
1. Przegląd
W tym module wykonasz następujące zadania:
- Tworzenie zarządzanego zbioru danych
- Importowanie danych z zasobnika Google Cloud Storage
- Aktualizowanie metadanych kolumny w celu odpowiedniego użycia w AutoML
- Trenowanie modelu przy użyciu opcji takich jak budżet i cel optymalizacji
- Przeprowadzanie prognoz zbiorczych online
2. Sprawdzanie danych
W tym module używane są dane ze zbioru danych Iowa Liquor Sales z publicznych zbiorów danych BigQuery. Ten zbiór danych zawiera informacje o zakupach hurtowych alkoholu w amerykańskim stanie Iowa od 2012 roku.
Aby wyświetlić oryginalne nieprzetworzone dane, kliknij Wyświetl zbiór danych. Aby uzyskać dostęp do tabeli, na pasku nawigacyjnym po lewej stronie kliknij kolejno projekt bigquery-public-datasets, zbiór danych iowa_liquor_sales i tabelę sales. Możesz kliknąć Podgląd, aby zobaczyć wybrane wiersze ze zbioru danych.
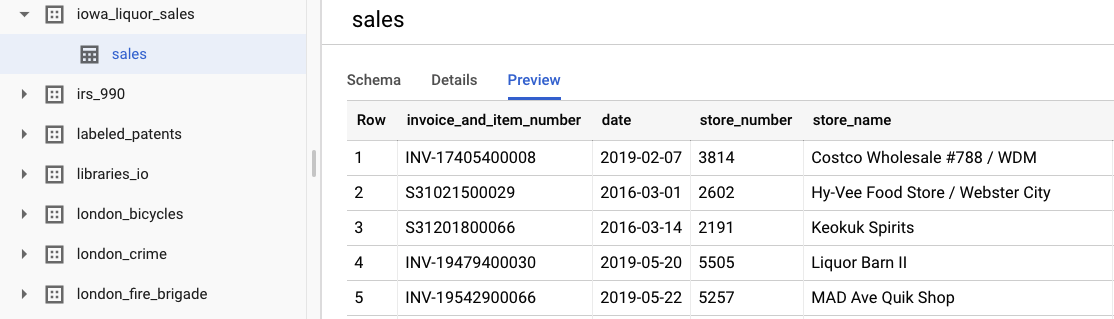
Na potrzeby tego laboratorium przeprowadziliśmy już wstępne przetwarzanie danych, aby pogrupować zakupy według dnia. Użyjemy wyodrębnionego z tabeli BigQuery pliku CSV. Kolumny w pliku CSV to:
- ds: data.
- y: suma wszystkich zakupów w danym dniu w dolarach.
- holiday: wartość logiczna określająca, czy data przypada w święto w Stanach Zjednoczonych.
- id: identyfikator ciągu czasowego (do obsługi wielu ciągów czasowych, np. według sklepu lub produktu). W tym przypadku będziemy prognozować ogólną liczbę zakupów w jednym szeregu czasowym, więc w każdym wierszu identyfikator będzie ustawiony na 0.
3. Importuj dane
Krok 1. Otwórz zbiory danych Vertex AI
Otwórz Zbiory danych w menu Vertex AI na pasku nawigacyjnym po lewej stronie konsoli Cloud.

Krok 2. Utwórz zbiór danych
Utwórz nowy zbiór danych, wybierając Dane tabelaryczne, a następnie typ problemu Prognozowanie. Wybierz nazwę iowa_daily lub inną, która Ci odpowiada.
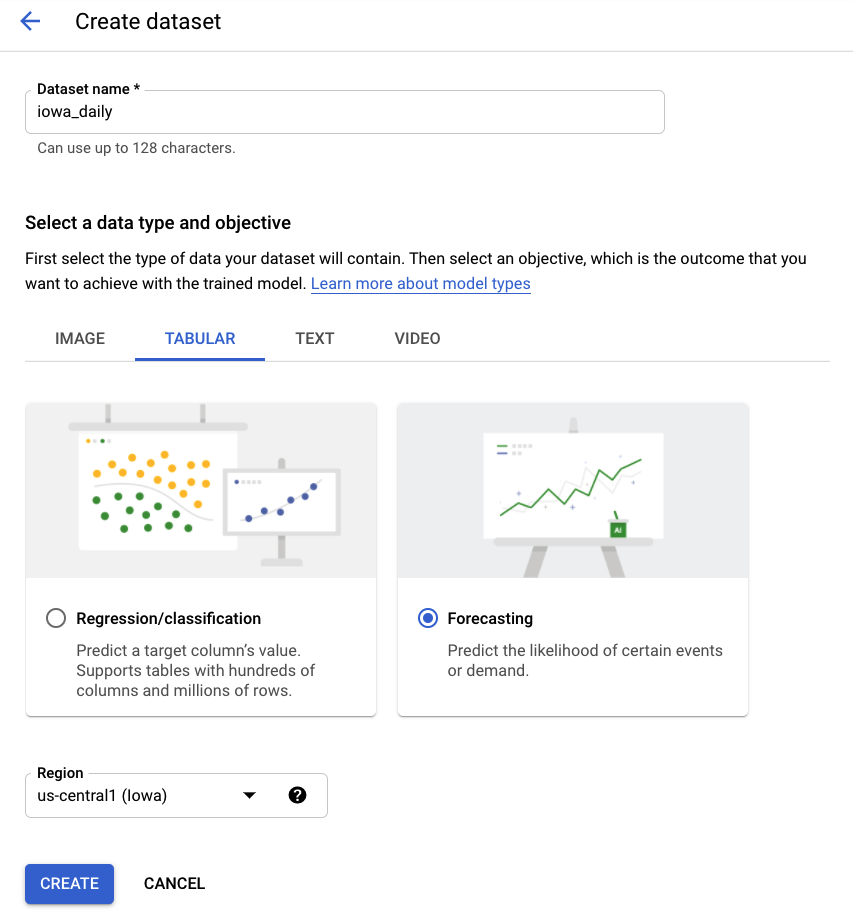
Krok 3. Zaimportuj dane
Następnym krokiem jest zaimportowanie danych do zbioru danych. Wybierz opcję Wybierz plik CSV z Cloud Storage. Następnie przejdź do pliku CSV w zasobniku AutoML Demo Alpha i wklej automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv.
4. Trenuj model
Krok 1. Skonfiguruj funkcje modelu
Po kilku minutach AutoML powiadomi Cię o zakończeniu importowania. W tym momencie możesz skonfigurować funkcje modelu.
- Wybierz kolumnę identyfikatora ciągu czasowego, która ma być identyfikatorem. W naszym zbiorze danych mamy tylko 1 szereg czasowy, więc jest to tylko formalność.
- Wybierz kolumnę czasu, która ma być ds.
Następnie wybierz Generate Statistics (Wygeneruj statystyki). Po zakończeniu procesu zobaczysz statystyki Brakujące % i Unikalne wartości. Ten proces może potrwać kilka minut, więc możesz przejść do następnego kroku.
Krok 2. Wytrenuj model
Aby rozpocząć proces trenowania, kliknij Trenuj model. Sprawdź, czy wybrana jest opcja AutoML, i kliknij Dalej.
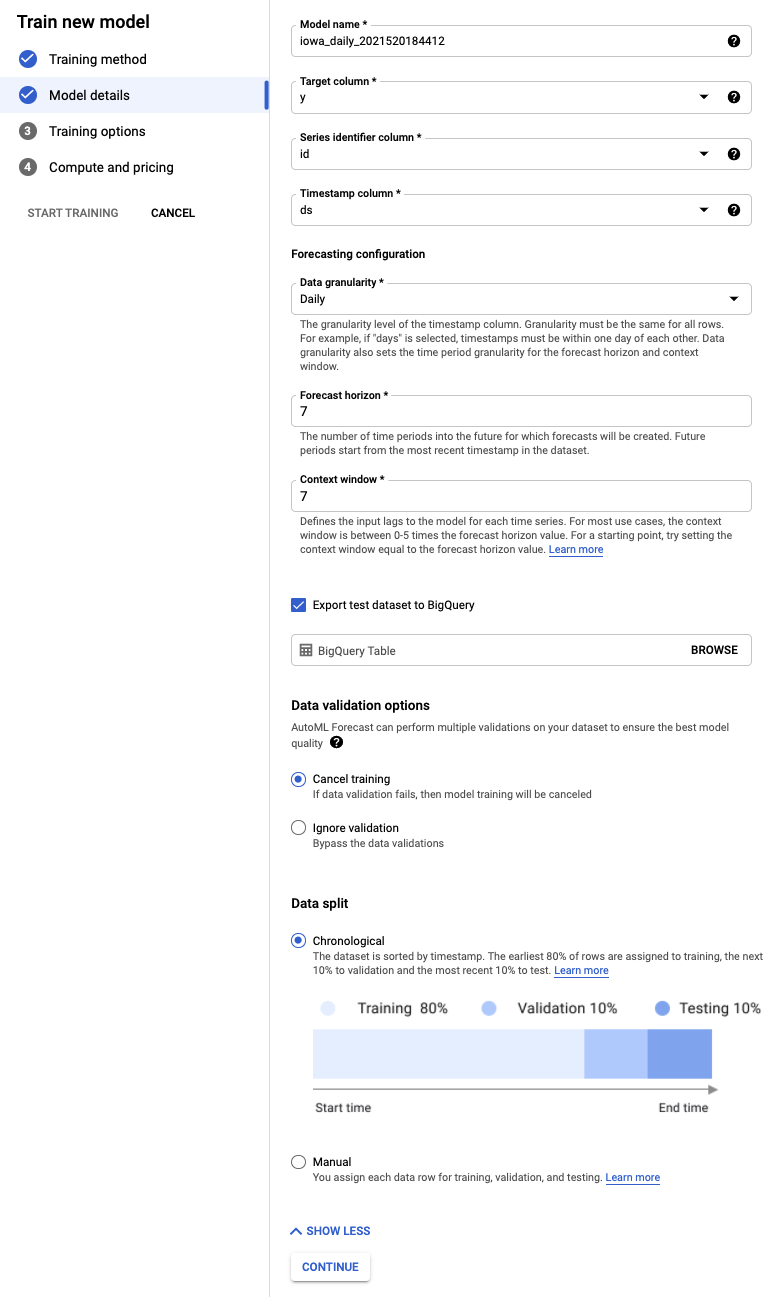
Krok 3. Zdefiniuj model
- Wybierz Kolumnę docelową, która ma mieć wartość y. To jest wartość, którą prognozujemy.
- Jeśli nie zostało to wcześniej ustawione, w kolumnie Identyfikator ciągu ustaw wartość id, a w kolumnie Sygnatura czasowa – ds.
- Ustaw Szczegółowość danych na Dni, a Horyzont prognozy na 7. To pole określa liczbę okresów, na które model może prognozować w przyszłości.
- Ustaw Okno kontekstu na 7 dni. Model będzie używać danych z ostatnich 30 dni do tworzenia prognoz. Krótsze i dłuższe okna mają swoje zalety i wady. Zwykle zaleca się wybieranie wartości od 1 do 10 razy większej od horyzontu prognozy.
- Zaznacz pole Wyeksportuj testowy zbiór danych do BigQuery. Możesz pozostawić to pole puste. W Twoim projekcie automatycznie utworzymy zbiór danych i tabelę (lub możesz określić wybraną lokalizację).
- Kliknij Dalej.
Krok 4. Ustaw opcje trenowania
Na tym etapie możesz podać więcej szczegółów o tym, jak chcesz wytrenować model.
- Ustaw kolumnę holiday na Dostępna w momencie prognozy, ponieważ wiemy, czy dana data jest świętem z wyprzedzeniem.
- Zmień cel optymalizacji na MAE. MAE, czyli średni błąd bezwzględny, jest bardziej odporny na wartości odstające niż błąd średniokwadratowy. Ponieważ pracujemy z danymi o codziennych zakupach, które mogą podlegać dużym wahaniom, MAE jest odpowiednią miarą do zastosowania.
- Kliknij Dalej.
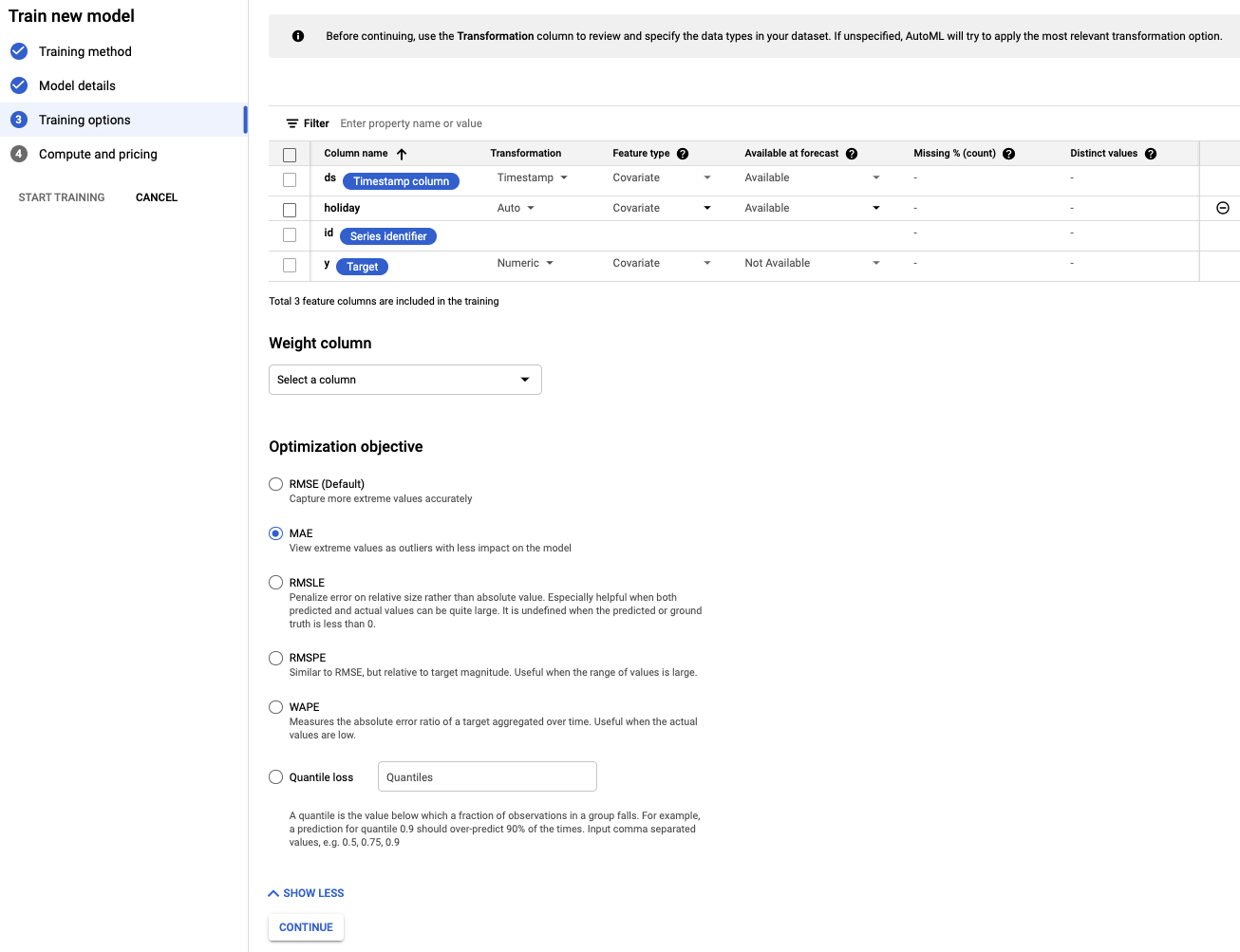
Krok 5. Rozpocznij trenowanie
Określ wybrany budżet. W tym przypadku do wytrenowania modelu wystarczy 1 godzina otwarcia węzła. Następnie rozpocznij proces trenowania.
Krok 6. Ocena modelu
Proces trenowania może potrwać 1–2 godziny (wliczając dodatkowy czas konfiguracji). Gdy się zakończy, otrzymasz e-maila. Gdy będzie gotowy, możesz sprawdzić dokładność utworzonego modelu.
5. Wykonaj prognozę
Krok 1. Sprawdź prognozy na podstawie danych testowych
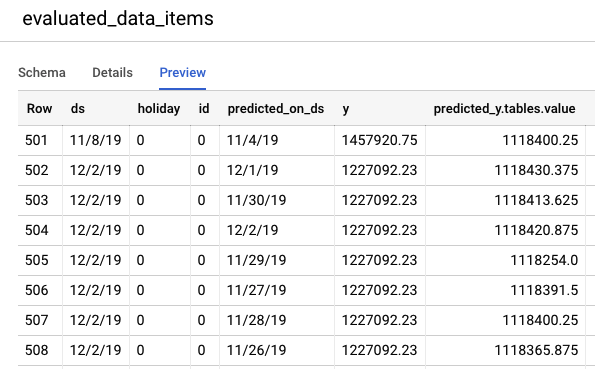
Otwórz konsolę BigQuery, aby wyświetlić prognozy dotyczące danych testowych. W projekcie automatycznie utworzy się nowy zbiór danych o nazwie: export_evaluated_data_items + <nazwa modelu> + <sygnatura czasowa>. W tym zbiorze danych znajdziesz tabelę evaluated_data_items, w której możesz sprawdzić prognozy.
Ta tabela ma kilka nowych kolumn:
- predicted_on_[date column]: data utworzenia prognozy. Jeśli np. predicted_on_ds to 4 listopada, a ds to 8 listopada, prognoza dotyczy 4 dni naprzód.
- predicted_[target column].tables.value: przewidywana wartość
Krok 2. Przeprowadź prognozy zbiorcze
Na koniec użyj modelu do tworzenia prognoz.
Plik wejściowy zawiera puste wartości dat, dla których mają być prognozowane dane, oraz dane historyczne:
ds | holiday | id | y |
15.05.2020 | 0 | 0 | 1751315.43 |
16.05.2020 | 0 | 0 | 0 |
17.05.2020 | 0 | 0 | 0 |
18.05.2020 | 0 | 0 | 1612066.43 |
19.05.2020 | 0 | 0 | 1773885,17 |
20.05.2020 | 0 | 0 | 1487270.92 |
21.05.2020 | 0 | 0 | 1024051.76 |
22.05.2020 | 0 | 0 | 1471736,31 |
23.05.2020 | 0 | 0 | <empty> |
24.05.2020 | 0 | 0 | <empty> |
25.05.2020 | 1 | 0 | <empty> |
26.05.2020 | 0 | 0 | <empty> |
27.05.2020 | 0 | 0 | <empty> |
28.05.2020 | 0 | 0 | <empty> |
29.05.2020 | 0 | 0 | <empty> |
Nową prognozę zbiorczą możesz utworzyć, klikając Prognozy zbiorcze na pasku nawigacyjnym po lewej stronie AI Platform (ujednoliconej).
Przykładowy plik wejściowy został utworzony w tym zasobniku pamięci: automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv
Możesz podać lokalizację tego pliku źródłowego. Następnie możesz wyeksportować prognozy do lokalizacji w Cloud Storage jako plik CSV lub do BigQuery. Na potrzeby tego modułu wybierz BigQuery i identyfikator projektu Google Cloud.
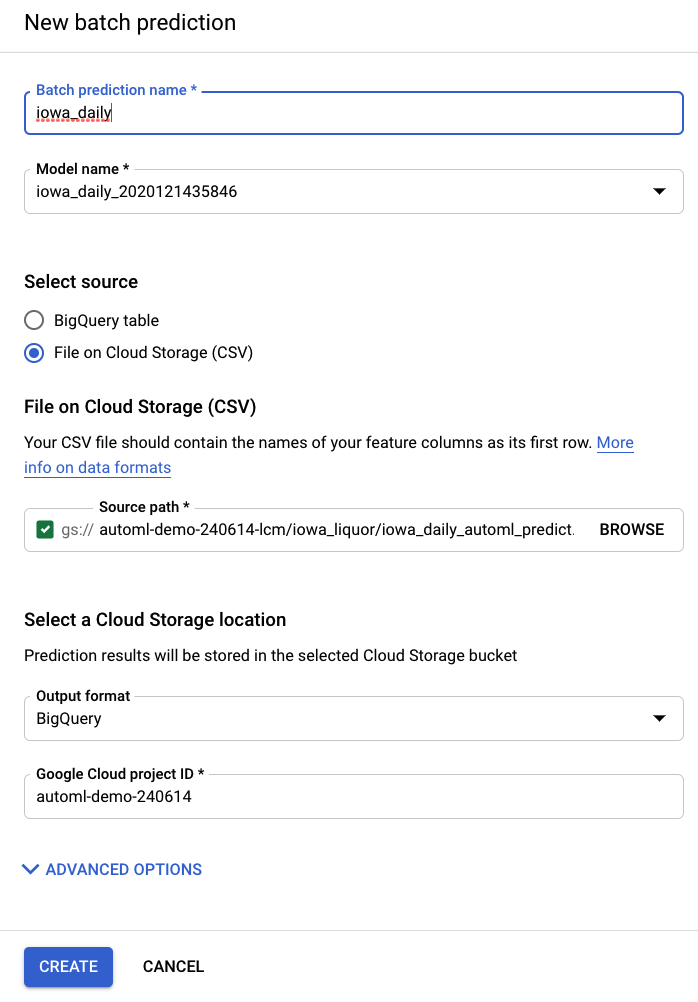
Proces prognozowania zbiorczego potrwa kilka minut. Po zakończeniu zadania możesz kliknąć zadanie prognozowania zbiorczego, aby wyświetlić szczegóły, w tym lokalizację eksportu. Aby uzyskać dostęp do prognoz w BigQuery, musisz w pasku nawigacyjnym po lewej stronie przejść do projektu, zbioru danych lub tabeli.
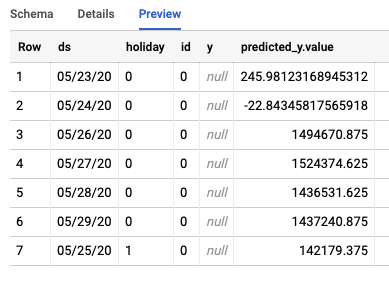
Zadanie utworzy w BigQuery 2 różne tabele. Jeden będzie zawierać wiersze z błędami, a drugi – prognozy. Oto przykład danych wyjściowych z tabeli Prognozy:
Krok 3. Podsumowanie
Gratulacje, udało Ci się utworzyć i wytrenować model prognozowania za pomocą AutoML. W tym module omówiliśmy importowanie danych, tworzenie modelu i generowanie prognoz.
Możesz już utworzyć własny model prognozowania.