
1. ภาพรวม
ใน Lab นี้ คุณจะได้ทำสิ่งต่อไปนี้
- สร้างชุดข้อมูลที่มีการจัดการ
- นำเข้าข้อมูลจาก Bucket ของ Google Cloud Storage
- อัปเดตข้อมูลเมตาของคอลัมน์เพื่อให้ใช้งานกับ AutoML ได้อย่างเหมาะสม
- ฝึกโมเดลโดยใช้ตัวเลือกต่างๆ เช่น งบประมาณและวัตถุประสงค์ในการเพิ่มประสิทธิภาพ
- ทำการคาดการณ์แบบกลุ่มออนไลน์
2. ตรวจสอบข้อมูล
แล็บนี้ใช้ข้อมูลจากชุดข้อมูลการขายสุราในไอโอวาจากชุดข้อมูลสาธารณะของ BigQuery ชุดข้อมูลนี้ประกอบด้วยการซื้อสุราในราคาส่งในรัฐไอโอวาของสหรัฐอเมริกาตั้งแต่ปี 2012
คุณดูข้อมูลดิบเดิมได้โดยเลือกดูชุดข้อมูล หากต้องการเข้าถึงตาราง ให้ไปที่โปรเจ็กต์ bigquery-public-datasets ในแถบนำทางด้านซ้าย จากนั้นไปที่ชุดข้อมูล iowa_liquor_sales แล้วไปที่ตาราง sales คุณเลือกแสดงตัวอย่างเพื่อดูแถวที่เลือกจากชุดข้อมูลได้
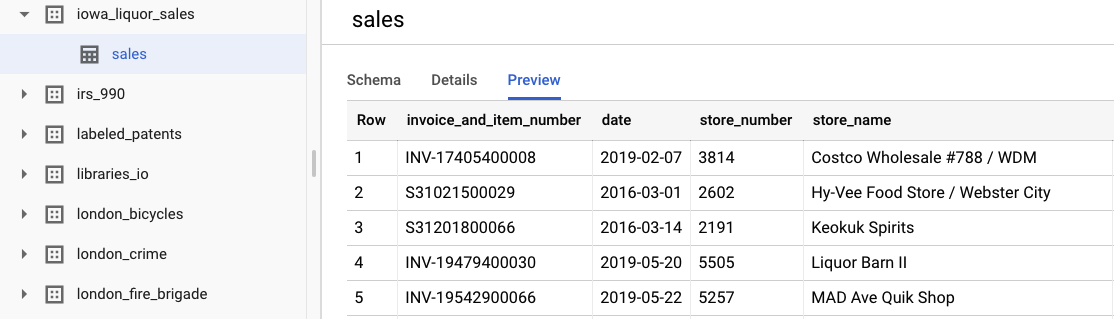
สําหรับวัตถุประสงค์ของแล็บนี้ เราได้ทําการประมวลผลข้อมูลเบื้องต้นบางอย่างเพื่อจัดกลุ่มการซื้อตามวันแล้ว เราจะใช้ข้อมูลที่ดึงจากตาราง BigQuery ในรูปแบบ CSV คอลัมน์ในไฟล์ CSV มีดังนี้
- ds: วันที่
- y: ผลรวมของการซื้อทั้งหมดในวันนั้นเป็นดอลลาร์
- holiday: บูลีนที่ระบุว่าวันที่เป็นวันหยุดของสหรัฐอเมริกาหรือไม่
- id: ตัวระบุอนุกรมเวลา (เพื่อรองรับอนุกรมเวลาหลายรายการ เช่น ตามร้านค้าหรือตามผลิตภัณฑ์) ในกรณีนี้ เราจะคาดการณ์การซื้อโดยรวมในอนุกรมเวลาเดียว ดังนั้นเราจึงตั้งค่ารหัสเป็น 0 สำหรับแต่ละแถว
3. นำเข้าข้อมูล
ขั้นตอนที่ 1: ไปที่ชุดข้อมูล Vertex AI
เข้าถึงชุดข้อมูลในเมนู Vertex AI จากแถบนำทางด้านซ้ายของ Cloud Console
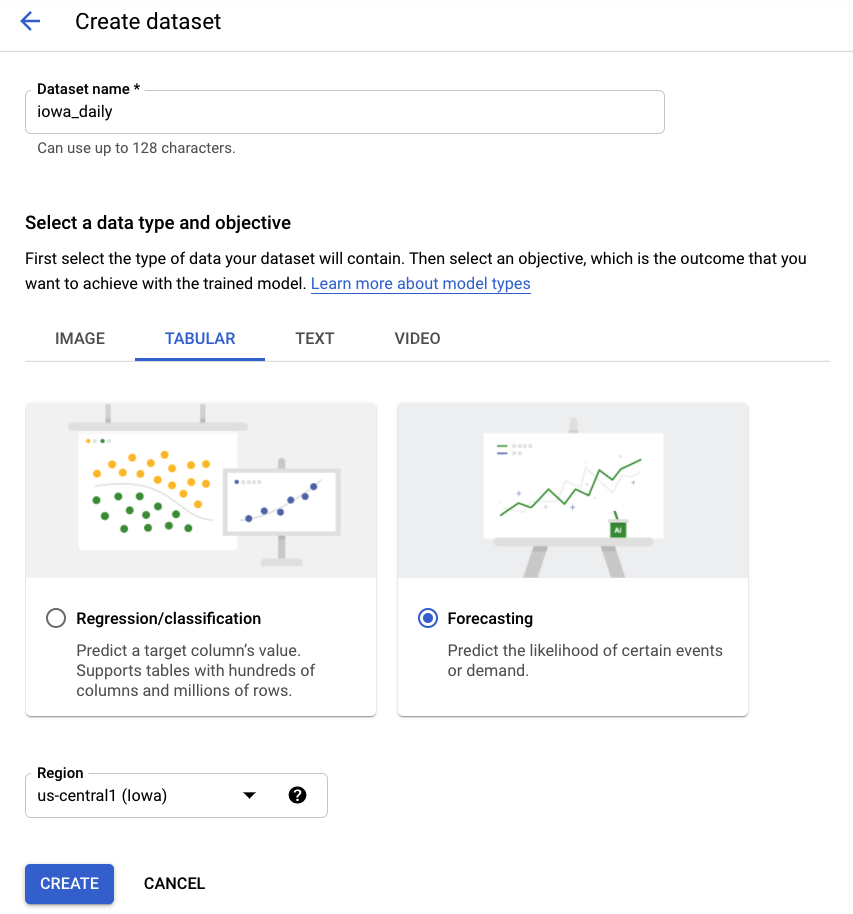
ขั้นตอนที่ 2: สร้างชุดข้อมูล
สร้างชุดข้อมูลใหม่โดยเลือกข้อมูลตาราง แล้วเลือกประเภทปัญหาการคาดการณ์ เลือกชื่อ iowa_daily หรือชื่ออื่นที่คุณต้องการ
ขั้นตอนที่ 3: นำเข้าข้อมูล
ขั้นตอนถัดไปคือการนําเข้าข้อมูลไปยังชุดข้อมูล เลือกตัวเลือกเพื่อเลือก CSV จาก Cloud Storage จากนั้นไปที่ไฟล์ CSV ในที่เก็บข้อมูล AutoML Demo Alpha แล้ววาง automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv
4. ฝึกโมเดล
ขั้นตอนที่ 1: กำหนดค่าฟีเจอร์โมเดล
หลังจากผ่านไป 2-3 นาที AutoML จะแจ้งให้คุณทราบว่าการนำเข้าเสร็จสมบูรณ์แล้ว จากนั้นคุณจะกำหนดค่าฟีเจอร์ของโมเดลได้
- เลือกคอลัมน์ตัวระบุอนุกรมเวลาเป็น id เรามีอนุกรมเวลาเพียงรายการเดียวในชุดข้อมูล ดังนั้นจึงเป็นเพียงพิธีการ
- เลือกคอลัมน์เวลาเป็น ds
จากนั้นเลือกสร้างสถิติ หลังจากกระบวนการเสร็จสมบูรณ์แล้ว คุณจะเห็นสถิติ %ที่ขาดหายไปและค่าที่ไม่ซ้ำกัน การดำเนินการนี้อาจใช้เวลาสักครู่ คุณจึงดำเนินการในขั้นตอนถัดไปได้เลยหากต้องการ
ขั้นตอนที่ 2: ฝึกโมเดล
เลือกฝึกโมเดลเพื่อเริ่มกระบวนการฝึก ตรวจสอบว่าได้เลือก AutoML แล้ว และดำเนินการต่อ
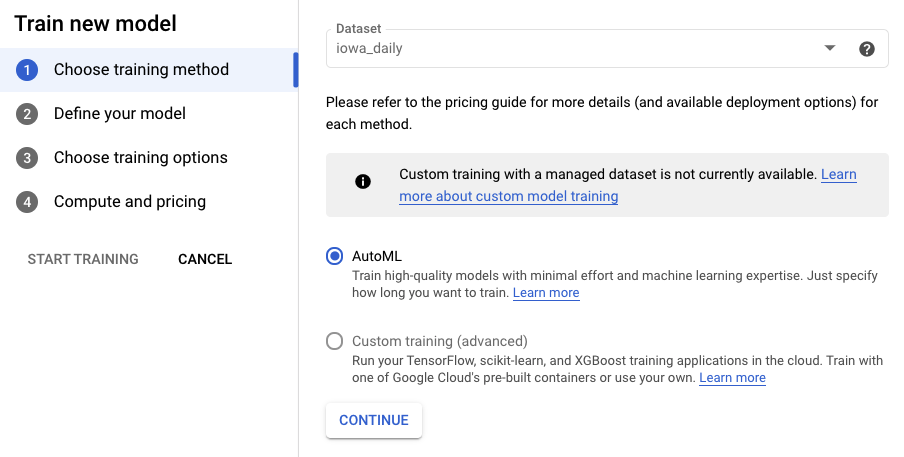
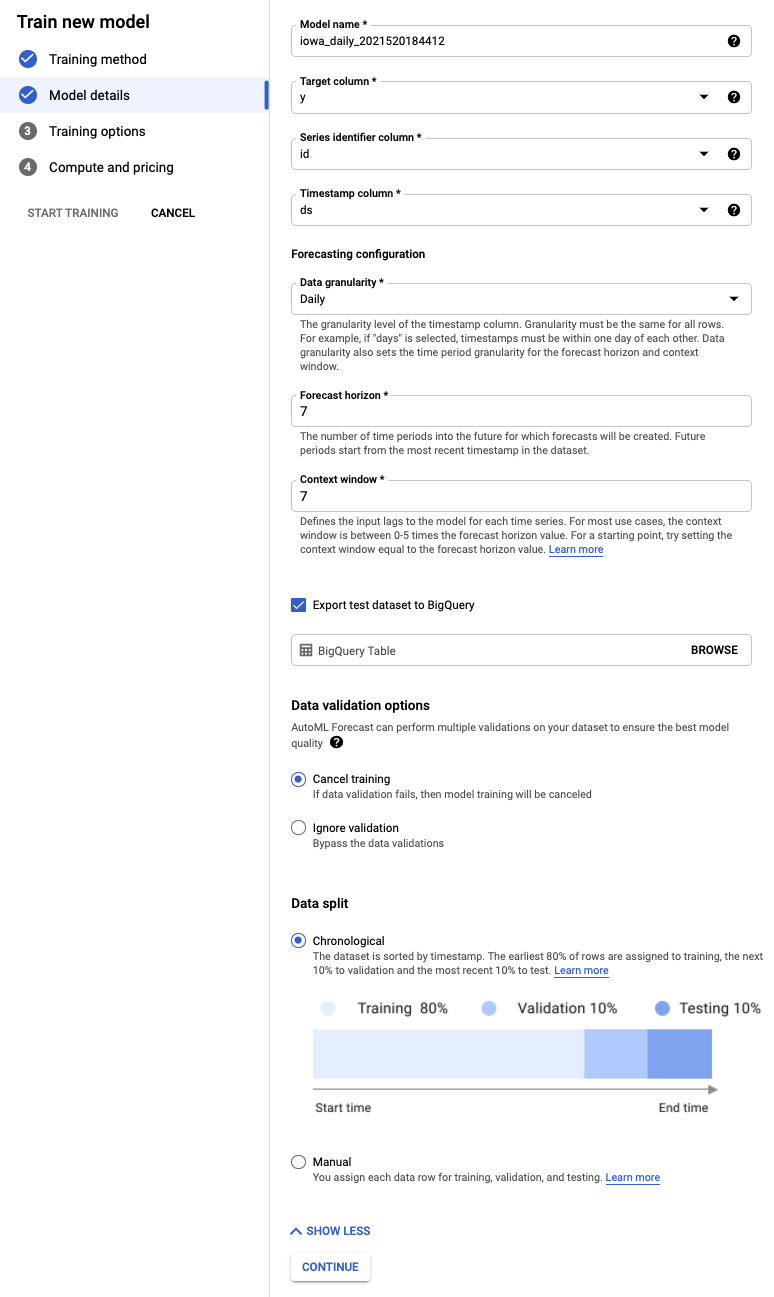
ขั้นตอนที่ 3: กำหนดโมเดล
- เลือกคอลัมน์เป้าหมายเป็น y นั่นคือมูลค่าที่เราคาดการณ์
- หากยังไม่ได้ตั้งค่าก่อนหน้านี้ ให้ตั้งค่าคอลัมน์ตัวระบุอนุกรมเป็น id และคอลัมน์การประทับเวลาเป็น ds
- ตั้งค่าความละเอียดของข้อมูลเป็นวัน และขอบเขตการคาดการณ์เป็น 7 ฟิลด์นี้ระบุจำนวนช่วงเวลาที่โมเดลคาดการณ์ได้ในอนาคต
- ตั้งค่ากรอบเวลาตามบริบทเป็น 7 วัน โมเดลจะใช้ข้อมูลจาก 30 วันก่อนหน้าเพื่อทำการคาดการณ์ การเลือกช่วงเวลาที่สั้นและยาวขึ้นมีข้อดีข้อเสียแตกต่างกัน และโดยทั่วไปแล้ว เราขอแนะนำให้เลือกค่าระหว่าง 1-10 เท่าของขอบเขตการพยากรณ์
- เลือกช่องเพื่อส่งออกชุดข้อมูลทดสอบไปยัง BigQuery คุณจะเว้นว่างไว้ก็ได้ แล้วระบบจะสร้างชุดข้อมูลและตารางในโปรเจ็กต์โดยอัตโนมัติ (หรือระบุตำแหน่งที่คุณต้องการ)
- เลือกต่อไป
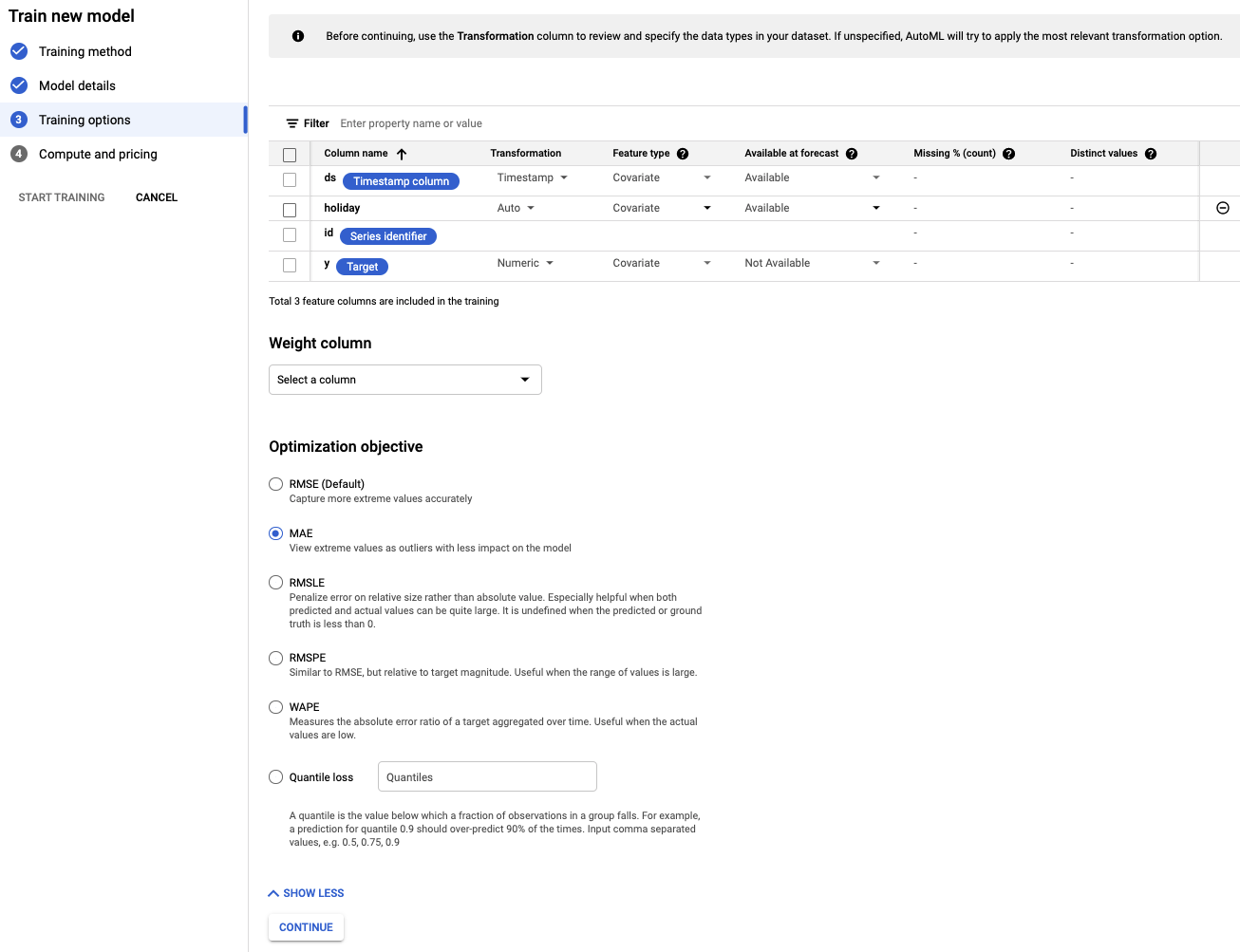
ขั้นตอนที่ 4: ตั้งค่าตัวเลือกการฝึก
ในขั้นตอนนี้ คุณสามารถระบุรายละเอียดเพิ่มเติมเกี่ยวกับวิธีฝึกโมเดลได้
- ตั้งค่าคอลัมน์วันหยุดเป็นพร้อมใช้งานในการคาดการณ์ เนื่องจากเราทราบว่าวันที่ที่กำหนดเป็นวันหยุดล่วงหน้าหรือไม่
- เปลี่ยนวัตถุประสงค์การเพิ่มประสิทธิภาพเป็น MAE MAE หรือค่าเฉลี่ยความคลาดเคลื่อนเฉลี่ยมีความยืดหยุ่นต่อค่าผิดปกติมากกว่าค่าเฉลี่ยความคลาดเคลื่อนกำลังสอง เนื่องจากเราใช้ข้อมูลการซื้อรายวันซึ่งอาจมีความผันผวนอย่างมาก MAE จึงเป็นเมตริกที่เหมาะสมในการใช้งาน
- เลือกต่อไป
ขั้นตอนที่ 5: เริ่มการฝึก
กำหนดงบประมาณที่คุณต้องการ ในกรณีนี้ 1 ชั่วโมงการทำงานของโหนดก็เพียงพอที่จะฝึกโมเดลแล้ว จากนั้นเริ่มกระบวนการฝึก
ขั้นตอนที่ 6: ประเมินโมเดล
กระบวนการฝึกอาจใช้เวลา 1-2 ชั่วโมงจึงจะเสร็จสมบูรณ์ (รวมถึงเวลาในการตั้งค่าเพิ่มเติม) คุณจะได้รับอีเมลเมื่อการฝึกเสร็จสมบูรณ์ เมื่อพร้อมแล้ว คุณจะดูความแม่นยำของโมเดลที่สร้างขึ้นได้
5. คาดการณ์
ขั้นตอนที่ 1: ตรวจสอบการคาดการณ์ในข้อมูลทดสอบ
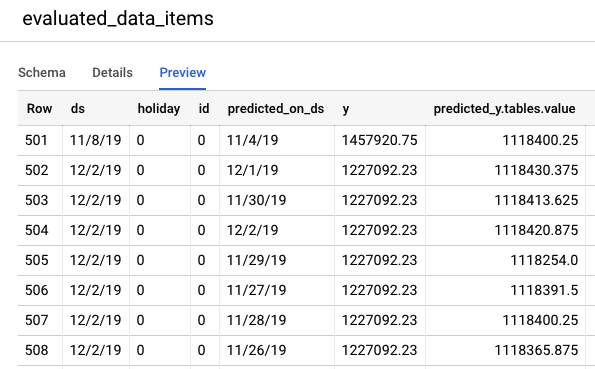
ไปที่คอนโซล BigQuery เพื่อดูการคาดการณ์ในข้อมูลทดสอบ ภายในโปรเจ็กต์ ระบบจะสร้างชุดข้อมูลใหม่โดยอัตโนมัติด้วยรูปแบบการตั้งชื่อ export_evaluated_data_items + <ชื่อโมเดล> + <การประทับเวลา> ภายในชุดข้อมูลนั้น คุณจะเห็นตาราง evaluated_data_items เพื่อตรวจสอบการคาดการณ์
ตารางนี้มีคอลัมน์ใหม่ 2 คอลัมน์ดังนี้
- predicted_on_[date column]: วันที่ที่ทำการคาดการณ์ เช่น หาก predicted_on_ds คือ 11/4 และ ds คือ 11/8 แสดงว่าเรากําลังคาดการณ์ล่วงหน้า 4 วัน
- predicted_[target column].tables.value: ค่าที่คาดการณ์
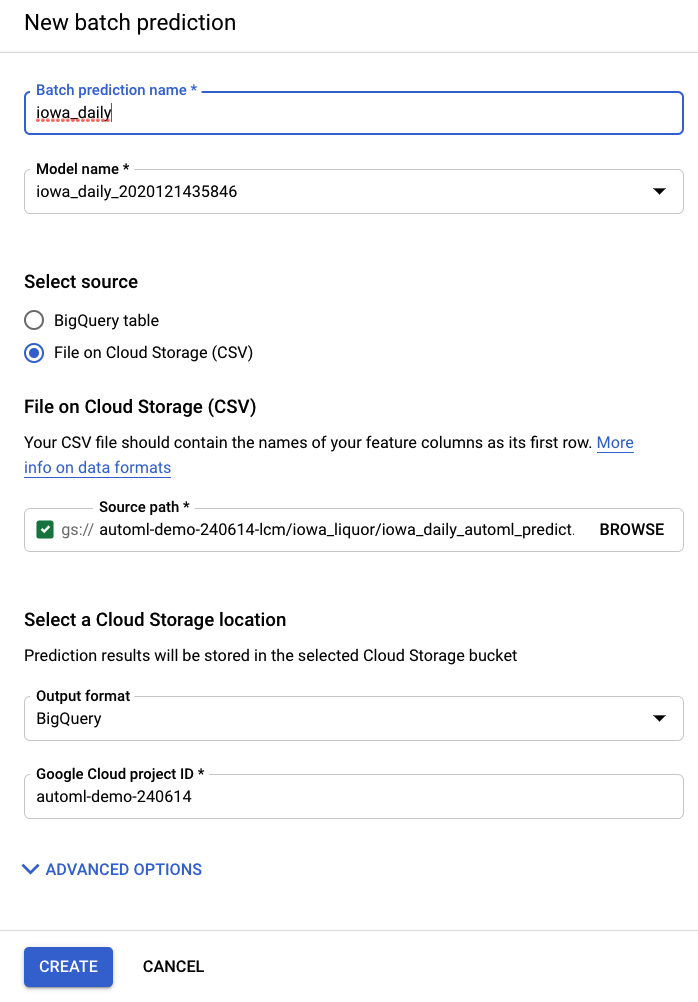
ขั้นตอนที่ 2: ดำเนินการคาดการณ์แบบกลุ่ม
สุดท้าย คุณจะต้องใช้โมเดลเพื่อทำการคาดการณ์
ไฟล์อินพุตมีค่าว่างสำหรับวันที่ที่จะคาดการณ์ พร้อมกับข้อมูลย้อนหลัง
ds | วันหยุด | id | y |
15/05/20 | 0 | 0 | 1751315.43 |
16/05/20 | 0 | 0 | 0 |
17/5/20 | 0 | 0 | 0 |
18/5/20 | 0 | 0 | 1612066.43 |
19/5/20 | 0 | 0 | 1773885.17 |
20/5/20 | 0 | 0 | 1487270.92 |
21/5/20 | 0 | 0 | 1024051.76 |
22/05/20 | 0 | 0 | 1471736.31 |
23/5/20 | 0 | 0 | <ว่าง> |
24/5/20 | 0 | 0 | <ว่าง> |
25/5/20 | 1 | 0 | <ว่าง> |
26/5/20 | 0 | 0 | <ว่าง> |
27/5/20 | 0 | 0 | <ว่าง> |
28/5/20 | 0 | 0 | <ว่าง> |
29/5/20 | 0 | 0 | <ว่าง> |
คุณสร้างการคาดการณ์แบบกลุ่มใหม่ได้จากรายการการคาดการณ์แบบกลุ่มในแถบนำทางด้านซ้ายของ AI Platform (แบบรวม)
ระบบจะสร้างไฟล์อินพุตตัวอย่างให้คุณที่นี่ในที่เก็บข้อมูล automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv
คุณระบุตำแหน่งไฟล์ต้นฉบับนี้ได้ จากนั้นคุณจะเลือกส่งออกการคาดการณ์ไปยังตำแหน่ง Cloud Storage เป็น CSV หรือไปยัง BigQuery ก็ได้ สำหรับแล็บนี้ ให้เลือก BigQuery แล้วเลือกรหัสโปรเจ็กต์ Google Cloud ของคุณ
กระบวนการคาดการณ์เป็นกลุ่มจะใช้เวลาหลายนาที หลังจากเสร็จสมบูรณ์แล้ว คุณสามารถคลิกที่งานการคาดการณ์แบบเป็นชุดเพื่อดูรายละเอียด รวมถึงตำแหน่งส่งออก ใน BigQuery คุณจะต้องไปที่โปรเจ็กต์ / ชุดข้อมูล / ตารางในแถบนำทางด้านซ้ายเพื่อเข้าถึงการคาดการณ์
งานจะสร้างตาราง 2 ตารางที่แตกต่างกันใน BigQuery ไฟล์หนึ่งจะมีแถวที่มีข้อผิดพลาด และอีกไฟล์จะมีข้อมูลการคาดการณ์ ตัวอย่างเอาต์พุตจากตารางการคาดการณ์มีดังนี้
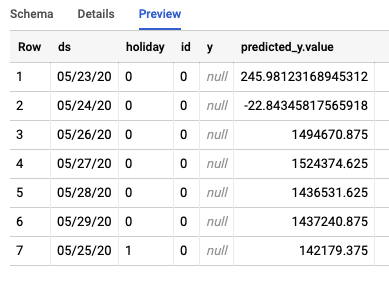
ขั้นตอนที่ 3: บทสรุป
ขอแสดงความยินดี คุณสร้างและฝึกโมเดลการคาดการณ์ด้วย AutoML เรียบร้อยแล้ว ในแล็บนี้ เราได้ครอบคลุมการนำเข้าข้อมูล การสร้างโมเดล และการคาดการณ์
คุณพร้อมที่จะสร้างโมเดลการคาดการณ์ของคุณเองแล้ว