
1. Giriş

Son Güncelleme: 2020-02-28
Bu codelab'de, CSV biçimli sağlık verilerini toplu olarak BigQuery'ye aktarmak için kullanılan bir veri alımı modeli gösterilmektedir. Bu laboratuvarda Cloud Data Fusion toplu veri ardışık düzenini kullanacağız. Gerçekçi sağlık hizmeti test verileri oluşturuldu ve sizin için Google Cloud Storage paketinde (gs://hcls_testing_data_fhir_10_patients/csv/) kullanıma sunuldu.
Bu kod laboratuvarında öğrenecekleriniz:
- Cloud Data Fusion'ı kullanarak GCS'den BigQuery'ye CSV verilerini nasıl alacağınızı (toplu iş planlı yükleme) öğrenin.
- Cloud Data Fusion'da sağlık hizmeti verilerini toplu olarak yüklemek, dönüştürmek ve maskelemek için veri entegrasyonu ardışık düzenini görsel olarak oluşturma
Bu codelab'i çalıştırmak için neye ihtiyacınız var?
- Bir GCP projesine erişiminiz olmalıdır.
- GCP projesi için size Sahip rolü atanmış olmalıdır.
- Başlık dahil olmak üzere CSV biçimindeki sağlık hizmeti verileri
GCP projeniz yoksa yeni bir GCP projesi oluşturmak için bu adımları uygulayın.
CSV biçimindeki sağlık hizmeti verileri, gs://hcls_testing_data_fhir_10_patients/csv/ adresindeki GCS paketine önceden yüklenmiştir. Her kaynak CSV dosyasının benzersiz bir şema yapısı vardır. Örneğin, Hastalar.csv, Sağlayıcılar.csv'den farklı bir şemaya sahiptir. Önceden yüklenmiş şema dosyalarını gs://hcls_testing_data_fhir_10_patients/csv_schemas adresinde bulabilirsiniz.
Yeni bir veri kümesine ihtiyacınız varsa SyntheaTM'i kullanarak istediğiniz zaman oluşturabilirsiniz. Ardından, giriş verilerini kopyalama adımında paketten kopyalamak yerine GCS'ye yükleyin.
2. GCP Projesi Kurulumu
Ortamınız için kabuk değişkenlerini başlatın.
PROJECT_ID'yi bulmak için Projeleri tanımlama başlıklı makaleyi inceleyin.
<!-- CODELAB: Initialize shell variables -> <!-- Your current GCP Project ID -> export PROJECT_ID=<PROJECT_ID> <!-- A new GCS Bucket in your current Project - INPUT -> export BUCKET_NAME=<BUCKET_NAME> <!-- A new BQ Dataset ID - OUTPUT -> export DATASET_ID=<DATASET_ID>
gsutil aracınıkullanarak giriş verilerini ve hata günlüklerini depolamak için GCS paketi oluşturun.
gsutil mb -l us gs://$BUCKET_NAME
Yapay veri kümesine erişin.
- Cloud Console'da oturum açmak için kullandığınız e-posta adresinden hcls-solutions-external+subscribe@google.com adresine katılma isteği içeren bir e-posta gönderin.
- İşlemi nasıl onaylayacağınızla ilgili talimatları içeren bir e-posta alırsınız.

- Gruba katılmak için e-postayı yanıtlama seçeneğini kullanın. Düğmeyi TIKLAMAYIN.
- Onay e-postasını aldıktan sonra codelab'deki sonraki adıma geçebilirsiniz.
Giriş verilerini kopyalama
gsutil -m cp -r gs://hcls_testing_data_fhir_10_patients/csv gs://$BUCKET_NAME
BigQuery veri kümesi oluşturun.
bq mk --location=us --dataset $PROJECT_ID:$DATASET_ID
3. Cloud Data Fusion Ortam Kurulumu
Cloud Data Fusion API'yi etkinleştirmek ve gerekli izinleri vermek için aşağıdaki adımları uygulayın:
API'leri etkinleştirin.
- GCP Console API Kitaplığı'na gidin.
- Proje listesinden projenizi seçin.
- API kitaplığında etkinleştirmek istediğiniz API'yi seçin. API'yi bulma konusunda yardıma ihtiyacınız varsa arama alanını ve/veya filtreleri kullanın.
- API sayfasında ETKİNLEŞTİR'i tıklayın.
Cloud Data Fusion örneği oluşturun.
- GCP Console'da ProjectID'nizi seçin.
- Sol menüden Veri Füzyonu'nu seçin, ardından sayfanın ortasındaki ÖRNEK OLUŞTUR düğmesini (ilk oluşturma) veya üst menüdeki ÖRNEK OLUŞTUR düğmesini (ek oluşturma) tıklayın.


- Örnek adını girin. Enterprise'ı seçin.

- OLUŞTUR düğmesini tıklayın.
Örnek izinlerini ayarlayın.
Bir örnek oluşturduktan sonra, örnekle ilişkili hizmet hesabına projenizde izin vermek için aşağıdaki adımları uygulayın:
- Örnek adını tıklayarak örnek ayrıntıları sayfasına gidin.

- Hizmet hesabını kopyalayın.

- Projenizin IAM sayfasına gidin.
- IAM izinleri sayfasında, hizmet hesabını yeni bir üye olarak ekleyip Cloud Data Fusion API Hizmet Aracısı rolünü vereceğiz. Ekle düğmesini tıklayın, ardından "hizmet hesabı"nı Yeni üyeler alanına yapıştırın ve Hizmet Yönetimi -> Cloud Data Fusion API Sunucusu Aracısı rolünü seçin.

- Kaydet'i tıklayın.
Bu adımlar tamamlandıktan sonra Cloud Data Fusion örnekleri sayfasındaki veya bir örneğin ayrıntılar sayfasındaki Örneği Görüntüle bağlantısını tıklayarak Cloud Data Fusion'ı kullanmaya başlayabilirsiniz.
Güvenlik duvarı kuralını ayarlayın.
- GCP Console -> VPC Network -> Firewall rules'a (Güvenlik duvarı kuralları) giderek default-allow-ssh kuralının mevcut olup olmadığını kontrol edin.

- Aksi takdirde, varsayılan ağa tüm giriş SSH trafiğine izin veren bir güvenlik duvarı kuralı ekleyin.
Komut satırını kullanarak:
gcloud beta compute --project={PROJECT_ID} firewall-rules create default-allow-ssh --direction=INGRESS --priority=1000 --network=default --action=ALLOW --rules=tcp:22 --source-ranges=0.0.0.0/0 --enable-logging
Kullanıcı arayüzünü kullanarak: Güvenlik Duvarı Kuralı Oluştur'u tıklayın ve bilgileri doldurun:


4. Dönüşüm için şema oluşturma
Artık GCP'de Cloud Fusion ortamımız olduğuna göre bir şema oluşturalım. CSV verilerinin dönüştürülmesi için bu şemaya ihtiyacımız var.
- Cloud Data Fusion penceresinde, İşlem sütunundaki Örneği Görüntüle bağlantısını tıklayın. Başka bir sayfaya yönlendirilirsiniz. Cloud Data Fusion örneğini açmak için sağlanan URL'yi tıklayın. Karşılama pop-up'ında "Tur başlat" veya "Hayır, teşekkürler" düğmesini tıklama tercihinize bağlıdır.
- "Hamburger" menüsünü genişletin, Pipeline -> Studio'yu seçin.

- Soldaki eklenti paletinde Dönüştür bölümünün altında, Veri İşleme Hatları kullanıcı arayüzünde görünecek olan Wrangler düğmesini çift tıklayın.

- Fare imlecini Wrangler düğümünün üzerine getirin ve Properties'i (Özellikler) tıklayın. Düzenle düğmesini tıklayın, ardından istenen şemayı oluşturmak için tüm veri alanlarını içermesi gereken bir .csv kaynak dosyası (örneğin, patients.csv) seçin.
- Her sütun adının (ör. gövde) yanındaki aşağı oku (sütun dönüşümleri) tıklayın.

- Varsayılan olarak, ilk içe aktarma işleminde veri dosyanızda yalnızca bir sütun olduğu varsayılır. CSV olarak ayrıştırmak için Ayrıştır → CSV'yi seçin, ardından sınırlayıcıyı belirleyin ve "İlk satırı başlık olarak ayarla" kutusunu uygun şekilde işaretleyin. Uygula düğmesini tıklayın.
- Gövde alanının yanındaki aşağı oku tıklayın, Gövde alanını kaldırmak için Sütunu Sil'i seçin. Ayrıca sütunları kaldırma, bazı sütunların veri türünü değiştirme (varsayılan olarak "dize" türü), sütunları bölme, sütun adlarını ayarlama vb. gibi diğer dönüşümleri de deneyebilirsiniz.

- "Sütunlar" ve "Dönüşüm adımları" sekmelerinde çıkış şeması ve Wrangler'ın tarifi gösterilir. Sağ üst köşedeki Uygula'yı tıklayın. Doğrula düğmesini tıklayın. Yeşil renkli "Hata bulunamadı" ifadesi, işlemin başarılı olduğunu gösterir.

- Wrangler Properties'de, İşlemler açılır listesini tıklayarak istediğiniz şemayı yerel depolama alanınıza Aktarın. Gerekirse gelecekte İçe aktarabilirsiniz.
- Wrangler tarifini gelecekte kullanmak üzere kaydedin.
parse-as-csv :body ',' true drop body
- Wrangler Properties (Wrangler Özellikleri) penceresini kapatmak için X düğmesini tıklayın.
5. Ardışık düzen için düğümler oluşturma
Bu bölümde, işlem hattı bileşenlerini oluşturacağız.
- Veri İşleme Hatları kullanıcı arayüzünün sol üst kısmında, işlem hattı türü olarak Veri İşleme Hattı - Toplu'nun seçili olduğunu görürsünüz.

- Sol panelde, işlem hattı için bir veya daha fazla düğüm seçebileceğiniz Filtre, Kaynak, Dönüştürme, Analiz, Havuz, Koşullar ve İşlemler, Hata İşleyiciler ve Uyarılar gibi farklı bölümler bulunur.

Kaynak düğüm
- Kaynak düğümünü seçin.
- Soldaki eklenti paletinde Kaynak bölümünün altında, Veri İşleme Hatları kullanıcı arayüzünde görünen Google Cloud Storage düğümünü çift tıklayın.
- İmleci GCS kaynak düğümünün üzerine getirin ve Özellikler'i tıklayın.

- Zorunlu alanları doldurun. Aşağıdaki alanları ayarlayın:
- Etiket = {herhangi bir metin}
- Referans adı = {herhangi bir metin}
- Project ID (Proje kimliği) = otomatik algılama
- Yol: Mevcut projenizdeki paketin GCS URL'si. Örneğin, gs://$BUCKET_NAME/csv/
- Biçim = metin
- Yol alanı = dosya adı
- Path Filename Only = true
- Read Files Recursively = true
- + düğmesini tıklayarak "filename" alanını GCS Çıkış Şeması'na ekleyin.
- Ayrıntılı açıklama için Belgeler'i tıklayın. Doğrula düğmesini tıklayın. Yeşil renkli "Hata bulunamadı" ifadesi, işlemin başarılı olduğunu gösterir.
- GCS Özellikleri'ni kapatmak için X düğmesini tıklayın.
Dönüştürme düğümü
- Dönüştürme düğümünü seçin.
- Soldaki eklenti paletinde Dönüştür bölümünün altında, Veri İşleme Hatları kullanıcı arayüzünde görünen Wrangler düğmesini çift tıklayın. GCS kaynak düğümünü Wrangler dönüştürme düğümüne bağlayın.
- Fare imlecini Wrangler düğümünün üzerine getirin ve Properties'i (Özellikler) tıklayın.
- Kaydedilmiş bir şemayı içe aktarmak için İşlemler açılır listesini tıklayın ve İçe aktar'ı seçin (örneğin: gs://hcls_testing_data_fhir_10_patients/csv_schemas/ schema (Patients).json). Ardından, önceki bölümde kaydedilen tarifi yapıştırın.
- Alternatif olarak, Dönüşüm için şema oluşturma bölümündeki Wrangler düğümünü yeniden kullanın.
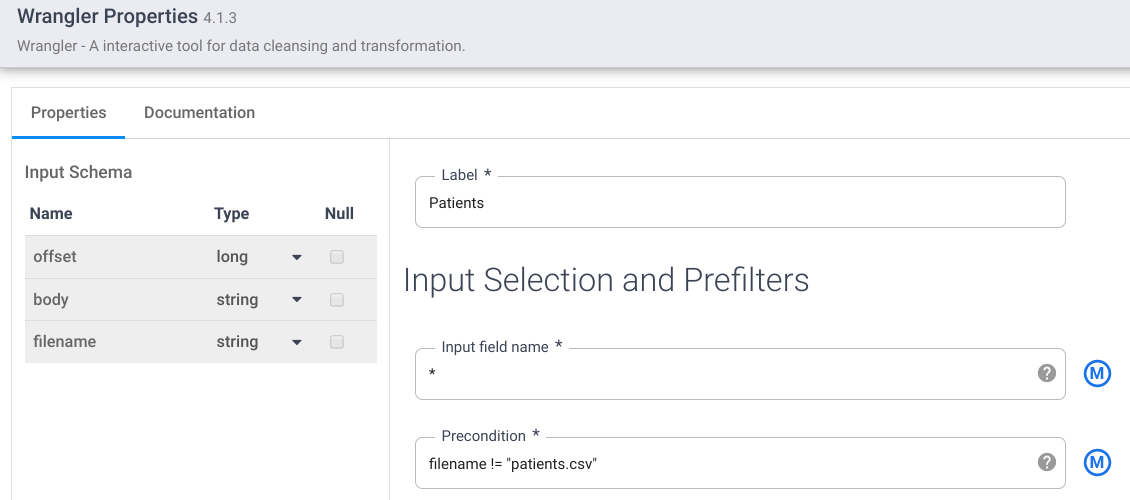
- Zorunlu alanları doldurun. Aşağıdaki alanları ayarlayın:
- Label = {any text}
- Giriş alanı adı = {*}
- Her giriş dosyasını (örneğin, patients.csv, providers.csv, allergies.csv vb.) Kaynak düğümünden ayırt etmek için Ön koşul = {filename != "patients.csv"}
- Kayıtları daha da dönüştüren, kullanıcı tarafından sağlanan JavaScript'i yürütmek için bir JavaScript düğümü ekleyin. Bu codelab'de, her kayıt güncellemesi için bir zaman damgası almak üzere JavaScript düğümünü kullanıyoruz. Wrangler dönüştürme düğümünü JavaScript dönüştürme düğümüne bağlayın. JavaScript Özellikleri'ni açın ve aşağıdaki işlevi ekleyin:

function transform(input, emitter, context) {
input.TIMESTAMP = (new Date()).getTime()*1000;
emitter.emit(input);
}
- + işaretini tıklayarak Çıkış Şeması'na TIMESTAMP adlı alanı ekleyin (yoksa). Veri türü olarak zaman damgasını seçin.

- Ayrıntılı açıklama için Belgeler'i tıklayın. Tüm giriş bilgilerini doğrulamak için Doğrula düğmesini tıklayın. Yeşil "Hata bulunamadı" ifadesi, işlemin başarılı olduğunu gösterir.
- Dönüştürme Özellikleri penceresini kapatmak için X düğmesini tıklayın.
Veri maskeleme ve kimlik gizleme
- Sütundaki aşağı oku tıklayıp Veri seçimini maskele bölümünde gereksinimlerinize uygun maskeleme kuralları uygulayarak (ör. Sosyal Güvenlik Numarası sütunu) tek tek veri sütunlarını seçebilirsiniz.

- Wrangler düğümünün Tarif penceresine daha fazla yönerge ekleyebilirsiniz. Örneğin, kimlik gizleme amacıyla aşağıdaki söz dizimine uygun karma oluşturma algoritmasıyla birlikte karma yönergesini kullanma:
hash <column> <algorithm> <encode> <column>: name of the column <algorithm>: Hashing algorithm (i.e. MD5, SHA-1, etc.) <encode>: default is true (hashed digest is encoded as hex with left-padding zeros). To disable hex encoding, set <encode> to false.

Sink node (Lavabo düğümü)
- Havuz düğümünü seçin.
- Soldaki eklenti paletinde, Sink bölümünde, Veri İşleme Hattı kullanıcı arayüzünde görünecek olan BigQuery düğmesini çift tıklayın.
- BigQuery havuz düğümünün üzerine gelin ve Özellikler'i tıklayın.

- Zorunlu alanları doldurun. Aşağıdaki alanları ayarlayın:
- Etiket = {herhangi bir metin}
- Referans adı = {herhangi bir metin}
- Project ID (Proje kimliği) = otomatik algılama
- Veri kümesi = Geçerli projede kullanılan BigQuery veri kümesi (ör. DATASET_ID)
- Tablo = {table name}
- Ayrıntılı açıklama için Belgeler'i tıklayın. Tüm giriş bilgilerini doğrulamak için Doğrula düğmesini tıklayın. Yeşil "Hata bulunamadı" ifadesi, işlemin başarılı olduğunu gösterir.

- BigQuery Özellikleri'ni kapatmak için X düğmesini tıklayın.
6. Toplu veri ardışık düzeni oluşturma
Bir işlem hattındaki tüm düğümleri bağlama
- Kaynak düğümün sağ kenarındaki bağlantı okunu (>) sürükleyip hedef düğümün sol kenarına bırakın.
- Bir işlem hattında, giriş dosyalarını aynı GCS Kaynak düğümünden alan birden fazla dal olabilir.

- Ardışık düzeni adlandırın.
Bu kadar basit. İlk toplu veri ardışık düzeninizi oluşturdunuz. Ardışık düzeni dağıtabilir ve çalıştırabilirsiniz.
Ardışık düzen uyarılarını e-posta ile gönderme (isteğe bağlı)
Pipeline Alert SendEmail özelliğini kullanmak için yapılandırmada sanal makine örneğinden posta göndermek üzere bir posta sunucusunun ayarlanması gerekir. Daha fazla bilgi için aşağıdaki referans bağlantısına bakın:
Örnekten e-posta gönderme | Compute Engine Dokümanları
Bu codelab'de, aşağıdaki adımları uygulayarak Mailgun üzerinden bir posta aktarıcı hizmeti ayarlıyoruz:
- Mailgun ile hesap oluşturmak ve e-posta geçiş hizmetini yapılandırmak için Sending email with Mailgun | Compute Engine Documentation (Mailgun ile e-posta gönderme | Compute Engine Dokümanları) başlıklı makaledeki talimatları uygulayın. Ek değişiklikler aşağıda verilmiştir.
- Tüm alıcıların e-posta adreslerini Mailgun'ın yetkili listesine ekleyin. Bu listeyi Mailgun> Gönderme> Genel Bakış seçeneğinde bulabilirsiniz.


Alıcılar, support@mailgun.net adresinden gönderilen e-postada "Kabul Ediyorum"u tıkladığında e-posta adresleri, kanal uyarı e-postalarını almak için yetkili listesine kaydedilir.

- "Başlamadan önce" bölümünün 3. adımı: Aşağıdaki gibi bir güvenlik duvarı kuralı oluşturun:

- "Postfix ile Mailgun'ı posta aktarıcı olarak yapılandırma" başlıklı makalenin 3. adımı. Talimatlarda belirtildiği gibi Yalnızca Yerel yerine İnternet Sitesi veya Akıllı ana makineyle internet'i seçin.

- "Postfix ile Mailgun'ı posta aktarıcı olarak yapılandırma" başlıklı makalenin 4. adımı. mynetworks'ün sonuna 10.128.0.0 /9 eklemek için vi/etc/postfix/main.cf dosyasını düzenleyin.

- Varsayılan smtp'yi (25) 587 numaralı bağlantı noktasına değiştirmek için vi /etc/postfix/master.cf dosyasını düzenleyin.

- Data Fusion Studio'nun sağ üst köşesinde Yapılandır'ı tıklayın. İşlem hattı uyarısı'nı ve Uyarılar penceresini açmak için + düğmesini tıklayın. SendEmail'i seçin.

- E-posta yapılandırma formunu doldurun. Her uyarı türü için Çalıştırma Koşulu açılır listesinden tamamlama, başarılı veya başarısız'ı seçin. İş Akışı Jetonunu Dahil Et = yanlış ise yalnızca İleti alanındaki bilgiler gönderilir. Include Workflow Token = true ise Message alanındaki bilgiler ve Workflow Token ayrıntılı bilgileri gönderilir. Protokol için küçük harf kullanmanız gerekir. Gönderen için şirket e-posta adresiniz dışında herhangi bir "sahte" e-posta adresi kullanma.

7. Ardışık Düzeni Yapılandırma, Dağıtma, Çalıştırma/Planlama

- Data Fusion Studio'nun sağ üst köşesinde Yapılandır'ı tıklayın. Motor Yapılandırması için Spark'ı seçin. Yapılandır penceresinde Kaydet'i tıklayın.

- Verileri önizlemek için Önizleme'yi, önceki pencereye dönmek için tekrar **Önizleme**'yi tıklayın. Ayrıca, işlem hattını önizleme modunda da **çalıştırabilirsiniz**.

- Günlükleri görüntülemek için Günlükler'i tıklayın.
- Tüm değişiklikleri kaydetmek için Kaydet'i tıklayın.
- Yeni bir işlem hattı oluştururken kaydedilmiş işlem hattı yapılandırmasını içe aktarmak için İçe aktar'ı tıklayın.
- Ardışık düzen yapılandırmasını dışa aktarmak için Dışa aktar'ı tıklayın.
- İşlem hattını dağıtmak için Dağıt'ı tıklayın.
- Dağıtım tamamlandıktan sonra Çalıştır'ı tıklayın ve işlem hattının tamamlanmasını bekleyin.

- İşlemler düğmesi altından Kopyala'yı seçerek işlem hattını kopyalayabilirsiniz.
- İşlemler düğmesi altındaki Dışa aktar'ı seçerek boru hattı yapılandırmasını dışa aktarabilirsiniz.
- Gerekirse ardışık düzen tetikleyicilerini ayarlamak için Studio penceresinin sol veya sağ kenarındaki Gelen tetikleyiciler veya Giden tetikleyiciler'i tıklayın.
- İşlem hattının düzenli olarak çalıştırılmasını ve verilerin yüklenmesini planlamak için Zamanla'yı tıklayın.

- Özet bölümünde, çalıştırma geçmişi, kayıtlar, hata günlükleri ve uyarılarla ilgili grafikler gösterilir.
8. Doğrulama
- Validate işlem hattı başarıyla yürütüldü.

- BigQuery veri kümesinde tüm tabloların olup olmadığını doğrulayın.
bq ls $PROJECT_ID:$DATASET_ID
tableId Type Labels Time Partitioning
----------------- ------- -------- -------------------
Allergies TABLE
Careplans TABLE
Conditions TABLE
Encounters TABLE
Imaging_Studies TABLE
Immunizations TABLE
Medications TABLE
Observations TABLE
Organizations TABLE
Patients TABLE
Procedures TABLE
Providers TABLE
- Uyarı e-postaları alma (yapılandırılmışsa)
Sonuçları görüntüleme
İşlem hattı çalıştıktan sonra sonuçları görüntülemek için:
- BigQuery kullanıcı arayüzünde tabloyu sorgulayın. BIGQUERY KULLANICI ARAYÜZÜNE GİT
- Aşağıdaki sorguyu kendi proje adınız, veri kümeniz ve tablonuzla güncelleyin.

9. Temizleme
Bu eğiticide kullanılan kaynaklar için Google Cloud Platform hesabınızın ücretlendirilmesini istemiyorsanız şunları yapın:
Eğitimi tamamladıktan sonra, kotanızı kullanmamaları ve gelecekte faturalandırılmamaları için GCP'de oluşturduğunuz kaynakları temizleyebilirsiniz. Aşağıdaki bölümlerde bu kaynakların nasıl silineceği veya devre dışı bırakılacağı açıklanmaktadır.
BigQuery veri kümesini silme
Bu eğitimin bir parçası olarak oluşturduğunuz BigQuery veri kümesini silmek için bu talimatları uygulayın.
GCS paketini silme
Bu eğitimin bir parçası olarak oluşturduğunuz GCS paketini silmek için aşağıdaki talimatları uygulayın.
Cloud Data Fusion örneğini silme
Cloud Data Fusion örneğinizi silmek için aşağıdaki talimatları uygulayın.
Projeyi silme
Faturalandırılmanın önüne geçmenin en kolay yolu, eğitim için oluşturduğunuz projeyi silmektir.
Projeyi silmek için:
- GCP Console'da Projeler sayfasına gidin. PROJELER SAYFASINA GİTME
- Proje listesinde, silmek istediğiniz projeyi seçin ve Sil'i tıklayın.
- İletişim kutusunda proje kimliğini yazın ve projeyi silmek için Kapat'ı tıklayın.
10. Tebrikler
Tebrikler, Cloud Data Fusion'ı kullanarak BigQuery'ye sağlık hizmetleri verilerini alma ile ilgili kod laboratuvarını başarıyla tamamladınız.
Google Cloud Storage'dan BigQuery'ye CSV verileri aktardınız.
Sağlık hizmeti verilerini toplu olarak yüklemek, dönüştürmek ve maskelemek için veri entegrasyonu ardışık düzenini görsel olarak oluşturdunuz.
Artık Google Cloud Platform'da BigQuery ile sağlık hizmetleri veri analizi yolculuğunuza başlamak için gereken temel adımları biliyorsunuz.