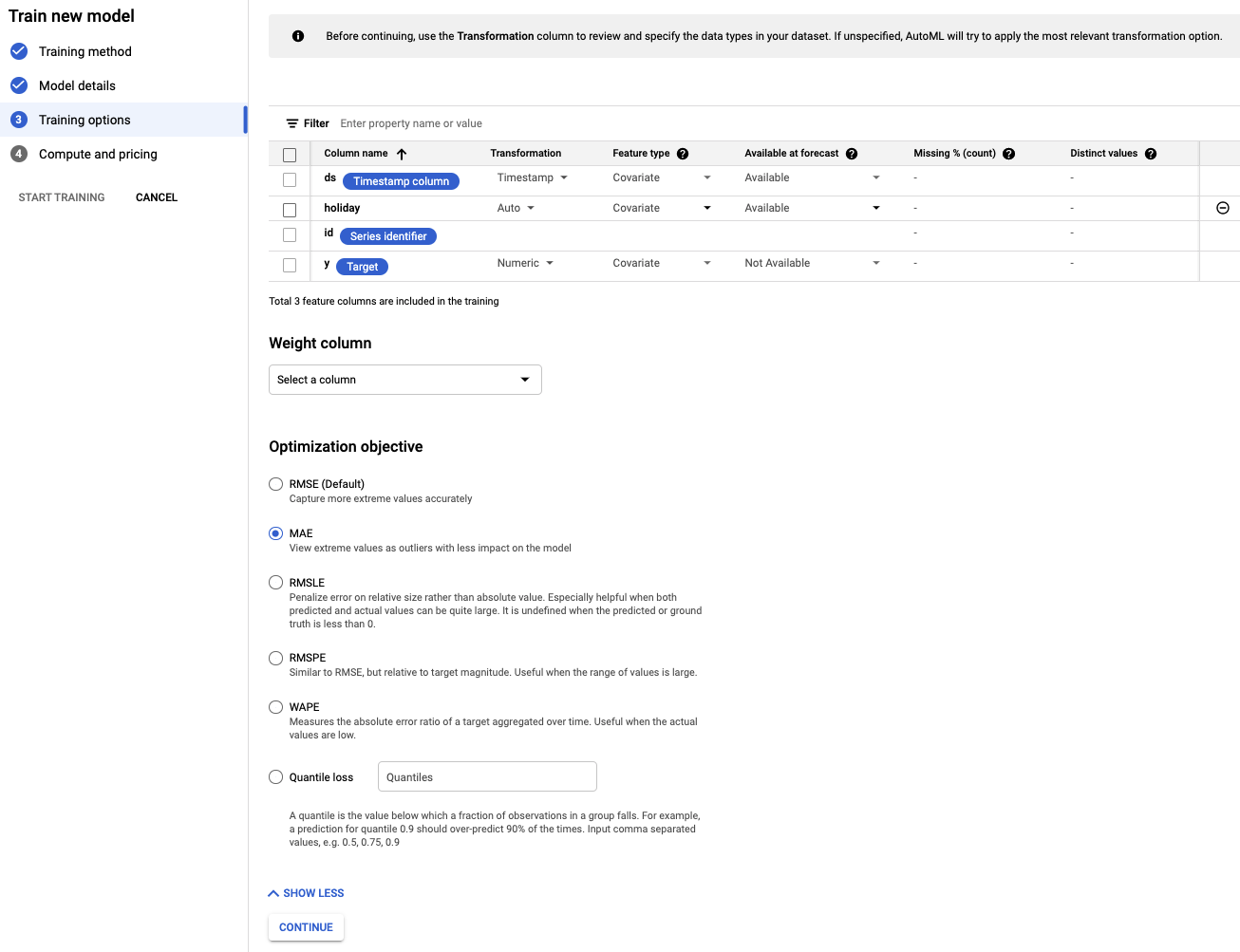
- पूर्वानुमान के लिए, छुट्टी कॉलम को उपलब्ध है के तौर पर सेट करें. ऐसा इसलिए, क्योंकि हमें पहले से पता होता है कि दी गई तारीख छुट्टी है या नहीं.
- ऑप्टिमाइज़ेशन के लक्ष्य को बदलकर MAE करें. MAE या औसत गड़बड़ी, वर्ग में गड़बड़ी के माध्य की तुलना में आउटलायर के लिए ज़्यादा बेहतर है. हम रोज़ाना के खरीदारी डेटा के साथ काम कर रहे हैं, जिसमें काफ़ी उतार-चढ़ाव हो सकता है. इसलिए, MAE का इस्तेमाल करना एक सही मेट्रिक है.
- जारी रखें चुनें.
पांचवां चरण: ट्रेनिंग शुरू करना
अपनी पसंद के मुताबिक बजट सेट करें. इस मामले में, मॉडल को ट्रेन करने के लिए एक नोड घंटा काफ़ी है. इसके बाद, ट्रेनिंग की प्रोसेस शुरू करें.
छठा चरण: मॉडल का आकलन करना
ट्रेनिंग की प्रोसेस को पूरा होने में एक से दो घंटे लग सकते हैं. इसमें सेटअप करने में लगने वाला समय भी शामिल है. ट्रेनिंग पूरी होने पर, आपको एक ईमेल मिलेगा. तैयार होने के बाद, बनाए गए मॉडल की सटीकता देखी जा सकती है.
5. अनुमान लगाना
पहला चरण: टेस्ट डेटा पर अनुमानों की समीक्षा करना
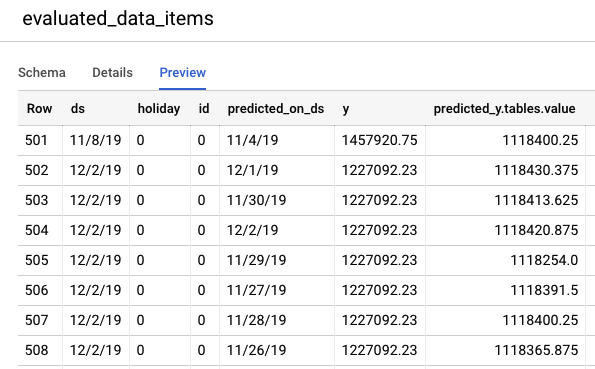
टेस्ट डेटा पर अनुमान देखने के लिए, BigQuery कंसोल पर जाएं. आपके प्रोजेक्ट में, export_evaluated_data_items + <मॉडल का नाम> + <टाइमस्टैंप> नाम के फ़ॉर्मैट वाला एक नया डेटासेट अपने-आप बन जाता है. इस डेटासेट में, आपको evaluated_data_items टेबल दिखेगी. इसमें जाकर, अनुमानों की समीक्षा की जा सकती है.
इस टेबल में कुछ नए कॉलम हैं:
- predicted_on_[date column]: वह तारीख जब अनुमान लगाया गया था. उदाहरण के लिए, अगर predicted_on_ds 4 नवंबर है और ds 8 नवंबर है, तो हम चार दिन पहले का अनुमान लगा रहे हैं.
- predicted_[target column].tables.value: अनुमानित वैल्यू
दूसरा चरण: बैच में अनुमानित नतीजे पाना
आखिर में, आपको अनुमान लगाने के लिए अपने मॉडल का इस्तेमाल करना होगा.
इनपुट फ़ाइल में, अनुमानित तारीखों के लिए खाली वैल्यू के साथ-साथ पुराना डेटा भी शामिल है:
ds | holiday | id | y |
15/5/20 | 0 | 0 | 1751315.43 |
16/5/20 | 0 | 0 | 0 |
17/5/20 | 0 | 0 | 0 |
18/5/20 | 0 | 0 | 1612066.43 |
19/5/20 | 0 | 0 | 1773885.17 |
20/5/20 | 0 | 0 | 1487270.92 |
21/5/20 | 0 | 0 | 1024051.76 |
22/5/20 | 0 | 0 | 1471736.31 |
23/5/20 | 0 | 0 | <empty> |
24/5/20 | 0 | 0 | <empty> |
25/5/20 | 1 | 0 | <empty> |
26/5/20 | 0 | 0 | <empty> |
27/5/20 | 0 | 0 | <empty> |
28/5/20 | 0 | 0 | <empty> |
29/5/20 | 0 | 0 | <empty> |
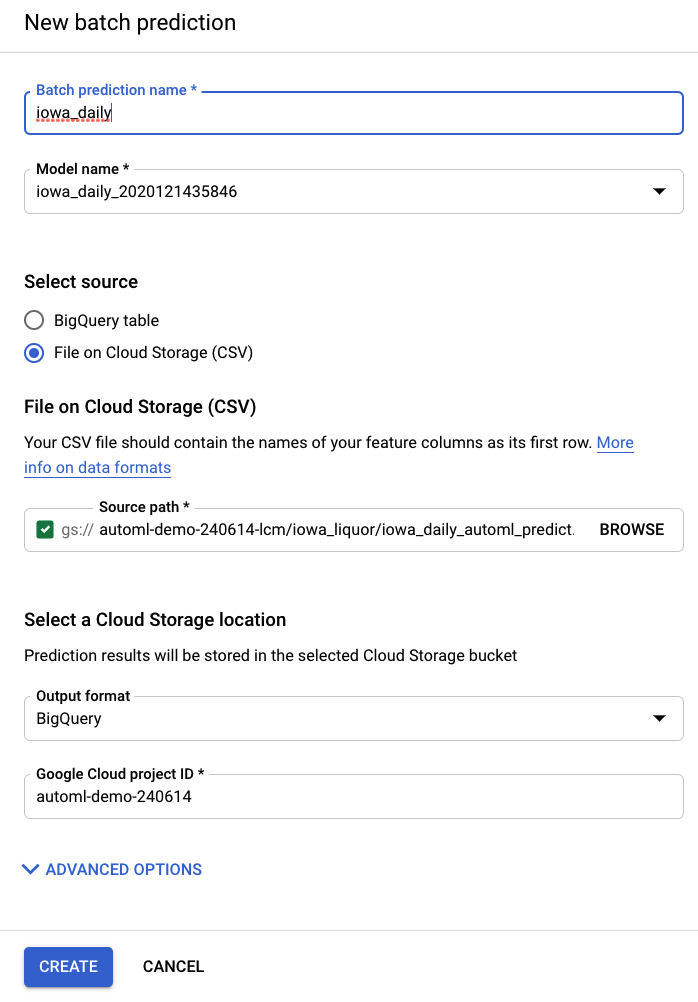
AI Platform (Unified) के बाईं ओर मौजूद नेविगेशन बार में, बैच के हिसाब से अनुमान आइटम से, बैच के हिसाब से नया अनुमान बनाया जा सकता है.
यहां स्टोरेज बकेट में, आपके लिए इनपुट फ़ाइल का एक उदाहरण बनाया गया है: automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv
आपके पास सोर्स फ़ाइल की लोकेशन देने का विकल्प है. इसके बाद, आपके पास अनुमानों को CSV फ़ाइल के तौर पर क्लाउड स्टोरेज की किसी जगह पर एक्सपोर्ट करने या BigQuery पर एक्सपोर्ट करने का विकल्प होता है. इस लैब के लिए, BigQuery को चुनें. इसके बाद, अपने Google Cloud प्रोजेक्ट का आईडी चुनें.
बैच के तौर पर अनुमान लगाने की प्रोसेस पूरी होने में कुछ मिनट लगेंगे. प्रोसेस पूरी होने के बाद, बैच प्रेडिक्शन जॉब पर क्लिक करके, एक्सपोर्ट की जगह की जानकारी देखी जा सकती है. अनुमानों को ऐक्सेस करने के लिए, आपको BigQuery में बाईं ओर मौजूद नेविगेशन बार में जाकर, प्रोजेक्ट / डेटासेट / टेबल पर जाना होगा.
इस जॉब से, BigQuery में दो अलग-अलग टेबल बनेंगी. एक में गड़बड़ी वाली सभी लाइनें होंगी और दूसरे में अनुमान होंगे. यहां अनुमानों की टेबल से मिले आउटपुट का एक उदाहरण दिया गया है:
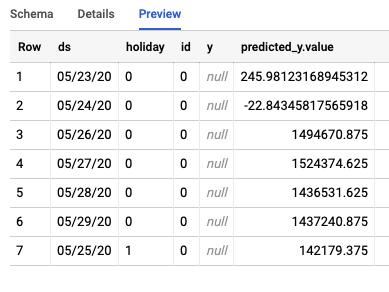
तीसरा चरण: निष्कर्ष
बधाई हो, आपने AutoML की मदद से अनुमान लगाने वाला मॉडल बना लिया है और उसे ट्रेन कर लिया है. इस लैब में, हमने डेटा इंपोर्ट करने, मॉडल बनाने, और अनुमान लगाने के बारे में बताया है.
अब आप अनुमान लगाने वाला अपना मॉडल बनाने के लिए तैयार हैं!