
1. Panoramica
In questo lab imparerai a:
- Crea un set di dati gestito
- Importa dati da un bucket Google Cloud Storage
- Aggiorna i metadati delle colonne per un utilizzo appropriato con AutoML
- Addestrare un modello utilizzando opzioni come un budget e un obiettivo di ottimizzazione
- Genera previsioni batch online
2. Esamina i dati
Questo lab utilizza i dati del set di dati sulle vendite di alcolici in Iowa dei set di dati pubblici di BigQuery. Questo set di dati è costituito da acquisti all'ingrosso di alcolici nello stato americano dell'Iowa dal 2012.
Puoi esaminare i dati non elaborati originali selezionando Visualizza set di dati. Per accedere alla tabella, vai al progetto bigquery-public-datasets nella barra di navigazione a sinistra, poi al set di dati iowa_liquor_sales e infine alla tabella sales. Puoi selezionare Anteprima per visualizzare una selezione di righe del set di dati.
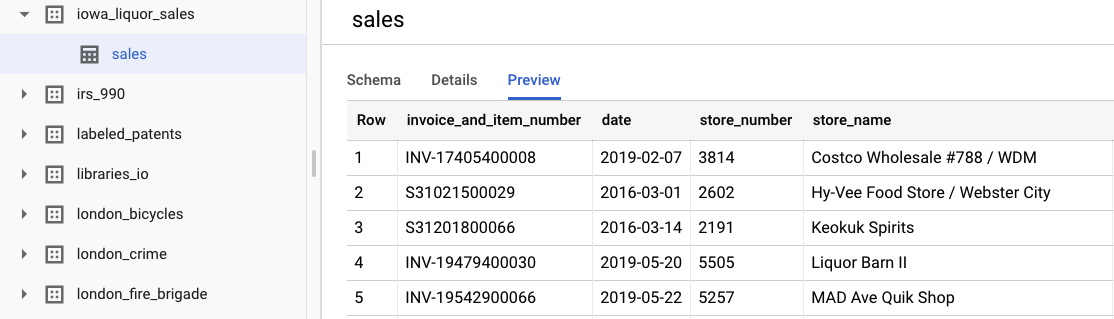
Ai fini di questo lab, abbiamo già eseguito una pre-elaborazione di base dei dati per raggruppare gli acquisti per giorno. Utilizzeremo un'estrazione CSV dalla tabella BigQuery. Le colonne nel file CSV sono:
- ds: la data
- y: la somma di tutti gli acquisti effettuati quel giorno in dollari
- holiday: un valore booleano che indica se la data è una festività statunitense
- id: un identificatore di serie temporale (per supportare più serie temporali, ad es. per negozio o per prodotto). In questo caso, prevederemo semplicemente gli acquisti complessivi in una serie temporale, quindi l'ID è impostato su 0 per ogni riga.
3. Importa dati
Passaggio 1: vai a Set di dati Vertex AI
Accedi a Set di dati nel menu Vertex AI dalla barra di navigazione a sinistra della console Google Cloud.
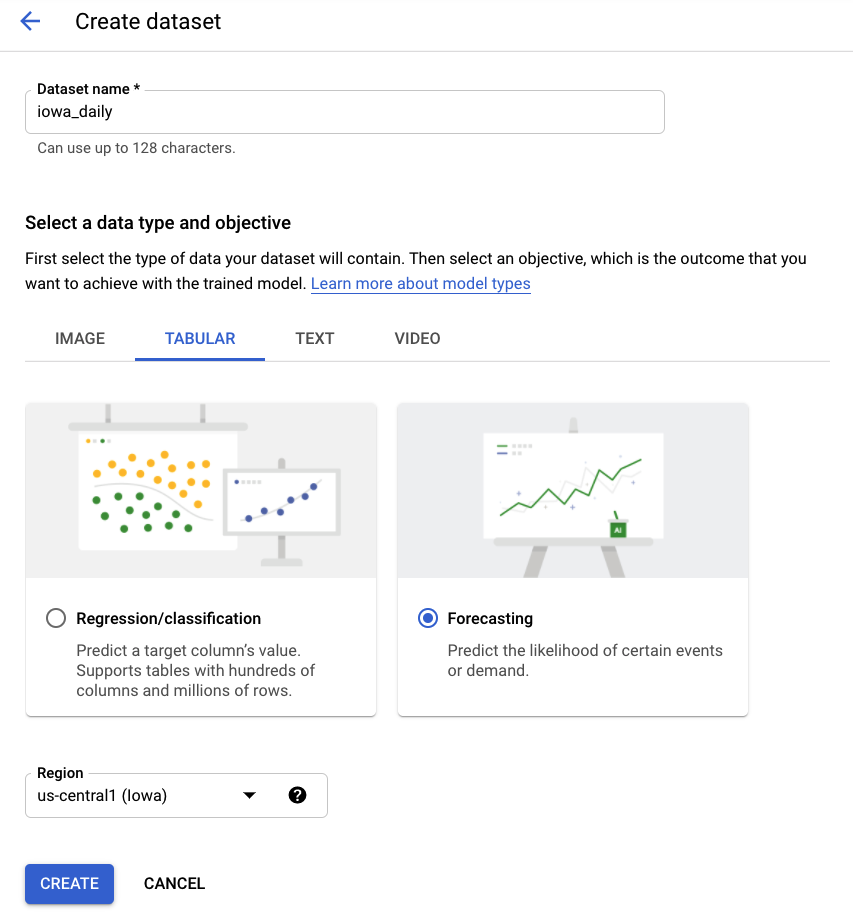
Passaggio 2: crea il set di dati
Crea un nuovo set di dati, selezionando Dati tabulari e poi il tipo di problema Previsione. Scegli il nome iowa_daily o un altro nome che preferisci.
Passaggio 3: importa i dati
Il passaggio successivo consiste nell'importare i dati nel set di dati. Scegli l'opzione Seleziona un file CSV da Cloud Storage. Poi, vai al file CSV nel bucket AutoML Demo Alpha e incolla automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv.
4. Addestra modello
Passaggio 1: configura le funzionalità del modello
Dopo alcuni minuti, AutoML ti avviserà che l'importazione è stata completata. A questo punto, puoi configurare le funzionalità del modello.
- Seleziona la colonna identificatore serie temporale da utilizzare come ID. Nel nostro set di dati è presente una sola serie temporale, quindi si tratta di una formalità.
- Seleziona la colonna Ora da ds.
Poi, seleziona Genera statistiche. Al termine della procedura, vedrai le statistiche %mancante e Valori distinti. L'operazione potrebbe richiedere alcuni minuti, quindi puoi procedere al passaggio successivo.
Passaggio 2: addestra il modello
Seleziona Addestra il modello per iniziare la procedura di addestramento. Assicurati che AutoML sia selezionato e fai clic su Continua.
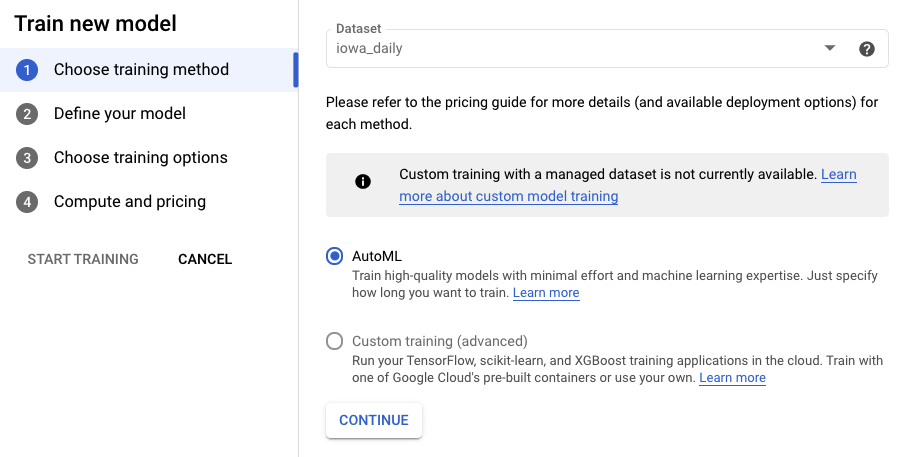
Passaggio 3: definisci il modello
- Seleziona la colonna target da impostare su y. Questo è il valore che stiamo prevedendo.
- Se non è già stata impostata in precedenza, imposta la colonna Identificatore serie su id e la colonna Timestamp su ds.
- Imposta la granularità dei dati su Giorni e l'orizzonte di previsione su 7. Questo campo specifica il numero di periodi che il modello può prevedere in futuro.
- Imposta la Finestra di contesto su 7 giorni. Il modello utilizzerà i dati dei 30 giorni precedenti per fare una previsione. Esistono compromessi tra finestre più brevi e più lunghe e in genere è consigliabile selezionare un valore compreso tra 1 e 10 volte l'orizzonte di previsione.
- Seleziona la casella per esportare il set di dati di test in BigQuery. Puoi lasciarlo vuoto e verrà creato automaticamente un set di dati e una tabella nel tuo progetto (o specificare una posizione a tua scelta).
- Seleziona Continua.
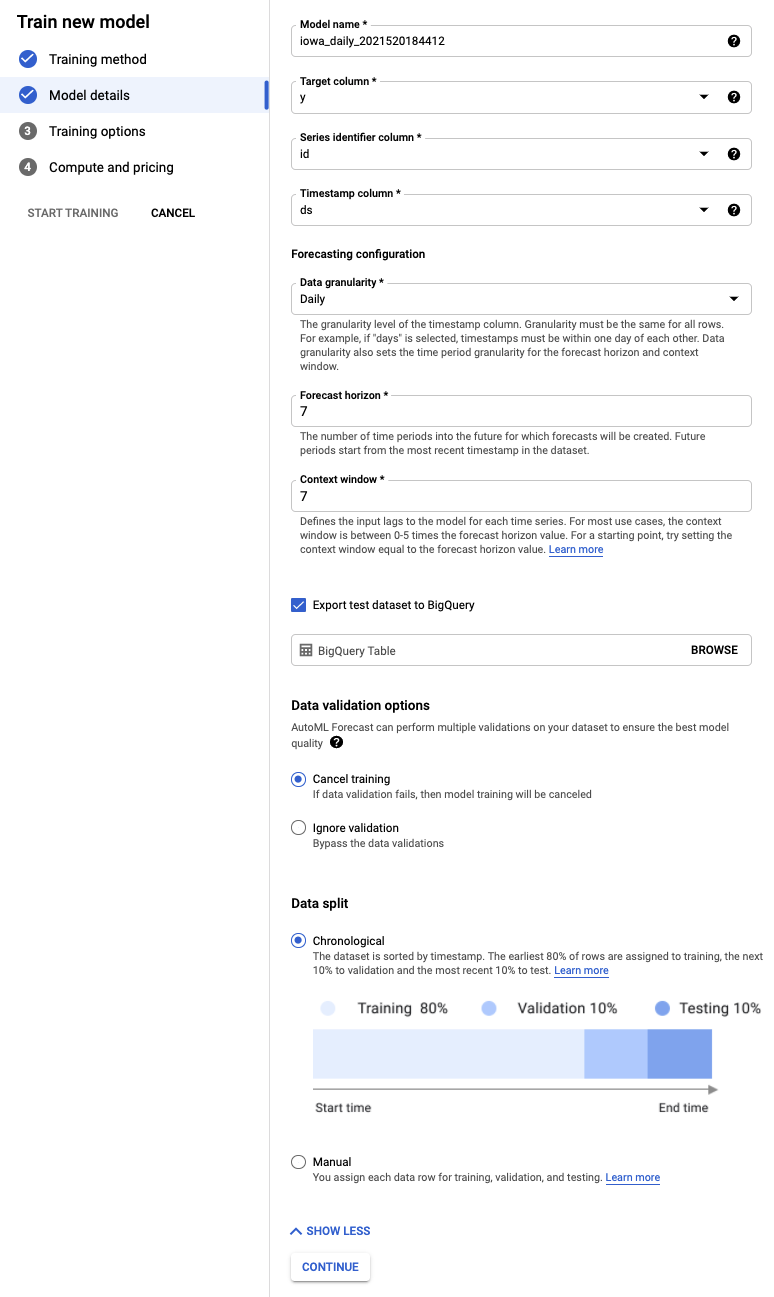
Passaggio 4: imposta le opzioni di addestramento
In questo passaggio, puoi specificare ulteriori dettagli su come addestrare il modello.
- Imposta la colonna festività su Disponibile nella previsione, perché sappiamo in anticipo se una determinata data è una festività.
- Modifica l'obiettivo di ottimizzazione in MAE. L'errore assoluto medio (MAE) è più resiliente agli outlier rispetto all'errore quadratico medio. Poiché utilizziamo dati di acquisto giornalieri che possono subire forti fluttuazioni, l'errore assoluto medio è una metrica appropriata da utilizzare.
- Seleziona Continua.
Passaggio 5: avvia l'addestramento
Imposta un budget a tua scelta. In questo caso, 1 ora nodo è sufficiente per addestrare il modello. Quindi, inizia la procedura di addestramento.
Passaggio 6: valuta il modello
Il completamento della procedura di addestramento può richiedere 1-2 ore (incluso l'eventuale tempo di configurazione aggiuntivo). Riceverai un'email al termine dell'addestramento. Quando è pronto, puoi visualizzare l'accuratezza del modello che hai creato.
5. Previsione
Passaggio 1: esamina le previsioni sui dati di test
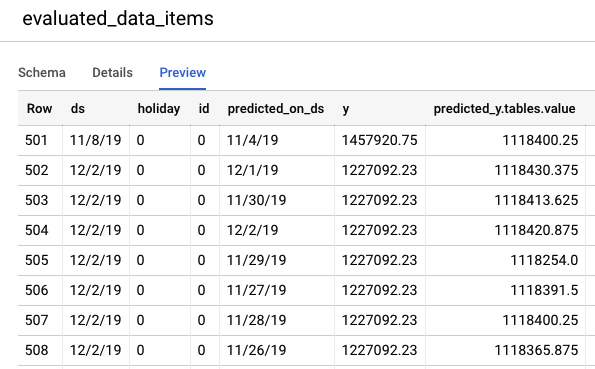
Vai alla console BigQuery per visualizzare le previsioni sui dati di test. All'interno del progetto, viene creato automaticamente un nuovo set di dati con lo schema di denominazione: export_evaluated_data_items + <nome modello> + <timestamp>. All'interno di questo set di dati, troverai la tabella evaluated_data_items per esaminare le previsioni.
Questa tabella ha un paio di nuove colonne:
- predicted_on_[date column]: la data in cui è stata effettuata la previsione. Ad esempio, se predicted_on_ds è 4/11 e ds è 8/11, la previsione è di 4 giorni.
- predicted_[target column].tables.value: il valore previsto
Passaggio 2: esegui le previsioni in batch
Infine, ti consigliamo di utilizzare il modello per fare previsioni.
Il file di input contiene valori vuoti per le date da prevedere, insieme ai dati storici:
ds | holiday | id | y |
15/05/20 | 0 | 0 | 1751315.43 |
16/05/20 | 0 | 0 | 0 |
17/05/20 | 0 | 0 | 0 |
18/05/20 | 0 | 0 | 1612066.43 |
19/05/2020 | 0 | 0 | 1773885.17 |
20/05/20 | 0 | 0 | 1487270.92 |
21/05/2020 | 0 | 0 | 1.024.051,76 |
22/05/20 | 0 | 0 | 1471736.31 |
23/05/20 | 0 | 0 | <empty> |
24/05/20 | 0 | 0 | <empty> |
25/05/20 | 1 | 0 | <empty> |
26/5/20 | 0 | 0 | <empty> |
27/05/20 | 0 | 0 | <empty> |
28/05/20 | 0 | 0 | <empty> |
29/05/20 | 0 | 0 | <empty> |
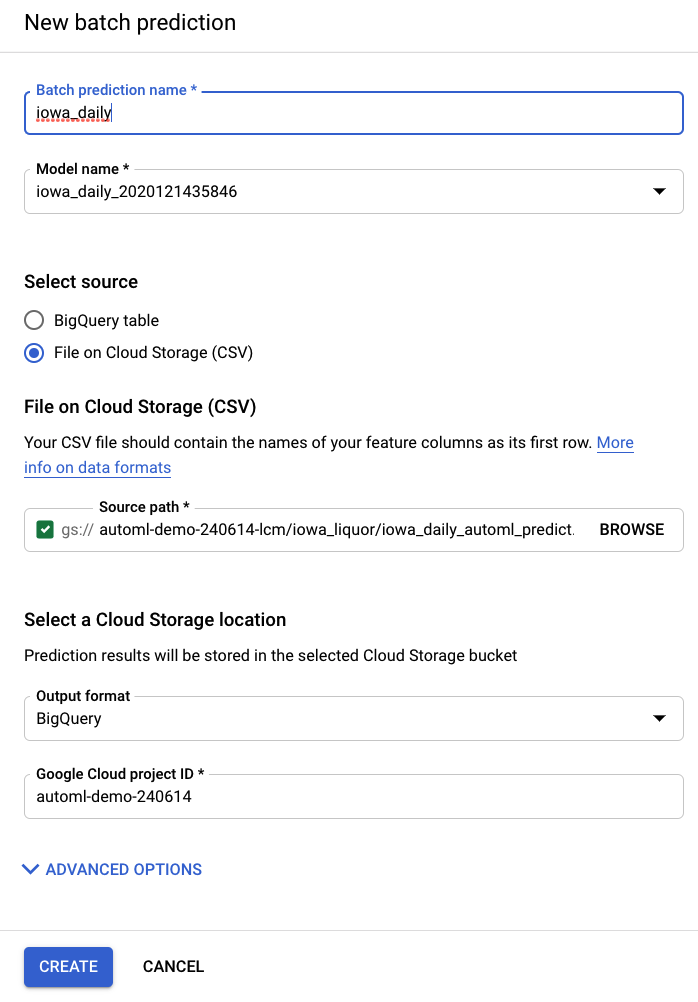
Puoi creare una nuova previsione batch dall'elemento Previsioni batch nella barra di navigazione a sinistra di AI Platform (Unified).
Qui viene creato un file di input di esempio in un bucket di archiviazione: automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv
Puoi fornire questa posizione del file di origine. Poi puoi scegliere di esportare le previsioni in una posizione di archiviazione cloud come file CSV o in BigQuery. Ai fini di questo lab, seleziona BigQuery e scegli l'ID progetto Google Cloud.
Il processo di previsione batch richiederà diversi minuti. Al termine, puoi fare clic sul job di previsione batch per visualizzare i dettagli, inclusa la posizione di esportazione. In BigQuery, devi andare al progetto, al set di dati o alla tabella nella barra di navigazione a sinistra per accedere alle previsioni.
Il job creerà due tabelle diverse in BigQuery. Uno conterrà le righe con errori, mentre l'altro conterrà le previsioni. Ecco un esempio dell'output della tabella Previsioni:
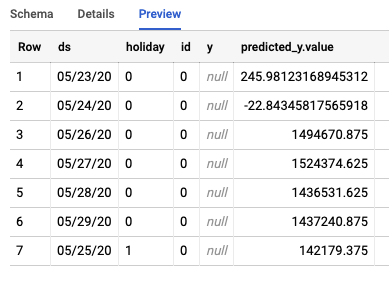
Passaggio 3: conclusione
Congratulazioni, hai creato e addestrato correttamente un modello di previsione con AutoML. In questo lab abbiamo trattato l'importazione dei dati, la creazione del modello e la generazione di previsioni.
Ora puoi creare il tuo modello di previsione.