
1. مقدمة
نظرة عامة
في هذا المختبر، ستستكشف سير عمل متعدد الوسائط في علم البيانات في BigQuery، وذلك في سياق سيناريو عقاري. ستبدأ بمجموعة بيانات أولية لعروض المنازل وصورها، ثم ستضيف إلى هذه البيانات ميزات مرئية باستخدام الذكاء الاصطناعي، وستنشئ نموذج تجميع لاكتشاف شرائح السوق المميّزة، وأخيرًا، ستنشئ أداة بحث مرئي فعّالة باستخدام عمليات التضمين المتجهة.
ستقارن سير العمل هذا المستند إلى لغة الاستعلامات البنيوية (SQL) بنهج حديث مستند إلى الذكاء الاصطناعي التوليدي باستخدام تجربة "وكيل تحليل البيانات" لإنشاء نموذج تجميع مستند إلى Python تلقائيًا من طلب نصي بسيط.
أهداف الدورة التعليمية
- إعداد مجموعة بيانات أولية خاصة ببطاقات بيانات العقارات لتحليلها من خلال هندسة الخصائص.
- تحسين بطاقات بيانات الفنادق من خلال استخدام وظائف الذكاء الاصطناعي في BigQuery لتحليل صور المنازل بحثًا عن الميزات المرئية الرئيسية
- إنشاء وتقييم نموذج متوسطات تصنيفية باستخدام تعلُّم الآلة في BigQuery (BQML) لتقسيم العقارات إلى مجموعات متميّزة
- أتمِت عملية إنشاء النماذج باستخدام "وكيل علوم البيانات" لإنشاء نموذج تجميع باستخدام Python.
- إنشاء تضمينات لصور المنازل من أجل تشغيل أداة بحث مرئية، والعثور على منازل مشابهة باستخدام طلبات بحث نصية أو صور
المتطلبات الأساسية
قبل بدء هذا الدرس التطبيقي، يجب أن تكون على دراية بما يلي:
- معرفة أساسية بلغة SQL ولغة البرمجة Python
- تشغيل رمز Python البرمجي في دفتر Jupyter
2. قبل البدء
إنشاء مشروع على Google Cloud
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع
تفعيل واجهات برمجة التطبيقات باستخدام Cloud Shell
Cloud Shell هي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بالأدوات اللازمة.
- انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud":

- بعد الاتصال بـ Cloud Shell، نفِّذ الأمر التالي للتحقّق من مصادقتك في Cloud Shell:
gcloud auth list
- نفِّذ الأمر التالي للتأكّد من إعداد مشروعك لاستخدامه مع gcloud:
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
تفعيل واجهات برمجة التطبيقات
- نفِّذ الأمر التالي لتفعيل جميع واجهات برمجة التطبيقات والخدمات المطلوبة:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- عند تنفيذ الأمر بنجاح، من المفترض أن تظهر لك رسالة مشابهة للرسالة الموضّحة أدناه:
Operation "operations/..." finished successfully.
- اخرج من Cloud Shell.
3- فتح "دفتر ملاحظات Lab" في BigQuery Studio
التنقّل في واجهة المستخدم:
- في Google Cloud Console، انتقِل إلى قائمة التنقّل > BigQuery.
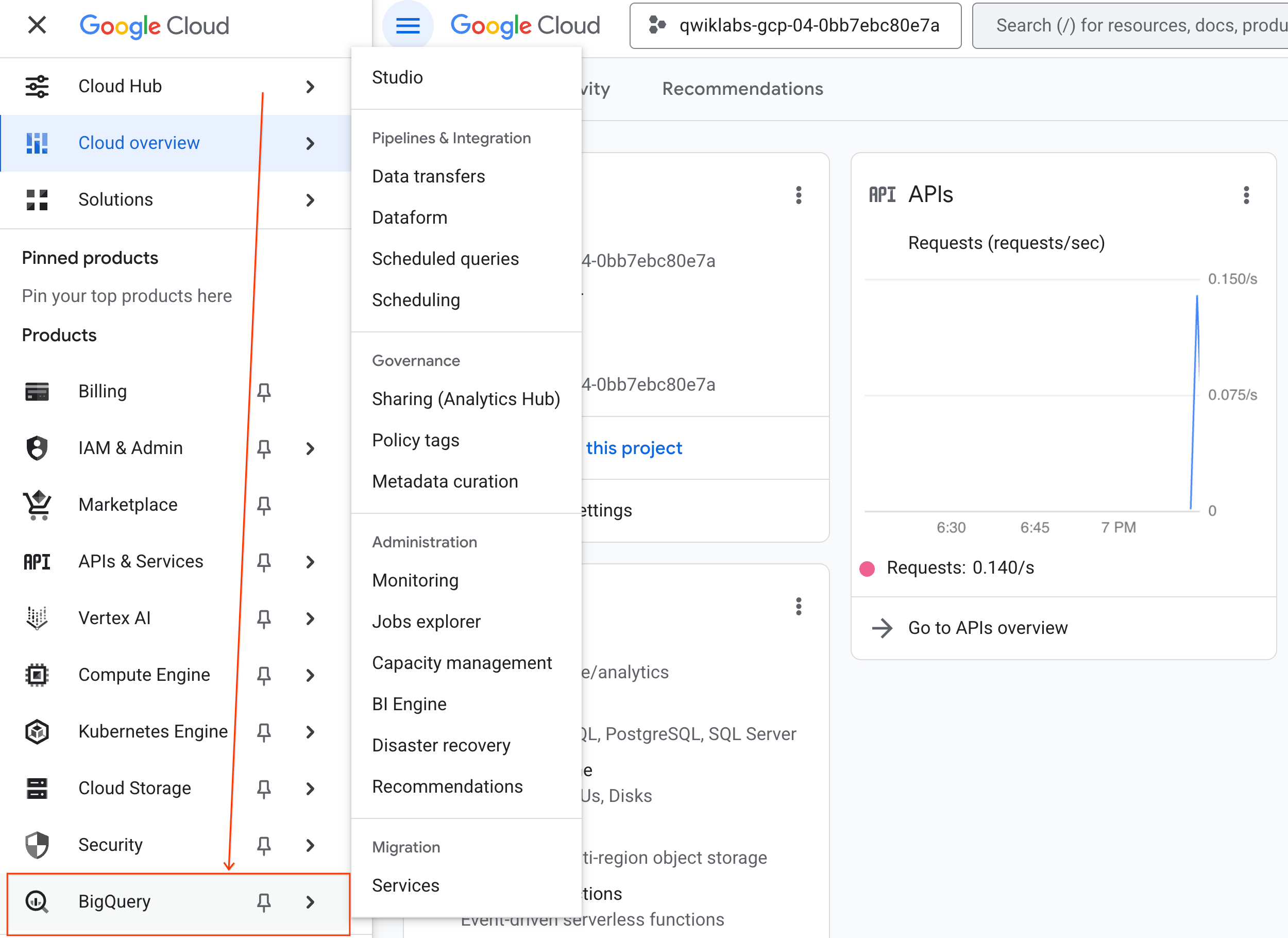
- في لوحة BigQuery Studio، انقر على زر السهم المتّجه للأسفل في القائمة المنسدلة، ومرِّر مؤشر الماوس فوق دفتر الملاحظات، ثم انقر على تحميل.
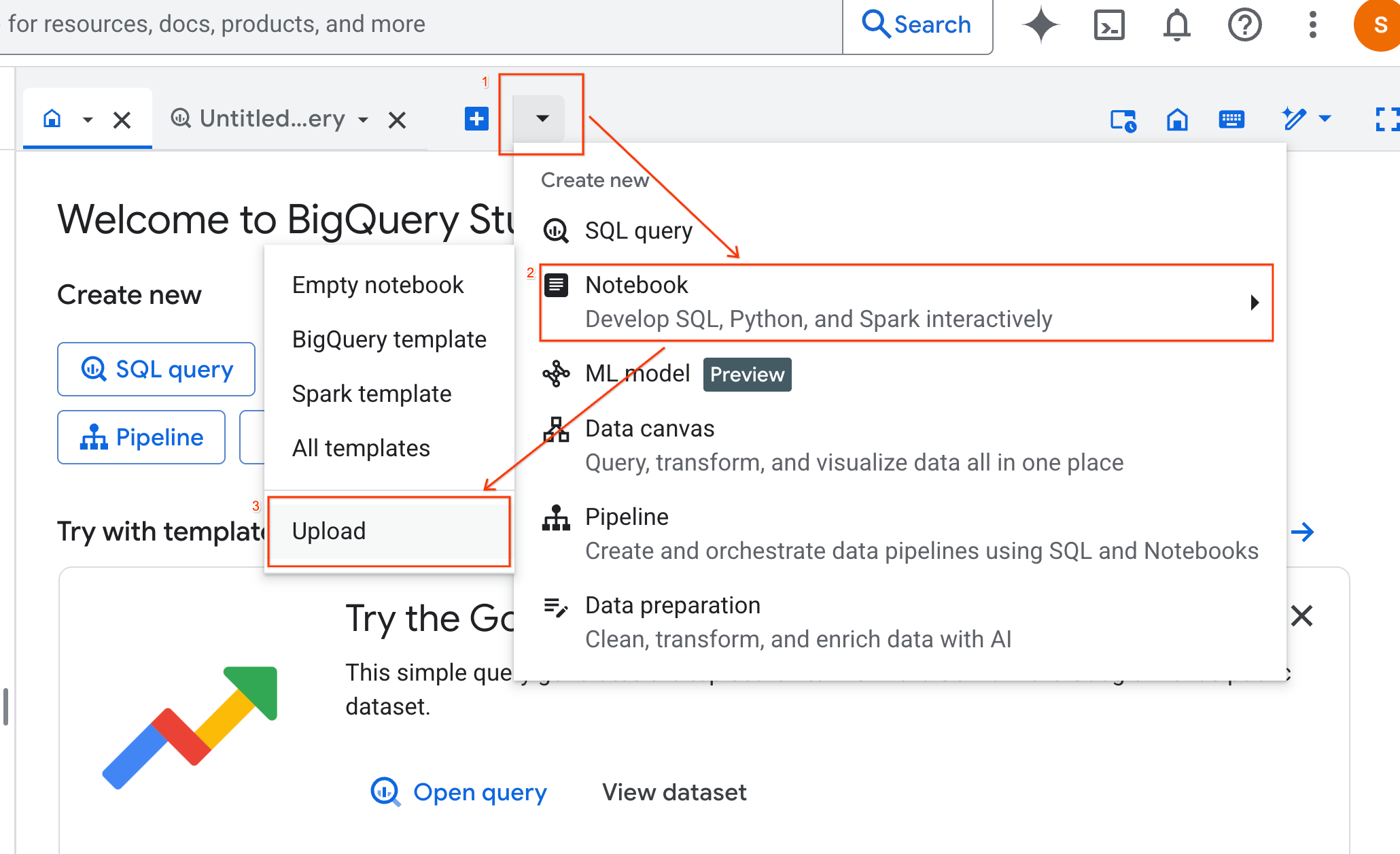
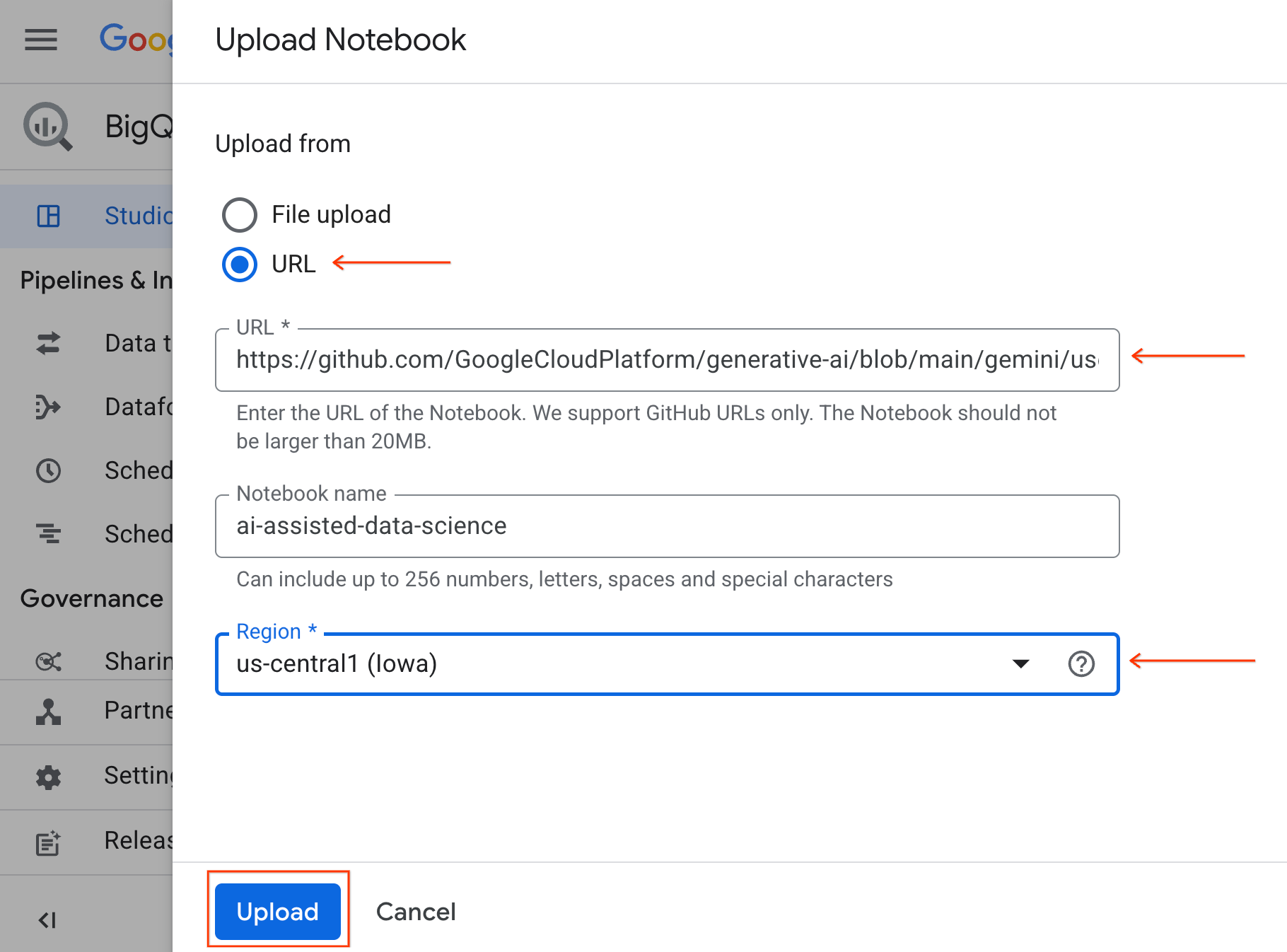
- انقر على زر الاختيار عنوان URL، وأدخِل عنوان URL التالي:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- اضبط المنطقة على
us-central1وانقر على تحميل.
- لفتح دفتر الملاحظات، انقر على السهم المتّجه للأسفل في جزء المستكشف الذي يحتوي على رقم تعريف مشروعك. بعد ذلك، انقر على القائمة المنسدلة دفاتر الملاحظات. انقر على دفتر الملاحظات
ai-assisted-data-science.
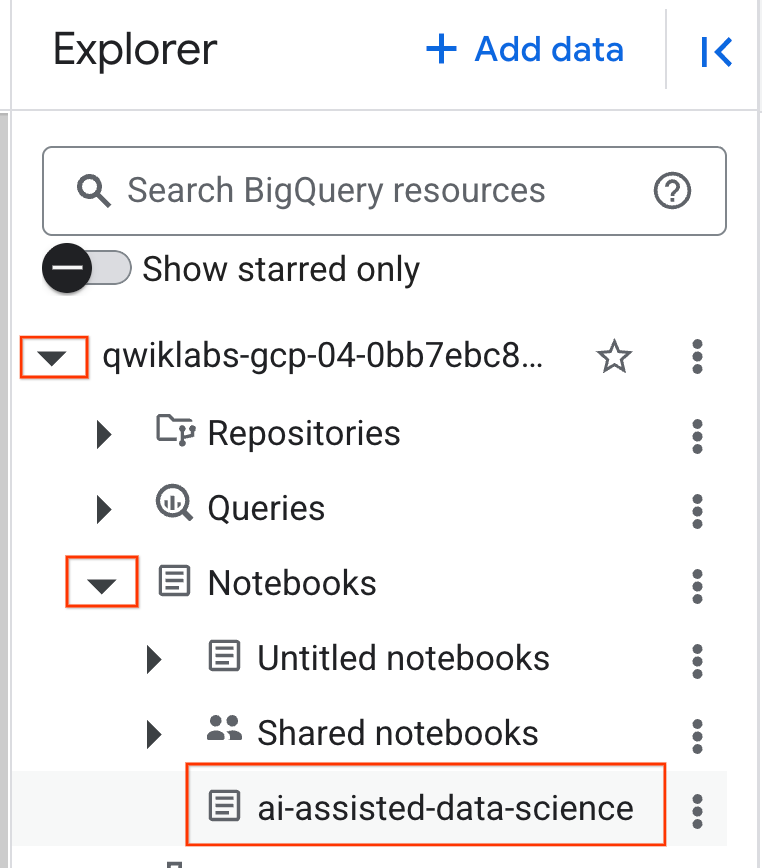
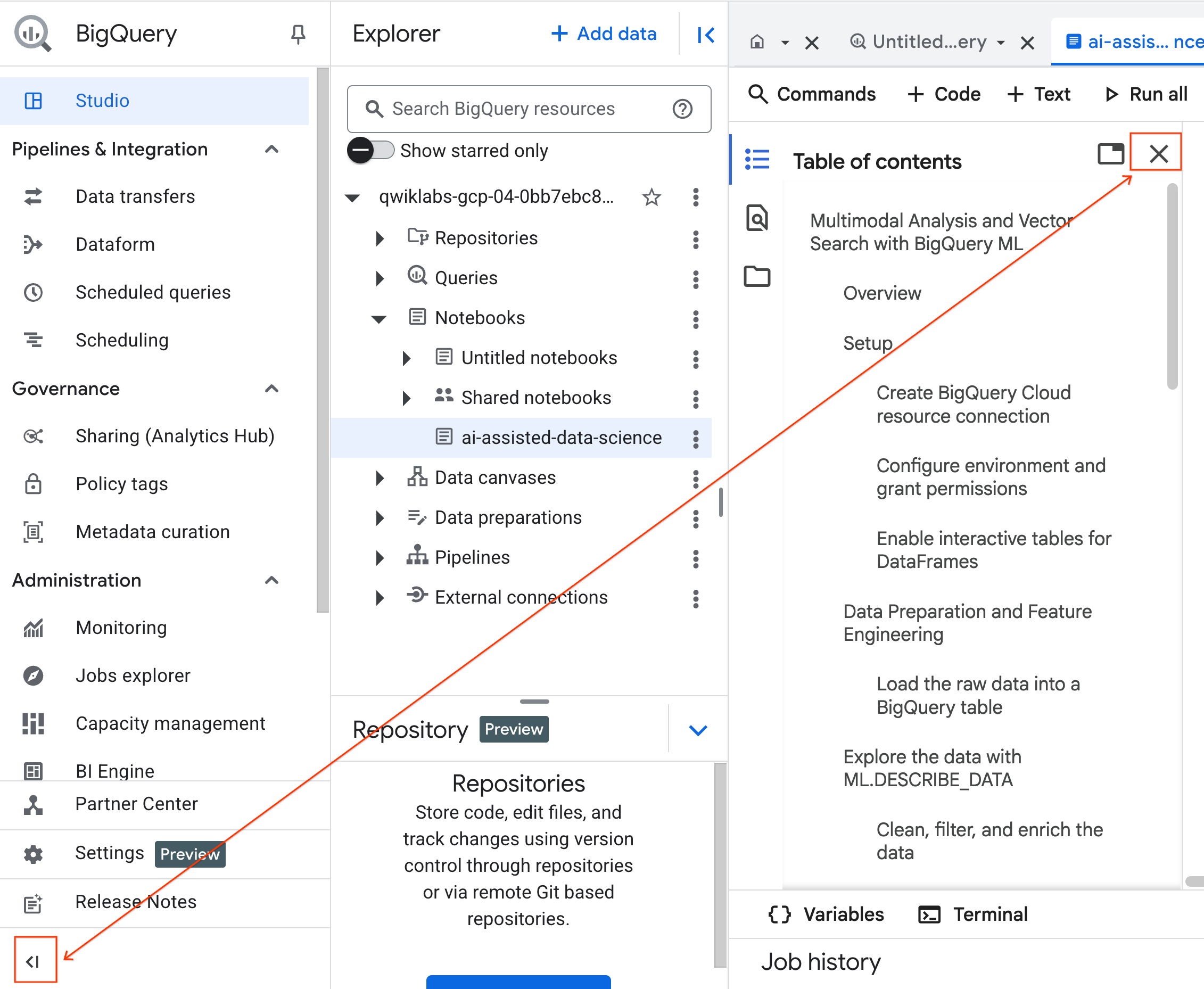
- (اختياري) يمكنك تصغير قائمة التنقّل في BigQuery وجدول المحتويات الخاص بدفتر الملاحظات لتوفير مساحة أكبر.
4. الاتصال ببيئة تشغيل وتنفيذ رمز الإعداد
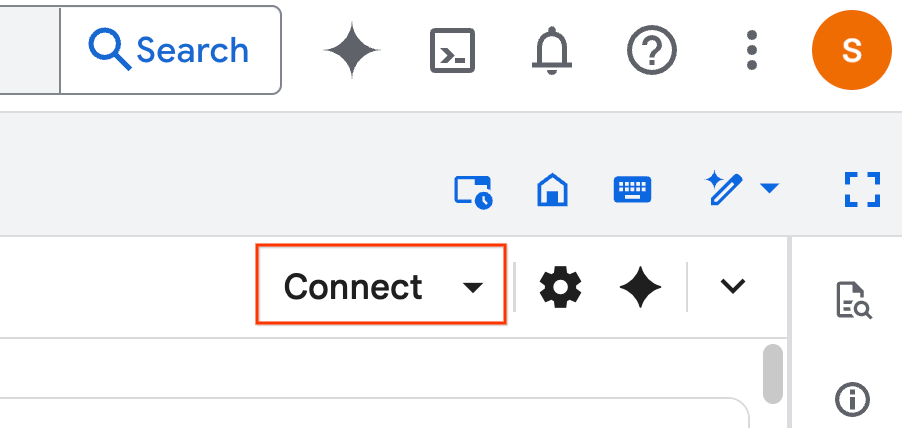
- انقر على ربط. إذا ظهرت نافذة منبثقة، امنح Colab Enterprise الإذن باستخدام حسابك. سيتم ربط ورقة الملاحظات تلقائيًا بوقت تشغيل. قد يستغرق إكمال هذه العملية بضع دقائق.
- بعد إنشاء وقت التشغيل، سيظهر لك ما يلي:
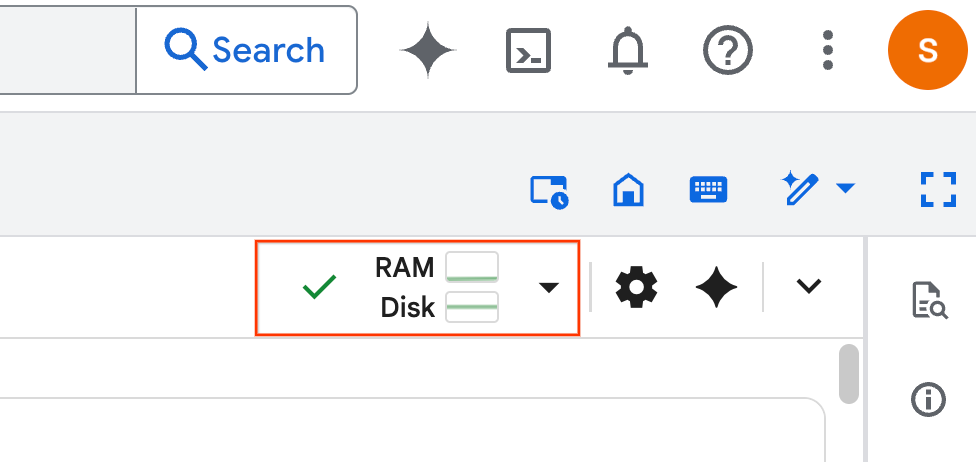
- ضمن دفتر الملاحظات، انتقِل إلى قسم الإعداد. انقر على الزر "تشغيل" بجانب الخلايا المخفية. يؤدي ذلك إلى إنشاء بعض الموارد اللازمة للمختبر في مشروعك. قد تستغرق هذه العملية دقيقة واحدة حتى تكتمل. يمكنك الاطّلاع على الخلايا ضمن الإعداد في الوقت الحالي.
5- إعداد البيانات وهندسة الميزات
في هذا القسم، ستتعرّف على الخطوة الأولى المهمة في أي مشروع لعلم البيانات، وهي إعداد البيانات. تبدأ بإنشاء مجموعة بيانات BigQuery لتنظيم عملك، ثم تحميل بيانات العقارات / الإسكان الأولية من ملف CSV في Cloud Storage إلى جدول جديد.
بعد ذلك، ستحوّل هذه البيانات الأولية إلى جدول نظيف يتضمّن ميزات جديدة. ويشمل ذلك فلترة البيانات، وإنشاء ميزة property_age جديدة، وإعداد بيانات الصور للتحليل المتعدّد الوسائط.
6. تحسين المحتوى المتعدّد الوسائط باستخدام دوال الذكاء الاصطناعي
يمكنك الآن إثراء بياناتك باستخدام إمكانات الذكاء الاصطناعي التوليدي. في هذا القسم، ستستخدم وظائف الذكاء الاصطناعي المضمّنة في BigQuery لتحليل الصور لكل إعلان عن منزل.
من خلال ربط BigQuery بنموذج Gemini، يمكنك استخراج ميزات جديدة قيّمة من الصور (مثل ما إذا كان المكان المخصّص للاستئجار يقع بالقرب من المياه ووصف موجز للمنزل) مباشرةً باستخدام SQL.
7. تدريب النموذج باستخدام الخوارزمية التصنيفية
بعد إثراء مجموعة البيانات الجديدة، ستكون جاهزًا لإنشاء نموذج تعلُّم آلي. هدفكم هو تقسيم بيانات المنازل المعروضة للبيع إلى مجموعات مميّزة، ويمكنكم تحقيق ذلك من خلال تدريب نموذج تجميع استنادًا إلى متوسطات تصنيفية مباشرةً في BigQuery باستخدام BigQuery Machine Learning (BQML). كجزء من هذه الخطوة الواحدة، يمكنك أيضًا تسجيل النموذج في سجلّ نماذج الذكاء الاصطناعي في Agent Platform، ما يتيح استخدامه على الفور ضمن المنظومة المتكاملة الأوسع نطاقًا لعمليات تعلّم الآلة (MLOps) على Google Cloud.
للتأكّد من تسجيل النموذج بنجاح، يمكنك العثور عليه في "سجل نماذج منصة الوكيل" باتّباع الخطوات التالية:
- في Google Cloud Console، انقر على قائمة التنقّل (☰) في أعلى يمين الصفحة.
- انتقِل إلى قسم منصة الوكيل وانقر على النماذج.
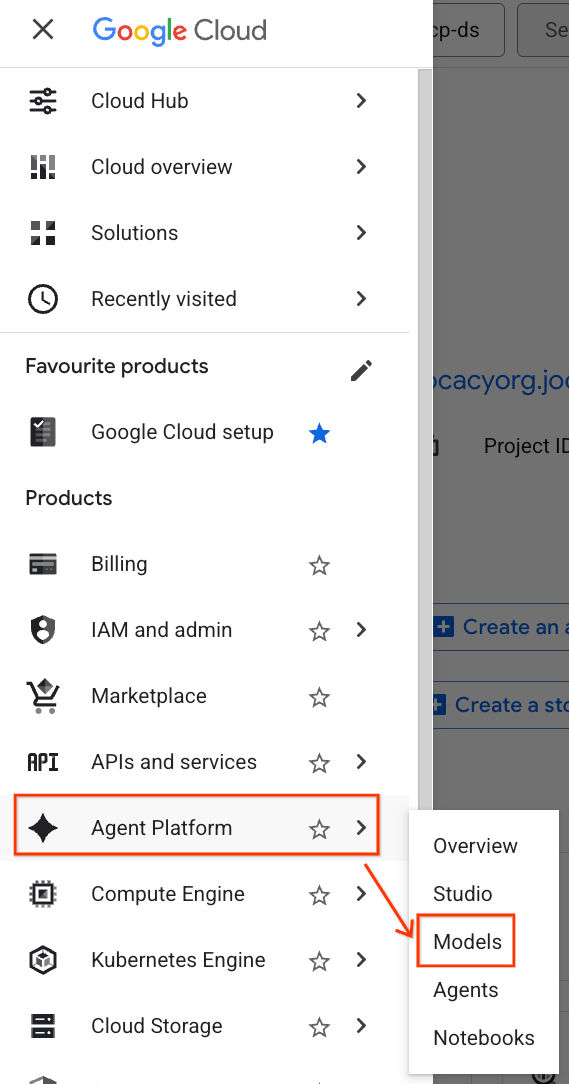
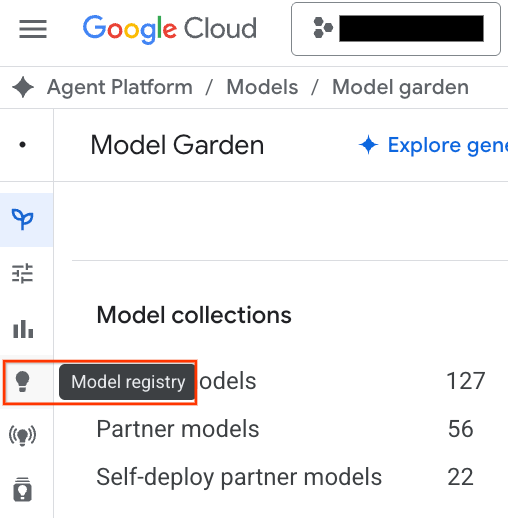
- انقر على الزر سجلّ النماذج المميّز في لقطة الشاشة.
- سيظهر نموذج BQML الخاص بك مُدرَجًا بجانب جميع النماذج المخصّصة الأخرى. في قائمة النماذج، ابحث عن النموذج المسمّى housing_clustering. يمكنك اتّخاذ الخطوة التالية والتفعيل في نقطة نهاية، ما يتيح لك استخدام النموذج لإجراء توقّعات في الوقت الفعلي على الإنترنت خارج بيئة BigQuery.
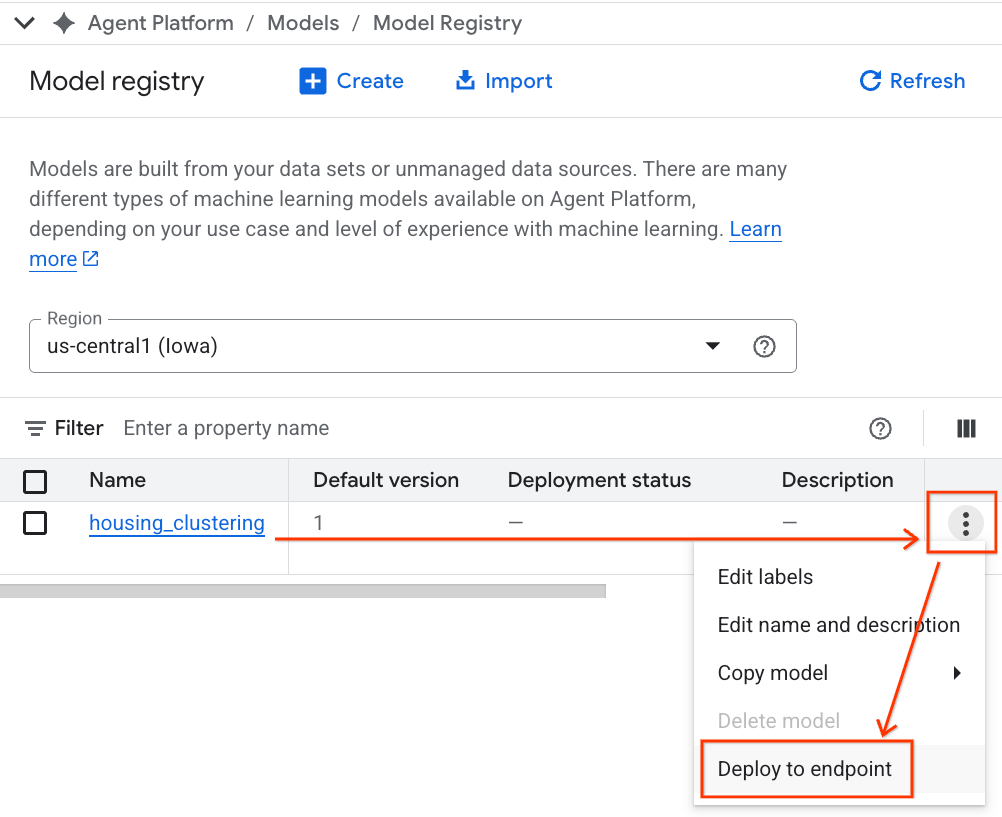
بعد استكشاف سجلّ النماذج، يمكنك الرجوع إلى ورقة ملاحظات Colab في BigQuery باتّباع الخطوات التالية:
- في قائمة التنقّل (☰)، انتقِل إلى BigQuery > Studio.
- وسِّع القوائم في لوحة استكشاف للعثور على دفتر الملاحظات وفتحه.
8. تقييم النموذج والتنبؤ
بعد تدريب نموذجك، تتمثّل الخطوة التالية في فهم المجموعات التي أنشأها. في هذه الخطوة، يمكنك استخدام دوال BigQuery Machine Learning، مثل ML.EVALUATE وML.CENTROIDS، لتحليل جودة النموذج والخصائص المحدّدة لكل شريحة.
بعد ذلك، استخدِم ML.PREDICT لتعيين كل منزل إلى مجموعة. من خلال تنفيذ هذا الاستعلام باستخدام الأمر السحري %%bigquery df، يمكنك تخزين النتائج في Pandas DataFrame باسم df. ويجعل هذا البيانات متاحة على الفور للخطوات اللاحقة في Python. ويوضّح ذلك إمكانية التشغيل التفاعلي بين SQL وPython في Colab Enterprise.
9- عرض المجموعات وتفسيرها
بعد تحميل التوقعات في إطار بيانات، يمكنك إنشاء عروض مرئية لإضفاء الحيوية على البيانات. في هذا القسم، ستستخدم مكتبات بايثون الشائعة، مثل "مات بلوت ليب"، لاستكشاف الاختلافات بين شرائح السكن.
ستنشئ مخططات مربّعية ورسومًا بيانية شريطية لمقارنة الميزات الرئيسية بشكل مرئي، مثل السعر وعمر العقار، ما يسهّل بناء فهم بديهي لكل مجموعة.
10. إنشاء أوصاف للمجموعات باستخدام نماذج Gemini
على الرغم من أنّ الأشكال البيانية والمراكز الهندسية العددية فعّالة، يتيح لك الذكاء الاصطناعي التوليدي المضي قدمًا وإنشاء شخصيات وصفية غنية لكل شريحة سكنية. يساعدك ذلك في فهم ماهية المجموعات، بالإضافة إلى الجمهور الذي تمثله.
في هذا القسم، ستجمع أولاً متوسط الإحصاءات لكل مجموعة، مثل السعر والمساحة. بعد ذلك، ستمرّر هذه البيانات إلى طلب لنموذج Gemini. بعد ذلك، يمكنك توجيه النموذج للعمل كخبير في مجال العقارات وإنشاء ملخّص مفصّل، بما في ذلك الخصائص الرئيسية والمشتري المستهدف لكل شريحة. والنتيجة هي مجموعة من الأوصاف الواضحة التي يمكن للمستخدمين قراءتها، ما يجعل المجموعات مفهومة على الفور وقابلة للتنفيذ من قِبل فريق التسويق.
يمكنك تعديل الطلب كما تراه مناسبًا وتجربة النتائج.
11. أتمتة عملية النمذجة باستخدام "وكيل علم البيانات"
الآن، ستستكشف سير عمل بديلًا وفعّالاً. بدلاً من كتابة الرموز يدويًا، ستستخدم وكيل علوم البيانات المدمج لإنشاء سير عمل كامل لنموذج التجميع تلقائيًا من طلب واحد باللغة الطبيعية.
اتّبِع الخطوات التالية لإنشاء النموذج وتشغيله باستخدام الوكيل:
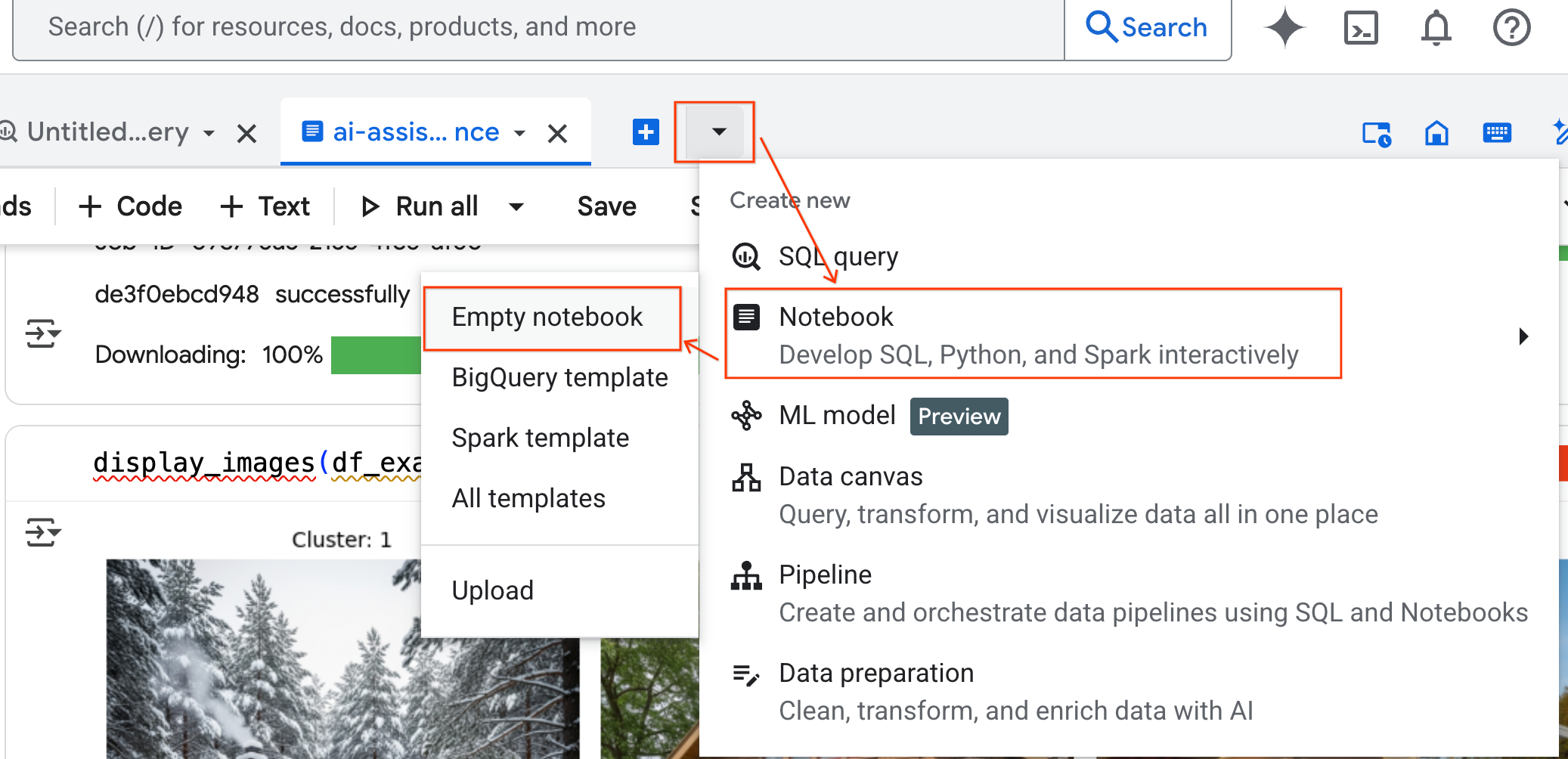
- في لوحة BigQuery Studio، انقر على زر السهم المتّجه للأسفل في القائمة المنسدلة، ومرِّر مؤشر الماوس فوق دفتر الملاحظات، ثم انقر على دفتر ملاحظات فارغ. يضمن ذلك عدم تداخل رمز الوكيل مع دفتر المختبر الأصلي.
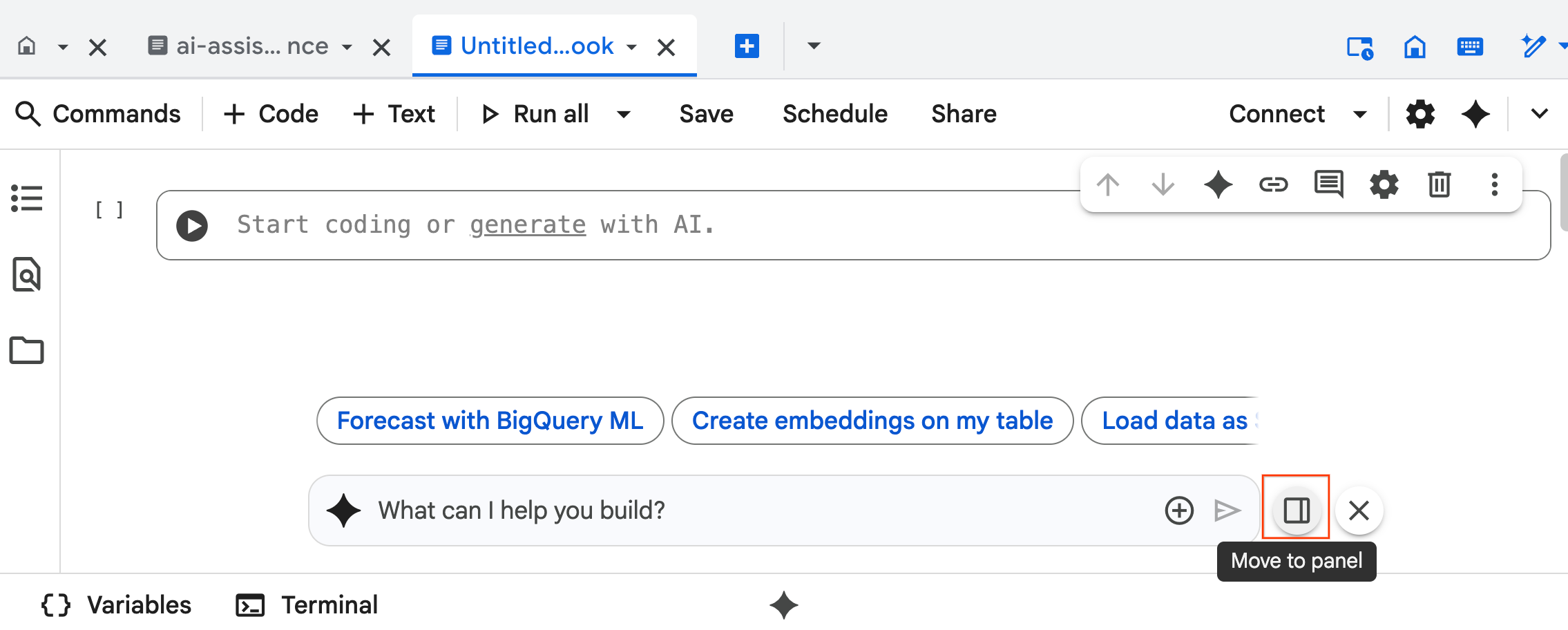
- تُفتح واجهة دردشة "وكيل علوم البيانات" في أسفل دفتر الملاحظات. انقر على الزر نقل إلى اللوحة لتثبيت المحادثة على الجانب الأيسر.
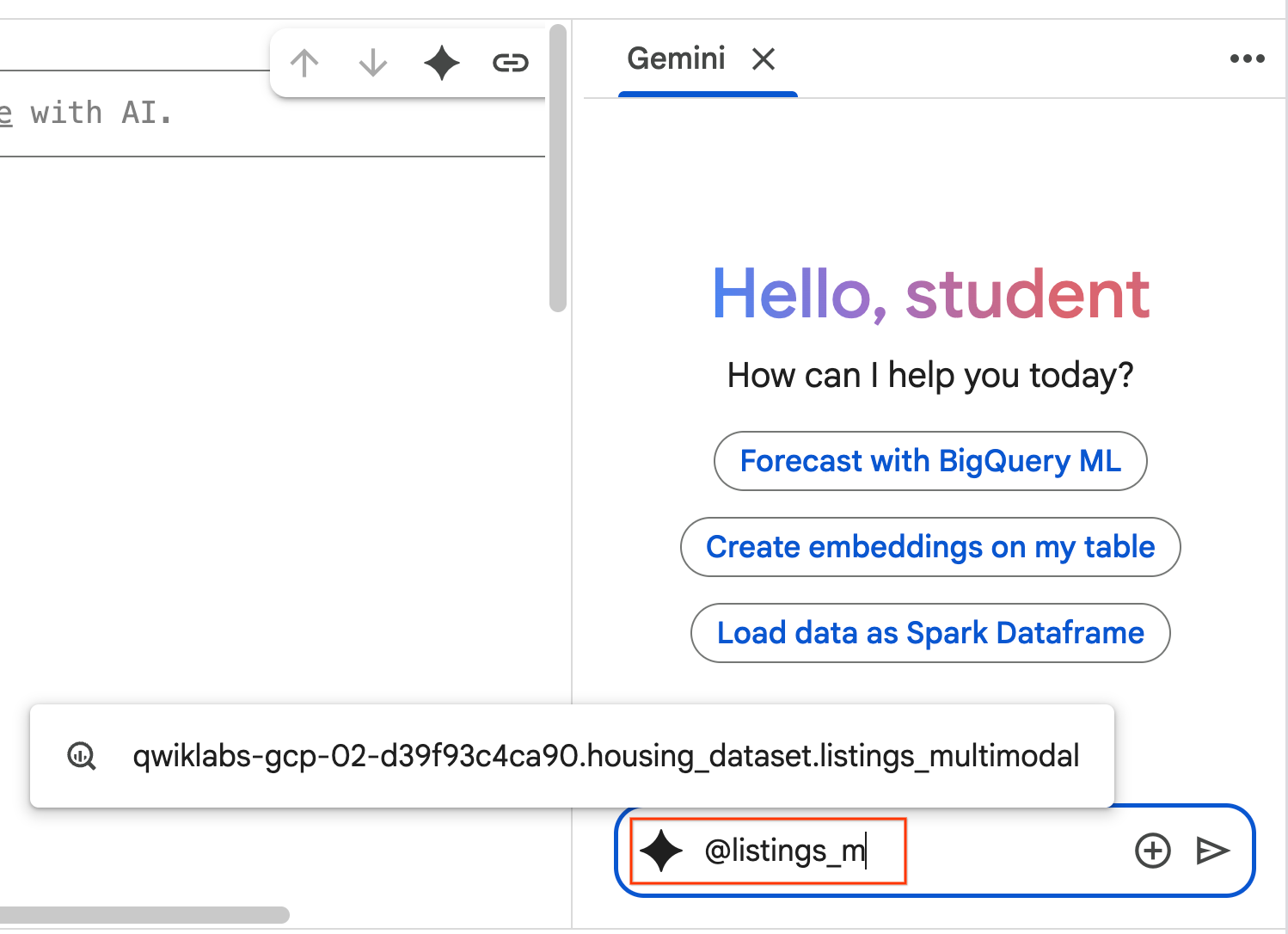
- ابدأ بكتابة
@listing_multimodalفي لوحة المحادثة وانقر على الجدول. يؤدي ذلك إلى ضبط جدولlistings_multimodalبشكلٍ صريح كسياق.
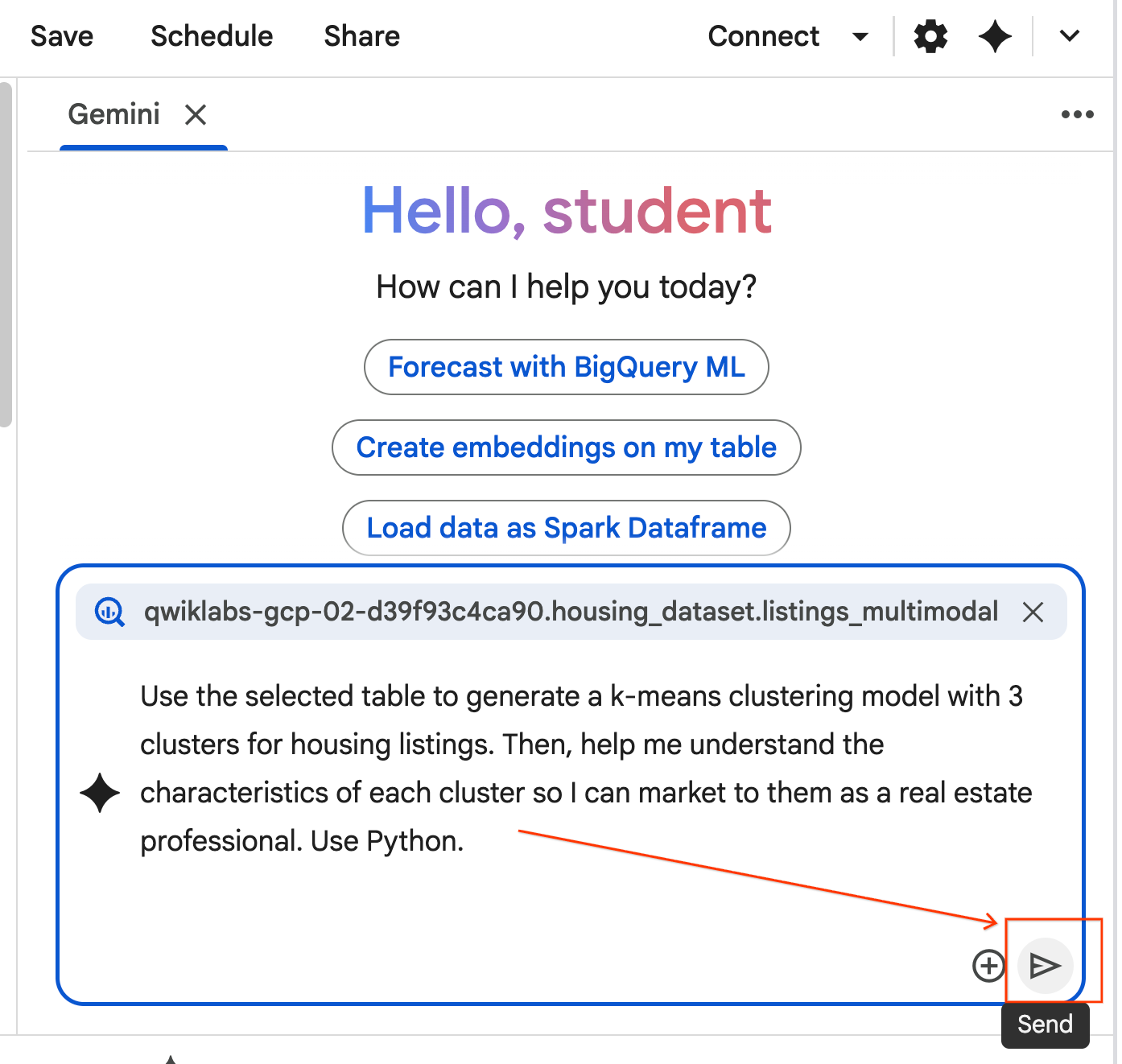
- انسخ الطلب أدناه وأدخِله في مربّع "محادثة مع الوكيل". بعد ذلك، انقر على إرسال لإرسال الطلب إلى "الوكيل".
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- سيفكّر الوكيل ويضع خطة. إذا كنت موافقًا على هذه الخطة، انقر على قبول وتنفيذ. سينشئ "الوكيل" رمز Python في خلية واحدة أو أكثر من الخلايا الجديدة.
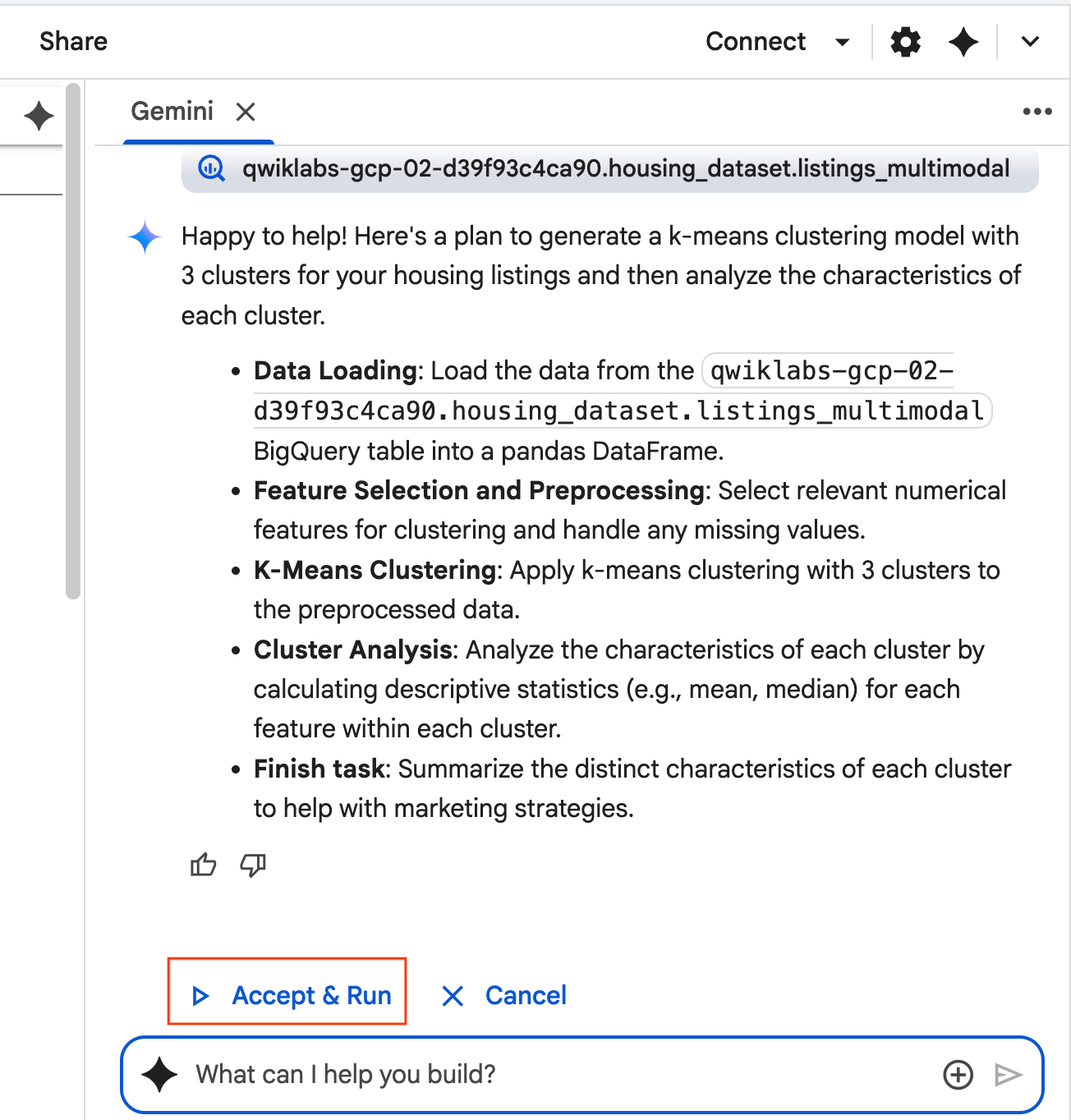
- يطلب منك "الوكيل" قبول كل مجموعة من الرموز البرمجية التي ينشئها وتشغيلها. يضمن ذلك إبقاء المستخدم على اطّلاع دائم على آخر الأخبار. يمكنك مراجعة الرمز أو تعديله ومتابعة كل خطوة إلى أن تنتهي.
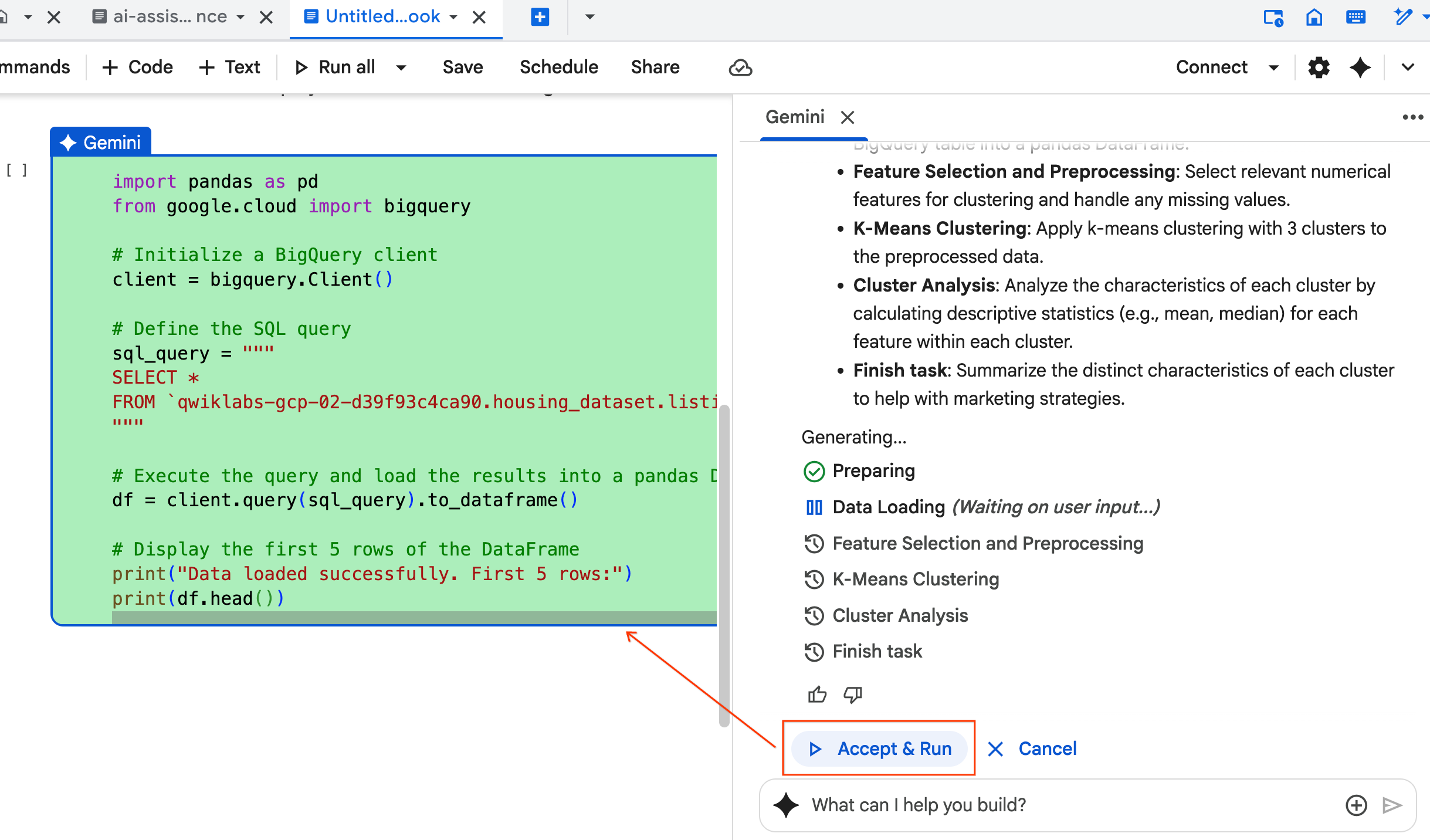
- بعد الانتهاء، ما عليك سوى إغلاق علامة تبويب دفتر الملاحظات الجديدة هذه والعودة إلى علامة التبويب الأصلية
ai-assisted-data-science.ipynbلمواصلة القسم الأخير من الدرس التطبيقي.
12. البحث المتعدد الوسائط باستخدام عمليات التضمين وVector Search
في هذا القسم الأخير، ستنفّذ البحث المتعدّد الوسائط مباشرةً في BigQuery. يتيح ذلك إجراء عمليات بحث سهلة، مثل العثور على منازل استنادًا إلى وصف نصي أو العثور على منازل تشبه صورة نموذجية.
تعمل هذه العملية أولاً عن طريق تحويل كل صورة منزل إلى تمثيل رقمي يُعرف باسم التضمين. تلتقط عملية التضمين المعنى الدلالي للصورة، ما يتيح لك العثور على عناصر مشابهة من خلال مقارنة المتجهات الرقمية الخاصة بها.
ستستخدم نموذج multimodalembedding لإنشاء هذه المتجهات لجميع بطاقات بياناتك. بعد إنشاء فهرس متّجه لتسريع عمليات البحث، يمكنك إجراء نوعَين من البحث عن التشابه: البحث من نص إلى صورة (للعثور على منازل تتطابق مع وصف) والبحث من صورة إلى صورة (للعثور على منازل تشبه صورة نموذجية).
ستُكمل كل ذلك في BigQuery، باستخدام دوالّ مثل ML.GENERATE_EMBEDDING لإنشاء التضمينات أو VECTOR_SEARCH للبحث عن التشابه.
13. تنظيف
لتنظيف جميع موارد Google Cloud المستخدَمة في هذا المشروع، يمكنك حذف مشروع على السحابة الإلكترونية.
بدلاً من ذلك، يمكنك حذف الموارد الفردية التي أنشأتها من خلال تشغيل الرمز التالي في خلية جديدة في دفتر الملاحظات:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
أخيرًا، يمكنك حذف دفتر الملاحظات نفسه:
- في جزء المستكشف في BigQuery Studio، وسِّع مشروعك وعُقدة دفاتر الملاحظات.
- انقر على النقاط الثلاث العمودية بجانب دفتر الملاحظات
ai-assisted-data-science. - اختَر حذف.
14. تهانينا!
تهانينا على إكمال Codelab.
المواضيع التي تناولناها
- إعداد مجموعة بيانات أولية خاصة ببطاقات بيانات العقارات لتحليلها من خلال هندسة الخصائص.
- تحسين بطاقات بيانات الفنادق من خلال استخدام وظائف الذكاء الاصطناعي في BigQuery لتحليل صور المنازل بحثًا عن الميزات المرئية الرئيسية
- إنشاء وتقييم نموذج متوسطات تصنيفية باستخدام BigQuery Machine Learning (BQML) لتقسيم المواقع إلى مجموعات مميزة
- أتمِت عملية إنشاء النماذج باستخدام "وكيل علوم البيانات" لإنشاء نموذج تجميع باستخدام Python.
- إنشاء تضمينات لصور المنازل من أجل تشغيل أداة بحث مرئية، والعثور على منازل مشابهة باستخدام طلبات بحث نصية أو صور