
1. परिचय
खास जानकारी
इस लैब में, आपको BigQuery में मल्टीमॉडल डेटा साइंस वर्कफ़्लो के बारे में जानने को मिलेगा. यह वर्कफ़्लो, रियल एस्टेट के एक उदाहरण पर आधारित है. आपको घर की लिस्टिंग और उनकी इमेज के रॉ डेटासेट से शुरुआत करनी होगी. इसके बाद, विज़ुअल फ़ीचर निकालने के लिए, इस डेटा को एआई की मदद से बेहतर बनाना होगा. साथ ही, अलग-अलग मार्केट सेगमेंट का पता लगाने के लिए, क्लस्टरिंग मॉडल बनाना होगा. आखिर में, वेक्टर एम्बेडिंग का इस्तेमाल करके, विज़ुअल सर्च करने वाला एक बेहतरीन टूल बनाना होगा.
इस एसक्यूएल-नेटिव वर्कफ़्लो की तुलना, जनरेटिव एआई के आधुनिक तरीके से की जाएगी. इसके लिए, डेटा साइंस एजेंट का इस्तेमाल करके, टेक्स्ट प्रॉम्प्ट से अपने-आप Python पर आधारित क्लस्टरिंग मॉडल जनरेट किया जाएगा.
आपको क्या सीखने को मिलेगा
- फ़िचर इंजीनियरिंग की मदद से विश्लेषण करने के लिए, रीयल एस्टेट लिस्टिंग का कच्चा डेटासेट तैयार करें.
- लिस्टिंग को बेहतर बनाएं. इसके लिए, BigQuery के एआई फ़ंक्शन का इस्तेमाल करके, घर की फ़ोटो में मौजूद मुख्य विज़ुअल सुविधाओं का विश्लेषण करें.
- प्रॉपर्टी को अलग-अलग क्लस्टर में सेगमेंट करने के लिए, BigQuery Machine Learning (BQML) की मदद से K-means मॉडल बनाएं और उसका आकलन करें.
- Python की मदद से क्लस्टरिंग मॉडल जनरेट करने के लिए, Data Science Agent का इस्तेमाल करके मॉडल अपने-आप बनने की सुविधा चालू करें.
- घर की इमेज के लिए, एम्बेडिंग जनरेट करें, ताकि विज़ुअल सर्च टूल को बेहतर बनाया जा सके. इससे टेक्स्ट या इमेज क्वेरी की मदद से, मिलते-जुलते घर ढूंढे जा सकते हैं.
ज़रूरी शर्तें
इस लैब को शुरू करने से पहले, आपको इनके बारे में जानकारी होनी चाहिए:
- एसक्यूएल और Python प्रोग्रामिंग की बुनियादी जानकारी.
- Jupyter notebook में Python कोड चलाना.
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell की मदद से एपीआई चालू करना
Cloud Shell, Google Cloud में चलने वाला एक कमांड-लाइन एनवायरमेंट है. इसमें ज़रूरी टूल पहले से लोड होते हैं.
- Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें:

- Cloud Shell से कनेक्ट होने के बाद, Cloud Shell में पुष्टि करने के लिए यह कमांड चलाएं:
gcloud auth list
- यह पुष्टि करने के लिए कि आपका प्रोजेक्ट, gcloud के साथ इस्तेमाल करने के लिए कॉन्फ़िगर किया गया है, यह निर्देश चलाएं:
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
एपीआई चालू करें
- सभी ज़रूरी एपीआई और सेवाओं को चालू करने के लिए, यह निर्देश चलाएं:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- कमांड के सही तरीके से लागू होने पर, आपको यहां दिखाए गए मैसेज जैसा कोई मैसेज दिखेगा:
Operation "operations/..." finished successfully.
- Cloud Shell से बाहर निकलें.
3. BigQuery Studio में Lab Notebook खोलना
यूज़र इंटरफ़ेस (यूआई) में एक जगह से दूसरी जगह जाने के लिए:
- Google Cloud Console में, नेविगेशन मेन्यू > BigQuery पर जाएं.
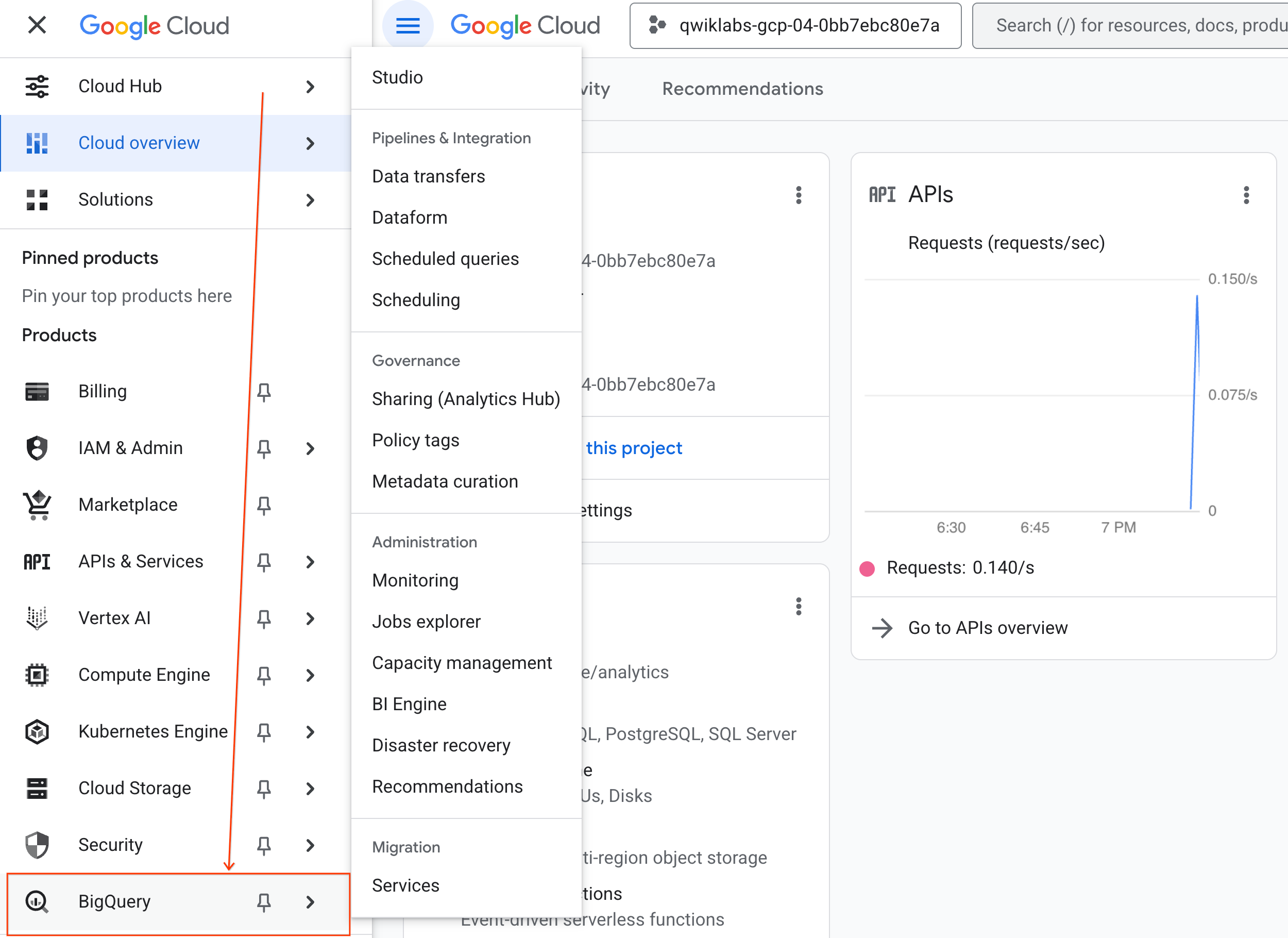
- BigQuery Studio पैनल में, ड्रॉपडाउन ऐरो बटन पर क्लिक करें. इसके बाद, नोटबुक पर कर्सर घुमाएं. फिर, अपलोड करें को चुनें.
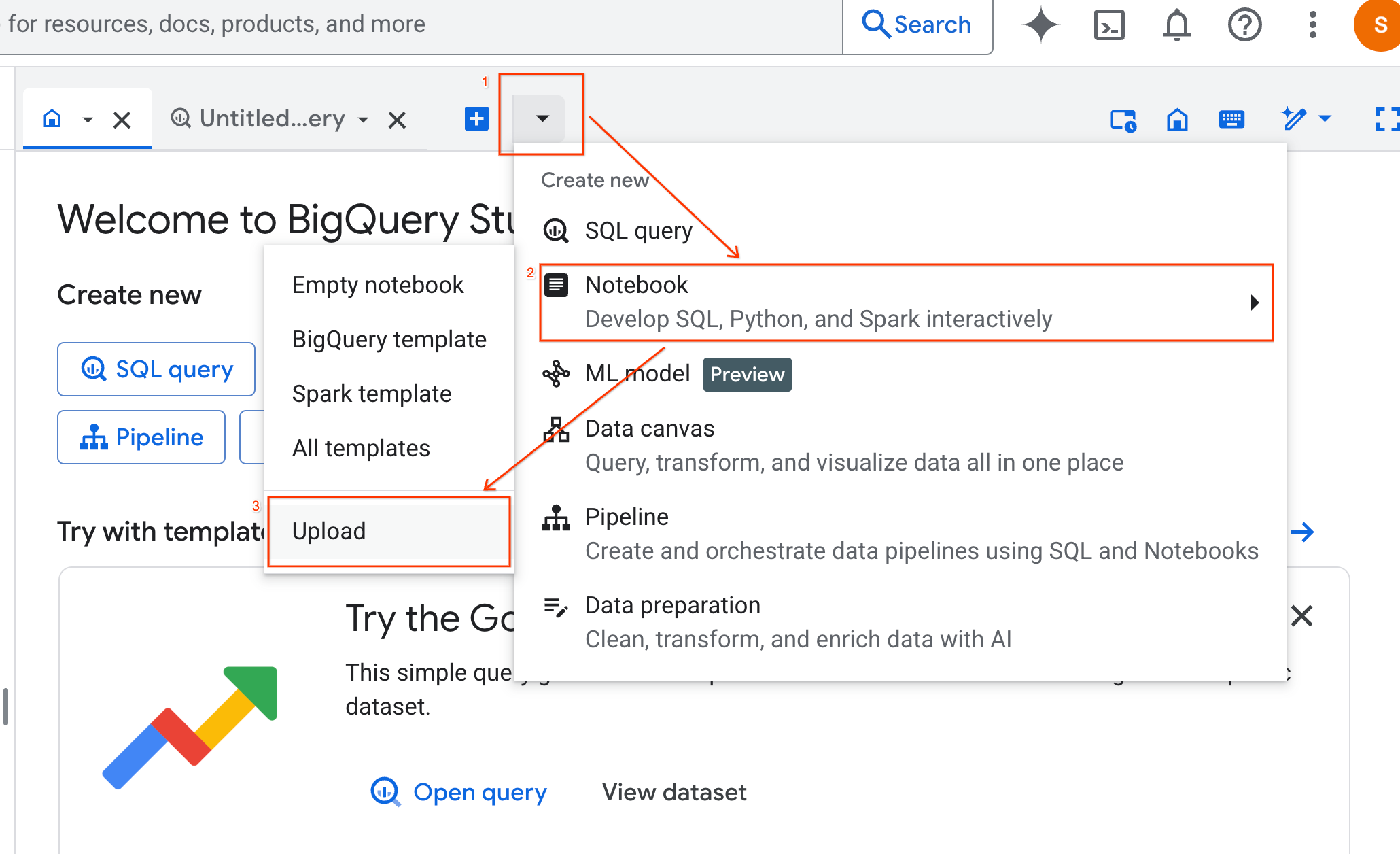
- यूआरएल रेडियो बटन चुनें और यह यूआरएल डालें:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- क्षेत्र को
us-central1पर सेट करें और अपलोड करें पर क्लिक करें.
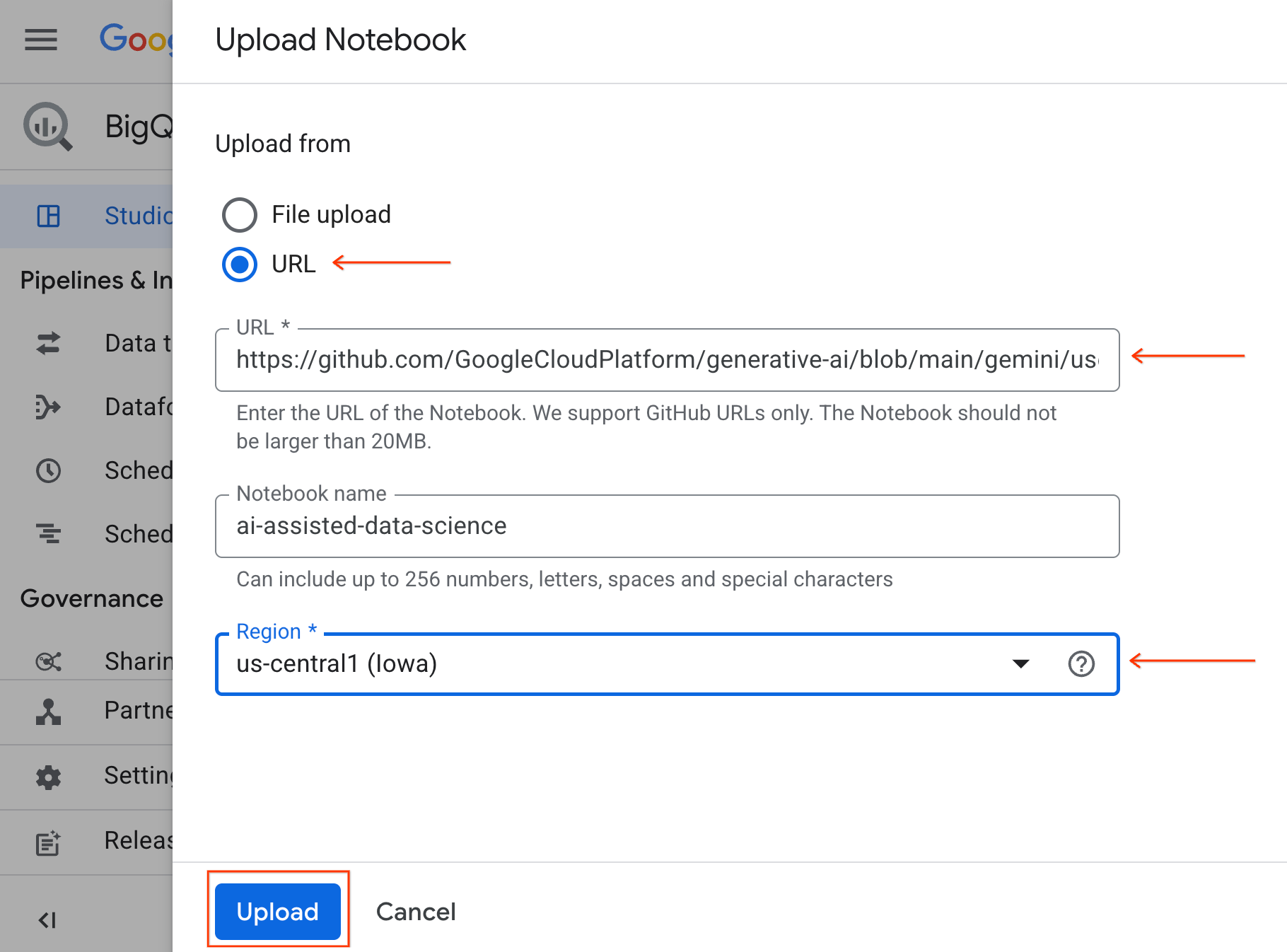
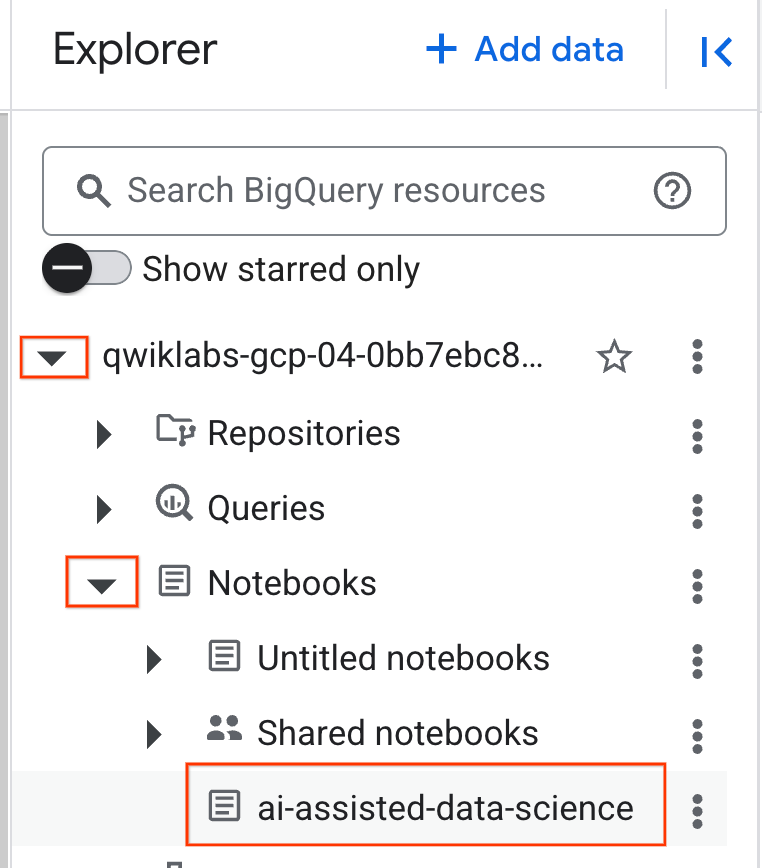
- नोटबुक खोलने के लिए, एक्सप्लोरर पैनल में मौजूद ड्रॉपडाउन ऐरो पर क्लिक करें. इस पैनल में आपका प्रोजेक्ट आईडी होता है. इसके बाद, नोटबुक के लिए, ड्रॉपडाउन पर क्लिक करें. नोटबुक
ai-assisted-data-scienceपर क्लिक करें.
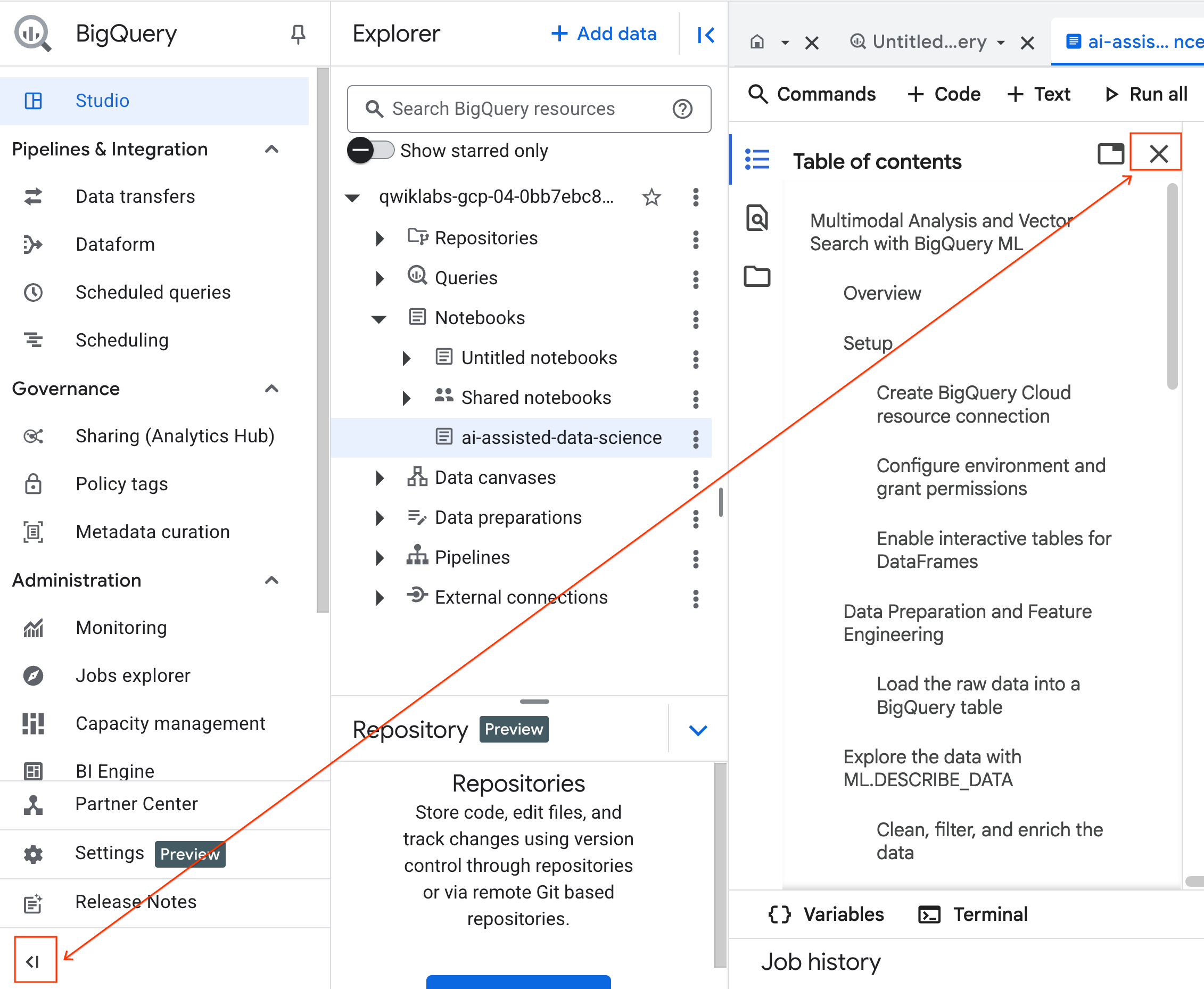
- (ज़रूरी नहीं) ज़्यादा जगह पाने के लिए, BigQuery नेविगेशन मेन्यू और नोटबुक की विषय सूची को छोटा करें.
4. किसी रनटाइम से कनेक्ट करना और सेटअप कोड चलाना
- कनेक्ट करें पर क्लिक करें. अगर कोई पॉप-अप दिखता है, तो अपने उपयोगकर्ता खाते से Colab Enterprise को अनुमति दें. आपकी नोटबुक, रनटाइम से अपने-आप कनेक्ट हो जाएगी. इस प्रोसेस को पूरा होने में कुछ मिनट लग सकते हैं.
- रनटाइम तय होने के बाद, आपको यह दिखेगा:
- नोटबुक में, स्क्रोल करके सेटअप सेक्शन पर जाएं. छिपी हुई सेल के बगल में मौजूद "चलाएं" बटन पर क्लिक करें. इससे आपके प्रोजेक्ट में लैब के लिए ज़रूरी कुछ संसाधन बन जाते हैं. इस प्रोसेस को पूरा होने में एक मिनट लग सकता है. इस बीच, सेटअप में जाकर सेल देखें.
5. डेटा तैयार करना और फ़ीचर इंजीनियरिंग
इस सेक्शन में, आपको डेटा साइंस के किसी भी प्रोजेक्ट का पहला ज़रूरी चरण पूरा करने का तरीका बताया जाएगा. यह चरण है, डेटा तैयार करना. सबसे पहले, अपना काम व्यवस्थित करने के लिए एक BigQuery डेटासेट बनाएं. इसके बाद, Cloud Storage में मौजूद CSV फ़ाइल से, रियल एस्टेट / हाउसिंग का रॉ डेटा नई टेबल में लोड करें.
इसके बाद, इस रॉ डेटा को नई सुविधाओं वाली साफ़-सुथरी टेबल में बदला जाएगा. इसमें लिस्टिंग को फ़िल्टर करना, नई property_age सुविधा बनाना, और मल्टीमॉडल विश्लेषण के लिए इमेज डेटा तैयार करना शामिल है.
6. एआई फ़ंक्शन की मदद से मल्टीमॉडल डेटा को बेहतर बनाना
अब जनरेटिव एआई की मदद से, अपने डेटा को बेहतर बनाया जा सकता है. इस सेक्शन में, हर घर की लिस्टिंग के लिए इमेज का विश्लेषण करने के लिए, BigQuery के बिल्ट-इन एआई फ़ंक्शन का इस्तेमाल किया जाता है.
BigQuery को Gemini मॉडल से कनेक्ट करके, सीधे एसक्यूएल की मदद से इमेज से नई और काम की सुविधाएं निकाली जा सकती हैं. जैसे, कोई प्रॉपर्टी पानी के आस-पास है या नहीं और घर के बारे में खास जानकारी.
7. के-मीन्स क्लस्टरिंग की मदद से मॉडल को ट्रेनिंग देना
डेटा को बेहतर बनाने के बाद, अब आपके पास मशीन लर्निंग मॉडल बनाने का विकल्प है. आपका लक्ष्य, घर की लिस्टिंग को अलग-अलग ग्रुप में बांटना है. इसके लिए, आपको BigQuery Machine Learning (BQML) का इस्तेमाल करके, BigQuery में सीधे तौर पर K-means क्लस्टरिंग मॉडल को ट्रेन करना होगा. इस एक ही चरण में, मॉडल को Agent Platform AI Model Registry में भी रजिस्टर किया जाता है. इससे यह Google Cloud पर, MLOps के बड़े इकोसिस्टम में तुरंत उपलब्ध हो जाता है.
यह पुष्टि करने के लिए कि आपका मॉडल रजिस्टर हो गया है, इसे एजेंट प्लैटफ़ॉर्म मॉडल रजिस्ट्री में देखा जा सकता है. इसके लिए, यह तरीका अपनाएं:
- Google Cloud Console में, सबसे ऊपर बाएं कोने में मौजूद नेविगेशन मेन्यू (☰) पर क्लिक करें.
- नीचे की ओर स्क्रोल करके, Agent Platform सेक्शन पर जाएं. इसके बाद, Models पर क्लिक करें.
- स्क्रीनशॉट में हाइलाइट किए गए मॉडल रजिस्ट्री बटन पर क्लिक करें.
- आपको अपना BQML मॉडल, अपने अन्य सभी कस्टम मॉडल के साथ दिखेगा. मॉडल की सूची में, housing_clustering नाम का मॉडल ढूंढें. इसके बाद, एंडपॉइंट पर डिप्लॉय करें का विकल्प चुना जा सकता है. इससे आपका मॉडल, BigQuery एनवायरमेंट के बाहर रीयल-टाइम में ऑनलाइन अनुमान लगाने के लिए उपलब्ध हो जाएगा.
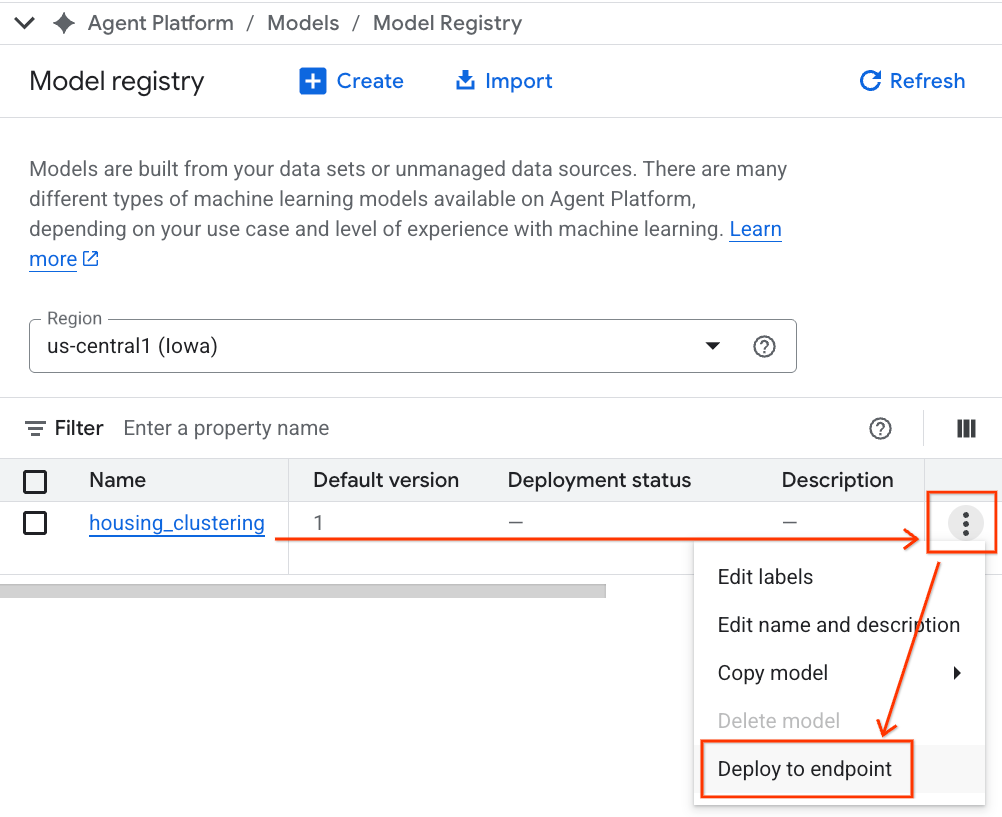
मॉडल रजिस्ट्री एक्सप्लोर करने के बाद, इन चरणों को अपनाकर BigQuery में अपनी Colab नोटबुक पर वापस जाएं:
- नेविगेशन मेन्यू (☰) में, BigQuery > Studio पर जाएं.
- अपनी नोटबुक ढूंढने और उसे खोलने के लिए, एक्सप्लोर करें पैनल में मौजूद मेन्यू को बड़ा करें.
8. मॉडल का आकलन और अनुमान
अपने मॉडल को ट्रेन करने के बाद, अगला चरण यह समझना है कि मॉडल ने कौनसे क्लस्टर बनाए हैं. यहां, मॉडल की क्वालिटी और हर सेगमेंट की खास बातों का विश्लेषण करने के लिए, BigQuery के मशीन लर्निंग फ़ंक्शन, जैसे कि ML.EVALUATE और ML.CENTROIDS का इस्तेमाल किया जाता है.
इसके बाद, हर घर को किसी क्लस्टर में असाइन करने के लिए, ML.PREDICT का इस्तेमाल करें. %%bigquery df मैजिक कमांड के साथ इस क्वेरी को चलाने पर, नतीजों को df नाम के pandas DataFrame में सेव किया जाता है. इससे डेटा, Python के अगले चरणों के लिए तुरंत उपलब्ध हो जाता है. इससे पता चलता है कि Colab Enterprise में SQL और Python एक-दूसरे के साथ कैसे काम करते हैं.
9. क्लस्टर को विज़ुअलाइज़ करना और उनकी व्याख्या करना
अनुमानों को DataFrame में लोड करने के बाद, डेटा को दिलचस्प बनाने के लिए विज़ुअलाइज़ेशन बनाए जा सकते हैं. इस सेक्शन में, हाउसिंग सेगमेंट के बीच के अंतर को एक्सप्लोर करने के लिए, Matplotlib जैसी लोकप्रिय Python लाइब्रेरी का इस्तेमाल किया जाएगा.
कीमत और प्रॉपर्टी की उम्र जैसी मुख्य सुविधाओं की तुलना करने के लिए, बॉक्स प्लॉट और बार चार्ट बनाए जाएंगे. इससे, हर क्लस्टर को आसानी से समझा जा सकेगा.
10. Gemini के मॉडल की मदद से क्लस्टर के ब्यौरे जनरेट करना
न्यूमेरिकल सेंट्रॉइड और चार्ट काफ़ी मददगार होते हैं. हालांकि, जनरेटिव एआई की मदद से, हर हाउसिंग सेगमेंट के लिए ज़्यादा जानकारी वाले और क्वालिटी वाले पर्सोना बनाए जा सकते हैं. इससे आपको यह समझने में मदद मिलती है कि क्लस्टर क्या हैं और वे किसकी जानकारी देते हैं.
इस सेक्शन में, आपको सबसे पहले हर क्लस्टर के लिए औसत आंकड़े इकट्ठा करने होंगे. जैसे, कीमत और स्क्वेयर फ़ीट. इसके बाद, इस डेटा को Gemini मॉडल के लिए प्रॉम्प्ट में पास करें. इसके बाद, मॉडल को रियल एस्टेट के पेशेवर के तौर पर काम करने के लिए कहा जाता है. साथ ही, हर सेगमेंट के लिए मुख्य विशेषताओं और टारगेट खरीदार के बारे में जानकारी देने वाली खास जानकारी जनरेट करने के लिए कहा जाता है. नतीजे में, ऐसी जानकारी मिलती है जिसे कोई भी व्यक्ति आसानी से पढ़ सकता है. इससे मार्केटिंग टीम को क्लस्टर के बारे में तुरंत पता चल जाता है और वह कार्रवाई कर पाती है.
अपनी ज़रूरत के हिसाब से प्रॉम्प्ट में बदलाव करें और नतीजों के साथ एक्सपेरिमेंट करें!
11. डेटा साइंस एजेंट की मदद से मॉडलिंग को ऑटोमेट करना
अब आपको एक बेहतर और वैकल्पिक वर्कफ़्लो के बारे में बताया जाएगा. मैन्युअल तरीके से कोड लिखने के बजाय, इंटिग्रेट किए गए डेटा साइंस एजेंट का इस्तेमाल किया जाएगा. इससे, आम बोलचाल की भाषा में दिए गए एक प्रॉम्प्ट से, पूरा क्लस्टरिंग मॉडल वर्कफ़्लो अपने-आप जनरेट हो जाएगा.
एजेंट का इस्तेमाल करके मॉडल जनरेट करने और उसे चलाने के लिए, यह तरीका अपनाएं:
- BigQuery Studio पैनल में, ड्रॉपडाउन ऐरो बटन पर क्लिक करें. इसके बाद, नोटबुक पर कर्सर घुमाएं और खाली नोटबुक चुनें. इससे यह पक्का होता है कि एजेंट का कोड, आपकी ओरिजनल लैब नोटबुक में कोई रुकावट न डाले.
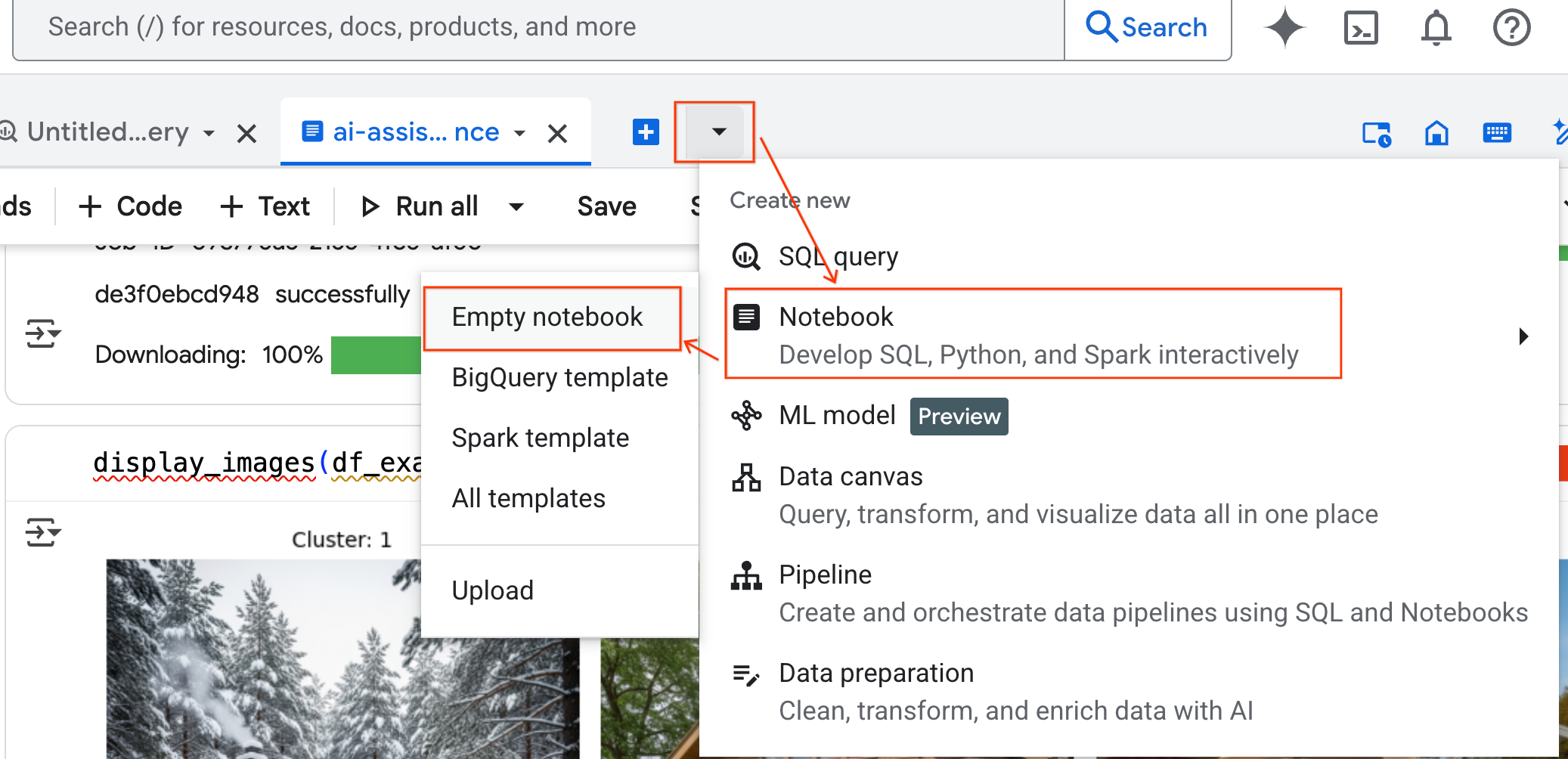
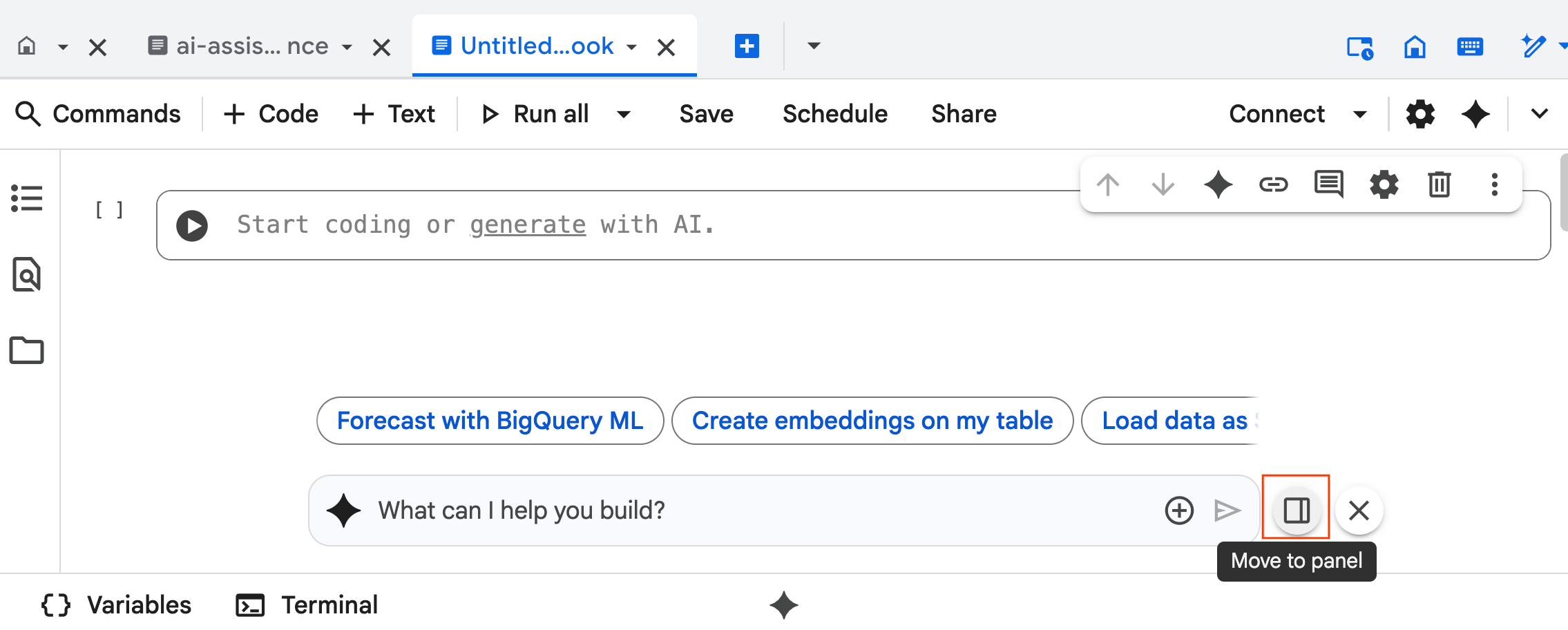
- नोटबुक में सबसे नीचे, डेटा साइंस एजेंट का चैट इंटरफ़ेस खुलता है. चैट को दाईं ओर पिन करने के लिए, पैनल में ले जाएं बटन पर क्लिक करें.
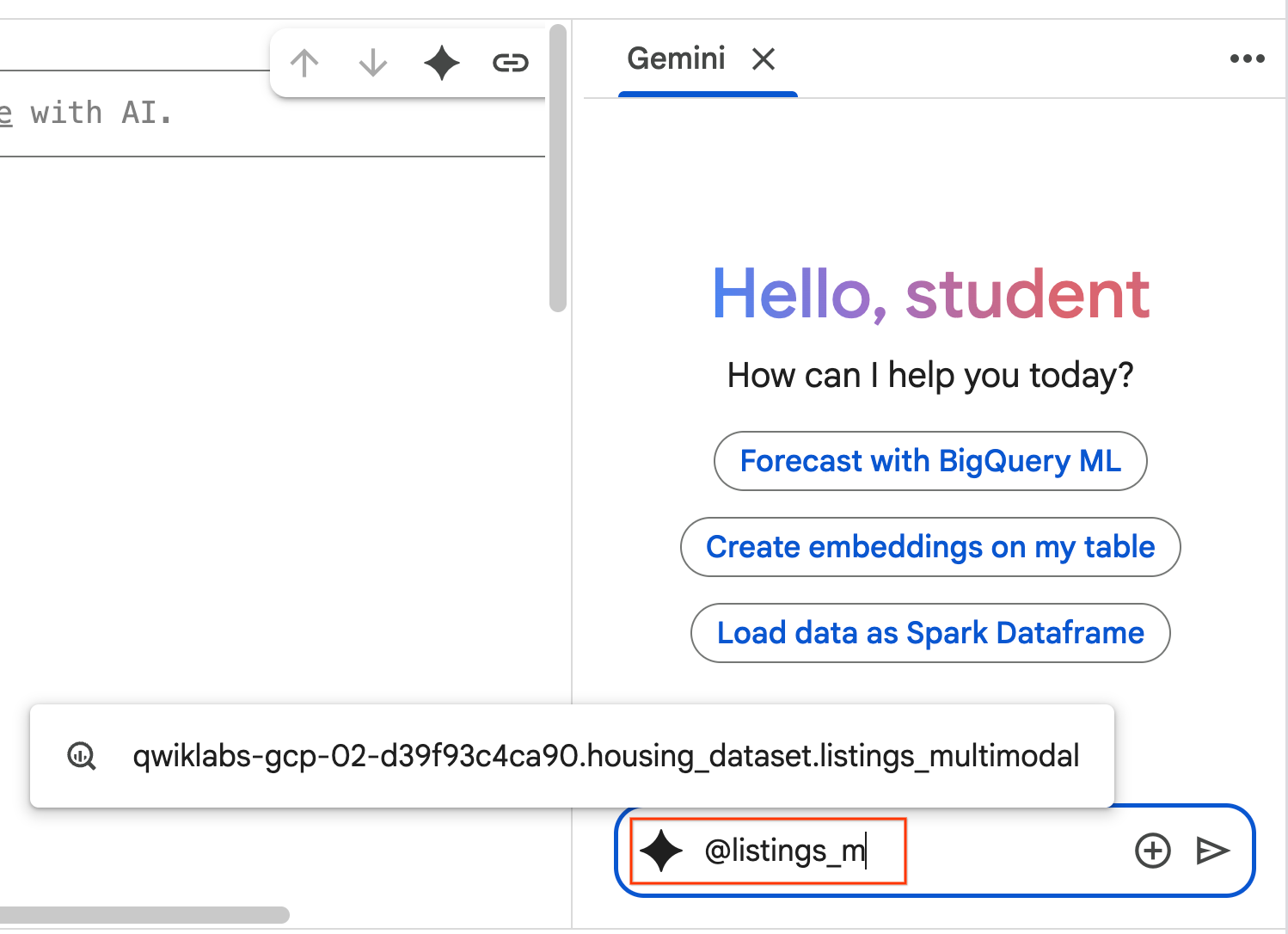
- चैट पैनल में
@listing_multimodalटाइप करना शुरू करें और टेबल पर क्लिक करें. इससेlistings_multimodalटेबल को संदर्भ के तौर पर साफ़ तौर पर सेट किया जाता है.
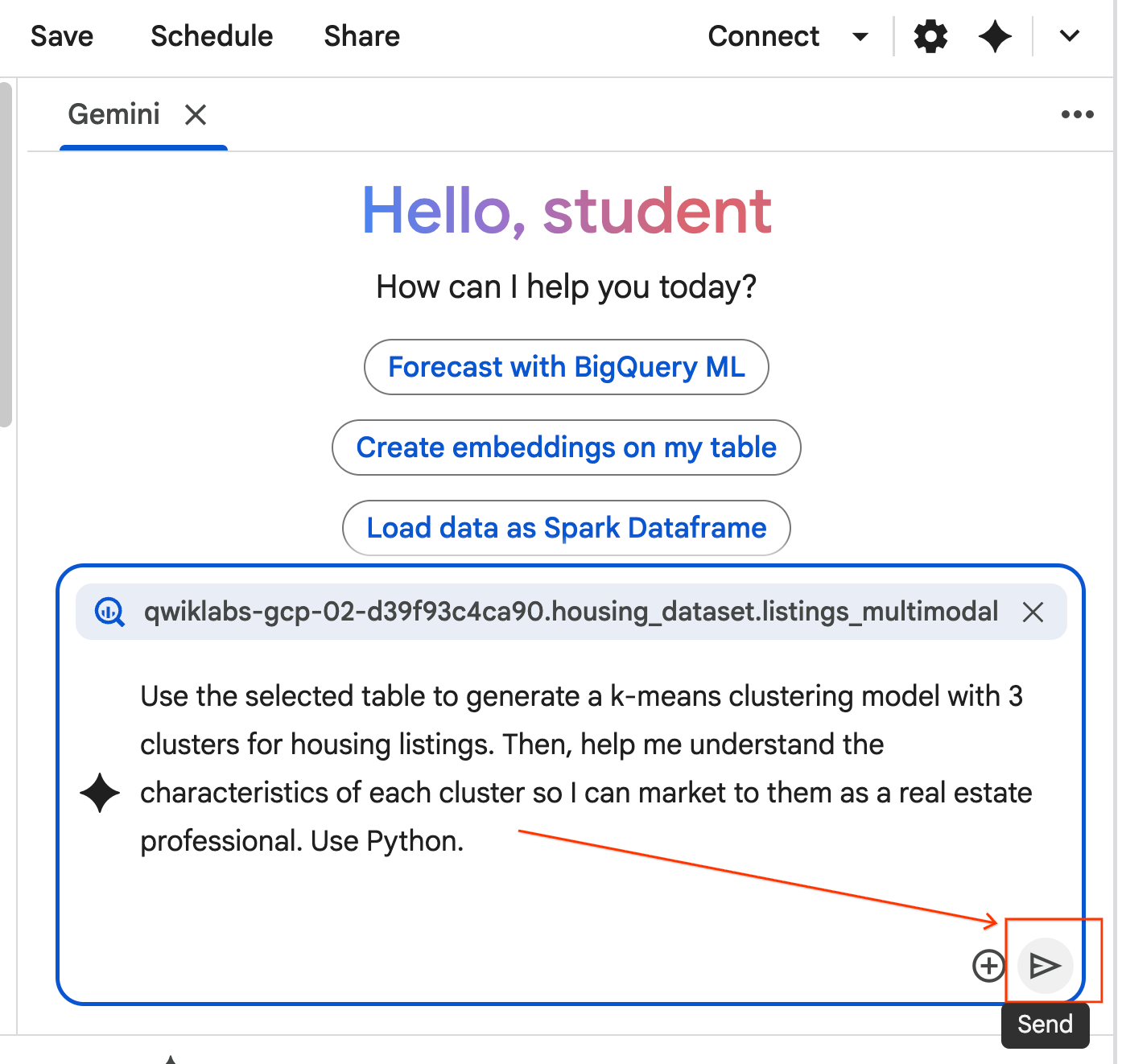
- नीचे दिए गए प्रॉम्प्ट को कॉपी करें और उसे एजेंट चैट बॉक्स में डालें. इसके बाद, एजेंट को प्रॉम्प्ट सबमिट करने के लिए, भेजें पर क्लिक करें.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- एजेंट, प्लान के बारे में सोचेगा और उसे तैयार करेगा. अगर आपको यह प्लान सही लगता है, तो स्वीकार करें और चलाएं पर क्लिक करें. एजेंट, एक या उससे ज़्यादा नई सेल में Python कोड जनरेट करेगा.
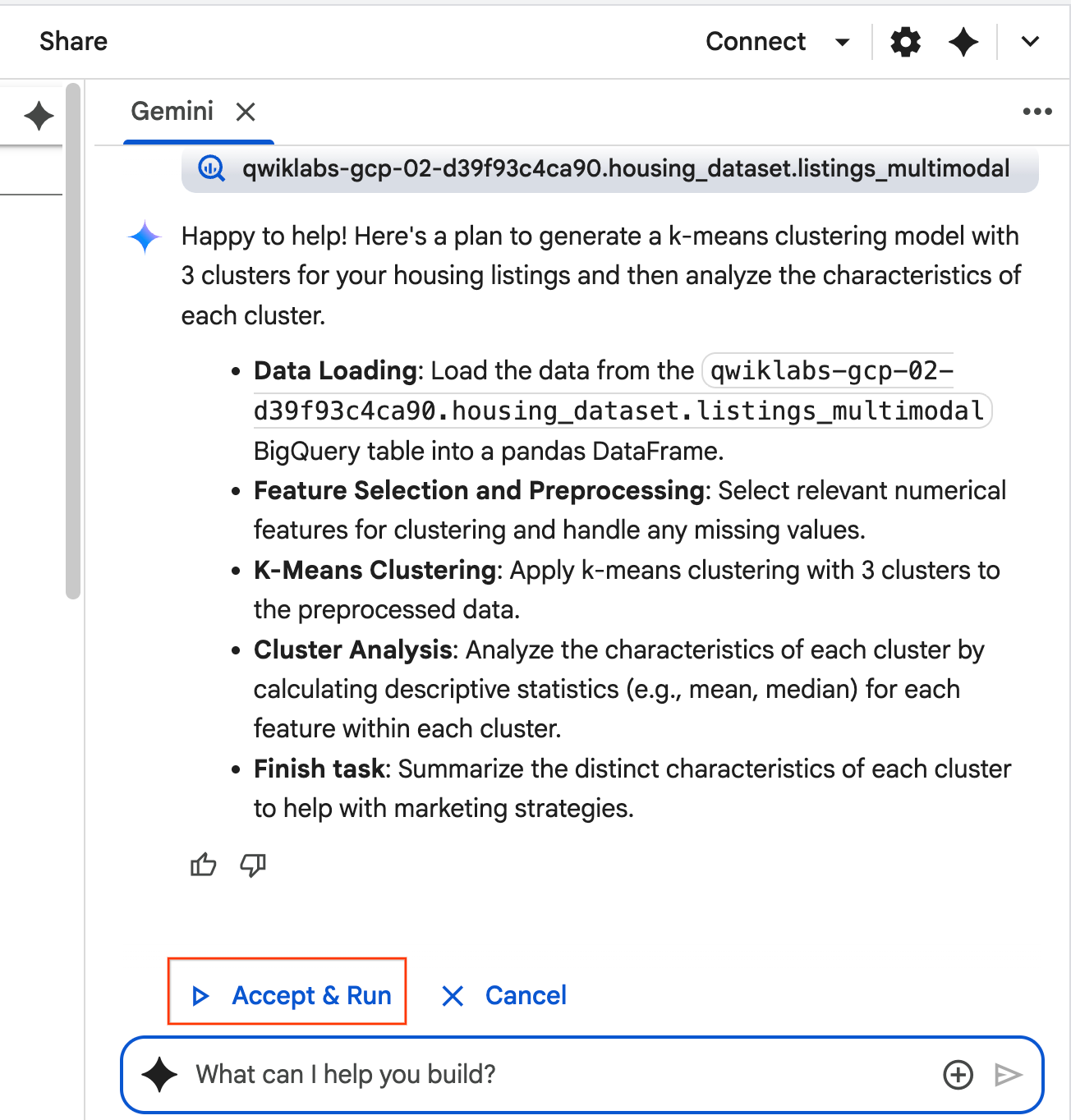
- एजेंट, जनरेट किए गए कोड के हर ब्लॉक को स्वीकार करने और चलाने के लिए कहता है. इससे, लोगों की भागीदारी बनी रहती है. कोड की समीक्षा करें या उसमें बदलाव करें. इसके बाद, हर चरण को पूरा करें.
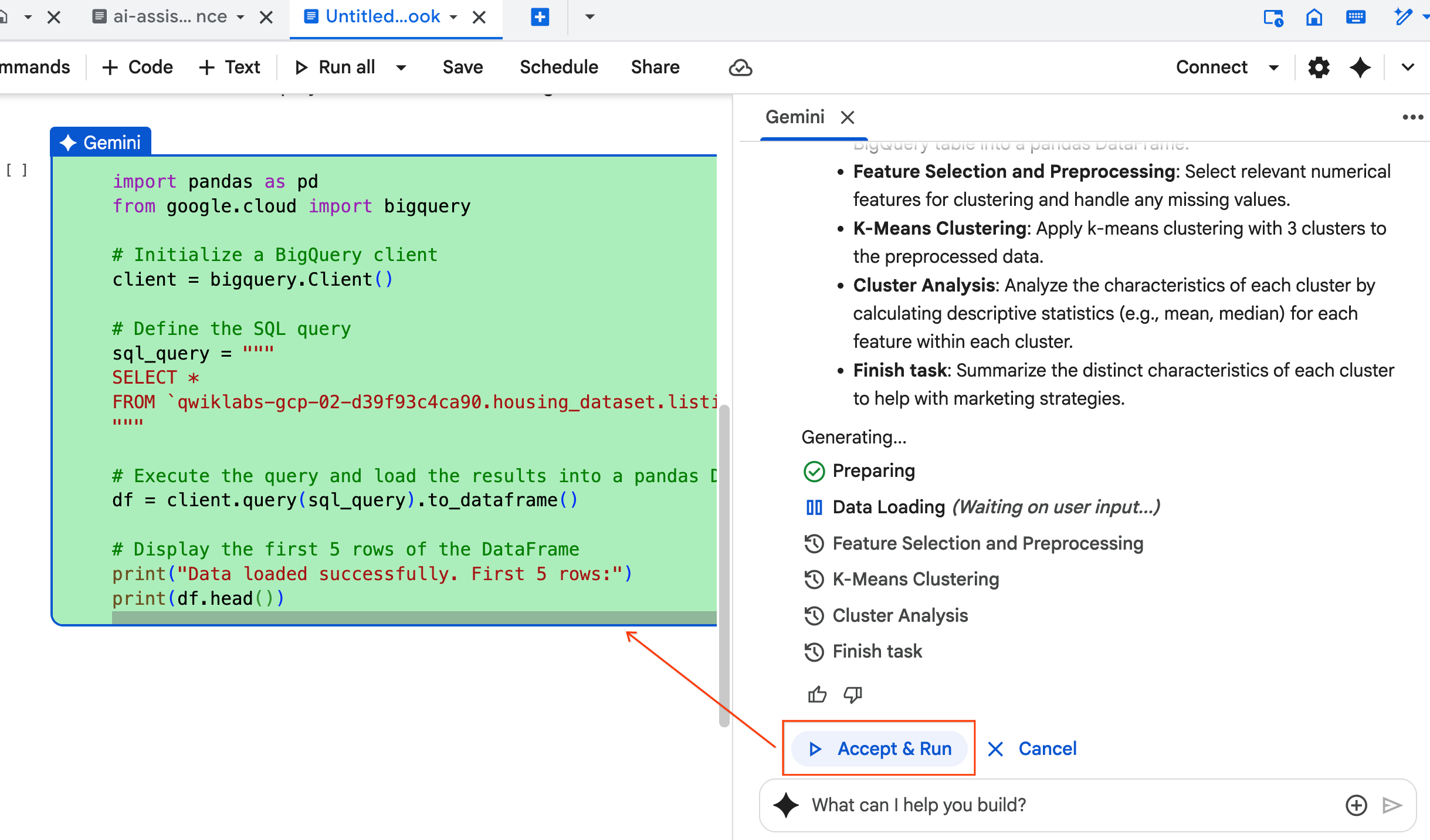
- जब आप यह काम पूरा कर लें, तब इस नई नोटबुक टैब को बंद कर दें. इसके बाद, लैब के आखिरी सेक्शन पर जाने के लिए,
ai-assisted-data-science.ipynbटैब पर वापस जाएं.
12. एंबेडिंग और वेक्टर सर्च की मदद से मल्टीमोडल सर्च
इस आखिरी सेक्शन में, BigQuery में सीधे तौर पर मल्टीमॉडल खोज को लागू किया जाता है. इससे, आसानी से खोज की जा सकती है. जैसे, टेक्स्ट के ब्यौरे के आधार पर घर ढूंढना या सैंपल फ़ोटो से मिलते-जुलते घर ढूंढना.
इस प्रोसेस में, सबसे पहले हर घर की इमेज को संख्या के तौर पर दिखाया जाता है. इसे एम्बेडिंग कहा जाता है. एम्बेडिंग, किसी इमेज के सिमैंटिक मतलब को कैप्चर करती है. इससे, संख्या वाले वेक्टर की तुलना करके मिलते-जुलते सामान ढूंढे जा सकते हैं.
अपनी सभी लिस्टिंग के लिए इन वेक्टर को जनरेट करने के लिए, multimodalembedding मॉडल का इस्तेमाल करें. वेक्टर इंडेक्स बनाने के बाद, दो तरह की मिलती-जुलती इमेज खोजी जाती हैं. पहली, टेक्स्ट से इमेज खोजना. जैसे, किसी ब्यौरे से मिलते-जुलते घर खोजना. दूसरी, इमेज से इमेज खोजना. जैसे, किसी सैंपल इमेज से मिलते-जुलते घर खोजना. वेक्टर इंडेक्स बनाने से, मिलती-जुलती इमेज को तेज़ी से खोजा जा सकता है.
यह सब BigQuery में किया जाएगा. इसके लिए, ML.GENERATE_EMBEDDING जैसे फ़ंक्शन का इस्तेमाल करके एम्बेडिंग जनरेट की जा सकती हैं या VECTOR_SEARCH का इस्तेमाल करके मिलती-जुलती जानकारी खोजी जा सकती है.
13. क्लीन अप करना
इस प्रोजेक्ट में इस्तेमाल किए गए सभी Google Cloud संसाधनों को हटाने के लिए, Google Cloud प्रोजेक्ट मिटाया जा सकता है.
इसके अलावा, अपनी नोटबुक की नई सेल में यह कोड चलाकर, बनाए गए अलग-अलग संसाधनों को मिटाया जा सकता है:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
आखिर में, नोटबुक को मिटाया जा सकता है:
- BigQuery Studio के एक्सप्लोरर पैनल में, अपने प्रोजेक्ट और नोटबुक नोड को बड़ा करें.
ai-assisted-data-scienceनोटबुक के बगल में मौजूद, तीन वर्टिकल बिंदुओं पर क्लिक करें.- मिटाएं चुनें.
14. बधाई हो!
कोडलैब पूरा करने के लिए बधाई!
हमने क्या-क्या कवर किया है
- फ़िचर इंजीनियरिंग की मदद से विश्लेषण करने के लिए, रीयल एस्टेट लिस्टिंग का कच्चा डेटासेट तैयार करें.
- लिस्टिंग को बेहतर बनाएं. इसके लिए, BigQuery के एआई फ़ंक्शन का इस्तेमाल करके, घर की फ़ोटो में मौजूद मुख्य विज़ुअल सुविधाओं का विश्लेषण करें.
- BigQuery Machine Learning (BQML) की मदद से, K-means मॉडल बनाएं और उसका आकलन करें. इससे प्रॉपर्टी को अलग-अलग क्लस्टर में बांटा जा सकता है.
- Python की मदद से क्लस्टरिंग मॉडल जनरेट करने के लिए, Data Science Agent का इस्तेमाल करके मॉडल अपने-आप बनने की सुविधा चालू करें.
- घर की इमेज के लिए, एम्बेडिंग जनरेट करें, ताकि विज़ुअल सर्च टूल को बेहतर बनाया जा सके. इससे टेक्स्ट या इमेज क्वेरी की मदद से, मिलते-जुलते घर ढूंढे जा सकते हैं.