
1. Introduzione
Panoramica
In questo lab esplorerai un workflow di data science multimodale in BigQuery, incentrato su uno scenario immobiliare. Inizierai con un set di dati non elaborati di annunci di case e relative immagini, arricchirai questi dati con l'AI per estrarre le caratteristiche visive, creerai un modello di clustering per scoprire segmenti di mercato distinti e, infine, creerai un potente strumento di ricerca visiva utilizzando i vector embedding.
Confronterai questo flusso di lavoro nativo SQL con un approccio moderno di AI generativa utilizzando l'agente Data Science per generare automaticamente un modello di clustering basato su Python da un semplice prompt di testo.
Obiettivi didattici
- Prepara un set di dati non elaborati di schede immobiliari per l'analisi tramite il feature engineering.
- Arricchisci le schede utilizzando le funzioni AI di BigQuery per analizzare le foto della casa e identificare le caratteristiche visive chiave.
- Crea e valuta un modello K-means con BigQuery Machine Learning (BQML) per segmentare le proprietà in cluster distinti.
- Automatizza la creazione di modelli utilizzando il Data Science Agent per generare un modello di clustering con Python.
- Genera embedding per le immagini delle case per potenziare uno strumento di ricerca visiva, trovando case simili con query di testo o immagini.
Prerequisiti
Prima di iniziare questo lab, dovresti acquisire familiarità con:
- Concetti di base della programmazione in SQL e Python.
- Esecuzione di codice Python in un notebook Jupyter.
2. Prima di iniziare
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Abilitare le API con Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene precaricato con gli strumenti necessari.
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud:

- Una volta connesso a Cloud Shell, esegui questo comando per verificare l'autenticazione in Cloud Shell:
gcloud auth list
- Esegui questo comando per verificare che il progetto sia configurato per l'utilizzo con gcloud:
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Abilita API
- Esegui questo comando per abilitare tutte le API e i servizi richiesti:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- Se il comando viene eseguito correttamente, dovresti visualizzare un messaggio simile a quello mostrato di seguito:
Operation "operations/..." finished successfully.
- Esci da Cloud Shell.
3. Apri il notebook del lab in BigQuery Studio
Navigazione nell'interfaccia utente:
- Nella console Google Cloud, vai a Menu di navigazione > BigQuery.
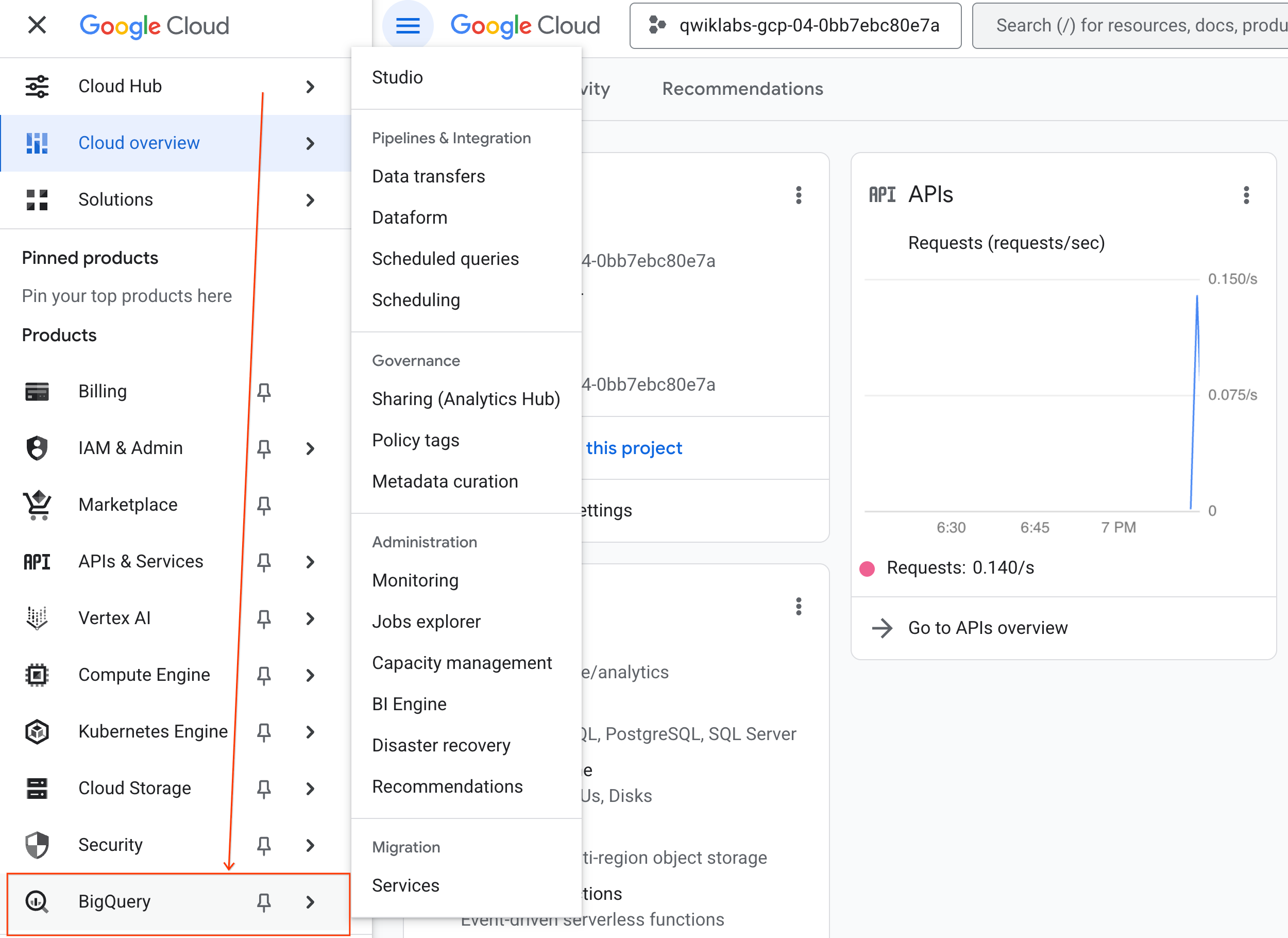
- Nel riquadro BigQuery Studio, fai clic sul pulsante Freccia giù, passa il mouse sopra Notebook e poi seleziona Carica.
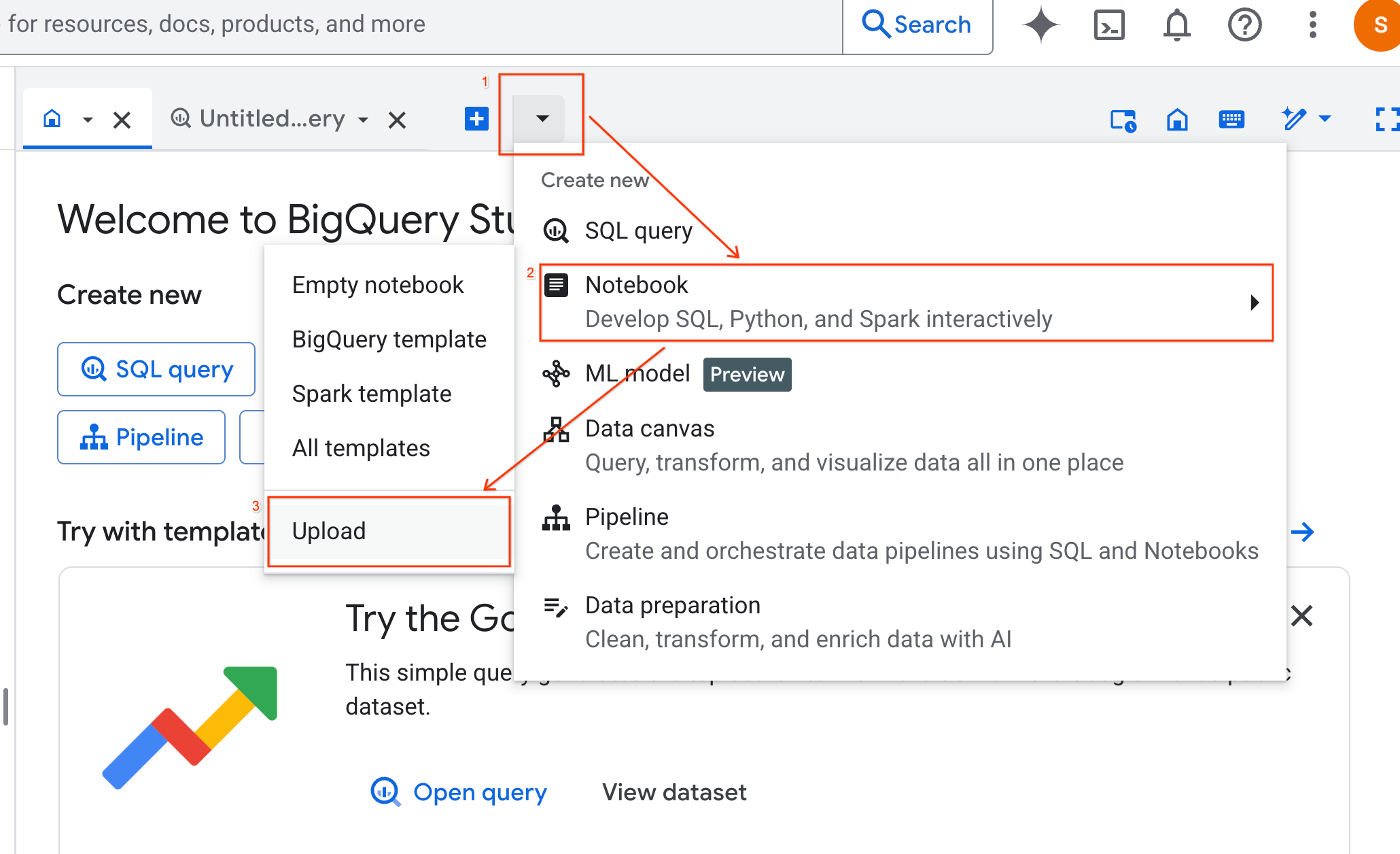
- Seleziona il pulsante di opzione URL e inserisci il seguente URL:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- Imposta la regione su
us-central1e fai clic su Carica.
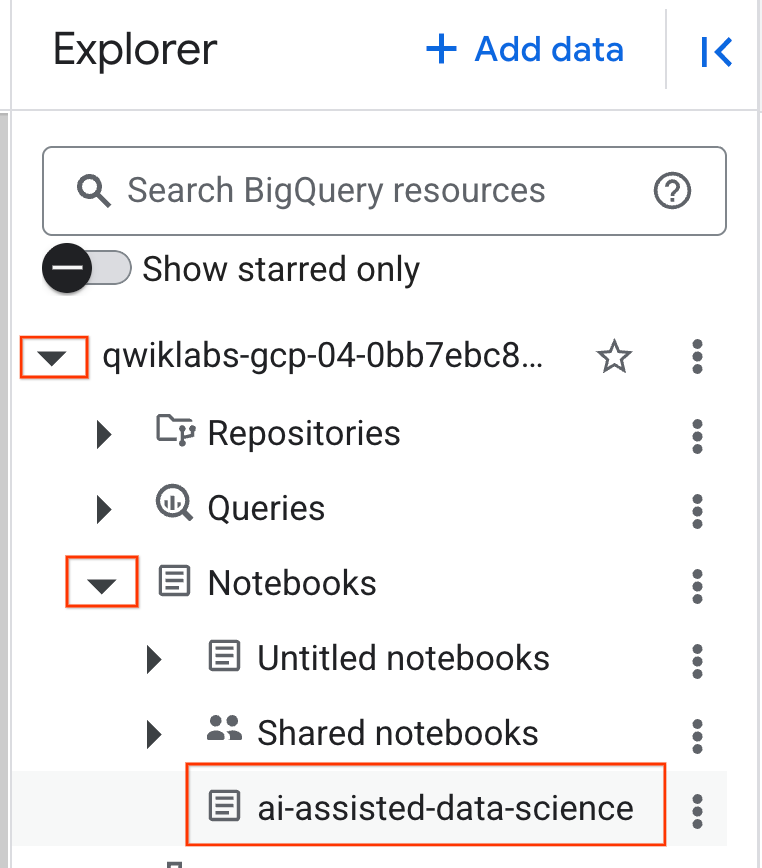
- Per aprire il blocco note, fai clic sulla freccia del menu a discesa nel riquadro Explorer che contiene l'ID progetto. Quindi, fai clic sul menu a discesa Notebook. Fai clic sul notebook
ai-assisted-data-science.
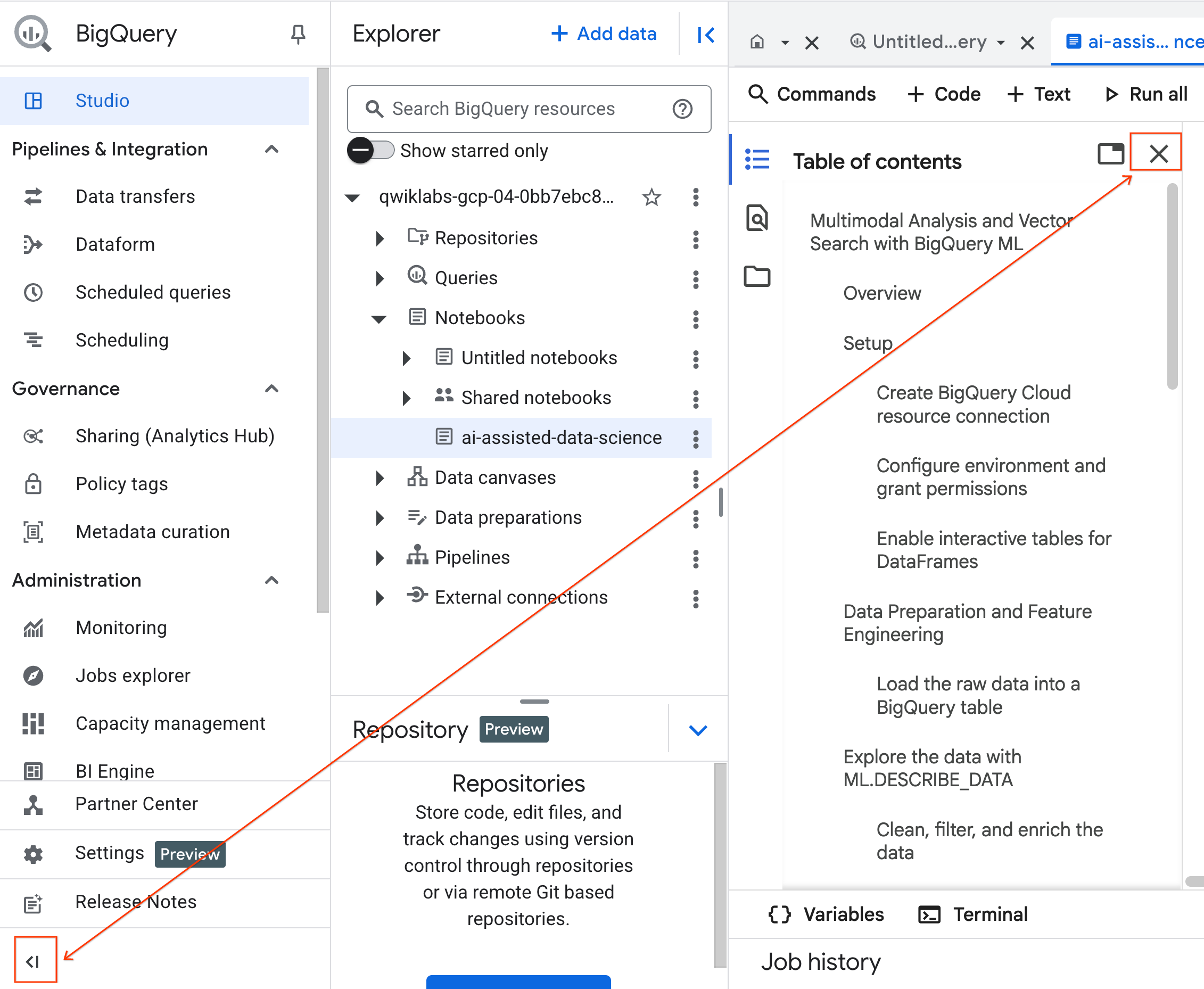
- (Facoltativo) Comprimi il menu di navigazione di BigQuery e il sommario del notebook per avere più spazio.
4. Connettiti a un runtime ed esegui il codice di configurazione
- Fai clic su Connetti. Se viene visualizzato un popup, autorizza Colab Enterprise con il tuo utente. Il notebook si connetterà automaticamente a un runtime. Il completamento dell'operazione potrebbe richiedere alcuni minuti.
- Una volta stabilito il runtime, vedrai quanto segue:
- Nel notebook, scorri fino alla sezione Configurazione. Fai clic sul pulsante "Esegui" accanto alle celle nascoste. In questo modo vengono create alcune risorse necessarie per il lab nel tuo progetto. Il completamento di questo processo potrebbe richiedere un minuto. Nel frattempo, puoi controllare le celle nella sezione Configurazione.
5. Preparazione dei dati e feature engineering
In questa sezione, esamineremo il primo passaggio importante di qualsiasi progetto di data science: la preparazione dei dati. Inizia creando un set di dati BigQuery per organizzare il lavoro, quindi carica i dati grezzi immobiliari / abitativi da un file CSV in Cloud Storage in una nuova tabella.
Poi, trasformerai questi dati non elaborati in una tabella pulita con nuove funzionalità. Ciò comporta il filtraggio delle schede, la creazione di una nuova funzionalità property_age e la preparazione dei dati delle immagini per l'analisi multimodale.
6. Arricchimento multimodale con le funzioni AI
Ora arricchirai i tuoi dati utilizzando la potenza dell'AI generativa. In questa sezione, utilizzerai le funzioni AI integrate di BigQuery per analizzare le immagini di ogni annuncio di casa.
Se colleghi BigQuery a un modello Gemini, estrai nuove funzionalità preziose dalle immagini (ad esempio se una proprietà si trova vicino all'acqua e una breve descrizione della casa) direttamente con SQL.
7. Addestramento del modello con il clustering K-means
Con il set di dati appena arricchito, puoi creare un modello di machine learning. Il tuo obiettivo è segmentare gli annunci di case in gruppi distinti e lo fai addestrando un modello di clustering K-means direttamente in BigQuery utilizzando BigQuery Machine Learning (BQML). Nell'ambito di questo singolo passaggio, registri anche il modello in Agent Platform AI Model Registry, rendendolo immediatamente disponibile nell'ecosistema MLOps più ampio su Google Cloud.
Per verificare che il modello sia stato registrato correttamente, puoi trovarlo nel registro dei modelli di Agent Platform seguendo questi passaggi:
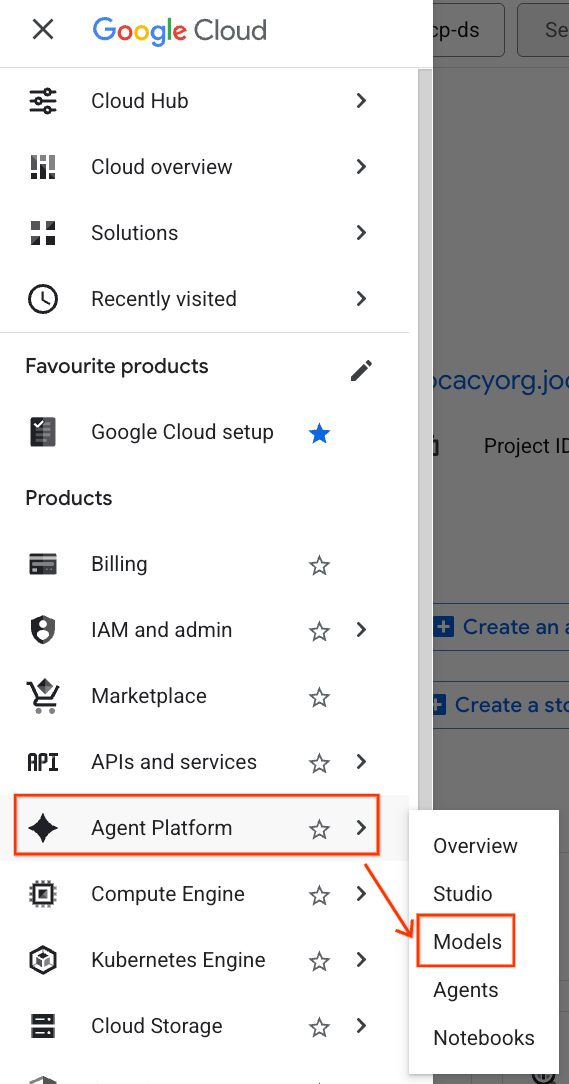
- Nella console Google Cloud, fai clic sul menu di navigazione (☰) nell'angolo in alto a sinistra.
- Scorri fino alla sezione Agent Platform e fai clic su Modelli.
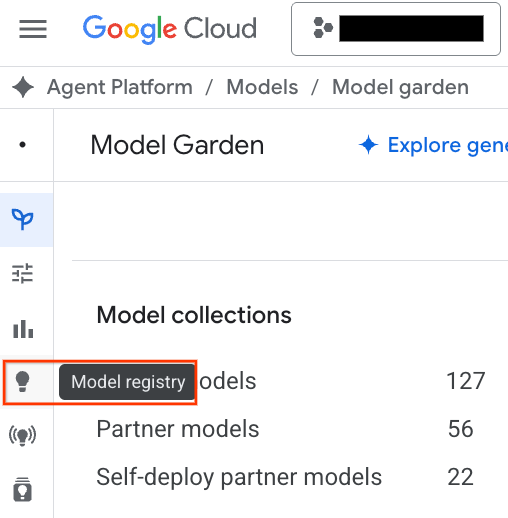
- Fai clic sul pulsante Model Registry evidenziato nello screenshot.
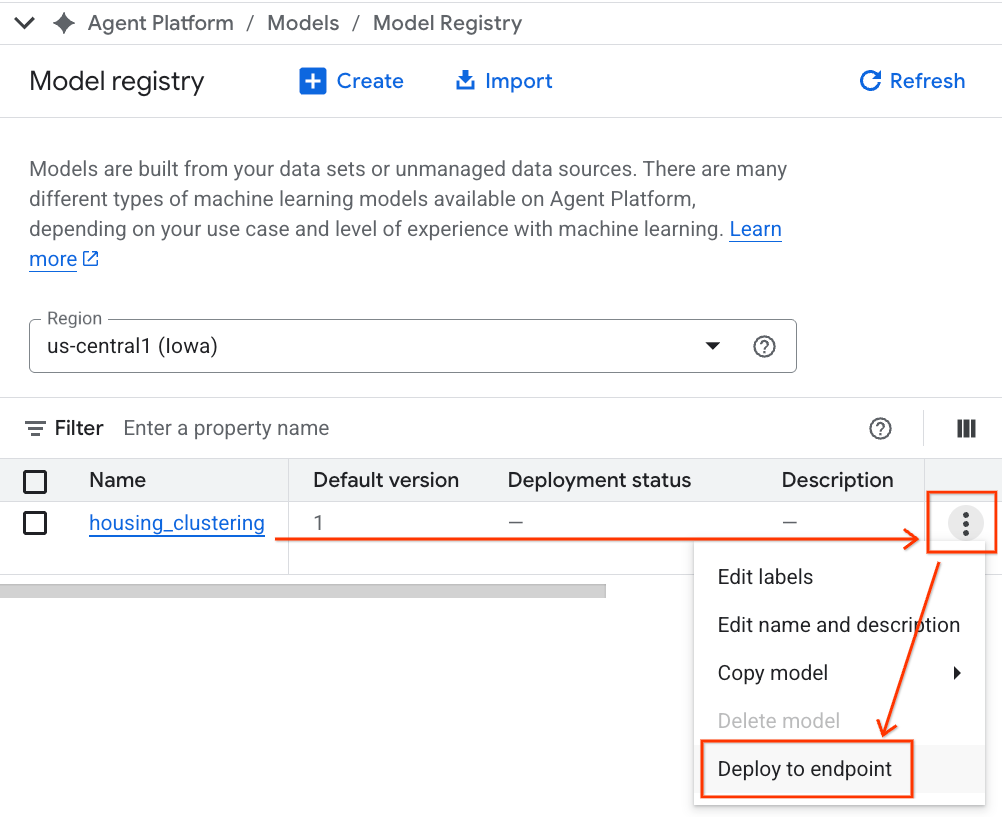
- Il modello BQML verrà visualizzato insieme a tutti gli altri modelli personalizzati. Nell'elenco dei modelli, trova il modello denominato housing_clustering. Puoi passare al passaggio successivo per eseguire il deployment su un endpoint, in modo che il modello sia disponibile per le previsioni online in tempo reale al di fuori dell'ambiente BigQuery.
Dopo aver esplorato il Model Registry, puoi tornare al tuo notebook di Colab in BigQuery seguendo questi passaggi:
- Nel menu di navigazione (☰), vai a BigQuery > Studio.
- Espandi i menu nel riquadro Esplora per trovare il notebook e aprirlo.
8. Valutazione e previsione del modello
Dopo aver addestrato il modello, il passaggio successivo consiste nel comprendere i cluster che ha creato. Qui utilizzi le funzioni di BigQuery Machine Learning come ML.EVALUATE e ML.CENTROIDS per analizzare la qualità del modello e le caratteristiche distintive di ogni segmento.
Poi utilizzi ML.PREDICT per assegnare ogni casa a un cluster. Se esegui questa query con il comando magico %%bigquery df, i risultati vengono archiviati in un DataFrame Pandas denominato df. In questo modo, i dati sono immediatamente disponibili per i passaggi Python successivi. Ciò evidenzia l'interoperabilità tra SQL e Python in Colab Enterprise.
9. Visualizzare e interpretare i cluster
Ora che le previsioni sono caricate in un DataFrame, puoi creare visualizzazioni per dare vita ai dati. In questa sezione, utilizzerai librerie Python popolari come Matplotlib per esplorare le differenze tra i segmenti di alloggi.
Creerai box plot e grafici a barre per confrontare visivamente le caratteristiche chiave come il prezzo e l'età della proprietà, in modo da comprendere facilmente ogni cluster.
10. Generare descrizioni dei cluster con i modelli Gemini
Sebbene i centroidi numerici e i grafici siano potenti, l'AI generativa ti consente di fare un ulteriore passo avanti e creare buyer persona ricche e qualitative per ogni segmento abitativo. In questo modo puoi capire non solo cosa sono i cluster, ma anche chi rappresentano.
In questa sezione, devi prima aggregare le statistiche medie per ogni cluster, come prezzo e metratura. Quindi, passerai questi dati a un prompt per il modello Gemini. A questo punto, chiedi al modello di agire come un professionista del settore immobiliare e di generare un riepilogo dettagliato, incluse le caratteristiche chiave e un acquirente target per ogni segmento. Il risultato è un insieme di descrizioni chiare e leggibili che rendono i cluster immediatamente comprensibili e utilizzabili da un team di marketing.
Modifica pure il prompt come meglio credi e sperimenta con i risultati.
11. Automatizzare la modellazione con Data Science Agent
Ora esplorerai un flusso di lavoro alternativo e potente. Anziché scrivere codice manualmente, utilizzerai l'agente Data Science integrato per generare automaticamente un flusso di lavoro completo del modello di clustering da un singolo prompt in linguaggio naturale.
Per generare ed eseguire il modello utilizzando l'agente:
- Nel riquadro BigQuery Studio, fai clic sul pulsante freccia del menu a discesa, passa il mouse sopra Notebook e poi seleziona Notebook vuoto. In questo modo, il codice dell'agente non interferisce con il tuo notebook di laboratorio originale.
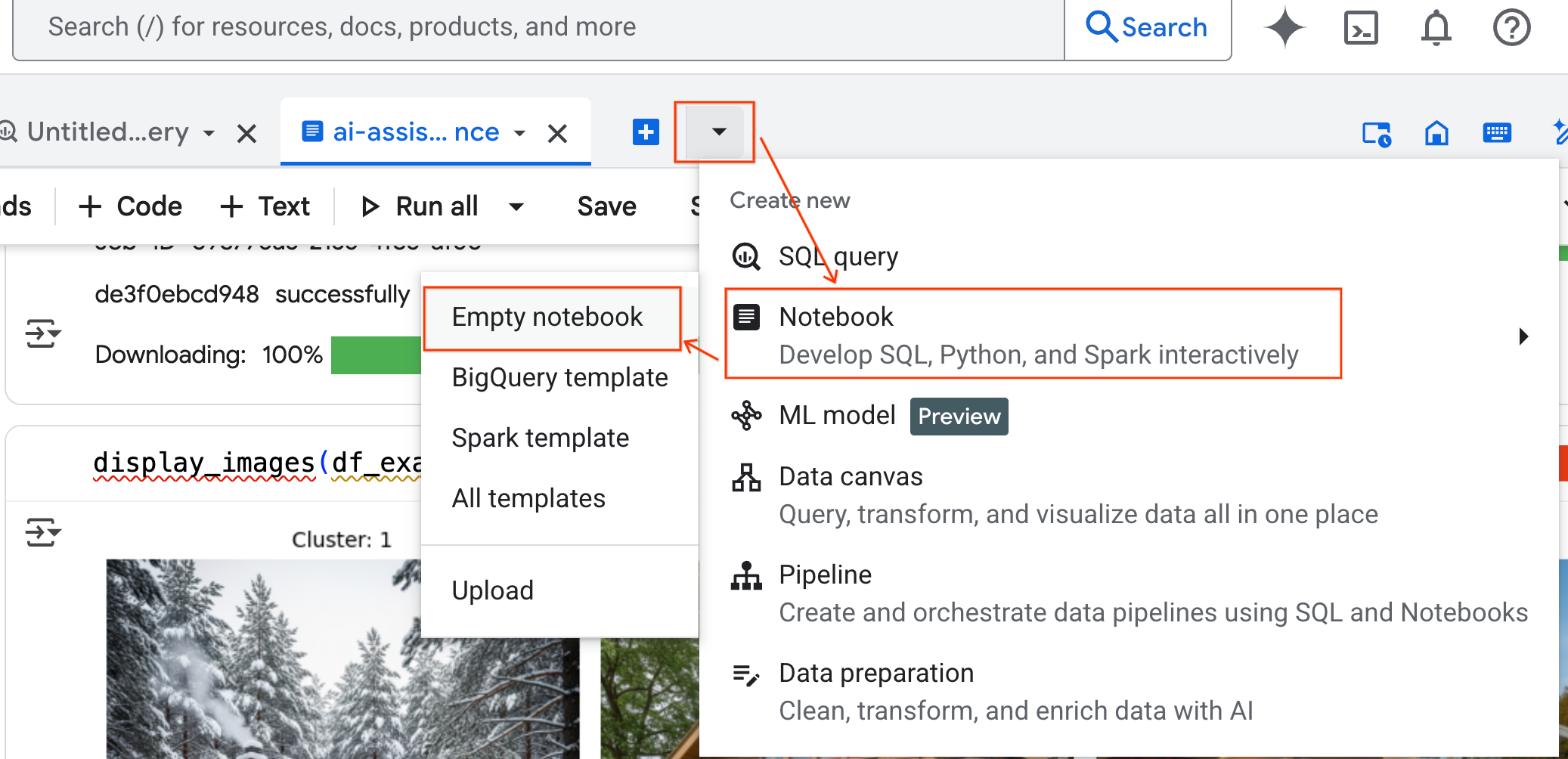
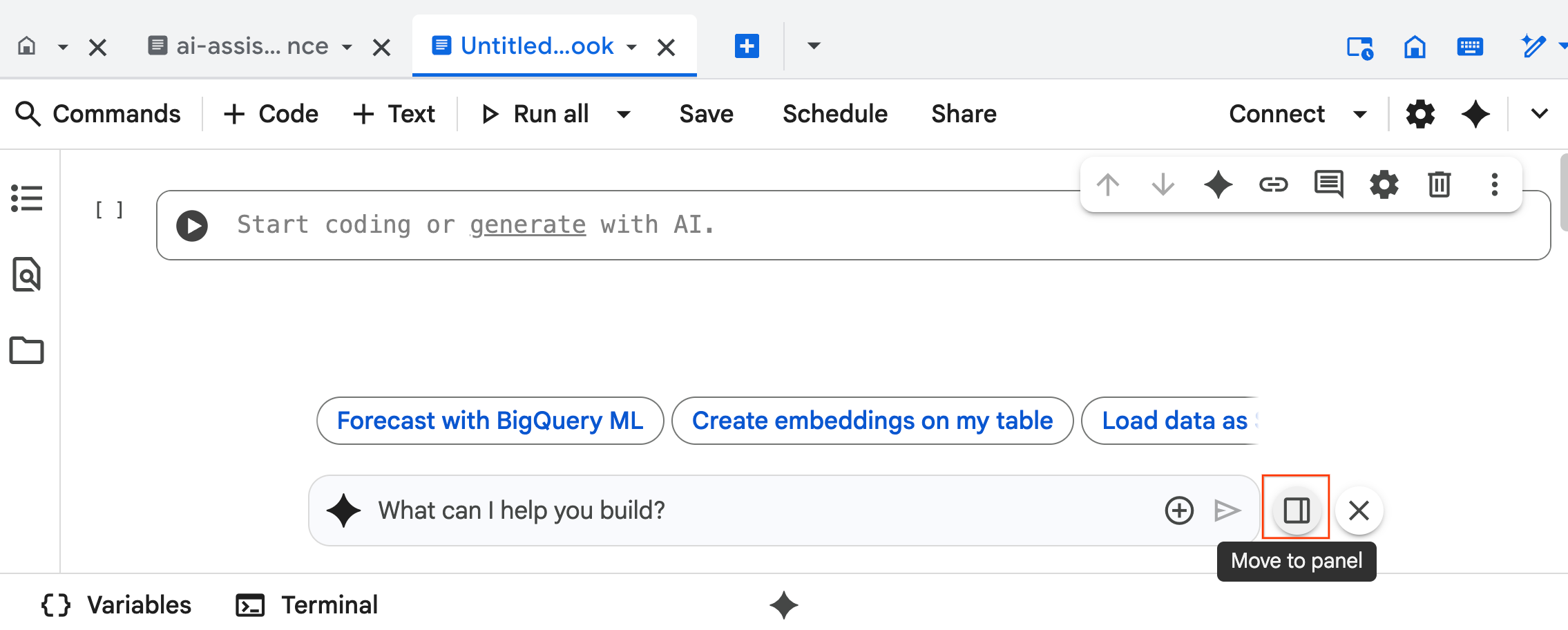
- L'interfaccia di chat di Data Science Agent si apre nella parte inferiore del notebook. Fai clic sul pulsante Sposta nel riquadro per bloccare la chat sul lato destro.
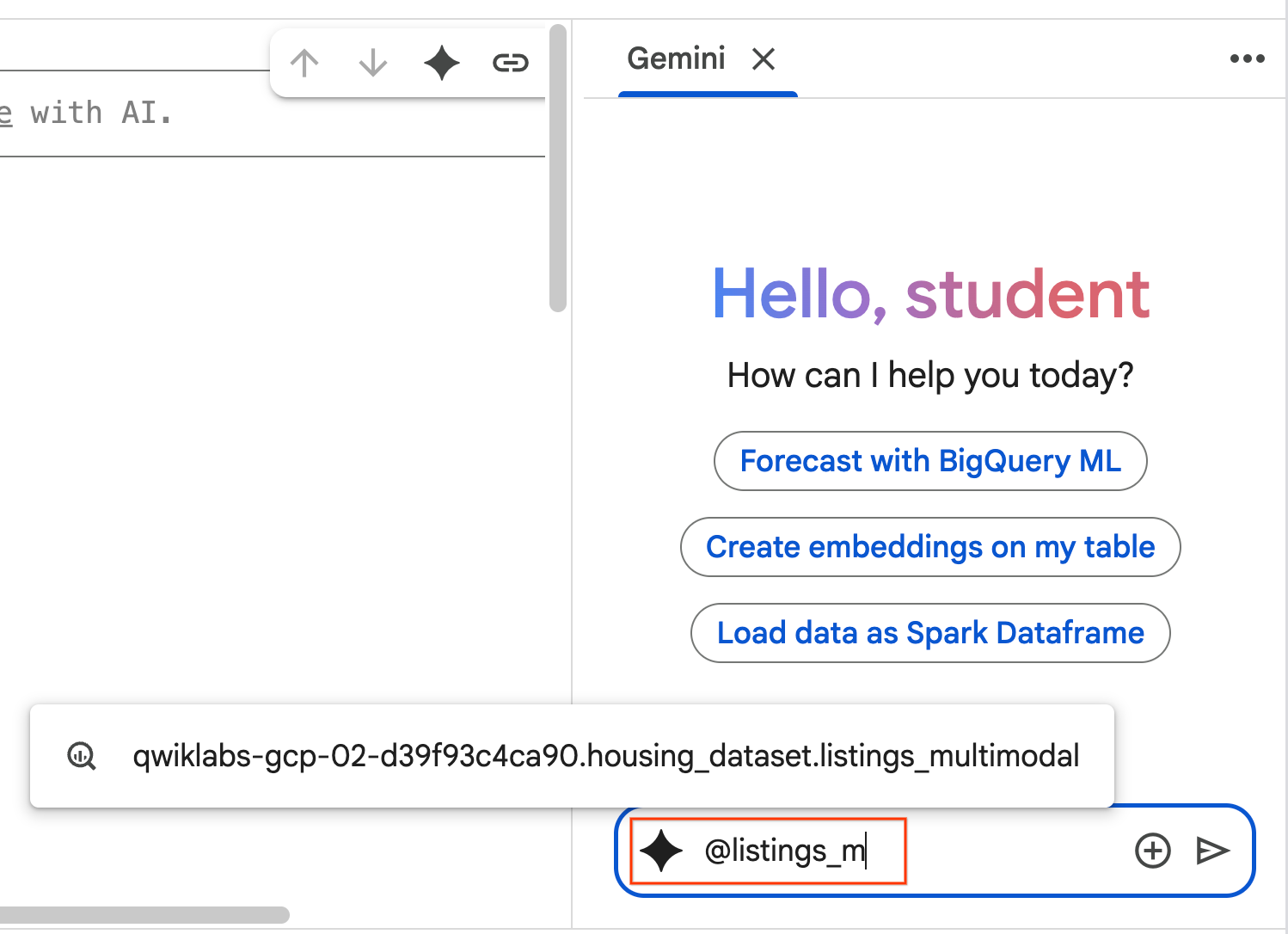
- Inizia a digitare
@listing_multimodalnel riquadro della chat e fai clic sulla tabella. Imposta in modo esplicito la tabellalistings_multimodalcome contesto.
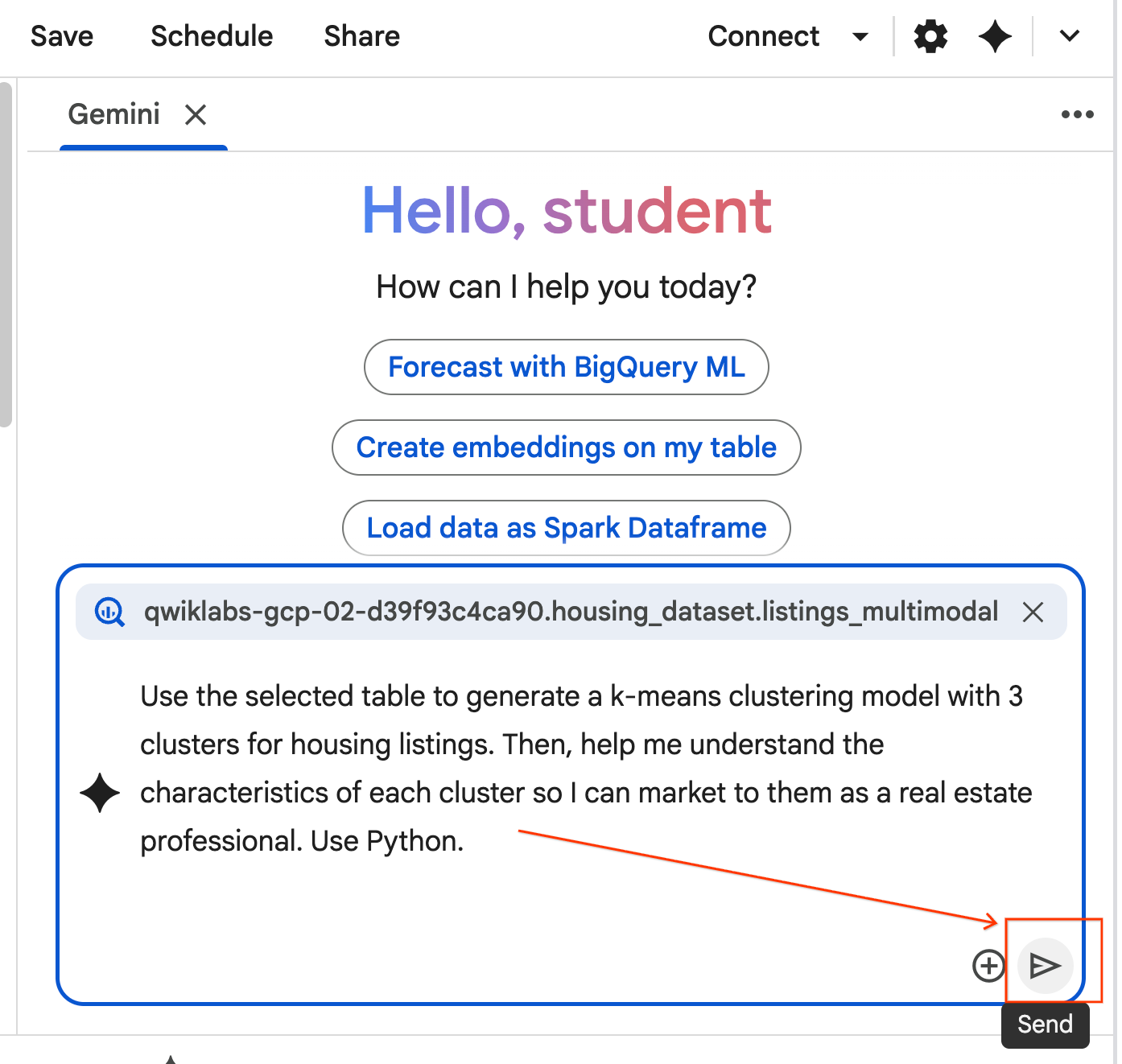
- Copia il prompt riportato di seguito e inseriscilo nella casella della chat con l'agente. Dopodiché, fai clic su Invia per inviare il prompt all'agente.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- L'agente penserà e formulerà un piano. Se questo piano ti soddisfa, fai clic su Accetta ed esegui. L'agente genererà codice Python in una o più nuove celle.
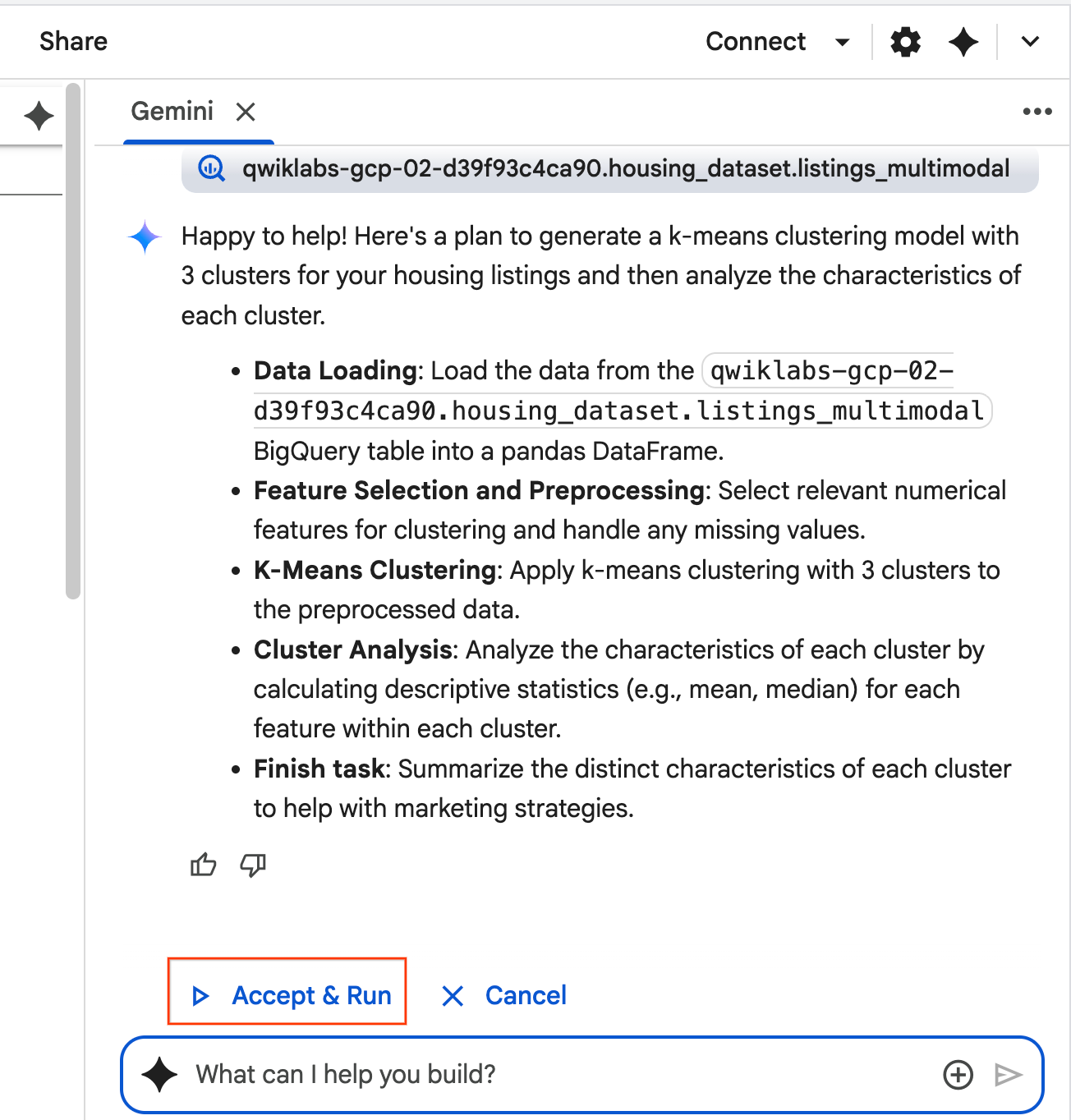
- L'agente ti chiede di Accettare ed eseguire ogni blocco di codice che genera. In questo modo, l'approccio human-in-the-loop viene mantenuto. Puoi rivedere o modificare il codice e continuare a seguire i passaggi fino al termine.
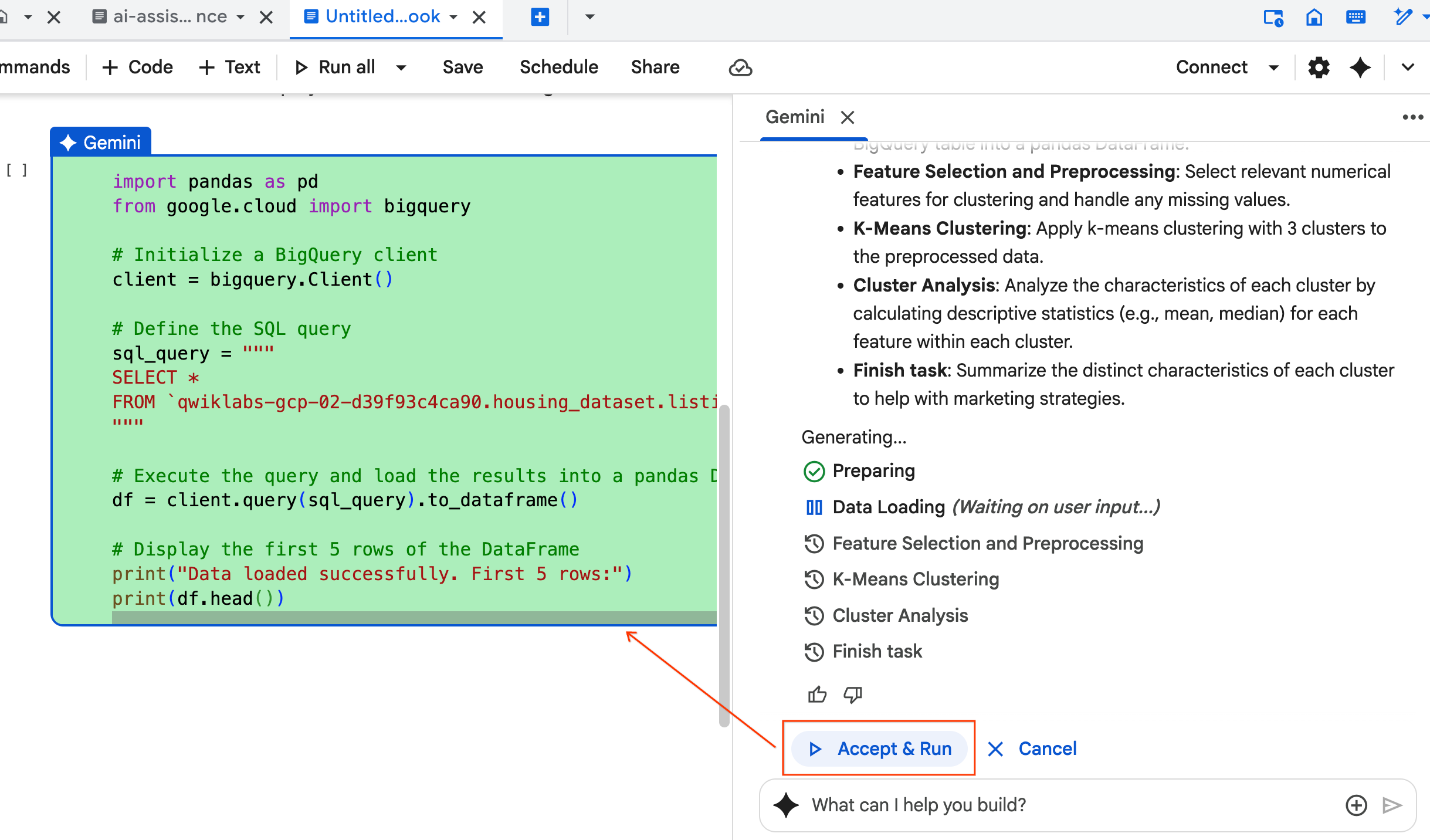
- Al termine, chiudi la nuova scheda del blocco note e torna alla scheda
ai-assisted-data-science.ipynboriginale per continuare con l'ultima sezione del lab.
12. Ricerca multimodale con embedding e ricerca vettoriale
In questa sezione finale, implementi la ricerca multimodale direttamente in BigQuery. Ciò consente ricerche intuitive, ad esempio trovare case in base a una descrizione testuale o trovare case simili a un'immagine di esempio.
La procedura prevede innanzitutto la conversione di ogni immagine della casa in una rappresentazione numerica chiamata incorporamento. Un embedding acquisisce il significato semantico di un'immagine, consentendoti di trovare elementi simili confrontando i loro vettori numerici.
Utilizzerai il modello multimodalembedding per generare questi vettori per tutte le tue schede. Dopo aver creato un indice vettoriale per accelerare le ricerche, esegui due tipi di ricerca per similarità: da testo a immagine (trovare case che corrispondono a una descrizione) e da immagine a immagine (trovare case simili a un'immagine di esempio).
Completerai tutto questo in BigQuery, utilizzando funzioni come ML.GENERATE_EMBEDDING per generare embedding o VECTOR_SEARCH per la ricerca di somiglianze.
13. Pulizia
Per liberare spazio da tutte le risorse Google Cloud utilizzate in questo progetto, puoi eliminare il progetto Google Cloud.
In alternativa, puoi eliminare le singole risorse che hai creato eseguendo questo codice in una nuova cella del notebook:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
Infine, puoi eliminare il notebook stesso:
- Nel riquadro Explorer di BigQuery Studio, espandi il progetto e il nodo Blocchi note.
- Fai clic sui tre puntini verticali accanto al blocco note
ai-assisted-data-science. - Seleziona Elimina.
14. Complimenti!
Congratulazioni per aver completato il codelab.
Argomenti trattati
- Prepara un set di dati non elaborati di schede immobiliari per l'analisi tramite il feature engineering.
- Arricchisci le schede utilizzando le funzioni AI di BigQuery per analizzare le foto della casa e identificare le caratteristiche visive chiave.
- Crea e valuta un modello K-means con BigQuery Machine Learning (BQML) per segmentare le proprietà in cluster distinti.
- Automatizza la creazione di modelli utilizzando il Data Science Agent per generare un modello di clustering con Python.
- Genera embedding per le immagini delle case per potenziare uno strumento di ricerca visiva, trovando case simili con query di testo o immagini.