
۱. مقدمه
نمای کلی
در این آزمایشگاه، شما یک گردش کار چندوجهی علوم داده در BigQuery را بررسی خواهید کرد که حول یک سناریوی املاک و مستغلات شکل گرفته است. شما با یک مجموعه داده خام از فهرست خانهها و تصاویر آنها شروع خواهید کرد، این دادهها را با هوش مصنوعی غنیسازی میکنید تا ویژگیهای بصری را استخراج کنید، یک مدل خوشهبندی برای کشف بخشهای متمایز بازار میسازید و در نهایت، یک ابزار جستجوی بصری قدرتمند با استفاده از جاسازیهای برداری ایجاد میکنید.
شما این گردش کار مبتنی بر SQL را با یک رویکرد هوش مصنوعی مدرن و مولد مقایسه خواهید کرد که در آن از عامل علوم داده برای تولید خودکار یک مدل خوشهبندی مبتنی بر پایتون از یک پیام متنی ساده استفاده میشود.
آنچه یاد خواهید گرفت
- یک مجموعه داده خام از فهرست املاک و مستغلات برای تجزیه و تحلیل از طریق مهندسی ویژگیها آماده کنید .
- با استفاده از توابع هوش مصنوعی BigQuery برای تجزیه و تحلیل عکسهای خانهها و یافتن ویژگیهای بصری کلیدی، فهرستها را غنیتر کنید .
- ساخت و ارزیابی یک مدل K-means با استفاده از یادگیری ماشین BigQuery (BQML) برای تقسیمبندی ویژگیها به خوشههای مجزا.
- با استفاده از Data Science Agent برای تولید یک مدل خوشهبندی با پایتون، ایجاد مدل را خودکار کنید .
- برای تصاویر خانهها، جاسازیهایی ایجاد کنید تا ابزار جستجوی بصری را تقویت کنید و خانههای مشابه را با جستجوی متن یا تصویر پیدا کنید.
پیشنیازها
قبل از شروع این آزمایشگاه، باید با موارد زیر آشنا باشید:
- برنامهنویسی مقدماتی SQL و پایتون.
- اجرای کد پایتون در نوتبوک ژوپیتر
۲. قبل از شروع
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
فعال کردن APIها با Cloud Shell
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید:

- پس از اتصال به Cloud Shell، این دستور را برای تأیید احراز هویت خود در Cloud Shell اجرا کنید:
gcloud auth list
- برای تأیید اینکه پروژه شما برای استفاده با gcloud پیکربندی شده است، دستور زیر را اجرا کنید:
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
فعال کردن APIها
- برای فعال کردن تمام APIها و سرویسهای مورد نیاز، این دستور را اجرا کنید:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- در صورت اجرای موفقیتآمیز دستور، باید پیامی مشابه آنچه در زیر نشان داده شده است را مشاهده کنید:
Operation "operations/..." finished successfully.
- از کلود شل خارج شوید.
۳. دفترچه آزمایشگاه را در BigQuery Studio باز کنید
پیمایش رابط کاربری:
- در کنسول گوگل کلود، به منوی ناوبری > BigQuery بروید.
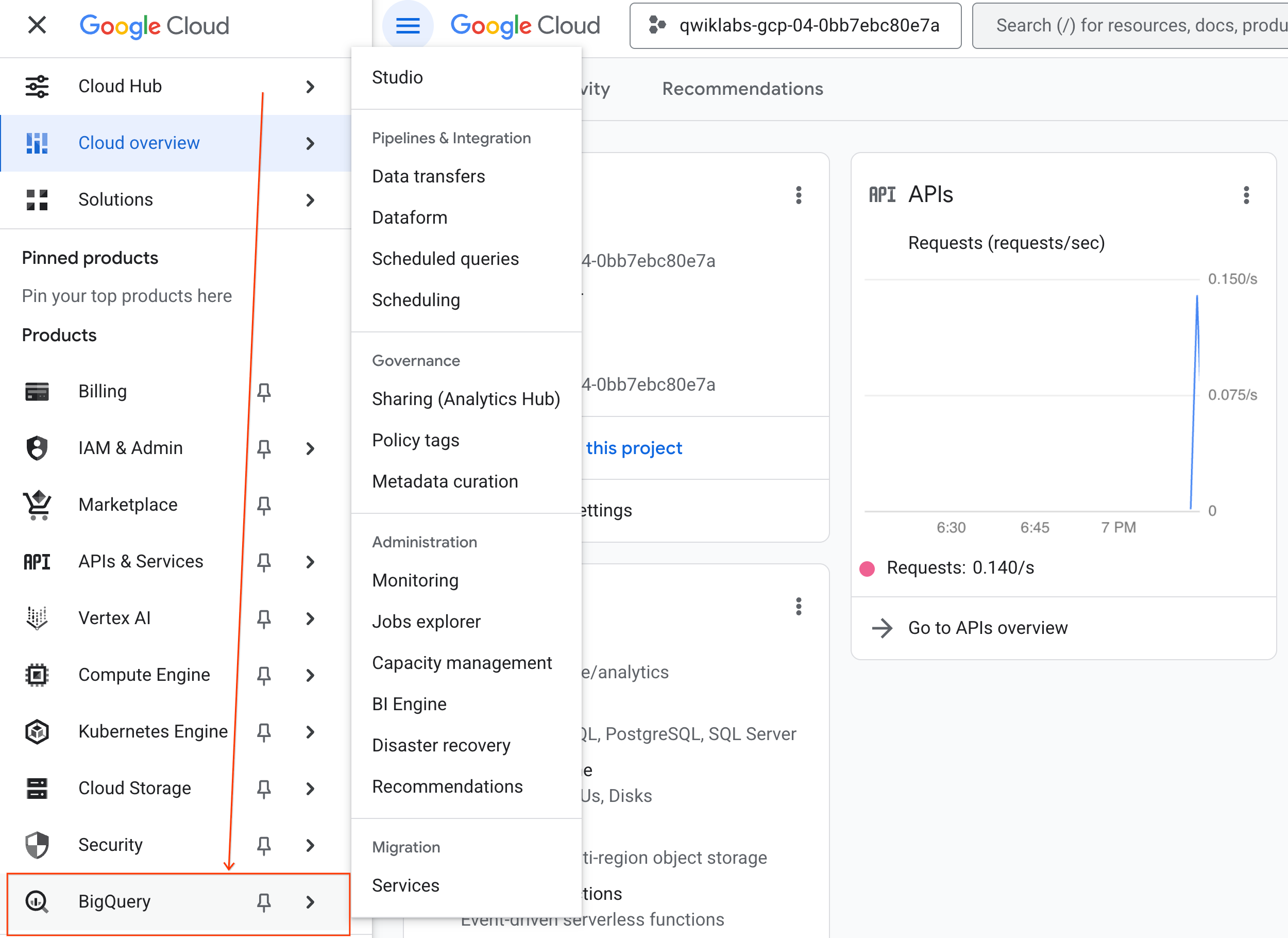
- در پنل BigQuery Studio ، روی دکمهی فلش کشویی کلیک کنید، موس را روی Notebook نگه دارید و سپس Upload را انتخاب کنید.
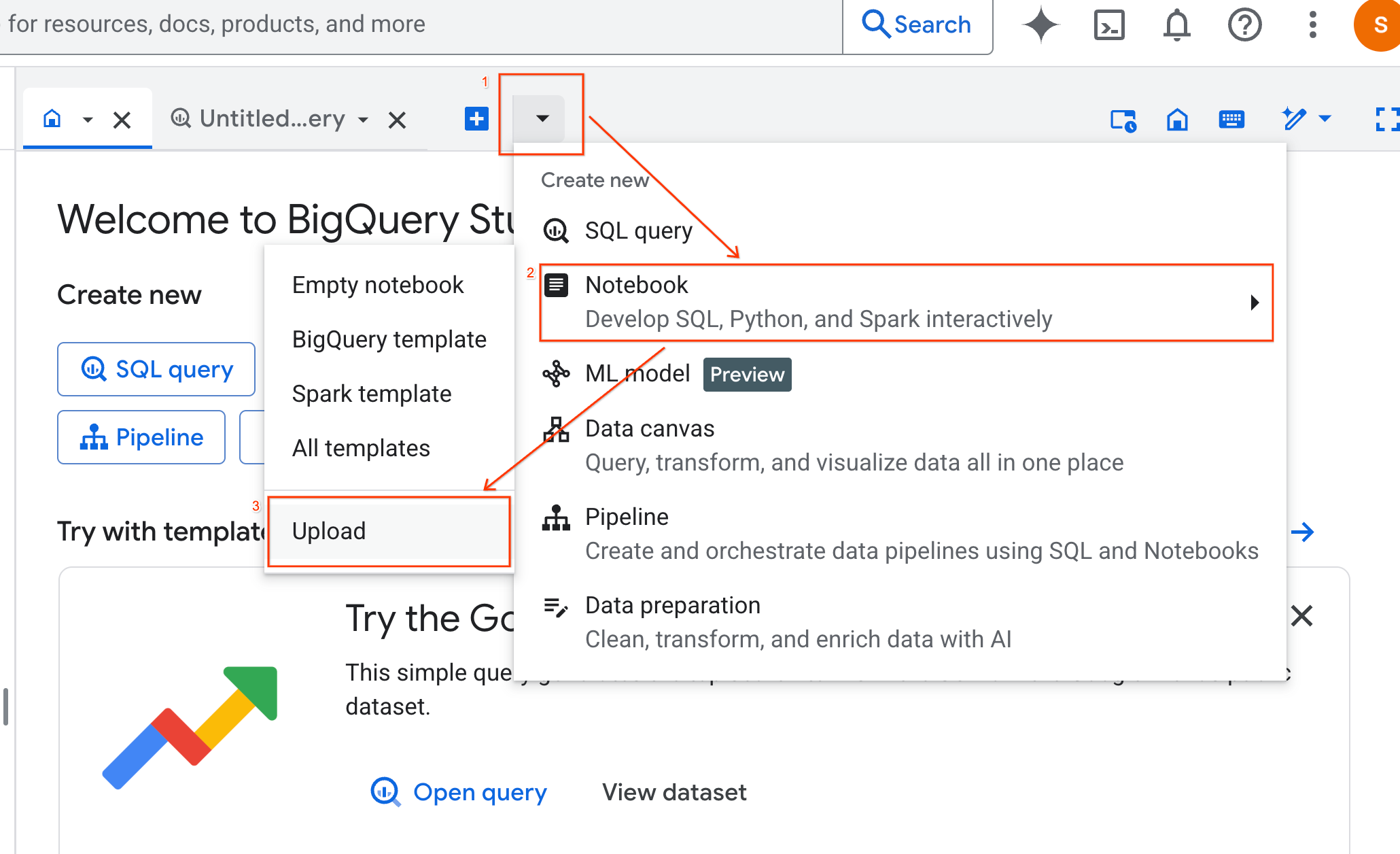
- دکمه رادیویی URL را انتخاب کنید و URL زیر را وارد کنید:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- منطقه را روی
us-central1تنظیم کنید و روی آپلود کلیک کنید.
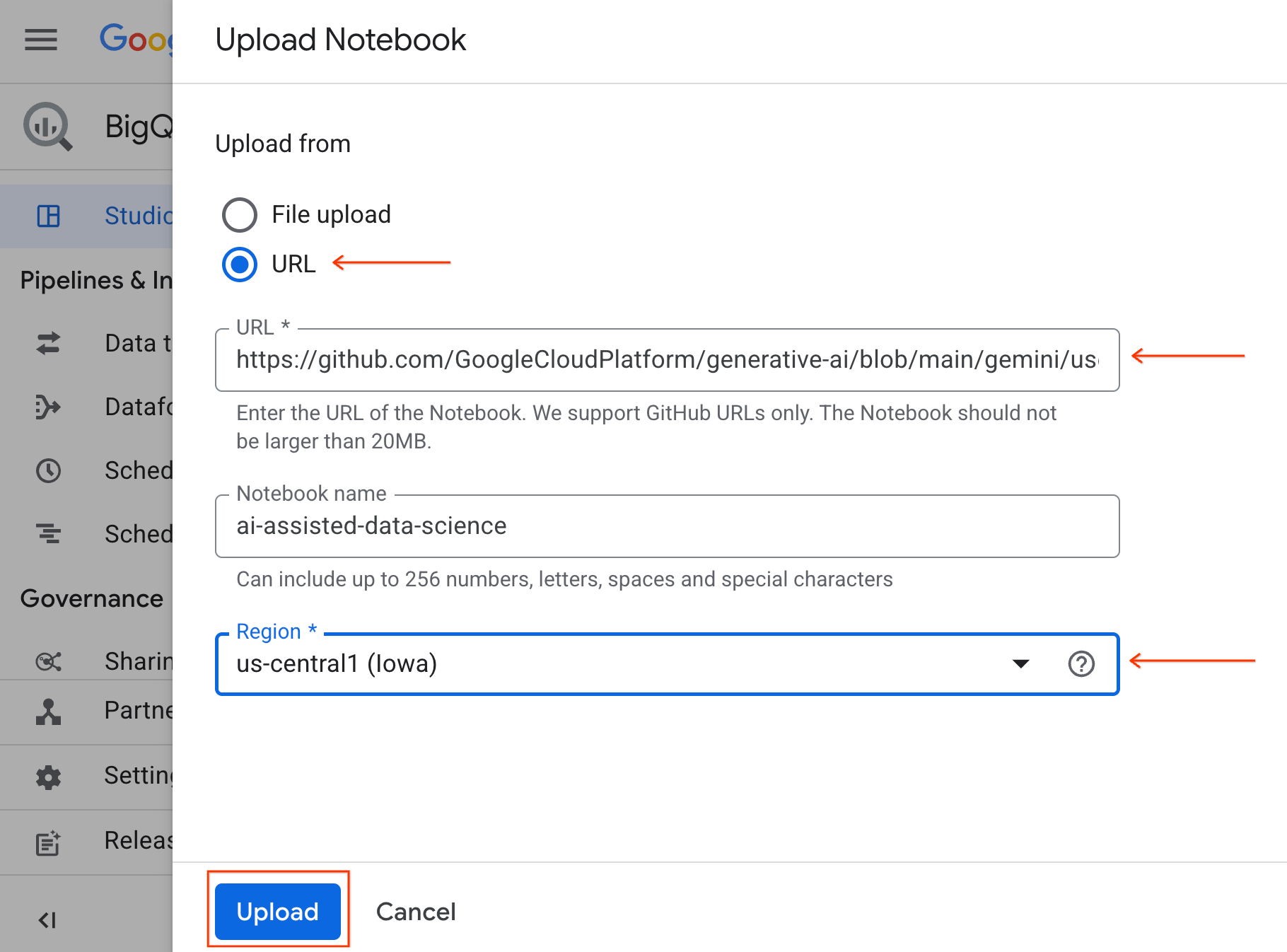
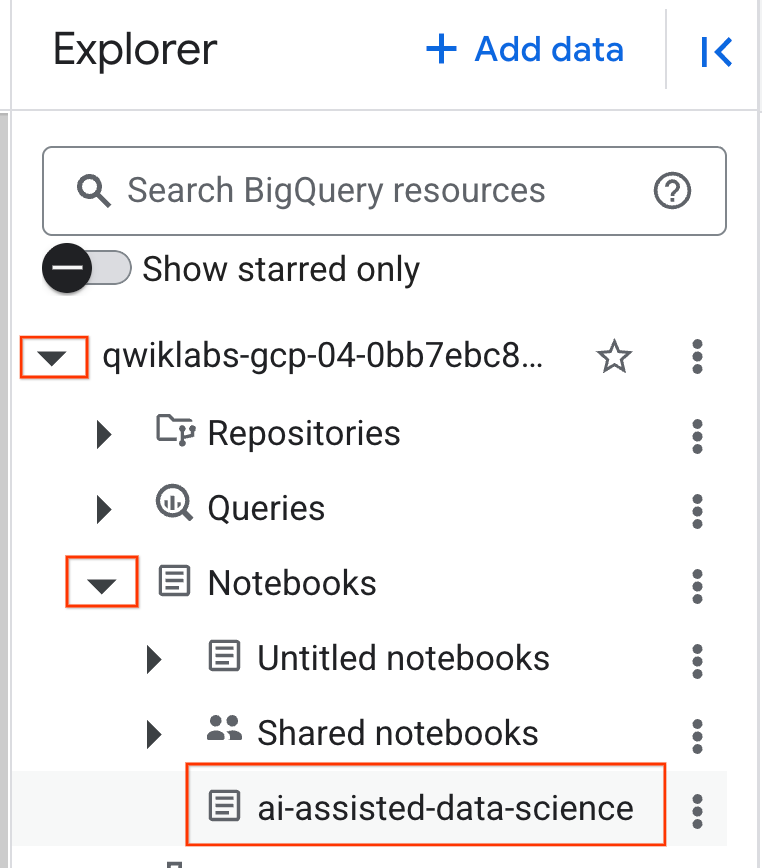
- برای باز کردن دفترچه یادداشت، روی فلش کشویی در پنجره Explorer که حاوی شناسه پروژه شماست کلیک کنید. سپس روی منوی کشویی Notebooks کلیک کنید. روی Notebook
ai-assisted-data-scienceکلیک کنید.
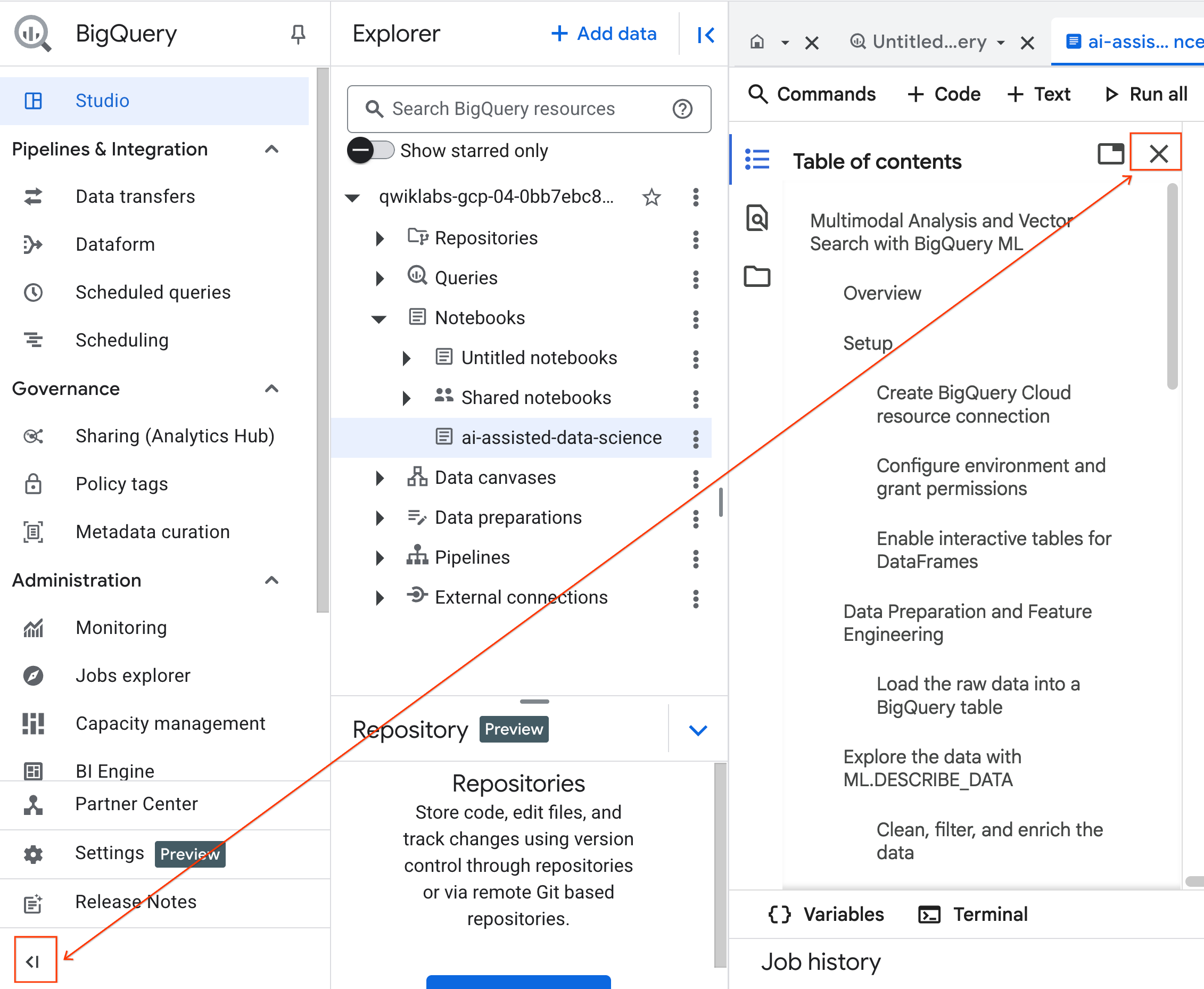
- (اختیاری) برای فضای بیشتر، منوی ناوبری BigQuery و فهرست مطالب دفترچه یادداشت را جمع کنید.
۴. به یک Runtime متصل شوید و کد راهاندازی را اجرا کنید
- روی اتصال کلیک کنید. اگر پنجرهای ظاهر شد، با نام کاربری خود، Colab Enterprise را مجاز کنید. نوتبوک شما بهطور خودکار به یک زمان اجرا متصل میشود. تکمیل این فرآیند ممکن است چند دقیقه طول بکشد.
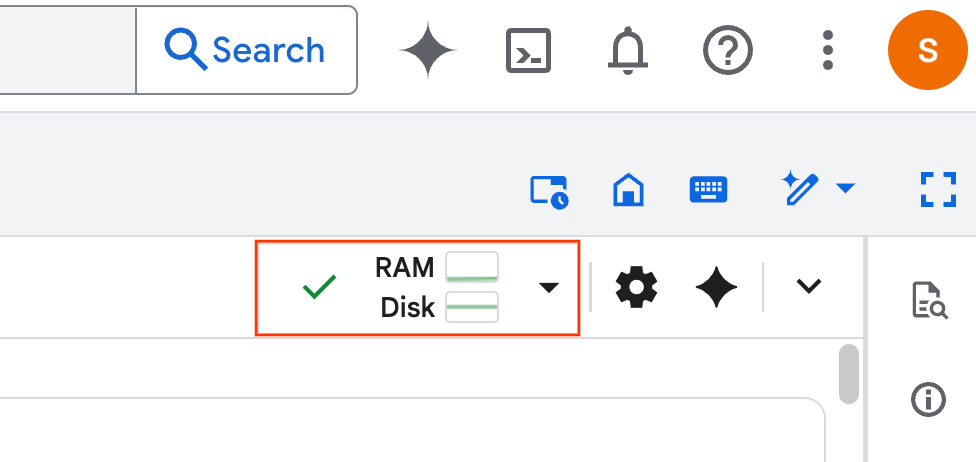
- پس از مشخص شدن زمان اجرا، تصویر زیر را مشاهده خواهید کرد:
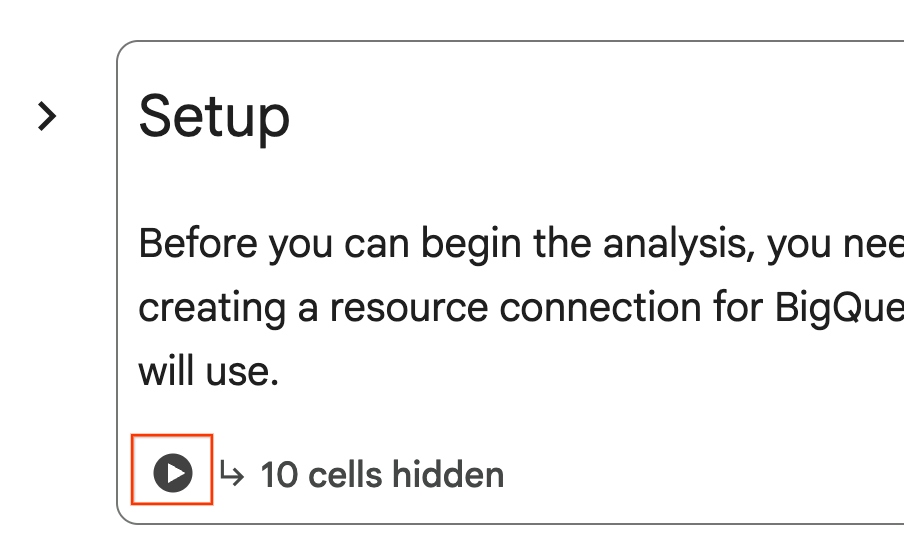
- در داخل دفترچه یادداشت، به بخش تنظیمات بروید. روی دکمه «اجرا» در کنار سلولهای پنهان کلیک کنید. این کار چند منبع لازم برای آزمایشگاه در پروژه شما را ایجاد میکند. تکمیل این فرآیند ممکن است یک دقیقه طول بکشد. در این فاصله میتوانید سلولهای زیر تنظیمات را بررسی کنید.
۵. آمادهسازی دادهها و مهندسی ویژگیها
در این بخش، شما با اولین گام مهم در هر پروژه علم داده آشنا خواهید شد: آمادهسازی دادهها. شما با ایجاد یک مجموعه داده BigQuery برای سازماندهی کار خود شروع میکنید و سپس دادههای خام املاک و مستغلات/مسکن را از یک فایل CSV در Cloud Storage در یک جدول جدید بارگذاری میکنید.
سپس، این دادههای خام را به یک جدول تمیز با ویژگیهای جدید تبدیل خواهید کرد. این شامل فیلتر کردن لیستها، ایجاد یک ویژگی جدید property_age و آمادهسازی دادههای تصویر برای تحلیل چندوجهی است.
۶. غنیسازی چندوجهی با توابع هوش مصنوعی
حالا شما با استفاده از قدرت هوش مصنوعی مولد، دادههای خود را غنیسازی خواهید کرد. در این بخش، از توابع هوش مصنوعی داخلی BigQuery برای تجزیه و تحلیل تصاویر مربوط به هر آگهی خانه استفاده میکنید.
با اتصال BigQuery به یک مدل Gemini ، میتوانید ویژگیهای جدید و ارزشمندی را از تصاویر (مانند اینکه آیا ملک در نزدیکی آب است یا خیر و شرح مختصری از خانه) مستقیماً با SQL استخراج کنید.
۷. آموزش مدل با خوشهبندی K-Means
با مجموعه دادههای غنیشدهی جدید، شما آمادهی ساخت یک مدل یادگیری ماشین هستید. هدف شما تقسیمبندی فهرست خانهها به گروههای مجزا است و این کار را با آموزش مستقیم یک مدل خوشهبندی K-means در BigQuery با استفاده از BigQuery Machine Learning (BQML) انجام میدهید. به عنوان بخشی از این مرحله، شما همچنین مدل را در Agent Platform AI Model Registry ثبت میکنید و آن را فوراً در اکوسیستم گستردهتر MLOps در Google Cloud در دسترس قرار میدهید.
برای تأیید ثبت موفقیتآمیز مدل خود، میتوانید با دنبال کردن مراحل زیر، آن را در رجیستری مدل پلتفرم عامل پیدا کنید:
- در کنسول گوگل کلود، روی منوی ناوبری (☰) در گوشه بالا سمت چپ کلیک کنید.
- به بخش پلتفرم عامل بروید و روی مدلها کلیک کنید.
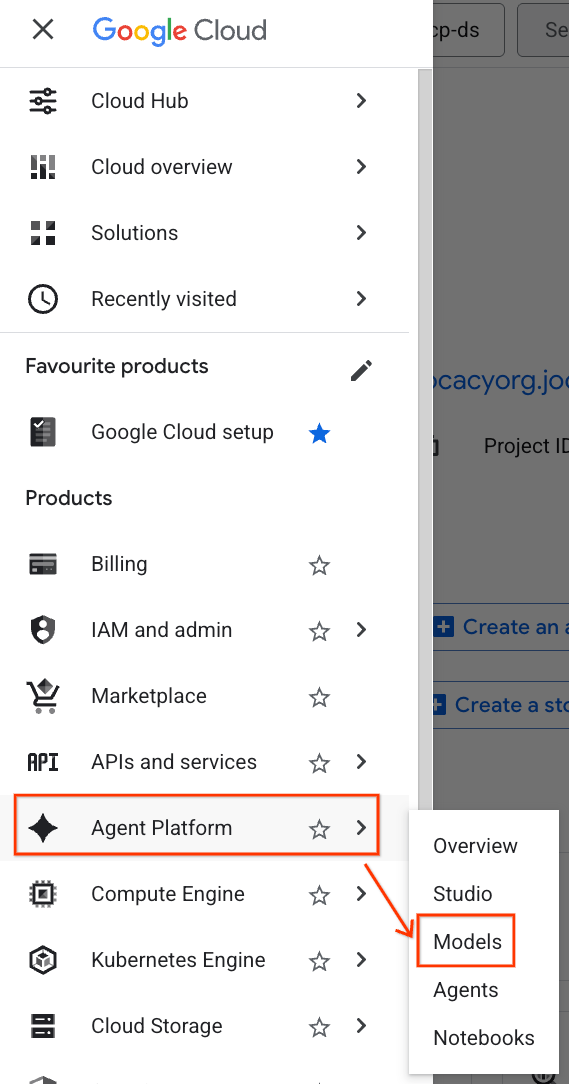
- روی دکمهی Model Registry که در تصویر مشخص شده است کلیک کنید.
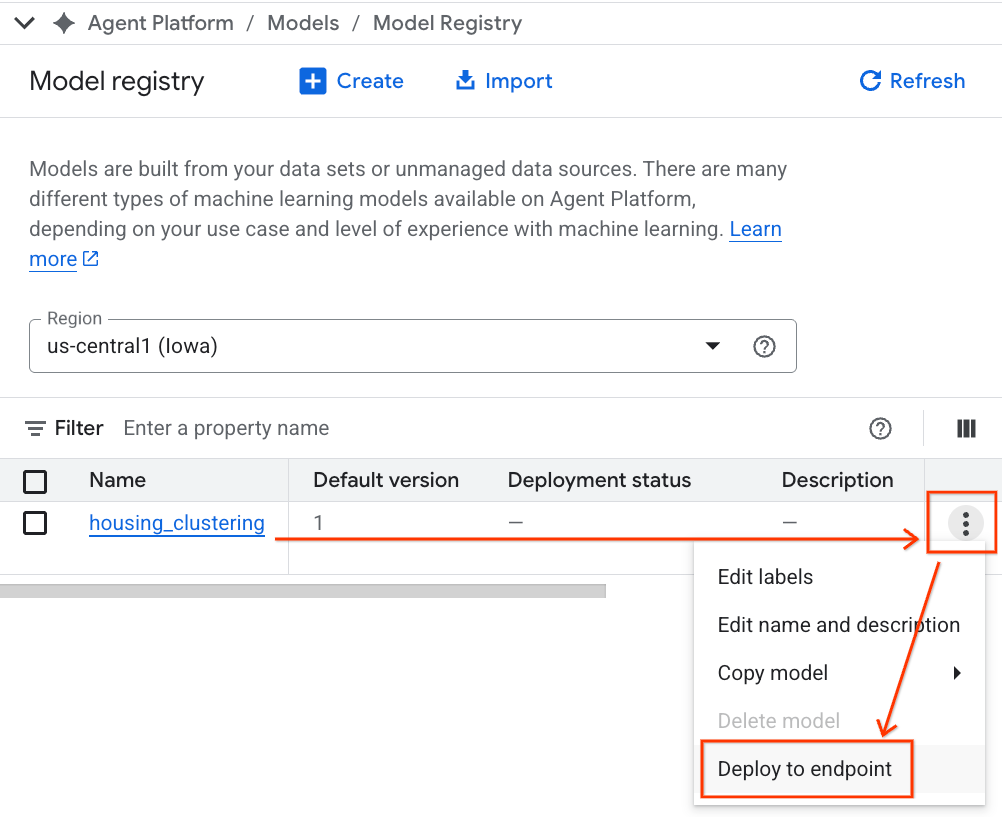
- مدل BQML خود را در کنار سایر مدلهای سفارشی خود مشاهده خواهید کرد. در لیست مدلها، مدلی با نام housing_clustering را پیدا کنید. میتوانید گام بعدی را Deploy to an endpoint بردارید، که مدل شما را برای پیشبینیهای آنلاین و بلادرنگ خارج از محیط BigQuery در دسترس قرار میدهد.
پس از بررسی رجیستری مدل، میتوانید با انجام این مراحل به دفترچه یادداشت Colab خود در BigQuery بازگردید:
- در منوی ناوبری (☰)، به BigQuery > Studio بروید.
- منوهای موجود در پنل کاوش را باز کنید تا دفترچه یادداشت خود را پیدا کرده و آن را باز کنید.
۸. ارزیابی و پیشبینی مدل
پس از آموزش مدل، مرحله بعدی درک خوشههایی است که ایجاد کرده است. در اینجا، شما از توابع یادگیری ماشین BigQuery مانند ML.EVALUATE و ML.CENTROIDS برای تجزیه و تحلیل کیفیت مدل و ویژگیهای تعیینکننده هر بخش استفاده میکنید.
سپس از ML.PREDICT برای اختصاص هر خانه به یک خوشه استفاده میکنید. با اجرای این پرسوجو با دستور جادویی %%bigquery df ، نتایج را در یک DataFrame از pandas به نام df ذخیره میکنید. این کار باعث میشود دادهها بلافاصله برای مراحل بعدی پایتون در دسترس باشند. این امر قابلیت همکاری بین SQL و پایتون را در Colab Enterprise برجسته میکند.
۹. خوشهها را تجسم و تفسیر کنید
با بارگذاری پیشبینیهایتان در یک DataFrame، میتوانید مصورسازیهایی برای زنده کردن دادهها ایجاد کنید. در این بخش، از کتابخانههای محبوب پایتون مانند Matplotlib برای بررسی تفاوتهای بین بخشهای مسکن استفاده خواهید کرد.
شما نمودارهای جعبهای و میلهای را برای مقایسه بصری ویژگیهای کلیدی مانند قیمت و سن ملک ایجاد خواهید کرد و درک شهودی از هر خوشه را آسان خواهید کرد.
۱۰. ایجاد توصیفات خوشه با مدلهای Gemini
در حالی که نمودارها و مراکز عددی قدرتمند هستند، هوش مصنوعی مولد به شما این امکان را میدهد که یک قدم جلوتر بروید و برای هر بخش مسکن، شخصیتهای غنی و کیفی ایجاد کنید. این به شما کمک میکند تا نه تنها بفهمید خوشهها چیستند ، بلکه بفهمید چه کسانی را نمایندگی میکنند.
در این بخش، ابتدا آمار میانگین هر خوشه، مانند قیمت و متراژ را جمعآوری میکنید. سپس، این دادهها را به یک درخواست برای مدل Gemini ارسال میکنید. سپس به مدل دستور میدهید که به عنوان یک متخصص املاک عمل کند و خلاصهای دقیق، شامل ویژگیهای کلیدی و یک خریدار هدف برای هر بخش، تولید کند. نتیجه، مجموعهای از توضیحات واضح و قابل خواندن توسط انسان است که خوشهها را بلافاصله برای یک تیم بازاریابی قابل فهم و عملی میکند.
میتوانید دستورالعمل را به دلخواه تغییر دهید و نتایج را آزمایش کنید!
۱۱. مدلسازی خودکار با عامل علوم داده
اکنون، شما یک گردش کار قدرتمند و جایگزین را بررسی خواهید کرد. به جای نوشتن کد به صورت دستی، از عامل یکپارچه علوم داده برای تولید خودکار یک گردش کار کامل مدل خوشهبندی از یک اعلان زبان طبیعی واحد استفاده خواهید کرد.
برای تولید و اجرای مدل با استفاده از عامل، این مراحل را دنبال کنید:
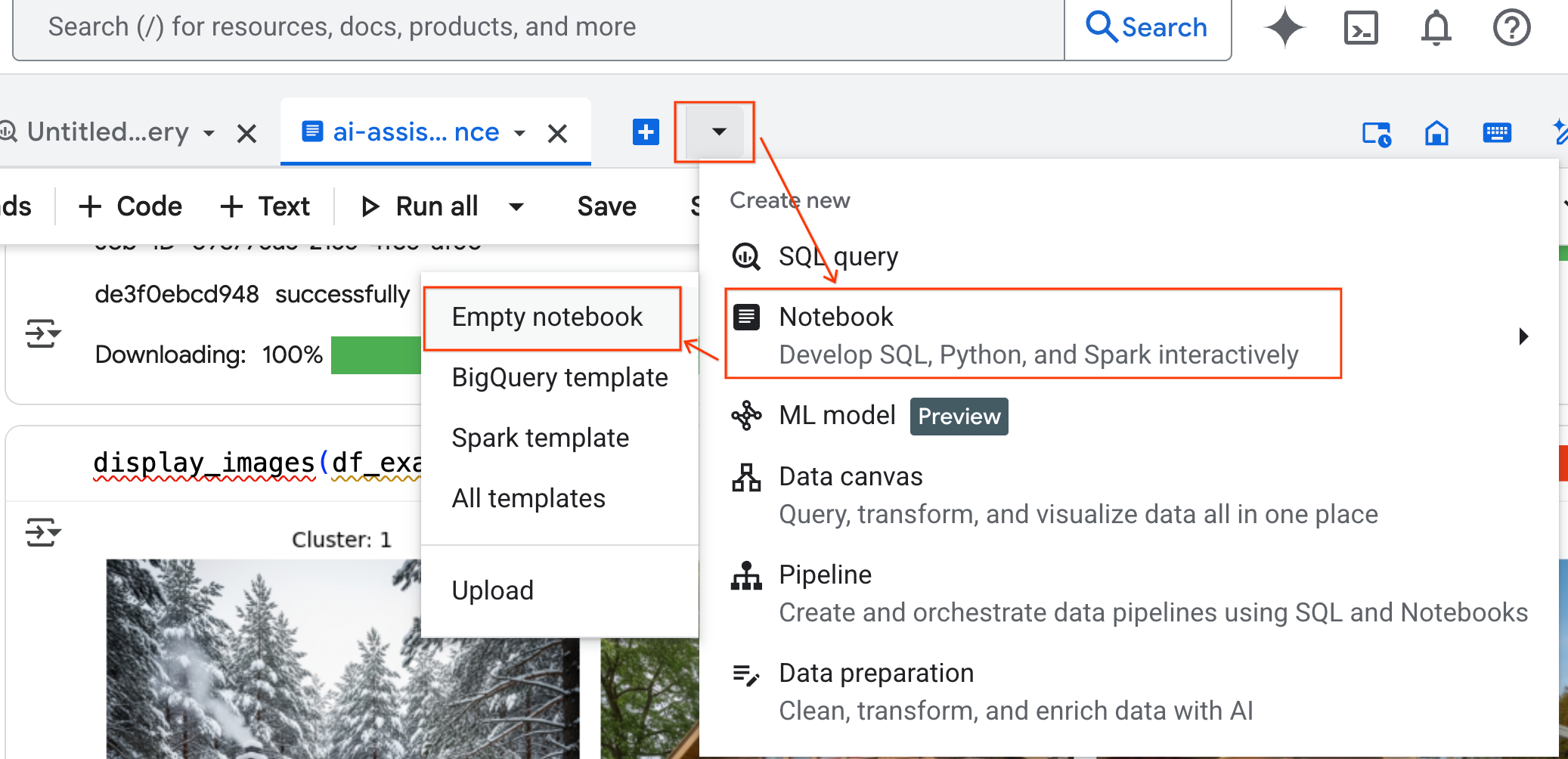
- در پنل BigQuery Studio ، روی دکمه فلش کشویی کلیک کنید، موس را روی Notebook ببرید و سپس Empty Notebook را انتخاب کنید. این کار تضمین میکند که کد عامل با دفترچه یادداشت آزمایشگاهی اصلی شما تداخل نداشته باشد.
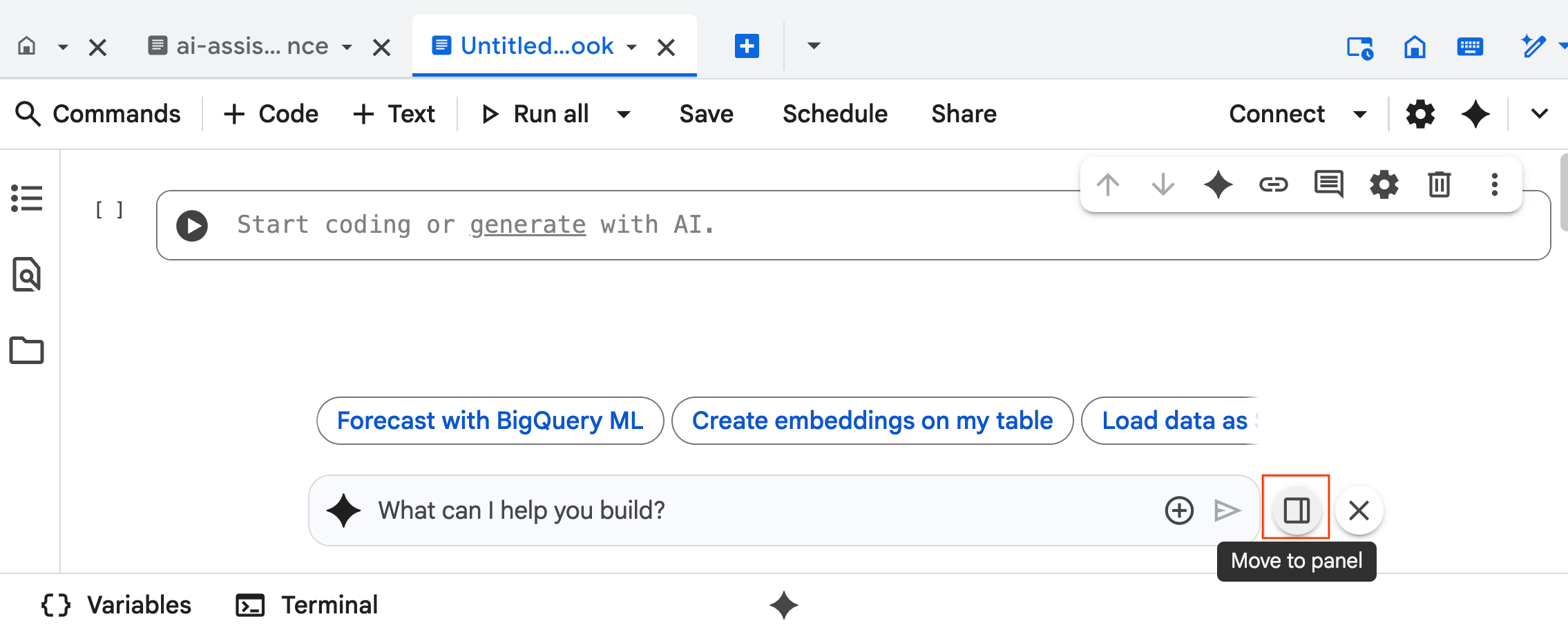
- رابط چت عامل علوم داده در پایین دفترچه باز میشود. برای پین کردن چت به سمت راست، روی دکمه « انتقال به پنل» کلیک کنید.
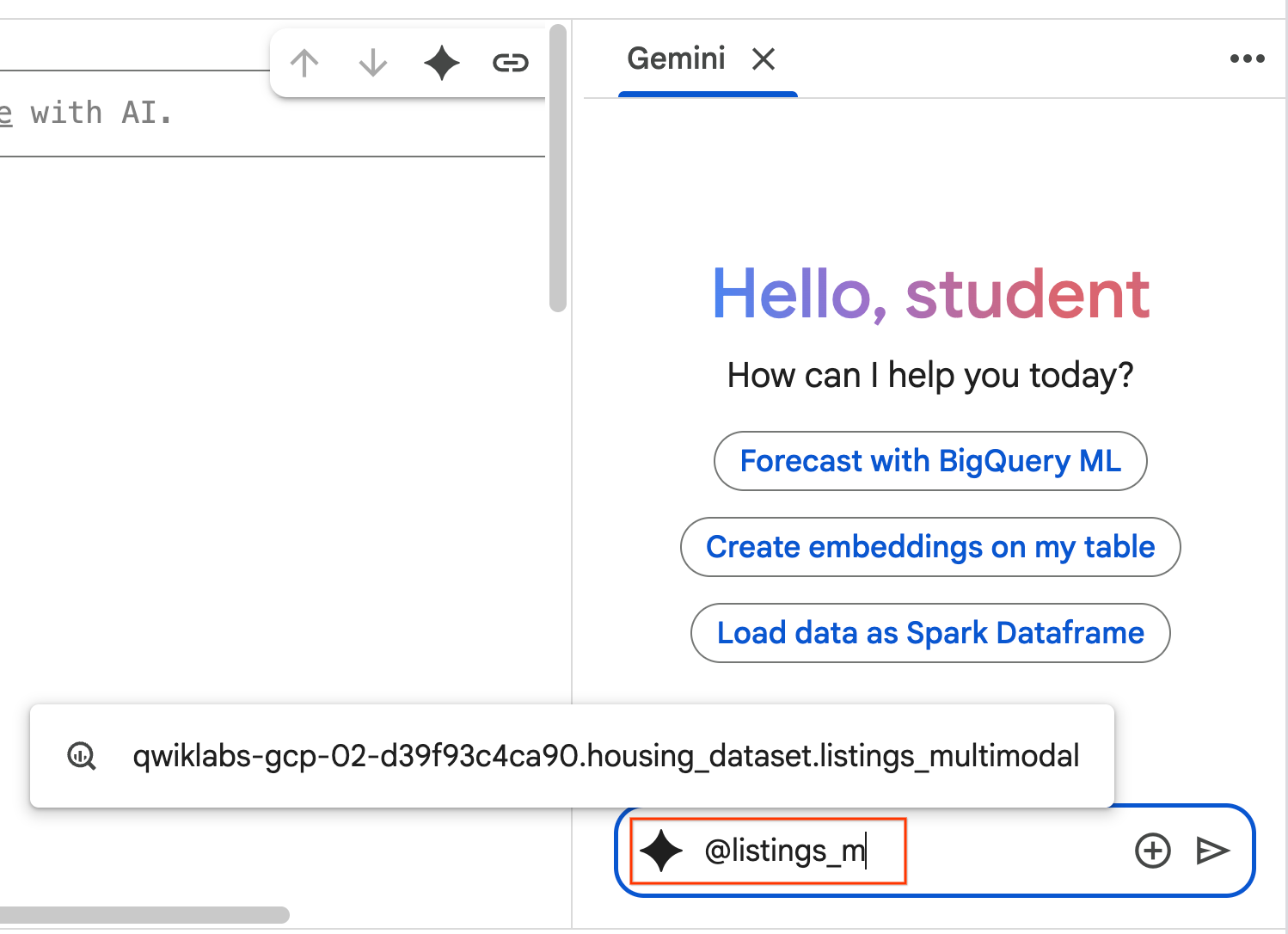
- شروع به تایپ
@listing_multimodal در پنجره چت کنید و روی جدول کلیک کنید . این کار به طور صریح جدولlistings_multimodalرا به عنوان زمینه تنظیم میکند.
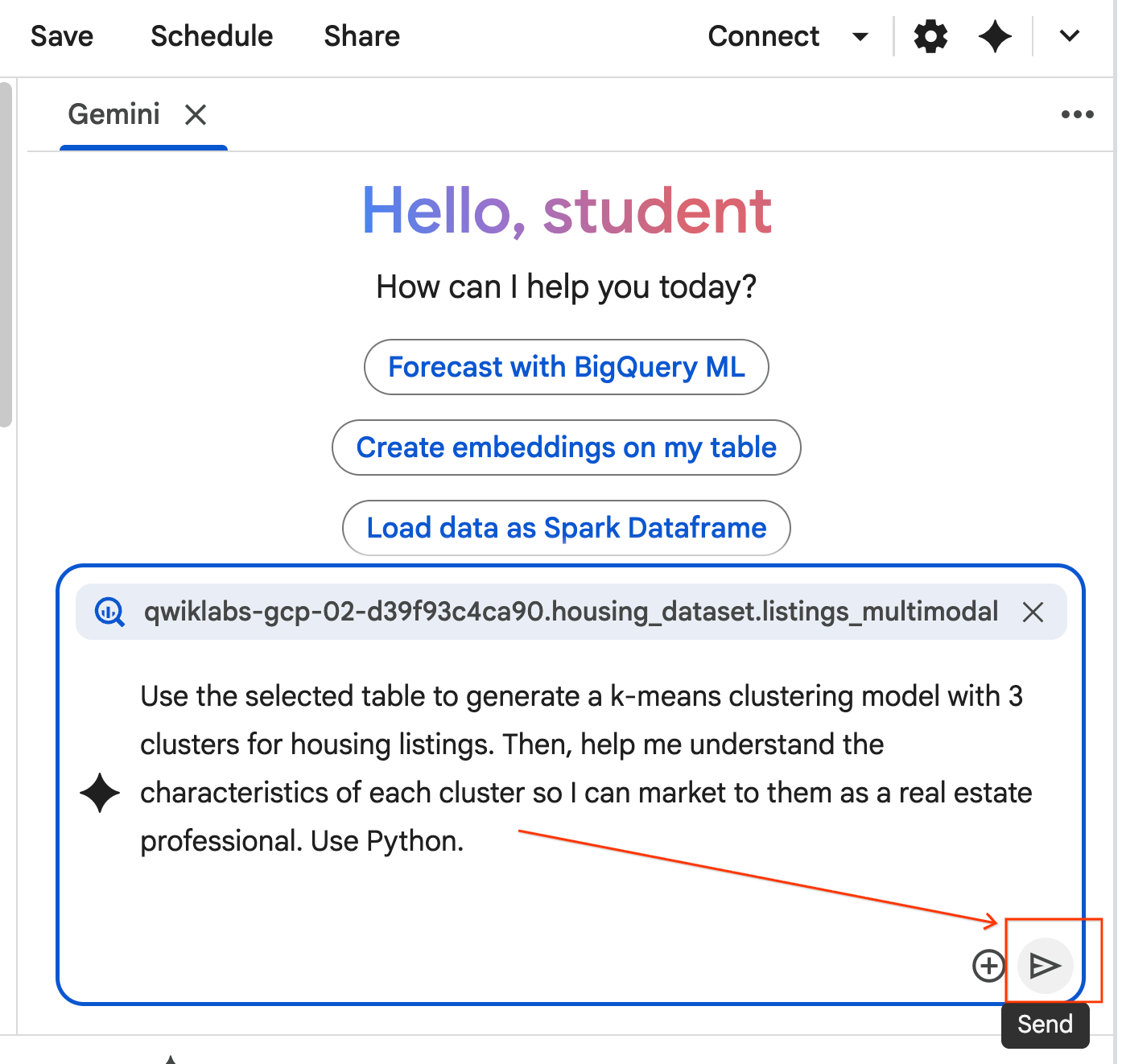
- متن زیر را کپی کرده و در کادر گفتگوی نماینده وارد کنید. پس از آن، برای ارسال متن به نماینده، روی ارسال کلیک کنید.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- عامل فکر میکند و طرحی را تدوین میکند. اگر با این طرح موافق هستید، روی «پذیرش و اجرا» کلیک کنید. عامل کد پایتون را در یک یا چند سلول جدید تولید میکند.
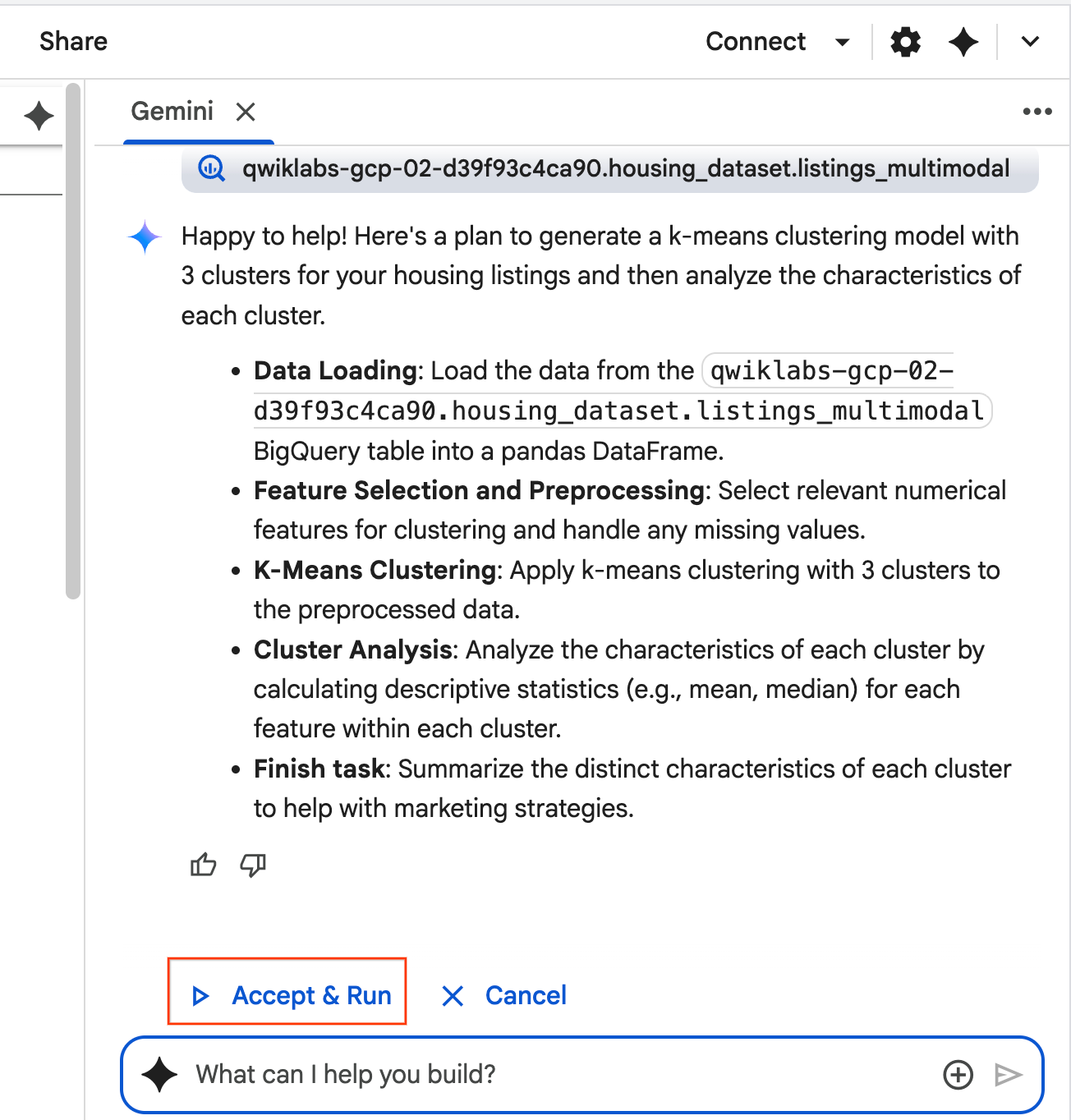
- عامل از شما میخواهد که هر بلوک کدی را که تولید میکند، بپذیرید و اجرا کنید . این کار باعث میشود که انسان در حلقه باشد. میتوانید کد را مرور یا ویرایش کنید و هر یک از مراحل را تا پایان کار ادامه دهید.
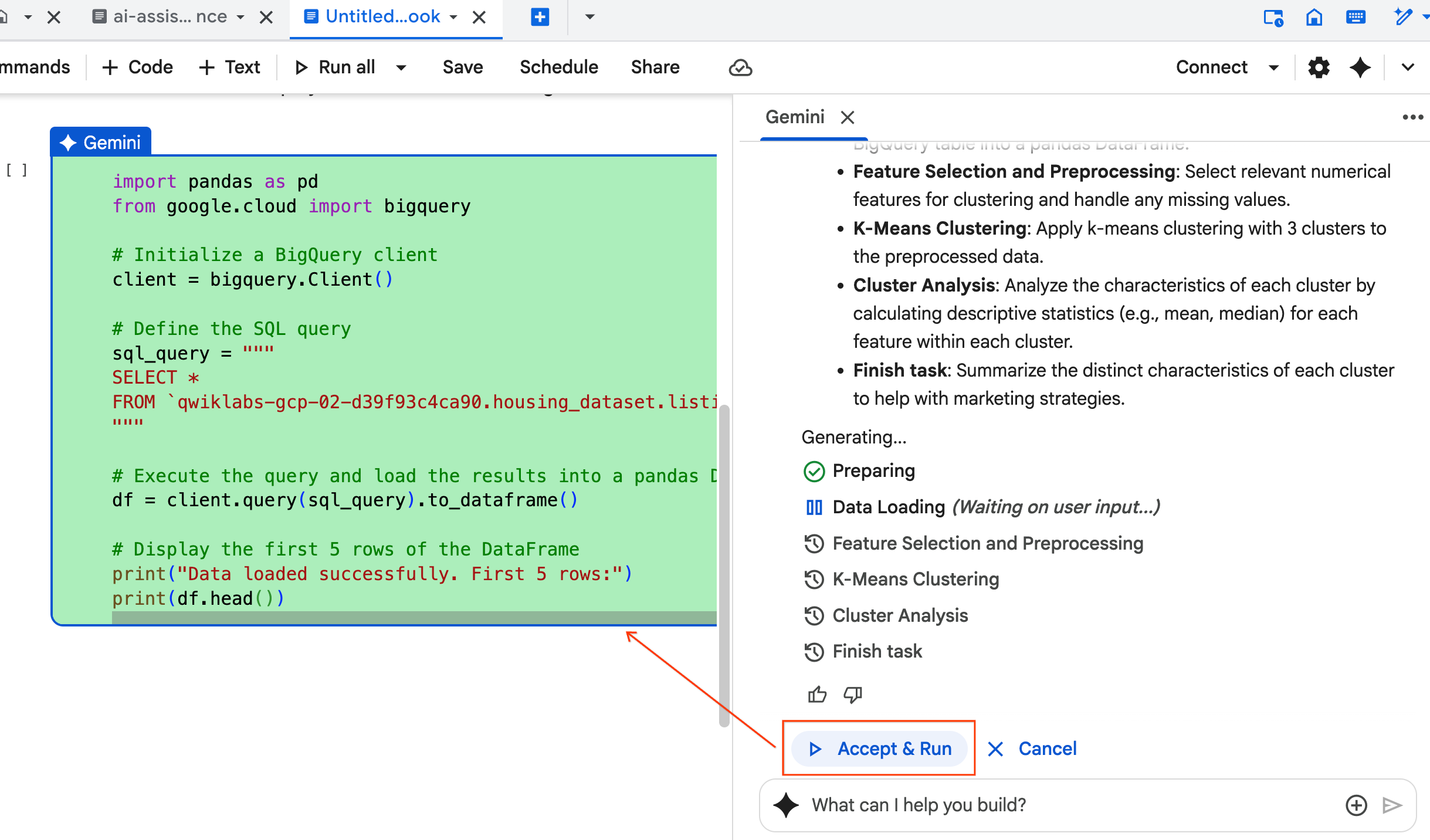
- پس از اتمام، کافیست این برگه جدید دفترچه یادداشت را ببندید و به برگه اصلی
ai-assisted-data-science.ipynbبرگردید تا بخش پایانی آزمایشگاه را ادامه دهید.
۱۲. جستجوی چندوجهی با جاسازیها و جستجوی برداری
در این بخش پایانی، شما جستجوی چندوجهی را مستقیماً در BigQuery پیادهسازی میکنید. این امر امکان جستجوهای شهودی، مانند یافتن خانهها بر اساس توضیحات متنی یا یافتن خانههایی که شبیه یک تصویر نمونه هستند را فراهم میکند.
این فرآیند با تبدیل اولیه هر تصویر خانه به یک نمایش عددی به نام جاسازی (embedding) انجام میشود. جاسازی، معنای معنایی یک تصویر را ثبت میکند و به شما امکان میدهد موارد مشابه را با مقایسه بردارهای عددی آنها پیدا کنید.
شما از مدل multimodalembedding برای تولید این بردارها برای همه فهرستهای خود استفاده خواهید کرد. پس از ایجاد یک شاخص برداری برای تسریع جستجوها، دو نوع جستجوی شباهت را انجام میدهید: متن به تصویر (یافتن خانههایی که با توضیحات مطابقت دارند) و تصویر به تصویر (یافتن خانههایی که شبیه یک تصویر نمونه هستند).
شما تمام این کارها را در BigQuery با استفاده از توابعی مانند ML.GENERATE_EMBEDDING برای تولید جاسازیها یا VECTOR_SEARCH برای جستجوی شباهت انجام خواهید داد.
۱۳. تمیز کردن
برای پاک کردن تمام منابع Google Cloud استفاده شده در این پروژه، میتوانید پروژه Google Cloud را حذف کنید .
روش دیگر این است که میتوانید منابع تکی ایجاد شده را با اجرای کد زیر در یک سلول جدید در دفترچه یادداشت خود حذف کنید:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
در نهایت، میتوانید خود دفترچه یادداشت را حذف کنید:
- در پنل Explorer در BigQuery Studio، پروژه و گره Notebooks را باز کنید.
- روی سه نقطه عمودی کنار دفترچه یادداشت
ai-assisted-data-scienceکلیک کنید. - حذف را انتخاب کنید.
۱۴. تبریک میگویم!
تبریک بابت تکمیل Codelab!
آنچه ما پوشش دادهایم
- یک مجموعه داده خام از فهرست املاک و مستغلات برای تجزیه و تحلیل از طریق مهندسی ویژگیها آماده کنید .
- با استفاده از توابع هوش مصنوعی BigQuery برای تجزیه و تحلیل عکسهای خانهها و یافتن ویژگیهای بصری کلیدی، فهرستها را غنیتر کنید .
- ساخت و ارزیابی یک مدل K-means با استفاده از یادگیری ماشین BigQuery (BQML) برای تقسیمبندی ویژگیها به خوشههای مجزا.
- با استفاده از Data Science Agent برای تولید یک مدل خوشهبندی با پایتون، ایجاد مدل را خودکار کنید .
- برای تصاویر خانهها، جاسازیهایی ایجاد کنید تا ابزار جستجوی بصری را تقویت کنید و خانههای مشابه را با جستجوی متن یا تصویر پیدا کنید.