
1. מבוא
סקירה כללית
בשיעור ה-Lab הזה תלמדו על תהליך עבודה של מדע נתונים מרובה-אופנים ב-BigQuery, במסגרת תרחיש של נדל"ן. תתחילו עם מערך נתונים גולמי של רשימות בתים והתמונות שלהם, תעשירו את הנתונים האלה באמצעות AI כדי לחלץ תכונות חזותיות, תיצרו מודל אשכולות כדי לגלות פלחי שוק נפרדים, ולבסוף תיצרו כלי חיפוש חזותי עוצמתי באמצעות הטמעות וקטוריות.
תשוו את תהליך העבודה הזה, שמתבסס על SQL, לגישה מודרנית של AI גנרטיבי באמצעות הסוכן Data Science כדי ליצור באופן אוטומטי מודל אשכולות מבוסס-Python מתוך הנחיה פשוטה בטקסט.
מה תלמדו
- מכינים מערך נתונים גולמי של רשימות נדל"ן לניתוח באמצעות הנדסת תכונות.
- שיפור כרטיסי הנכסים באמצעות פונקציות ה-AI של BigQuery כדי לנתח תמונות של בתים ולזהות תכונות ויזואליות מרכזיות.
- ליצור ולבדוק מודל K-means באמצעות BigQuery Machine Learning (BQML) כדי לפלח נכסים לקלאסטרים נפרדים.
- יצירת מודל אוטומטית באמצעות Data Science Agent כדי ליצור מודל אשכולות עם Python.
- יצירת הטמעות של תמונות של בתים כדי להפעיל כלי לחיפוש חזותי, ולמצוא בתים דומים באמצעות שאילתות טקסט או תמונות.
דרישות מוקדמות
לפני שמתחילים את שיעור ה-Lab הזה, חשוב להכיר את הנושאים הבאים:
- ידע בסיסי ב-SQL ובשפת התכנות Python.
- הרצת קוד Python ב-notebook של Jupyter.
2. לפני שמתחילים
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
הפעלת ממשקי API באמצעות Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud ומגיעה עם כלים שנדרשים לשימוש.
- לוחצים על Activate Cloud Shell (הפעלת Cloud Shell) בחלק העליון של מסוף Google Cloud:

- אחרי שמתחברים ל-Cloud Shell, מריצים את הפקודה הבאה כדי לאמת את האימות ב-Cloud Shell:
gcloud auth list
- מריצים את הפקודה הבאה כדי לוודא שהפרויקט מוגדר לשימוש ב-gcloud:
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
הפעלת ממשקי ה-API
- מריצים את הפקודה הזו כדי להפעיל את כל ממשקי ה-API והשירותים הנדרשים:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- אם הפקודה תפעל בהצלחה, תוצג הודעה שדומה לזו שמופיעה בהמשך:
Operation "operations/..." finished successfully.
- יוצאים מ-Cloud Shell.
3. פתיחת Lab Notebook ב-BigQuery Studio
ניווט בממשק המשתמש:
- במסוף Google Cloud, עוברים אל תפריט הניווט > BigQuery.
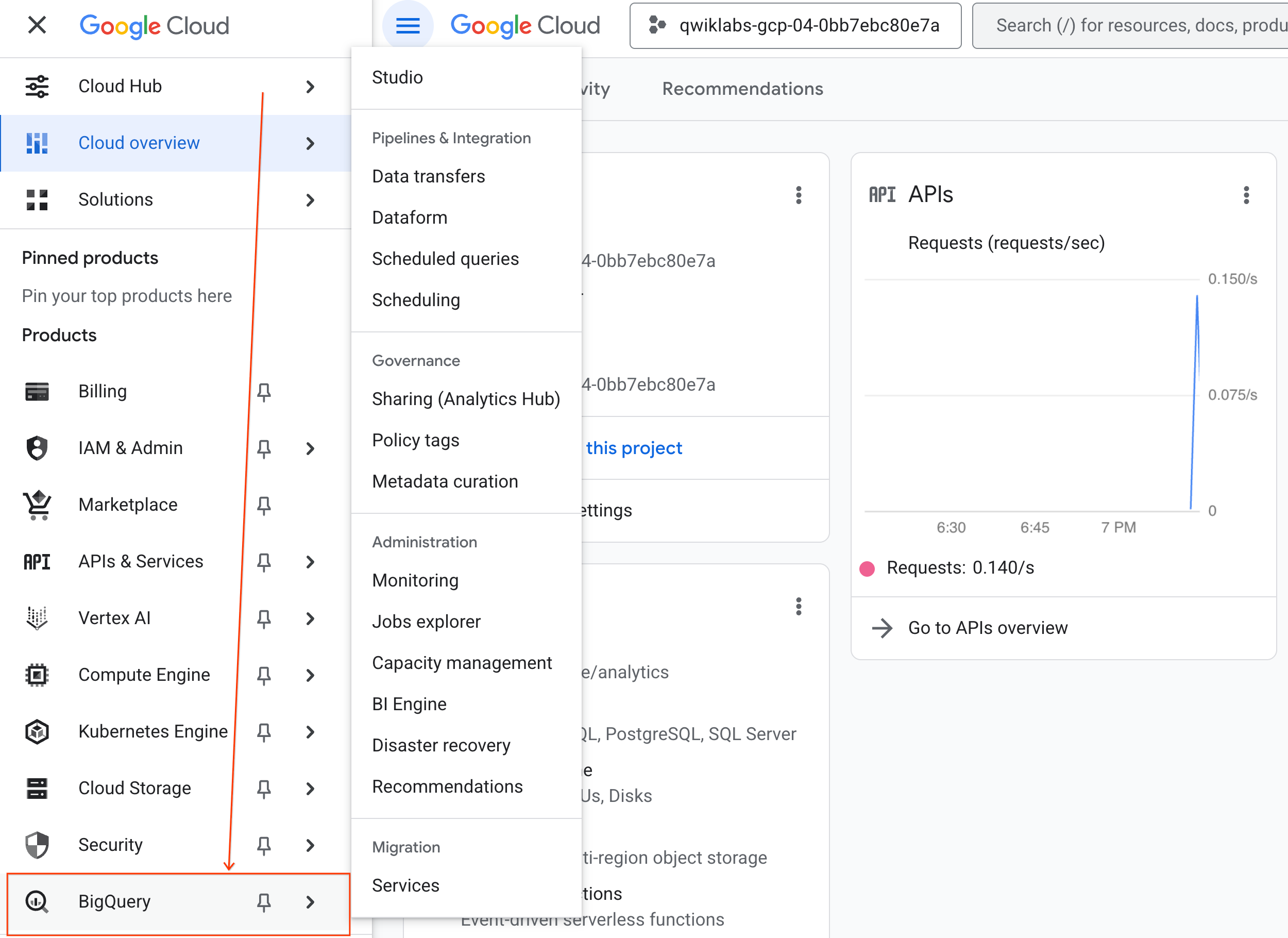
- בחלונית BigQuery Studio, לוחצים על לחצן החץ לתפריט הנפתח, מעבירים את העכבר מעל מחברת ובוחרים באפשרות העלאה.
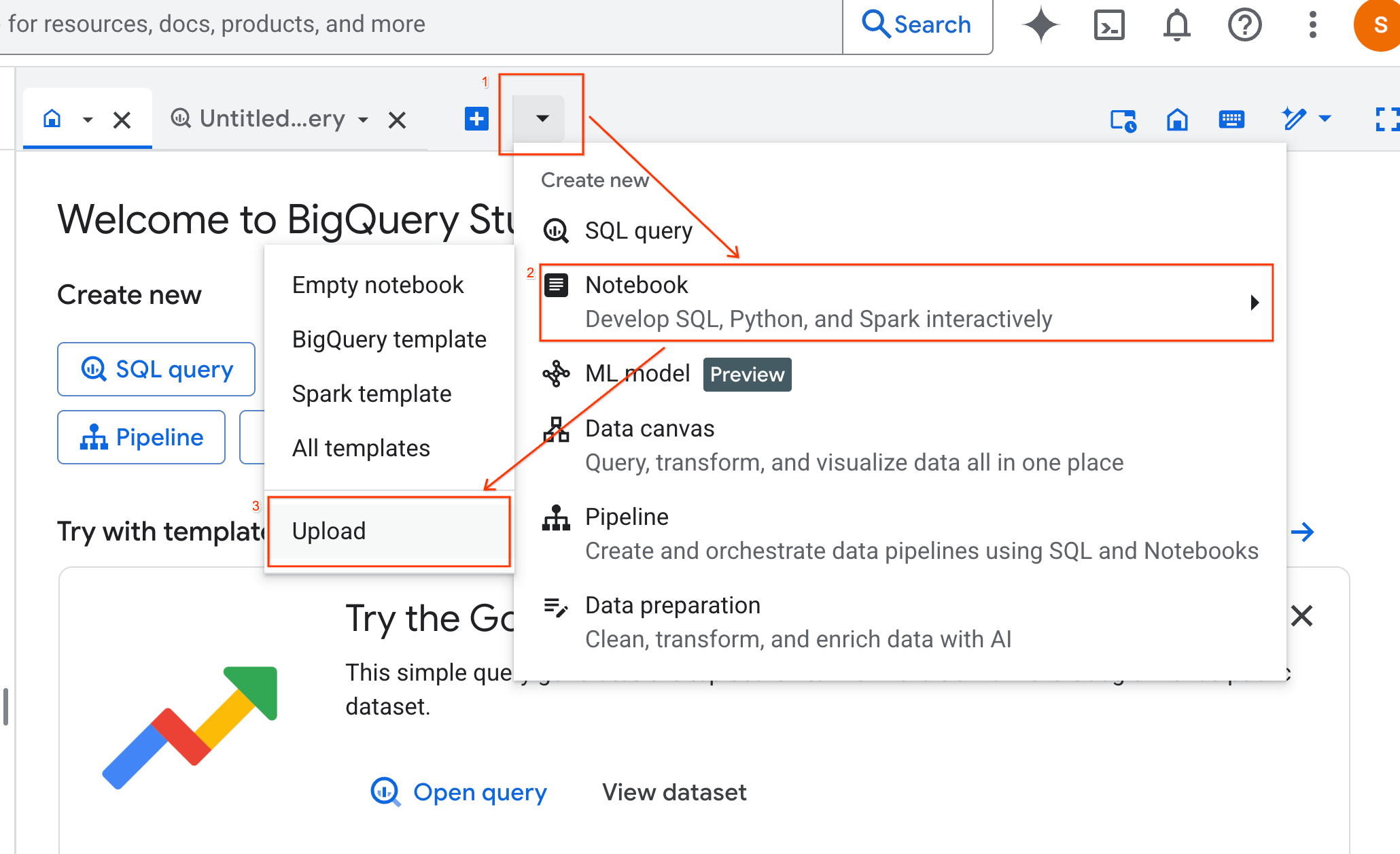
- בוחרים בלחצן האפשרויות כתובת URL ומזינים את כתובת ה-URL הבאה:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- מגדירים את האזור ל-
us-central1ולוחצים על העלאה.
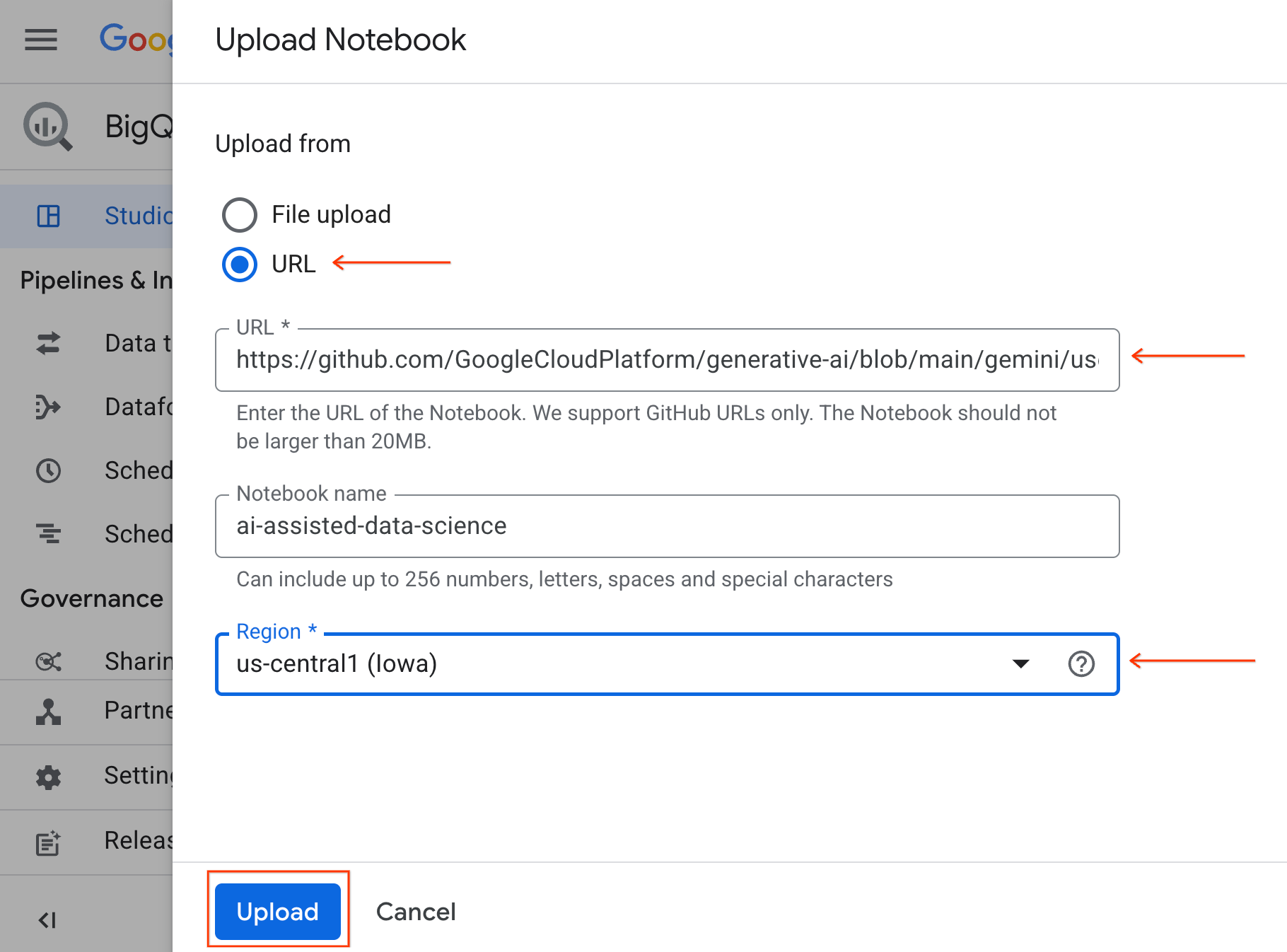
- כדי לפתוח את המחברת, לוחצים על החץ לתפריט הנפתח בחלונית Explorer שכוללת את מזהה הפרויקט. לוחצים על התפריט הנפתח מחברות. לוחצים על ה-Notebook
ai-assisted-data-science.
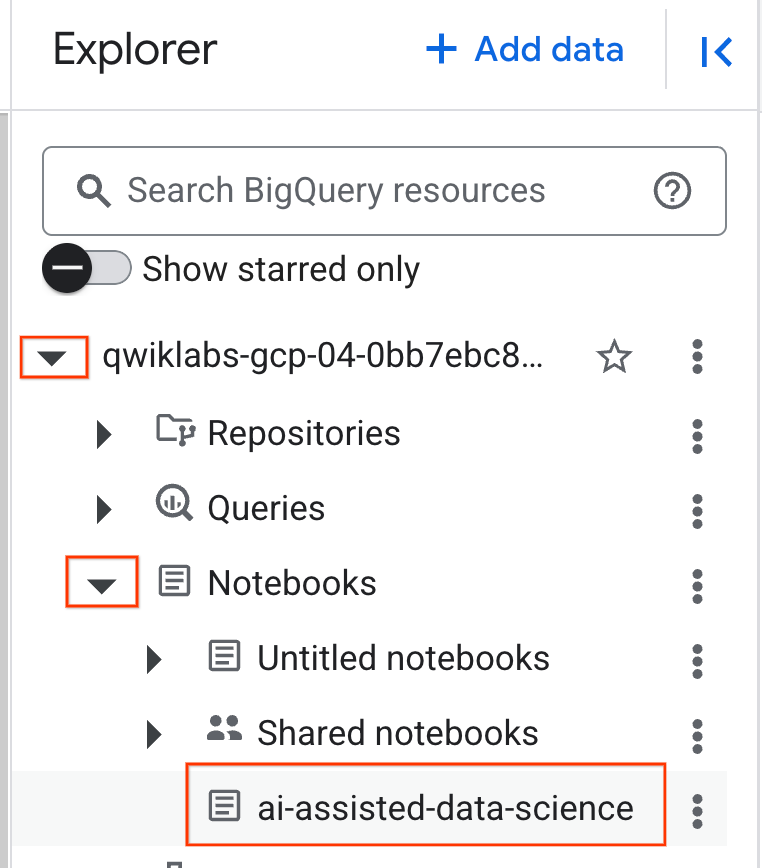
- (אופציונלי) כדי לפנות מקום, אפשר לכווץ את תפריט הניווט של BigQuery ואת תוכן העניינים של המחברת.
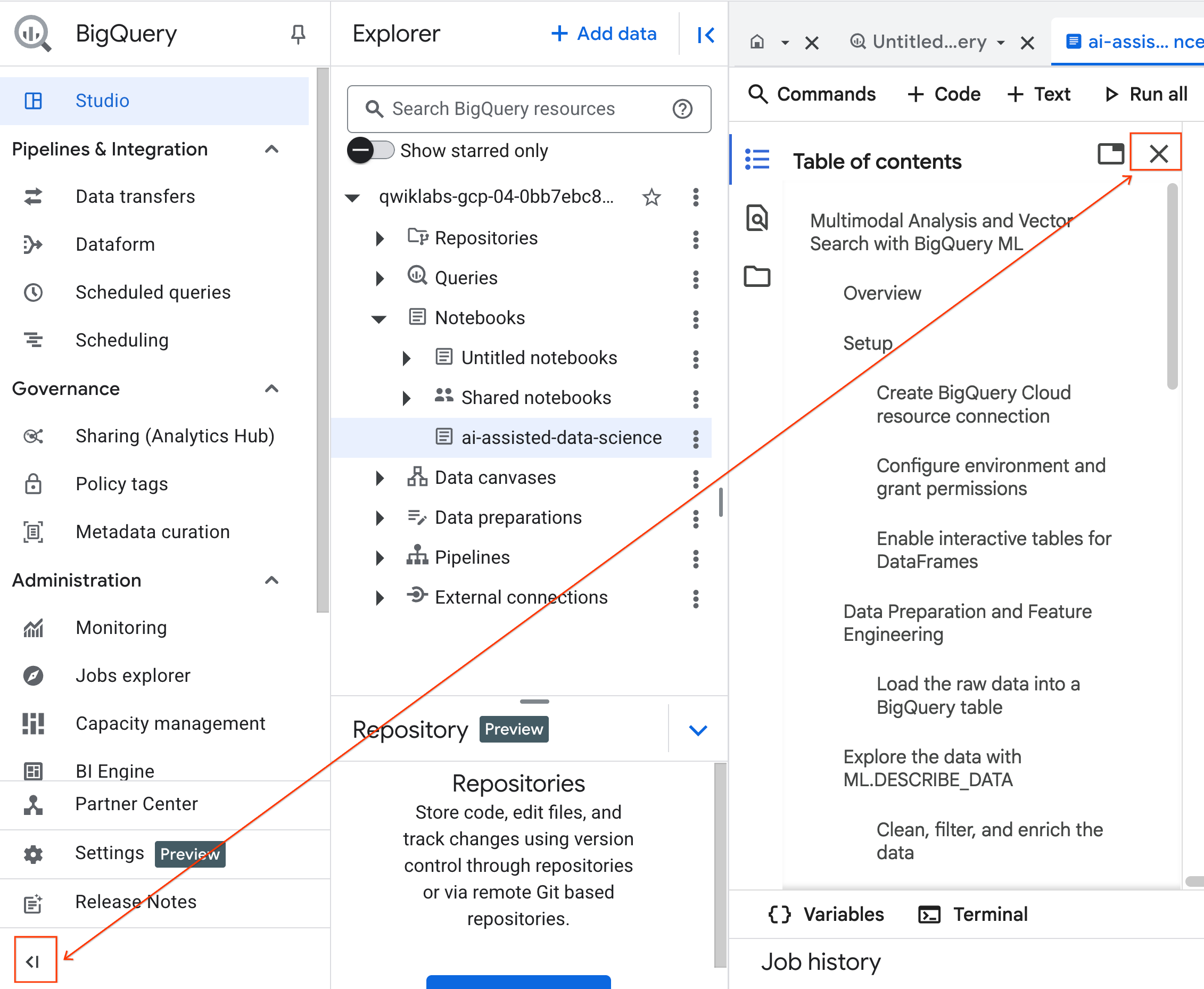
4. התחברות לסביבת זמן ריצה והרצת קוד ההגדרה
- לוחצים על חיבור. אם מופיע חלון קופץ, מאשרים את השימוש ב-Colab Enterprise עם המשתמש. ה-notebook יתחבר אוטומטית לסביבת זמן ריצה. הפעולה הזו עשויה להימשך כמה דקות.
- אחרי שהסביבה תוגדר, תראו את הדברים הבאים:
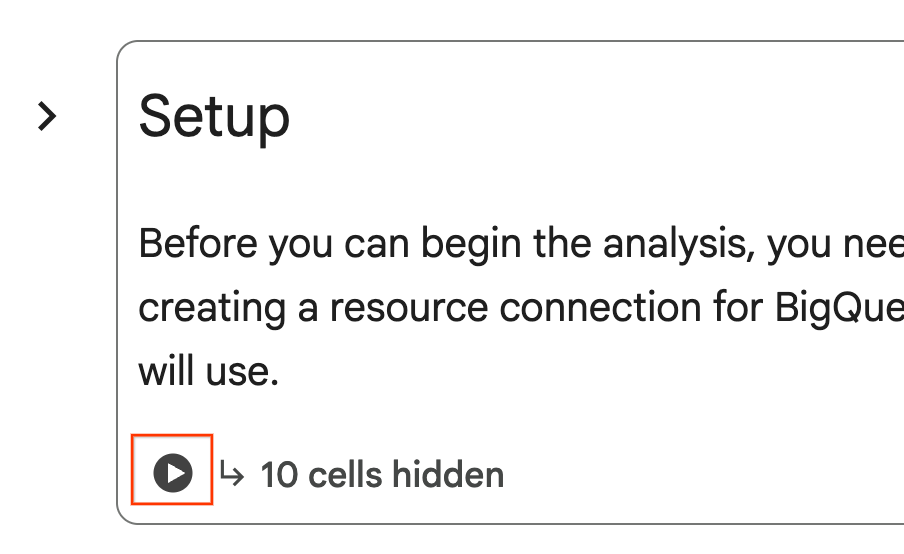
- במחברת, גוללים לקטע הגדרה. לוחצים על הלחצן 'הפעלה' לצד התאים המוסתרים. כך נוצרים כמה משאבים שנדרשים לשיעור ה-Lab בפרויקט. יכול להיות שהתהליך יימשך דקה. בינתיים, אפשר לבדוק את התאים בקטע הגדרה.
5. הכנת נתונים והנדסת תכונות
בקטע הזה תעברו על השלב החשוב הראשון בכל פרויקט של מדעי הנתונים: הכנת הנתונים. מתחילים ביצירת מערך נתונים ב-BigQuery כדי לארגן את העבודה, ואז טוענים את הנתונים הגולמיים של הנדל"ן או הדיור מקובץ CSV ב-Cloud Storage לטבלה חדשה.
לאחר מכן, תמירו את הנתונים הגולמיים האלה לטבלה נקייה עם תכונות חדשות. התהליך כולל סינון של כרטיסי המוצר, יצירה של תכונה חדשה של property_age והכנת נתוני התמונות לניתוח מולטימודאלי.
6. העשרה מולטי-מודאלית באמצעות פונקציות AI
עכשיו נשתמש ביכולות של AI גנרטיבי כדי להעשיר את הנתונים. בקטע הזה, תשתמשו בפונקציות ה-AI המובנות של BigQuery כדי לנתח את התמונות של כל בית שמופיע ברשימה.
כשמקשרים את BigQuery למודל Gemini, אפשר לחלץ תכונות חדשות וחשובות מתמונות (למשל, אם נכס נמצא ליד מים ותיאור קצר של הבית) ישירות באמצעות SQL.
7. אימון מודל באמצעות אשכולות K-Means
אחרי שהעשרתם את מערך הנתונים, אתם יכולים לבנות מודל ללמידת מכונה. המטרה היא לפלח את רשימת הבתים לקבוצות נפרדות, ואפשר לעשות את זה באמצעות אימון של מודל אשכולות K-means ישירות ב-BigQuery באמצעות למידת מכונה של BigQuery (BQML). במסגרת השלב הזה, אתם גם רושמים את המודל ב-Agent Platform AI Model Registry, וכך הוא זמין באופן מיידי במערכת האקולוגית הרחבה יותר של MLOps ב-Google Cloud.
כדי לוודא שהמודל נרשם בהצלחה, אפשר למצוא אותו במאגר המודלים של Agent Platform באופן הבא:
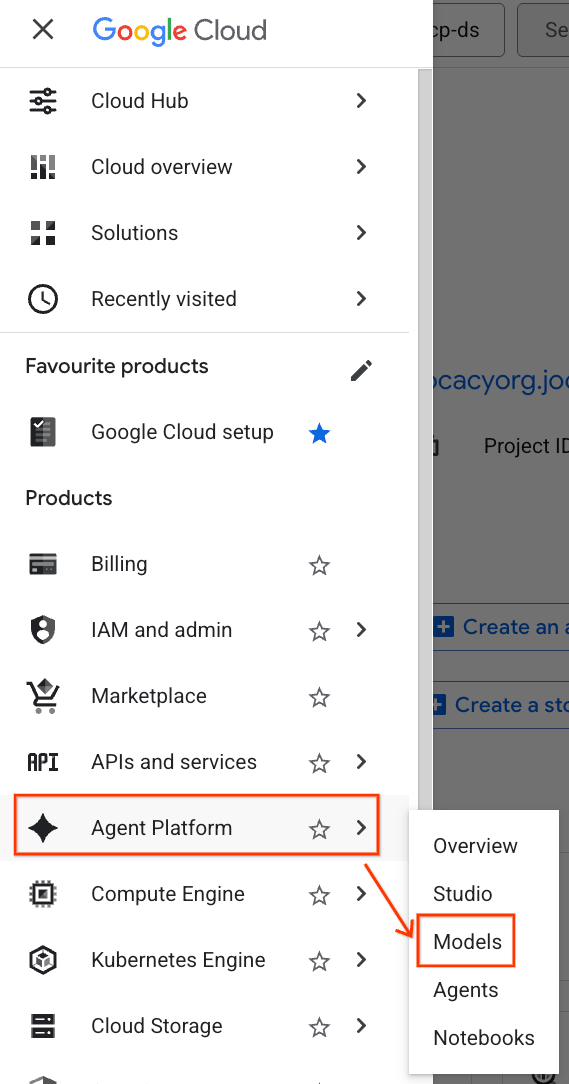
- ב-מסוף Google Cloud, לוחצים על תפריט הניווט (☰) בפינה הימנית העליונה.
- גוללים לקטע Agent Platform (פלטפורמת סוכנים) ולוחצים על Models (מודלים).
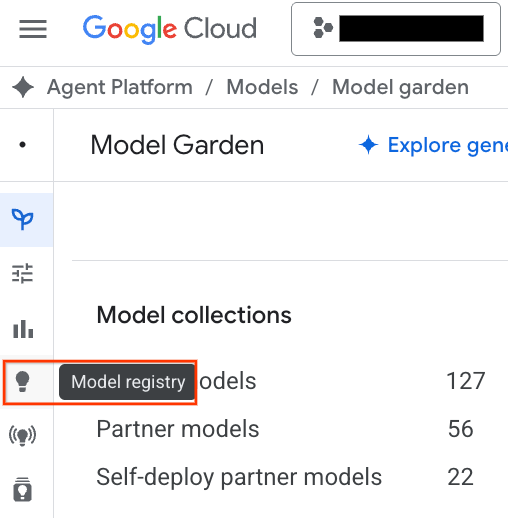
- לוחצים על הלחצן Model Registry (מאגר מודלים) שמודגש בצילום המסך.
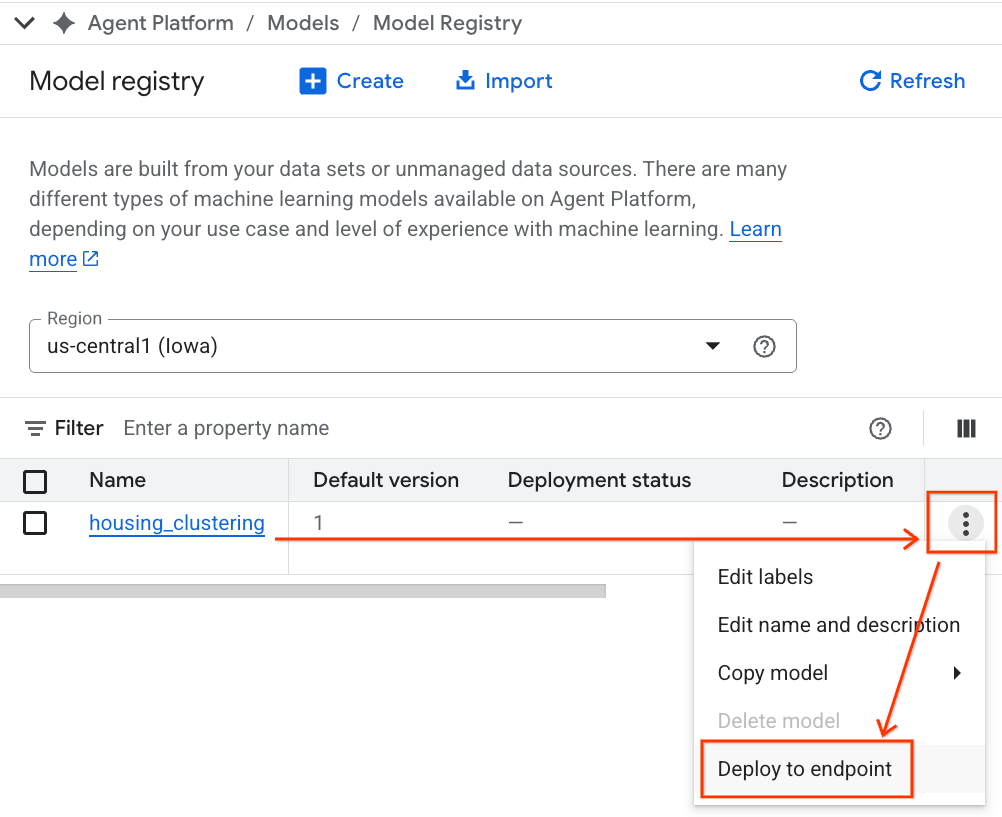
- מודל ה-BQML שלכם יופיע ברשימה לצד כל המודלים המותאמים אישית האחרים. ברשימת המודלים, מחפשים את המודל שנקרא housing_clustering. אפשר לעבור לשלב הבא של פריסה לנקודת קצה, שתאפשר למודל שלכם להיות זמין לחיזויים אונליין בזמן אמת מחוץ לסביבת BigQuery.
אחרי שבודקים את מרשם המודלים, אפשר לחזור ל-notebook של Colab ב-BigQuery באמצעות השלבים הבאים:
- בתפריט הניווט (☰), עוברים אל BigQuery > Studio.
- מרחיבים את התפריטים בחלונית חיפוש כדי למצוא את המחברת ולפתוח אותה.
8. הערכה וחיזוי של מודלים
אחרי שמסיימים לאמן את המודל, השלב הבא הוא להבין את האשכולות שהוא יצר. בשלב הזה, משתמשים בפונקציות של BigQuery Machine Learning כמו ML.EVALUATE ו-ML.CENTROIDS כדי לנתח את איכות המודל ואת המאפיינים המגדירים של כל פלח.
לאחר מכן משתמשים ב-ML.PREDICT כדי להקצות כל בית לאשכול. כשמריצים את השאילתה הזו באמצעות הפקודה המיוחדת %%bigquery df, התוצאות נשמרות ב-pandas DataFrame בשם df. כך הנתונים יהיו זמינים באופן מיידי לשלבי Python הבאים. הדוגמה הזו ממחישה את יכולת הפעולה ההדדית בין SQL ל-Python ב-Colab Enterprise.
9. המחשה ויזואלית של אשכולות ופירוש שלהם
אחרי שהתחזיות נטענות ל-DataFrame, אפשר ליצור תצוגות חזותיות כדי להמחיש את הנתונים. בקטע הזה תשתמשו בספריות פופולריות של Python כמו Matplotlib כדי לבדוק את ההבדלים בין פלחי הדיור.
תצרו תרשימי תיבות ותרשימי עמודות כדי להשוות באופן חזותי בין תכונות מרכזיות כמו מחיר וגיל הנכס, וכך תוכלו להבין בקלות את כל אשכול.
10. יצירת תיאורים של אשכולות באמצעות מודלים של Gemini
השימוש ב-AI גנרטיבית מאפשר לכם ליצור פרסונות איכותיות ועשירות לכל פלח של שוק הדיור, מעבר לשימוש בנקודות מרכזיות מספריות ובטבלאות. כך תוכלו להבין לא רק מה מייצגים האשכולות, אלא גם מי הם האנשים שהם מייצגים.
בקטע הזה, קודם כל תצטרכו לצבור את הנתונים הסטטיסטיים הממוצעים של כל אשכול, כמו מחיר ושטח. לאחר מכן, מעבירים את הנתונים האלה להנחיה למודל Gemini. לאחר מכן, נותנים למודל הוראה לפעול כמו מומחה בתחום הנדל"ן וליצור סיכום מפורט, כולל מאפיינים מרכזיים וקונה פוטנציאלי לכל פלח. התוצאה היא קבוצה של תיאורים ברורים וקריאים, שמאפשרים לצוות השיווק להבין את האשכולות באופן מיידי ולפעול לפיהם.
אתם יכולים לשנות את ההנחיה כרצונכם ולהתנסות עם התוצאות.
11. אוטומציה של יצירת מודלים באמצעות Data Science Agent
עכשיו נסביר על תהליך עבודה חלופי ויעיל. במקום לכתוב קוד באופן ידני, תשתמשו בData Science Agent המשולב כדי ליצור באופן אוטומטי תהליך עבודה מלא של מודל אשכולות מתוך הנחיה אחת בשפה טבעית.
כדי ליצור את המודל ולהריץ אותו באמצעות הסוכן:
- בחלונית BigQuery Studio, לוחצים על לחצן החץ לתפריט הנפתח, מעבירים את העכבר מעל Notebook ובוחרים באפשרות Empty Notebook. כך קוד הסוכן לא יפריע למחברת המקורית שלכם.
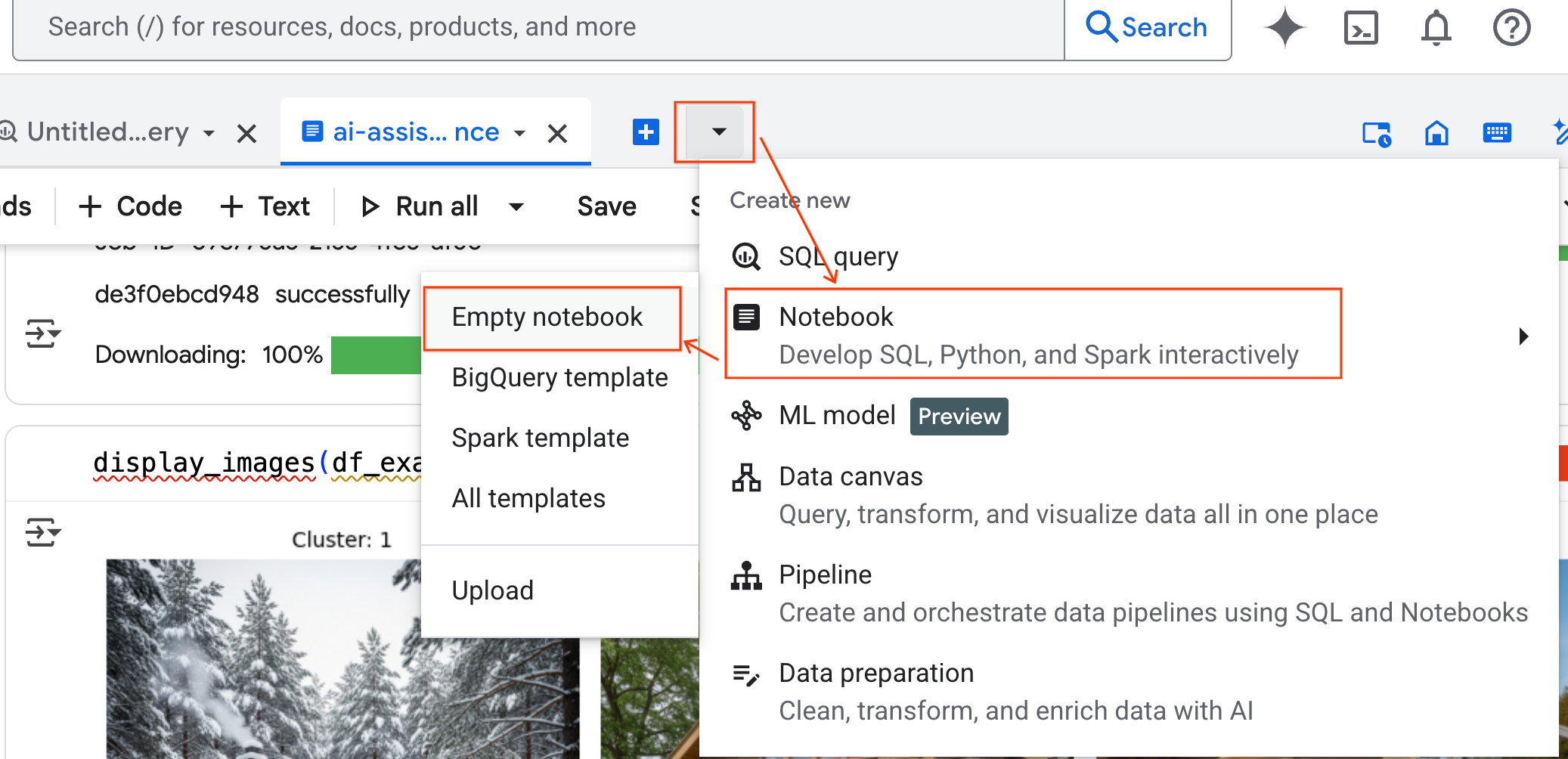
- ממשק הצ'אט של Data Science Agent נפתח בתחתית המחברת. לוחצים על הלחצן העברה לחלונית כדי להצמיד את הצ'אט לצד שמאל.
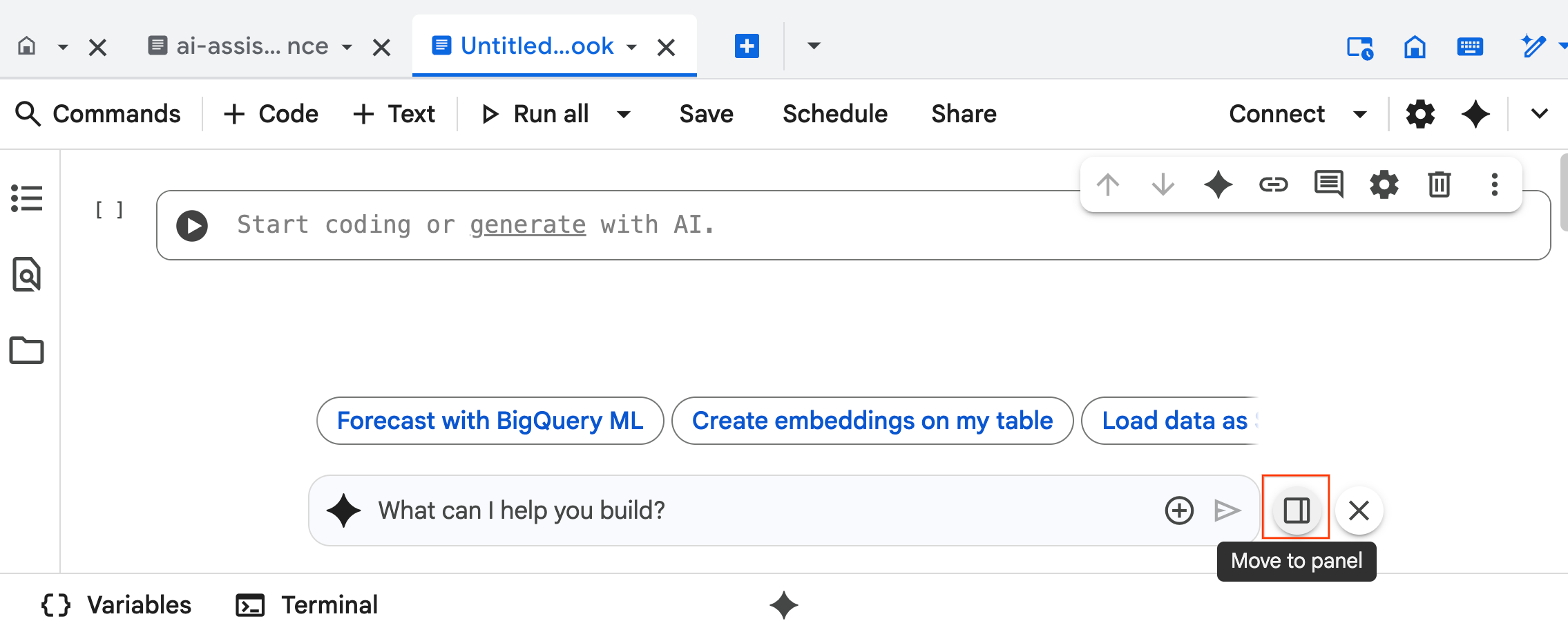
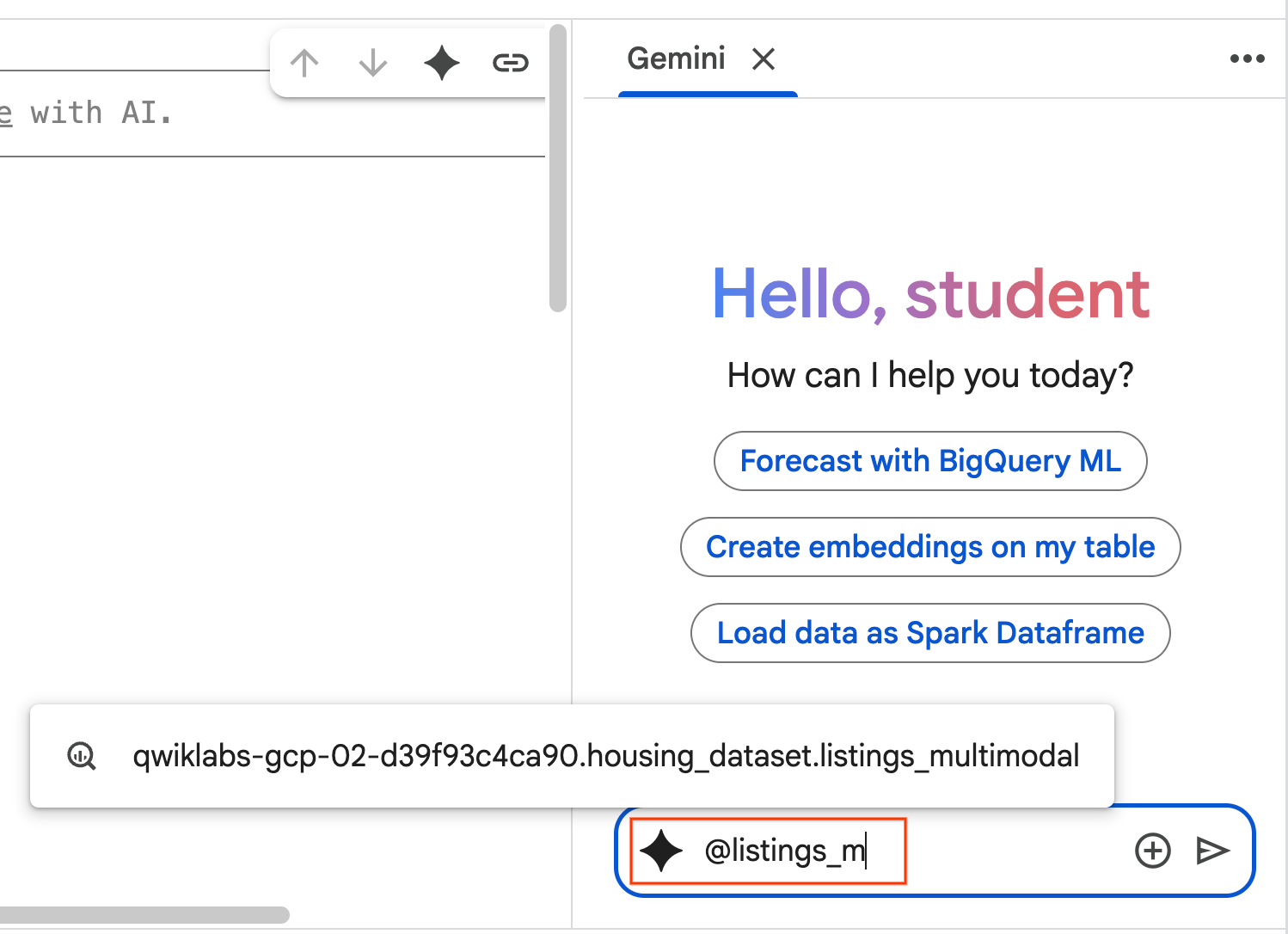
- מתחילים להקליד
@listing_multimodalבחלונית הצ'אט ולוחצים על הטבלה. הפעולה הזו מגדירה במפורש את הטבלהlistings_multimodalכהקשר.
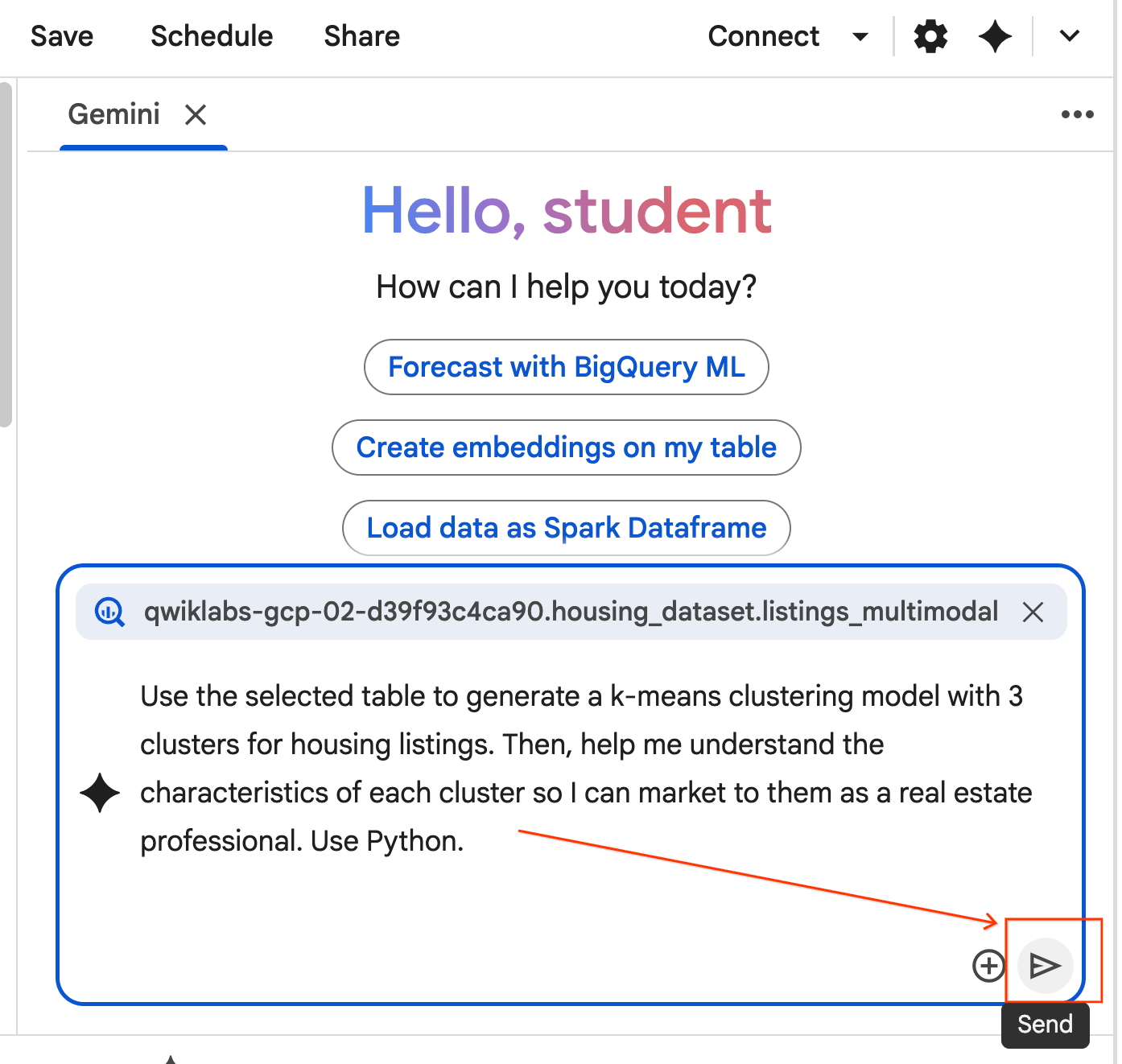
- מעתיקים את ההנחיה שלמטה ומזינים אותה בתיבת הצ'אט של הסוכן. לאחר מכן, לוחצים על שליחה כדי לשלוח את ההנחיה לסוכן.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- הסוכן יחשוב ויגבש תוכנית. אם התוכנית מתאימה לכם, לוחצים על אישור והפעלה. הסוכן ייצור קוד Python בתא חדש אחד או יותר.
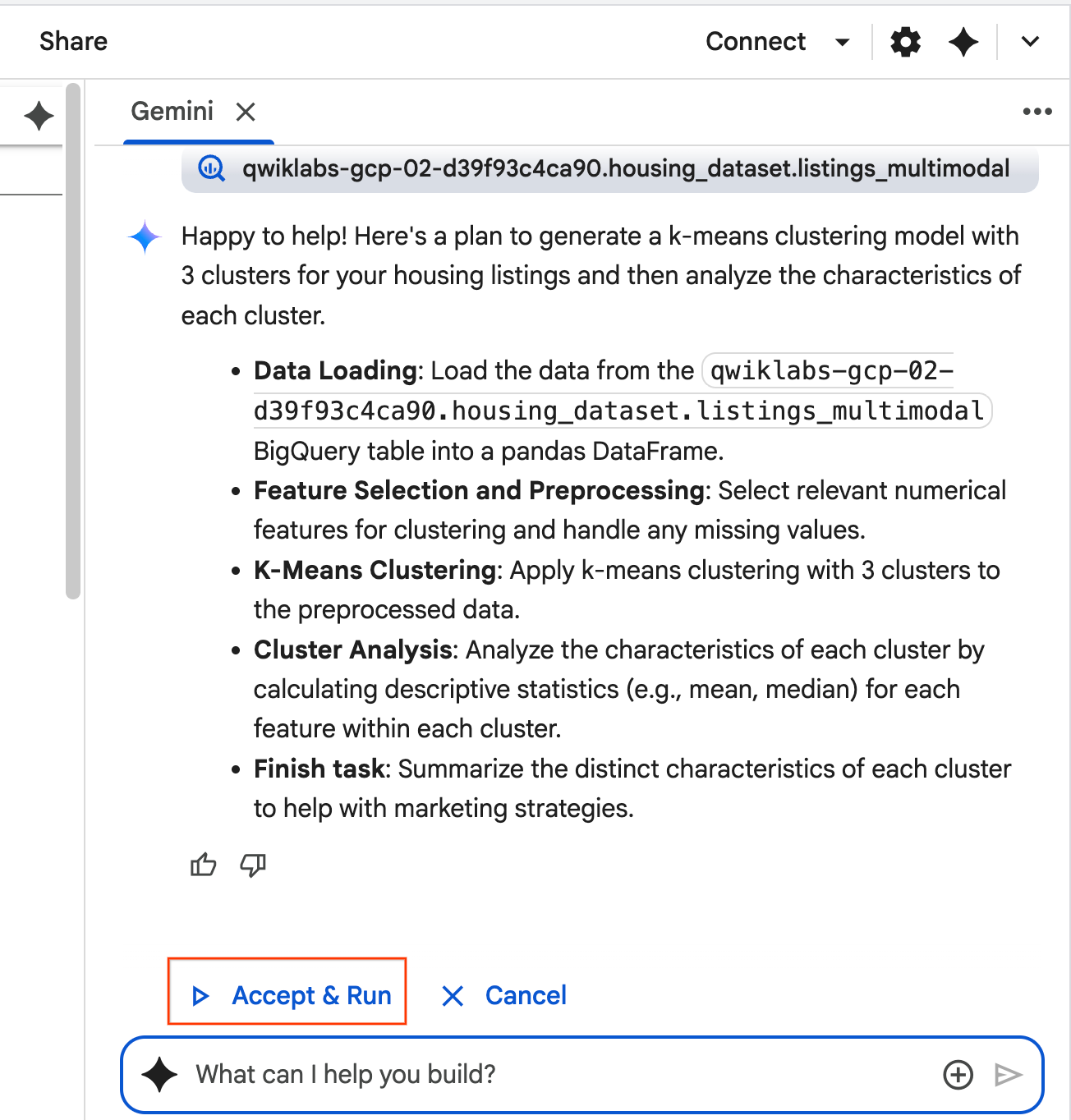
- הסוכן יבקש מכם לאשר ולהריץ כל בלוק קוד שהוא יוצר. כך האדם שבתהליך נשאר בתהליך. אתם יכולים לבדוק או לערוך את הקוד ולהמשיך בכל אחד מהשלבים עד שתסיימו.
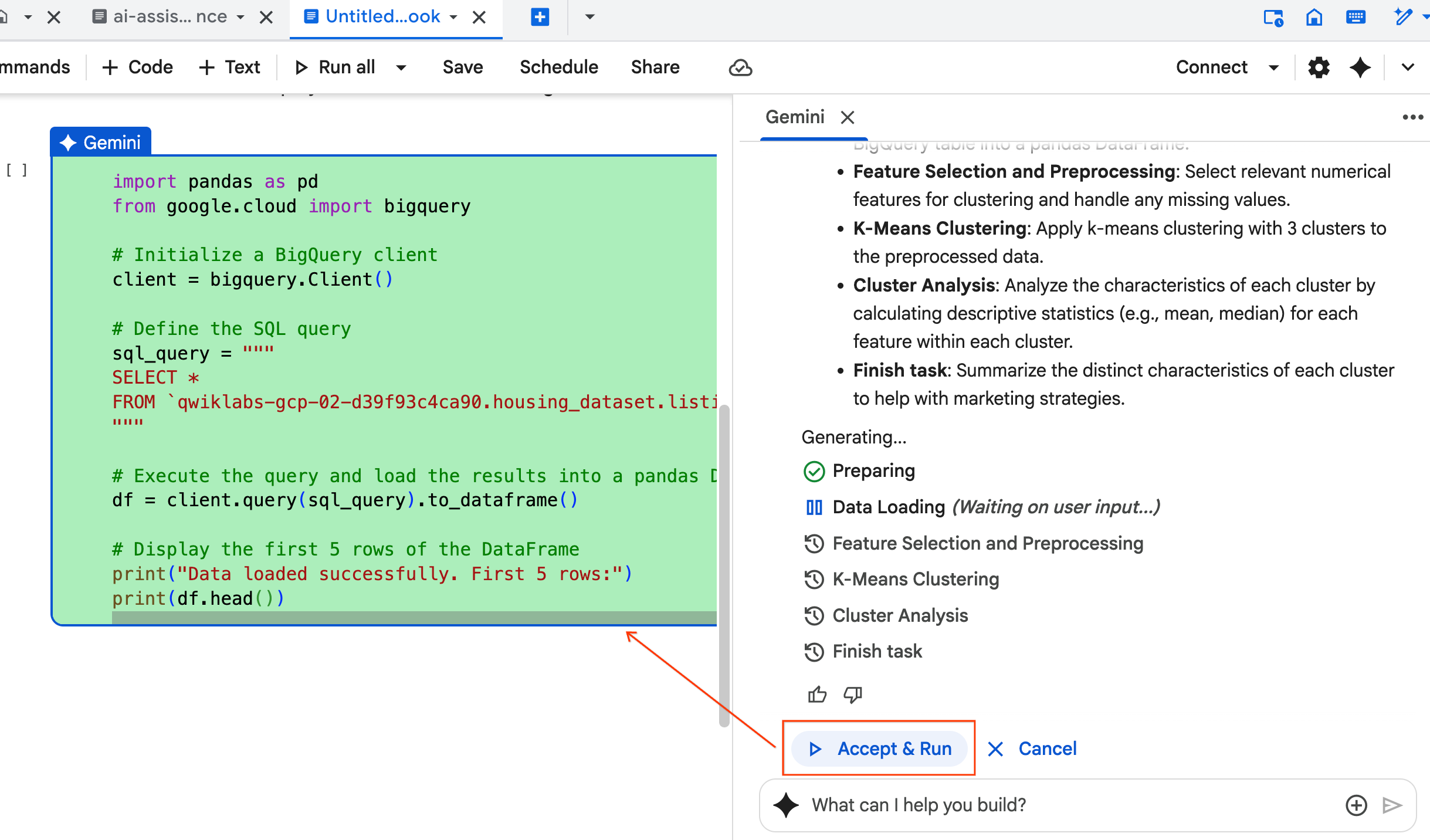
- בסיום, פשוט סוגרים את הכרטיסייה החדשה של המחברת וחוזרים לכרטיסייה המקורית
ai-assisted-data-science.ipynbכדי להמשיך לקטע האחרון של ה-Lab.
12. חיפוש מרובה מצבים באמצעות הטמעות וחיפוש וקטורי
בקטע האחרון הזה, תטמיעו חיפוש מולטימודאלי ישירות ב-BigQuery. כך אפשר לבצע חיפושים אינטואיטיביים, כמו חיפוש בתים על סמך תיאור טקסטואלי או חיפוש בתים שדומים לתמונה לדוגמה.
התהליך מתחיל בהמרת כל תמונה של בית לייצוג מספרי שנקרא הטמעה. הטמעה מתעדת את המשמעות הסמנטית של תמונה, ומאפשרת לכם למצוא פריטים דומים על ידי השוואה בין הווקטורים המספריים שלהם.
תשתמשו במודל multimodalembedding כדי ליצור את הווקטורים האלה לכל כרטיסי המוצר. אחרי שיוצרים אינדקס וקטורי כדי להאיץ את החיפושים, מבצעים שני סוגים של חיפוש דמיון: יצירת תמונות לפי טקסט (מציאת בתים שתואמים לתיאור) וחיפוש תמונה לתמונה (מציאת בתים שנראים כמו תמונה לדוגמה).
את כל הפעולות האלה מבצעים ב-BigQuery, באמצעות פונקציות כמו ML.GENERATE_EMBEDDING ליצירת הטבעות או VECTOR_SEARCH לחיפוש דמיון.
13. ניקוי
כדי לנקות את כל המשאבים של Google Cloud שנעשה בהם שימוש בפרויקט הזה, אפשר למחוק את הפרויקט של Google Cloud.
אפשר גם למחוק את המשאבים הבודדים שיצרתם על ידי הפעלת הקוד הבא בתא חדש במחברת:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
לבסוף, אפשר למחוק את המחברת עצמה:
- בחלונית Explorer ב-BigQuery Studio, מרחיבים את הפרויקט ואת הצומת Notebooks.
- לוחצים על סמל האפשרויות הנוספות (3 נקודות אנכיות) לצד מחברת
ai-assisted-data-science. - בוחרים באפשרות מחיקה.
14. מעולה!
כל הכבוד, סיימתם את ה-Codelab!
מה נכלל
- מכינים מערך נתונים גולמי של רשימות נדל"ן לניתוח באמצעות הנדסת תכונות.
- שיפור כרטיסי הנכסים באמצעות פונקציות ה-AI של BigQuery כדי לנתח תמונות של בתים ולזהות תכונות ויזואליות מרכזיות.
- ליצור ולהעריך מודל K-means באמצעות BigQuery Machine Learning (BQML) כדי לפלח נכסים לקלאסטרים נפרדים.
- יצירת מודל אוטומטית באמצעות Data Science Agent כדי ליצור מודל אשכולות עם Python.
- יצירת הטמעות של תמונות של בתים כדי להפעיל כלי לחיפוש חזותי, ולמצוא בתים דומים באמצעות שאילתות טקסט או תמונות.