
1. Introduction
Présentation
Dans cet atelier, vous allez explorer un workflow de science des données multimodales dans BigQuery, dans le contexte d'un scénario immobilier. Vous commencerez par un ensemble de données brutes d'annonces immobilières et de leurs images. Vous enrichirez ces données avec l'IA pour extraire des caractéristiques visuelles, créerez un modèle de clustering pour découvrir des segments de marché distincts et, enfin, créerez un puissant outil de recherche visuelle à l'aide d'embeddings vectoriels.
Vous comparerez ce workflow SQL natif à une approche moderne d'IA générative en utilisant l'agent Data Science pour générer automatiquement un modèle de clustering basé sur Python à partir d'un simple prompt textuel.
Points abordés
- Préparez un ensemble de données brutes d'annonces immobilières pour l'analyse grâce à l'ingénierie des caractéristiques.
- Enrichissez les annonces en utilisant les fonctions d'IA de BigQuery pour analyser les photos de maisons et identifier les principales caractéristiques visuelles.
- Créez et évaluez un modèle de k-moyennes avec BigQuery Machine Learning (BQML) pour segmenter les propriétés en clusters distincts.
- Automatisez la création de modèles en utilisant le Data Science Agent pour générer un modèle de clustering avec Python.
- Générez des embeddings pour les images de maisons afin d'alimenter un outil de recherche visuelle permettant de trouver des maisons similaires à l'aide de requêtes textuelles ou d'images.
Prérequis
Avant de commencer cet atelier, vous devez :
- avoir des connaissances de base en programmation SQL et Python ;
- savoir exécuter du code Python dans un notebook Jupyter ;
2. Avant de commencer
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Activer des API avec Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud et fourni avec les outils nécessaires.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud :

- Une fois connecté à Cloud Shell, exécutez la commande suivante pour vérifier votre authentification dans Cloud Shell :
gcloud auth list
- Exécutez la commande suivante pour vérifier que votre projet est configuré pour être utilisé avec gcloud :
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Activer les API
- Exécutez cette commande pour activer toutes les API et tous les services requis :
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- Si la commande s'exécute correctement, un message semblable à celui ci-dessous s'affiche :
Operation "operations/..." finished successfully.
- Quittez Cloud Shell.
3. Ouvrir le notebook de l'atelier dans BigQuery Studio
Navigation dans l'UI :
- Dans la console Google Cloud, accédez au menu de navigation > BigQuery.
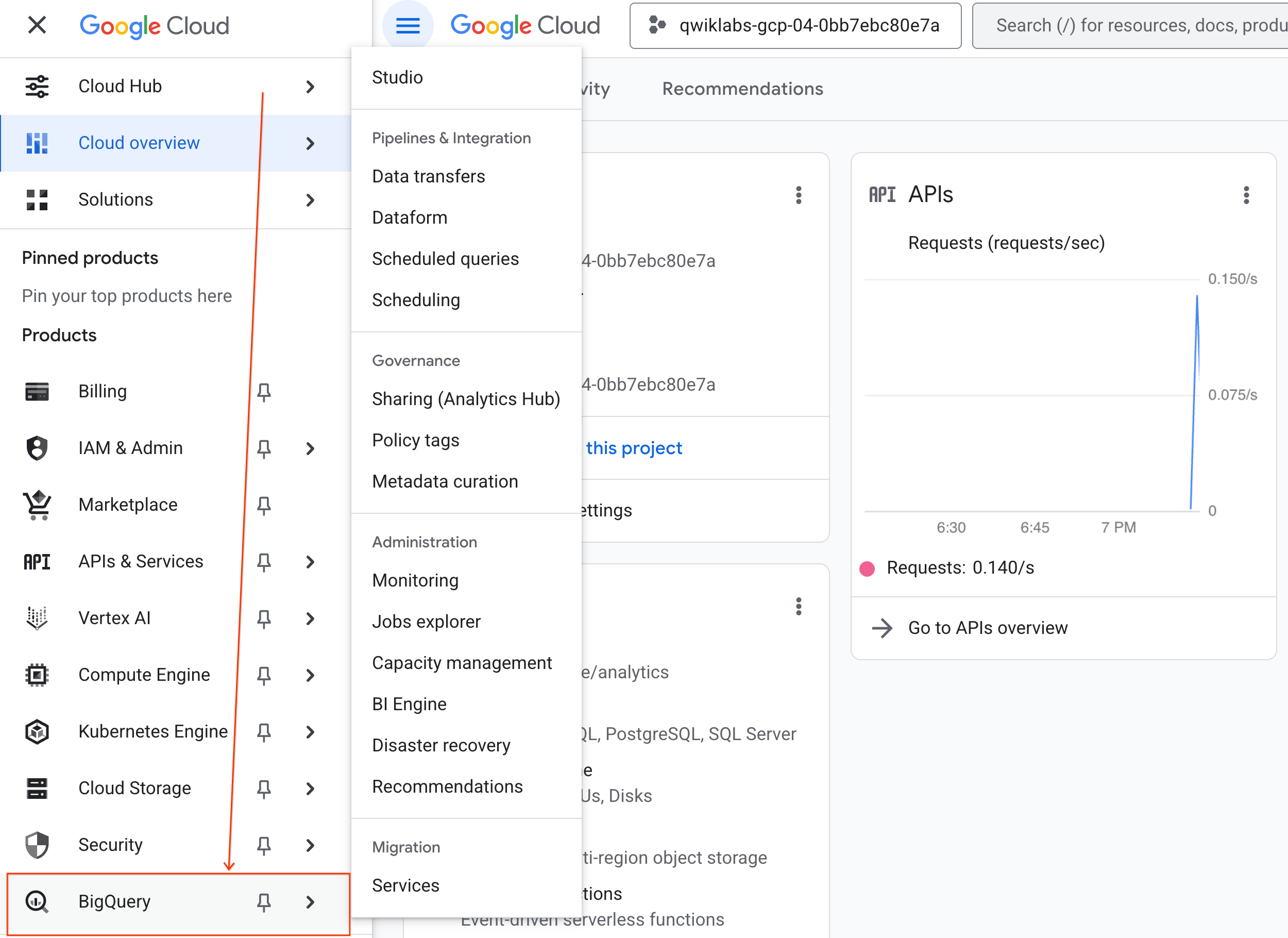
- Dans le volet BigQuery Studio, cliquez sur la flèche du menu déroulant, pointez sur Notebook, puis sélectionnez Importer.
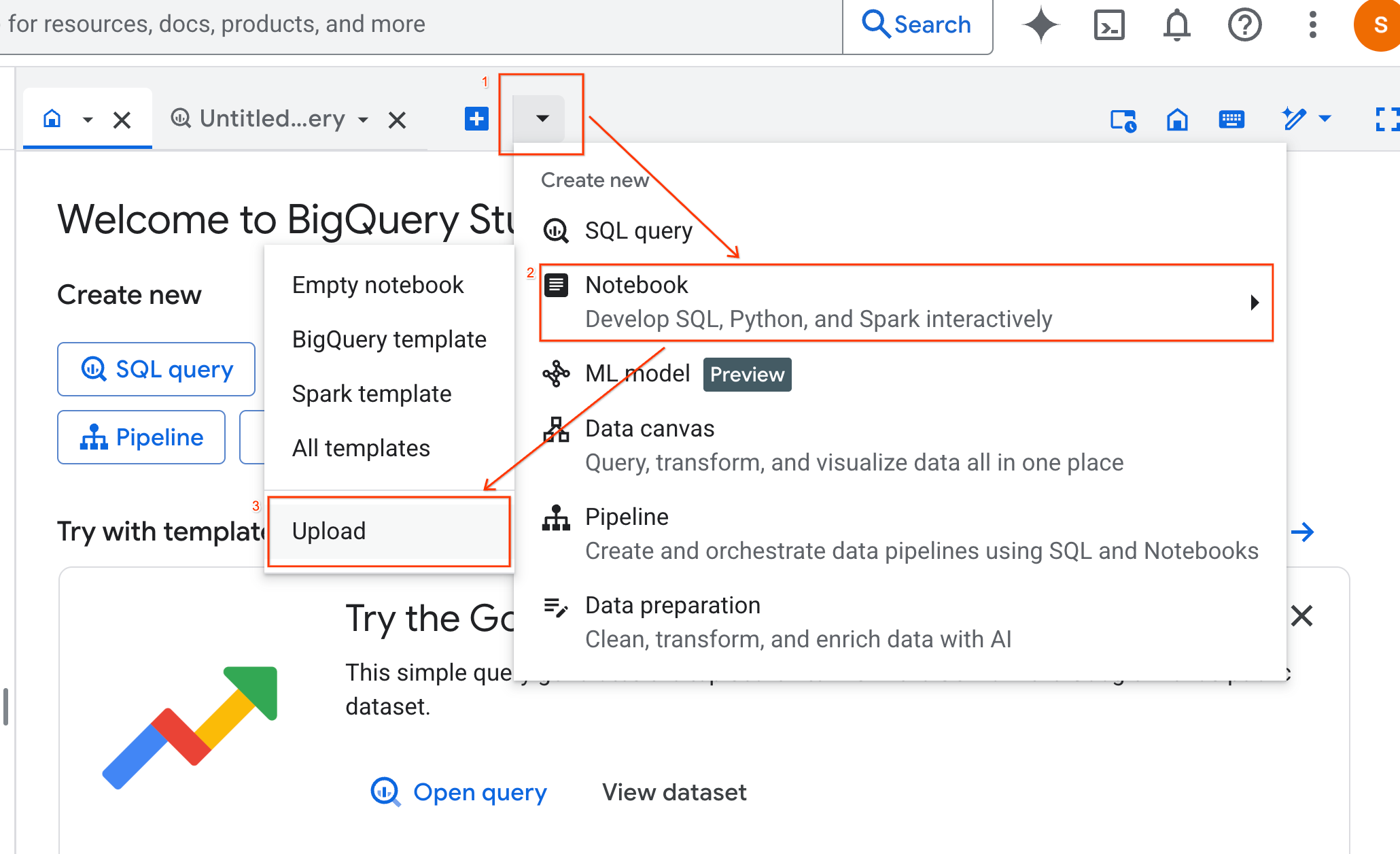
- Sélectionnez la case d'option URL, puis saisissez l'URL suivante :
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- Définissez la région sur
us-central1, puis cliquez sur Importer.
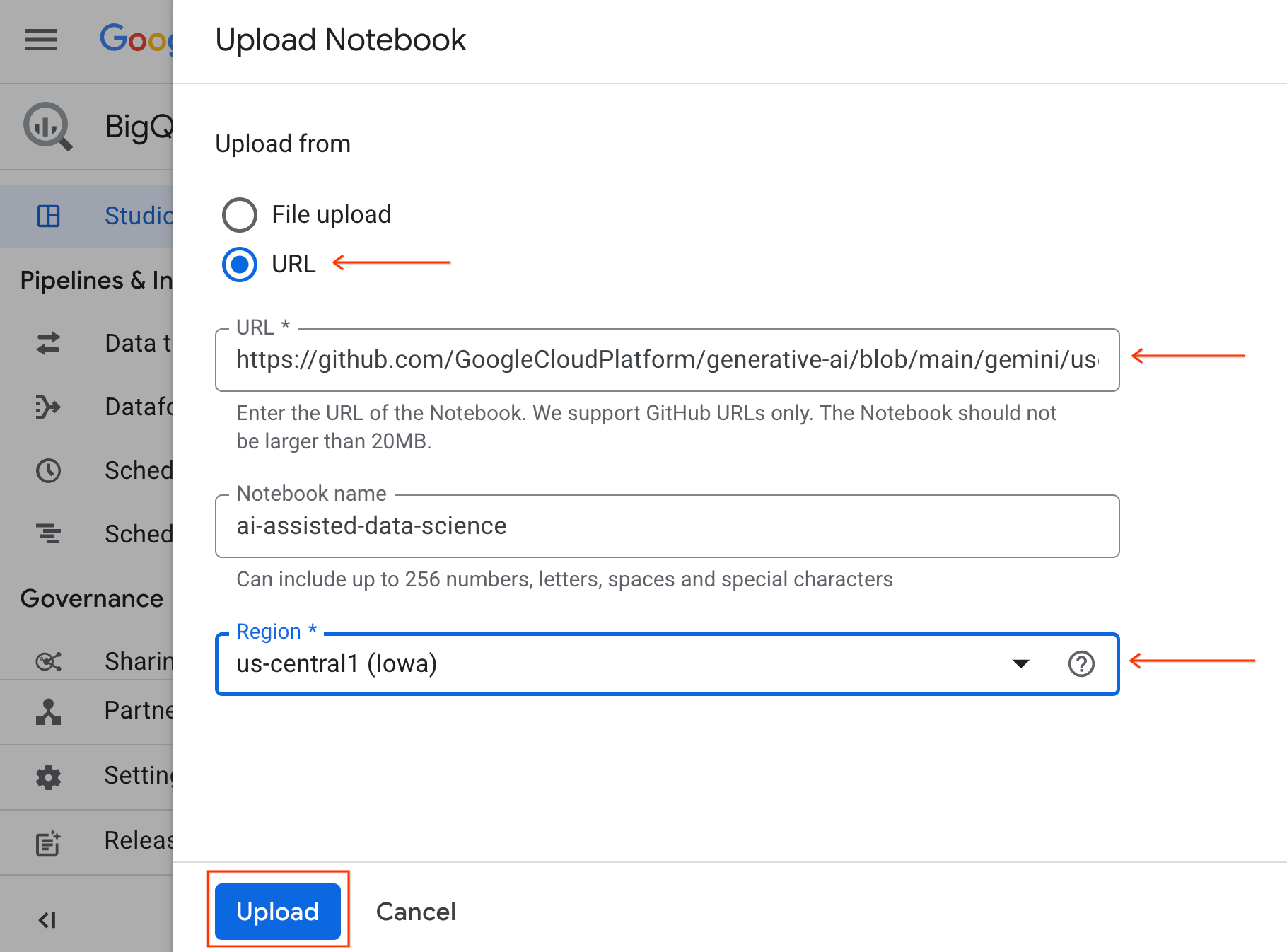
- Pour ouvrir le notebook, cliquez sur la flèche du menu déroulant dans le volet Explorateur contenant l'ID du projet. Cliquez ensuite sur le menu déroulant Notebooks. Cliquez sur le notebook
ai-assisted-data-science.
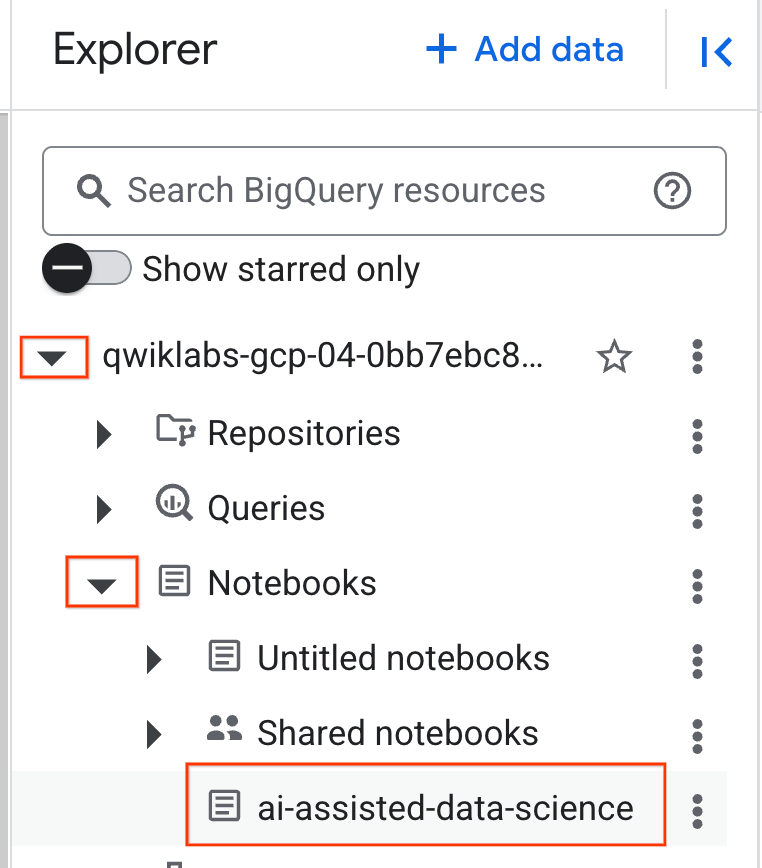
- (Facultatif) Réduisez le menu de navigation BigQuery et la table des matières du notebook pour gagner de l'espace.
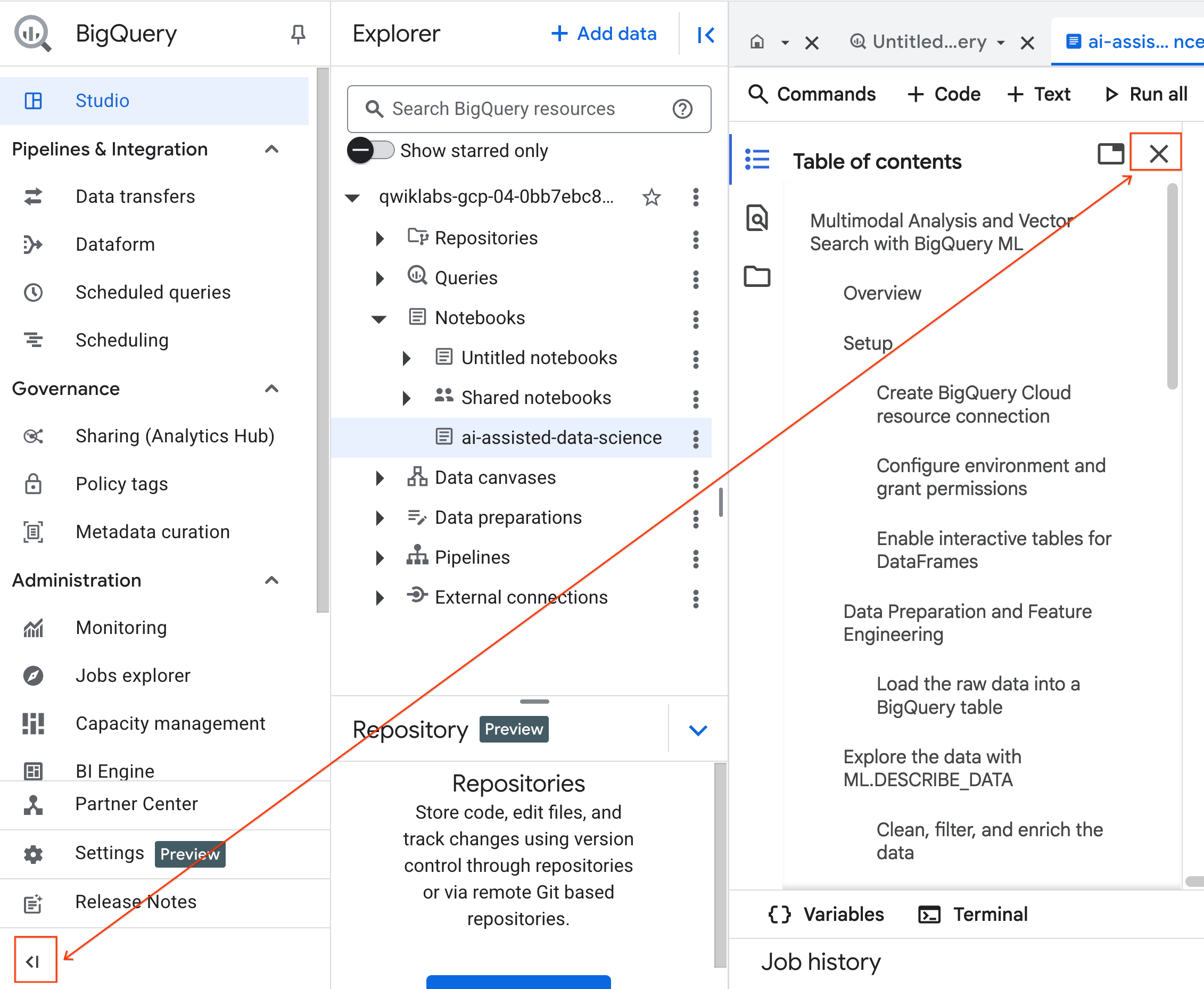
4. Se connecter à un environnement d'exécution et exécuter le code de configuration
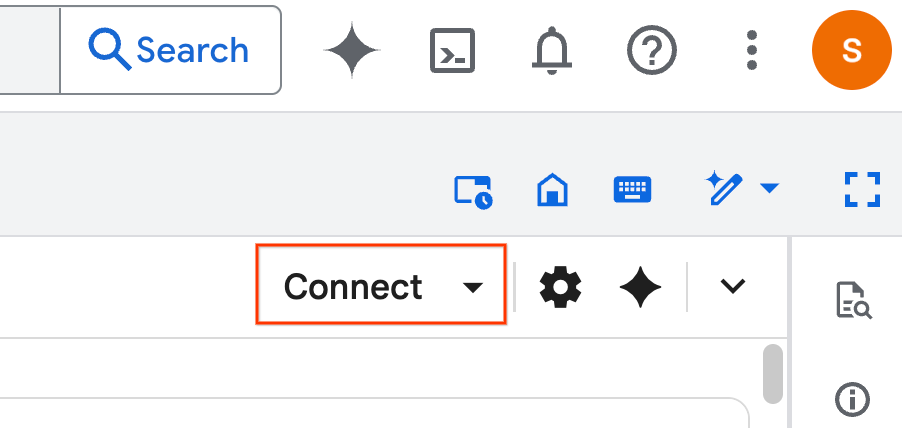
- Cliquez sur Se connecter. Si un pop-up s'affiche, autorisez Colab Enterprise avec votre utilisateur. Votre notebook se connectera automatiquement à un environnement d'exécution. Cette opération peut prendre quelques minutes.
- Une fois le temps d'exécution établi, le message suivant s'affiche :
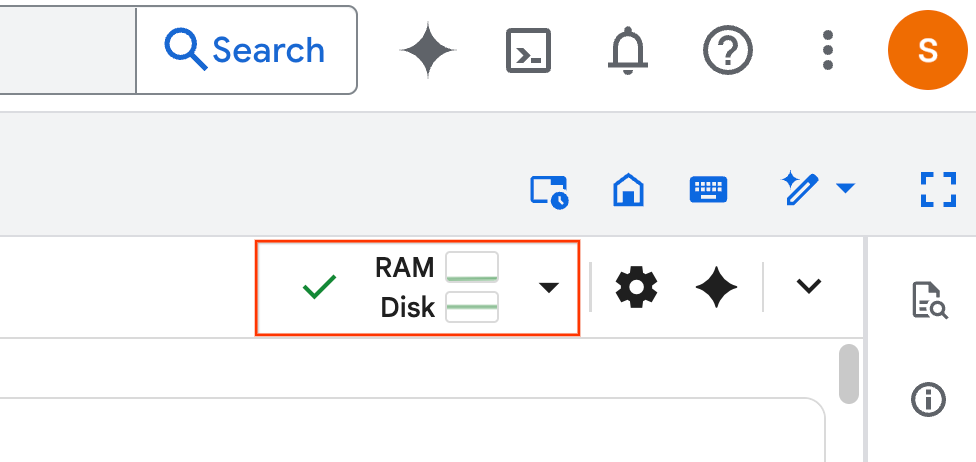
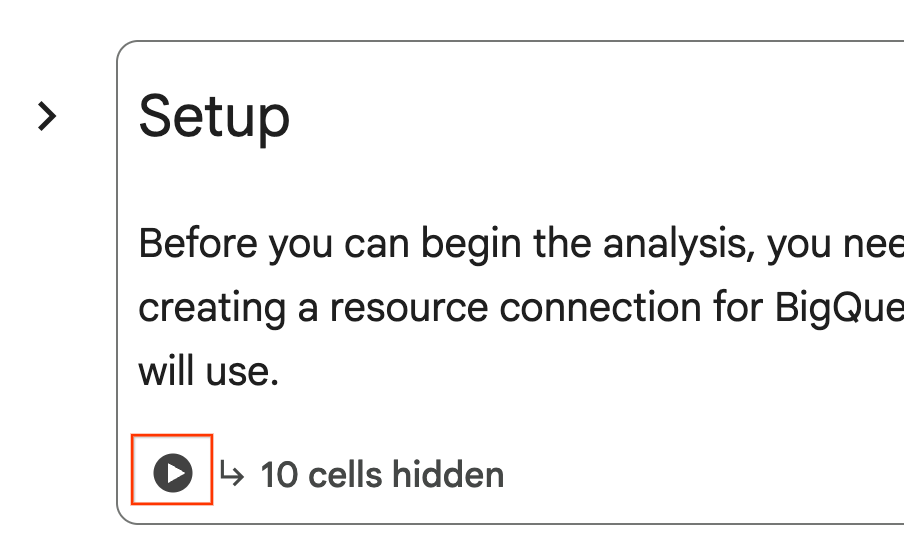
- Dans le notebook, accédez à la section Setup (Configuration). Cliquez sur le bouton "Exécuter" à côté des cellules masquées. Cette commande crée quelques ressources nécessaires à l'atelier dans votre projet. Cette opération peut prendre une minute. En attendant, n'hésitez pas à consulter les cellules sous Configuration.
5. Préparation des données et ingénierie des caractéristiques
Dans cette section, vous allez passer en revue la première étape importante de tout projet de science des données : la préparation de vos données. Vous commencez par créer un ensemble de données BigQuery pour organiser votre travail, puis vous chargez les données brutes sur l'immobilier et le logement à partir d'un fichier CSV dans Cloud Storage dans une nouvelle table.
Vous transformerez ensuite ces données brutes en un tableau nettoyé avec de nouvelles caractéristiques. Cela implique de filtrer les fiches, de créer une fonctionnalité property_age et de préparer les données d'image pour l'analyse multimodale.
6. Enrichissement multimodal avec les fonctions d'IA
Vous allez maintenant enrichir vos données grâce à la puissance de l'IA générative. Dans cette section, vous allez utiliser les fonctions d'IA intégrées de BigQuery pour analyser les images de chaque annonce immobilière.
En connectant BigQuery à un modèle Gemini, vous pouvez extraire de nouvelles fonctionnalités intéressantes à partir d'images (par exemple, si une propriété se trouve à proximité d'un point d'eau et une brève description de la maison) directement avec SQL.
7. Entraînement d'un modèle avec le clustering en k-moyennes
Maintenant que vous avez enrichi votre ensemble de données, vous êtes prêt à créer un modèle de machine learning. Votre objectif est de segmenter les annonces immobilières en groupes distincts. Pour ce faire, vous allez entraîner un modèle de clustering k-moyennes directement dans BigQuery à l'aide de BigQuery Machine Learning (BQML). Au cours de cette étape unique, vous enregistrez également le modèle dans Agent Platform AI Model Registry, ce qui le rend instantanément disponible dans l'écosystème MLOps plus vaste de Google Cloud.
Pour vérifier que votre modèle a bien été enregistré, vous pouvez le trouver dans le Model Registry de la plate-forme d'agents en procédant comme suit :
- Dans la console Google Cloud, cliquez sur le menu de navigation (☰) en haut à gauche.
- Faites défiler la page jusqu'à la section Plate-forme de l'agent, puis cliquez sur Modèles.
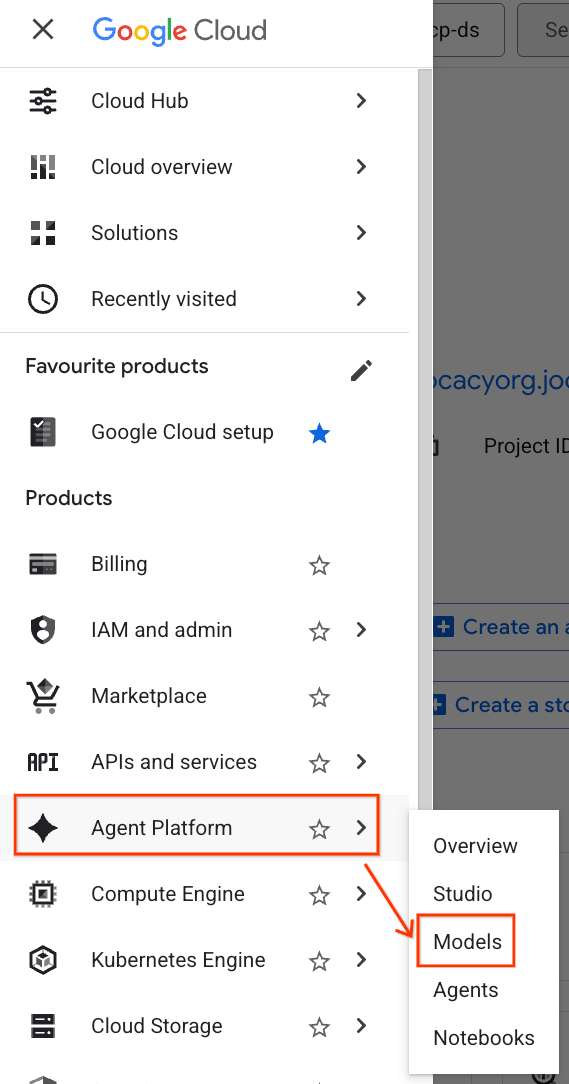
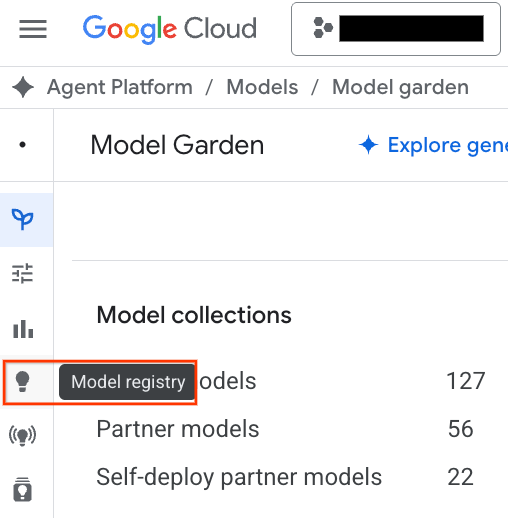
- Cliquez sur le bouton Model Registry mis en évidence dans la capture d'écran.
- Votre modèle BQML s'affiche à côté de tous vos autres modèles personnalisés. Dans la liste des modèles, recherchez celui nommé housing_clustering. Vous pouvez ensuite déployer votre modèle sur un point de terminaison pour le rendre disponible pour les prédictions en ligne en temps réel en dehors de l'environnement BigQuery.
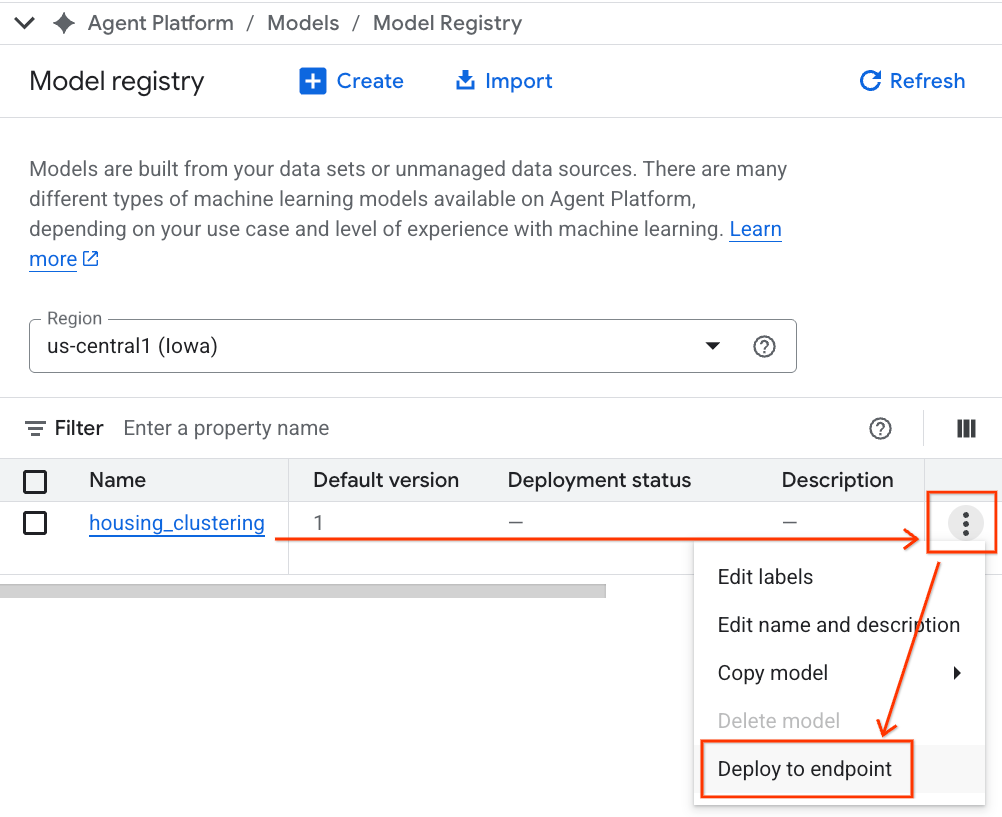
Après avoir exploré le Model Registry, vous pouvez revenir à votre notebook Colab dans BigQuery en procédant comme suit :
- Dans le menu de navigation (☰), accédez à BigQuery > Studio.
- Développez les menus du volet Explorer pour trouver votre notebook et l'ouvrir.
8. Évaluation et prédiction du modèle
Une fois votre modèle entraîné, l'étape suivante consiste à comprendre les clusters qu'il a créés. Ici, vous utilisez des fonctions BigQuery Machine Learning telles que ML.EVALUATE et ML.CENTROIDS pour analyser la qualité du modèle et les caractéristiques de chaque segment.
Vous utilisez ensuite ML.PREDICT pour attribuer chaque maison à un cluster. En exécutant cette requête avec la commande magique %%bigquery df, vous stockez les résultats dans un DataFrame pandas nommé df. Les données sont ainsi immédiatement disponibles pour les étapes Python suivantes. Cela met en évidence l'interopérabilité entre SQL et Python dans Colab Enterprise.
9. Visualiser et interpréter les clusters
Maintenant que vos prédictions sont chargées dans un DataFrame, vous pouvez créer des visualisations pour donner vie aux données. Dans cette section, vous allez utiliser des bibliothèques Python populaires comme Matplotlib pour explorer les différences entre les segments de logements.
Vous allez créer des graphiques en boîte et à barres pour comparer visuellement des caractéristiques clés comme le prix et l'âge de la propriété, ce qui vous permettra de comprendre intuitivement chaque cluster.
10. Générer des descriptions de clusters avec les modèles Gemini
Bien que les centroïdes numériques et les graphiques soient puissants, l'IA générative vous permet d'aller plus loin et de créer des personas qualitatifs et riches pour chaque segment de logement. Cela vous aide à comprendre non seulement ce que sont les clusters, mais aussi qui ils représentent.
Dans cette section, vous allez d'abord agréger les statistiques moyennes pour chaque cluster, comme le prix et la superficie. Vous transmettrez ensuite ces données dans un prompt pour le modèle Gemini. Vous demandez ensuite au modèle d'agir comme un professionnel de l'immobilier et de générer un résumé détaillé, y compris les caractéristiques clés et l'acheteur cible pour chaque segment. Vous obtenez ainsi un ensemble de descriptions claires et lisibles qui permettent à une équipe marketing de comprendre et d'exploiter immédiatement les clusters.
N'hésitez pas à modifier la requête comme vous le souhaitez et à tester les résultats.
11. Automatiser la modélisation avec Data Science Agent
Vous allez maintenant découvrir un workflow alternatif puissant. Au lieu d'écrire du code manuellement, vous utiliserez l'agent de science des données intégré pour générer automatiquement un workflow de modèle de clustering complet à partir d'une seule requête en langage naturel.
Pour générer et exécuter le modèle à l'aide de l'agent, procédez comme suit :
- Dans le volet BigQuery Studio, cliquez sur la flèche du menu déroulant, pointez sur Notebook, puis sélectionnez Notebook vide. Cela garantit que le code de l'agent n'interfère pas avec votre notebook de laboratoire d'origine.
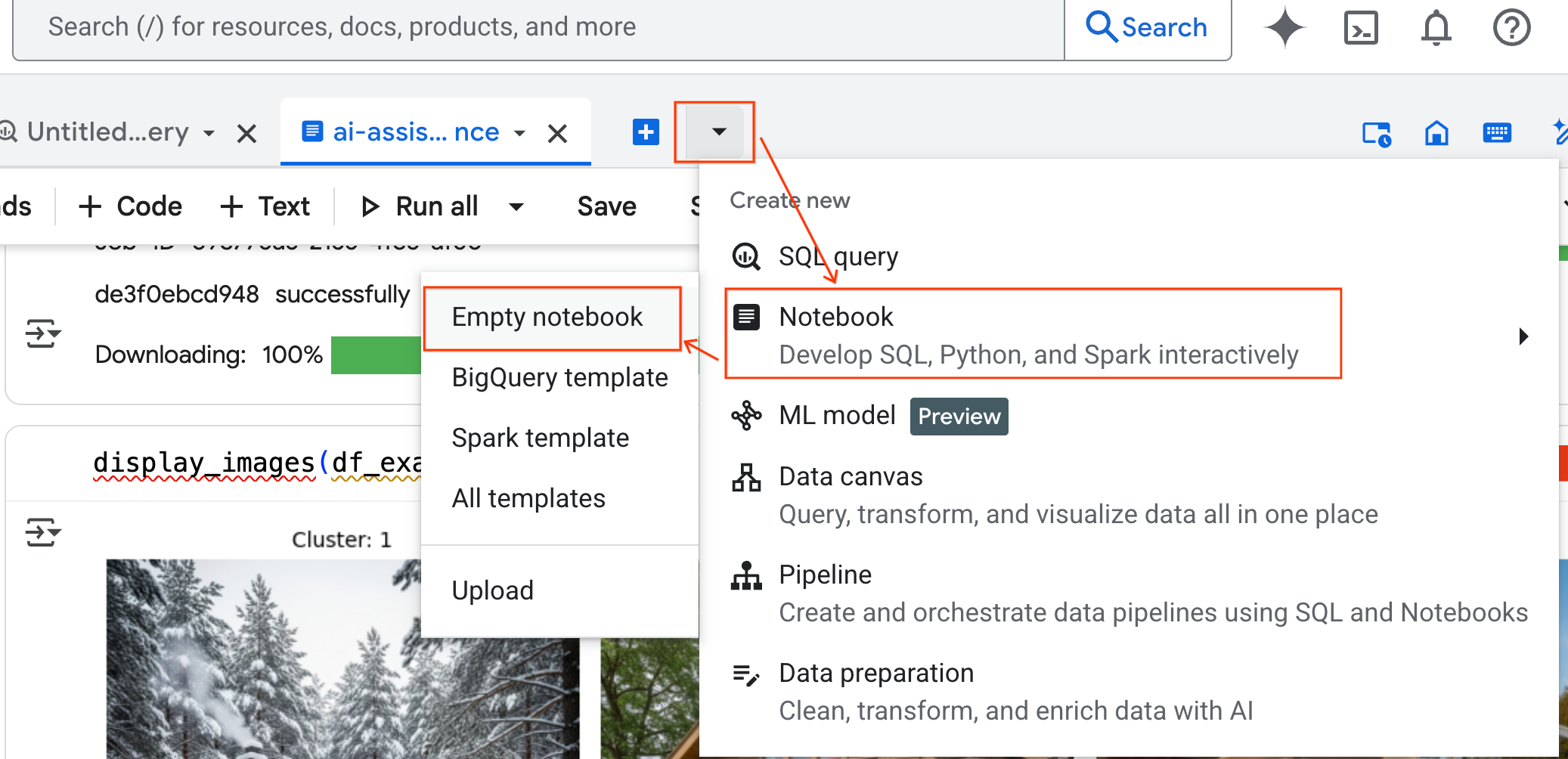
- L'interface de chat de l'agent Data Science s'ouvre en bas du notebook. Cliquez sur le bouton Déplacer vers le panneau pour épingler le chat sur la droite.
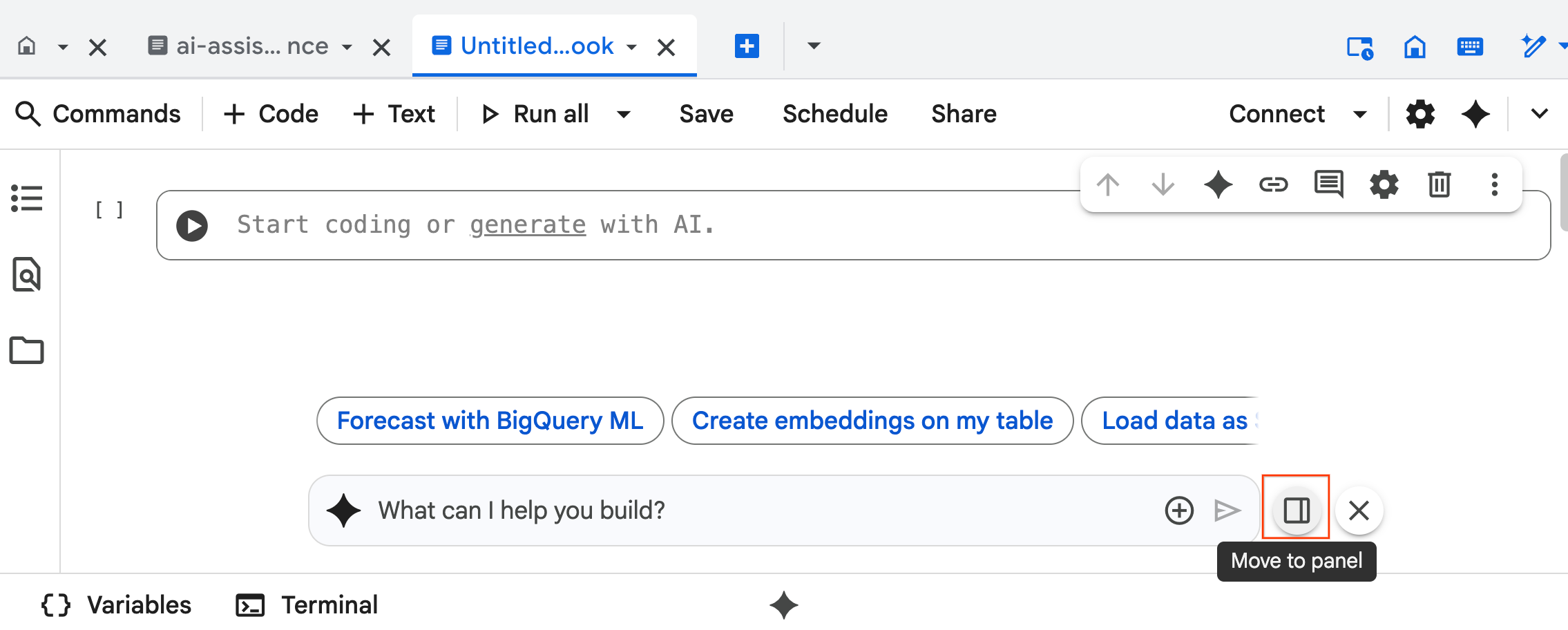
- Commencez à saisir
@listing_multimodaldans le volet de chat, puis cliquez sur le tableau. Cela définit explicitement la tablelistings_multimodalcomme contexte.
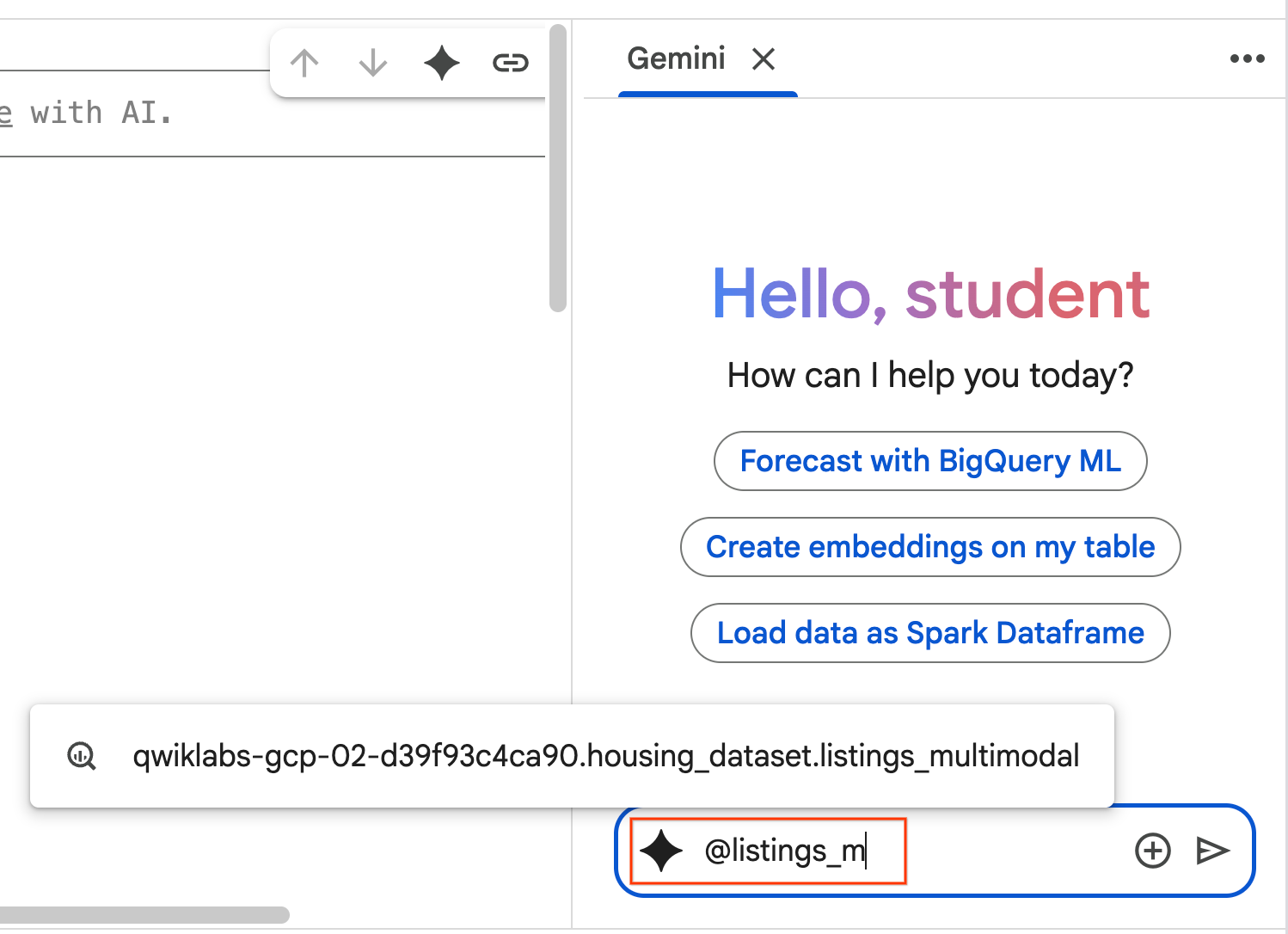
- Copiez le prompt ci-dessous et saisissez-le dans la boîte de chat de l'agent. Cliquez ensuite sur Envoyer pour envoyer la requête à l'agent.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
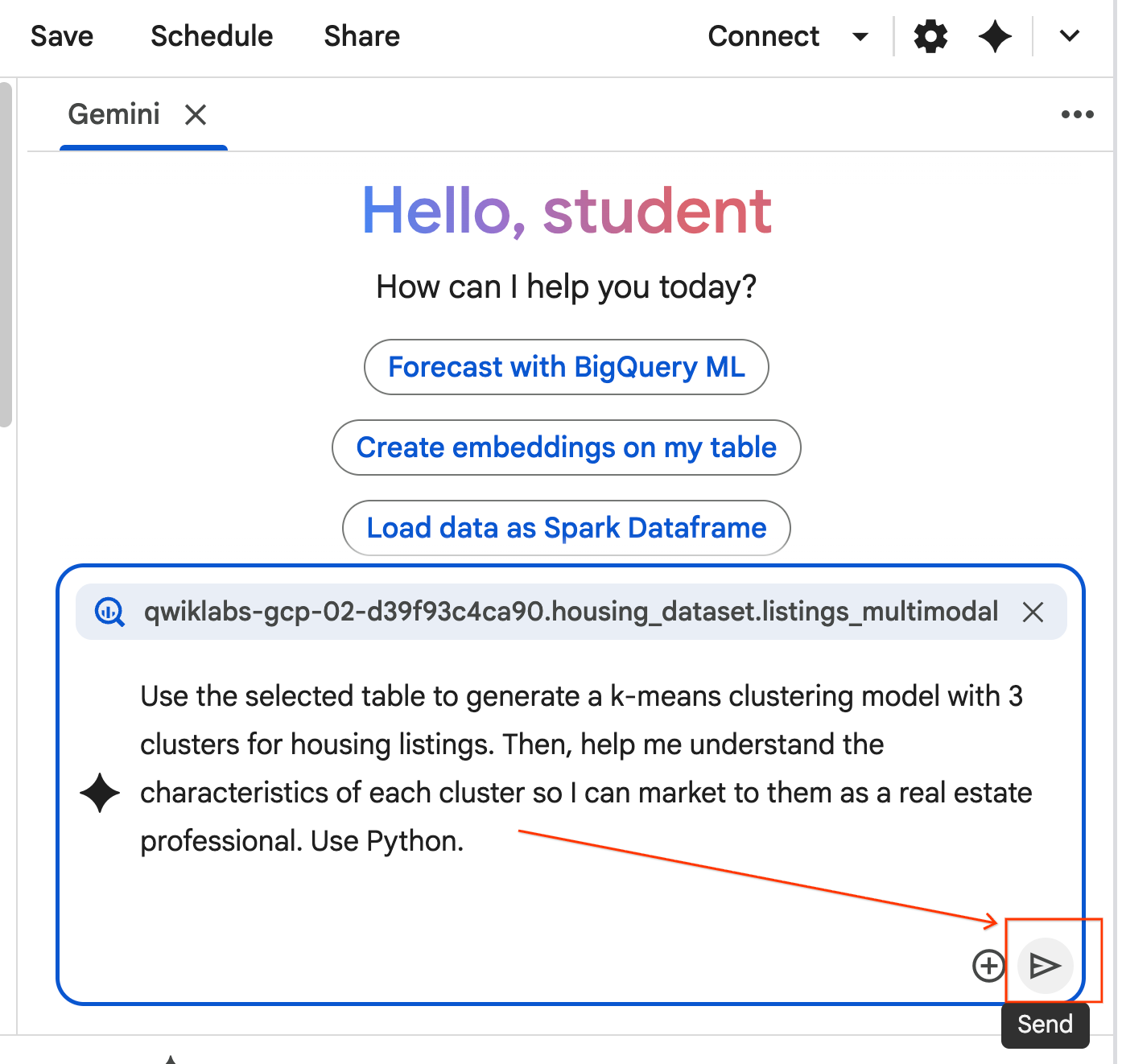
- L'agent réfléchit et élabore un plan. Si ce plan vous convient, cliquez sur Accepter et exécuter. L'agent génère du code Python dans une ou plusieurs nouvelles cellules.
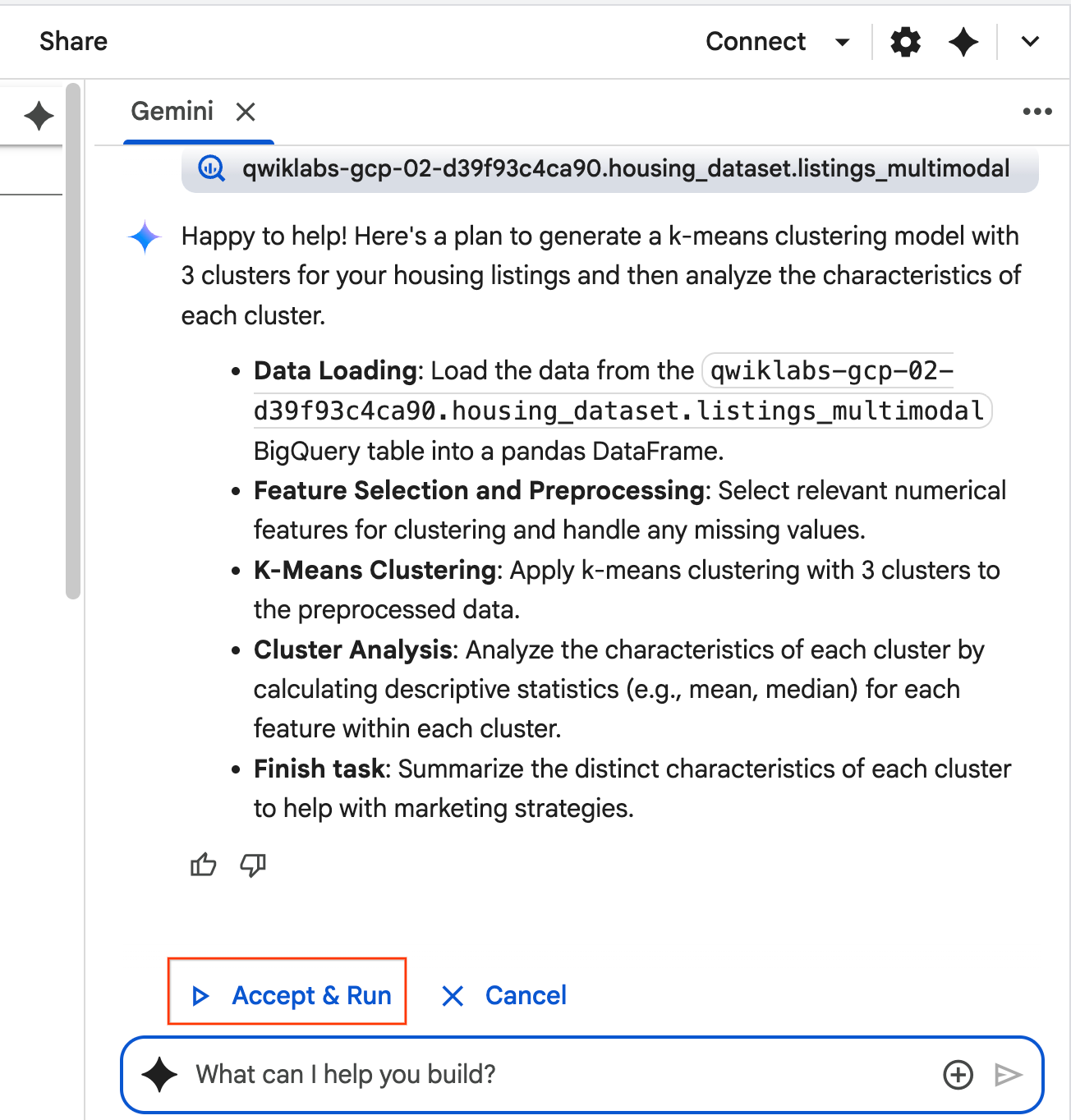
- L'agent vous demande d'accepter et d'exécuter chaque bloc de code qu'il génère. Cela permet de garder une intervention humaine. N'hésitez pas à examiner ou à modifier le code, et à suivre chaque étape jusqu'à la fin.
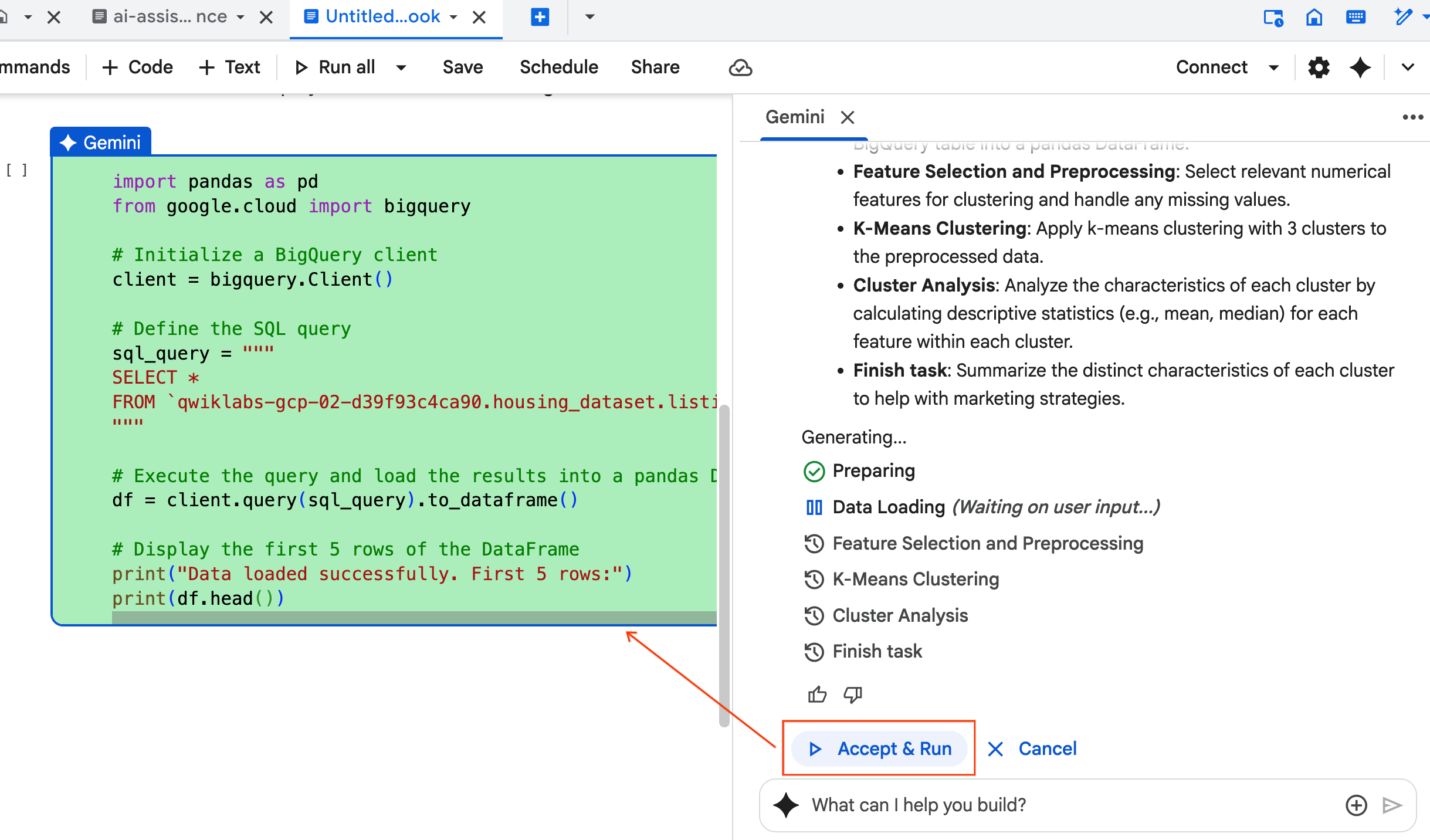
- Une fois terminé, fermez simplement ce nouvel onglet de notebook et revenez à l'onglet
ai-assisted-data-science.ipynbd'origine pour poursuivre la dernière section de l'atelier.
12. Recherche multimodale avec des embeddings et Vector Search
Dans cette dernière section, vous allez implémenter la recherche multimodale directement dans BigQuery. Cela permet d'effectuer des recherches intuitives, par exemple pour trouver des maisons à partir d'une description textuelle ou des maisons qui ressemblent à une photo d'exemple.
Le processus consiste d'abord à convertir chaque image de maison en une représentation numérique appelée embedding. Un embedding capture la signification sémantique d'une image, ce qui vous permet de trouver des éléments similaires en comparant leurs vecteurs numériques.
Vous utiliserez le modèle multimodalembedding pour générer ces vecteurs pour toutes vos fiches. Après avoir créé un index vectoriel pour accélérer les recherches, vous effectuez deux types de recherche par similarité : texte-vers-image (recherche de maisons correspondant à une description) et image-vers-image (recherche de maisons ressemblant à un exemple d'image).
Vous effectuerez toutes ces opérations dans BigQuery, à l'aide de fonctions telles que ML.GENERATE_EMBEDDING pour générer des embeddings ou VECTOR_SEARCH pour la recherche de similarité.
13. Nettoyage
Pour nettoyer toutes les ressources Google Cloud utilisées dans ce projet, vous pouvez supprimer le projet Google Cloud.
Vous pouvez également supprimer les ressources individuelles que vous avez créées en exécutant le code suivant dans une nouvelle cellule de votre notebook :
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
Enfin, vous pouvez supprimer le notebook lui-même :
- Dans le volet Explorateur de BigQuery Studio, développez votre projet et le nœud Notebooks.
- Cliquez sur les trois points verticaux à côté du notebook
ai-assisted-data-science. - Sélectionnez Supprimer.
14. Félicitations !
Bravo ! Vous avez terminé cet atelier de programmation.
Points abordés
- Préparez un ensemble de données brutes d'annonces immobilières pour l'analyse grâce à l'ingénierie des caractéristiques.
- Enrichissez les annonces en utilisant les fonctions d'IA de BigQuery pour analyser les photos de maisons et identifier les principales caractéristiques visuelles.
- Créez et évaluez un modèle de clustering en k-moyennes avec BigQuery Machine Learning (BQML) pour segmenter les propriétés en clusters distincts.
- Automatisez la création de modèles en utilisant le Data Science Agent pour générer un modèle de clustering avec Python.
- Générez des embeddings pour les images de maisons afin d'alimenter un outil de recherche visuelle permettant de trouver des maisons similaires à l'aide de requêtes textuelles ou d'images.