
1. Introdução
Visão geral
Neste laboratório, você vai conhecer um fluxo de trabalho de ciência de dados multimodal no BigQuery, com foco em um cenário imobiliário. Você vai começar com um conjunto de dados brutos de anúncios de casas e imagens, enriquecer esses dados com IA para extrair recursos visuais, criar um modelo de clusterização para descobrir segmentos de mercado distintos e, por fim, criar uma ferramenta de pesquisa visual eficiente usando embeddings de vetores.
Você vai comparar esse fluxo de trabalho nativo do SQL com uma abordagem moderna de IA generativa usando o Agente de Ciência de Dados para gerar automaticamente um modelo de clusterização baseado em Python com um comando de texto simples.
O que você vai aprender
- Prepare um conjunto de dados brutos de anúncios de imóveis para análise usando a engenharia de atributos.
- Enriqueça as páginas de detalhes usando as funções de IA do BigQuery para analisar fotos de casas e identificar recursos visuais importantes.
- Crie e avalie um modelo k-means com o BigQuery Machine Learning (BQML) para segmentar propriedades em clusters distintos.
- Automatize a criação de modelos usando o Agente de ciência de dados para gerar um modelo de clustering com Python.
- Gere embeddings de imagens de casas para usar uma ferramenta de pesquisa visual e encontrar imóveis semelhantes com consultas de texto ou imagem.
Pré-requisitos
Antes de fazer este laboratório, você precisa saber os seguintes conceitos:
- Noções básicas de programação em SQL e Python.
- Execução de códigos Python em um notebook do Jupyter.
2. Antes de começar
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Ativar APIs com o Cloud Shell
O Cloud Shell é um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com as ferramentas necessárias.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud:

- Depois de se conectar ao Cloud Shell, execute este comando para verificar sua autenticação:
gcloud auth list
- Execute o comando a seguir para confirmar se o projeto está configurado para uso com a gcloud:
gcloud config list project
- Se o projeto não estiver definido, use este comando:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Ativar APIs
- Execute este comando para ativar todas as APIs e serviços necessários:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- Após a execução do comando, você vai ver uma mensagem semelhante à mostrada abaixo:
Operation "operations/..." finished successfully.
- Saia do Cloud Shell.
3. Abrir o notebook do laboratório no BigQuery Studio
Navegação na interface:
- No console do Google Cloud, acesse Menu de navegação > BigQuery.
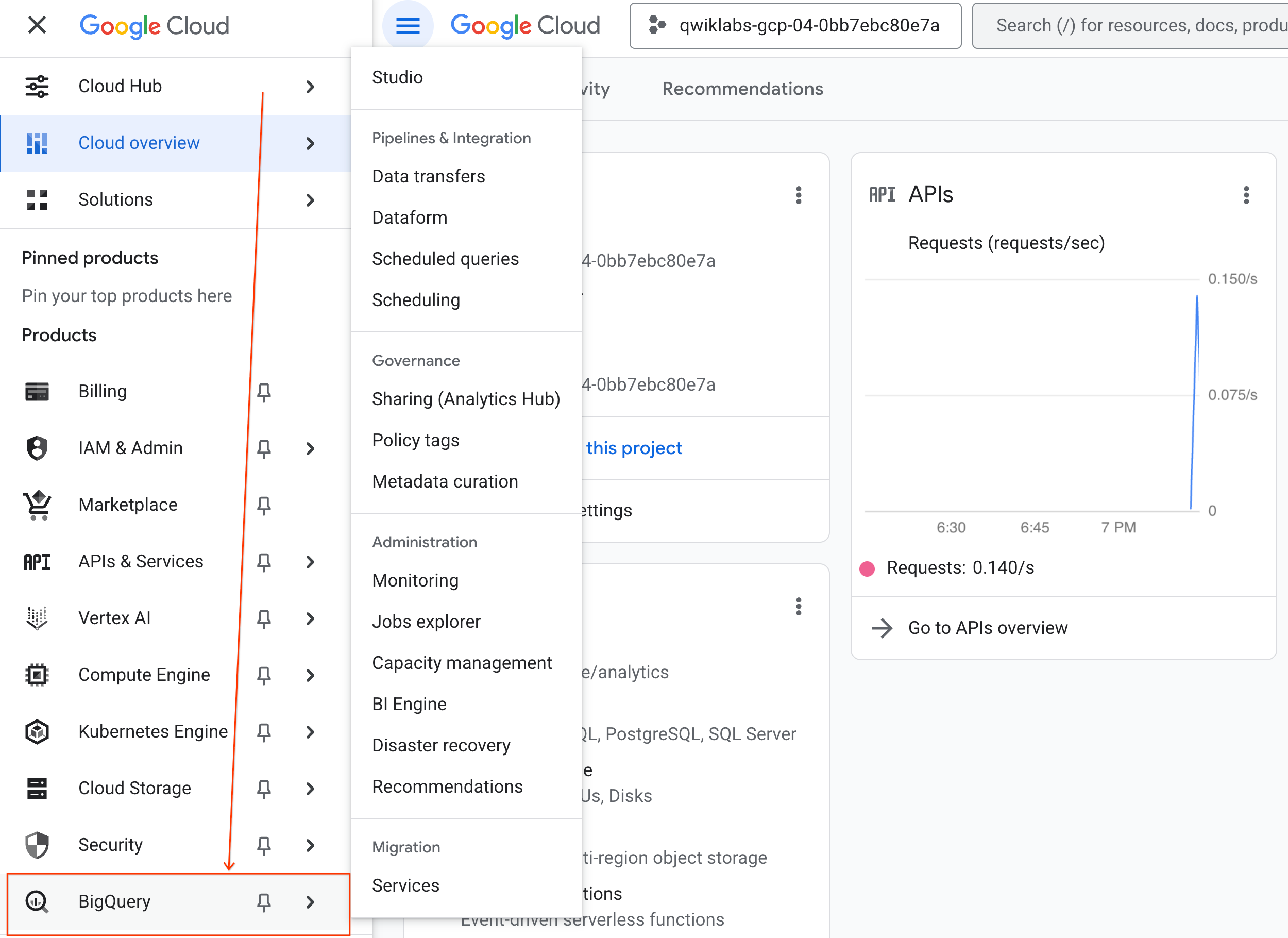
- No painel BigQuery Studio, clique no botão de seta do menu suspenso, passe o cursor sobre Notebook e selecione Fazer upload.
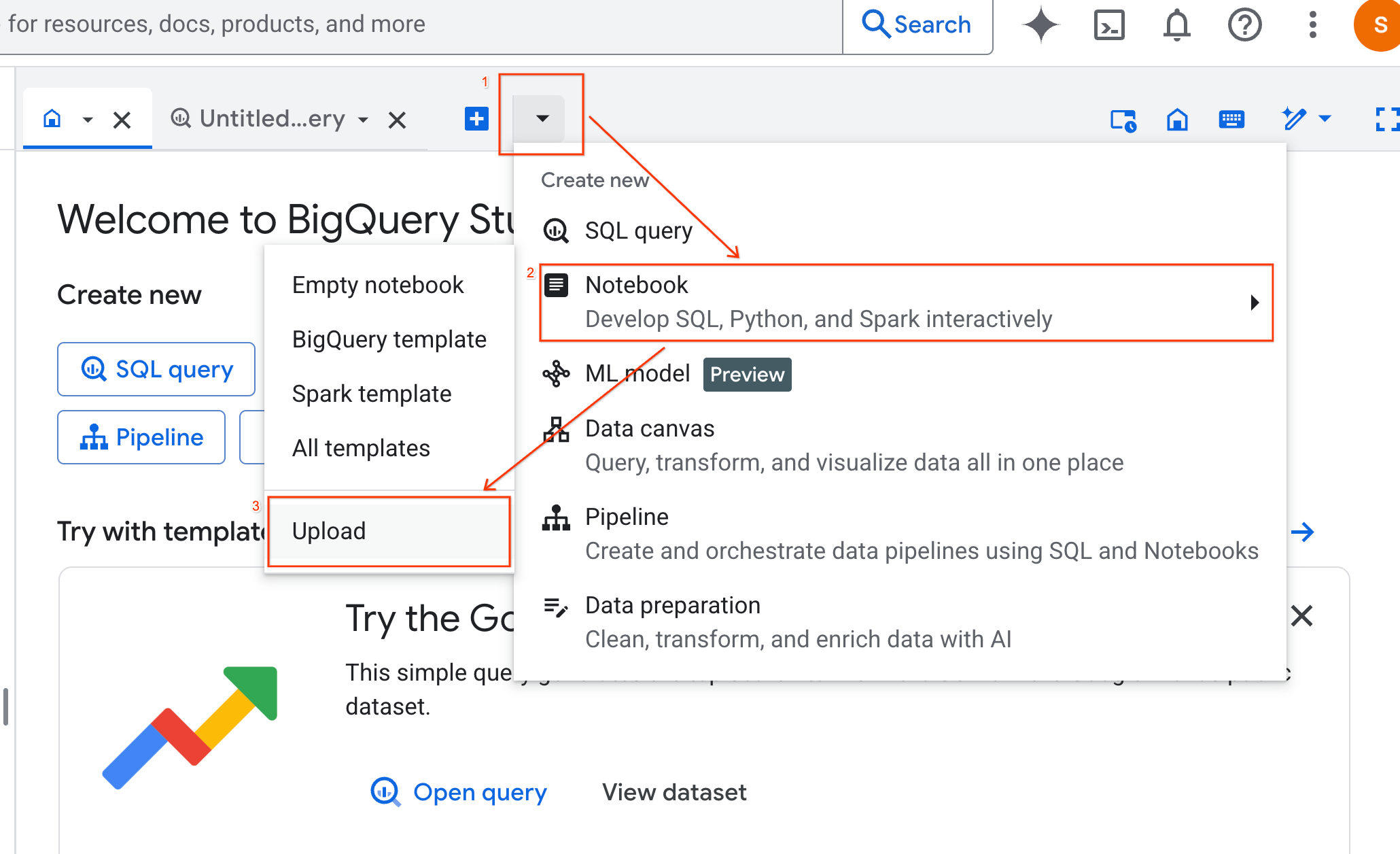
- Selecione o botão de opção URL e insira o seguinte URL:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- Defina a região como
us-central1e clique em Fazer upload.
- Para abrir o notebook, clique na seta suspensa no painel Explorador que contém o ID do projeto. Em seguida, clique no menu suspenso Notebooks. Clique no notebook
ai-assisted-data-science.
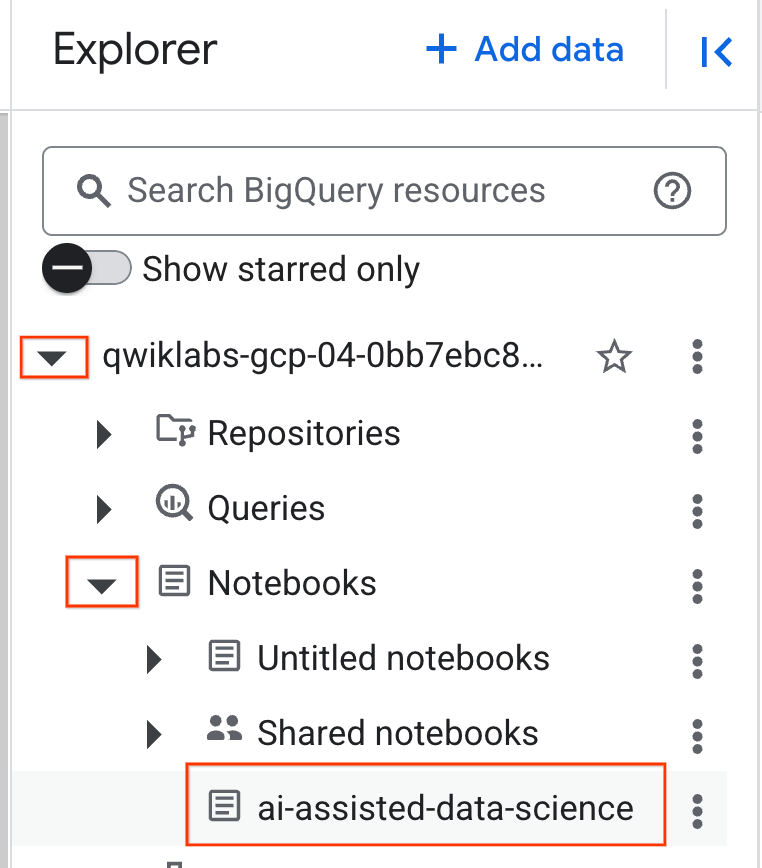
- (Opcional) Recolha o menu de navegação do BigQuery e o Sumário do notebook para ter mais espaço.
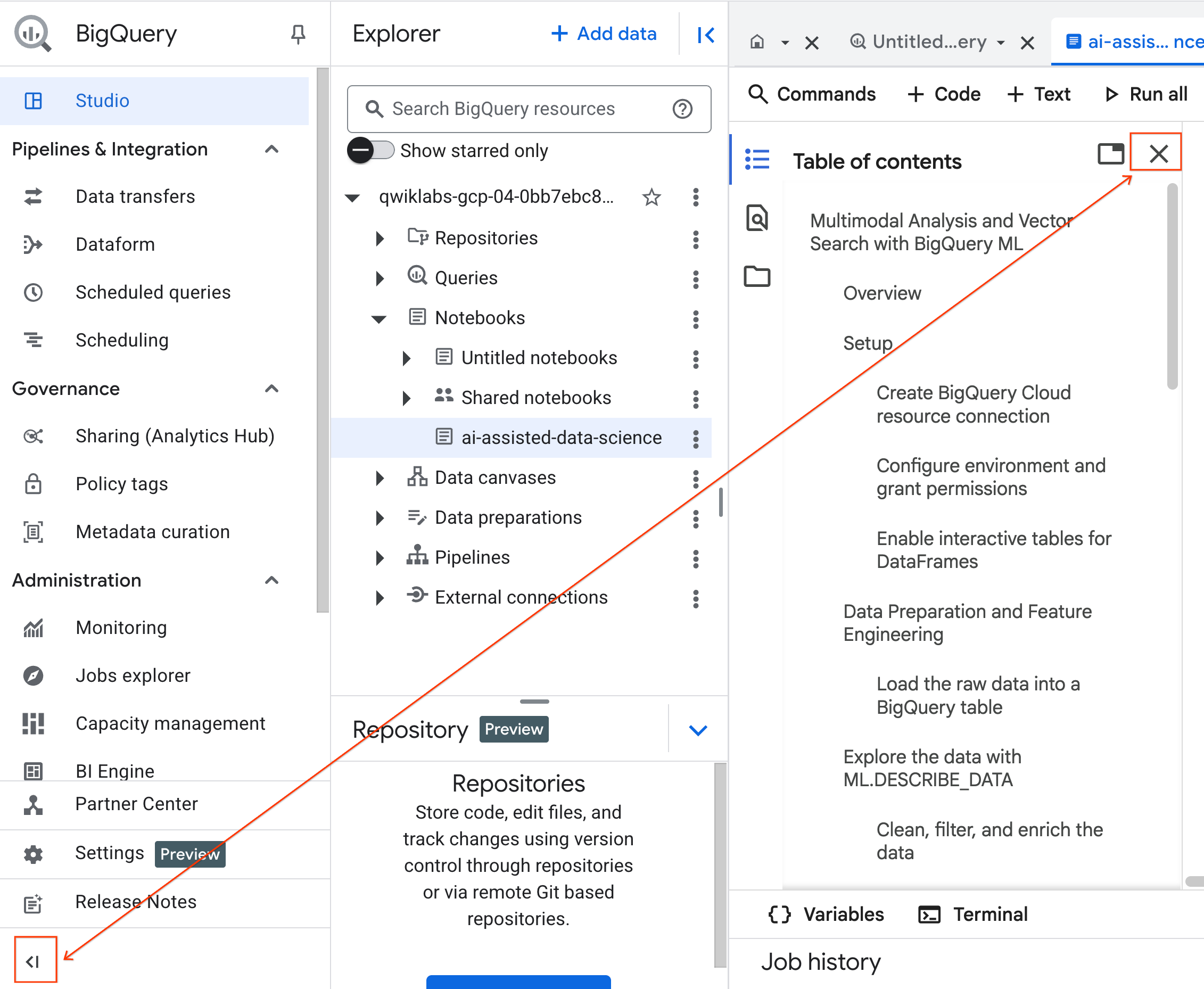
4. Conectar-se a um ambiente de execução e executar o código de configuração
- Clique em Conectar. Se um pop-up aparecer, autorize o Colab Enterprise com seu usuário. Seu notebook vai se conectar automaticamente a um ambiente de execução. Esse processo pode levar alguns minutos.
- Depois que o ambiente de execução for estabelecido, você verá o seguinte:
- No notebook, role até a seção Configuração. Clique no botão "Executar" ao lado das células ocultas. Isso cria alguns recursos necessários para o laboratório no seu projeto. Esse processo pode levar um minuto para ser concluído. Enquanto isso, confira as células em Configuração.
5. Preparação de dados e engenharia de atributos
Nesta seção, você vai passar pela primeira etapa importante de qualquer projeto de ciência de dados: a preparação dos dados. Comece criando um conjunto de dados do BigQuery para organizar seu trabalho e carregue os dados brutos de imóveis / moradias de um arquivo CSV no Cloud Storage em uma nova tabela.
Em seguida, você vai transformar esses dados brutos em uma tabela limpa com novos recursos. Isso envolve filtrar as informações do produto, criar um novo recurso property_age e preparar os dados de imagem para análise multimodal.
6. Enriquecimento multimodal com funções de IA
Agora você vai enriquecer seus dados usando o poder da IA generativa. Nesta seção, você vai usar as funções de IA integradas do BigQuery para analisar as imagens de cada anúncio de casa.
Ao conectar o BigQuery a um modelo do Gemini, você extrai recursos novos e valiosos de imagens (como se uma propriedade está perto da água e uma breve descrição da casa) diretamente com SQL.
7. Treinamento de modelos com clustering k-means
Com o conjunto de dados enriquecido, você já pode criar um modelo de machine learning. Seu objetivo é segmentar os anúncios de imóveis em grupos distintos. Para isso, treine um modelo de agrupamento K-means diretamente no BigQuery usando o BigQuery Machine Learning (BQML). Como parte dessa única etapa, você também registra o modelo no Agent Platform AI Model Registry, disponibilizando-o instantaneamente no ecossistema mais amplo de MLOps no Google Cloud.
Para confirmar se o modelo foi registrado com sucesso, você pode encontrá-lo no Model Registry da Plataforma do Agente seguindo estas etapas:
- No console do Google Cloud, clique no menu de navegação (☰) no canto superior esquerdo.
- Role a tela até a seção Plataforma do agente e clique em Modelos.
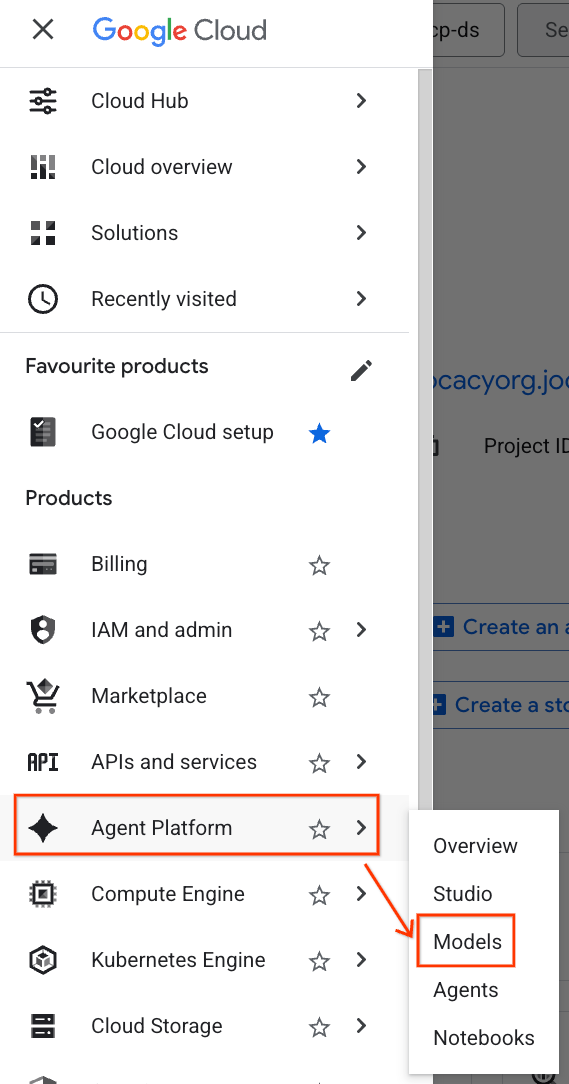
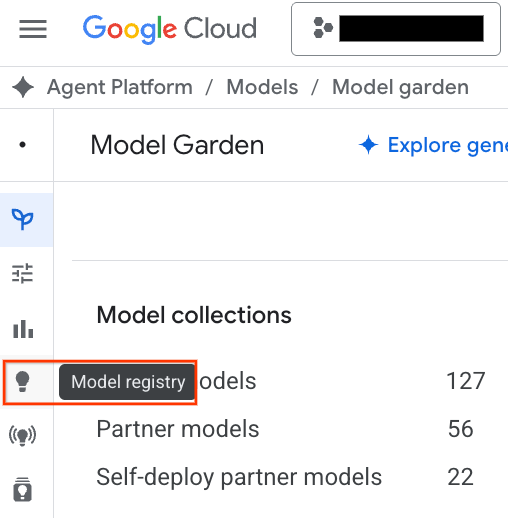
- Clique no botão Model Registry destacado na captura de tela.
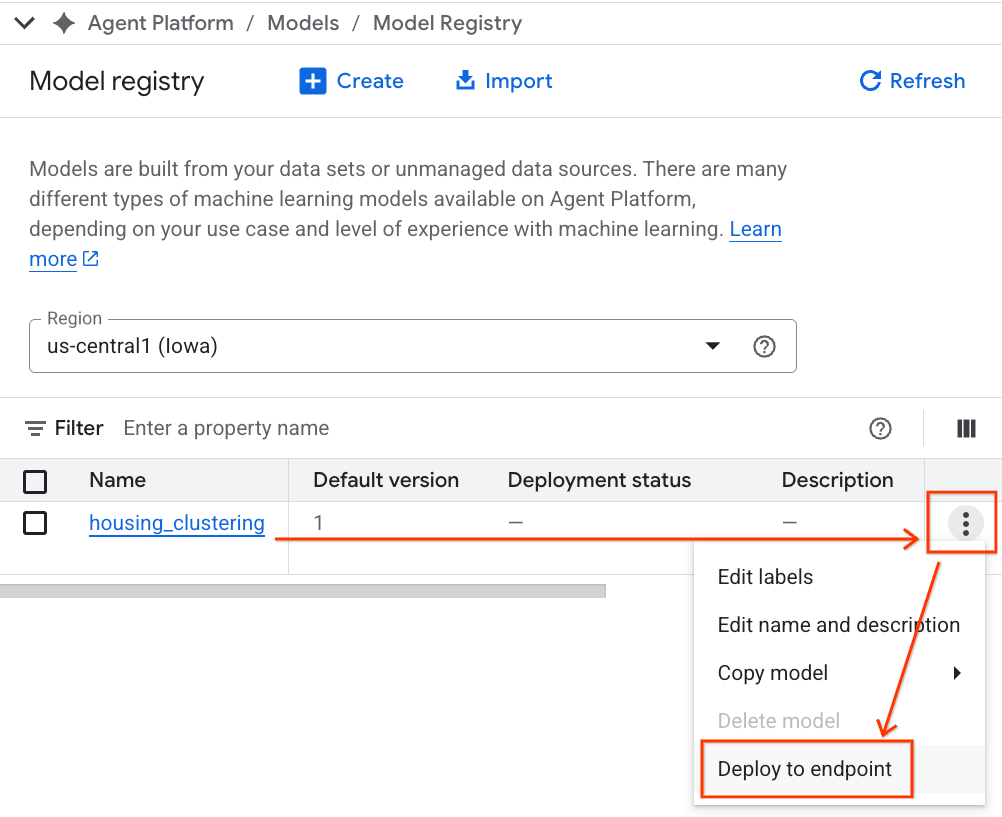
- Seu modelo do BQML vai aparecer listado com todos os outros modelos personalizados. Na lista de modelos, encontre o modelo chamado housing_clustering. Você pode dar o próximo passo e implantar em um endpoint, o que disponibilizaria seu modelo para previsões on-line em tempo real fora do ambiente do BigQuery.
Depois de explorar o Model Registry, siga estas etapas para voltar ao notebook do Colab no BigQuery:
- No Menu de navegação (☰), acesse BigQuery > Studio.
- Abra os menus no painel Análise para encontrar e abrir seu notebook.
8. Avaliação e previsão de modelos
Depois de treinar o modelo, a próxima etapa é entender os clusters criados. Aqui, você usa funções do BigQuery Machine Learning, como ML.EVALUATE e ML.CENTROIDS, para analisar a qualidade do modelo e as características definidoras de cada segmento.
Em seguida, use ML.PREDICT para atribuir cada casa a um cluster. Ao executar essa consulta com o comando mágico %%bigquery df, você armazena os resultados em um DataFrame do Pandas chamado df. Isso disponibiliza os dados imediatamente para as próximas etapas do Python. Isso destaca a interoperabilidade entre SQL e Python no Colab Enterprise.
9. Visualizar e interpretar clusters
Com as previsões carregadas em um DataFrame, você pode criar visualizações para dar vida aos dados. Nesta seção, você vai usar bibliotecas Python conhecidas, como Matplotlib, para analisar as diferenças entre os segmentos de imóveis.
Você vai criar boxplots e gráficos de barras para comparar visualmente recursos importantes, como preço e idade do imóvel, facilitando a criação de uma compreensão intuitiva de cada cluster.
10. Gerar descrições de cluster com modelos do Gemini
Embora os centroides numéricos e os gráficos sejam úteis, a IA generativa permite ir além e criar personas ricas e qualitativas para cada segmento de moradia. Isso ajuda você a entender não apenas o que são os clusters, mas quem eles representam.
Nesta seção, você vai agregar as estatísticas médias de cada cluster, como preço e metragem quadrada. Em seguida, você vai transmitir esses dados para um comando do modelo do Gemini. Em seguida, instrua o modelo a agir como um profissional do setor imobiliário e gerar um resumo detalhado, incluindo as principais características e um comprador-alvo para cada segmento. O resultado é um conjunto de descrições claras e legíveis que tornam os clusters imediatamente compreensíveis e úteis para uma equipe de marketing.
Altere o comando como quiser e teste os resultados.
11. Automatizar a modelagem com o agente de ciência de dados
Agora, você vai conhecer um fluxo de trabalho alternativo e eficiente. Em vez de escrever código manualmente, você vai usar o Agente de ciência de dados integrado para gerar automaticamente um fluxo de trabalho completo de modelo de clusterização com base em um único comando de linguagem natural.
Siga estas etapas para gerar e executar o modelo usando o agente:
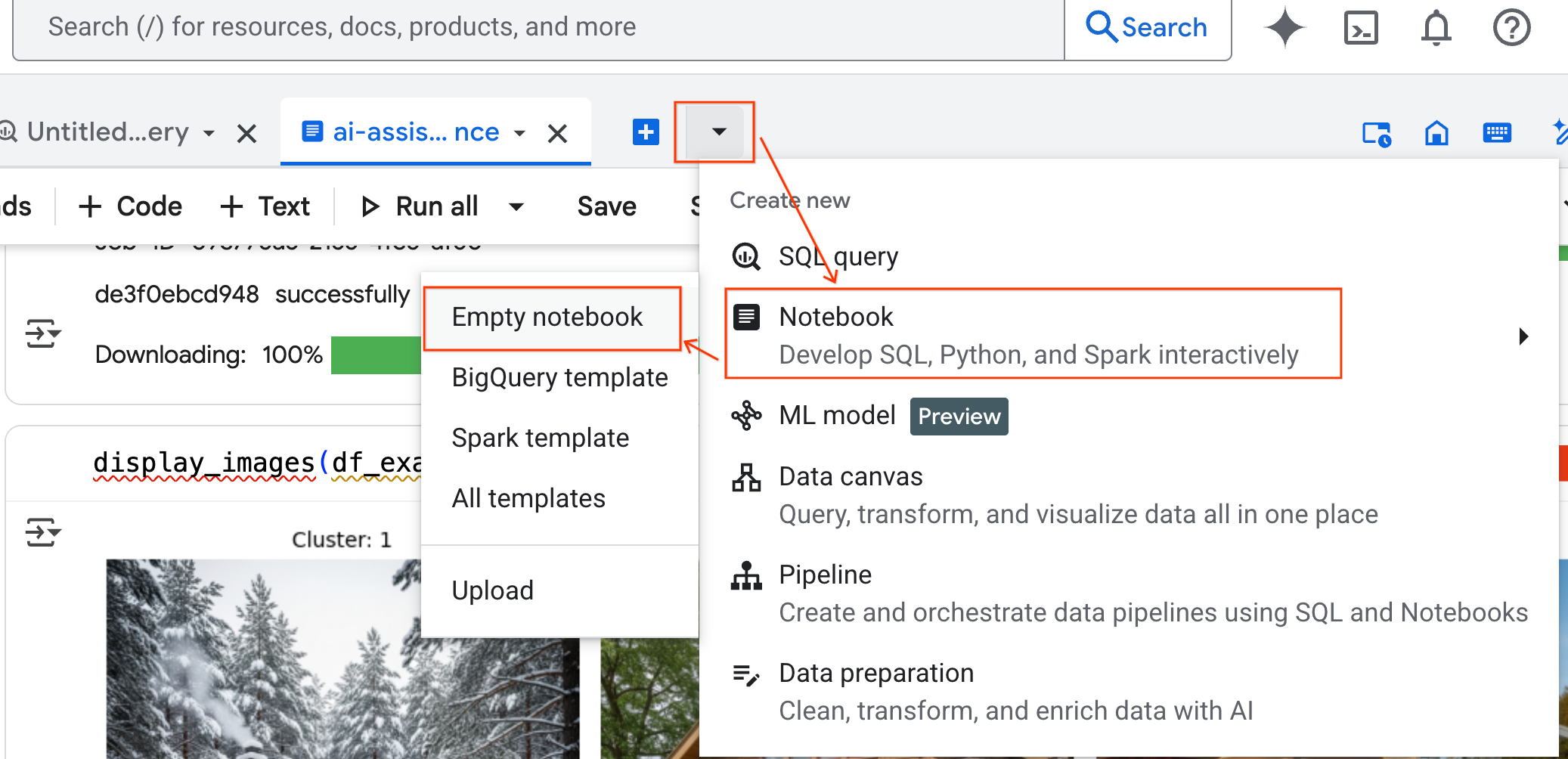
- No painel BigQuery Studio, clique no botão de seta do menu suspenso, passe o cursor sobre Notebook e selecione Notebook vazio. Isso garante que o código do agente não interfira no seu notebook de laboratório original.
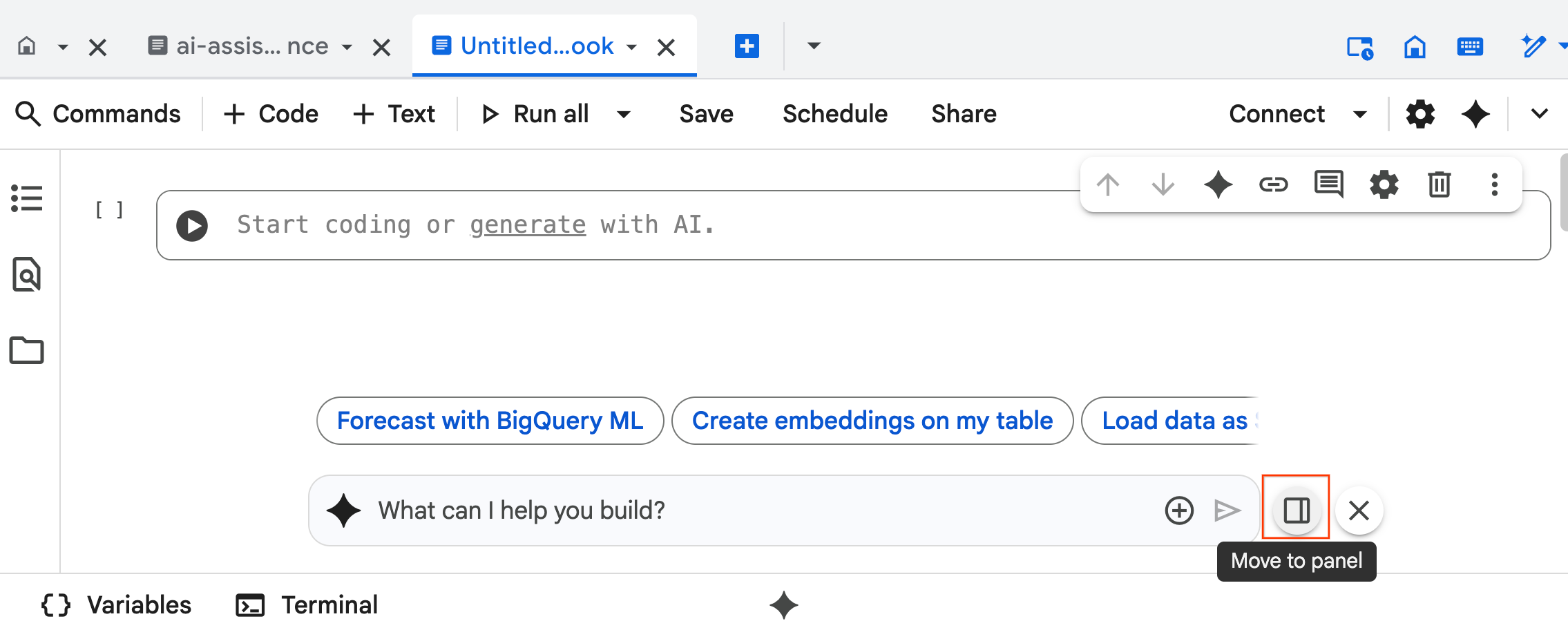
- A interface de chat do Agente de Ciência de Dados é aberta na parte de baixo do notebook. Clique no botão Mover para o painel para fixar o chat no lado direito.
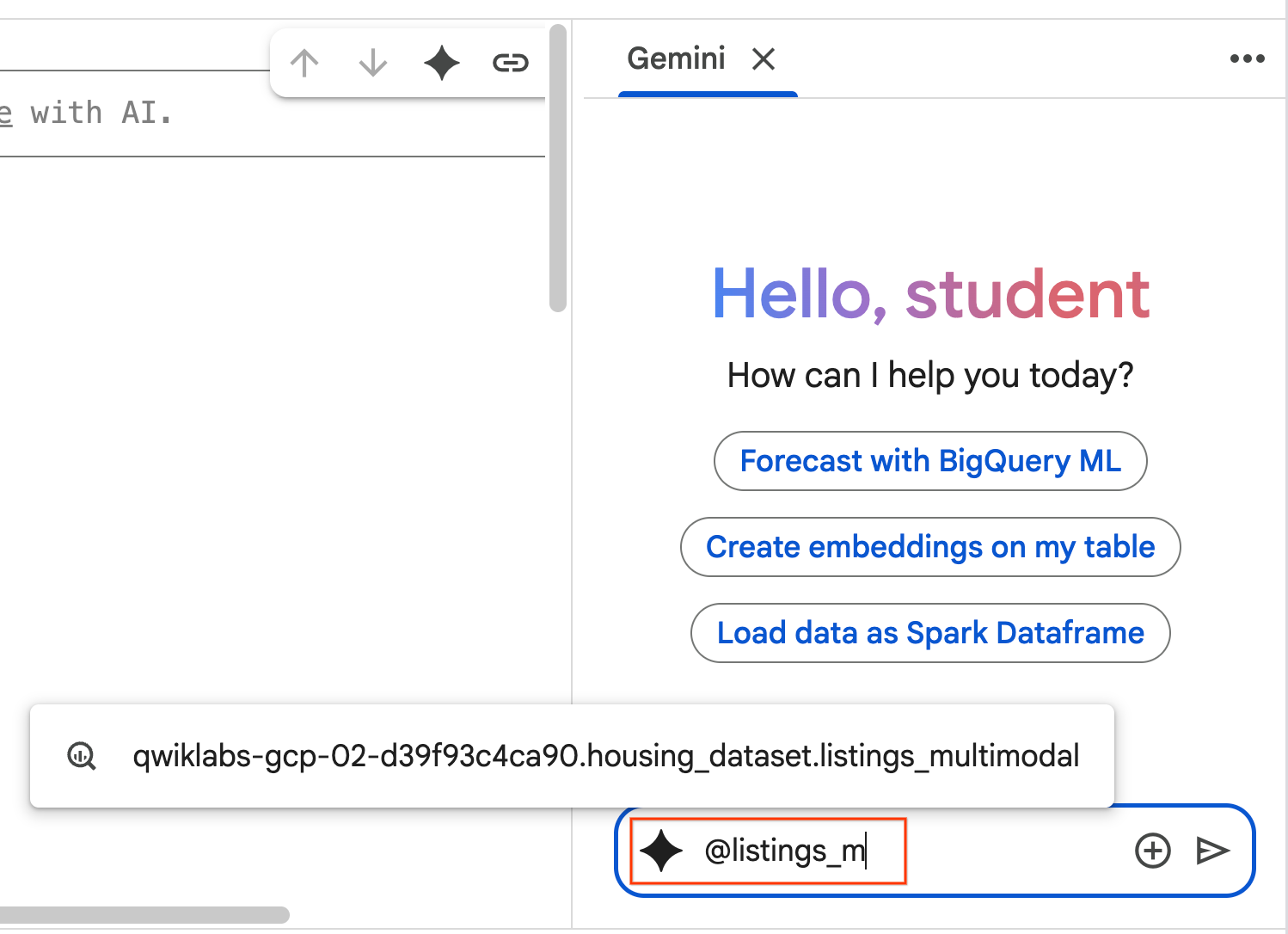
- Comece a digitar
@listing_multimodalno painel de chat e clique na tabela. Isso define explicitamente a tabelalistings_multimodalcomo contexto.
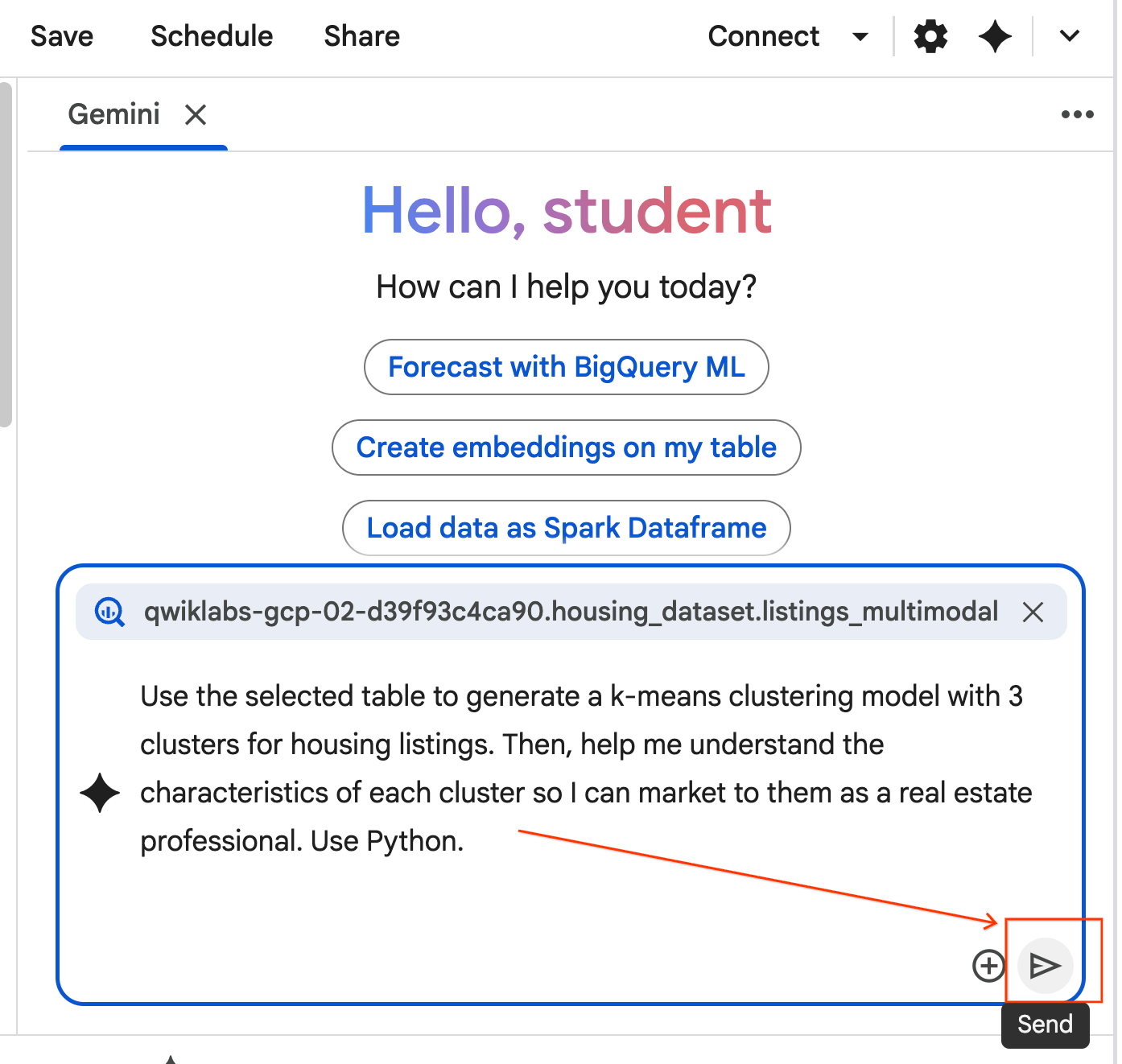
- Copie o comando abaixo e insira na caixa de chat do agente. Em seguida, clique em Enviar para enviar o comando ao agente.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- O agente vai pensar e formular um plano. Se você concordar com esse plano, clique em Aceitar e executar. O agente vai gerar código Python em uma ou mais células novas.
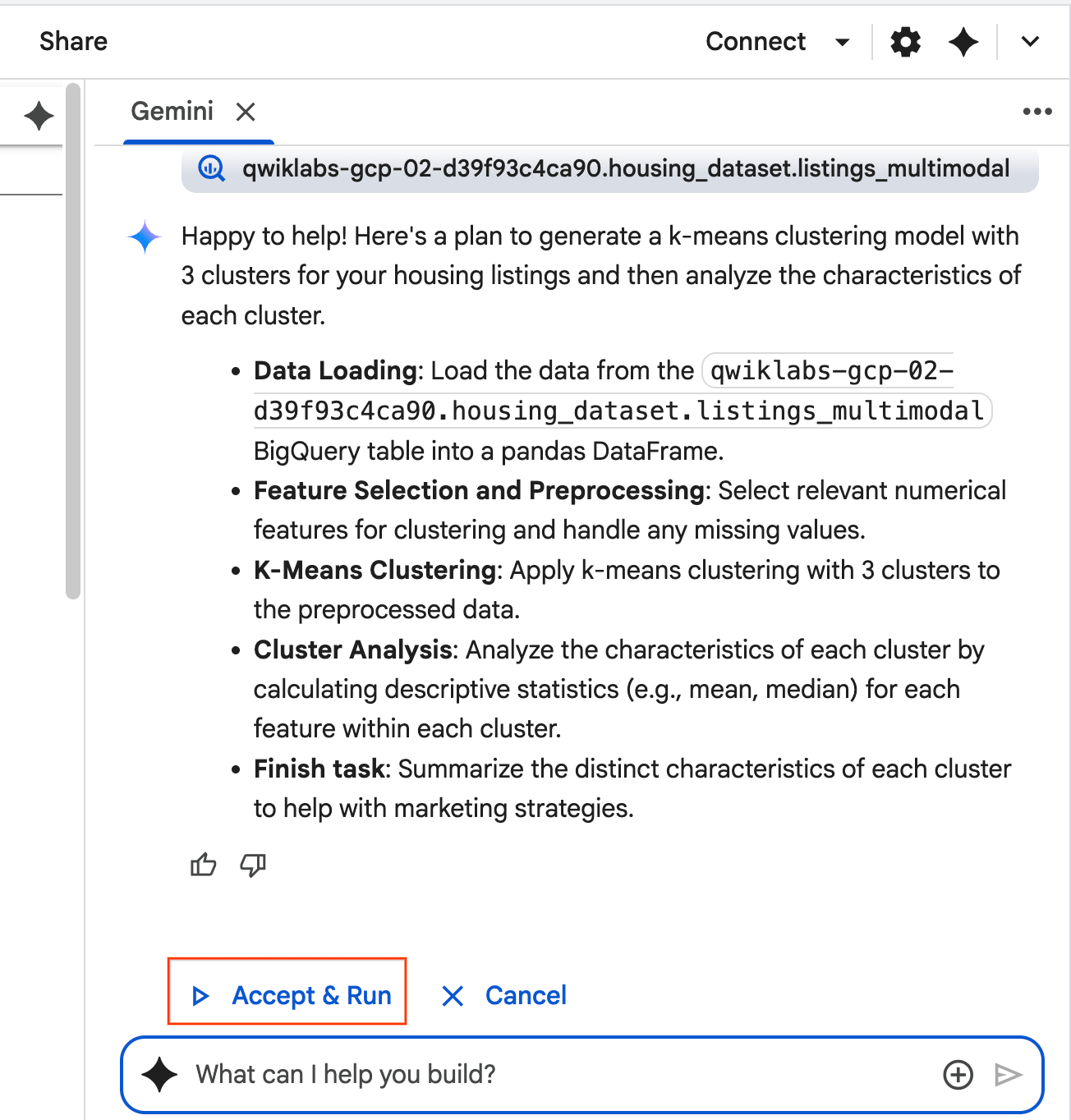
- O agente pede que você clique em Aceitar e executar em cada bloco de código gerado. Assim, o processo usa a abordagem "human in the loop". Revise ou edite o código e continue seguindo cada uma das etapas até terminar.
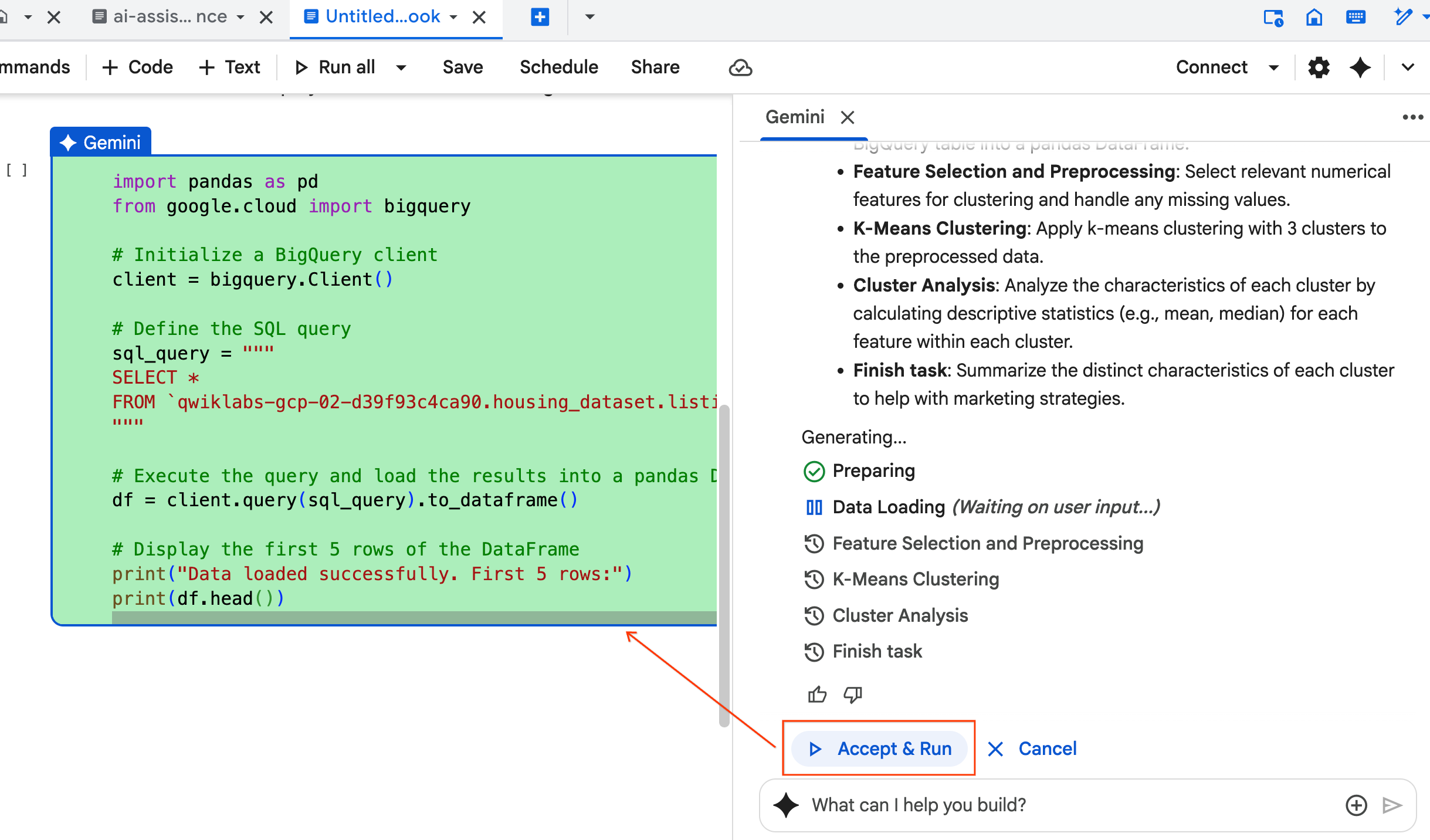
- Quando terminar, feche a nova guia do notebook e volte para a guia
ai-assisted-data-science.ipynboriginal para continuar com a seção final do laboratório.
12. Pesquisa multimodal com embeddings e pesquisa vetorial
Nesta última seção, você vai implementar a pesquisa multimodal diretamente no BigQuery. Isso permite pesquisas intuitivas, como encontrar casas com base em uma descrição de texto ou encontrar casas semelhantes a uma imagem de amostra.
O processo funciona convertendo primeiro cada imagem da casa em uma representação numérica chamada embedding. Um embedding captura o significado semântico de uma imagem, permitindo que você encontre itens semelhantes comparando os vetores numéricos deles.
Você vai usar o modelo multimodalembedding para gerar esses vetores para todas as suas fichas. Depois de criar um índice de vetor para acelerar as pesquisas, você realiza dois tipos de pesquisa por similaridade: conversão de texto em imagem (encontrar casas que correspondam a uma descrição) e imagem para imagem (encontrar casas que se pareçam com uma imagem de amostra).
Você vai fazer tudo isso no BigQuery, usando funções como ML.GENERATE_EMBEDDING para gerar embeddings ou VECTOR_SEARCH para pesquisa de similaridade.
13. Como fazer a limpeza
Para limpar todos os recursos do Google Cloud usados neste projeto, exclua o projeto do Google Cloud.
Como alternativa, exclua os recursos individuais criados executando o seguinte código em uma nova célula no notebook:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
Por fim, você pode excluir o notebook:
- No painel Explorer do BigQuery Studio, expanda seu projeto e o nó Notebooks.
- Clique nos três pontos verticais ao lado do notebook
ai-assisted-data-science. - Selecione Excluir.
14. Parabéns!
Parabéns por concluir o codelab.
O que aprendemos
- Prepare um conjunto de dados brutos de anúncios de imóveis para análise usando a engenharia de atributos.
- Enriqueça as páginas de detalhes usando as funções de IA do BigQuery para analisar fotos de casas e identificar recursos visuais importantes.
- Crie e avalie um modelo k-means com o BigQuery Machine Learning (BQML) para segmentar propriedades em clusters distintos.
- Automatize a criação de modelos usando o Agente de ciência de dados para gerar um modelo de clustering com Python.
- Gere embeddings de imagens de casas para usar uma ferramenta de pesquisa visual e encontrar imóveis semelhantes com consultas de texto ou imagem.