
1. Einführung
Übersicht
In diesem Lab sehen Sie sich einen multimodalen Data-Science-Workflow in BigQuery anhand eines Beispiels aus der Immobilienbranche an. Sie beginnen mit einem Rohdatensatz von Hausangeboten und den zugehörigen Bildern, reichern diese Daten mit KI an, um visuelle Merkmale zu extrahieren, erstellen ein Clustering-Modell, um unterschiedliche Marktsegmente zu ermitteln, und entwickeln schließlich ein leistungsstarkes visuelles Suchtool mit Vektoreinbettungen.
Sie vergleichen diesen SQL-nativen Workflow mit einem modernen, generativen KI-Ansatz, indem Sie den Data Science Agent verwenden, um automatisch ein Python-basiertes Clustering-Modell aus einem einfachen Text-Prompt zu generieren.
Lerninhalte
- Rohdatensatz mit Immobilienangeboten für die Analyse durch Feature Engineering vorbereiten.
- Einträge anreichern: Mit den KI-Funktionen von BigQuery können Sie Hausfotos auf wichtige visuelle Merkmale hin analysieren.
- Erstellen und bewerten Sie ein K-Means-Modell mit BigQuery Machine Learning (BQML), um Properties in verschiedene Cluster zu segmentieren.
- Modellerstellung automatisieren: Mit dem Data Science Agent können Sie ein Clustering-Modell mit Python generieren.
- Einbettungen für Hausbilder generieren, um ein Tool für die visuelle Suche zu ermöglichen, mit dem ähnliche Häuser mit Text- oder Bildabfragen gefunden werden können.
Vorbereitung
Für dieses Lab sollten Sie folgende Konzepte kennen:
- Grundlegende Kenntnisse der Programmierung mit SQL und Python
- Ausführen von Python-Code in einem Jupyter-Notebook
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
APIs mit Cloud Shell aktivieren
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und mit den erforderlichen Tools vorinstalliert ist.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren:

- Wenn Sie eine Verbindung zu Cloud Shell hergestellt haben, führen Sie diesen Befehl aus, um Ihre Authentifizierung in Cloud Shell zu überprüfen:
gcloud auth list
- Führen Sie den folgenden Befehl aus, um zu bestätigen, dass Ihr Projekt für die Verwendung mit gcloud konfiguriert ist:
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
APIs aktivieren
- Führen Sie den folgenden Befehl aus, um alle erforderlichen APIs und Dienste zu aktivieren:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- Bei erfolgreicher Ausführung des Befehls sollte eine Meldung wie die unten gezeigte angezeigt werden:
Operation "operations/..." finished successfully.
- Beenden Sie Cloud Shell.
3. Lab-Notebook in BigQuery Studio öffnen
Navigation auf der Benutzeroberfläche:
- Klicken Sie in der Google Cloud Console auf das Navigationsmenü > BigQuery.
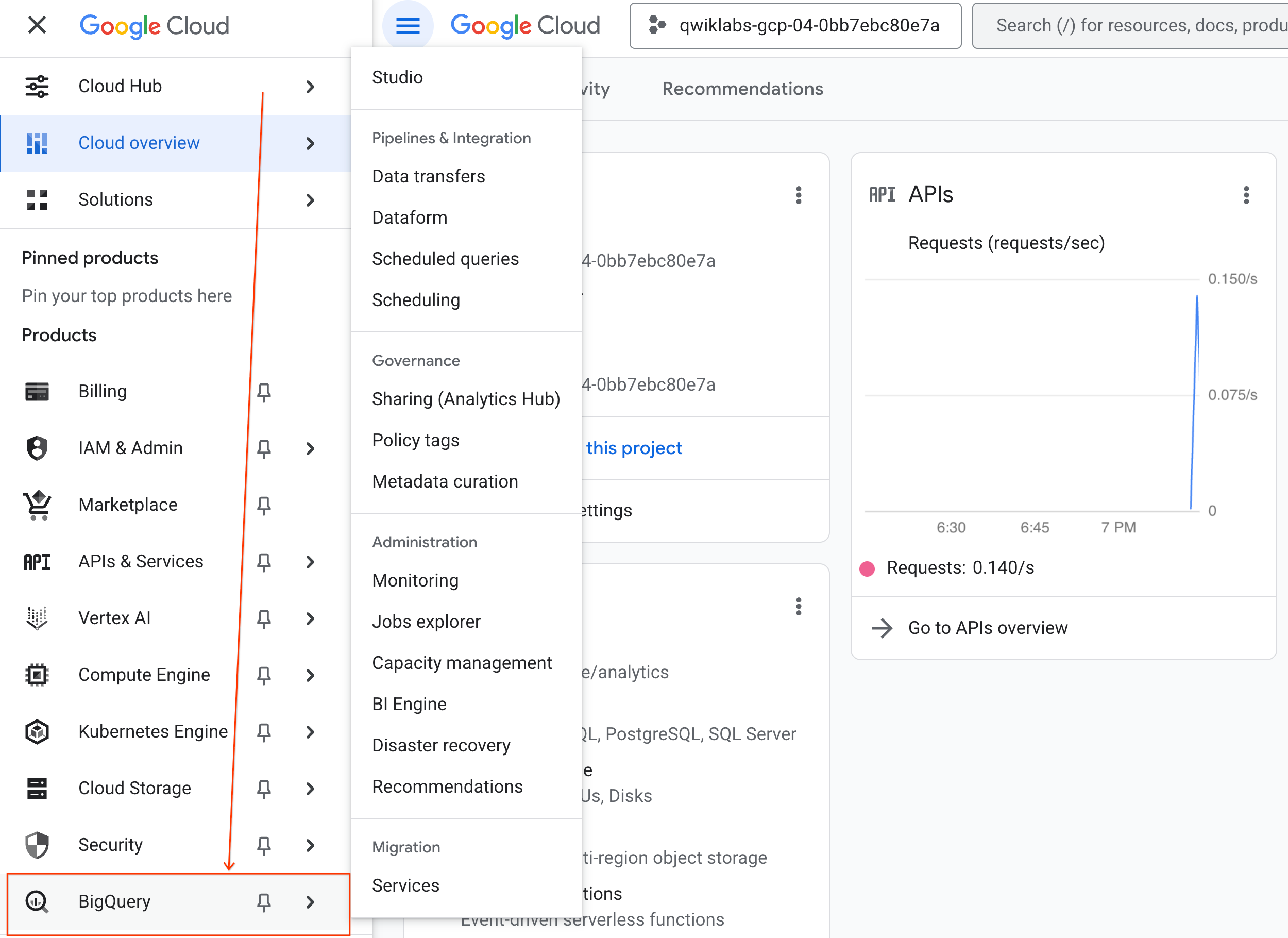
- Klicken Sie im Bereich BigQuery Studio auf den Drop-down-Pfeil, bewegen Sie den Mauszeiger auf Notebook und wählen Sie Hochladen aus.
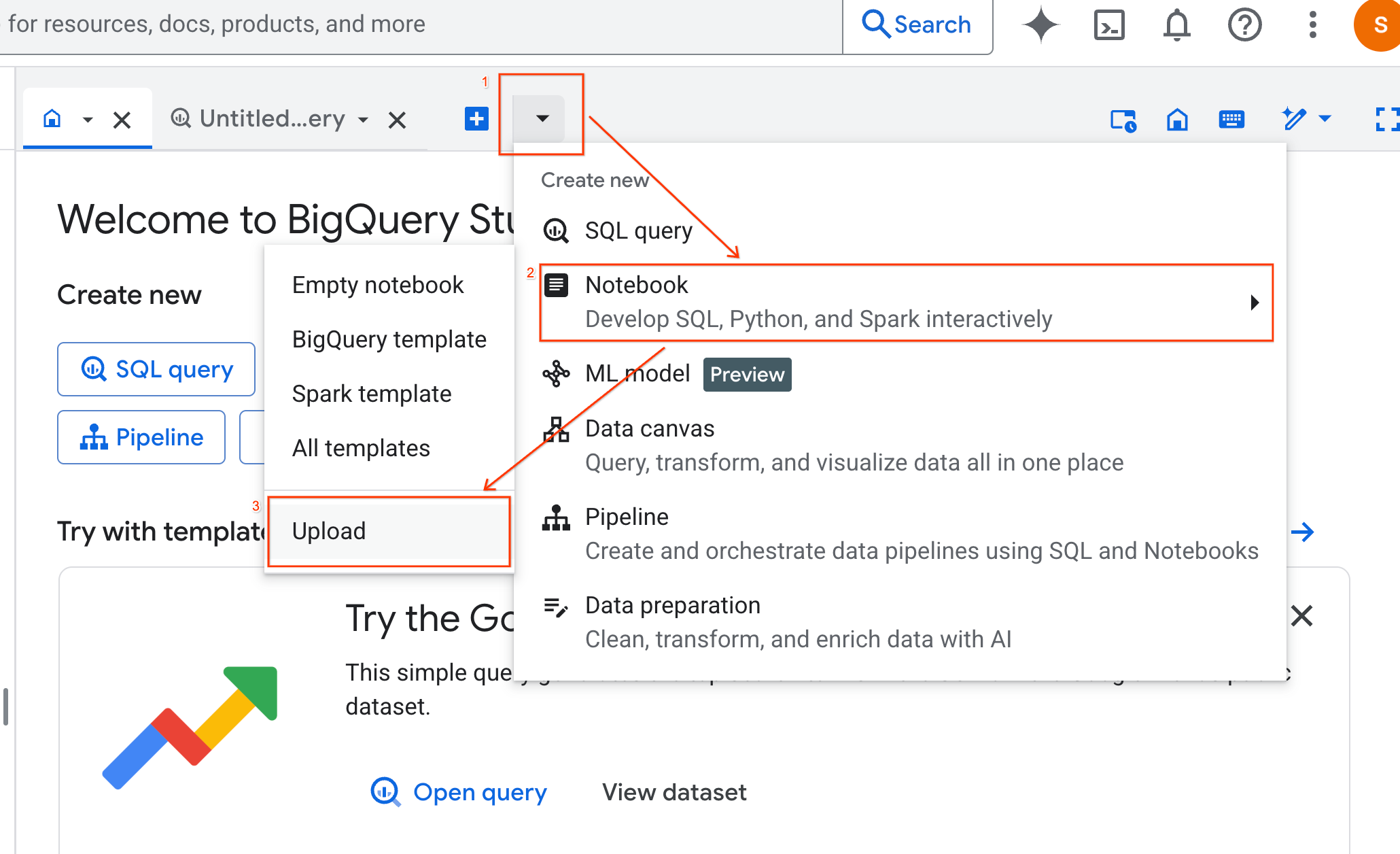
- Wählen Sie das Optionsfeld URL aus und geben Sie die folgende URL ein:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- Legen Sie die Region auf
us-central1fest und klicken Sie auf Hochladen.
- Klicken Sie zum Öffnen des Notebooks im Bereich Explorer, der Ihre Projekt-ID enthält, auf den Drop-down-Pfeil. Klicken Sie dann auf das Drop-down-Menü für Notebooks. Klicken Sie auf das Notebook
ai-assisted-data-science.
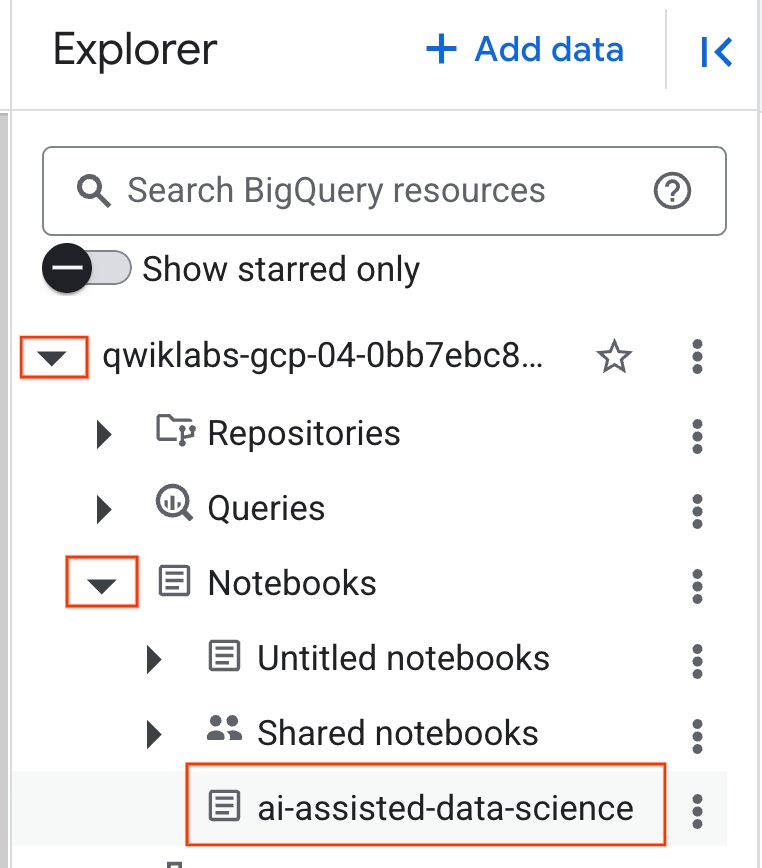
- (Optional) Sie können das BigQuery-Navigationsmenü und das Inhaltsverzeichnis des Notebooks minimieren, um mehr Platz zu schaffen.
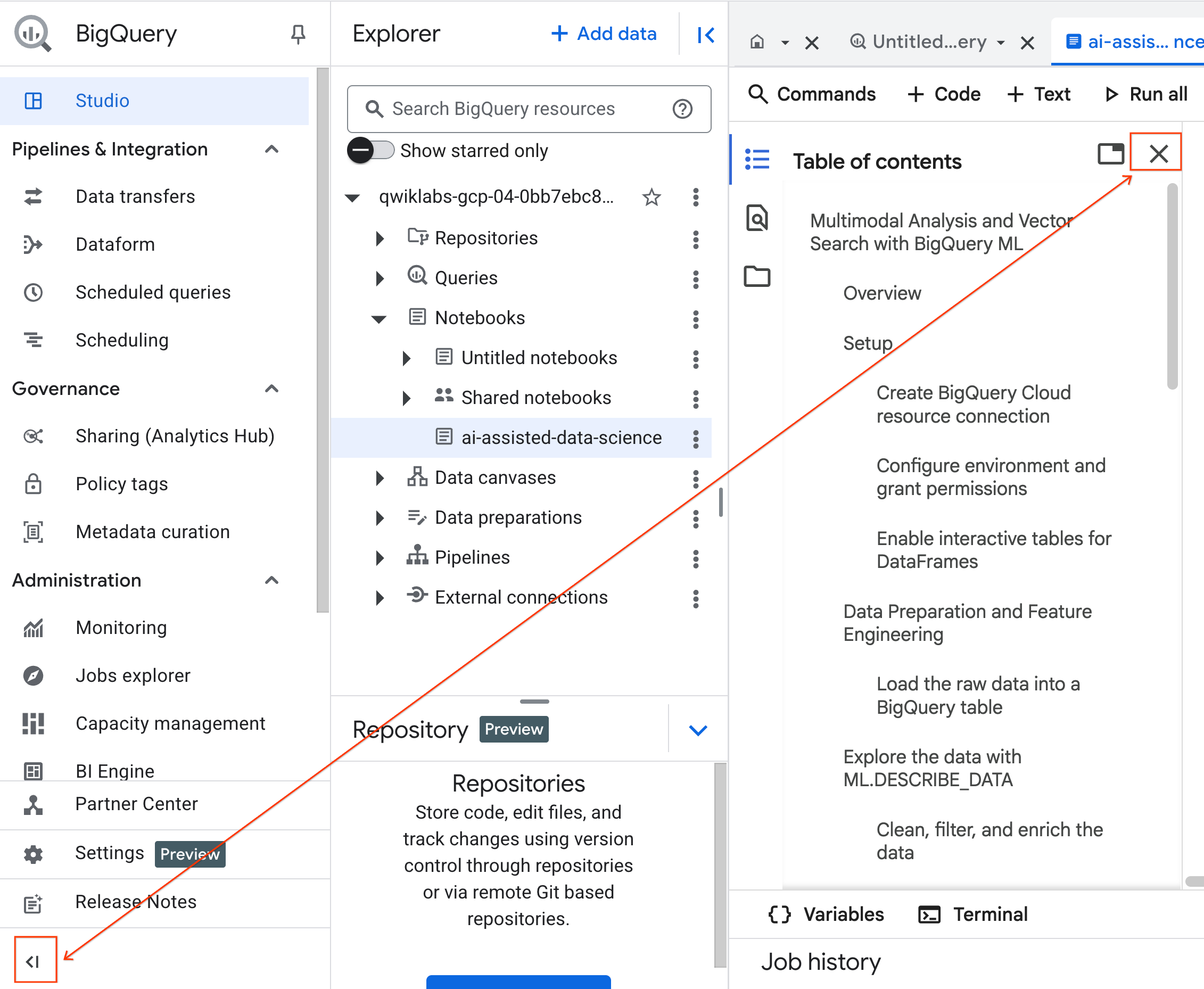
4. Mit einer Laufzeit verbinden und Einrichtungscode ausführen
- Klicken Sie auf Verbinden. Wenn ein Pop-up angezeigt wird, autorisieren Sie Colab Enterprise mit Ihrem Nutzerkonto. Ihr Notebook wird automatisch mit einer Laufzeit verbunden. Dies kann einige Minuten dauern.
- Sobald die Laufzeitumgebung eingerichtet ist, wird Folgendes angezeigt:
- Scrollen Sie im Notebook zum Abschnitt Einrichtung. Klicken Sie neben den ausgeblendeten Zellen auf den Button „Ausführen“. Dadurch werden einige für das Lab erforderliche Ressourcen in Ihrem Projekt erstellt. Dieser Vorgang kann eine Minute dauern. Sehen Sie sich in der Zwischenzeit gerne die Zellen unter Einrichtung an.
5. Datenvorbereitung und Feature Engineering
In diesem Abschnitt durchlaufen Sie den ersten wichtigen Schritt in jedem Data-Science-Projekt: die Vorbereitung Ihrer Daten. Zuerst erstellen Sie ein BigQuery-Dataset, um Ihre Arbeit zu organisieren. Anschließend laden Sie die Rohdaten zu Immobilien und Wohnungen aus einer CSV-Datei in Cloud Storage in eine neue Tabelle.
Anschließend transformieren Sie diese Rohdaten in eine bereinigte Tabelle mit neuen Features. Dazu gehören das Filtern der Einträge, das Erstellen eines neuen property_age-Features und das Vorbereiten der Bilddaten für die multimodale Analyse.
6. Multimodale Anreicherung mit KI-Funktionen
Als Nächstes reichern Sie Ihre Daten mit generativer KI an. In diesem Abschnitt verwenden Sie die integrierten KI-Funktionen von BigQuery, um die Bilder für jedes Hausangebot zu analysieren.
Wenn Sie BigQuery mit einem Gemini-Modell verbinden, können Sie direkt mit SQL neue, wertvolle Funktionen aus Bildern extrahieren, z. B. ob sich ein Grundstück in der Nähe von Wasser befindet, und eine kurze Beschreibung des Hauses.
7. Modelltraining mit K-Means-Clustering
Mit dem neu angereicherten Dataset können Sie jetzt ein Machine-Learning-Modell erstellen. Ihr Ziel ist es, die Hausangebote in verschiedene Gruppen zu segmentieren. Dazu trainieren Sie ein K-Means-Clustering-Modell direkt in BigQuery mit BigQuery Machine Learning (BQML). In diesem einzigen Schritt registrieren Sie das Modell auch in der Agent Platform AI Model Registry, sodass es sofort im gesamten MLOps-Ökosystem in Google Cloud verfügbar ist.
So prüfen Sie, ob Ihr Modell erfolgreich registriert wurde: Sie finden es in der Agent Platform Model Registry, indem Sie die folgenden Schritte ausführen:
- Klicken Sie in der Google Cloud Console links oben auf das Navigationsmenü (☰).
- Scrollen Sie zum Bereich Agent Platform und klicken Sie auf Models (Modelle).
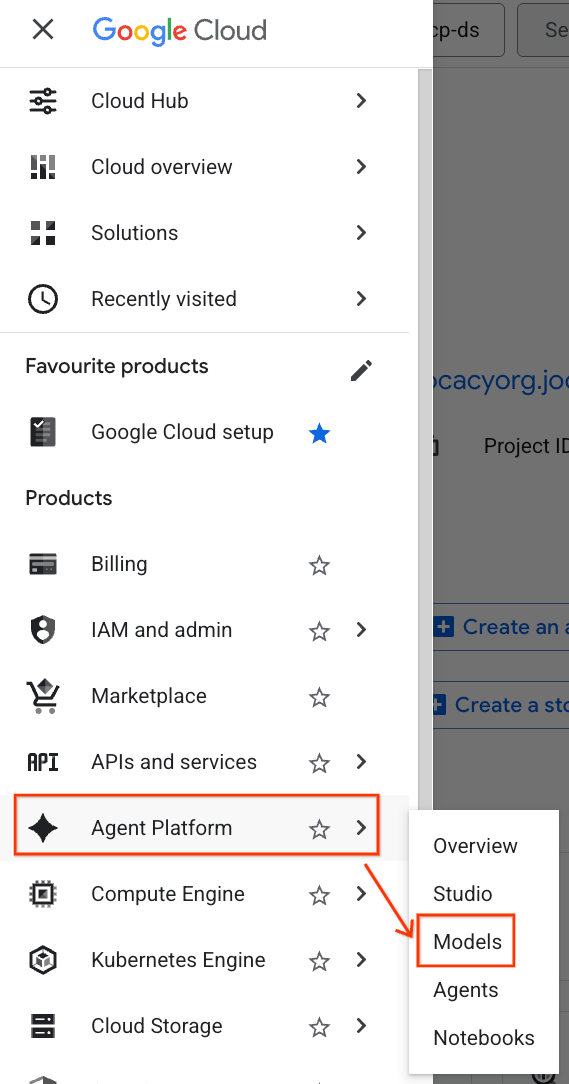
- Klicken Sie auf die im Screenshot hervorgehobene Schaltfläche Model Registry (Modellregistrierung).
- Ihr BQML-Modell wird neben allen anderen benutzerdefinierten Modellen aufgeführt. Suchen Sie in der Liste der Modelle nach dem Modell mit dem Namen housing_clustering. Sie können als Nächstes an einem Endpunkt bereitstellen, wodurch Ihr Modell für Echtzeit-Onlinevorhersagen außerhalb der BigQuery-Umgebung verfügbar wird.
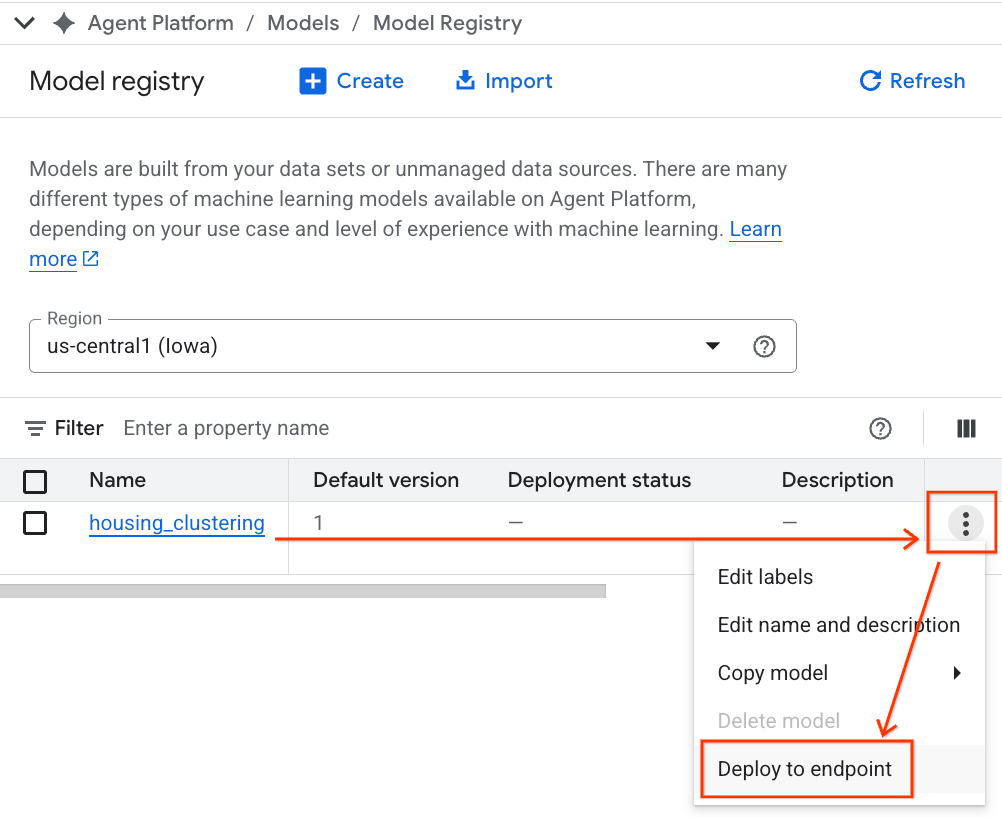
Nachdem Sie die Model Registry untersucht haben, können Sie mit diesen Schritten zu Ihrem Colab-Notebook in BigQuery zurückkehren:
- Klicken Sie im Navigationsmenü (☰) auf BigQuery > Studio.
- Maximieren Sie die Menüs im Bereich Explore, um Ihr Notebook zu finden und zu öffnen.
8. Modellbewertung und ‑vorhersage
Nach dem Trainieren des Modells müssen Sie die erstellten Cluster analysieren. Hier verwenden Sie BigQuery Machine Learning-Funktionen wie ML.EVALUATE und ML.CENTROIDS, um die Qualität des Modells und die definierenden Merkmale der einzelnen Segmente zu analysieren.
Anschließend verwenden Sie ML.PREDICT, um jedes Haus einem Cluster zuzuweisen. Wenn Sie diese Abfrage mit dem Magic-Befehl %%bigquery df ausführen, werden die Ergebnisse in einem Pandas-DataFrame mit dem Namen df gespeichert. Dadurch sind die Daten sofort für die nachfolgenden Python-Schritte verfügbar. Dies unterstreicht die Interoperabilität zwischen SQL und Python in Colab Enterprise.
9. Cluster visualisieren und interpretieren
Nachdem Sie Ihre Vorhersagen in einen DataFrame geladen haben, können Sie Visualisierungen erstellen, um die Daten zum Leben zu erwecken. In diesem Abschnitt verwenden Sie beliebte Python-Bibliotheken wie Matplotlib, um die Unterschiede zwischen den Wohnsegmenten zu untersuchen.
Sie erstellen Boxplots und Balkendiagramme, um wichtige Merkmale wie Preis und Alter der Immobilie visuell zu vergleichen. So können Sie sich ein intuitives Bild von jedem Cluster machen.
10. Clusterbeschreibungen mit Gemini-Modellen generieren
Numerische Schwerpunkte und Diagramme sind zwar leistungsstark, mit generativer KI können Sie aber noch einen Schritt weiter gehen und aussagekräftige, qualitative Personas für jedes Wohnsegment erstellen. So können Sie nicht nur nachvollziehen, was die Cluster sind, sondern auch, wer sie repräsentieren.
In diesem Abschnitt aggregieren Sie zuerst die durchschnittlichen Statistiken für jeden Cluster, z. B. Preis und Quadratmeterzahl. Anschließend übergeben Sie diese Daten an einen Prompt für das Gemini-Modell. Anschließend weisen Sie das Modell an, als Immobilienexperte zu agieren und eine detaillierte Zusammenfassung zu erstellen, die für jedes Segment wichtige Merkmale und einen potenziellen Käufer enthält. Das Ergebnis ist eine Reihe von klaren, für Menschen lesbaren Beschreibungen, die die Cluster für ein Marketingteam sofort nachvollziehbar und umsetzbar machen.
Sie können den Prompt nach Belieben ändern und mit den Ergebnissen experimentieren.
11. Modellierung mit dem Data Science Agent automatisieren
Als Nächstes sehen Sie sich einen leistungsstarken alternativen Workflow an. Anstatt Code manuell zu schreiben, verwenden Sie den integrierten Data Science Agent, um einen vollständigen Workflow für das Clustering-Modell automatisch aus einem einzigen Prompt in natürlicher Sprache zu generieren.
So generieren und führen Sie das Modell mit dem Agenten aus:
- Klicken Sie im Bereich BigQuery Studio auf den Drop-down-Pfeil, bewegen Sie den Mauszeiger auf Notebook und wählen Sie dann Leeres Notebook aus. So wird sichergestellt, dass der Code des Agents nicht mit Ihrem ursprünglichen Lab-Notebook in Konflikt gerät.
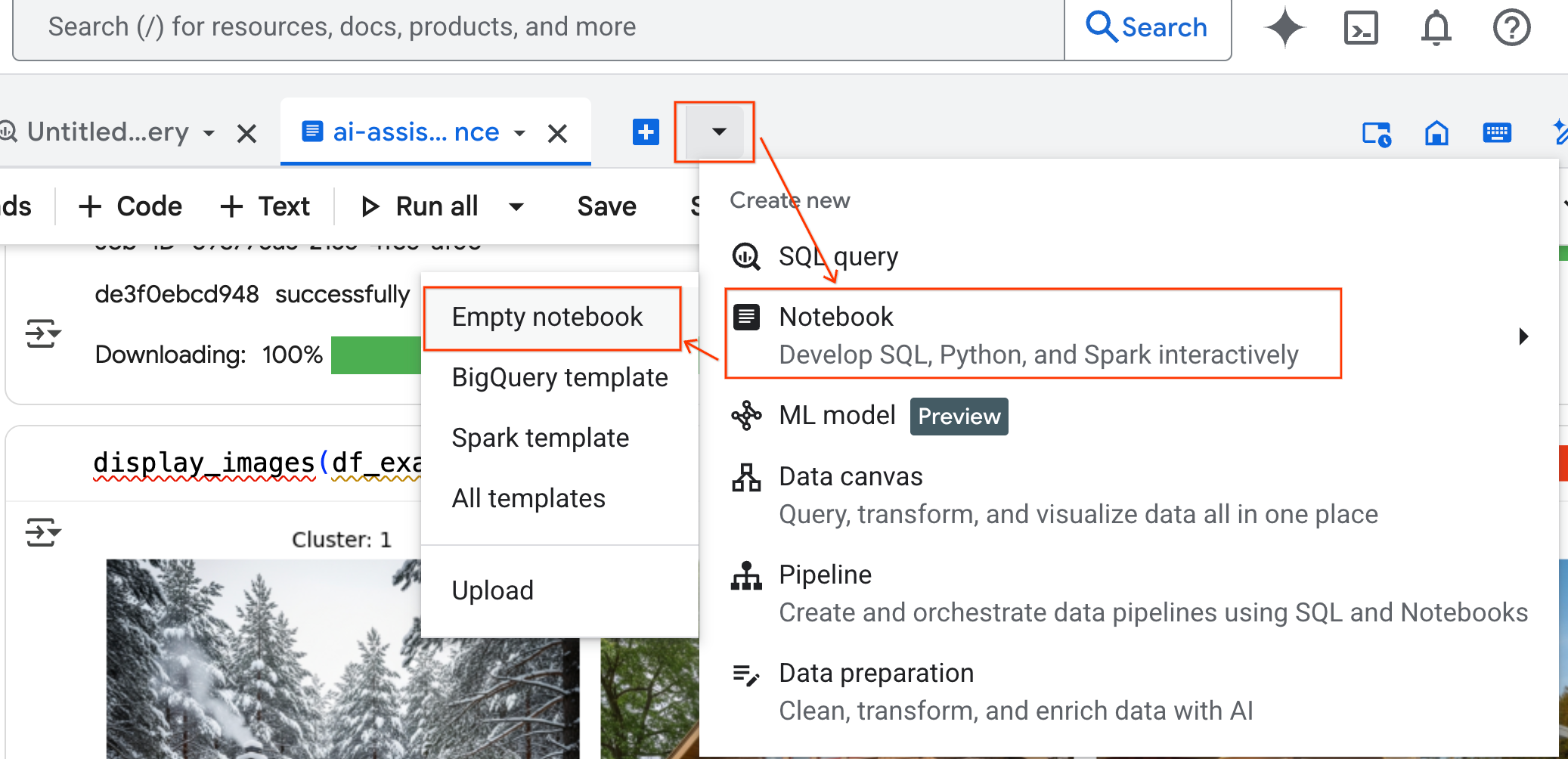
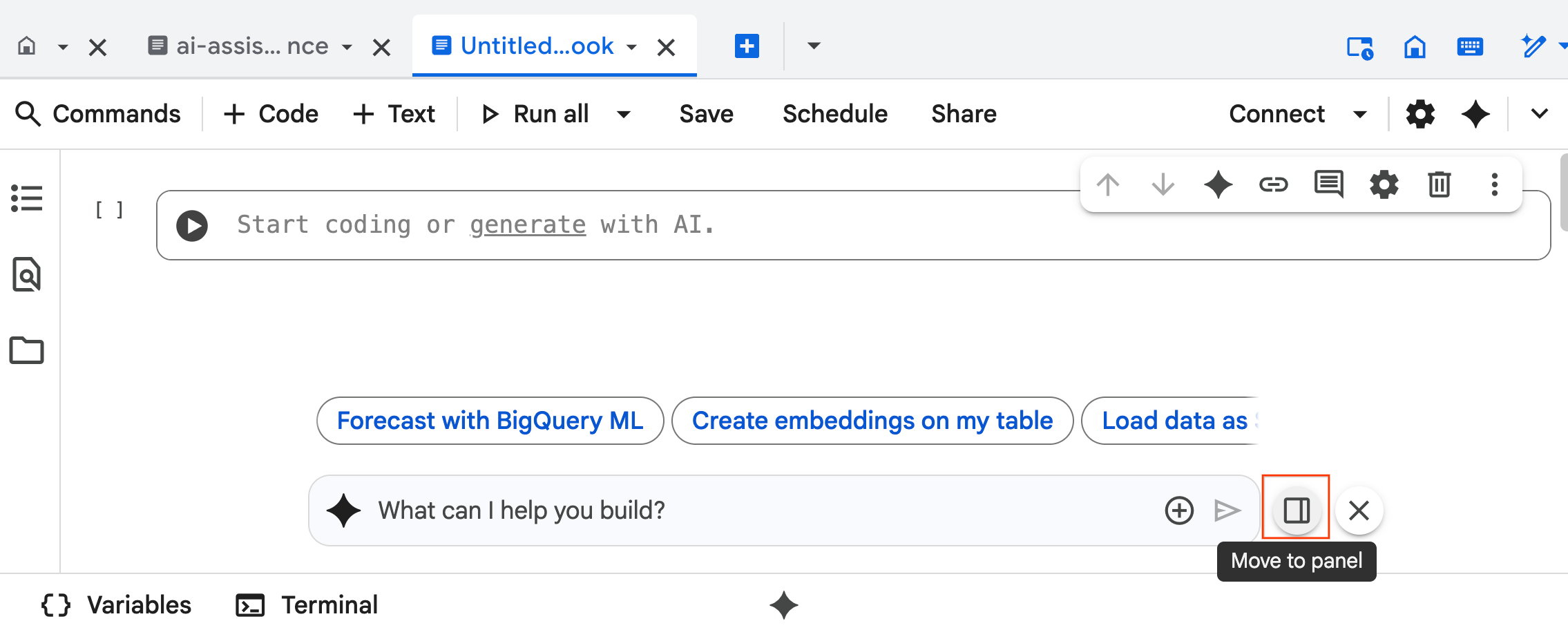
- Die Chat-Oberfläche von Data Science Agent wird unten im Notebook geöffnet. Klicken Sie auf den Button In Seitenleiste verschieben, um den Chat auf der rechten Seite anzupinnen.
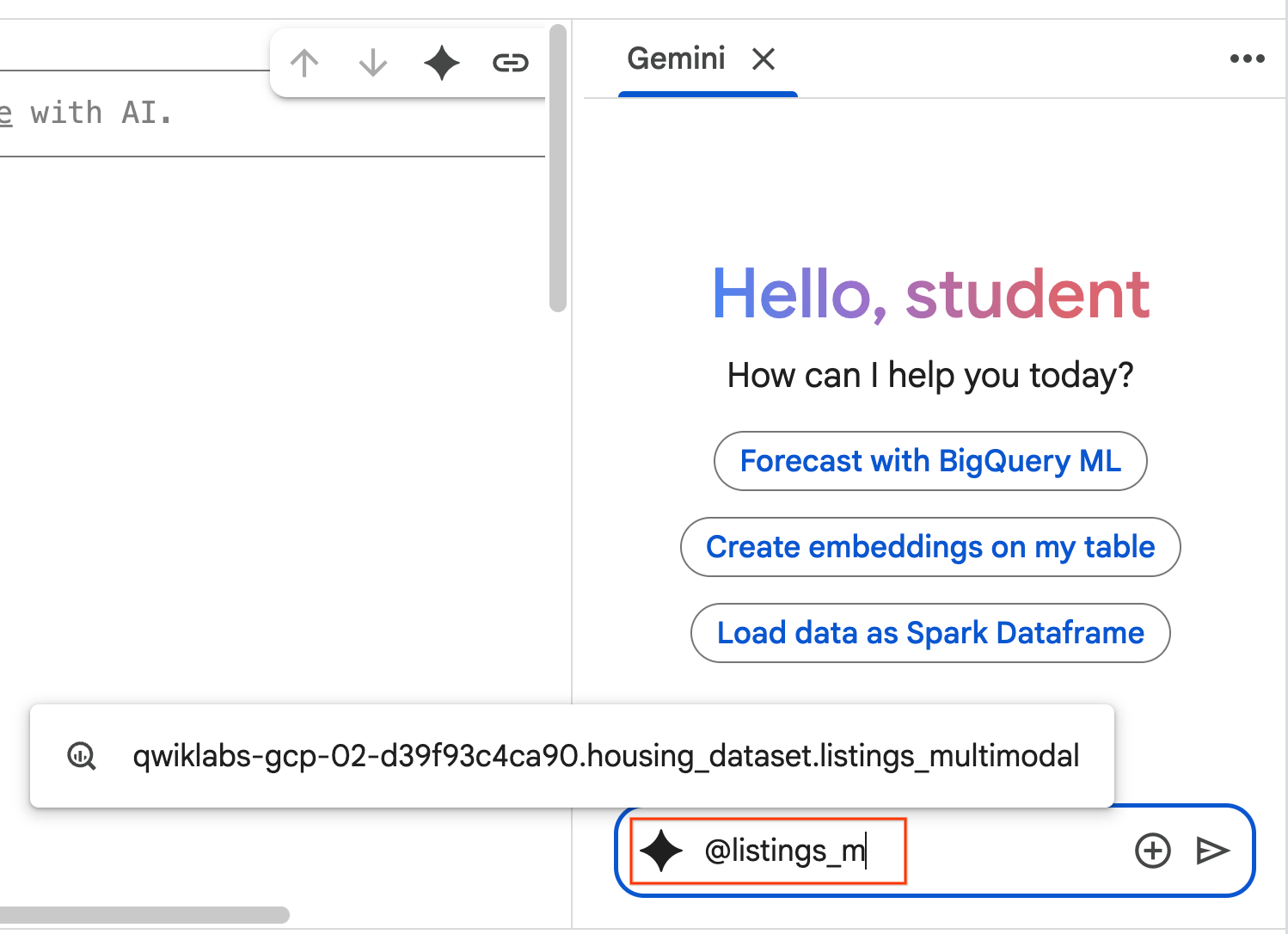
- Beginnen Sie mit der Eingabe von
@listing_multimodalim Chatbereich und klicken Sie auf die Tabelle. Dadurch wird die Tabellelistings_multimodalexplizit als Kontext festgelegt.
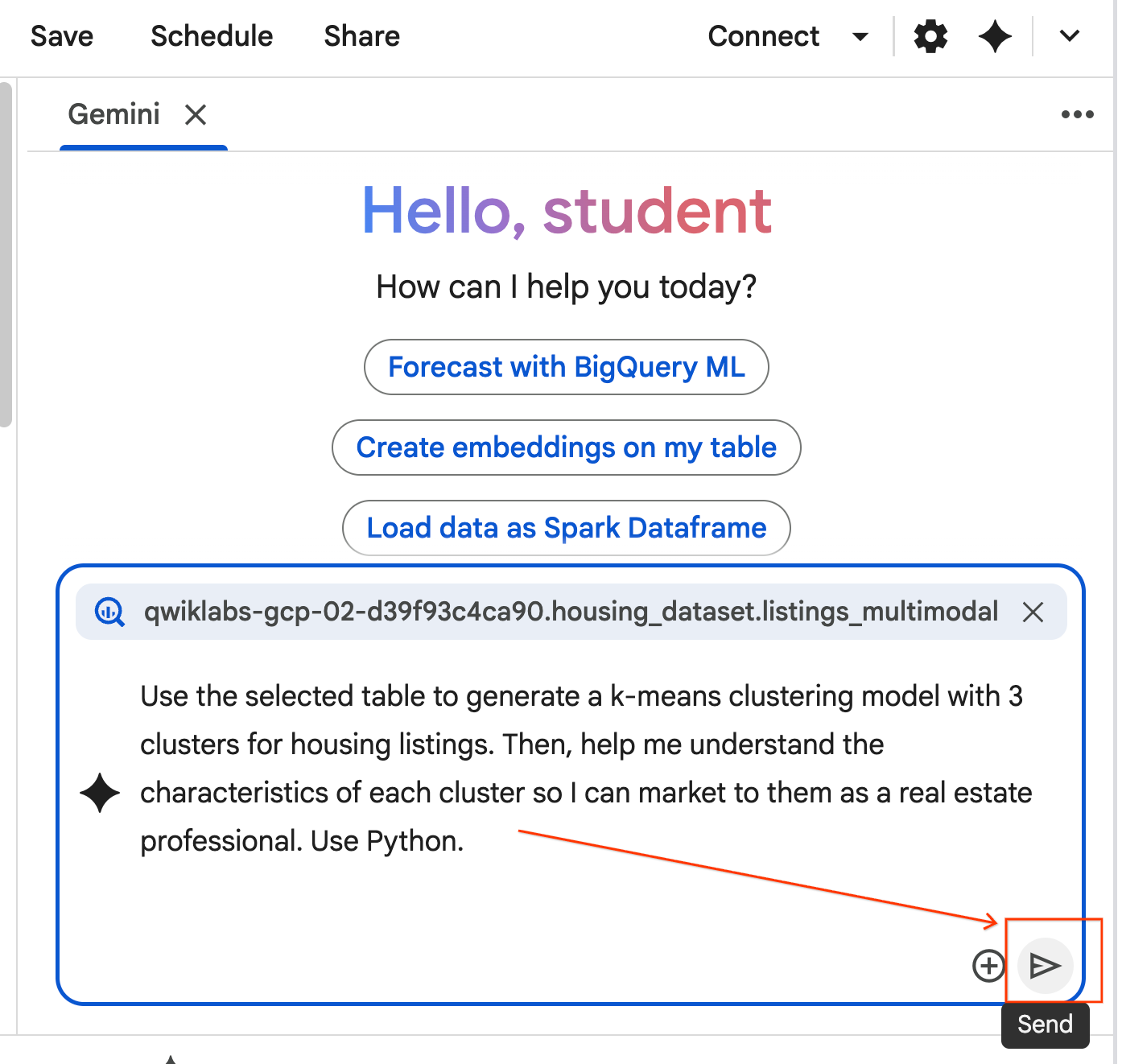
- Kopieren Sie den folgenden Prompt und geben Sie ihn in das Agent-Chatfeld ein. Klicken Sie anschließend auf Senden, um den Prompt an den Agent zu senden.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- Der KI-Agent überlegt und formuliert einen Plan. Wenn Sie mit diesem Plan einverstanden sind, klicken Sie auf Akzeptieren und ausführen. Der Agent generiert Python-Code in einer oder mehreren neuen Zellen.
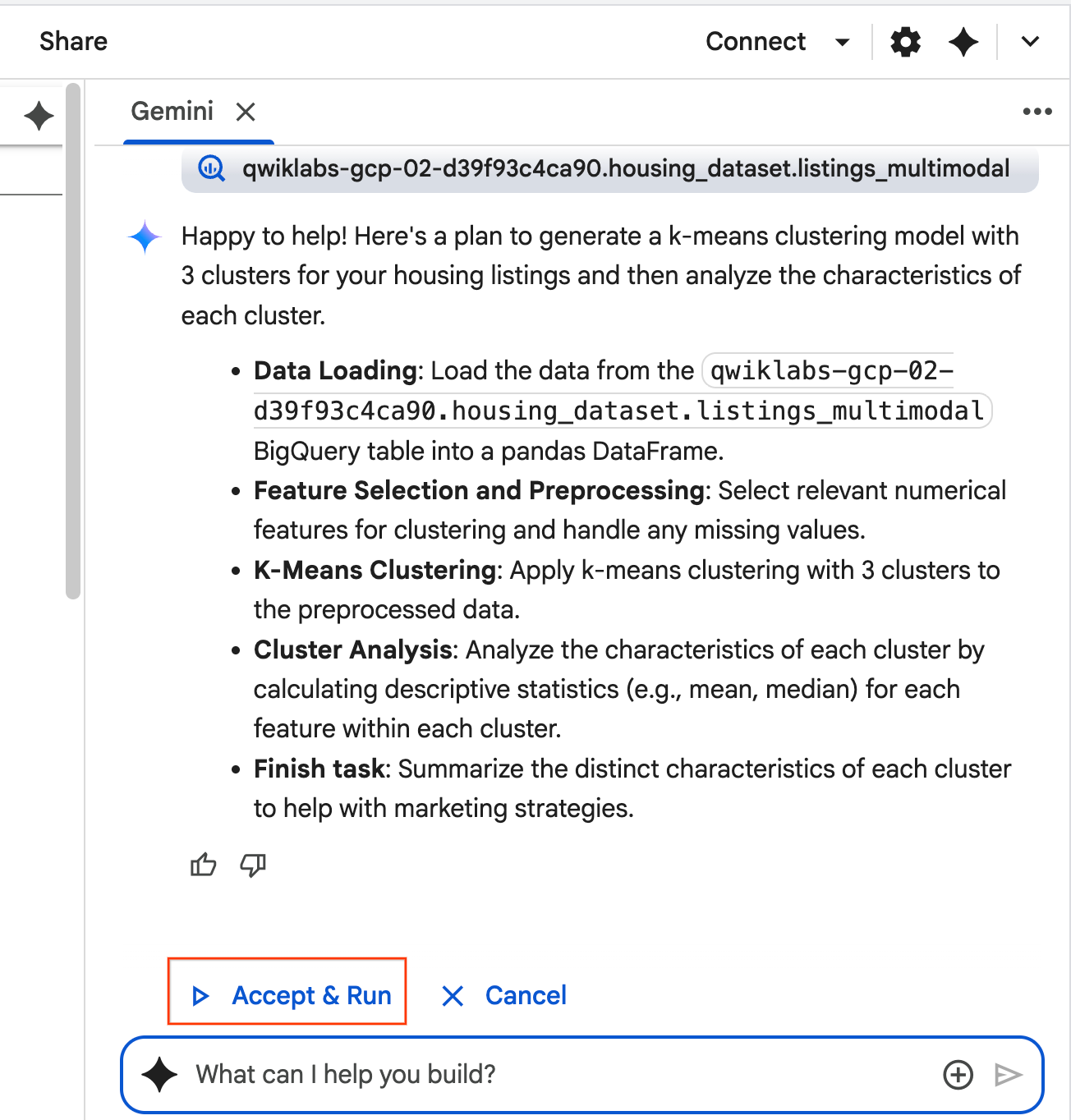
- Der Agent fordert Sie auf, jeden generierten Codeblock zu Accept & Run (Akzeptieren und ausführen). So wird der Human-in-the-Loop-Ansatz beibehalten. Sie können den Code jederzeit überprüfen oder bearbeiten und mit den einzelnen Schritten fortfahren, bis Sie fertig sind.
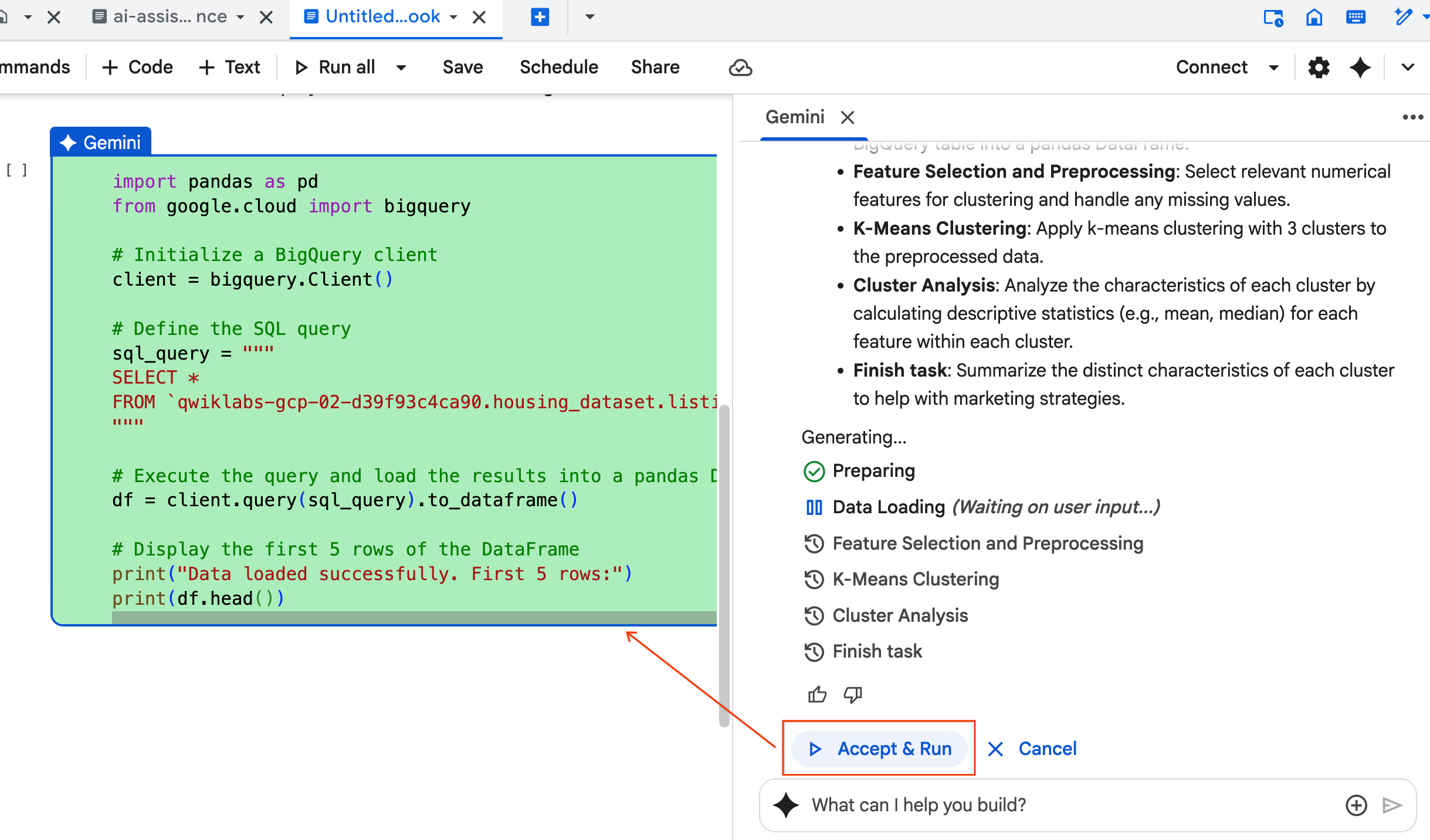
- Wenn Sie fertig sind, schließen Sie einfach diesen neuen Notebook-Tab und kehren Sie zum ursprünglichen Tab
ai-assisted-data-science.ipynbzurück, um mit dem letzten Abschnitt des Labs fortzufahren.
12. Multimodale Suche mit Einbettungen und Vektorsuche
In diesem letzten Abschnitt implementieren Sie die multimodale Suche direkt in BigQuery. So können Sie intuitiv suchen, z. B. nach Häusern anhand einer Textbeschreibung oder nach Häusern, die einem Beispielbild ähneln.
Dabei wird zuerst jedes Hausbild in eine numerische Darstellung umgewandelt, die als Einbettung bezeichnet wird. Eine Einbettung erfasst die semantische Bedeutung eines Bildes. So können Sie ähnliche Elemente finden, indem Sie ihre numerischen Vektoren vergleichen.
Sie verwenden das multimodalembedding-Modell, um diese Vektoren für alle Ihre Einträge zu generieren. Nachdem Sie einen Vektorindex erstellt haben, um die Suche zu beschleunigen, führen Sie zwei Arten von Ähnlichkeitssuchen durch: Text-zu-Bild (Häuser finden, die einer Beschreibung entsprechen) und Bild-zu-Bild (Häuser finden, die wie ein Beispielbild aussehen).
Sie erledigen alles in BigQuery und verwenden Funktionen wie ML.GENERATE_EMBEDDING zum Generieren von Einbettungen oder VECTOR_SEARCH für die Ähnlichkeitssuche.
13. Bereinigen
Wenn Sie alle für dieses Projekt verwendeten Google Cloud-Ressourcen bereinigen möchten, können Sie das Google Cloud-Projekt löschen.
Alternativ können Sie die einzelnen Ressourcen löschen, die Sie erstellt haben. Führen Sie dazu den folgenden Code in einer neuen Zelle in Ihrem Notebook aus:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
Zum Schluss können Sie das Notebook selbst löschen:
- Maximieren Sie im Bereich Explorer von BigQuery Studio Ihr Projekt und den Knoten Notebooks.
- Klicken Sie neben dem
ai-assisted-data-science-Notebook auf das Dreipunkt-Menü. - Wählen Sie Löschen aus.
14. Glückwunsch!
Herzlichen Glückwunsch zum Abschluss des Codelabs!
Behandelte Themen
- Rohdatensatz mit Immobilienangeboten für die Analyse durch Feature Engineering vorbereiten.
- Einträge anreichern: Mit den KI-Funktionen von BigQuery können Sie Hausfotos auf wichtige visuelle Merkmale hin analysieren.
- Erstellen und bewerten Sie ein K-Means-Modell mit BigQuery Machine Learning (BQML), um Properties in verschiedene Cluster zu segmentieren.
- Modellerstellung automatisieren: Mit dem Data Science Agent können Sie ein Clustering-Modell mit Python generieren.
- Einbettungen für Hausbilder generieren, um ein Tool für die visuelle Suche zu ermöglichen, mit dem ähnliche Häuser mit Text- oder Bildabfragen gefunden werden können.