
1. はじめに
概要
このラボでは、不動産のシナリオを想定して、BigQuery でマルチモーダル データ サイエンス ワークフローを探索します。まず、住宅物件とその画像の未加工データセットから始め、AI でこのデータを拡充して視覚的特徴を抽出し、クラスタリング モデルを構築して個別の市場セグメントを見つけます。最後に、ベクトル エンベディングを使用して強力な画像検索ツールを作成します。
この SQL ネイティブ ワークフローと、最新の生成 AI アプローチを比較します。データ サイエンス エージェントを使用して、簡単なテキスト プロンプトから Python ベースのクラスタリング モデルを自動的に生成します。
学習内容
- 特徴量エンジニアリングを通じて分析用の不動産物件の未加工データセットを準備 する。
- BigQuery の AI 関数を使用して住宅の写真を分析し、主要な視覚的特徴を抽出して物件情報を拡充 する。
- BigQuery Machine Learning(BQML)を使用して K 平均法モデルを構築して評価 し、物件を個別のクラスタに分割する。
- データ サイエンス エージェントを使用して Python でクラスタリング モデルを生成し、モデルの作成を自動化 する。
- 住宅画像のエンベディングを生成 して画像検索ツールを強化し、テキストまたは画像クエリで類似の住宅を見つける。
前提条件
このラボを開始する前に、以下について理解しておく必要があります。
- 基本的な SQL と Python のプログラミング。
- Jupyter ノートブックでの Python コードの実行。
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell で API を有効にする
**Cloud Shell** は Google Cloud 上で動作するコマンドライン環境で、必要なツールがプリロードされています。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする 」アイコンをクリックします。

- Cloud Shell に接続したら、次のコマンドを実行して Cloud Shell で認証を確認します。
gcloud auth list
- 次のコマンドを実行して、プロジェクトが gcloud で使用するように構成されていることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API を有効にする
- 次のコマンドを実行して、必要なすべての API とサービスを有効にします。
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- コマンドが正常に実行されると、次のようなメッセージが表示されます。
Operation "operations/..." finished successfully.
- Cloud Shell を終了します。
3. BigQuery Studio でラボのノートブックを開く
UI の操作:
- Google Cloud コンソールで、ナビゲーション メニュー > [BigQuery] に移動します。
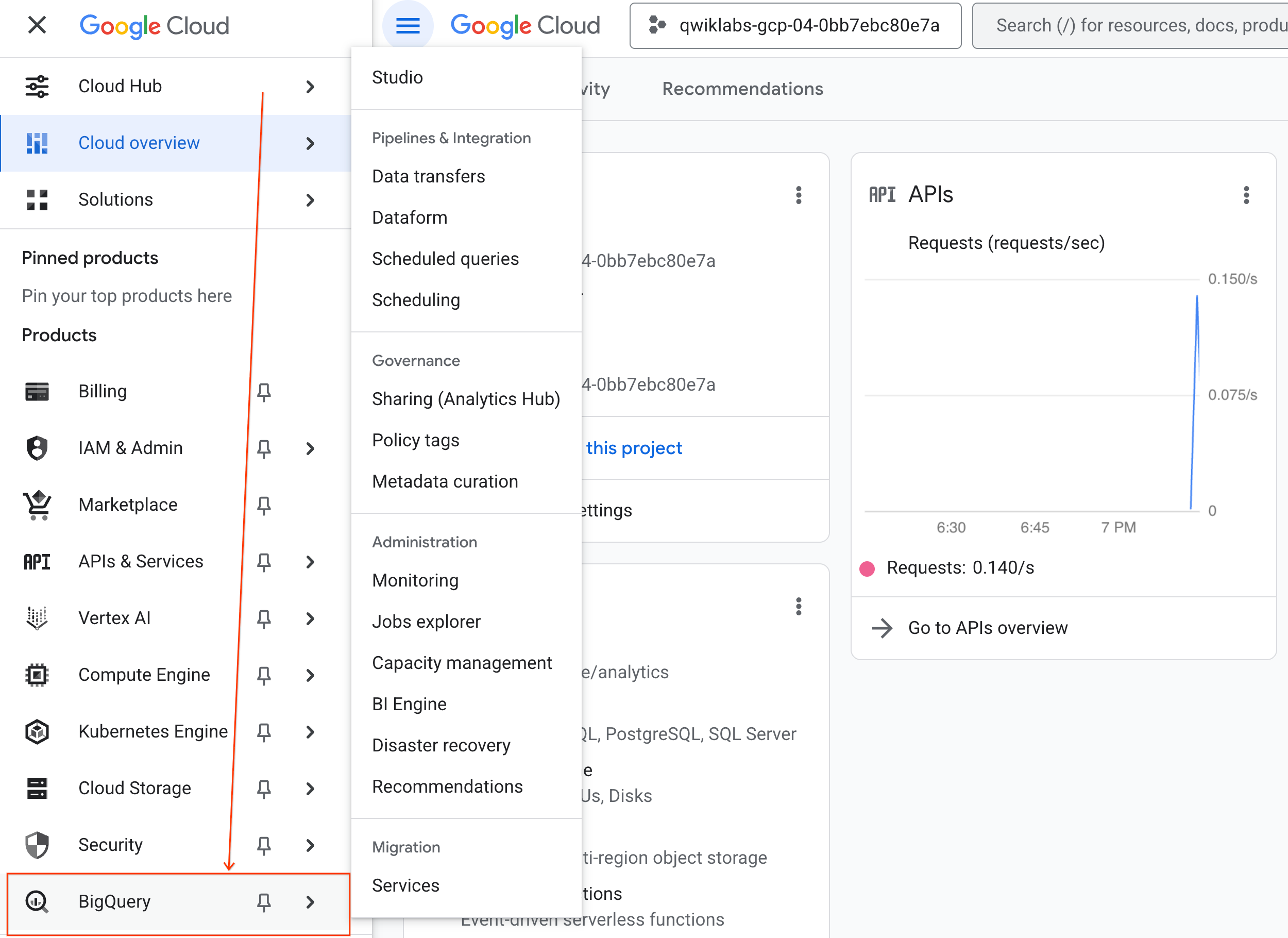
- [BigQuery Studio] ペインで、プルダウン矢印ボタンをクリックし、[ノートブック] にカーソルを合わせて、[アップロード] を選択します。
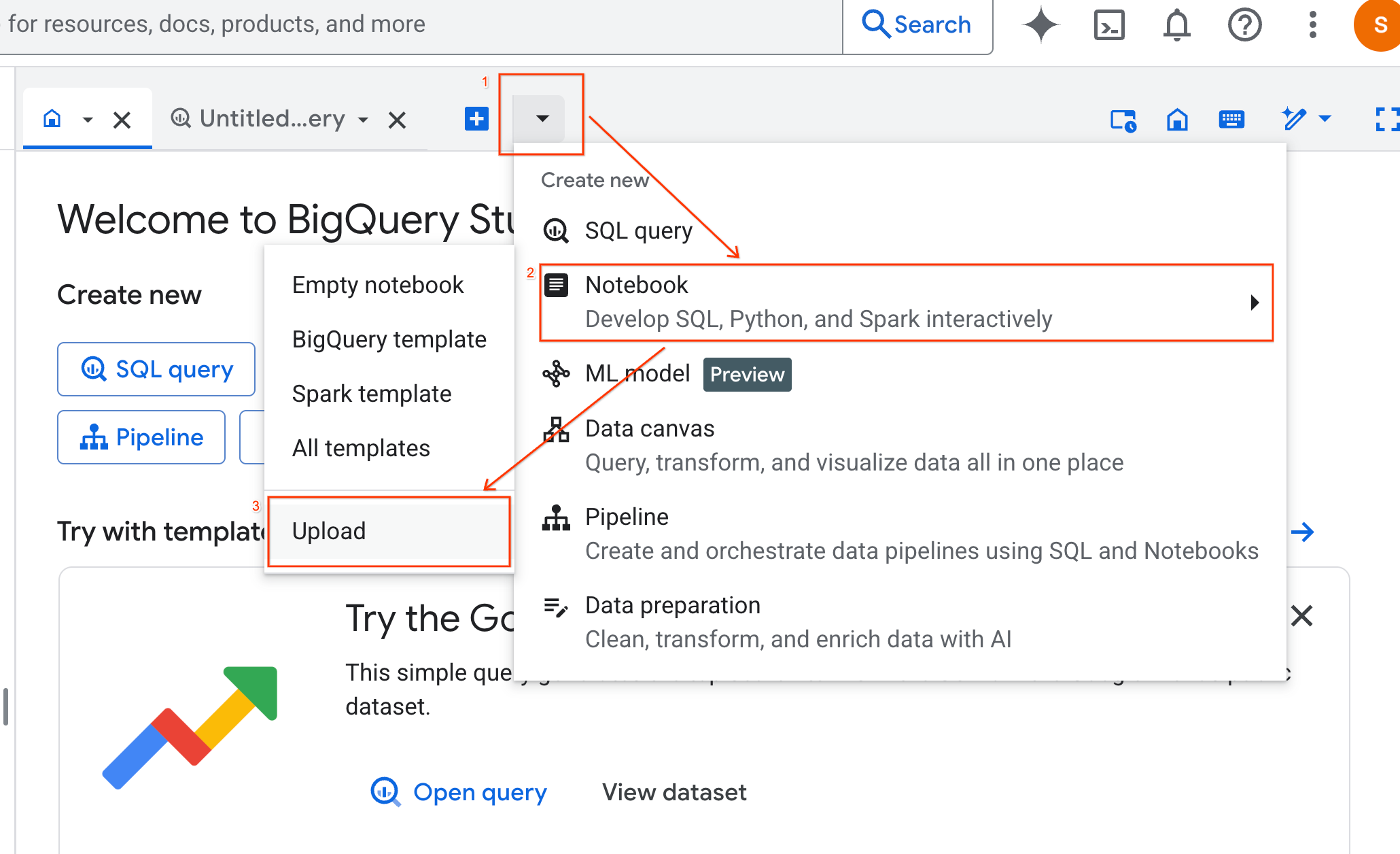
- [URL] ラジオボタンを選択し、次の URL を入力します。
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- リージョンを
us-central1に設定して、[アップロード] をクリックします。
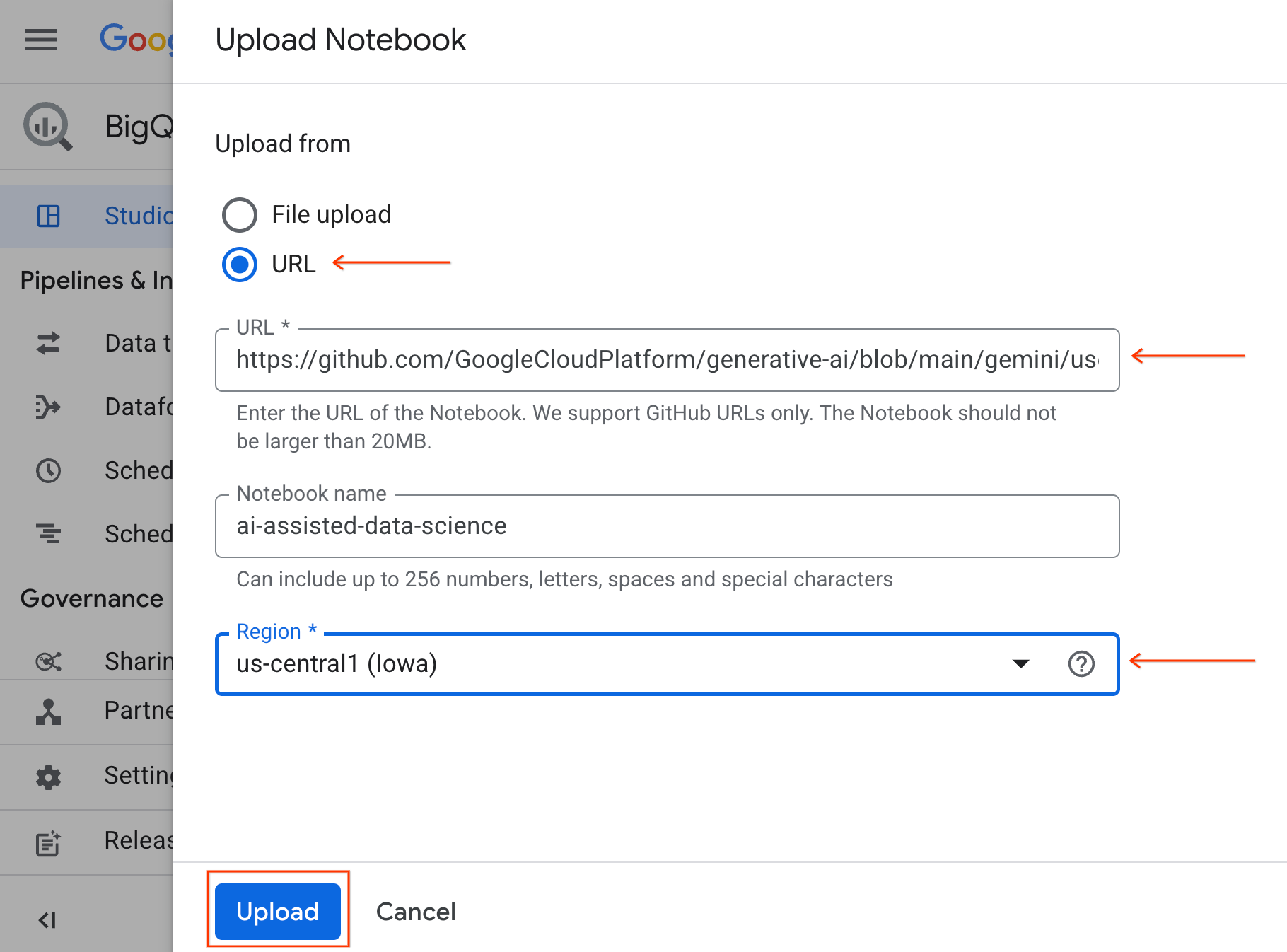
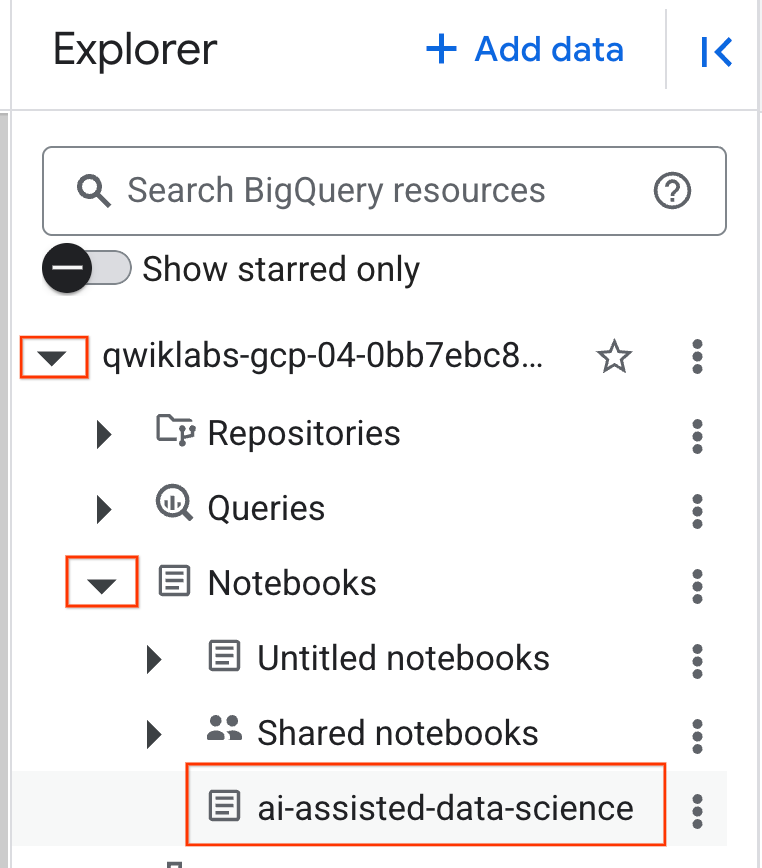
- ノートブックを開くには、プロジェクト ID を含む [エクスプローラ] ペインでプルダウン矢印をクリックします。次に、[ノートブック] のプルダウンをクリックします。ノートブック
ai-assisted-data-scienceをクリックします。
- (省略可)スペースを増やすため、BigQuery ナビゲーション メニュー とノートブックの目次 を折りたたみます。
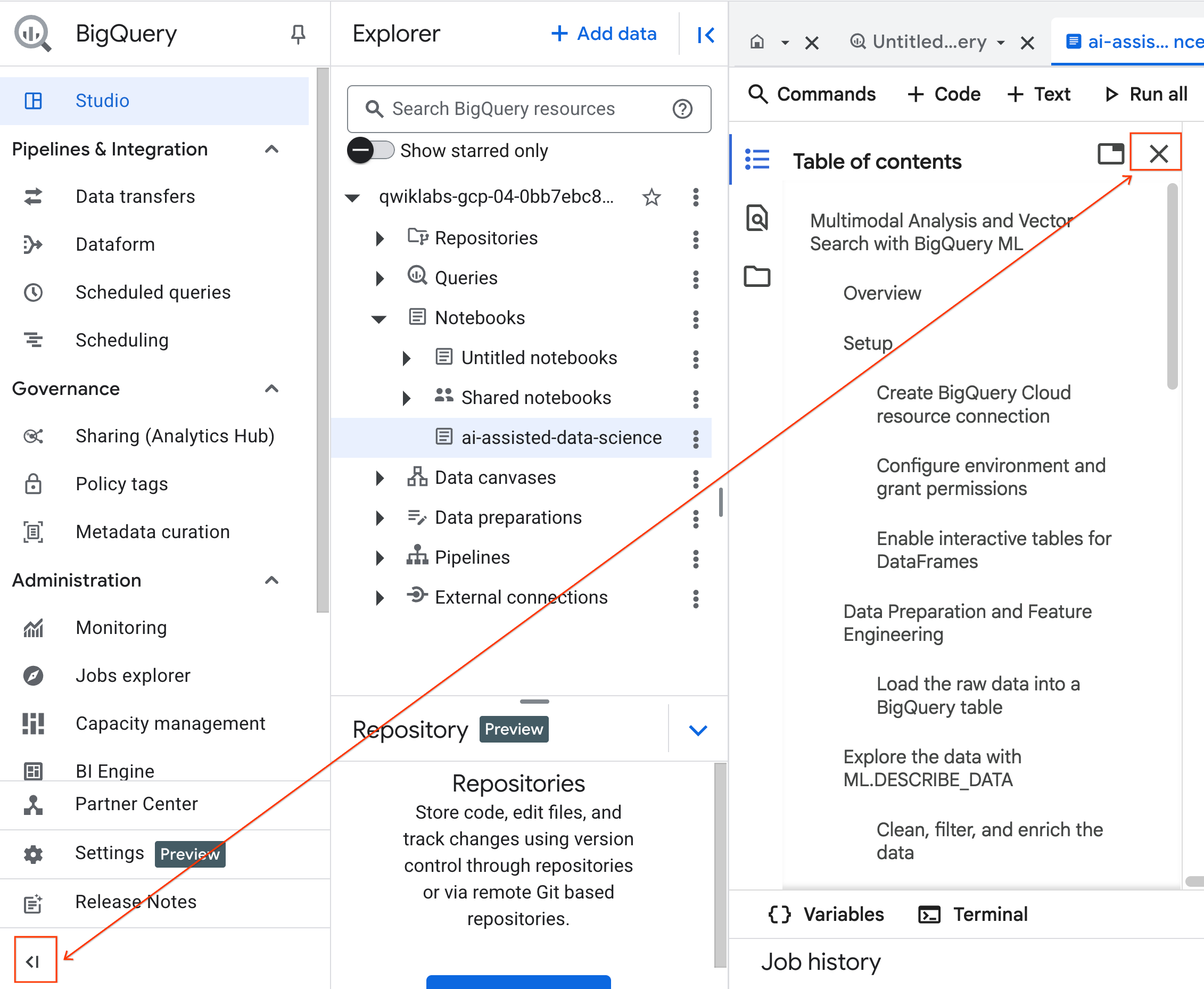
4. ランタイムに接続して設定コードを実行する
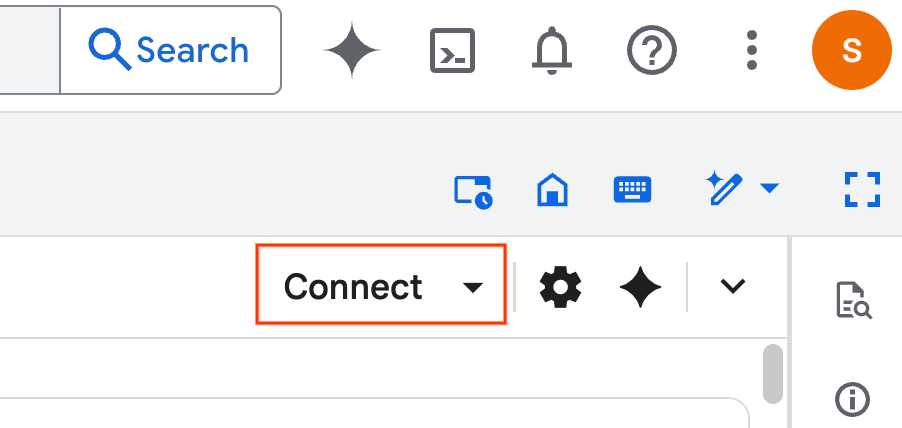
- [接続] をクリックします。ポップアップが表示されたら、ユーザーで Colab Enterprise を承認します。ノートブックがランタイムに自動的に接続されます。完了するまでに数分かかることがあります。
- ランタイムが確立されると、次のようになります。
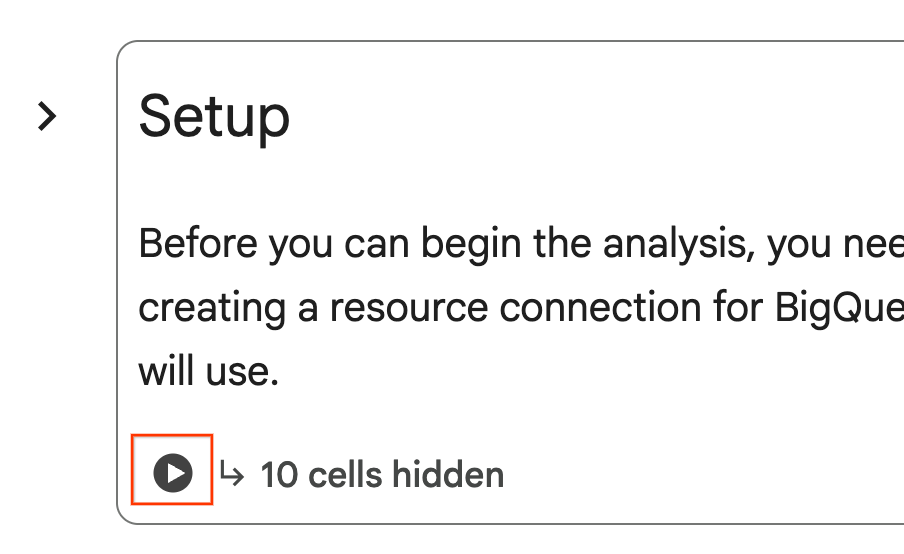
- ノートブック内で、[設定] セクションまでスクロールします。非表示のセルの横にある [実行] ボタンをクリックします。これにより、ラボに必要なリソースがプロジェクトに作成されます。このプロセスが完了するまでに 1 分ほどかかることがあります。それまでの間、[設定] の下のセルを確認してください。
5. データの準備と特徴量エンジニアリング
このセクションでは、データ サイエンス プロジェクトの最初の重要なステップであるデータの準備を行います。まず、BigQuery データセットを作成して作業を整理し、Cloud Storage の CSV ファイルから未加工の不動産 / 住宅データを新しいテーブルに読み込みます。
次に、この未加工データを新しい特徴を持つクリーンなテーブルに変換します。これには、物件情報のフィルタリング、新しい property_age 特徴の作成、マルチモーダル分析用の画像データの準備が含まれます。
6. AI 関数を使用したマルチモーダル エンリッチメント
ここでは、生成 AI の力を使用してデータを拡充します。このセクションでは、BigQuery の組み込み AI 関数を使用して、各住宅物件の画像を分析します。
BigQuery を Gemini モデルに接続することで、画像から新しい価値のある特徴(物件が水辺に近いかどうか、住宅の簡単な説明など)を SQL で直接抽出できます。
7. K 平均法クラスタリングを使用したモデルのトレーニング
新しく拡充されたデータセットを使用して、ML モデルを構築する準備ができました。目標は、住宅物件を個別のセグメントに分割することです。これを行うには、BigQuery Machine Learning(BQML)を使用して、BigQuery で K 平均法クラスタリング モデルを直接トレーニングします。この 1 つのステップで、Agent Platform AI Model Registry にモデルを登録し、Google Cloud の広範な MLOps エコシステム内で即座に利用できるようにします。
モデルが正常に登録されたことを確認するには、次の手順で Agent Platform Model Registry で確認します。
- Google Cloud コンソールで、左上にあるナビゲーション メニュー (☰)をクリックします。
- [Agent Platform] セクションまでスクロールして、[モデル] をクリックします。
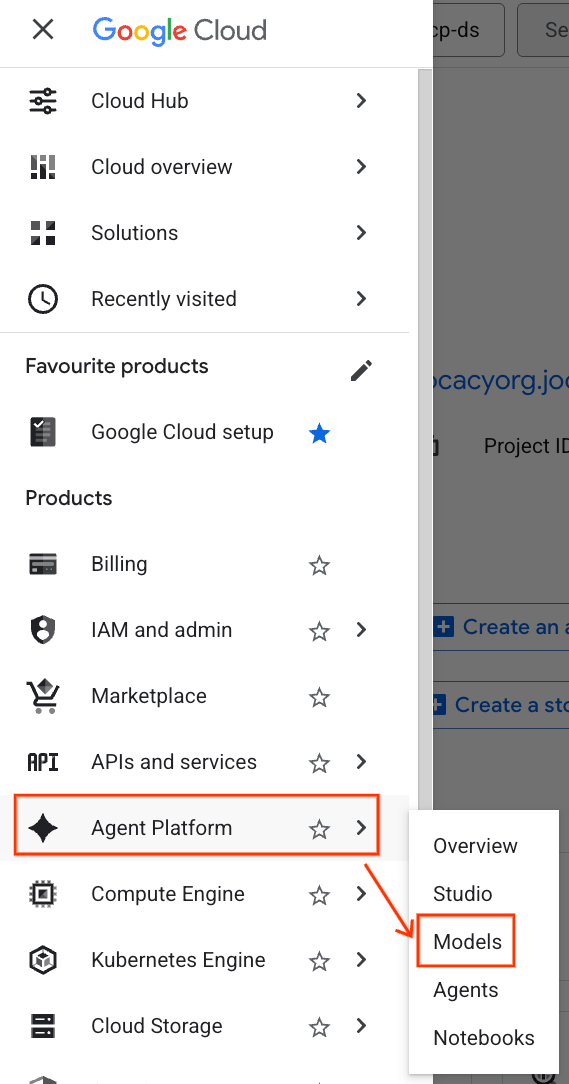
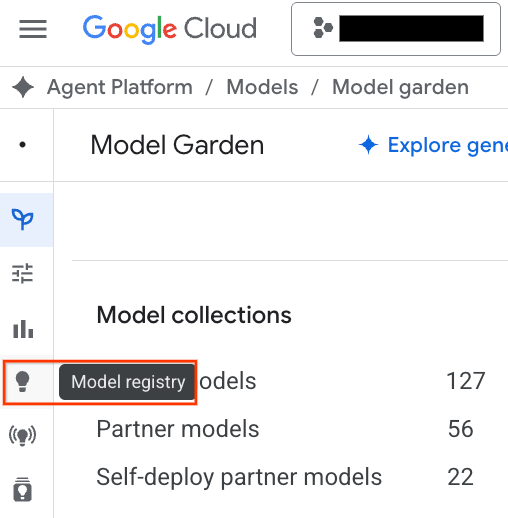
- スクリーンショットでハイライト表示されている [Model Registry] ボタンをクリックします。
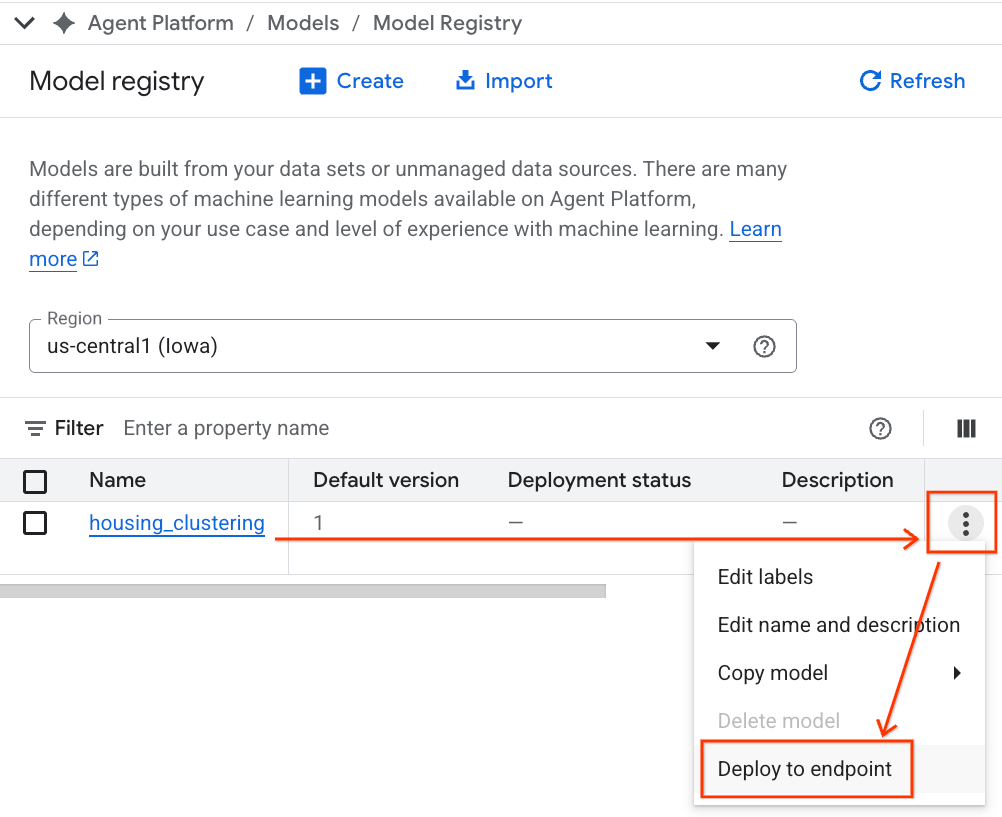
- BQML モデルが、他のすべてのカスタムモデルとともに一覧表示されます。モデルのリストで、housing_clustering という名前のモデルを見つけます。次のステップとして、[**エンドポイントにデプロイ**] を選択できます。これにより、BigQuery 環境外でリアルタイムのオンライン予測にモデルを使用できるようになります。
Model Registry を確認したら、次の手順で BigQuery の Colab ノートブックに戻ります。
- [ナビゲーション メニュー](☰)で、[BigQuery] > [Studio] に移動します。
- [エクスプローラ] ペインでメニューを開き、ノートブックを見つけて開きます。
8. モデルの評価と予測
モデルのトレーニングが完了したら、次のステップは作成されたクラスタを理解することです。ここでは、ML.EVALUATE や ML.CENTROIDS などの BigQuery Machine Learning 関数を使用して、モデルの品質と各セグメントの定義特性を分析します。
次に、ML.PREDICT を使用して、各住宅をクラスタに割り当てます。%%bigquery df マジック コマンドを使用してこのクエリを実行すると、結果が df という名前の pandas DataFrame に保存されます。これにより、後続の Python ステップでデータをすぐに使用できるようになります。これは、Colab Enterprise での SQL と Python の相互運用性を強調しています。
9. クラスタの可視化と解釈
予測が DataFrame に読み込まれたので、ビジュアリゼーションを作成してデータを活用できます。このセクションでは、Matplotlib などの一般的な Python ライブラリを使用して、住宅セグメント間の違いを調べます。
箱ひげ図と棒グラフを作成して、価格や物件の築年数などの主要な特徴を視覚的に比較し、各クラスタを直感的に理解できるようにします。
10. Gemini モデルでクラスタの説明を生成する
数値の重心とグラフは強力ですが、生成 AI を使用すると、さらに一歩進んで、住宅セグメントごとにリッチで定性的なペルソナを作成できます。これにより、クラスタがどのようなものかだけでなく、クラスタが誰を表しているのかを理解できます。
このセクションでは、まず価格や延べ床面積など、各クラスタの平均統計を集計します。次に、このデータを Gemini モデルのプロンプトに渡します。次に、不動産の専門家として行動し、主要な特徴や各セグメントのターゲット バイヤーなど、詳細な概要を生成するようにモデルに指示します。その結果、マーケティング チームがクラスタをすぐに理解して対応できるように、明確で人間が読める説明のセットが生成されます。
必要に応じてプロンプトを変更し、結果を試してください。
11. データ サイエンス エージェントを使用したモデリングの自動化
次に、強力な代替ワークフローについて説明します。コードを手動で作成する代わりに、統合されたデータ サイエンス エージェントを使用して、単一の自然言語プロンプトから完全なクラスタリング モデル ワークフローを自動的に生成します。
エージェントを使用してモデルを生成して実行する手順は次のとおりです。
- [BigQuery Studio] ペインで、プルダウン矢印ボタンをクリックし、[ノートブック] にカーソルを合わせて、[空のノートブック] を選択します。これにより、エージェントのコードが元のラボのノートブックに干渉しないようにします。
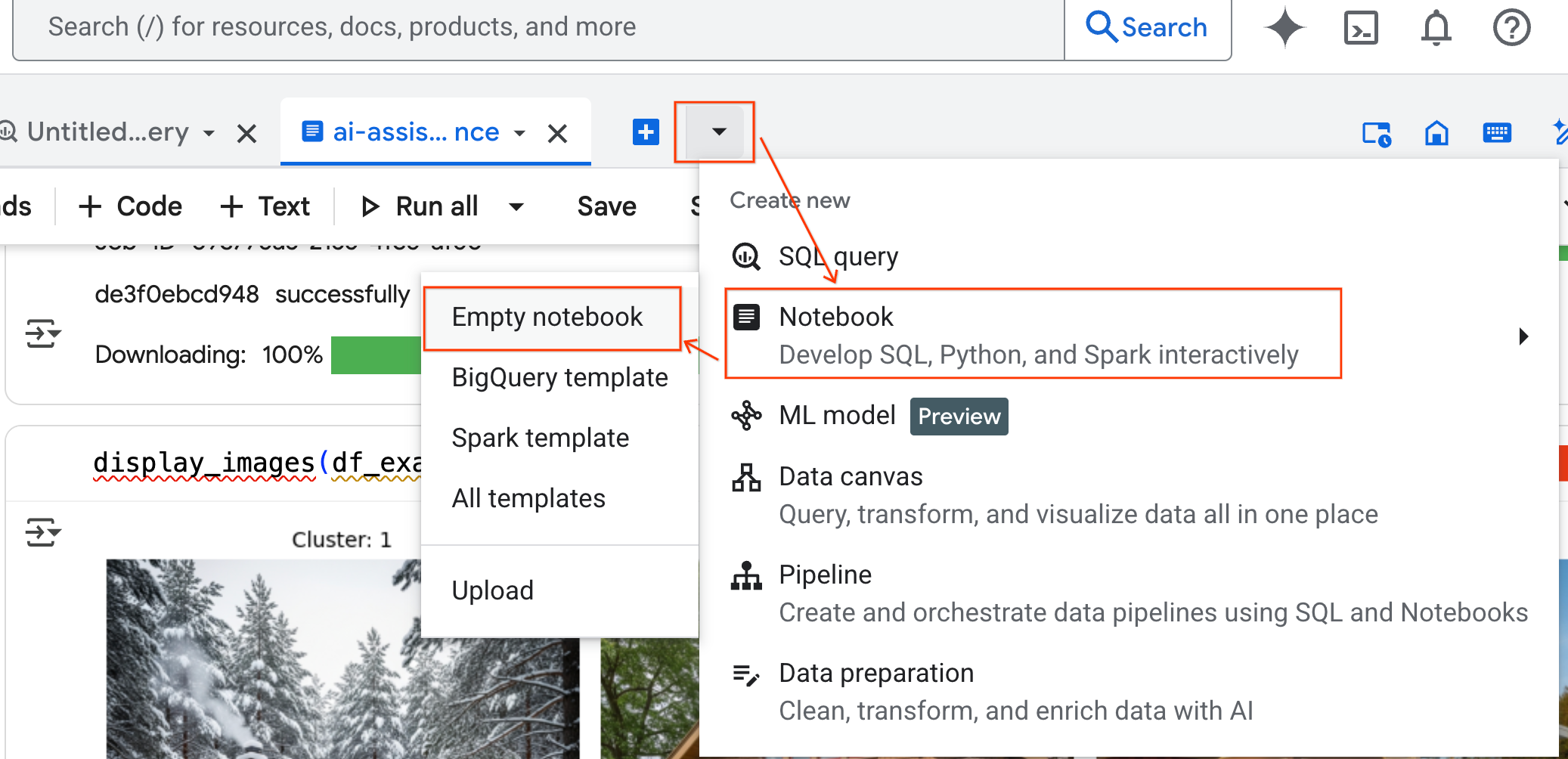
- ノートブックの下部にデータ サイエンス エージェントのチャット インターフェースが開きます。[パネルに移動] ボタンをクリックして、チャットを右側に固定します。
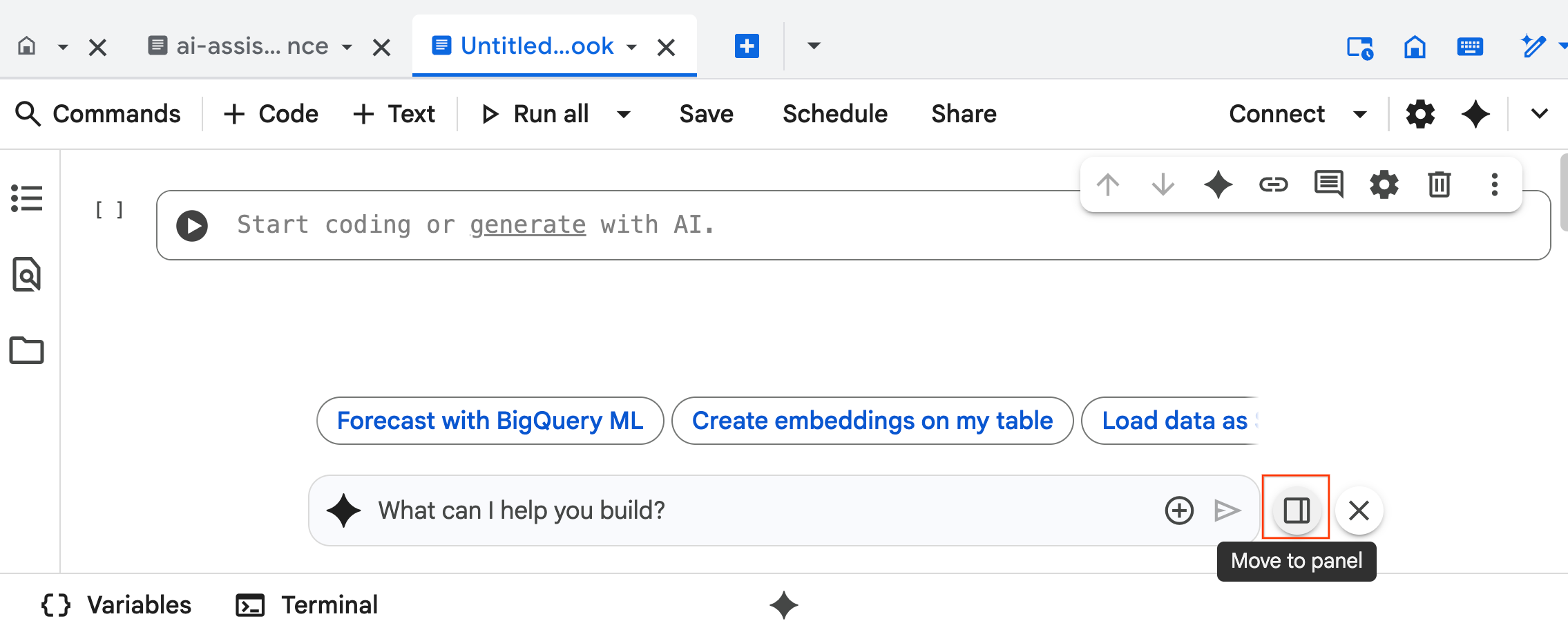
- チャット ペインに「
@listing_multimodal」と入力し、テーブルをクリック します。これにより、listings_multimodalテーブルがコンテキストとして明示的に設定されます。
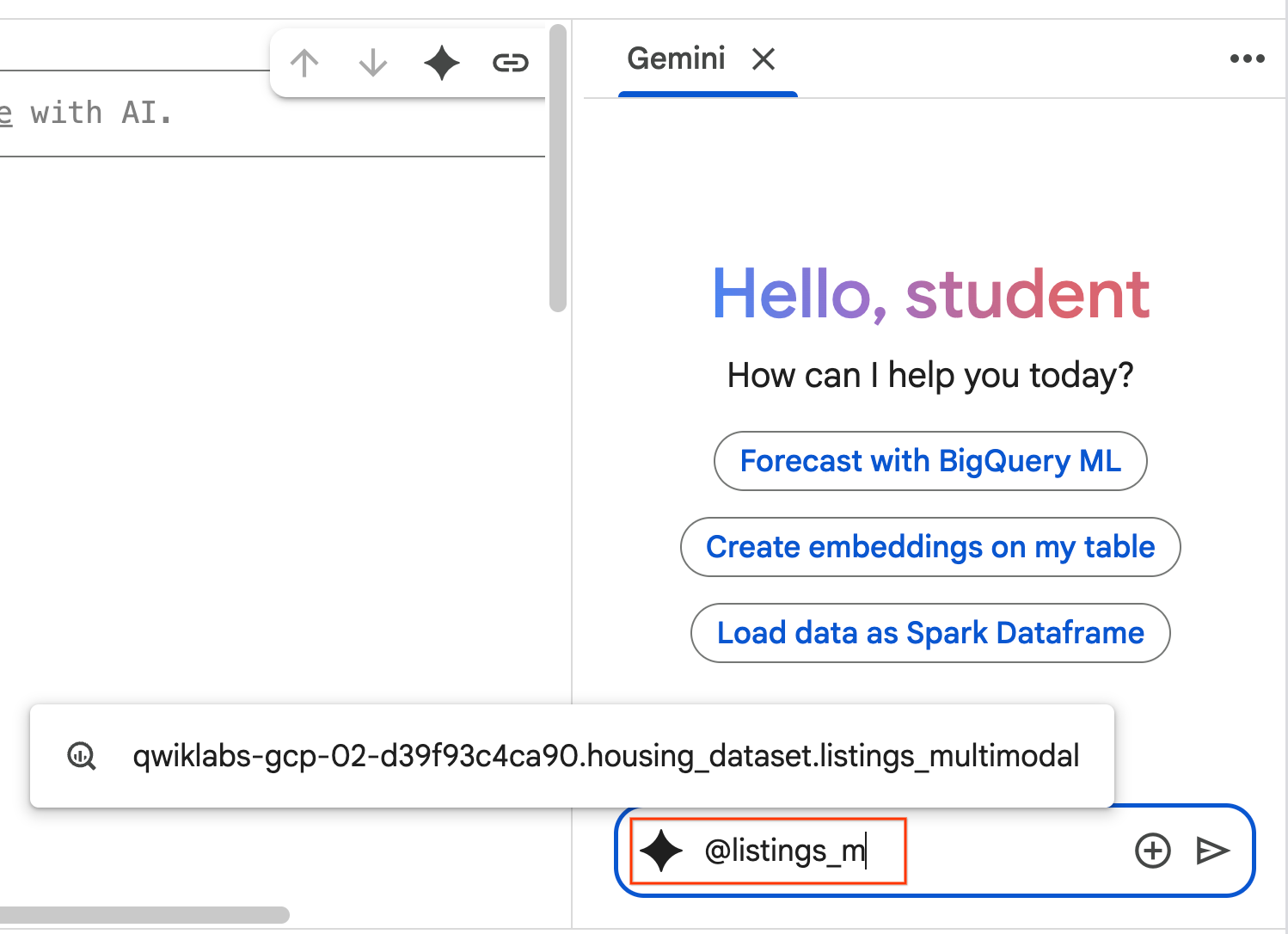
- 以下のプロンプトをコピーして、エージェント チャット ボックスに入力します。その後、[送信] をクリックしてプロンプトをエージェントに送信します。
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
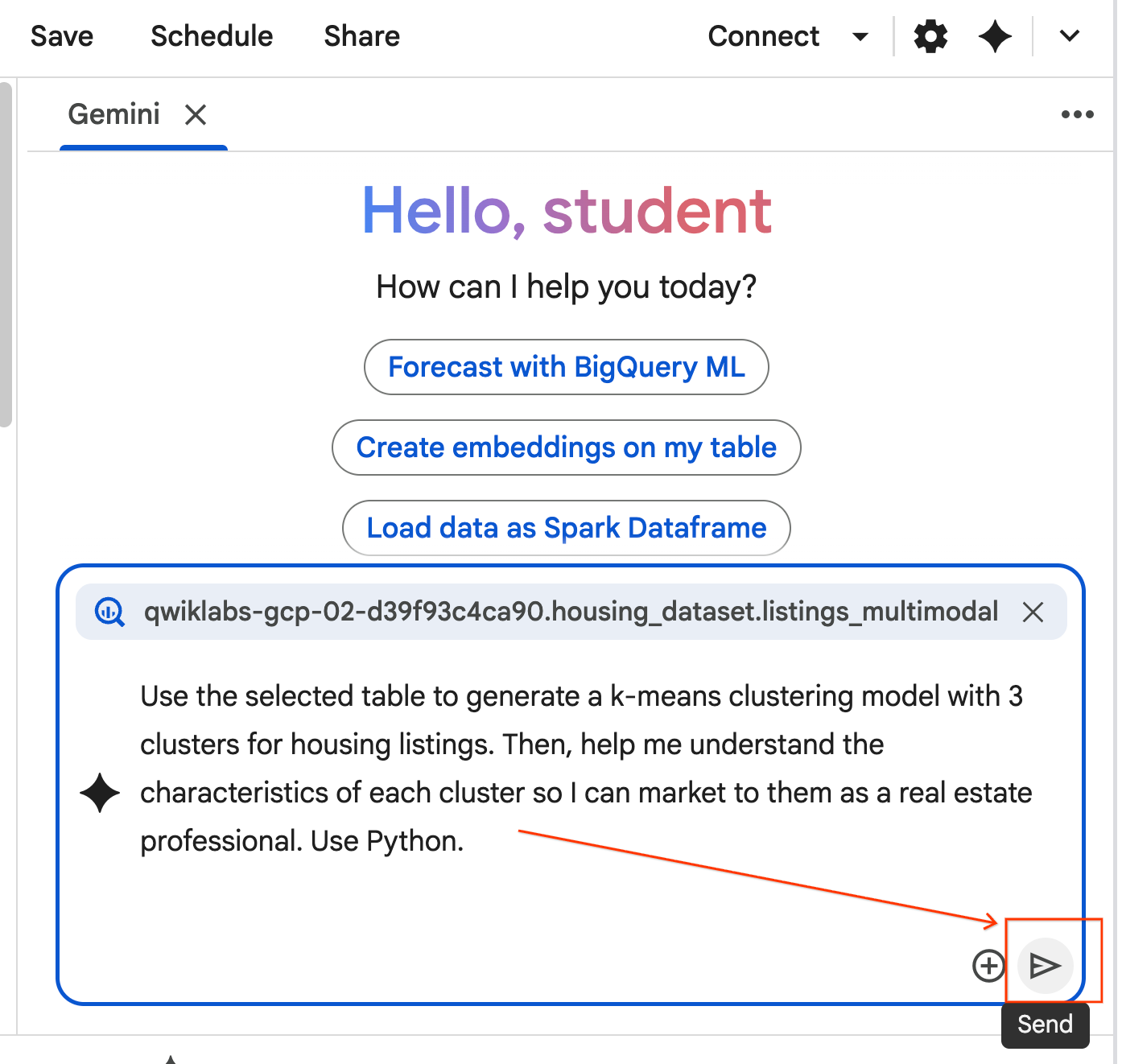
- エージェントが計画を立てます。このプランで問題なければ、[承認して実行] をクリックします。エージェントが 1 つ以上の新しいセルに Python コードを生成します。
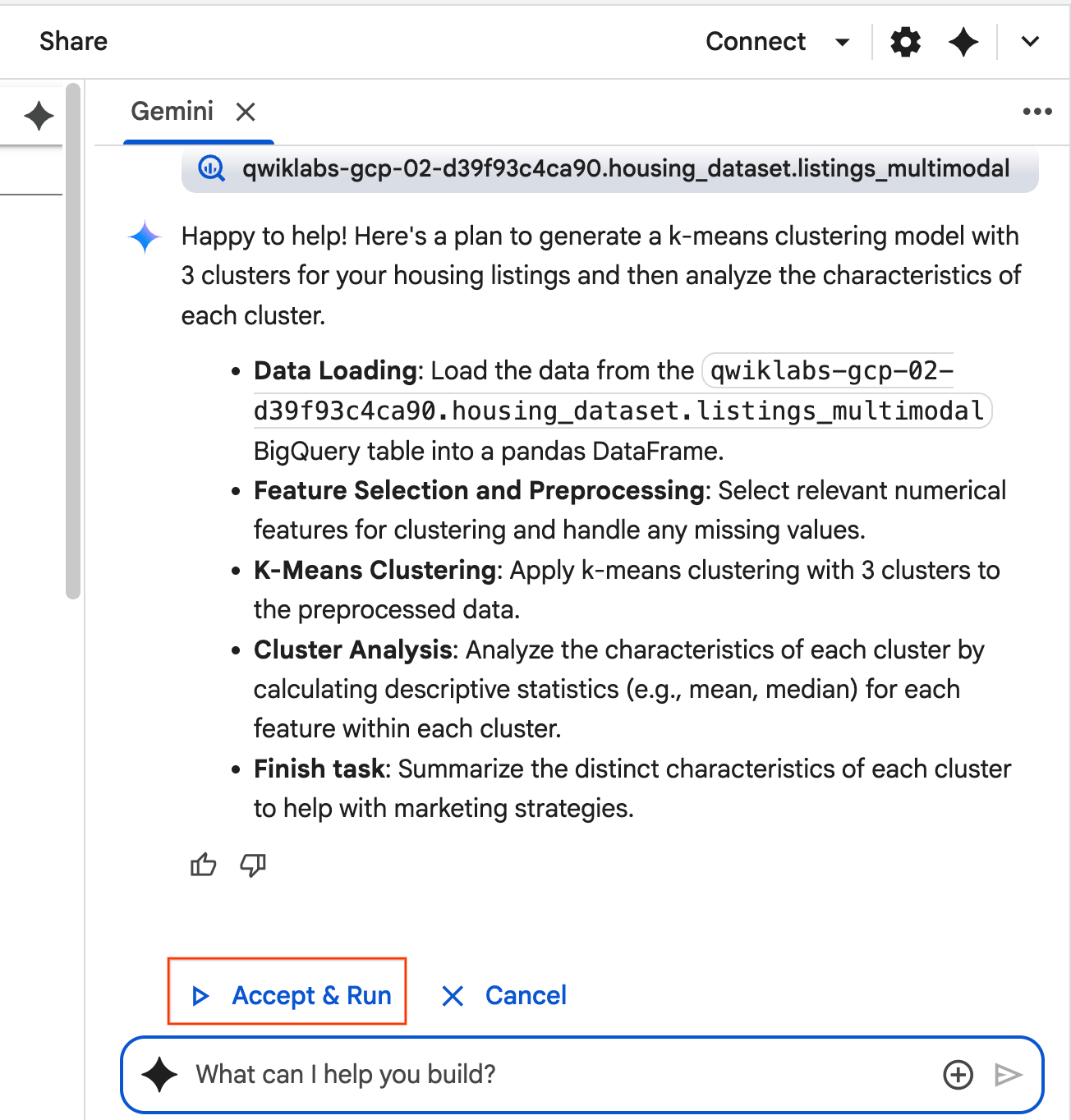
- エージェントは、生成するコードブロックごとに [承認して実行] をクリックするように求めます。これにより、人間参加型が維持されます。コードを確認または編集して、完了するまで各ステップを進めてください。
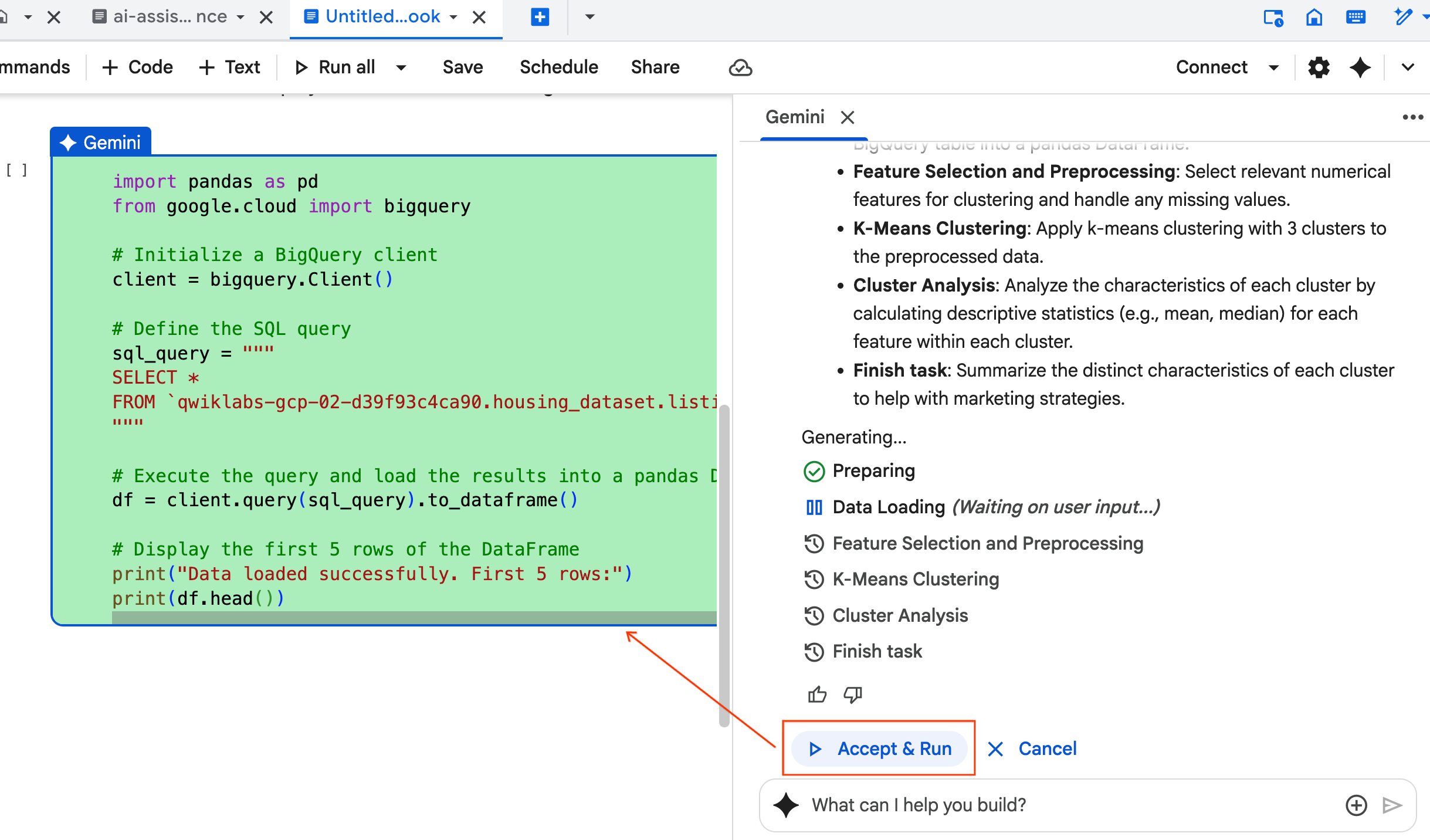
- 完了したら、この新しいノートブックのタブを閉じて、元の
ai-assisted-data-science.ipynbタブに戻り、ラボの最後のセクションに進みます。
12. エンベディングとベクトル検索を使用したマルチモーダル検索
この最後のセクションでは、BigQuery 内で直接マルチモーダル検索を実装します。これにより、テキストの説明に基づいて住宅を見つけたり、サンプル画像に似た住宅を見つけたりするなど、直感的な検索が可能になります。
このプロセスでは、まず各住宅画像をエンベディングと呼ばれる数値表現に変換します。エンベディングは画像のセマンティックな意味を捉え、数値ベクトルを比較することで類似のアイテムを見つけることができます。
multimodalembedding モデルを使用して、すべての物件情報のベクトルを生成します。ベクトル インデックスを作成して検索を高速化した後、テキスト画像変換(説明に一致する住宅を見つける)と画像から画像への類似検索(サンプル画像に似た住宅を見つける)の 2 種類の類似検索を実行します。
これらはすべて BigQuery で行います。ML.GENERATE_EMBEDDING などの関数を使用してエンベディングを生成し、VECTOR_SEARCH を使用して類似検索を行います。
13. クリーンアップ
このプロジェクトで使用しているすべての Google Cloud リソースをクリーンアップするには、Google Cloud プロジェクトを削除します。
または、ノートブックの新しいセルで次のコードを実行して、作成した個々のリソースを削除することもできます。
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
最後に、ノートブック自体を削除できます。
- BigQuery Studio の [エクスプローラ] ペインで、プロジェクトと [ノートブック] ノードを開きます。
ai-assisted-data-scienceノートブックの横にあるその他メニューをクリックします。- [削除] を選択します。
14. 完了
以上で、この Codelab は完了です。
学習した内容
- 特徴量エンジニアリングを通じて分析用の不動産物件の未加工データセットを準備 する。
- BigQuery の AI 関数を使用して住宅の写真を分析し、主要な視覚的特徴を抽出して物件情報を拡充 する。
- BigQuery Machine Learning(BQML)を使用して K 平均法モデルを構築して評価 し、物件を個別のクラスタに分割する。
- データ サイエンス エージェントを使用して Python でクラスタリング モデルを生成し、モデルの作成を自動化 する。
- 住宅画像のエンベディングを生成 して画像検索ツールを強化し、テキストまたは画像クエリで類似の住宅を見つける。