
1. 소개
개요
이 실습에서는 부동산 시나리오를 중심으로 BigQuery의 멀티모달 데이터 과학 워크플로를 살펴봅니다. 주택 목록과 이미지의 원시 데이터 세트로 시작하여 AI로 이 데이터를 보강하여 시각적 특징을 추출하고, 클러스터링 모델을 빌드하여 고유한 시장 세그먼트를 파악하고, 마지막으로 벡터 임베딩을 사용하여 강력한 시각적 검색 도구를 만듭니다.
간단한 텍스트 프롬프트를 사용하여 데이터 과학 에이전트로 Python 기반 클러스터링 모델을 자동으로 생성하여 이 SQL 네이티브 워크플로를 최신 생성형 AI 접근 방식과 비교합니다.
학습할 내용
- 특성 추출을 통해 분석할 부동산 등록정보의 원시 데이터 세트를 준비합니다.
- BigQuery의 AI 함수를 사용하여 주택 사진에서 주요 시각적 특징을 분석하여 등록정보를 보강합니다.
- BigQuery 머신러닝 (BQML)을 사용하여 K-평균 모델을 빌드하고 평가하여 속성을 고유한 클러스터로 분류합니다.
- 데이터 과학 에이전트를 사용하여 Python으로 클러스터링 모델을 생성하여 모델 생성을 자동화합니다.
- 텍스트 또는 이미지 쿼리로 유사한 주택을 찾는 시각적 검색 도구를 지원하기 위해 주택 이미지의 임베딩을 생성합니다.
기본 요건
이 실습을 시작하기 전에 다음 개념을 숙지해야 합니다.
- 기본 SQL 및 Python 프로그래밍
- Jupyter 노트북에서 Python 코드를 실행하는 방법
2. 시작하기 전에
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell로 API 사용 설정
Cloud Shell은 Google Cloud에서 실행되는 명령줄 환경으로, 필요한 도구가 미리 로드되어 제공됩니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 실행하여 Cloud Shell에서 인증을 확인합니다.
gcloud auth list
- 다음 명령어를 실행하여 프로젝트가 gcloud와 함께 사용하도록 구성되어 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API 사용 설정
- 다음 명령어를 실행하여 필요한 모든 API와 서비스를 사용 설정합니다.
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- 명령어가 성공적으로 실행되면 아래와 유사한 메시지가 표시됩니다.
Operation "operations/..." finished successfully.
- Cloud Shell을 종료합니다.
3. BigQuery Studio에서 실습 노트북 열기
UI 탐색:
- Google Cloud 콘솔에서 탐색 메뉴 > BigQuery로 이동합니다.
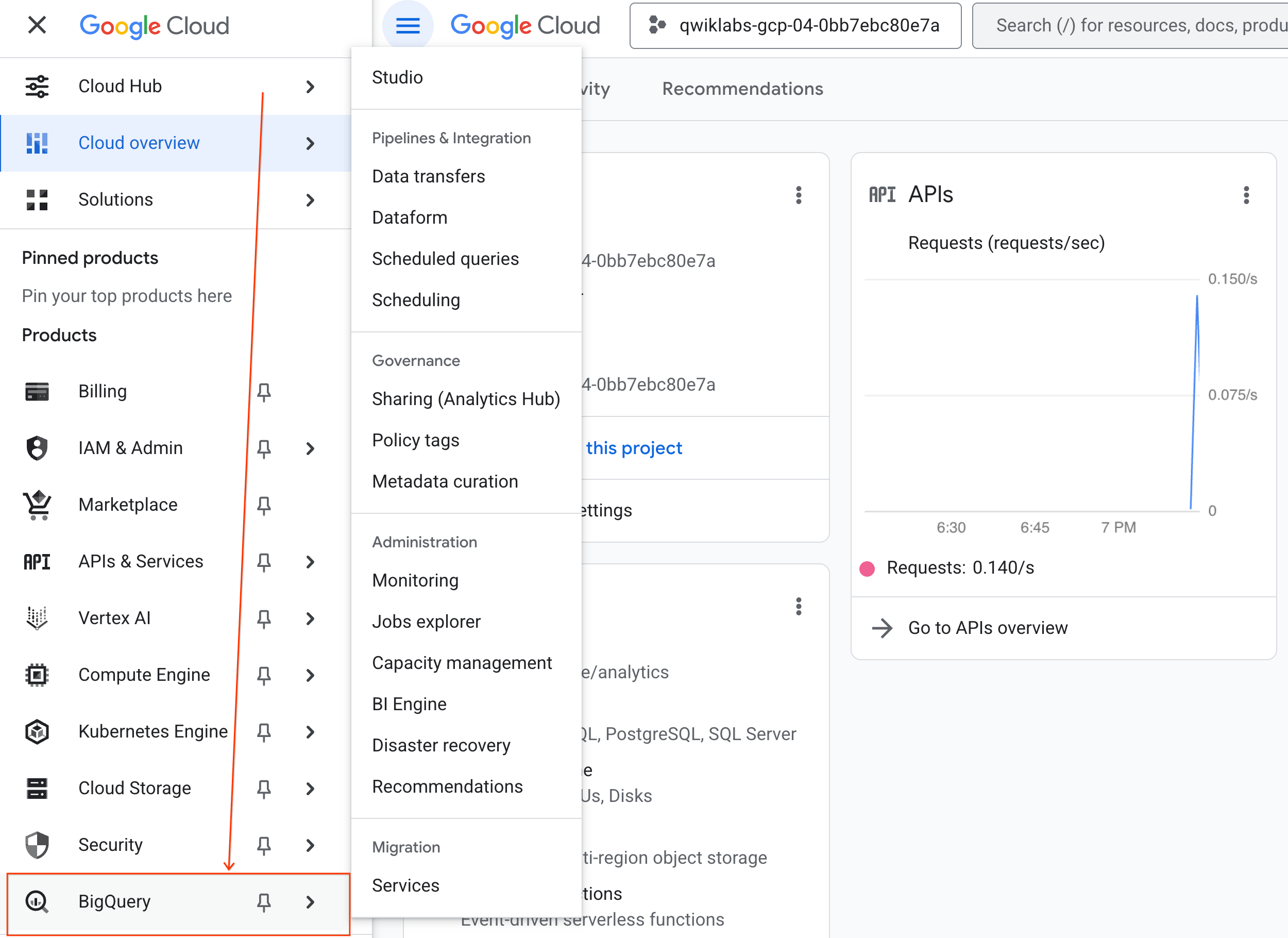
- BigQuery Studio 창에서 드롭다운 화살표 버튼을 클릭하고 노트북 위로 마우스를 가져간 다음 업로드를 선택합니다.
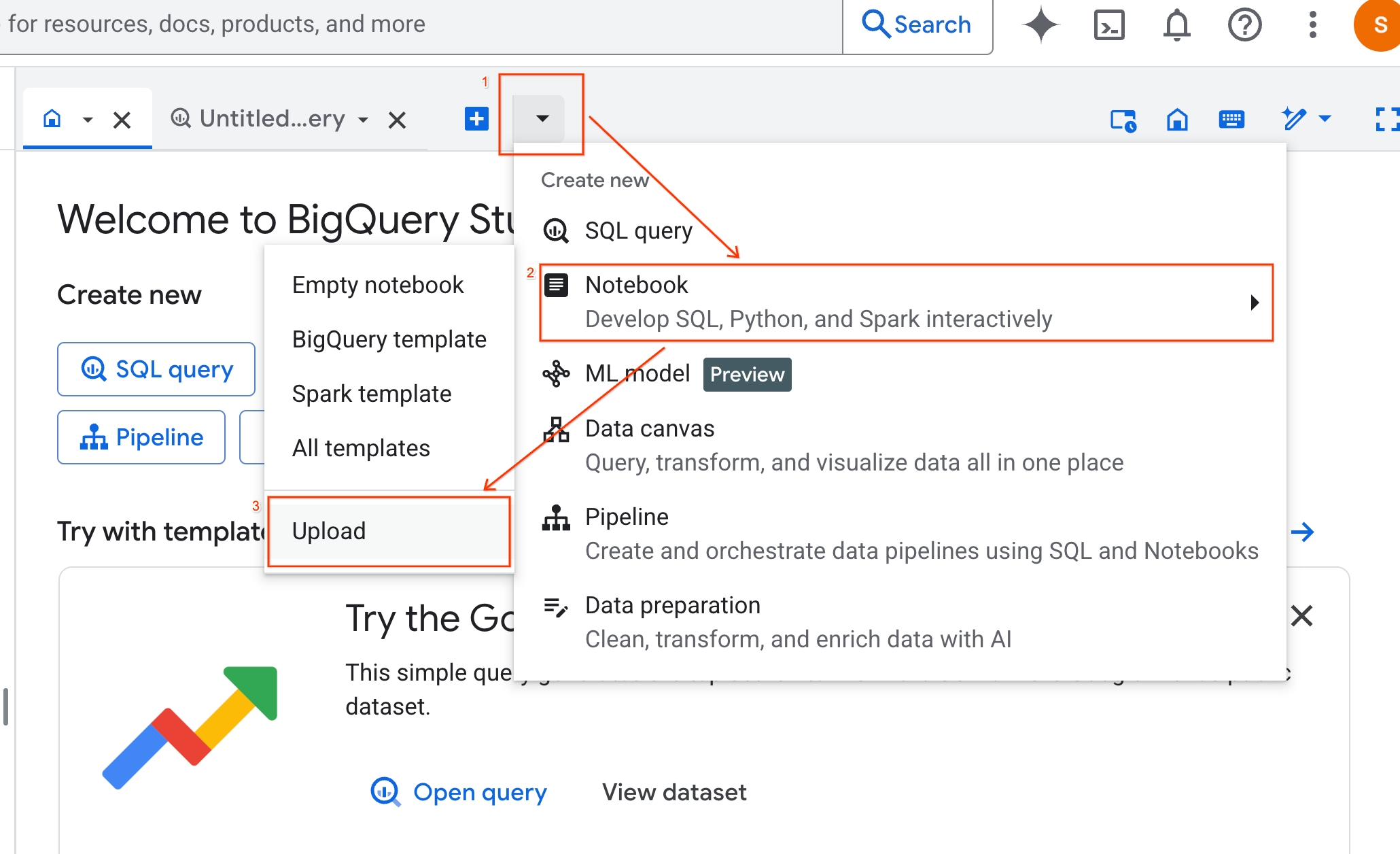
- URL 라디오 버튼을 선택하고 다음 URL을 입력합니다.
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- 리전을
us-central1로 설정하고 업로드를 클릭합니다.
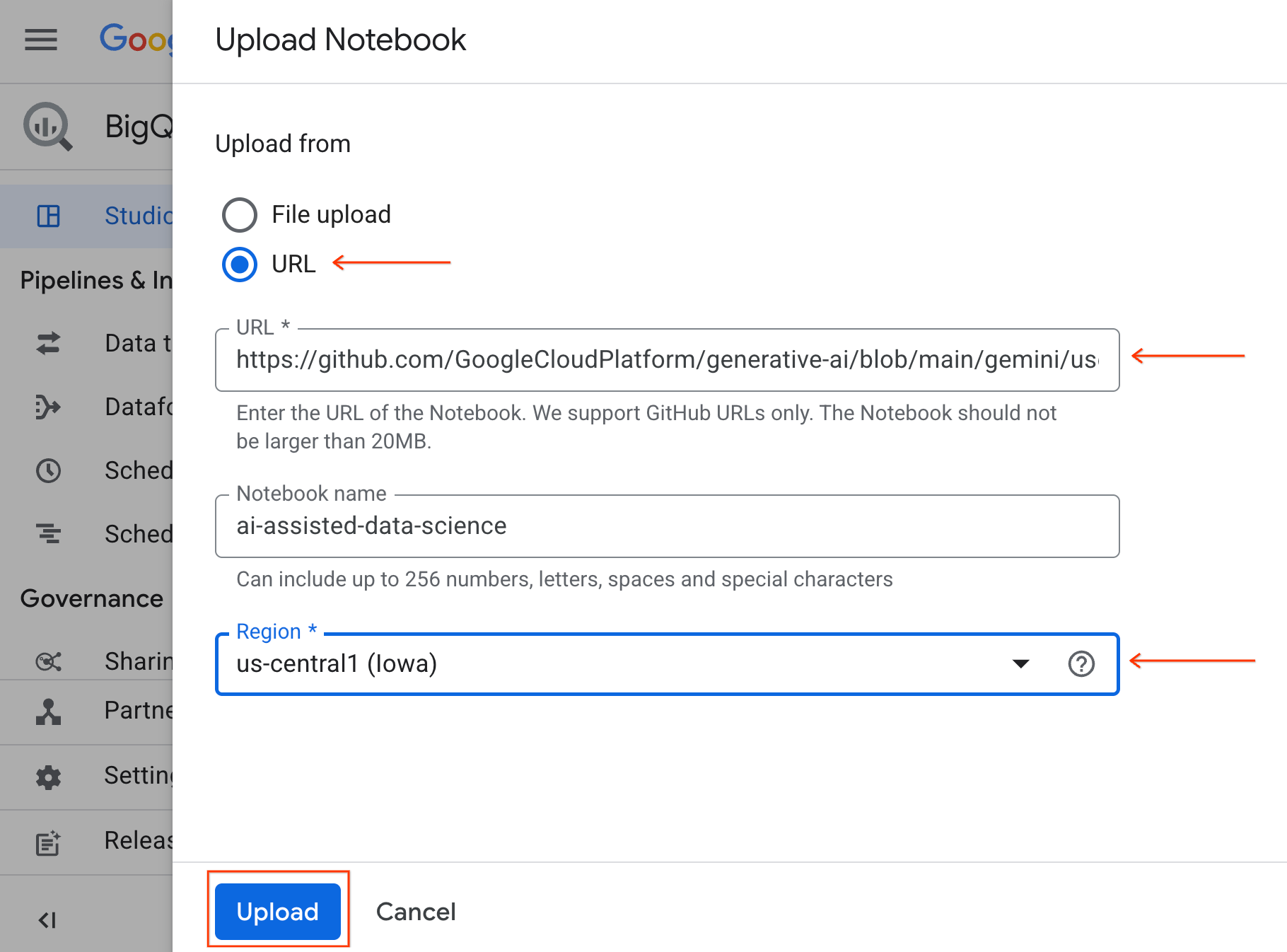
- 노트북을 열려면 프로젝트 ID가 포함된 탐색기 창에서 드롭다운 화살표를 클릭합니다. 그런 다음 노트북 드롭다운을 클릭합니다. 노트북
ai-assisted-data-science을 클릭합니다.
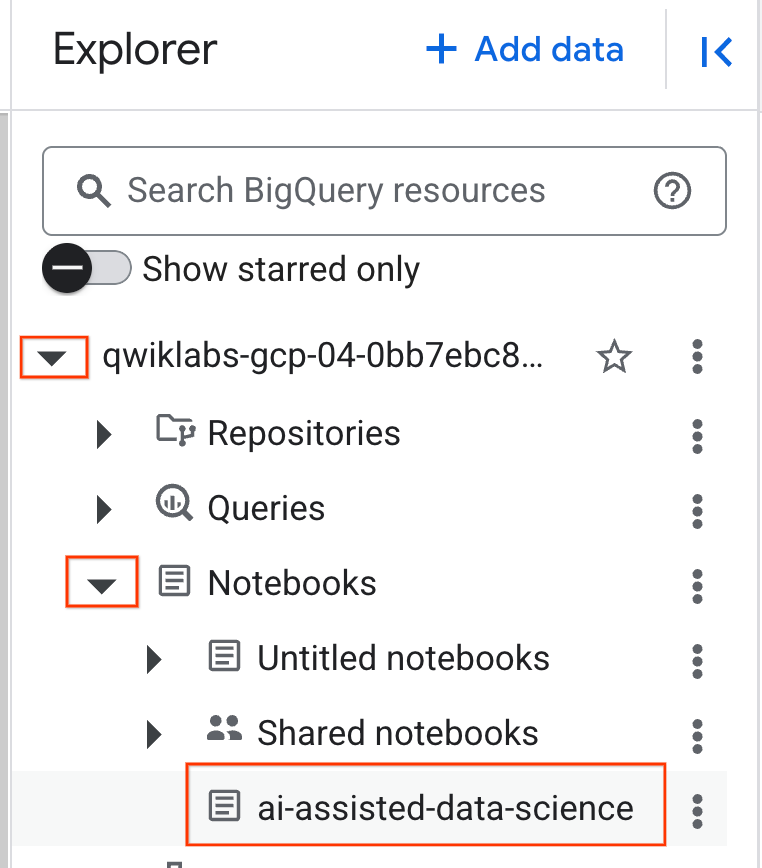
- (선택사항) 공간을 확보하려면 BigQuery 탐색 메뉴와 노트북의 목차를 접습니다.
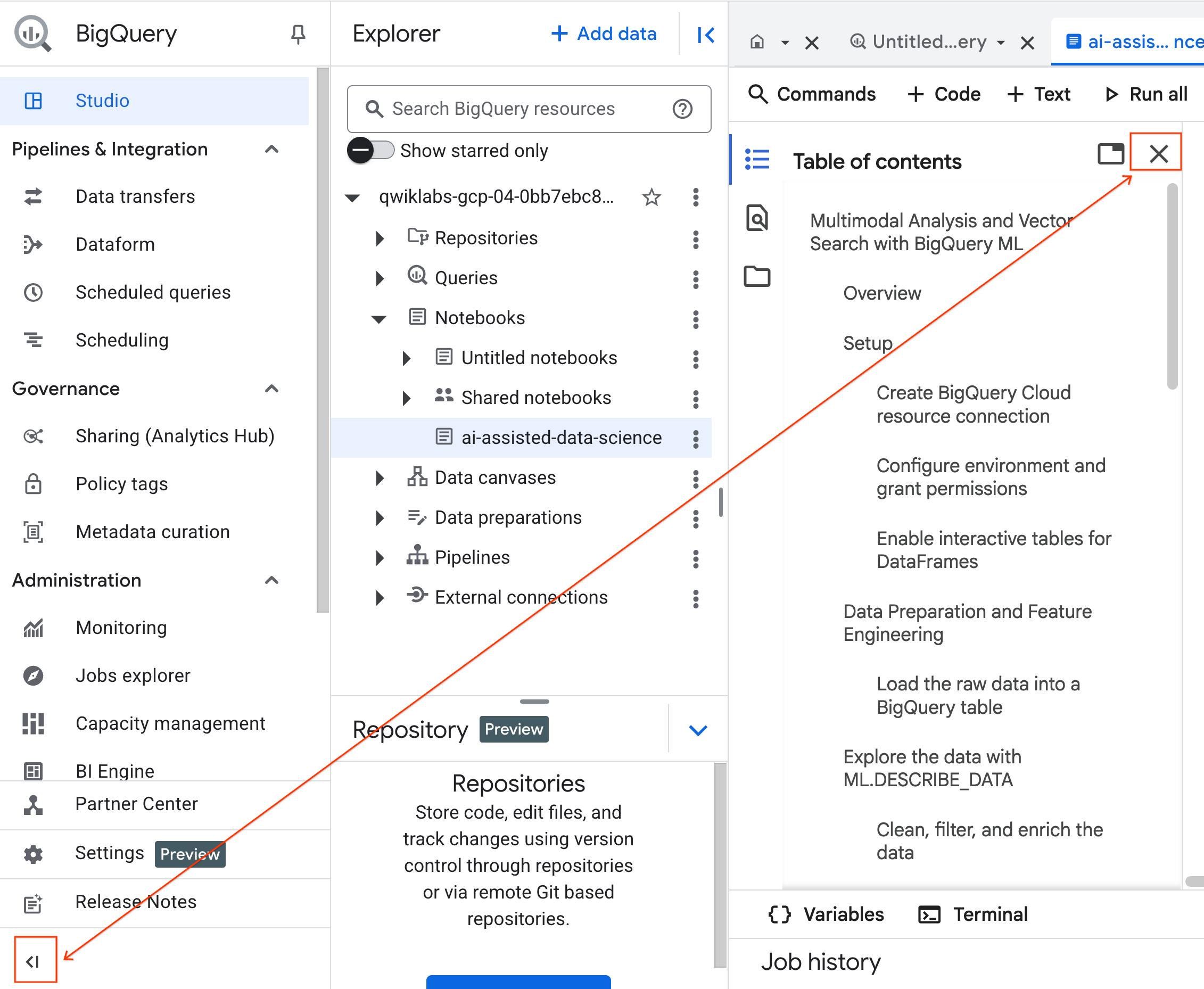
4. 런타임에 연결하고 설정 코드 실행
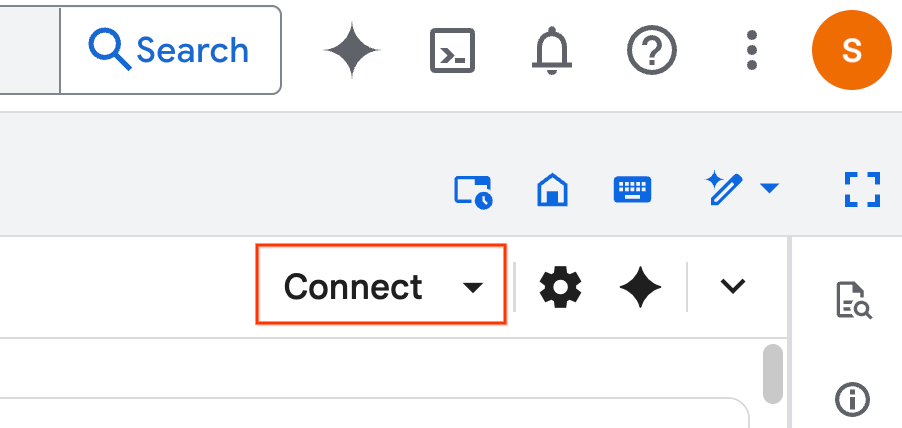
- 연결을 클릭합니다. 팝업이 표시되면 사용자로 Colab Enterprise를 승인합니다. 노트북이 런타임에 자동으로 연결됩니다. 완료하는 데 몇 분 정도 걸릴 수 있습니다.
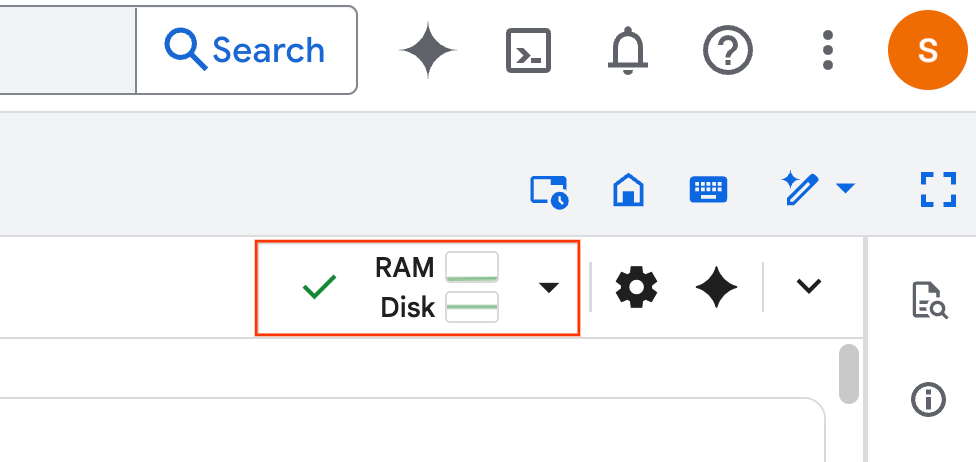
- 런타임이 설정되면 다음이 표시됩니다.
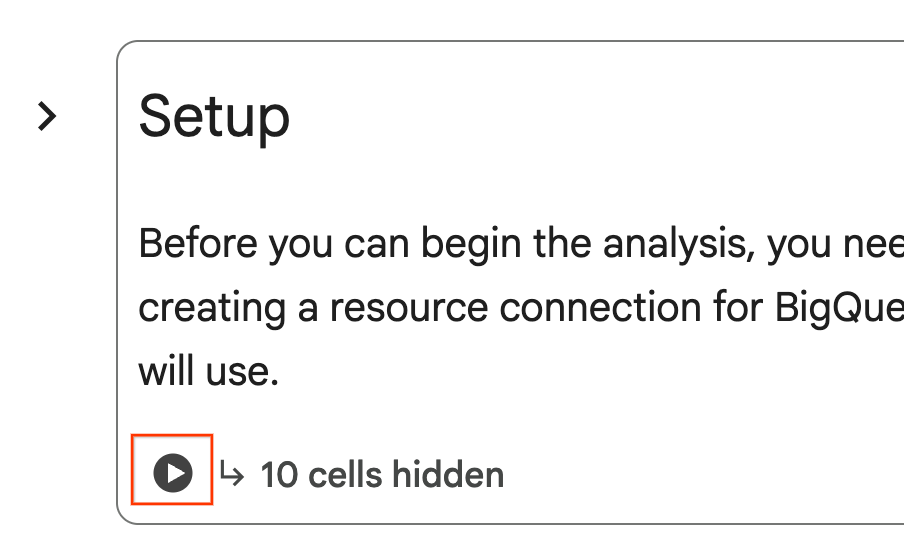
- 노트북에서 설정 섹션으로 스크롤합니다. 숨겨진 셀 옆에 있는 '실행' 버튼을 클릭합니다. 이렇게 하면 프로젝트에 실습에 필요한 몇 가지 리소스가 생성됩니다. 이 프로세스를 완료하는 데 1분 정도 걸릴 수 있습니다. 그동안 설정 아래의 셀을 확인해 보세요.
5. 데이터 준비 및 특성 추출
이 섹션에서는 모든 데이터 과학 프로젝트의 첫 번째 중요한 단계인 데이터 준비를 살펴봅니다. 먼저 BigQuery 데이터 세트를 만들어 작업을 정리한 다음 Cloud Storage의 CSV 파일에서 원시 부동산 / 주택 데이터를 새 테이블로 로드합니다.
그런 다음 이 원시 데이터를 새로운 기능이 포함된 정리된 테이블로 변환합니다. 여기에는 등록정보 필터링, 새로운 property_age 기능 생성, 멀티모달 분석을 위한 이미지 데이터 준비가 포함됩니다.
6. AI 함수를 사용한 멀티모달 보강
이제 생성형 AI의 기능을 사용하여 데이터를 보강합니다. 이 섹션에서는 BigQuery의 내장 AI 함수를 사용하여 각 주택 등록정보의 이미지를 분석합니다.
BigQuery를 Gemini 모델에 연결하면 SQL을 사용하여 이미지에서 유용한 새로운 기능을 직접 추출할 수 있습니다 (예: 숙박 시설이 물가 근처에 있는지 여부, 숙박 시설에 관한 간략한 설명).
7. k-평균 클러스터링을 사용한 모델 학습
새로 보강된 데이터 세트를 사용하여 머신러닝 모델을 빌드할 수 있습니다. 목표는 주택 등록정보를 별개의 그룹으로 분류하는 것입니다. 이를 위해 BigQuery 머신러닝 (BQML)을 사용하여 BigQuery에서 직접 K-평균 클러스터링 모델을 학습시킵니다. 이 단일 단계의 일환으로 Agent Platform AI Model Registry에 모델을 등록하여 Google Cloud의 광범위한 MLOps 생태계 내에서 즉시 사용할 수 있습니다.
모델이 성공적으로 등록되었는지 확인하려면 다음 단계에 따라 에이전트 플랫폼 Model Registry에서 모델을 찾으세요.
- Google Cloud 콘솔의 왼쪽 상단에서 탐색 메뉴 (☰)를 클릭합니다.
- 에이전트 플랫폼 섹션으로 스크롤한 다음 모델을 클릭합니다.
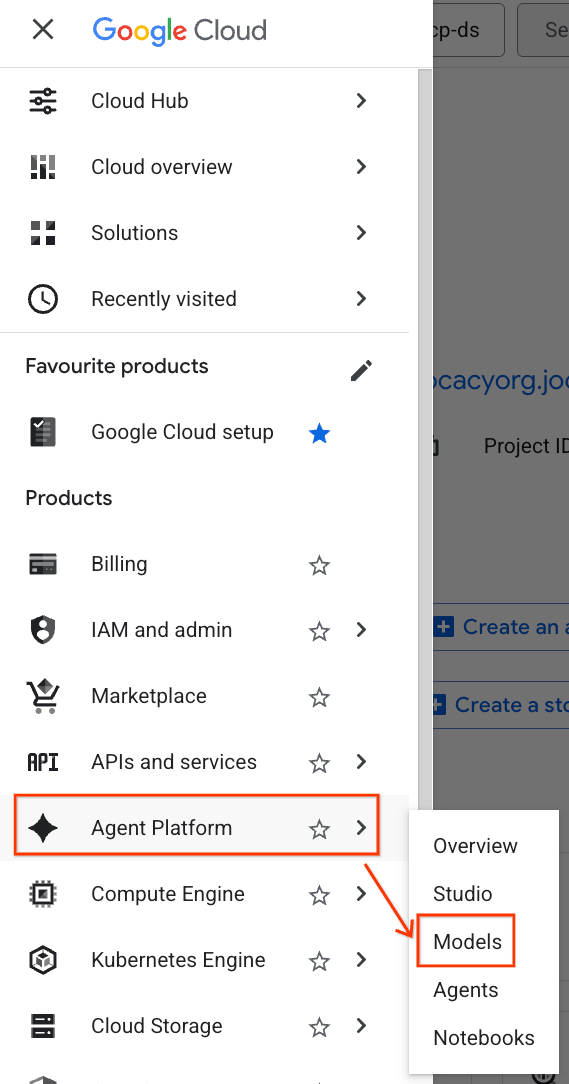
- 스크린샷에서 강조 표시된 Model Registry 버튼을 클릭합니다.
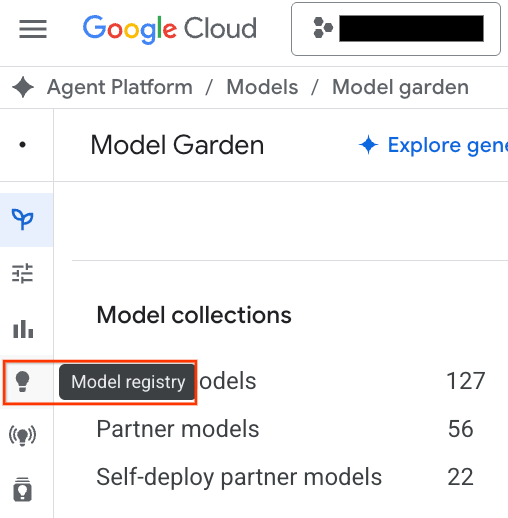
- BQML 모델이 다른 모든 맞춤 모델과 함께 나열됩니다. 모델 목록에서 housing_clustering이라는 모델을 찾습니다. 다음 단계로 엔드포인트에 배포하여 BigQuery 환경 외부에서 실시간 온라인 예측에 모델을 사용할 수 있습니다.
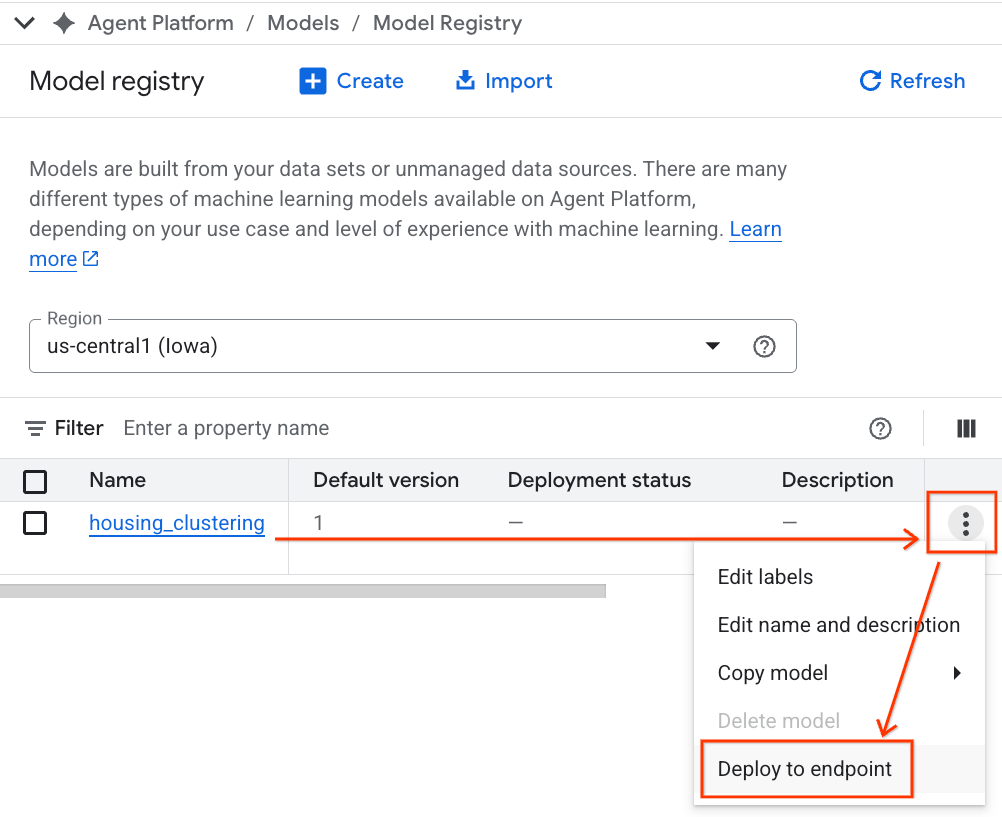
Model Registry를 살펴본 후 다음 단계에 따라 BigQuery의 Colab 노트북으로 돌아갈 수 있습니다.
- 탐색 메뉴 (☰)에서 BigQuery > Studio로 이동합니다.
- 탐색 창에서 메뉴를 펼쳐 노트북을 찾아 엽니다.
8. 모델 평가 및 예측
모델을 학습시킨 후 다음 단계는 모델에서 생성된 클러스터를 이해하는 것입니다. 여기에서는 ML.EVALUATE 및 ML.CENTROIDS과 같은 BigQuery 머신러닝 함수를 사용하여 모델의 품질과 각 세그먼트의 정의 특성을 분석합니다.
그런 다음 ML.PREDICT을 사용하여 각 주택을 클러스터에 할당합니다. %%bigquery df 매직 명령어로 이 쿼리를 실행하면 결과가 df이라는 pandas DataFrame에 저장됩니다. 이렇게 하면 후속 Python 단계에서 데이터를 즉시 사용할 수 있습니다. 이를 통해 Colab Enterprise에서 SQL과 Python 간의 상호 운용성을 확인할 수 있습니다.
9. 클러스터 시각화 및 해석
이제 예측이 DataFrame에 로드되었으므로 시각화를 만들어 데이터를 생생하게 표현할 수 있습니다. 이 섹션에서는 Matplotlib과 같은 인기 있는 Python 라이브러리를 사용하여 주택 세그먼트 간의 차이점을 살펴봅니다.
상자 그림과 막대 그래프를 만들어 가격, 부동산 연령과 같은 주요 특징을 시각적으로 비교하면 각 클러스터를 직관적으로 이해하기 쉽습니다.
10. Gemini 모델로 클러스터 설명 생성
수치 중심점과 차트도 유용하지만 생성형 AI를 사용하면 한 단계 더 나아가 각 주택 세그먼트에 대한 풍부한 정성적 페르소나를 만들 수 있습니다. 이를 통해 클러스터가 무엇인지뿐만 아니라 누구를 나타내는지도 파악할 수 있습니다.
이 섹션에서는 먼저 가격, 면적과 같은 각 클러스터의 평균 통계를 집계합니다. 그런 다음 이 데이터를 Gemini 모델의 프롬프트에 전달합니다. 그런 다음 모델에 부동산 전문가 역할을 맡아 각 세그먼트의 주요 특징과 타겟 구매자를 포함한 자세한 요약을 생성하도록 지시합니다. 그 결과 마케팅팀이 클러스터를 즉시 이해하고 조치를 취할 수 있는 명확하고 사람이 읽을 수 있는 설명이 생성됩니다.
원하는 대로 프롬프트를 변경하고 결과를 실험해 보세요.
11. 데이터 과학 에이전트로 모델링 자동화
이제 강력한 대체 워크플로를 살펴보겠습니다. 코드를 수동으로 작성하는 대신 통합된 데이터 과학 에이전트를 사용하여 단일 자연어 프롬프트에서 완전한 클러스터링 모델 워크플로를 자동으로 생성합니다.
에이전트를 사용하여 모델을 생성하고 실행하려면 다음 단계를 따르세요.
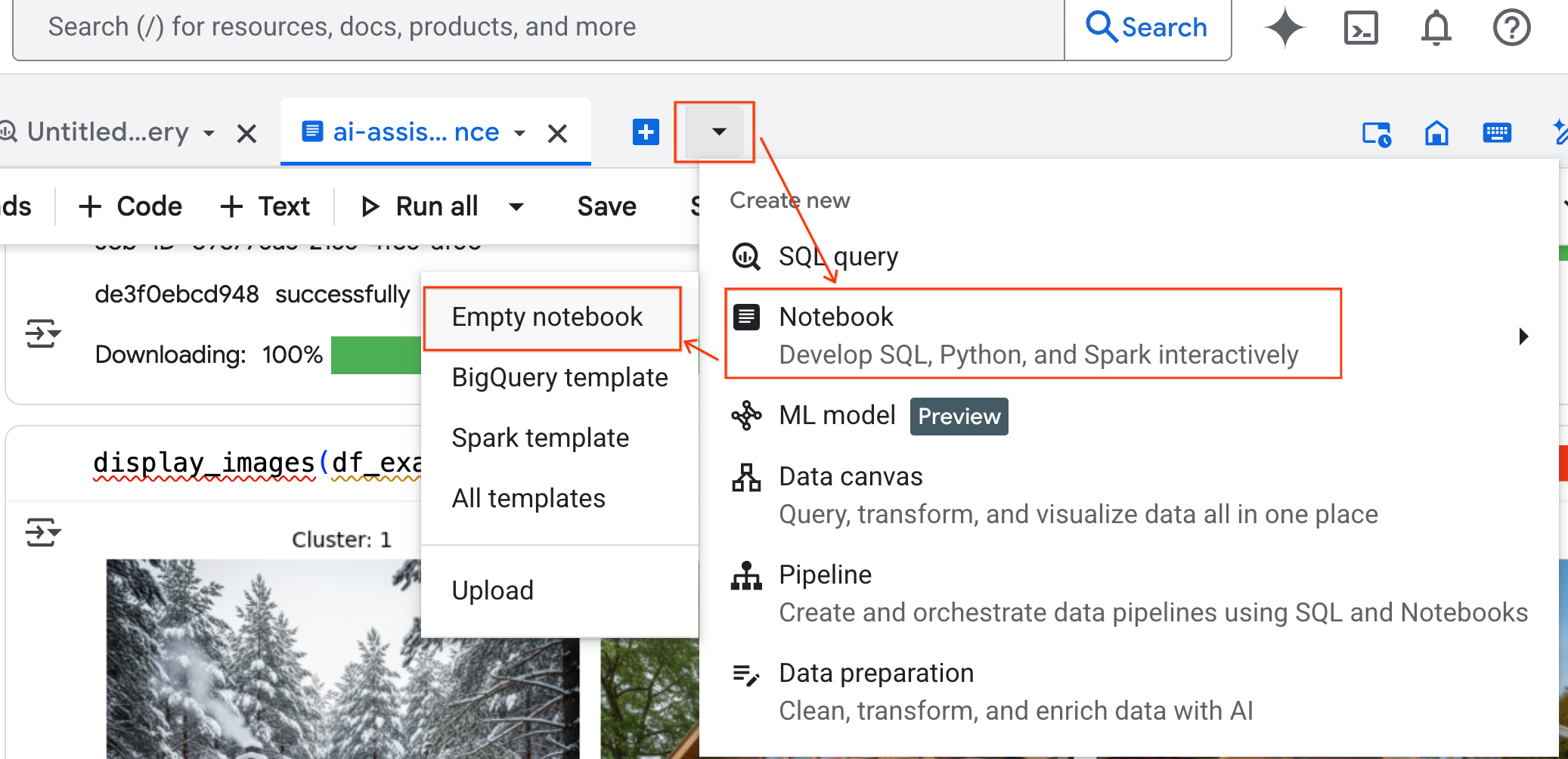
- BigQuery Studio 창에서 드롭다운 화살표 버튼을 클릭하고 노트북 위로 마우스를 가져간 다음 빈 노트북을 선택합니다. 이렇게 하면 에이전트의 코드가 원래 실험실 노트북을 방해하지 않습니다.
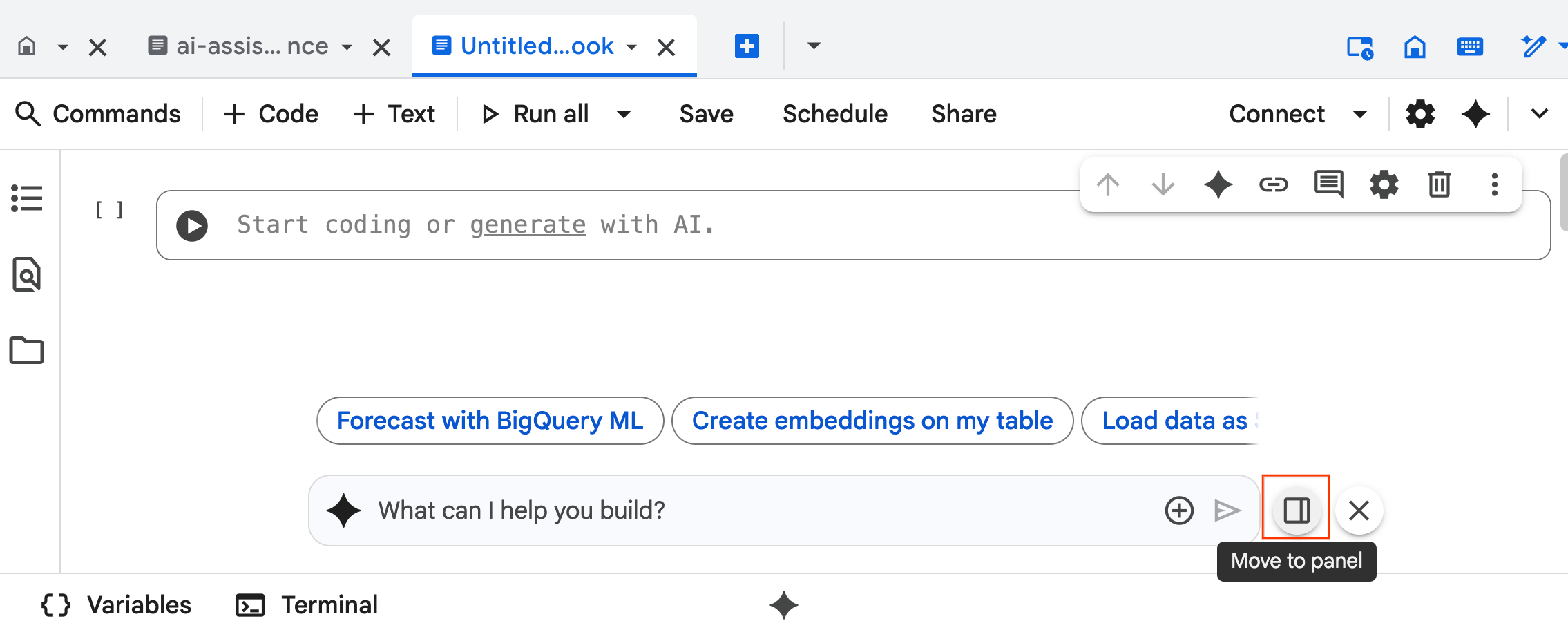
- 데이터 과학 에이전트 채팅 인터페이스가 노트북 하단에 열립니다. 패널로 이동 버튼을 클릭하여 채팅을 오른쪽에 고정합니다.
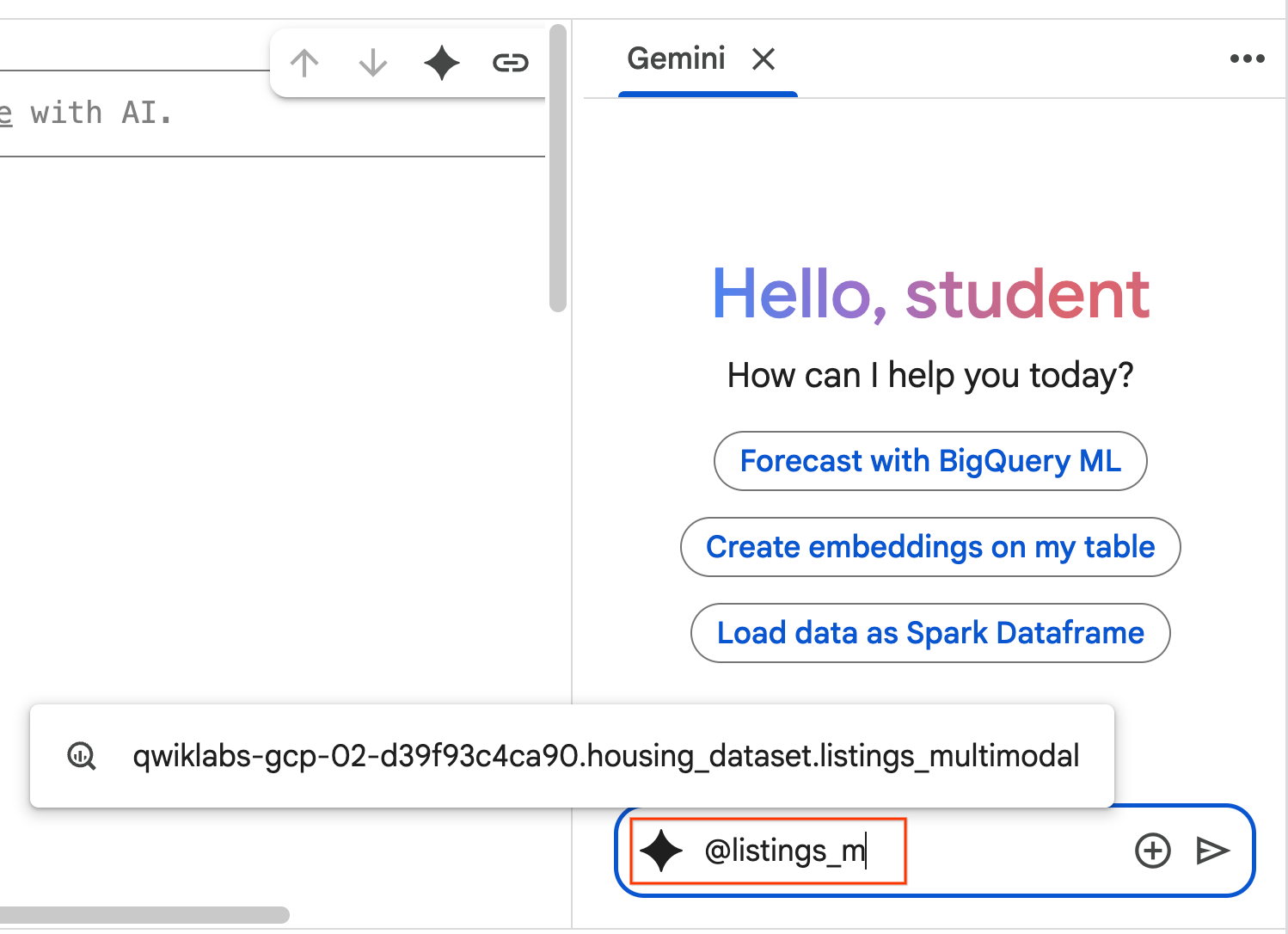
- 채팅 창에
@listing_multimodal를 입력하고 테이블을 클릭합니다. 이렇게 하면listings_multimodal테이블이 컨텍스트로 명시적으로 설정됩니다.
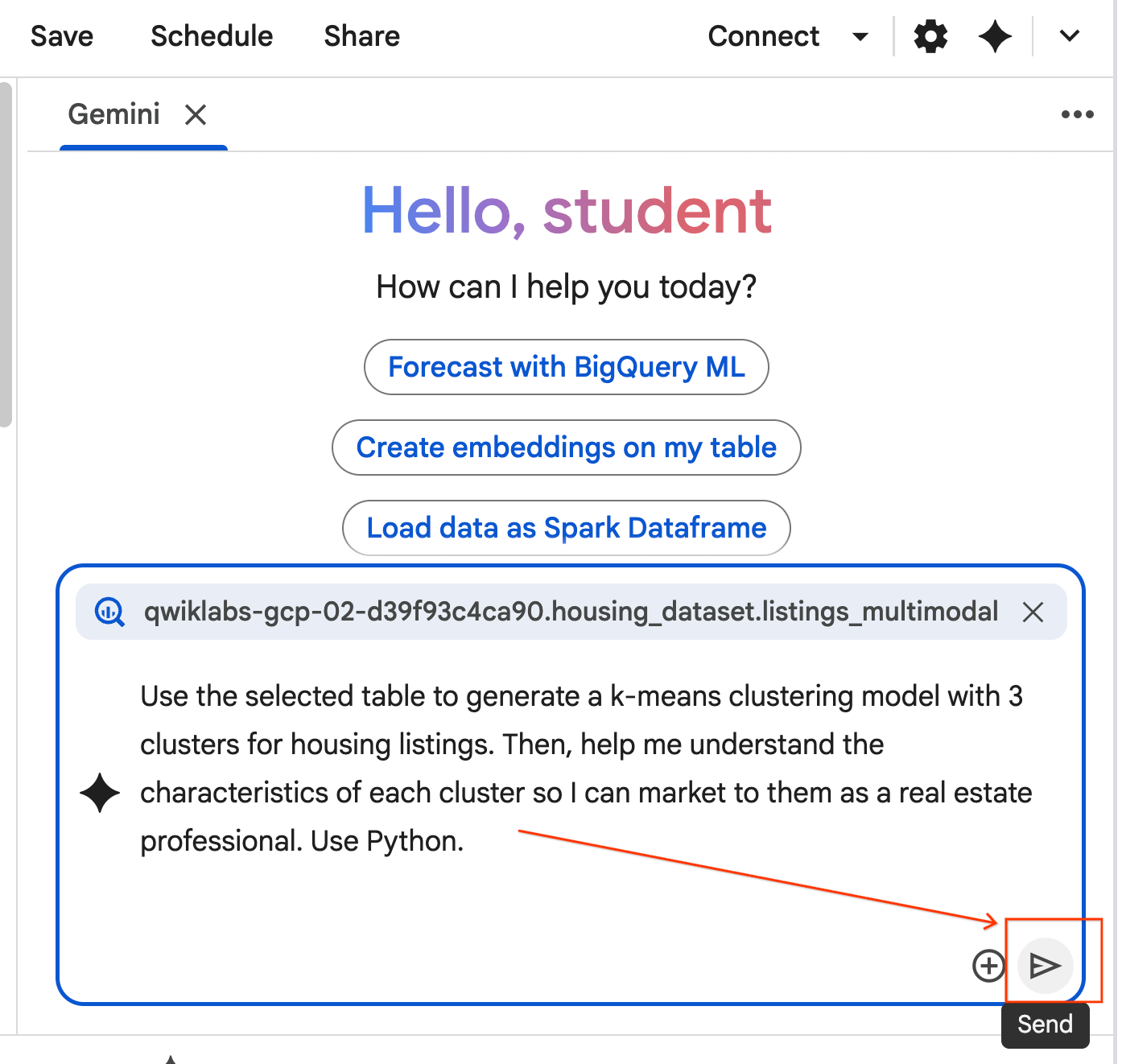
- 아래 프롬프트를 복사하여 에이전트 채팅 상자에 입력합니다. 그런 다음 보내기를 클릭하여 프롬프트를 에이전트에 제출합니다.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- 에이전트가 생각하고 계획을 수립합니다. 이 계획이 마음에 들면 수락 및 실행을 클릭합니다. 에이전트가 하나 이상의 새 셀에 Python 코드를 생성합니다.
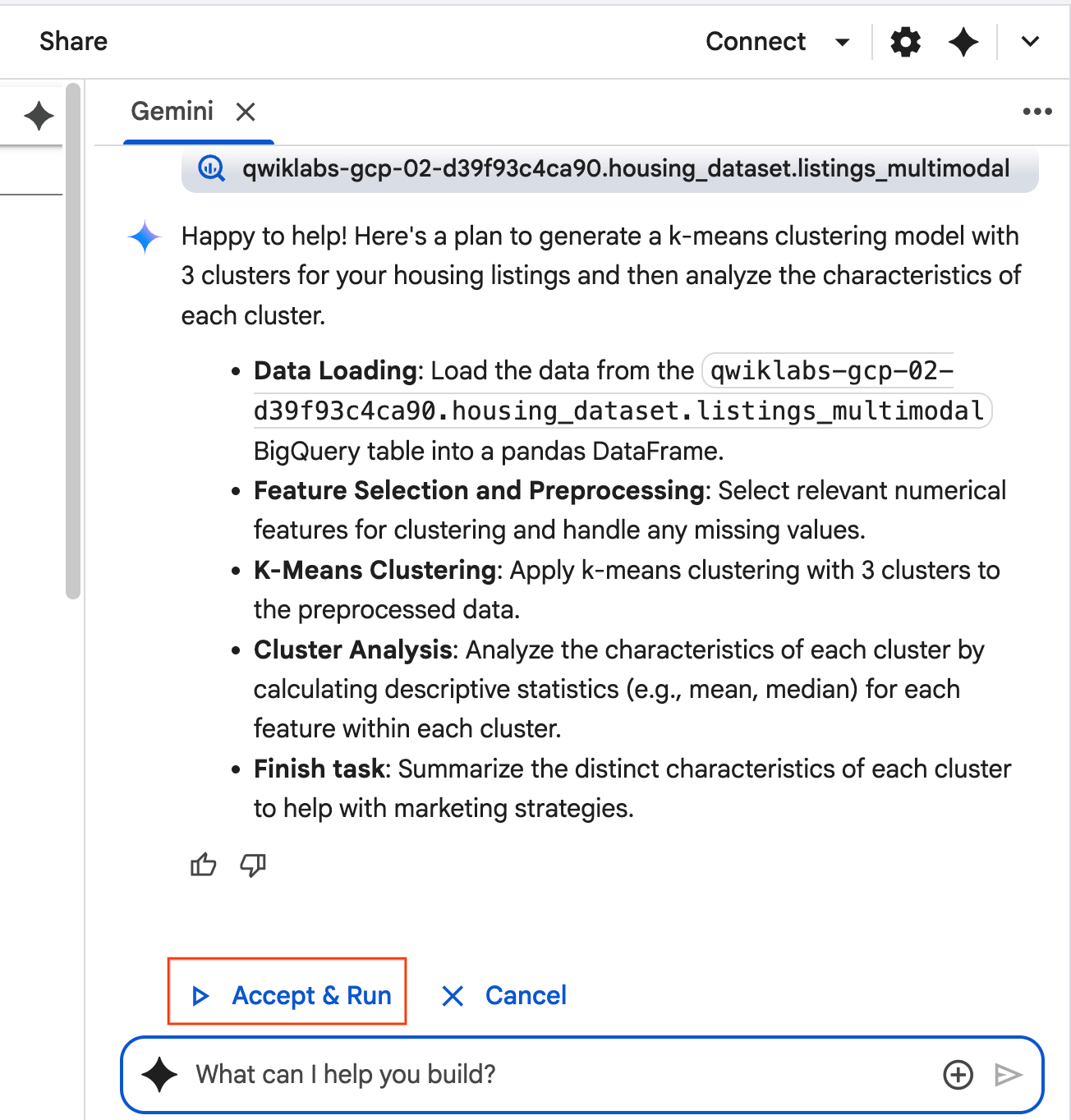
- 에이전트가 생성하는 각 코드 블록을 수락 후 실행하라는 메시지가 표시됩니다. 이렇게 하면 인간 참여형(Human-In-The-Loop) 프로세스가 유지됩니다. 코드를 검토하거나 수정하고 완료될 때까지 각 단계를 계속 진행하세요.
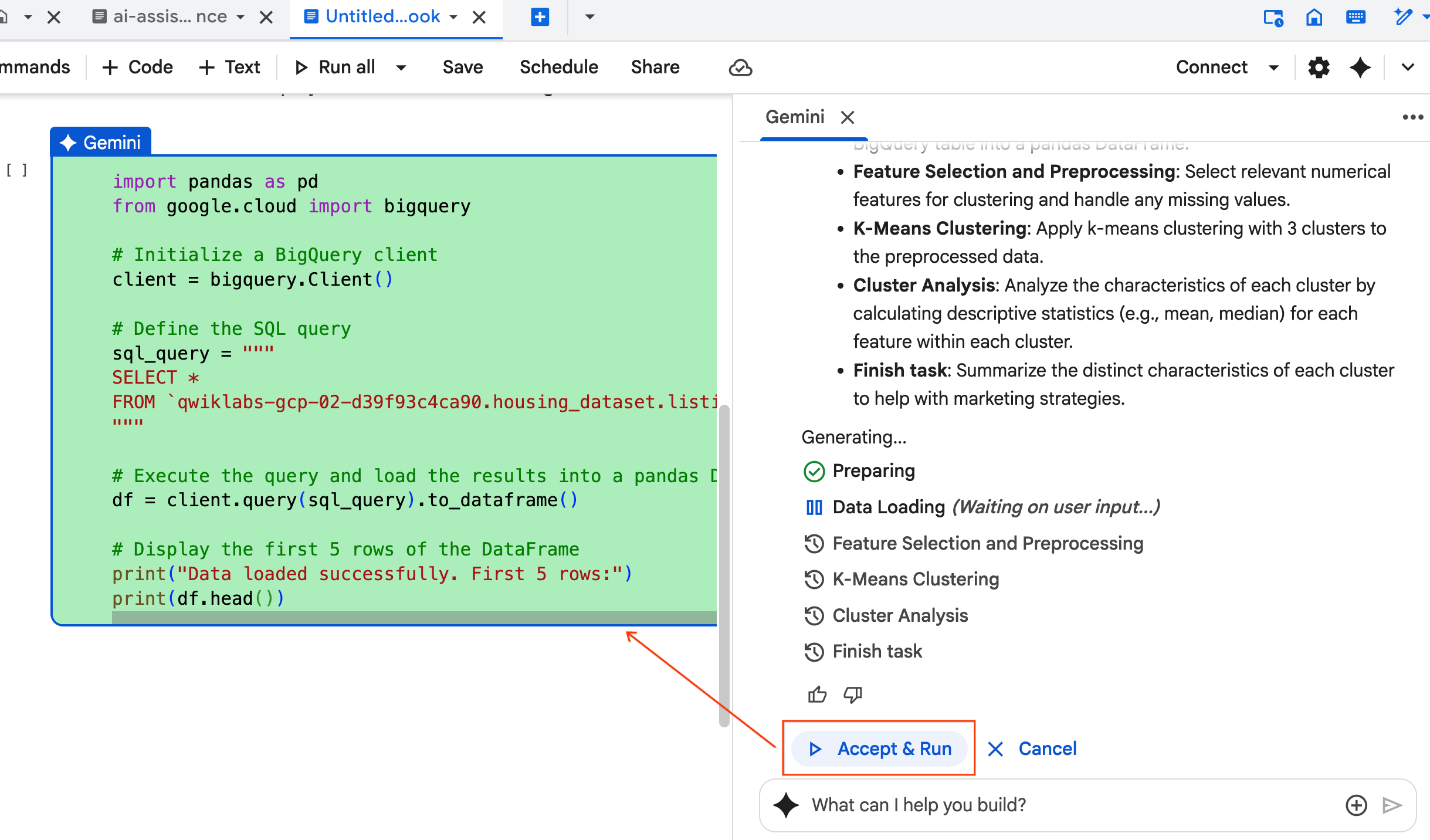
- 완료되면 이 새 노트북 탭을 닫고 원래
ai-assisted-data-science.ipynb탭으로 돌아가 실습의 마지막 섹션을 계속 진행합니다.
12. 임베딩 및 벡터 검색을 사용한 멀티모달 검색
이 마지막 섹션에서는 BigQuery 내에서 직접 멀티모달 검색을 구현합니다. 이를 통해 텍스트 설명을 기반으로 주택을 찾거나 샘플 사진과 유사한 주택을 찾는 등 직관적인 검색이 가능합니다.
이 프로세스는 먼저 각 주택 이미지를 임베딩이라고 하는 숫자 표현으로 변환하는 방식으로 작동합니다. 임베딩은 이미지의 시맨틱 의미를 포착하므로 숫자 벡터를 비교하여 유사한 항목을 찾을 수 있습니다.
multimodalembedding 모델을 사용하여 모든 등록정보에 대해 이러한 벡터를 생성합니다. 조회를 가속화하기 위해 벡터 색인을 만든 후 텍스트 이미지 변환 (설명과 일치하는 주택 찾기) 및 이미지-이미지 (샘플 이미지와 유사한 주택 찾기)의 두 가지 유형의 유사성 검색을 실행합니다.
이 모든 작업은 BigQuery에서 ML.GENERATE_EMBEDDING과 같은 함수를 사용하여 임베딩을 생성하거나 VECTOR_SEARCH를 사용하여 유사성 검색을 실행하여 완료합니다.
13. 삭제
이 프로젝트에 사용된 모든 Google Cloud 리소스를 정리하려면 Google Cloud 프로젝트를 삭제하면 됩니다.
또는 노트북의 새 셀에서 다음 코드를 실행하여 만든 개별 리소스를 삭제할 수 있습니다.
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
마지막으로 노트북 자체를 삭제할 수 있습니다.
- BigQuery Studio의 탐색기 창에서 프로젝트와 Notebooks 노드를 펼칩니다.
ai-assisted-data-science노트북 옆에 있는 세 개의 세로 점을 클릭합니다.- 삭제를 선택합니다.
14. 축하합니다.
축하합니다. Codelab을 완료했습니다.
학습한 내용
- 특성 추출을 통해 분석할 부동산 등록정보의 원시 데이터 세트를 준비합니다.
- BigQuery의 AI 함수를 사용하여 주택 사진에서 주요 시각적 특징을 분석하여 등록정보를 보강합니다.
- BigQuery 머신러닝 (BQML)으로 K-평균 모델을 빌드하고 평가하여 속성을 고유한 클러스터로 분류합니다.
- 데이터 과학 에이전트를 사용하여 Python으로 클러스터링 모델을 생성하여 모델 생성을 자동화합니다.
- 텍스트 또는 이미지 쿼리로 유사한 주택을 찾는 시각적 검색 도구를 지원하기 위해 주택 이미지의 임베딩을 생성합니다.