
1. Introducción
Descripción general
En este lab, explorarás un flujo de trabajo de ciencia de datos multimodal en BigQuery, enmarcado en una situación inmobiliaria. Comenzarás con un conjunto de datos sin procesar de publicaciones de casas y sus imágenes, enriquecerás estos datos con IA para extraer atributos visuales, compilarás un modelo de agrupamiento para descubrir distintos segmentos de mercado y, por último, crearás una potente herramienta de búsqueda visual con embeddings de vectores.
Compararás este flujo de trabajo nativo de SQL con un enfoque moderno de IA generativa usando el Agente de ciencia de datos para generar automáticamente un modelo de agrupamiento basado en Python a partir de una simple instrucción de texto.
Qué aprenderás
- Prepara un conjunto de datos sin procesar de fichas de bienes raíces para el análisis a través de la ingeniería de atributos.
- Enriquece las fichas con las funciones de IA de BigQuery para analizar las fotos de las casas y detectar las características visuales clave.
- Crea y evalúa un modelo de K-means con BigQuery Machine Learning (BQML) para segmentar las propiedades en clústeres distintos.
- Automatiza la creación de modelos con el agente de ciencia de datos para generar un modelo de agrupamiento en clústeres con Python.
- Generar embeddings para imágenes de casas y potenciar una herramienta de búsqueda visual que encuentre casas similares con consultas de texto o imágenes
Requisitos previos
Antes de comenzar este lab, debes tener los siguientes conocimientos:
- Conocimientos básicos de programación en SQL y Python
- Ejecutar código de Python en un notebook de Jupyter
2. Antes de comenzar
Crea un proyecto de Google Cloud
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Habilita las APIs con Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud:

- Una vez que te conectes a Cloud Shell, ejecuta este comando para verificar tu autenticación en Cloud Shell:
gcloud auth list
- Ejecuta el siguiente comando para confirmar que tu proyecto esté configurado para usar gcloud:
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Habilita las APIs
- Ejecuta este comando para habilitar todas las APIs y los servicios requeridos:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- Cuando el comando se ejecute correctamente, deberías ver un mensaje similar al que se muestra a continuación:
Operation "operations/..." finished successfully.
- Sal de Cloud Shell.
3. Abre el notebook del lab en BigQuery Studio
Navegación por la IU:
- En la consola de Google Cloud, ve al menú de navegación > BigQuery.
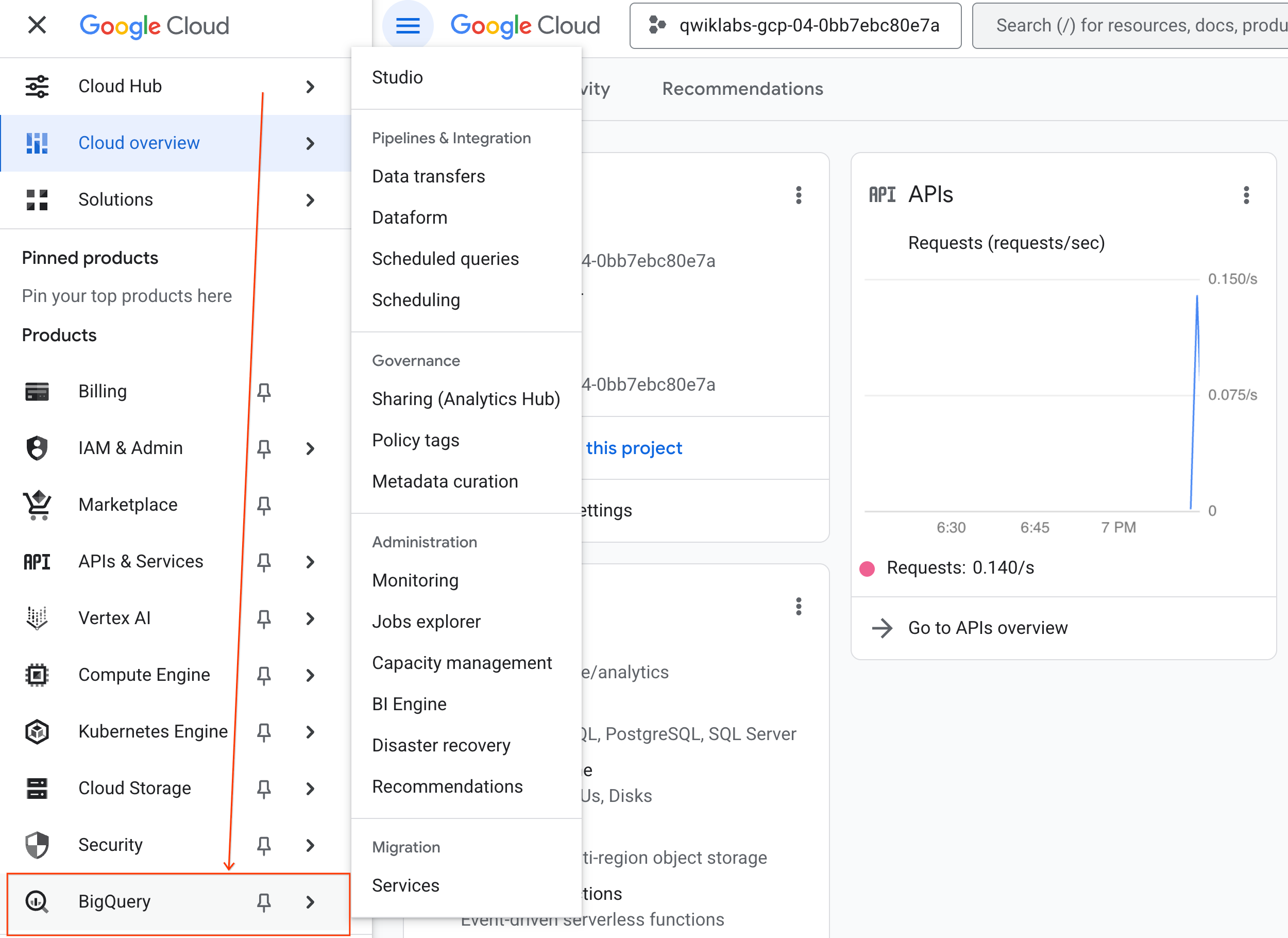
- En el panel BigQuery Studio, haz clic en el botón de flecha desplegable, coloca el cursor sobre Notebook y, luego, selecciona Subir.
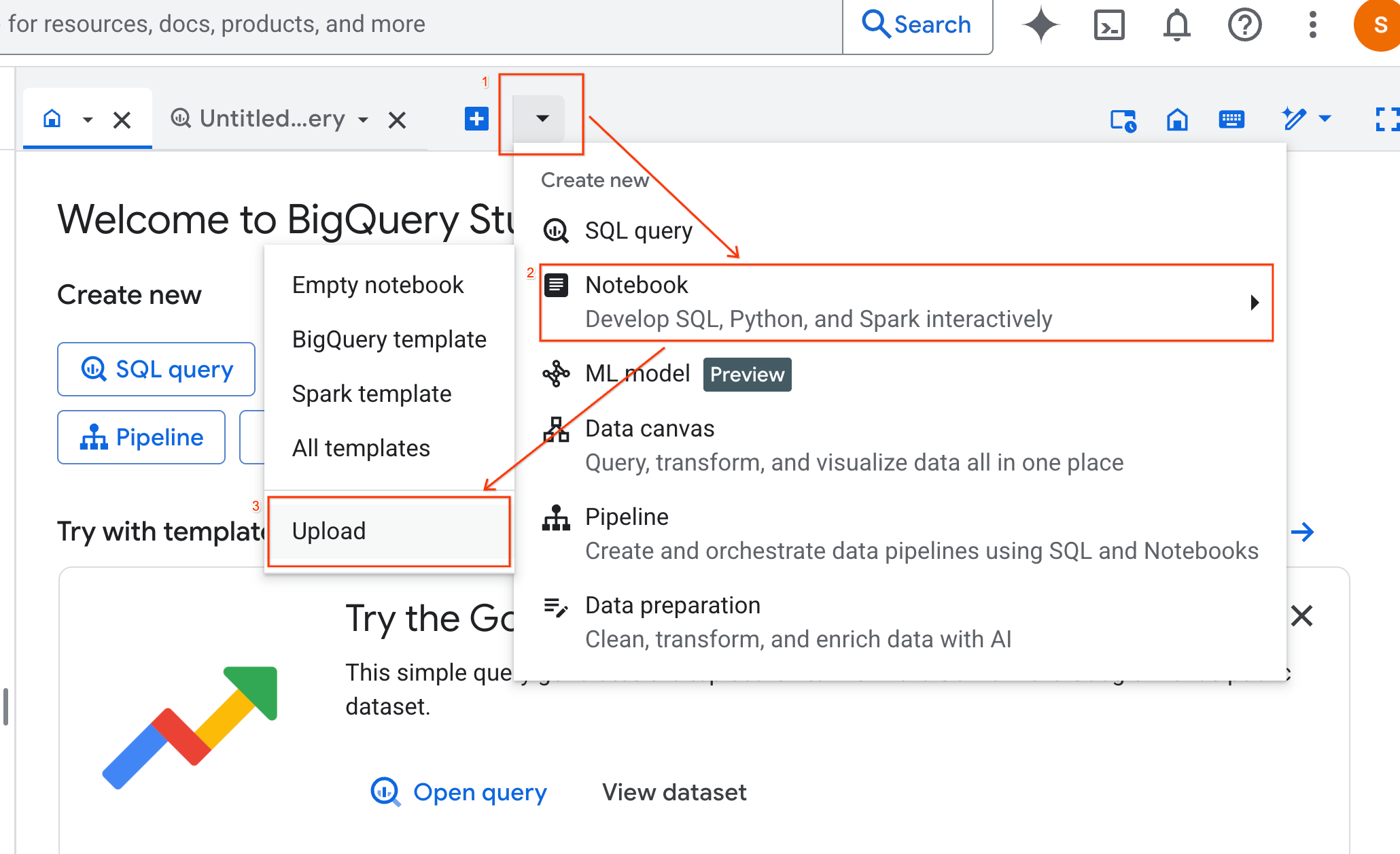
- Selecciona el botón de selección URL y, luego, ingresa la siguiente URL:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- Establece la región en
us-central1y haz clic en Subir.
- Para abrir el notebook, haz clic en la flecha desplegable del panel Explorador que contiene tu ID del proyecto. Luego, haz clic en el menú desplegable Notebooks. Haz clic en el cuaderno
ai-assisted-data-science.
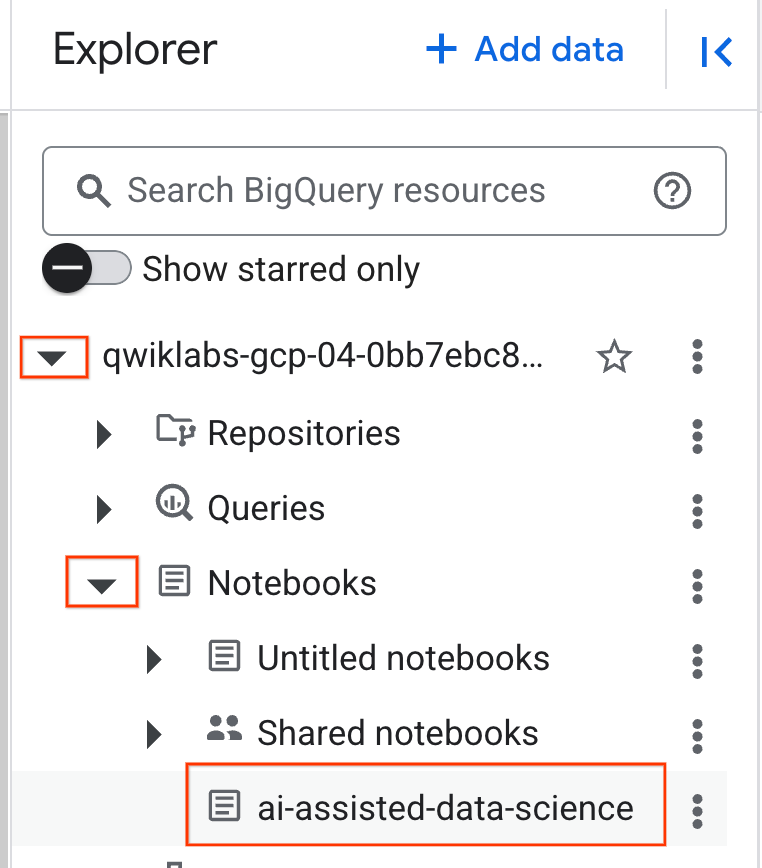
- (Opcional) Contrae el menú de navegación de BigQuery y el índice del notebook para tener más espacio.
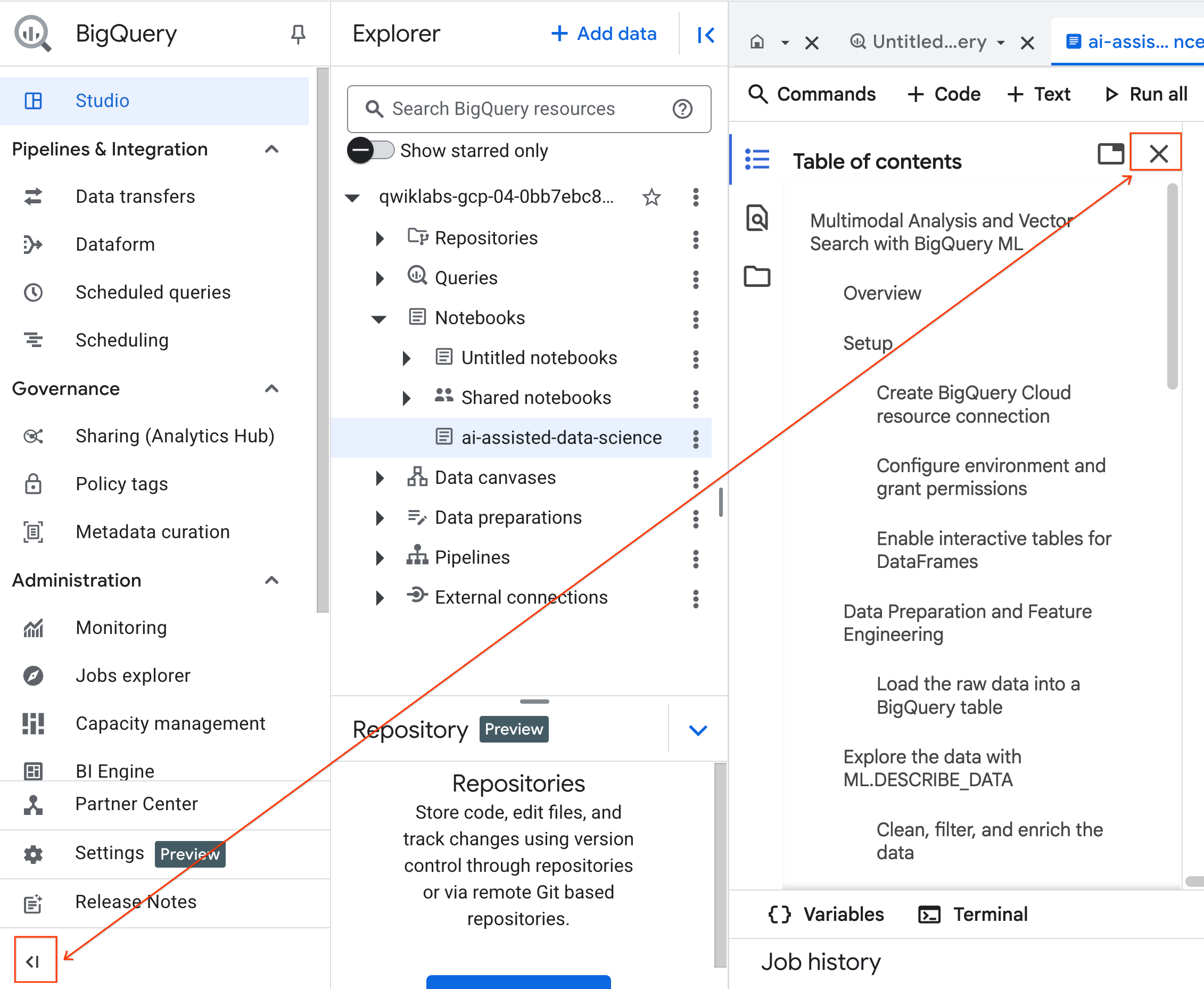
4. Conéctate a un entorno de ejecución y ejecuta el código de configuración
- Haz clic en Conectar. Si aparece una ventana emergente, autoriza Colab Enterprise con tu usuario. Tu notebook se conectará automáticamente a un entorno de ejecución. Este proceso puede tardar unos minutos en completarse.
- Una vez que se establezca el tiempo de ejecución, verás lo siguiente:
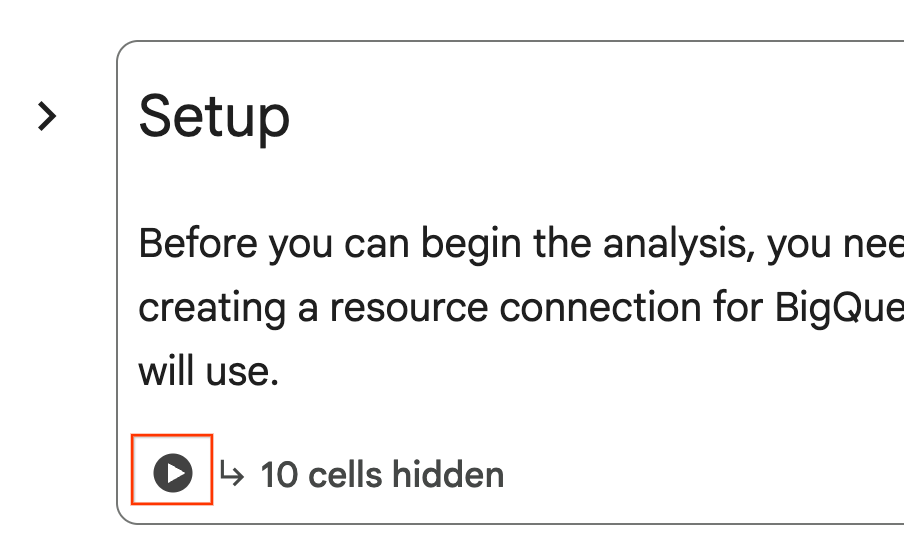
- En el notebook, desplázate hasta la sección Configuración. Haz clic en el botón "Ejecutar" junto a las celdas ocultas. Esto crea algunos recursos necesarios para el lab en tu proyecto. Este proceso puede tardar un minuto en completarse. Mientras tanto, puedes revisar las celdas en Configuración.
5. Preparación de datos y diseño de atributos
En esta sección, repasarás el primer paso importante de cualquier proyecto de ciencia de datos: la preparación de los datos. Para comenzar, crea un conjunto de datos de BigQuery para organizar tu trabajo y, luego, carga los datos sin procesar de bienes raíces o viviendas desde un archivo CSV en Cloud Storage en una tabla nueva.
Luego, transformarás estos datos sin procesar en una tabla limpia con atributos nuevos. Esto implica filtrar las fichas, crear una nueva función property_age y preparar los datos de imagen para el análisis multimodal.
6. Enriquecimiento multimodal con funciones de IA
Ahora enriquecerás tus datos con el poder de la IA generativa. En esta sección, usarás las funciones integradas basadas en IA de BigQuery para analizar las imágenes de cada ficha de la casa.
Si conectas BigQuery a un modelo de Gemini, puedes extraer funciones nuevas y valiosas de las imágenes (por ejemplo, si una propiedad está cerca del agua y una breve descripción de la casa) directamente con SQL.
7. Entrenamiento del modelo con agrupamiento en clústeres de k-means
Con tu conjunto de datos recién enriquecido, ya puedes compilar un modelo de aprendizaje automático. Tu objetivo es segmentar los anuncios de casas en grupos distintos, y lo harás entrenando un modelo de agrupamiento de K-means directamente en BigQuery con BigQuery Machine Learning (BQML). Como parte de este único paso, también registras el modelo en Agent Platform AI Model Registry, lo que lo hace disponible de inmediato en el ecosistema de MLOps más amplio de Google Cloud.
Para confirmar que tu modelo se registró correctamente, puedes encontrarlo en el registro de modelos de la Plataforma de agentes siguiendo estos pasos:
- En la consola de Google Cloud, haz clic en el menú de navegación (☰) en la esquina superior izquierda.
- Desplázate hasta la sección Agent Platform y haz clic en Models.
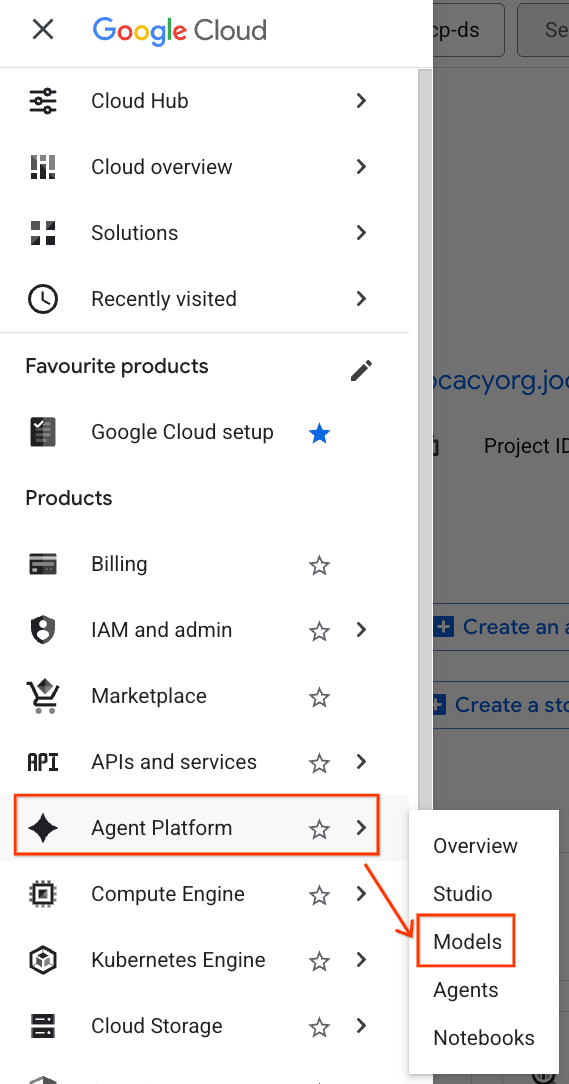
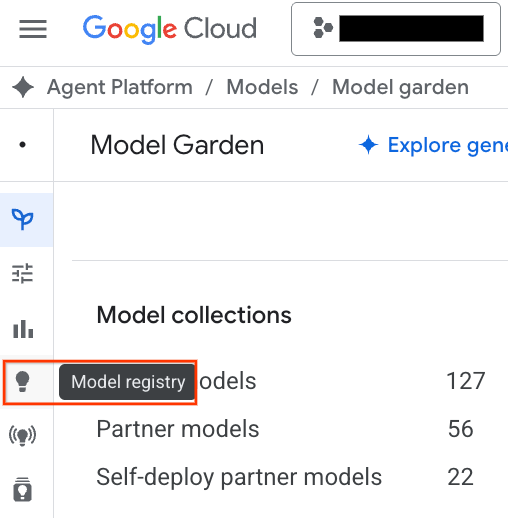
- Haz clic en el botón Model Registry destacado en la captura de pantalla.
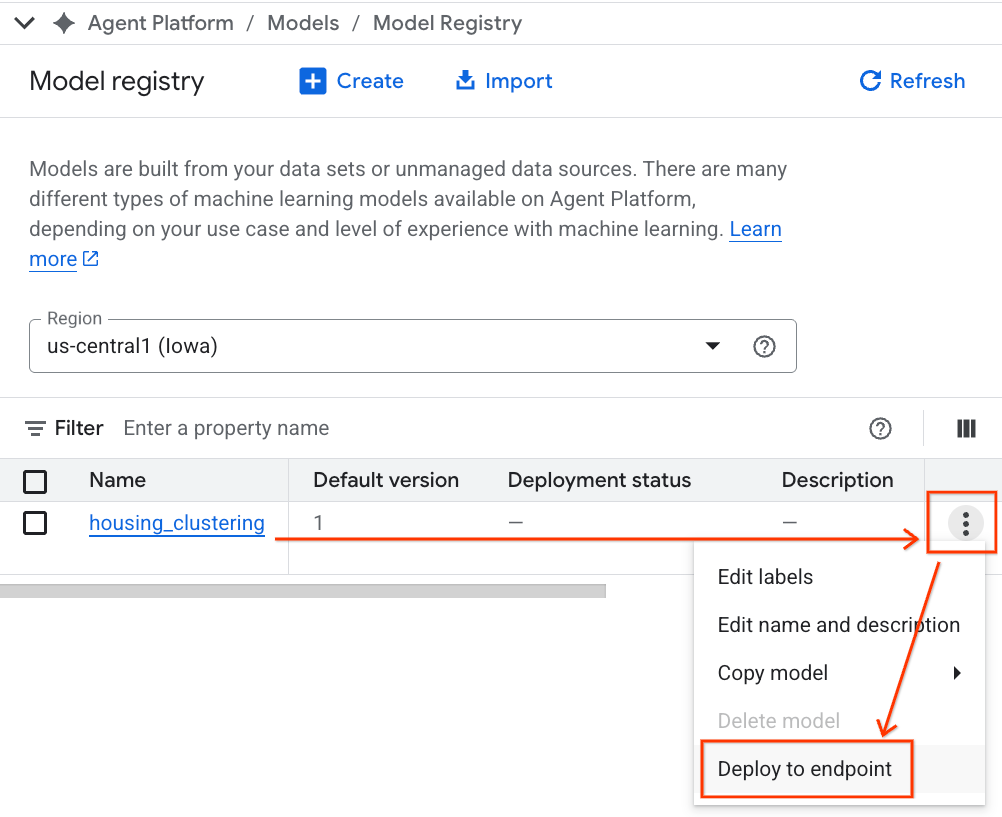
- Verás tu modelo de BQML junto con todos tus otros modelos personalizados. En la lista de modelos, busca el modelo llamado housing_clustering. Podrías dar el siguiente paso para implementar en un extremo, lo que haría que tu modelo esté disponible para las predicciones en línea en tiempo real fuera del entorno de BigQuery.
Después de explorar el registro de modelos, puedes volver a tu notebook de Colab en BigQuery con estos pasos:
- En el menú de navegación (☰), ve a BigQuery > Studio.
- Expande los menús en el panel Explorador para encontrar tu notebook y abrirlo.
8. Evaluación y predicción del modelo
Después de entrenar tu modelo, el siguiente paso es comprender los clústeres que creó. Aquí, usarás funciones de BigQuery Machine Learning, como ML.EVALUATE y ML.CENTROIDS, para analizar la calidad del modelo y las características definitorias de cada segmento.
Luego, usas ML.PREDICT para asignar cada casa a un clúster. Si ejecutas esta consulta con el comando mágico %%bigquery df, almacenarás los resultados en un DataFrame de Pandas llamado df. Esto hace que los datos estén disponibles de inmediato para los pasos posteriores de Python. Esto destaca la interoperabilidad entre SQL y Python en Colab Enterprise.
9. Visualiza e interpreta clústeres
Ahora que tus predicciones se cargaron en un DataFrame, puedes crear visualizaciones para dar vida a los datos. En esta sección, usarás bibliotecas populares de Python, como Matplotlib, para explorar las diferencias entre los segmentos de viviendas.
Crearás diagramas de caja y gráficos de barras para comparar visualmente las características clave, como el precio y la antigüedad de la propiedad, lo que facilitará la creación de una comprensión intuitiva de cada clúster.
10. Genera descripciones de clústeres con los modelos de Gemini
Si bien los centroides y los gráficos numéricos son poderosos, la IA generativa te permite ir un paso más allá y crear arquetipos cualitativos enriquecidos para cada segmento de vivienda. Esto te ayuda a comprender no solo qué son los clústeres, sino también a quiénes representan.
En esta sección, primero agregarás las estadísticas promedio de cada clúster, como el precio y la superficie en pies cuadrados. Luego, pasarás estos datos a una instrucción para el modelo de Gemini. Luego, le indicas al modelo que actúe como un profesional de bienes raíces y genere un resumen detallado, incluidas las características clave y un comprador objetivo para cada segmento. El resultado es un conjunto de descripciones claras y legibles que hacen que los clústeres sean comprensibles y prácticos de inmediato para un equipo de marketing.
No dudes en modificar la instrucción como te parezca y experimentar con los resultados.
11. Automatiza el modelado con el Agente de ciencia de datos
Ahora, explorarás un flujo de trabajo alternativo y potente. En lugar de escribir código de forma manual, usarás el agente de ciencia de datos integrado para generar automáticamente un flujo de trabajo completo del modelo de agrupamiento a partir de una sola instrucción en lenguaje natural.
Sigue estos pasos para generar y ejecutar el modelo con el agente:
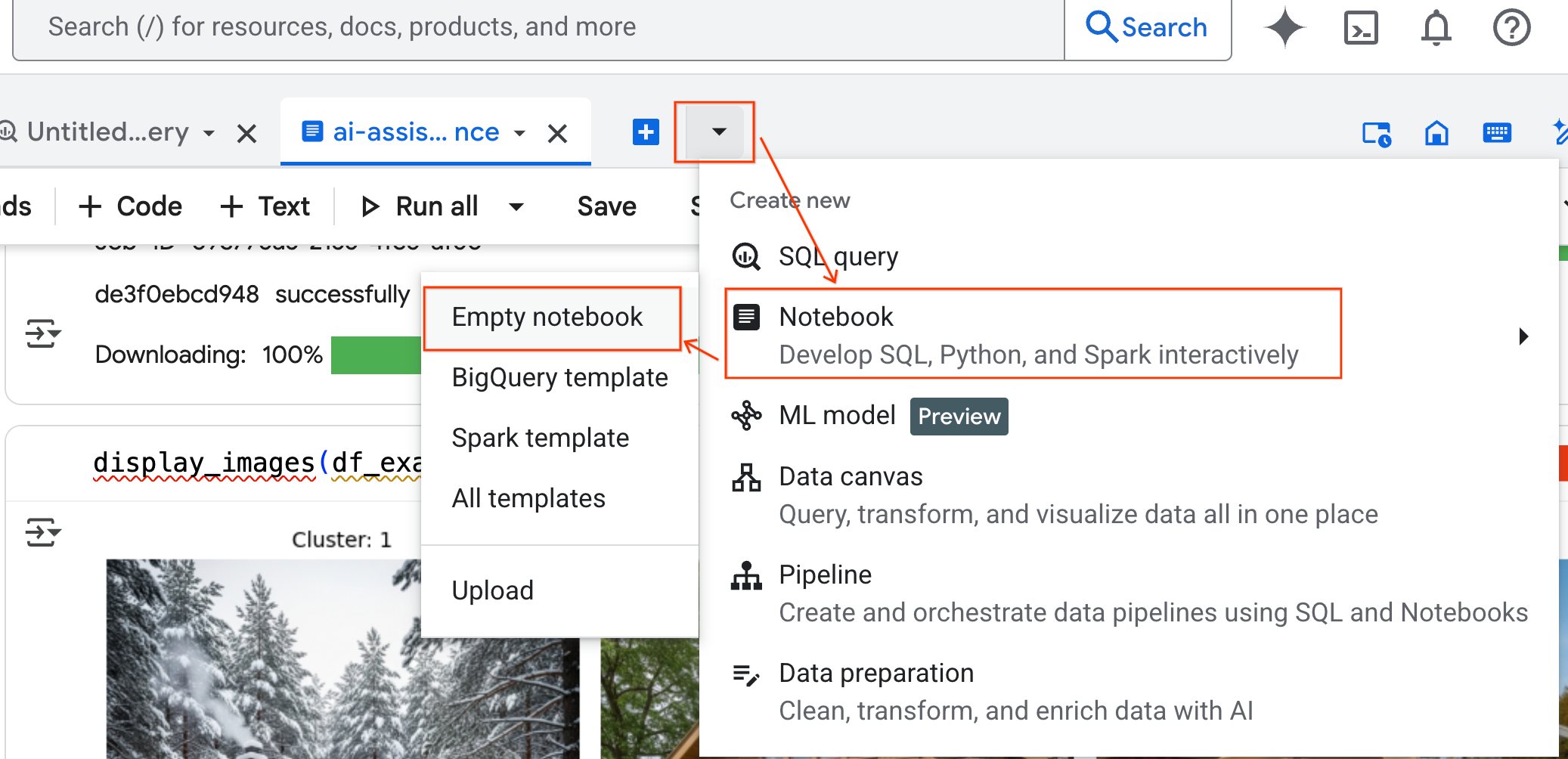
- En el panel BigQuery Studio, haz clic en el botón de flecha del menú desplegable, coloca el cursor sobre Notebook y, luego, selecciona Empty Notebook. Esto garantiza que el código del agente no interfiera en tu notebook de laboratorio original.
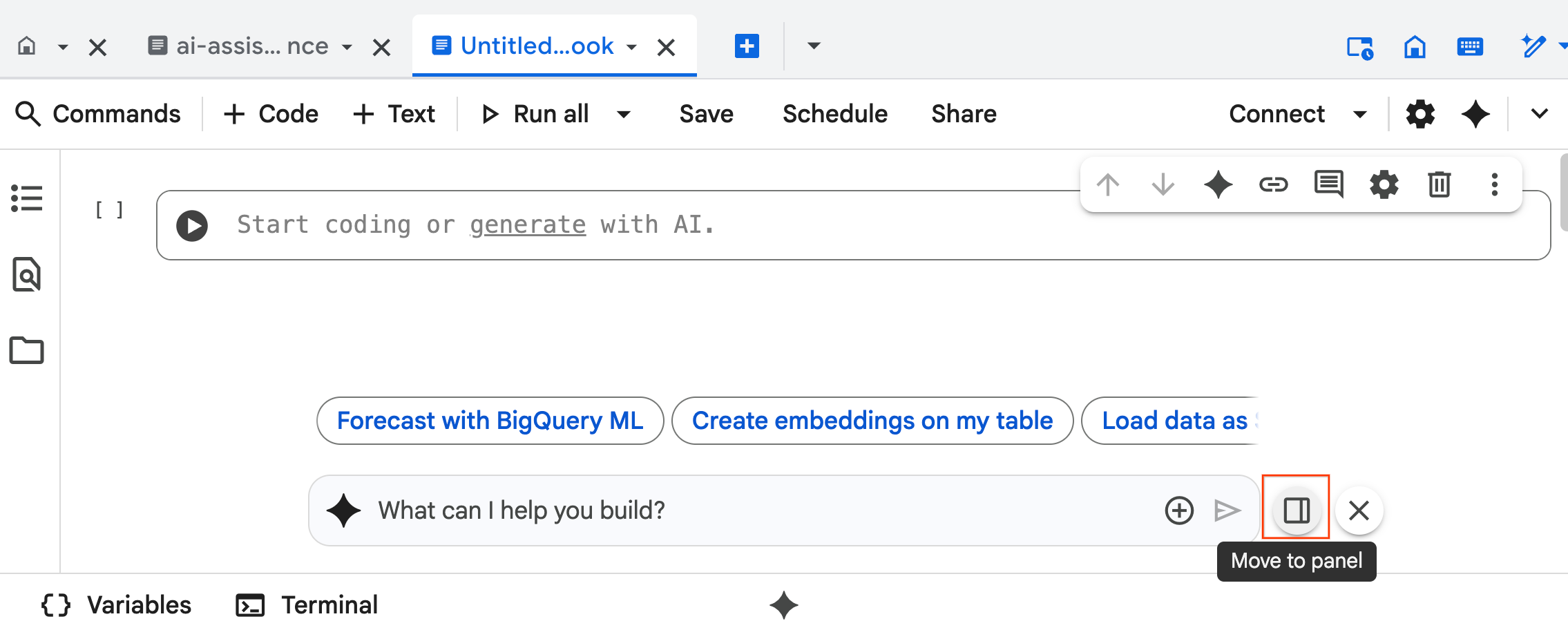
- La interfaz de chat del Agente de ciencia de datos se abre en la parte inferior del notebook. Haz clic en el botón Mover al panel para fijar el chat en el lado derecho.
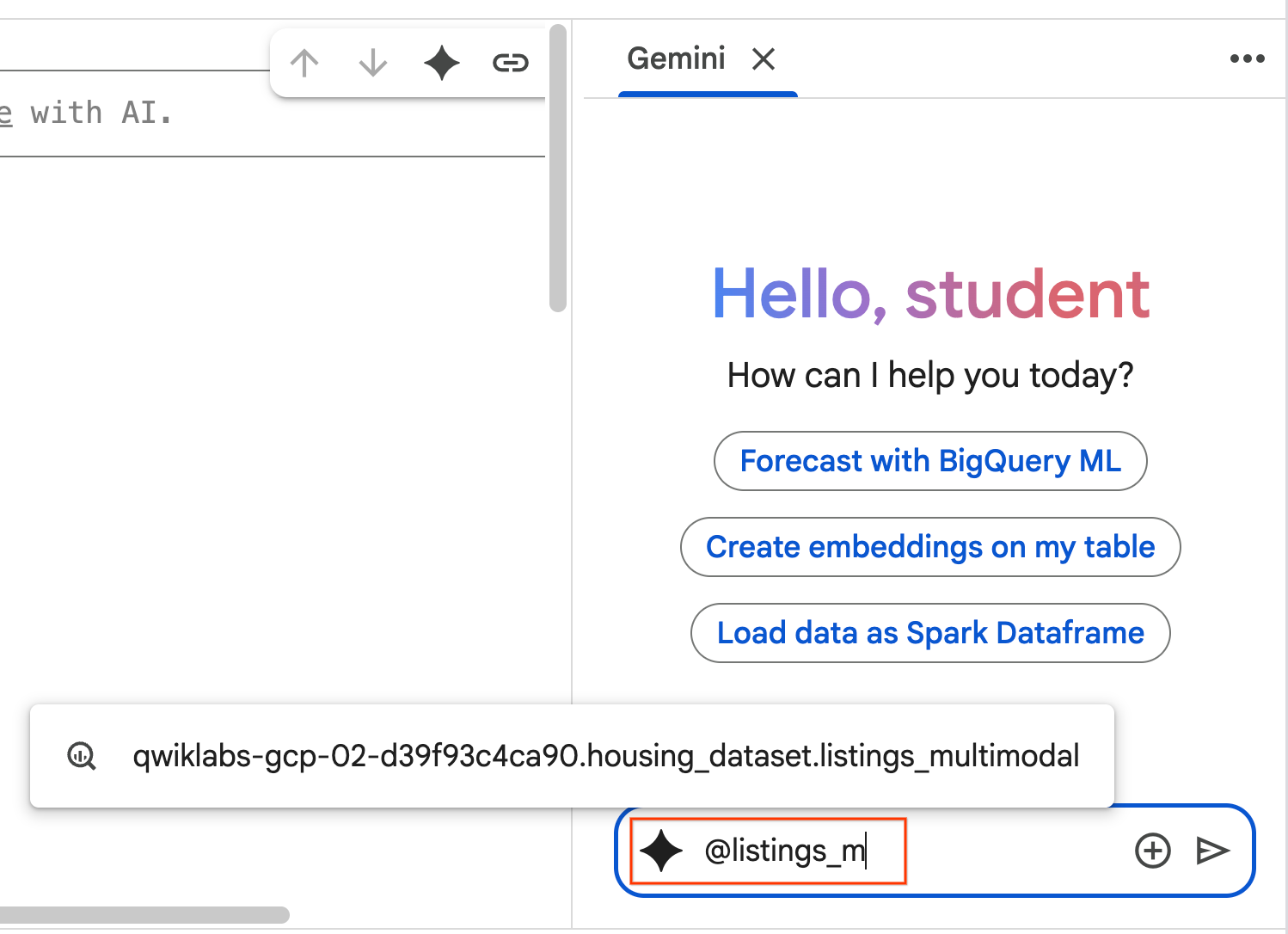
- Comienza a escribir
@listing_multimodalen el panel de chat y haz clic en la tabla. Esto establece explícitamente la tablalistings_multimodalcomo contexto.
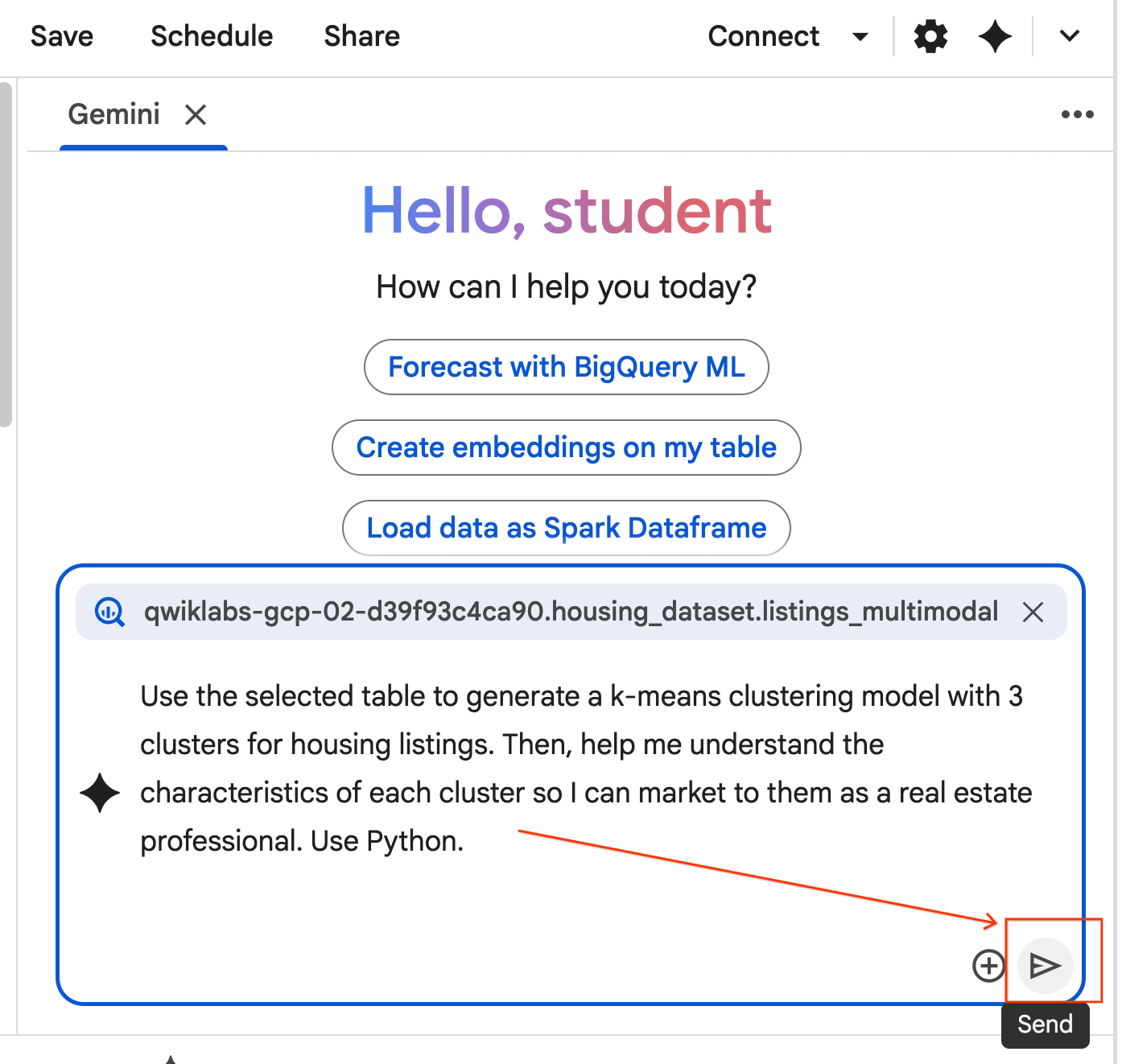
- Copia la siguiente instrucción y pégala en el cuadro de chat del agente. Luego, haz clic en Enviar para enviar la instrucción al agente.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- El agente pensará y formulará un plan. Si aceptas este plan, haz clic en Aceptar y ejecutar. El agente generará código de Python en una o más celdas nuevas.
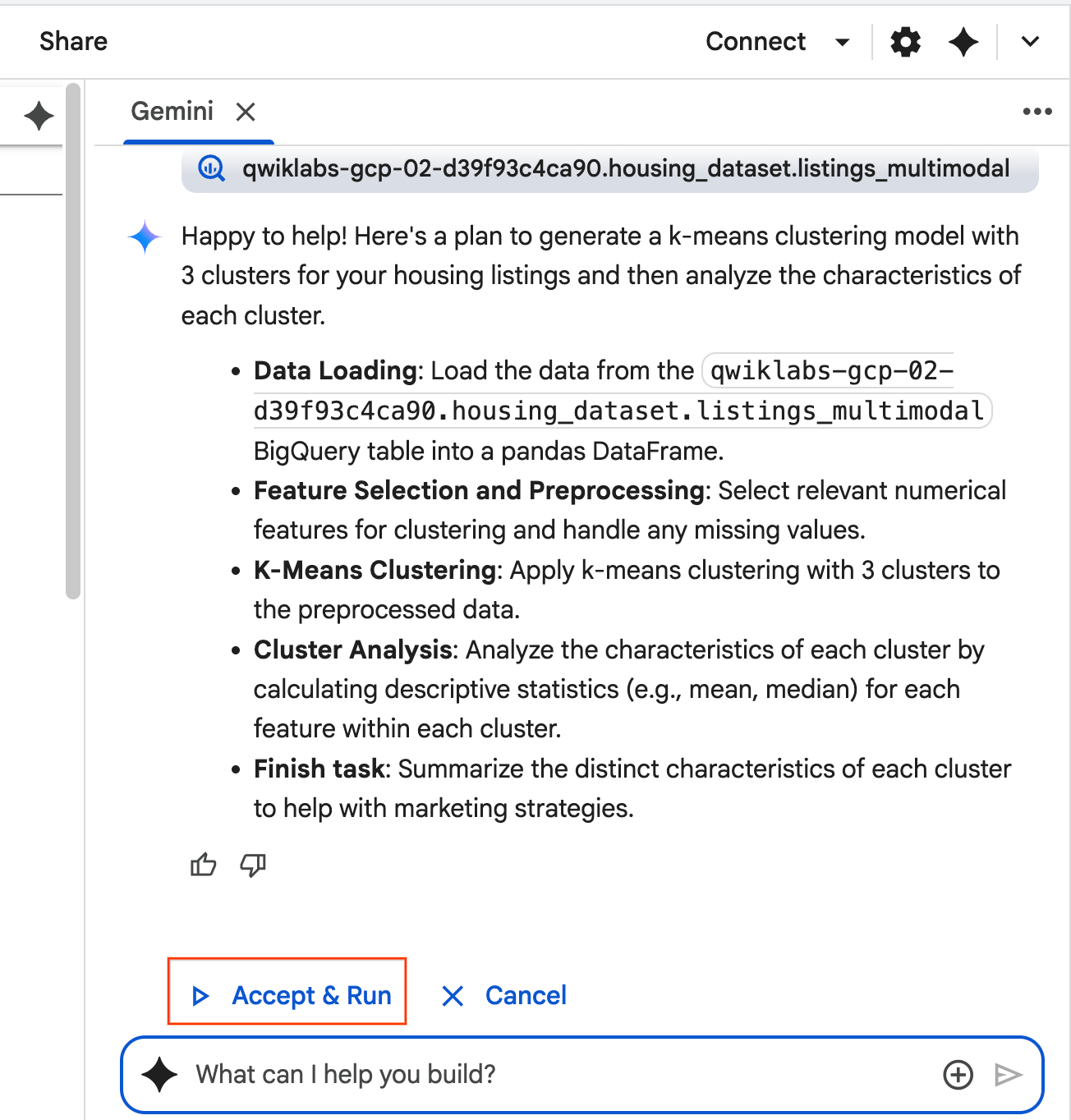
- El agente te pide que Aceptes y ejecutes cada bloque de código que genera. Esto mantiene la interacción humana. Puedes revisar o editar el código y continuar con cada uno de los pasos hasta que termines.
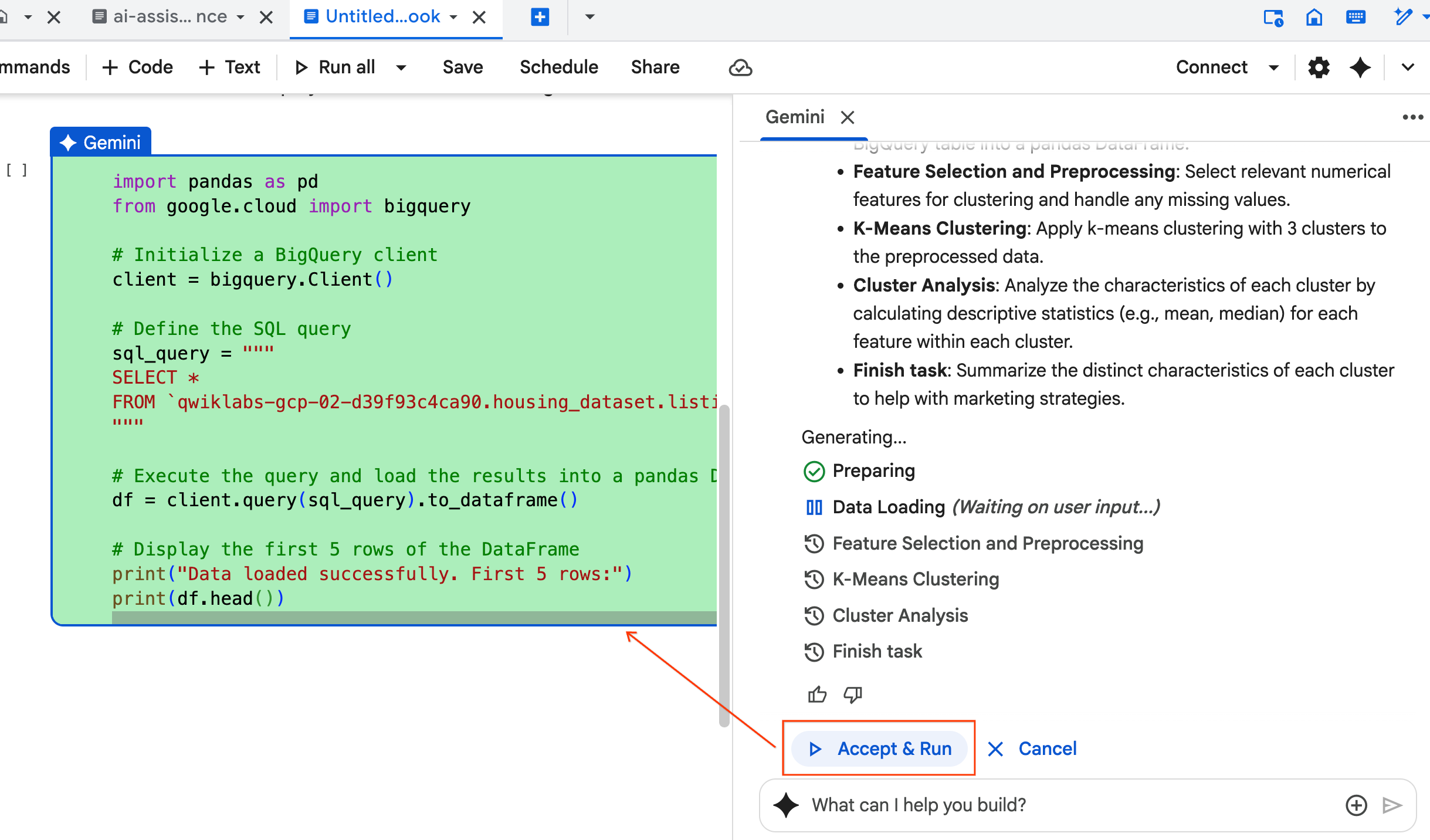
- Cuando termines, cierra la nueva pestaña del notebook y regresa a la pestaña original de
ai-assisted-data-science.ipynbpara continuar con la sección final del lab.
12. Búsqueda multimodal con Embeddings y Vector Search
En esta sección final, implementarás la búsqueda multimodal directamente en BigQuery. Esto permite realizar búsquedas intuitivas, como encontrar casas según una descripción de texto o encontrar casas que se parezcan a una imagen de muestra.
El proceso funciona convirtiendo primero cada imagen de la casa en una representación numérica llamada incorporación. Un embedding captura el significado semántico de una imagen, lo que te permite encontrar elementos similares comparando sus vectores numéricos.
Usarás el modelo multimodalembedding para generar estos vectores para todas tus fichas. Después de crear un índice de vectores para acelerar las búsquedas, realizas dos tipos de búsquedas de similitud: de texto a imagen (para encontrar casas que coincidan con una descripción) y de imagen a imagen (para encontrar casas que se parezcan a una imagen de muestra).
Completarás todo esto en BigQuery, con funciones como ML.GENERATE_EMBEDDING para generar embeddings o VECTOR_SEARCH para la búsqueda de similitud.
13. Limpieza
Para limpiar todos los recursos de Google Cloud que se usaron en este proyecto, puedes borrar el proyecto de Google Cloud.
Como alternativa, puedes borrar los recursos individuales que creaste. Para ello, ejecuta el siguiente código en una celda nueva del notebook:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
Por último, puedes borrar el notebook:
- En el panel Explorador de BigQuery Studio, expande tu proyecto y el nodo Notebooks.
- Haz clic en los tres puntos verticales junto al notebook
ai-assisted-data-science. - Selecciona Borrar.
14. ¡Felicitaciones!
¡Felicitaciones por completar el codelab!
Temas abordados
- Prepara un conjunto de datos sin procesar de fichas de bienes raíces para el análisis a través de la ingeniería de atributos.
- Enriquece las fichas con las funciones de IA de BigQuery para analizar las fotos de las casas y detectar las características visuales clave.
- Crea y evalúa un modelo de K-means con BigQuery Machine Learning (BQML) para segmentar propiedades en clústeres distintos.
- Automatiza la creación de modelos con el agente de ciencia de datos para generar un modelo de agrupamiento en clústeres con Python.
- Generar embeddings para imágenes de casas y potenciar una herramienta de búsqueda visual que encuentre casas similares con consultas de texto o imágenes