
1. 總覽
本實驗室的學習內容如下:
- 建立代管資料集
- 從 Google Cloud Storage 值區匯入資料
- 更新欄中繼資料,以便適當搭配 AutoML 使用
- 使用預算和最佳化目標等選項訓練模型
- 進行線上批次預測
2. 查看資料
本實驗室會使用 BigQuery 公開資料集的愛荷華州酒類銷售量資料集。這個資料集包含 2012 年以來,美國愛荷華州批發酒類購買交易的資料。
選取「查看資料集」即可查看原始資料。如要存取表格,請在左側導覽列中依序前往「bigquery-public-datasets」專案、「iowa_liquor_sales」資料集和「sales」表格。選取「預覽」即可查看資料集中的部分資料列。
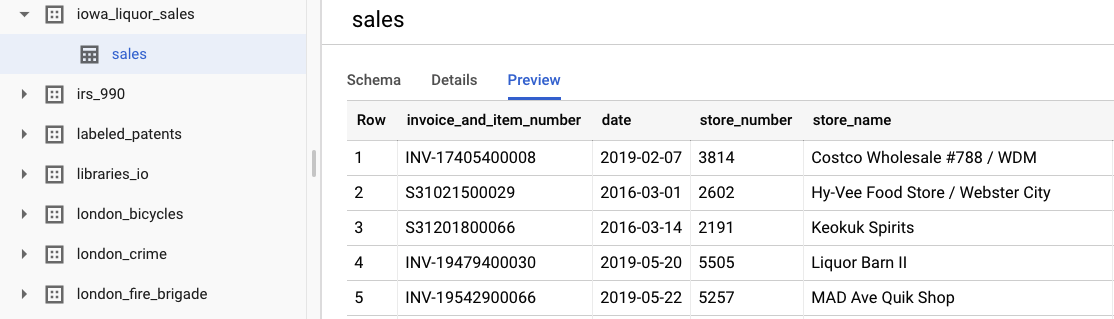
在本實驗室中,我們已完成一些基本資料前處理作業,將購買交易依日期分組。我們會使用從 BigQuery 資料表匯出的 CSV 檔案。CSV 檔案中的資料欄如下:
- ds:日期
- y:當天所有購買交易的總金額 (以美元計)
- holiday:日期是否為美國節日的布林值
- id:時間序列 ID (支援多個時間序列,例如依商店或產品)。在本例中,我們只會預測單一時間序列的整體購買量,因此每列的 ID 都會設為 0。
3. 匯入資料
步驟 1:前往 Vertex AI 資料集
在 Cloud 控制台的左側導覽列中,存取 Vertex AI 選單中的「資料集」。
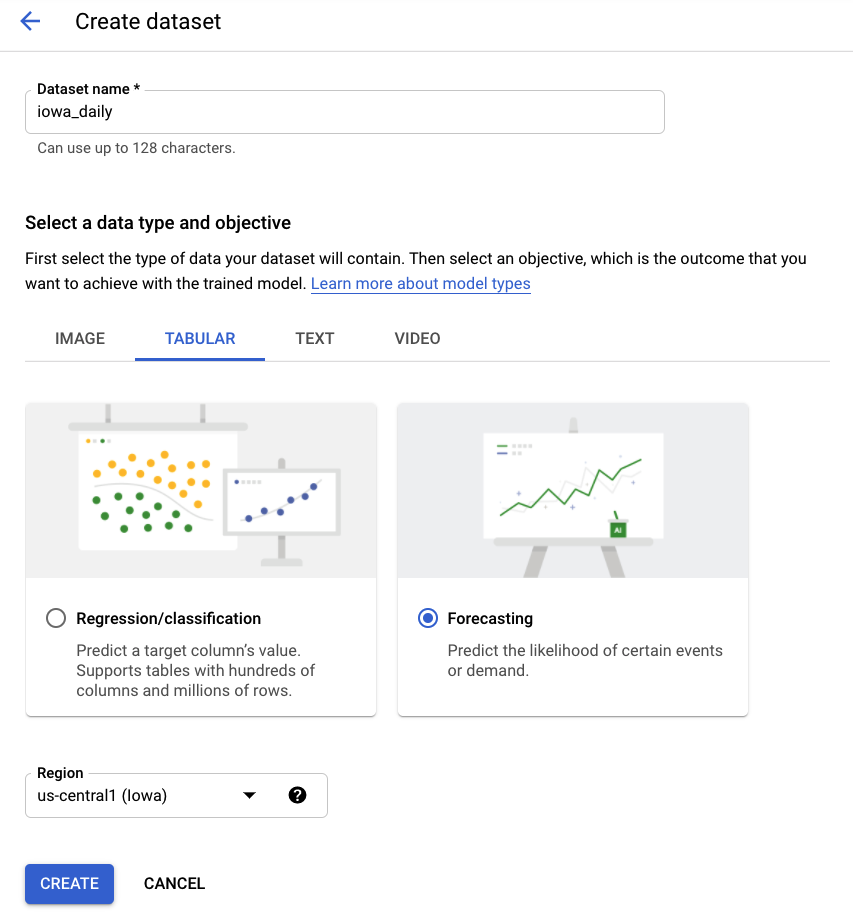
步驟 2:建立資料集
建立新的資料集,選取「表格資料」,然後選取「預測」問題類型。選擇 iowa_daily 或其他偏好的名稱。
步驟 3:匯入資料
下一步是將資料匯入資料集。選擇「選取 Cloud Storage 中的 CSV 檔案」選項。然後前往 AutoML Demo Alpha bucket 中的 CSV 檔案,並貼上 automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv。
4. 訓練模型
步驟 1:設定模型功能
幾分鐘後,AutoML 會通知您匯入作業已完成。屆時即可設定模型功能。
- 選取要當做 ID 的「時間序列 ID 欄」。我們的資料集中只有一個時間序列,因此這只是形式上的做法。
- 選取要 ds 的「時間」欄。
然後選取「產生統計資料」。程序完成後,您會看到「缺少 %」和「相異值」統計資料。這項程序可能需要幾分鐘,因此你可以先進行下一個步驟。
步驟 2:訓練模型
選取「訓練模型」即可開始訓練程序。確認已選取 AutoML,然後按一下「繼續」。
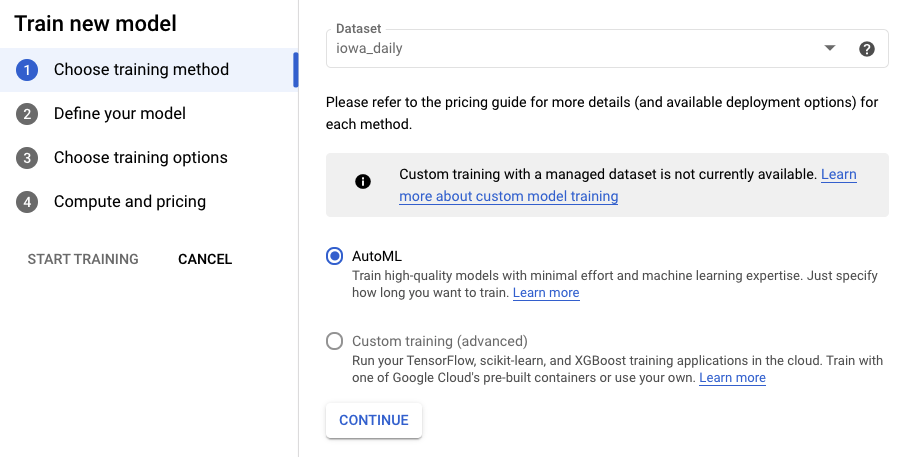
步驟 3:定義模型
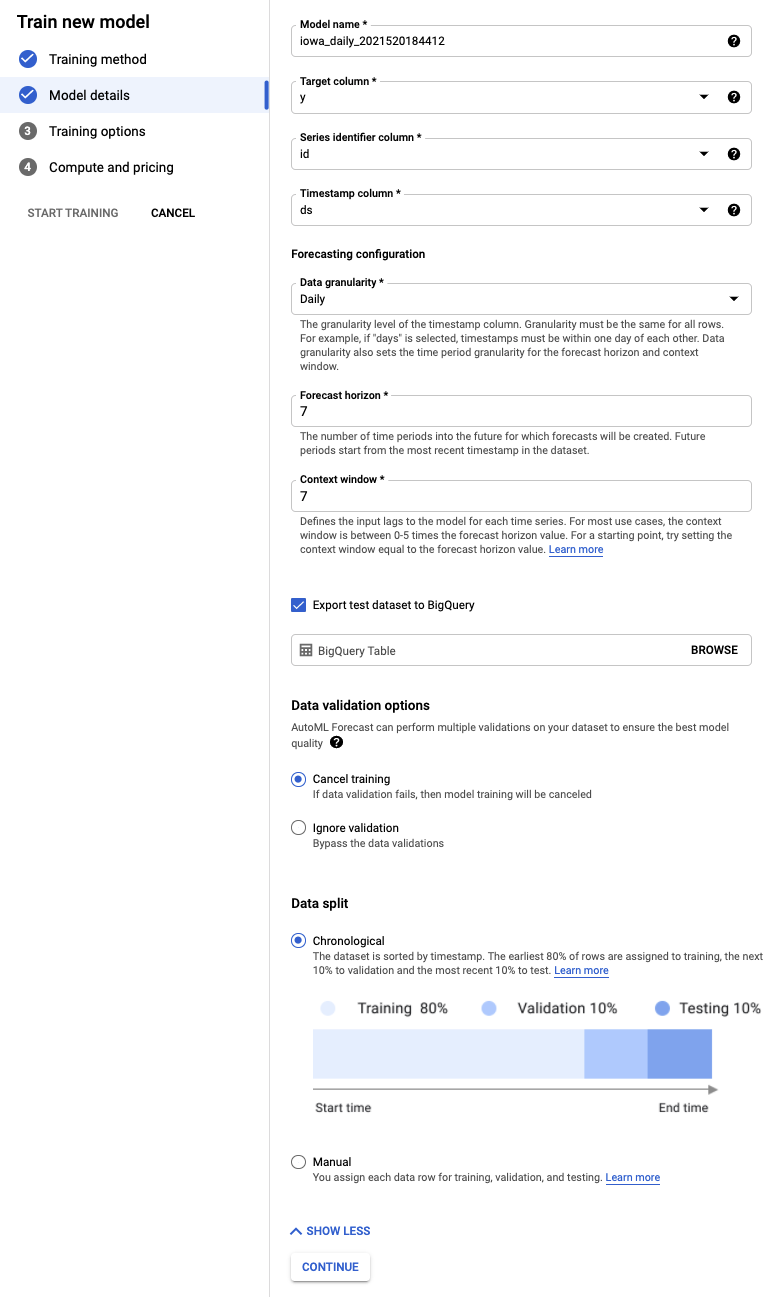
- 選取要設為 y 的「目標資料欄」。這就是我們要預測的值。
- 如果先前未設定,請將「時間序列 ID」欄設為 id,並將「時間戳記」欄設為 ds。
- 將「資料精細程度」設為「天」,並將「預測期間」設為「7」。這個欄位會指定模型可預測的未來週期數。
- 將「背景期間」設為 7 天。模型會使用過去 30 天的資料進行預測。較短和較長的區間各有優缺點,一般建議選取預測期間的 1 至 10 倍。
- 勾選「將測試資料集匯出至 BigQuery」方塊。您可以將其留空,系統會在專案中自動建立資料集和資料表 (或指定您選擇的位置)。
- 選取「繼續」。
步驟 4:設定訓練選項
在這個步驟中,您可以指定更多模型訓練方式的詳細資料。
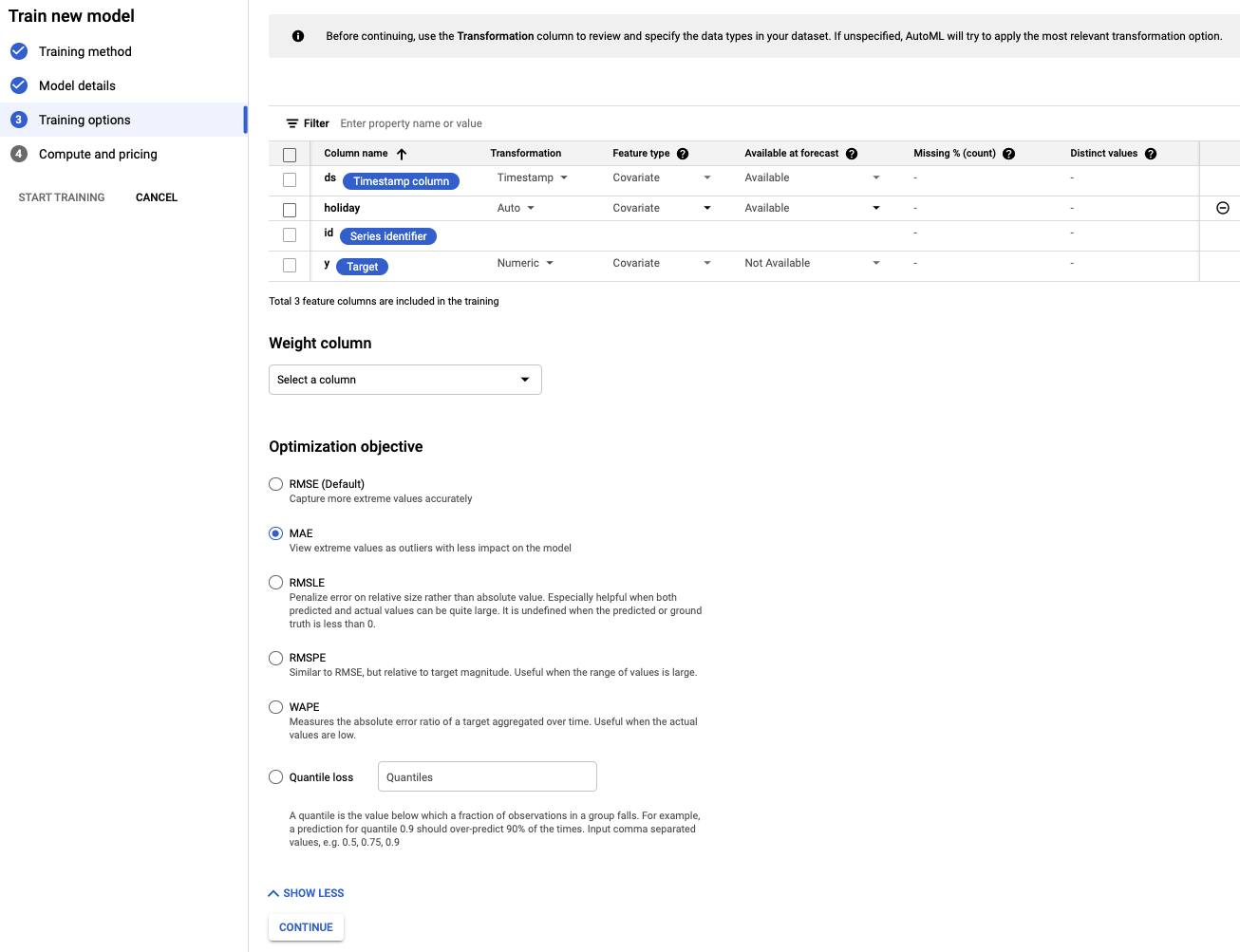
- 將「holiday」欄位設為「Available」,因為我們事先知道指定日期是否為假日。
- 將「最佳化目標」變更為「MAE」。相較於均方誤差,平均絕對誤差 (MAE) 對離群值的容錯能力較高。由於我們處理的是每日購買資料,這類資料的波動幅度可能很大,因此 MAE 是合適的指標。
- 選取「繼續」。
步驟 5:啟動訓練
設定所需預算,在本例中,1 個節點時數就足以訓練模型。接著開始訓練程序。
步驟 6:評估模型
訓練程序可能需要 1 到 2 小時才能完成 (包括任何額外的設定時間)。訓練完成後,你會收到電子郵件通知。準備就緒後,您就可以查看所建模型的準確度。
5. 預測
步驟 1:查看測試資料的預測結果
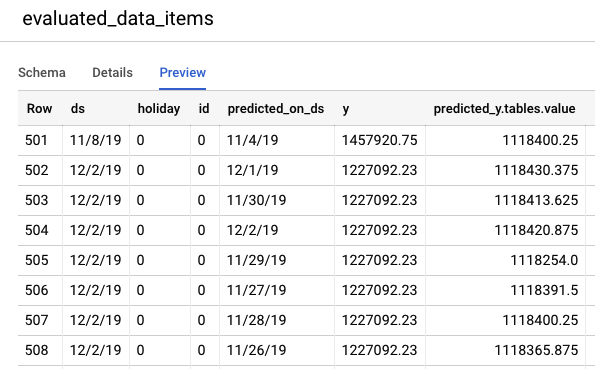
前往 BigQuery 控制台,查看測試資料的預測結果。系統會在專案中自動建立新資料集,命名方式為:export_evaluated_data_items + <model name> + <timestamp>。您可以在該資料集中找到 evaluated_data_items 資料表,查看預測結果。
這份表格新增了幾個資料欄:
- predicted_on_[date column]:預測日期。舉例來說,如果 predicted_on_ds 為 11/4,而 ds 為 11/8,則預測提前 4 天。
- predicted_[目標資料欄].tables.value:預測值
步驟 2:執行批次預測
最後,您會想使用模型進行預測。
輸入檔案包含要預測日期的空值,以及歷來資料:
ds | holiday | id | y |
2020 年 5 月 15 日 | 0 | 0 | 1751315.43 |
2020 年 5 月 16 日 | 0 | 0 | 0 |
2020 年 5 月 17 日 | 0 | 0 | 0 |
2020 年 5 月 18 日 | 0 | 0 | 1612066.43 |
2020 年 5 月 19 日 | 0 | 0 | 1773885.17 |
2020 年 5 月 20 日 | 0 | 0 | 1487270.92 |
2020 年 5 月 21 日 | 0 | 0 | 1024051.76 |
2020 年 5 月 22 日 | 0 | 0 | 1471736.31 |
2020 年 5 月 23 日 | 0 | 0 | <empty> |
2020/5/24 | 0 | 0 | <empty> |
2020 年 5 月 25 日 | 1 | 0 | <empty> |
2020 年 5 月 26 日 | 0 | 0 | <empty> |
2020/5/27 | 0 | 0 | <empty> |
2020/5/28 | 0 | 0 | <empty> |
2020 年 5 月 29 日 | 0 | 0 | <empty> |
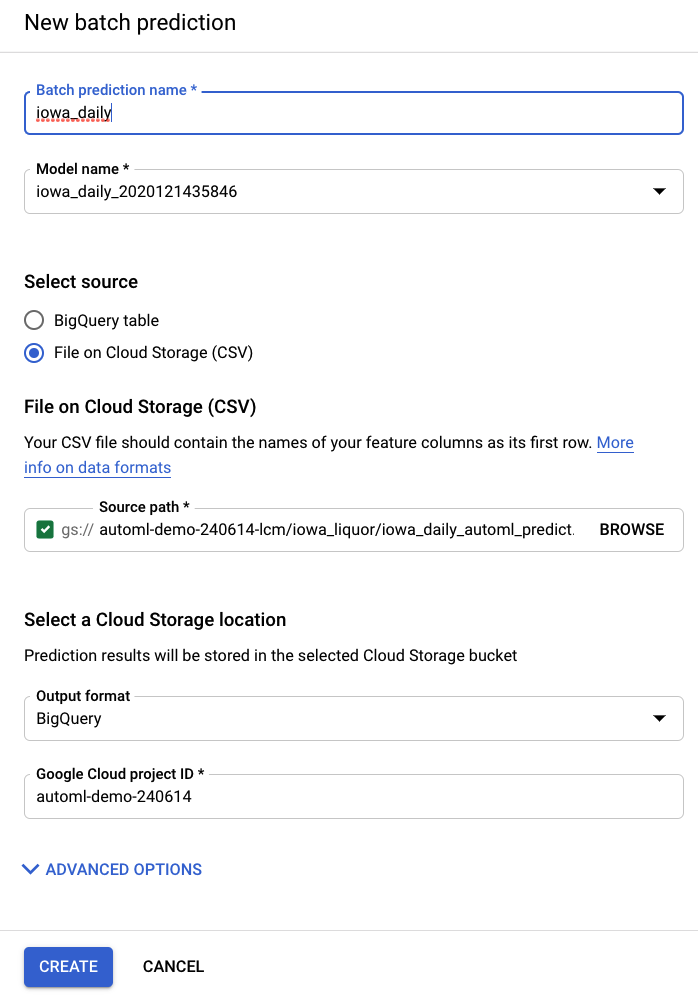
在 AI Platform (Unified) 左側導覽列中,選取「批次預測」項目,即可建立新的批次預測。
系統已在儲存空間 bucket 中為您建立範例輸入檔案:automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv
你可以提供這個來源檔案位置。接著,您可以選擇將預測結果匯出至雲端儲存空間 (CSV 格式) 或 BigQuery。在本實驗室中,請選取「BigQuery」,然後選擇「您的 Google Cloud 專案 ID」。
批次預測程序需要幾分鐘才能完成。完成後,您可以點選批次預測工作來查看詳細資料,包括「匯出位置」。在 BigQuery 中,您需要前往左側導覽列中的專案 / 資料集 / 資料表,才能存取預測結果。
這項作業會在 BigQuery 中建立兩個不同的資料表。一個包含有錯誤的列,另一個則包含預測結果。以下是「預測」表格的輸出範例:
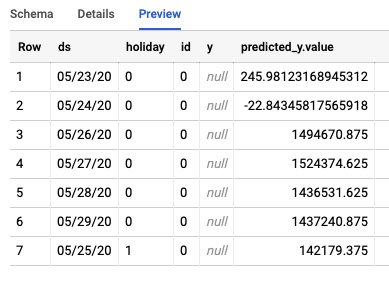
步驟 3:結論
恭喜!您已成功使用 AutoML 建構及訓練預測模型。在本實驗室中,我們介紹了如何匯入資料、建構模型及進行預測。
您已準備好建構自己的預測模型!