
1. Wprowadzenie
Przegląd
W tym module poznasz wielomodowy przepływ pracy związany z nauką o danych w BigQuery na przykładzie scenariusza związanego z nieruchomościami. Zaczniesz od surowego zbioru danych z ogłoszeniami o sprzedaży domów i ich zdjęciami, wzbogacisz te dane za pomocą AI, aby wyodrębnić cechy wizualne, utworzysz model klastrowania, aby odkryć odrębne segmenty rynku, a na koniec utworzysz zaawansowane narzędzie do wyszukiwania wizualnego za pomocą osadzania wektorowego.
Porównasz ten natywny dla SQL przepływ pracy z nowoczesnym podejściem opartym na generatywnej AI, używając agenta Data Science do automatycznego generowania modelu grupowania opartego na Pythonie na podstawie prostego prompta tekstowego.
Czego się nauczysz
- Przygotuj surowy zbiór danych z ofertami nieruchomości do analizy za pomocą inżynierii cech.
- Wzbogacaj informacje, korzystając z funkcji AI w BigQuery do analizowania zdjęć domów pod kątem kluczowych cech wizualnych.
- Tworzenie i ocenianie modelu k-średnich za pomocą uczenia maszynowego w BigQuery (BQML) w celu segmentowania usług na odrębne klastry.
- Zautomatyzuj tworzenie modelu, korzystając z agenta Data Science do wygenerowania modelu klastrowania w Pythonie.
- Generuj osadzanie obrazów domów, aby zasilać narzędzie do wyszukiwania wizualnego, które znajduje podobne domy za pomocą zapytań tekstowych lub obrazowych.
Wymagania wstępne
Zanim zaczniesz ten moduł, musisz:
- znać podstawy programowania w SQL i Pythonie,
- uruchamiać kod Pythona w notatniku Jupyter.
2. Zanim zaczniesz
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt w chmurze Google Cloud.
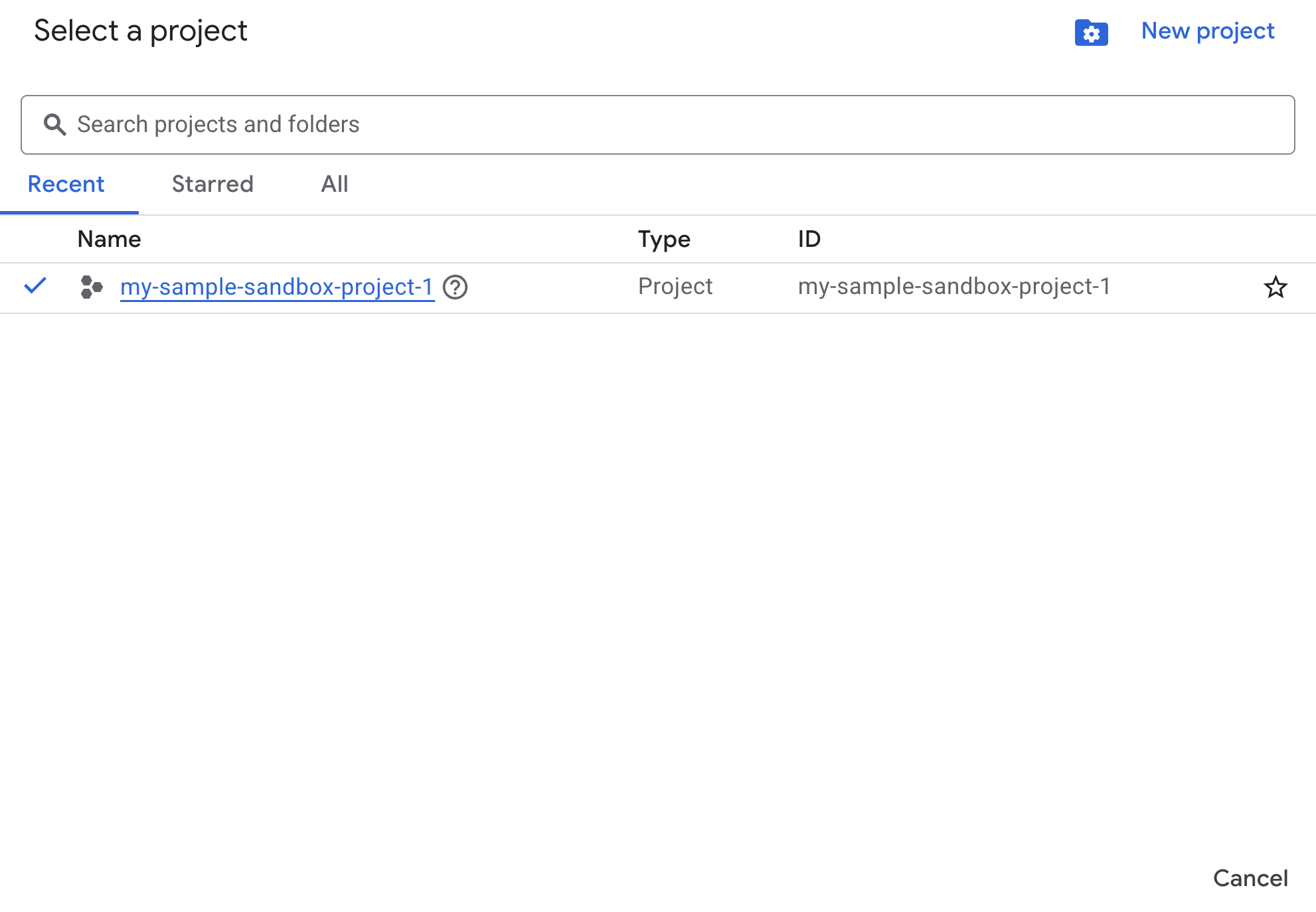
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Włączanie interfejsów API za pomocą Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell:

- Po połączeniu z Cloud Shell uruchom to polecenie, aby sprawdzić uwierzytelnianie w Cloud Shell:
gcloud auth list
- Aby sprawdzić, czy projekt jest skonfigurowany do używania z gcloud, uruchom to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Włącz interfejsy API
- Aby włączyć wszystkie wymagane interfejsy API i usługi, uruchom to polecenie:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
- Zamknij Cloud Shell.
3. Otwieranie notatnika laboratorium w BigQuery Studio
Poruszanie się po interfejsie:
- W konsoli Google Cloud kliknij Menu nawigacyjne > BigQuery.
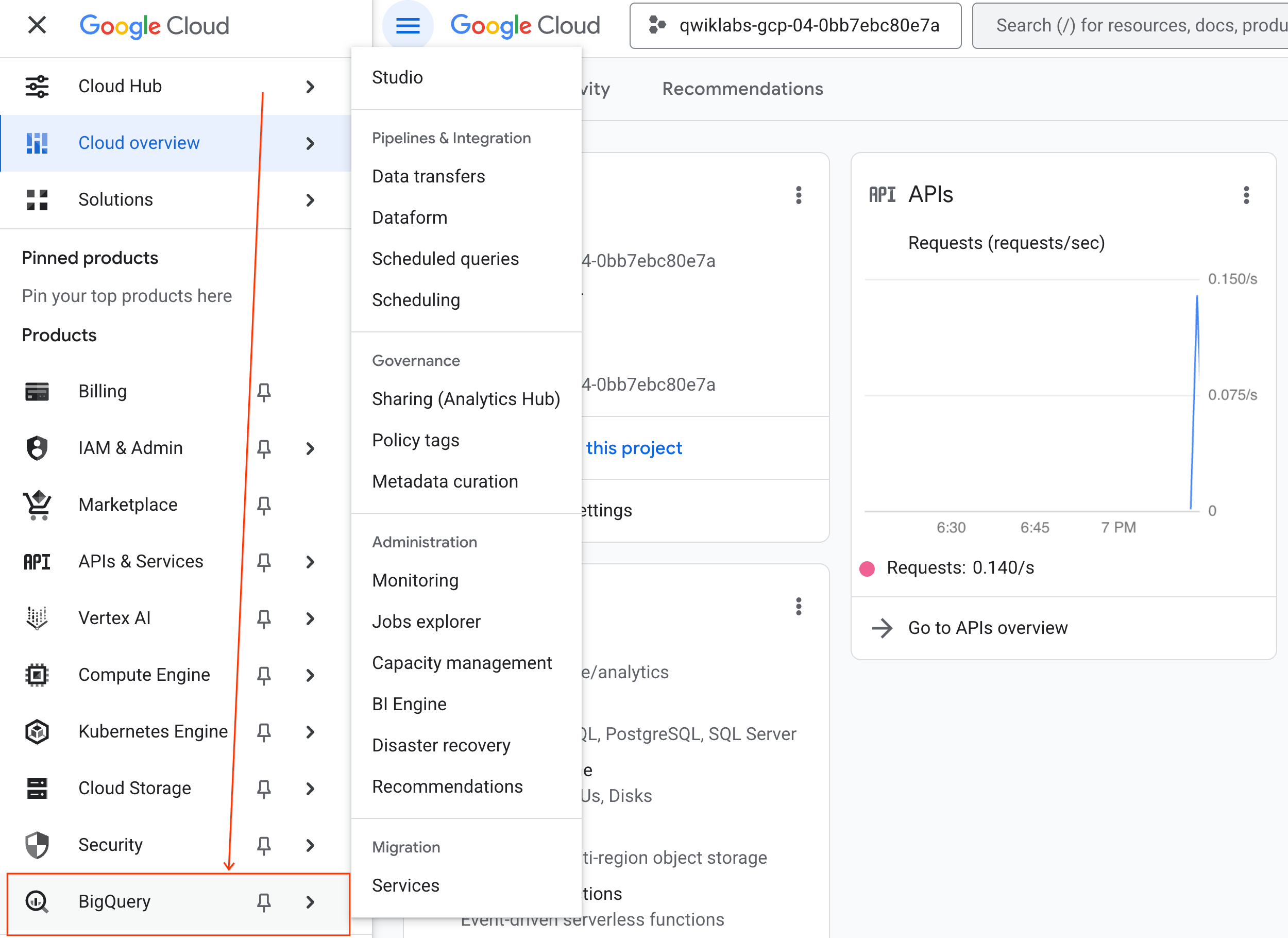
- W panelu BigQuery Studio kliknij przycisk strzałki menu, najedź kursorem na Notatnik, a następnie wybierz Prześlij.
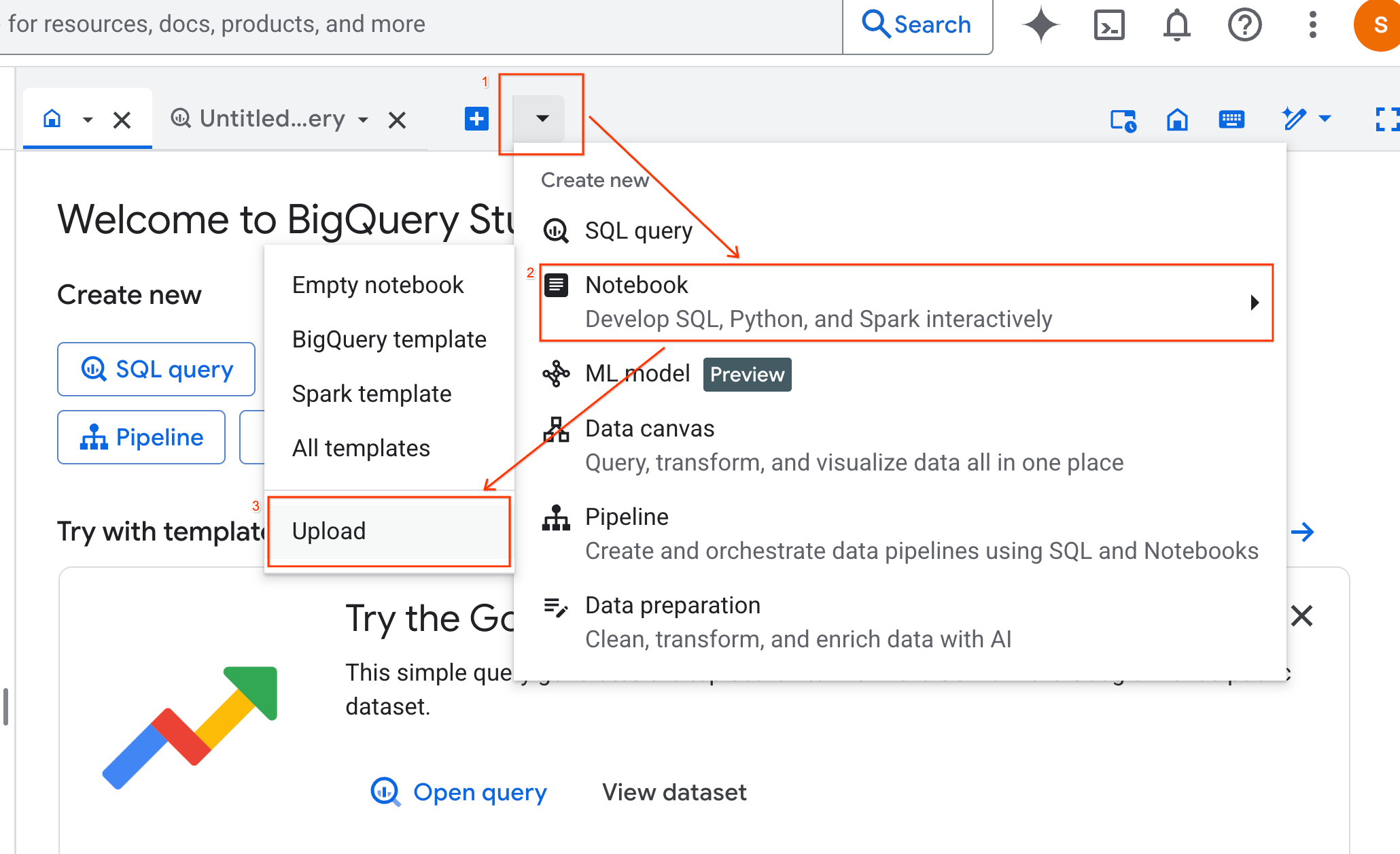
- Zaznacz opcję URL i wpisz ten adres URL:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- Ustaw region na
us-central1i kliknij Prześlij.
- Aby otworzyć notatnik, kliknij strzałkę menu w panelu Eksplorator, który zawiera identyfikator Twojego projektu. Następnie kliknij menu Notatniki. Kliknij notatnik
ai-assisted-data-science.
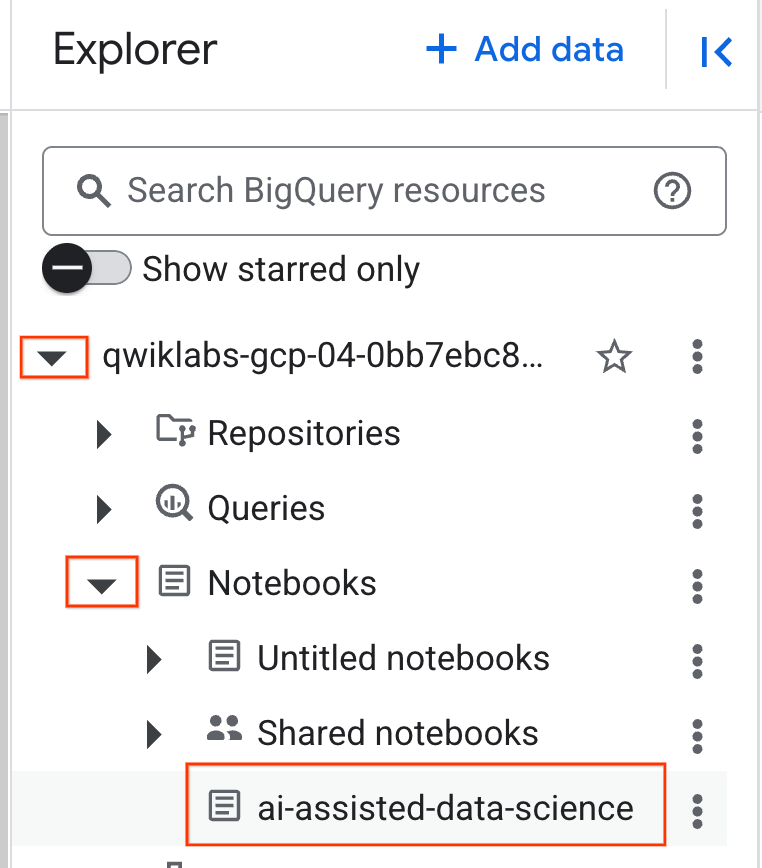
- (Opcjonalnie) Zwiń menu nawigacyjne BigQuery i spis treści notatnika, aby uzyskać więcej miejsca.
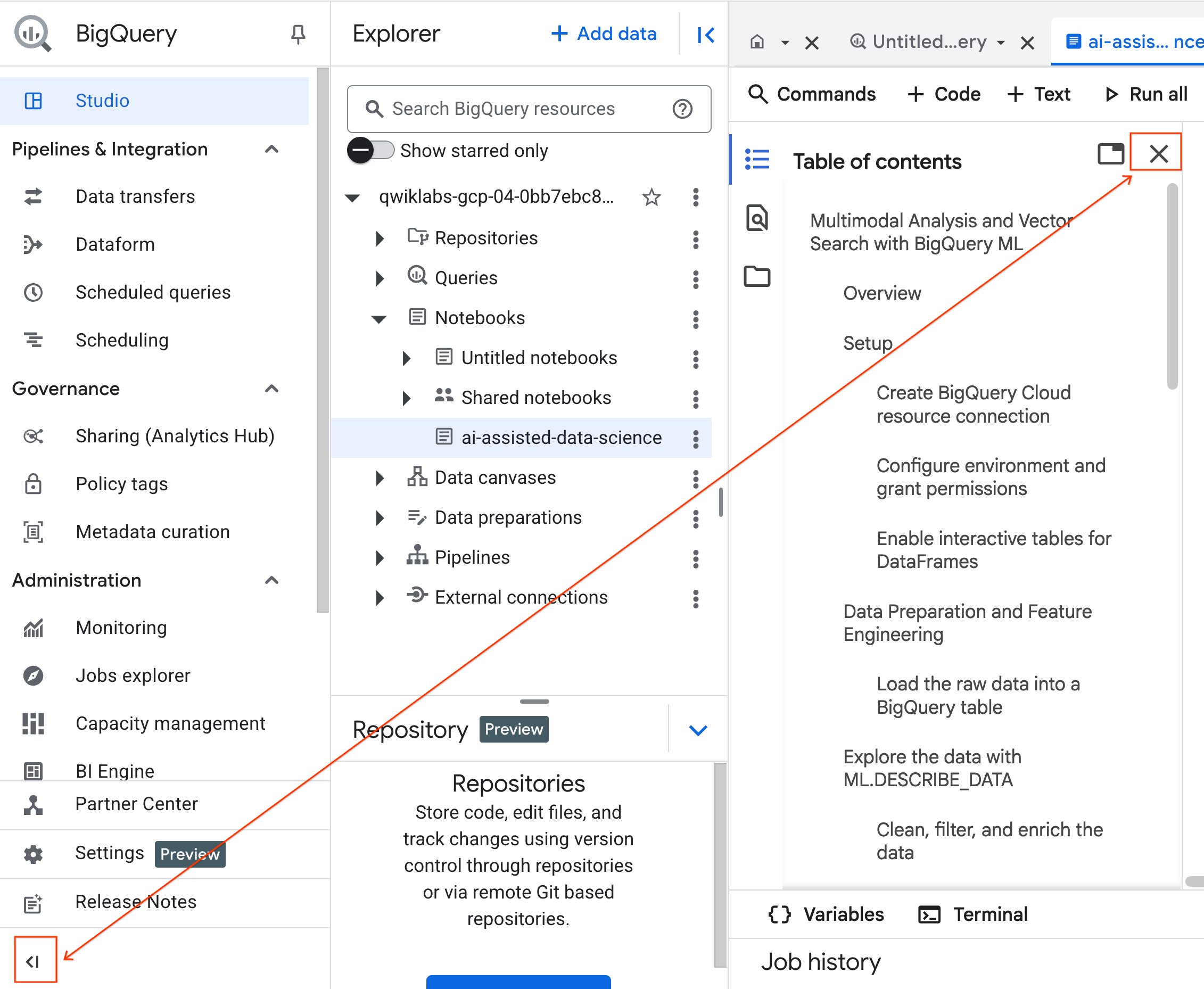
4. Łączenie się ze środowiskiem wykonawczym i uruchamianie kodu konfiguracji
- Kliknij Połącz. Jeśli pojawi się wyskakujące okienko, autoryzuj Colab Enterprise za pomocą swojego użytkownika. Notatnik automatycznie połączy się ze środowiskiem wykonawczym. Może to potrwać kilka minut.
- Gdy czas działania zostanie ustalony, zobaczysz te informacje:
- W notatniku przewiń do sekcji Konfiguracja. Kliknij przycisk „Uruchom” obok ukrytych komórek. Spowoduje to utworzenie w projekcie kilku zasobów niezbędnych do wykonania ćwiczenia. Ten proces może potrwać minutę. W międzyczasie możesz sprawdzić komórki w sekcji Konfiguracja.
5. Przygotowanie danych i inżynieria cech
W tej sekcji wykonasz pierwszy ważny krok w każdym projekcie związanym z nauką o danych: przygotowanie danych. Zacznij od utworzenia zbioru danych BigQuery, aby uporządkować pracę, a następnie wczytaj surowe dane dotyczące nieruchomości i mieszkań z pliku CSV w Cloud Storage do nowej tabeli.
Następnie przekształcisz te nieprzetworzone dane w oczyszczoną tabelę z nowymi funkcjami. Obejmuje to filtrowanie informacji, tworzenie nowej funkcji property_age i przygotowywanie danych obrazu do analizy multimodalnej.
6. Wzbogacanie multimodalne za pomocą funkcji AI
Teraz możesz wzbogacić dane, korzystając z możliwości generatywnej AI. W tej sekcji użyjesz wbudowanych funkcji AI w BigQuery, aby przeanalizować obrazy dla każdej oferty domu.
Połączenie BigQuery z modelem Gemini umożliwia wyodrębnianie nowych, wartościowych cech z obrazów (np. czy nieruchomość znajduje się w pobliżu wody i krótki opis domu) bezpośrednio za pomocą SQL.
7. Trenowanie modelu za pomocą grupowania k-średnich
Dzięki nowemu, wzbogaconemu zbiorowi danych możesz teraz utworzyć model uczenia maszynowego. Chcesz podzielić oferty domów na różne grupy. W tym celu wytrenujesz model grupowania metodą k-średnich bezpośrednio w BigQuery za pomocą uczenia maszynowego w BigQuery (BQML). W ramach tego jednego kroku zarejestrujesz też model w Model Registry na platformie agentów, dzięki czemu będzie on od razu dostępny w szerszym ekosystemie MLOps w Google Cloud.
Aby sprawdzić, czy model został zarejestrowany, możesz go znaleźć w Model Registry platformy Agent Platform. W tym celu wykonaj te czynności:
- W konsoli Google Cloud kliknij Menu nawigacyjne (☰) w lewym górnym rogu.
- Przewiń do sekcji Platforma agentów i kliknij Modele.
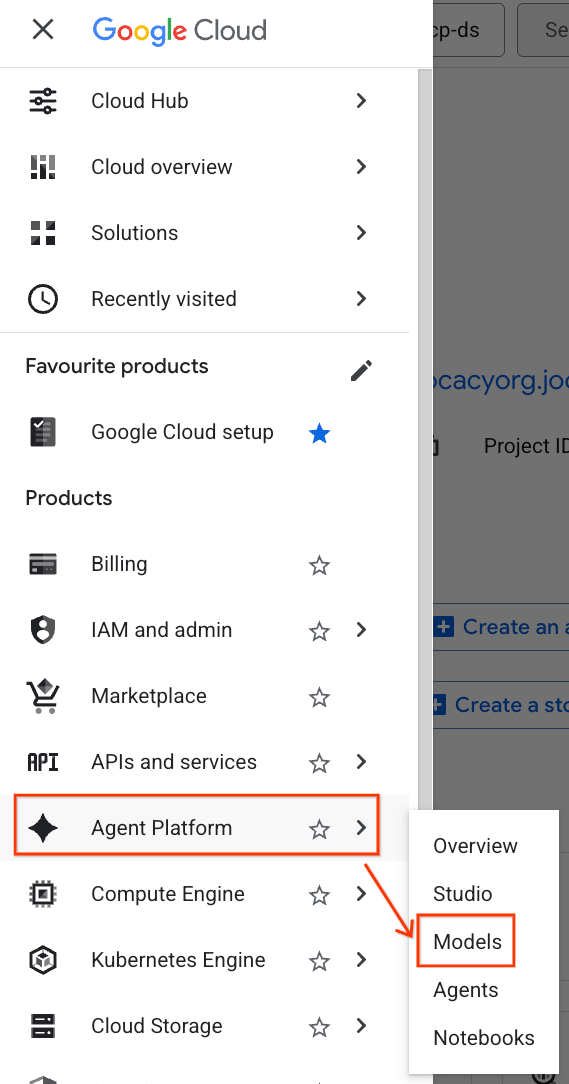
- Kliknij przycisk Model Registry wyróżniony na zrzucie ekranu.
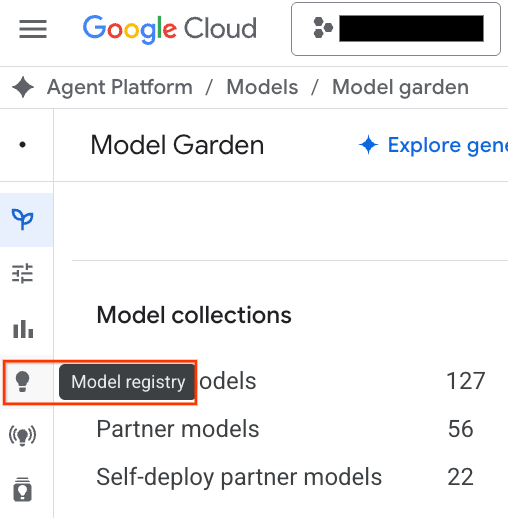
- Model BQML będzie widoczny na liście obok wszystkich innych modeli niestandardowych. Na liście modeli znajdź model o nazwie housing_clustering. Możesz wykonać kolejny krok i wdrożyć model w punkcie końcowym, dzięki czemu będzie on dostępny do prognoz online w czasie rzeczywistym poza środowiskiem BigQuery.
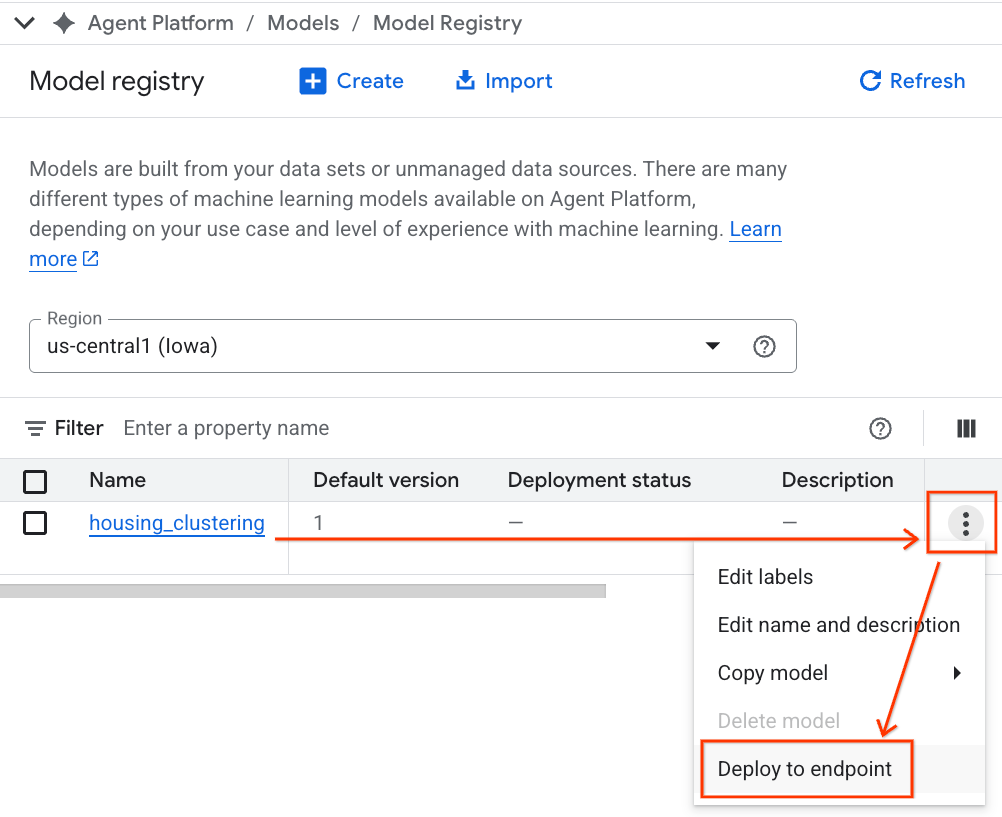
Po zapoznaniu się z rejestrem modeli możesz wrócić do notatnika Colab w BigQuery, wykonując te czynności:
- W Menu nawigacyjnym (☰) otwórz BigQuery > Studio.
- Rozwiń menu w panelu Eksploruj, aby znaleźć i otworzyć notatnik.
8. Ocena i prognozowanie modelu
Po wytrenowaniu modelu kolejnym krokiem jest zrozumienie utworzonych przez niego klastrów. Użyjesz tu funkcji uczenia maszynowego w BigQuery, takich jak ML.EVALUATE i ML.CENTROIDS, aby przeanalizować jakość modelu i określające cechy każdego segmentu.
Następnie użyj funkcji ML.PREDICT, aby przypisać każdy dom do klastra. Uruchamiając to zapytanie za pomocą polecenia magicznego %%bigquery df, zapisujesz wyniki w strukturze DataFrame biblioteki pandas o nazwie df. Dzięki temu dane są od razu dostępne w kolejnych krokach Pythona. Podkreśla to interoperacyjność SQL i Pythona w Colab Enterprise.
9. Wizualizacja i interpretacja klastrów
Po wczytaniu prognoz do ramki danych możesz tworzyć wizualizacje, aby ożywić dane. W tej sekcji użyjesz popularnych bibliotek Pythona, takich jak Matplotlib, aby zbadać różnice między segmentami rynku mieszkaniowego.
Utworzysz wykresy pudełkowe i słupkowe, aby wizualnie porównać kluczowe cechy, takie jak cena i wiek nieruchomości, co ułatwi intuicyjne zrozumienie każdego klastra.
10. Generowanie opisów klastrów za pomocą modeli Gemini
Chociaż centroidy liczbowe i wykresy są przydatne, generatywna AI pozwala pójść o krok dalej i tworzyć bogate, jakościowe profile dla każdego segmentu rynku mieszkaniowego. Dzięki temu dowiesz się nie tylko, czym są klastry, ale też kogo reprezentują.
W tej sekcji najpierw zbierzesz średnie statystyki dla każdego klastra, takie jak cena i powierzchnia. Następnie przekażesz te dane do promptu dla modelu Gemini. Następnie instruujesz model, aby działał jak specjalista ds. nieruchomości i generował szczegółowe podsumowanie, w tym kluczowe cechy i docelowego kupującego dla każdego segmentu. W rezultacie otrzymasz zestaw jasnych, zrozumiałych dla człowieka opisów, dzięki którym zespoły marketingowe będą mogły od razu zrozumieć klastry i podjąć odpowiednie działania.
Możesz dowolnie modyfikować prompt i eksperymentować z wynikami.
11. Automatyzacja modelowania za pomocą agenta Data Science Agent
Teraz poznasz wydajny, alternatywny przepływ pracy. Zamiast ręcznie pisać kod, użyjesz zintegrowanego agenta Data Science, aby automatycznie wygenerować kompletny przepływ pracy modelu grupowania na podstawie jednego promptu w języku naturalnym.
Aby wygenerować i uruchomić model za pomocą agenta:
- W panelu BigQuery Studio kliknij przycisk strzałki menu, najedź kursorem na Notatnik, a następnie wybierz Pusty notatnik. Dzięki temu kod agenta nie będzie kolidować z oryginalnym dziennikiem laboratoryjnym.
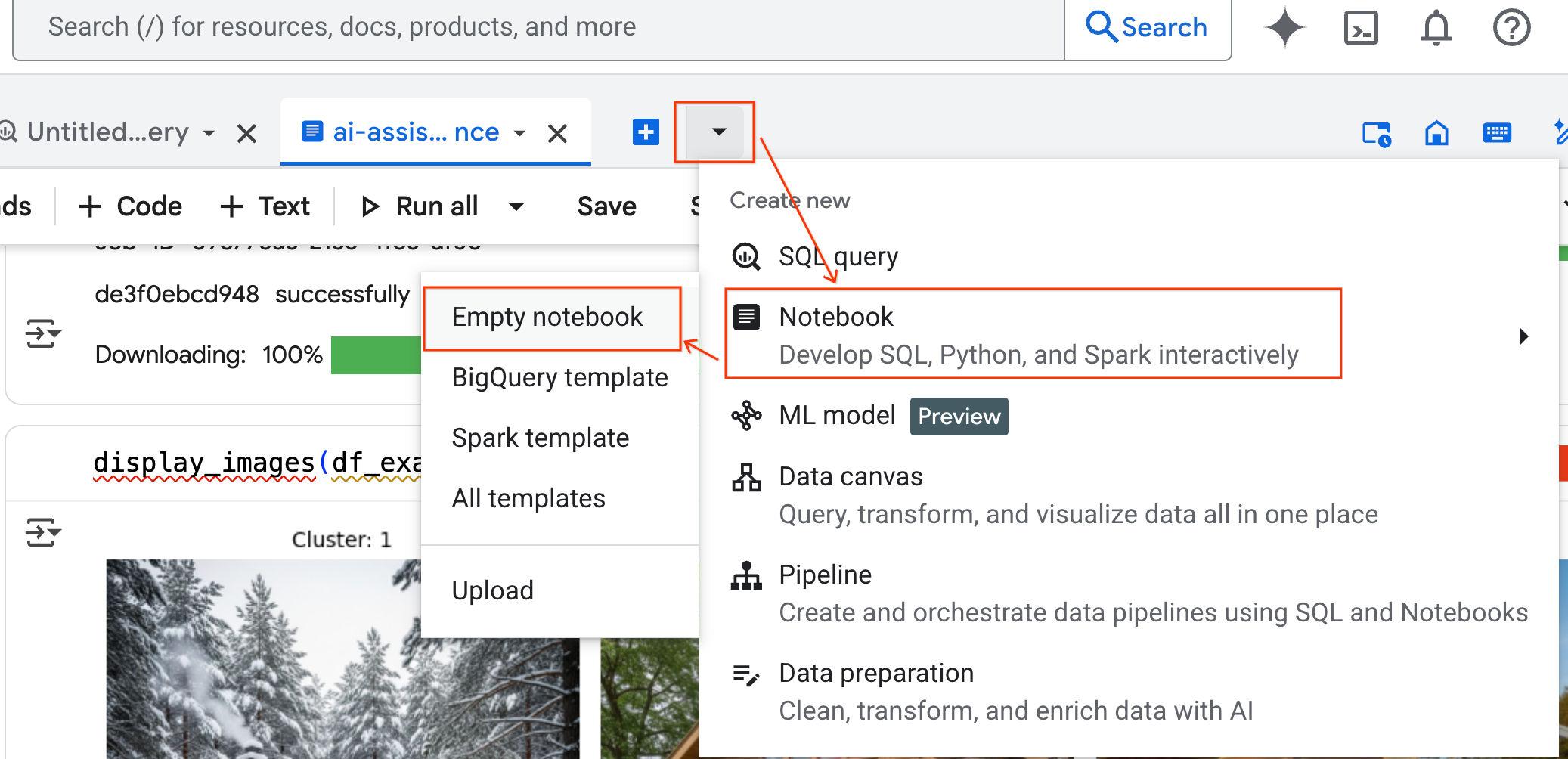
- U dołu notatnika otworzy się interfejs czatu Data Science Agent. Kliknij przycisk Przenieś do panelu, aby przypiąć czat po prawej stronie.
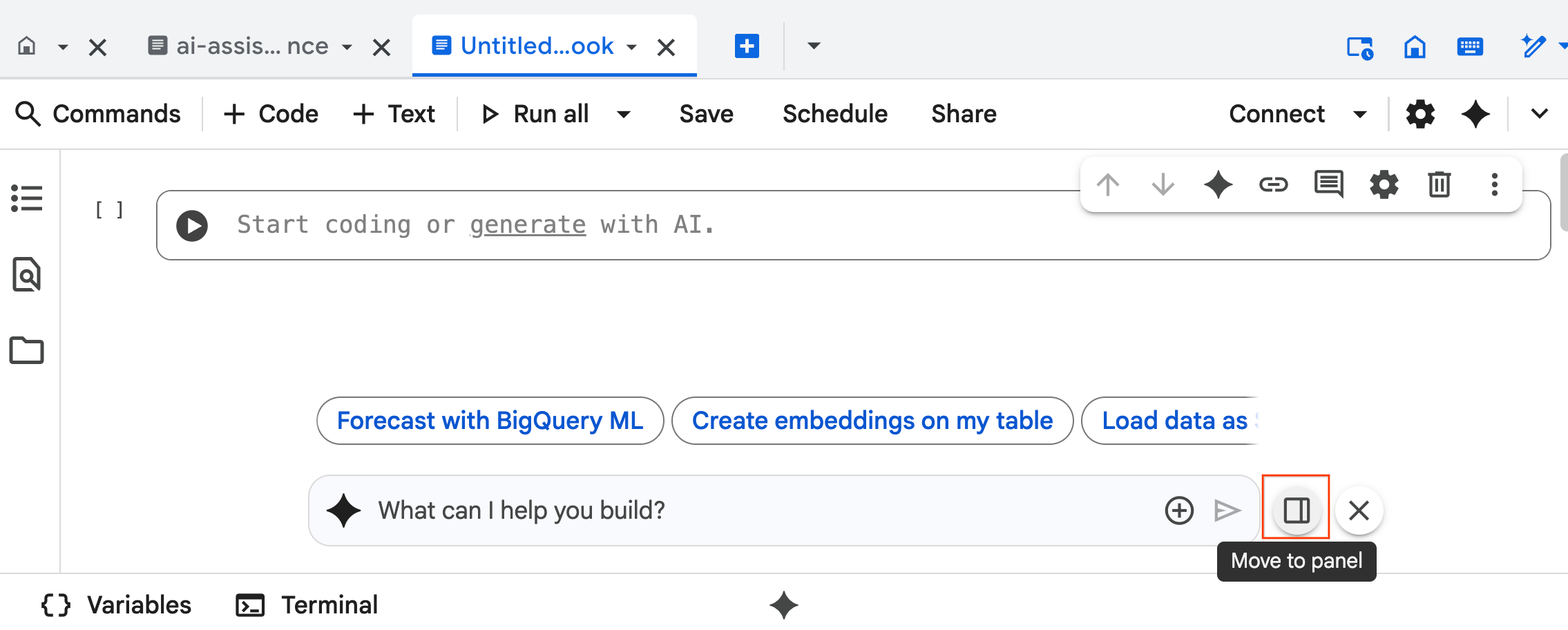
- Zacznij pisać
@listing_multimodalw panelu czatu i kliknij tabelę. Spowoduje to wyraźne ustawienie tabelilistings_multimodaljako kontekstu.
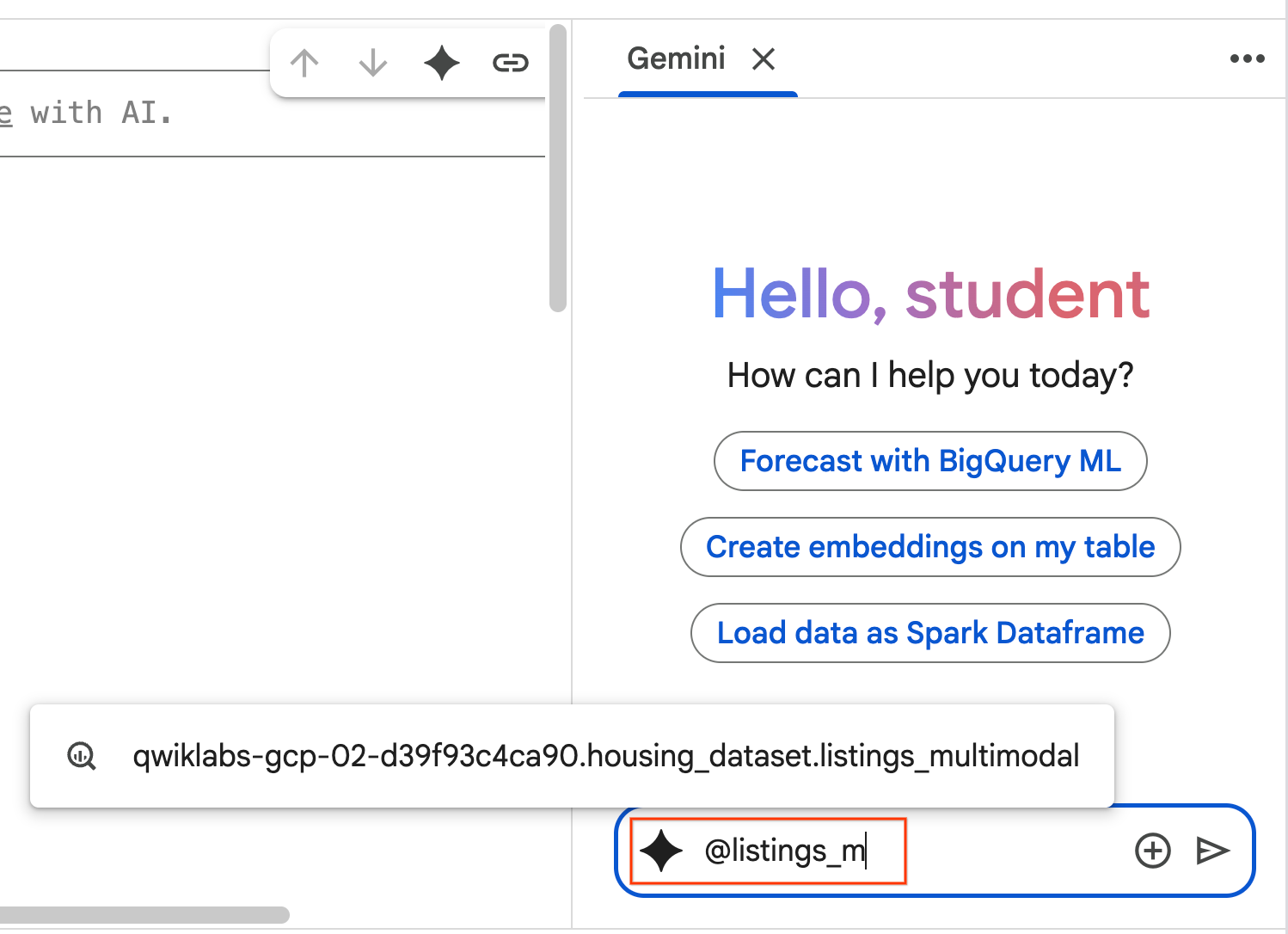
- Skopiuj prompt poniżej i wpisz go w polu czatu z agentem. Następnie kliknij Wyślij, aby przesłać prompta do agenta.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
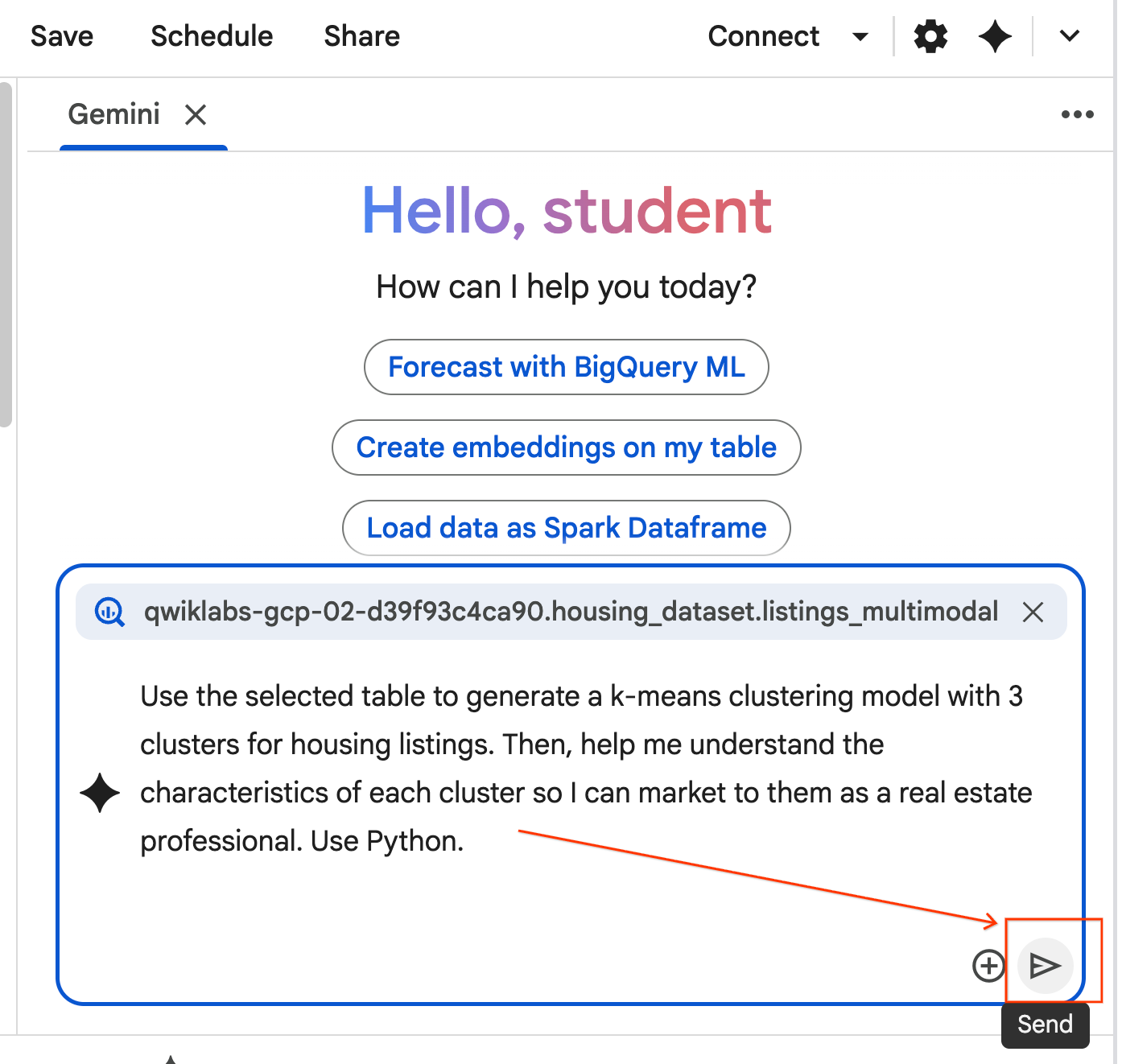
- Agent przemyśli sprawę i opracuje plan. Jeśli ten plan Ci odpowiada, kliknij Zaakceptuj i uruchom. Agent wygeneruje kod Pythona w co najmniej 1 nowej komórce.
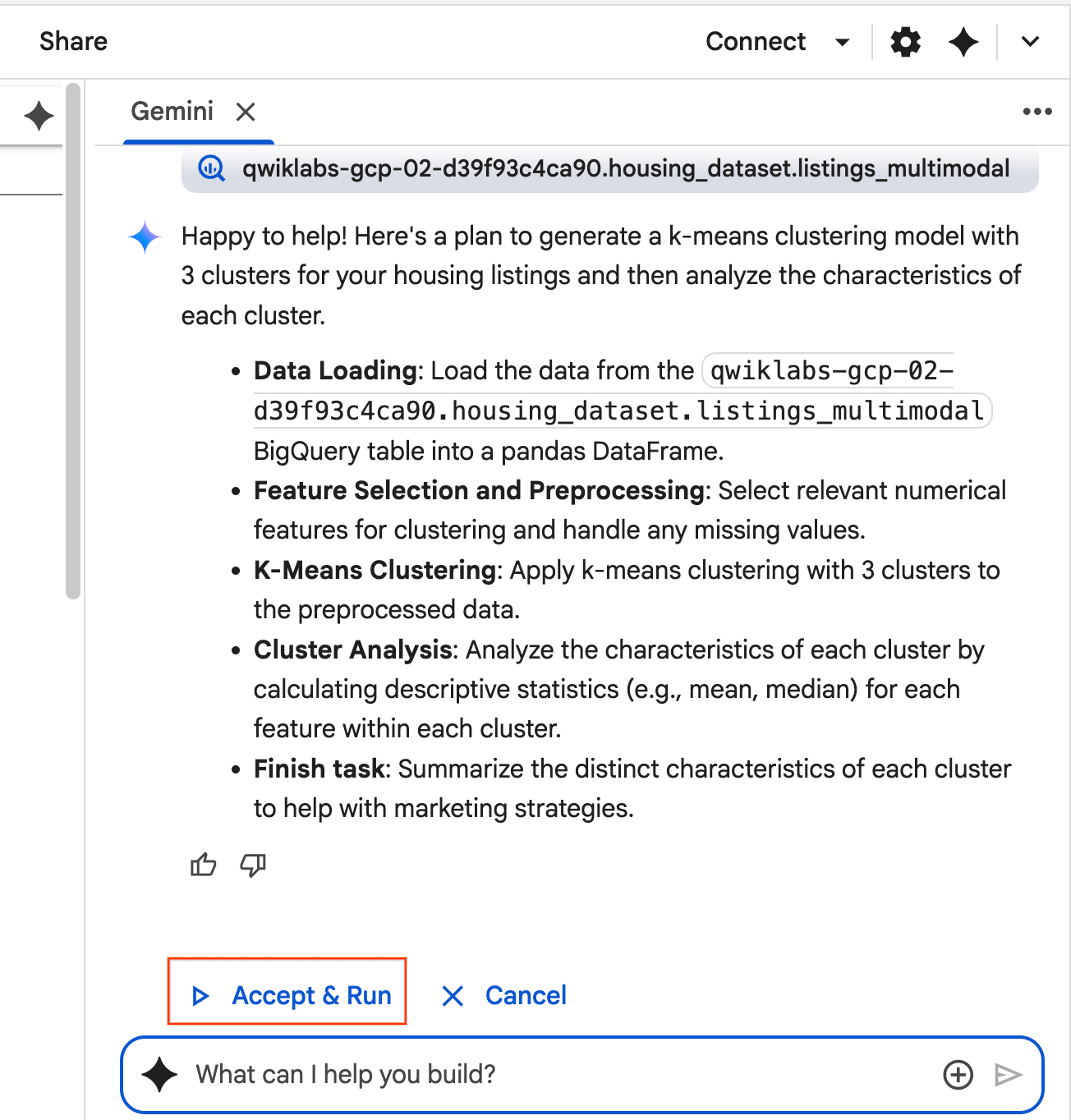
- Agent prosi o zaakceptowanie i uruchomienie każdego wygenerowanego bloku kodu. Dzięki temu w procesie uczestniczy człowiek. Możesz sprawdzić lub edytować kod i wykonywać kolejne kroki, aż skończysz.
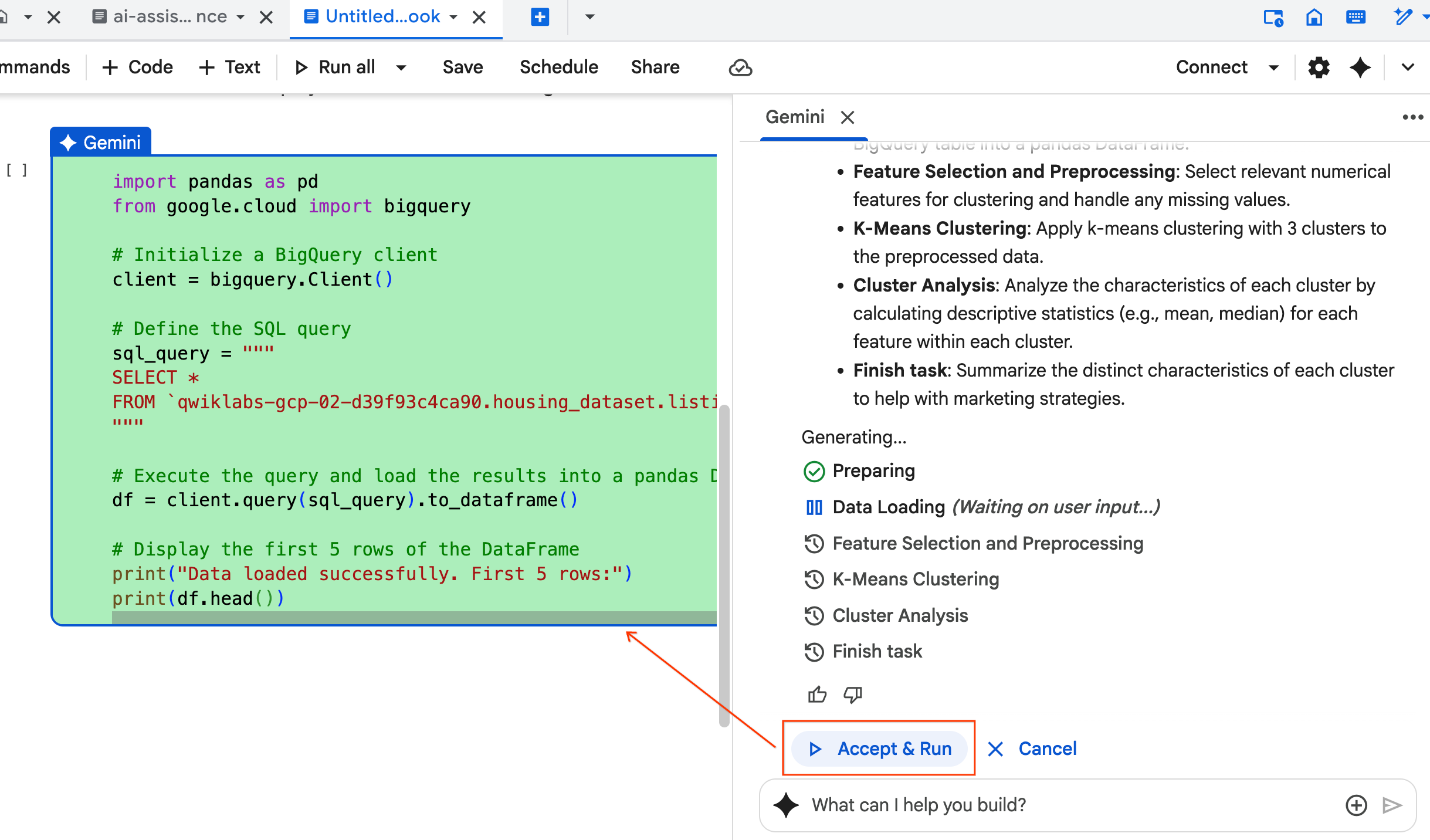
- Gdy skończysz, zamknij nową kartę notatnika i wróć na pierwotną kartę
ai-assisted-data-science.ipynb, aby przejść do ostatniej sekcji modułu.
12. Wyszukiwanie wielomodalne za pomocą wektorów dystrybucyjnych i wyszukiwania wektorowego
W tej ostatniej sekcji zaimplementujesz wyszukiwanie multimodalne bezpośrednio w BigQuery. Umożliwia to intuicyjne wyszukiwanie, np. znajdowanie domów na podstawie opisu tekstowego lub domów podobnych do przykładowego zdjęcia.
Proces ten polega na przekształceniu każdego zdjęcia domu w reprezentację numeryczną zwaną wektorem. Wektor dystrybucyjny zawiera znaczenie semantyczne obrazu, co umożliwia znajdowanie podobnych elementów przez porównywanie ich wektorów liczbowych.
Do wygenerowania tych wektorów dla wszystkich informacji o produktach użyjesz multimodalembedding modelu. Po utworzeniu indeksu wektorowego, który przyspiesza wyszukiwanie, możesz przeprowadzić 2 rodzaje wyszukiwania podobieństw: zamiana tekstu na obraz (znajdowanie domów pasujących do opisu) i obraz do obrazu (znajdowanie domów podobnych do przykładowego obrazu).
Wszystkie te czynności wykonasz w BigQuery, korzystając z funkcji takich jak ML.GENERATE_EMBEDDING do generowania wektorów lub VECTOR_SEARCH do wyszukiwania podobieństw.
13. Czyszczenie
Aby usunąć wszystkie zasoby Google Cloud używane w tym projekcie, możesz usunąć projekt Google Cloud.
Możesz też usunąć poszczególne utworzone zasoby, uruchamiając ten kod w nowej komórce w notatniku:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
Na koniec możesz usunąć sam notatnik:
- W panelu Eksplorator BigQuery Studio rozwiń projekt i węzeł Notatniki.
- Kliknij 3 pionowe kropki obok
ai-assisted-data-sciencenotatnika. - Kliknij Usuń.
14. Gratulacje!
Gratulujemy ukończenia ćwiczeń z programowania.
Omówione zagadnienia
- Przygotuj surowy zbiór danych z ofertami nieruchomości do analizy za pomocą inżynierii cech.
- Wzbogacaj informacje, korzystając z funkcji AI w BigQuery do analizowania zdjęć domów pod kątem kluczowych cech wizualnych.
- Twórz i oceniaj model algorytmu centroidów za pomocą uczenia maszynowego w BigQuery (BQML), aby dzielić usługi na odrębne klastry.
- Zautomatyzuj tworzenie modelu, korzystając z agenta Data Science do wygenerowania modelu klastrowania w Pythonie.
- Generuj osadzanie obrazów domów, aby zasilać narzędzie do wyszukiwania wizualnego, które znajduje podobne domy za pomocą zapytań tekstowych lub obrazowych.