
1. บทนำ
ภาพรวม
ในแล็บนี้ คุณจะได้สำรวจเวิร์กโฟลว์ด้านวิทยาศาสตร์ข้อมูลแบบมัลติโมดัลใน BigQuery ซึ่งอิงตามสถานการณ์อสังหาริมทรัพย์ คุณจะเริ่มต้นด้วยชุดข้อมูลดิบของข้อมูลบ้านและรูปภาพ เสริมข้อมูลนี้ด้วย AI เพื่อดึงฟีเจอร์ภาพ สร้างโมเดลการจัดกลุ่มเพื่อค้นหากลุ่มตลาดที่แตกต่างกัน และสุดท้ายคือสร้างเครื่องมือค้นหาภาพที่มีประสิทธิภาพโดยใช้การฝังเวกเตอร์
คุณจะเปรียบเทียบเวิร์กโฟลว์ SQL ดั้งเดิมนี้กับแนวทาง Generative AI ที่ทันสมัยโดยใช้ Data Science Agent เพื่อสร้างโมเดลการจัดกลุ่มที่ใช้ Python โดยอัตโนมัติจากพรอมต์ข้อความอย่างง่าย
สิ่งที่คุณจะได้เรียนรู้
- เตรียมชุดข้อมูลดิบของข้อมูลอสังหาริมทรัพย์เพื่อการวิเคราะห์ผ่าน Feature Engineering
- เพิ่มคุณค่าให้ข้อมูลโดยใช้ฟังก์ชัน AI ของ BigQuery เพื่อวิเคราะห์รูปภาพบ้านสำหรับฟีเจอร์ภาพที่สำคัญ
- สร้างและประเมินโมเดล K-means ด้วย BigQuery Machine Learning (BQML) เพื่อแบ่งกลุ่มพร็อพเพอร์ตี้เป็นคลัสเตอร์ที่แตกต่างกัน
- สร้างโมเดลโดยอัตโนมัติโดยใช้ Data Science Agent เพื่อสร้างโมเดลการจัดกลุ่มด้วย Python
- สร้างการฝังสำหรับรูปภาพบ้านเพื่อขับเคลื่อนเครื่องมือค้นหาด้วยภาพ โดยค้นหาบ้านที่คล้ายกันด้วยข้อความหรือการค้นหาด้วยรูปภาพ
ข้อกำหนดเบื้องต้น
ก่อนเริ่มแล็บนี้ คุณควรมีความรู้เกี่ยวกับสิ่งต่อไปนี้
- การเขียนโปรแกรม SQL และ Python ขั้นพื้นฐาน
- การเรียกใช้โค้ด Python ในสมุดบันทึก Jupyter
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
เปิดใช้ API ด้วย Cloud Shell
Cloud Shell คือสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งโหลดเครื่องมือที่จำเป็นไว้ล่วงหน้า
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้เรียกใช้คำสั่งต่อไปนี้เพื่อยืนยันการตรวจสอบสิทธิ์ใน Cloud Shell
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้เพื่อยืนยันว่าได้กำหนดค่าโปรเจ็กต์ให้ใช้กับ gcloud แล้ว
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
เปิดใช้ API
- เรียกใช้คำสั่งนี้เพื่อเปิดใช้ API และบริการที่จำเป็นทั้งหมด
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- เมื่อเรียกใช้คำสั่งสำเร็จ คุณควรเห็นข้อความที่คล้ายกับข้อความที่แสดงด้านล่าง
Operation "operations/..." finished successfully.
- ออกจาก Cloud Shell
3. เปิดสมุดบันทึก Lab ใน BigQuery Studio
การไปยังส่วนต่างๆ ของ UI
- ในคอนโซล Google Cloud ให้ไปที่เมนูการนำทาง > BigQuery
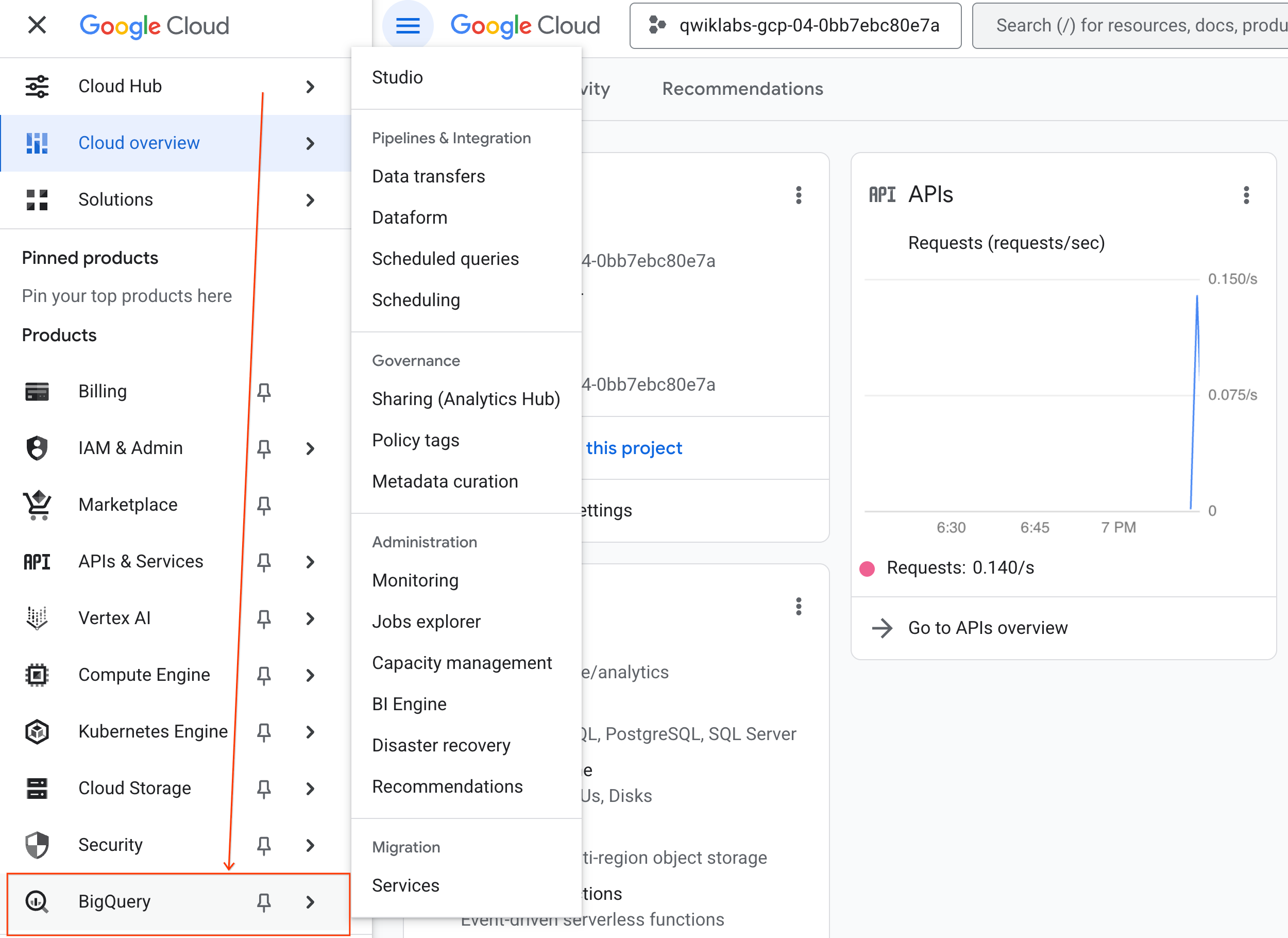
- ในแผง BigQuery Studio ให้คลิกปุ่มลูกศรเมนูแบบเลื่อนลง วางเมาส์เหนือ Notebook แล้วเลือกอัปโหลด
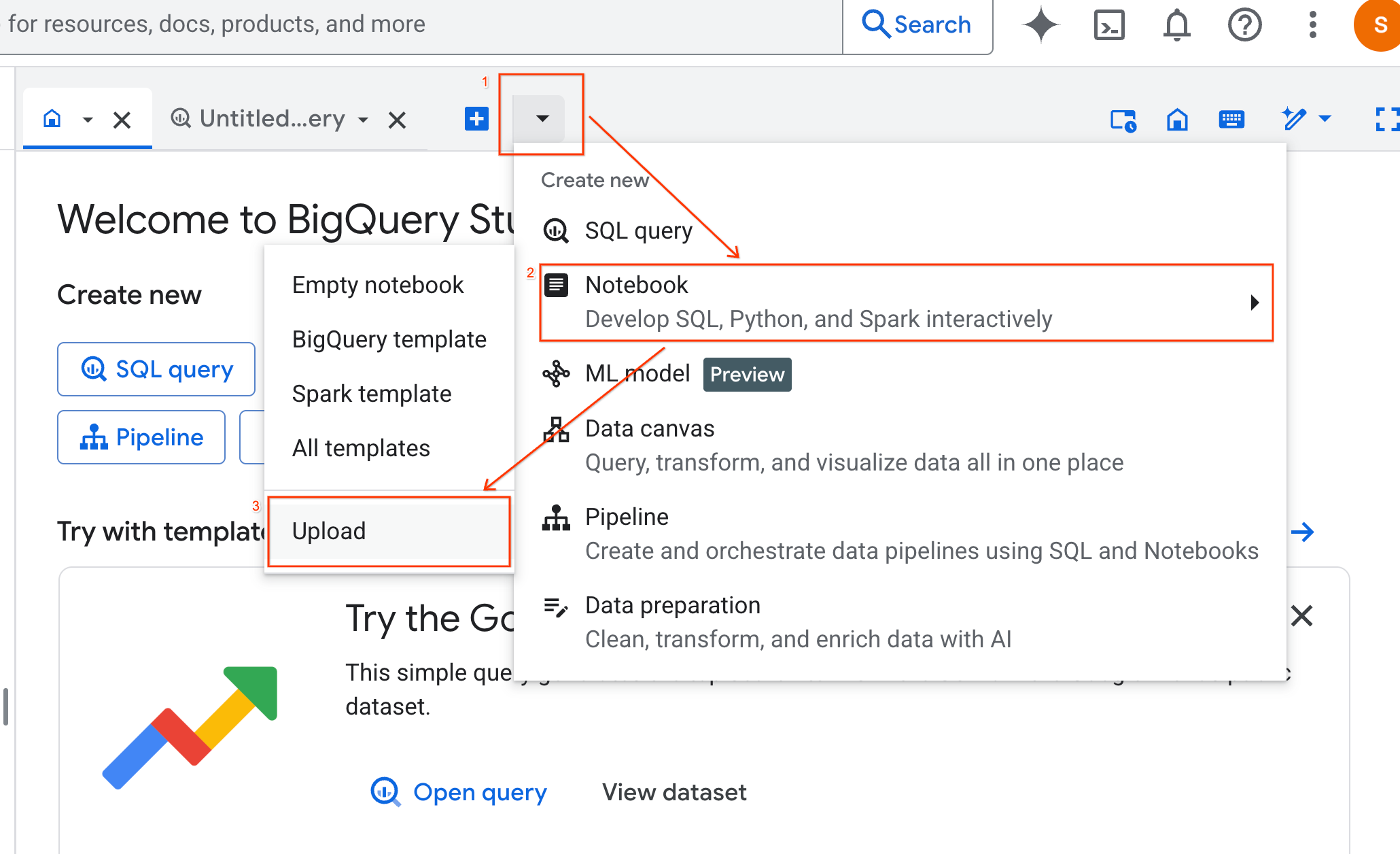
- เลือกปุ่มตัวเลือก URL แล้วป้อน URL ต่อไปนี้
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- ตั้งค่าภูมิภาคเป็น
us-central1แล้วคลิกอัปโหลด
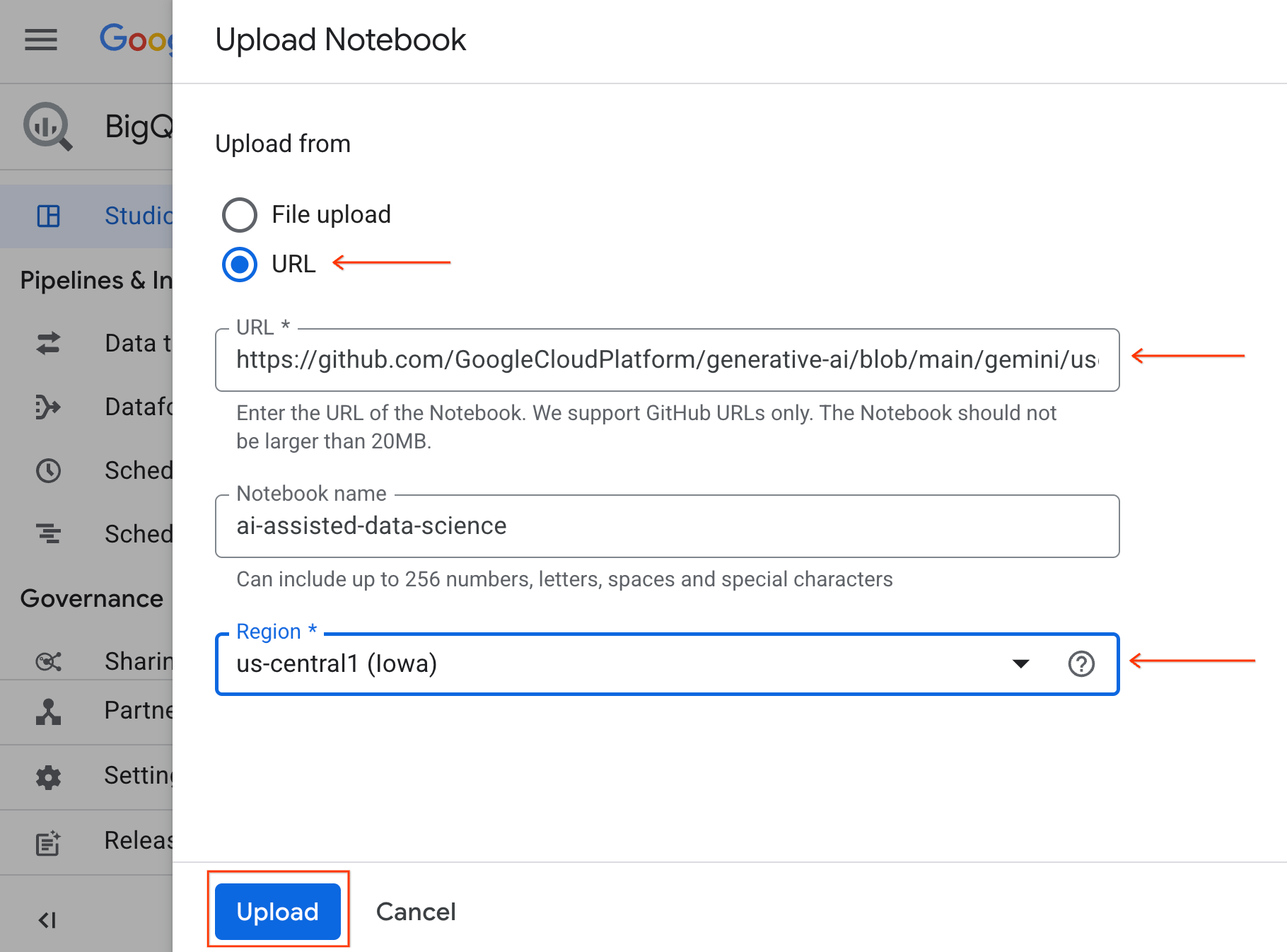
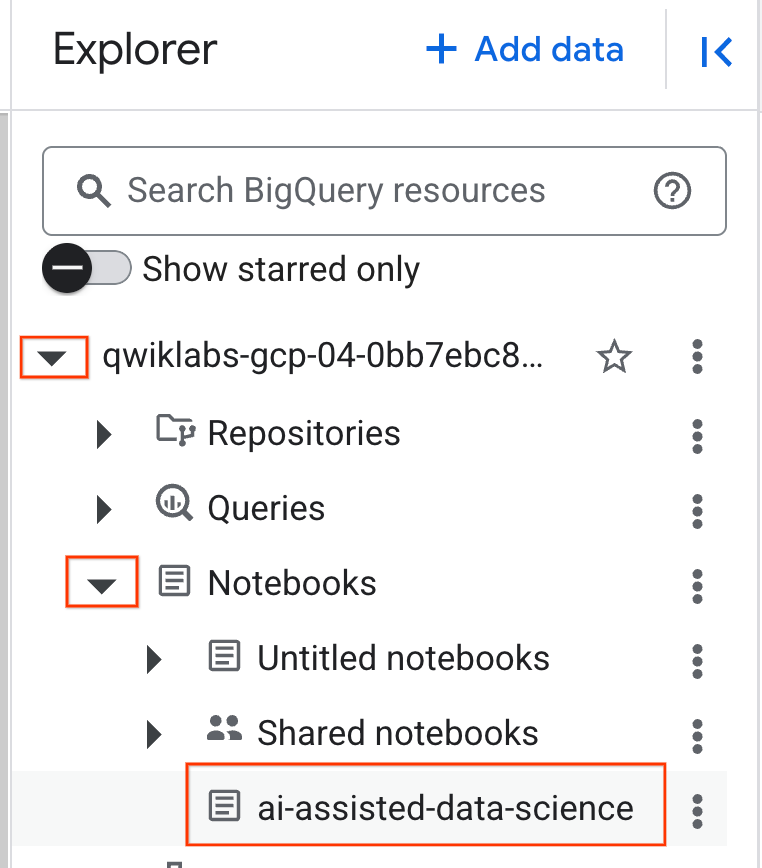
- หากต้องการเปิด Notebook ให้คลิกลูกศรเมนูแบบเลื่อนลงในแผง Explorer ที่มีรหัสโปรเจ็กต์ จากนั้นคลิกเมนูแบบเลื่อนลงสำหรับ Notebook คลิก Notebook
ai-assisted-data-science
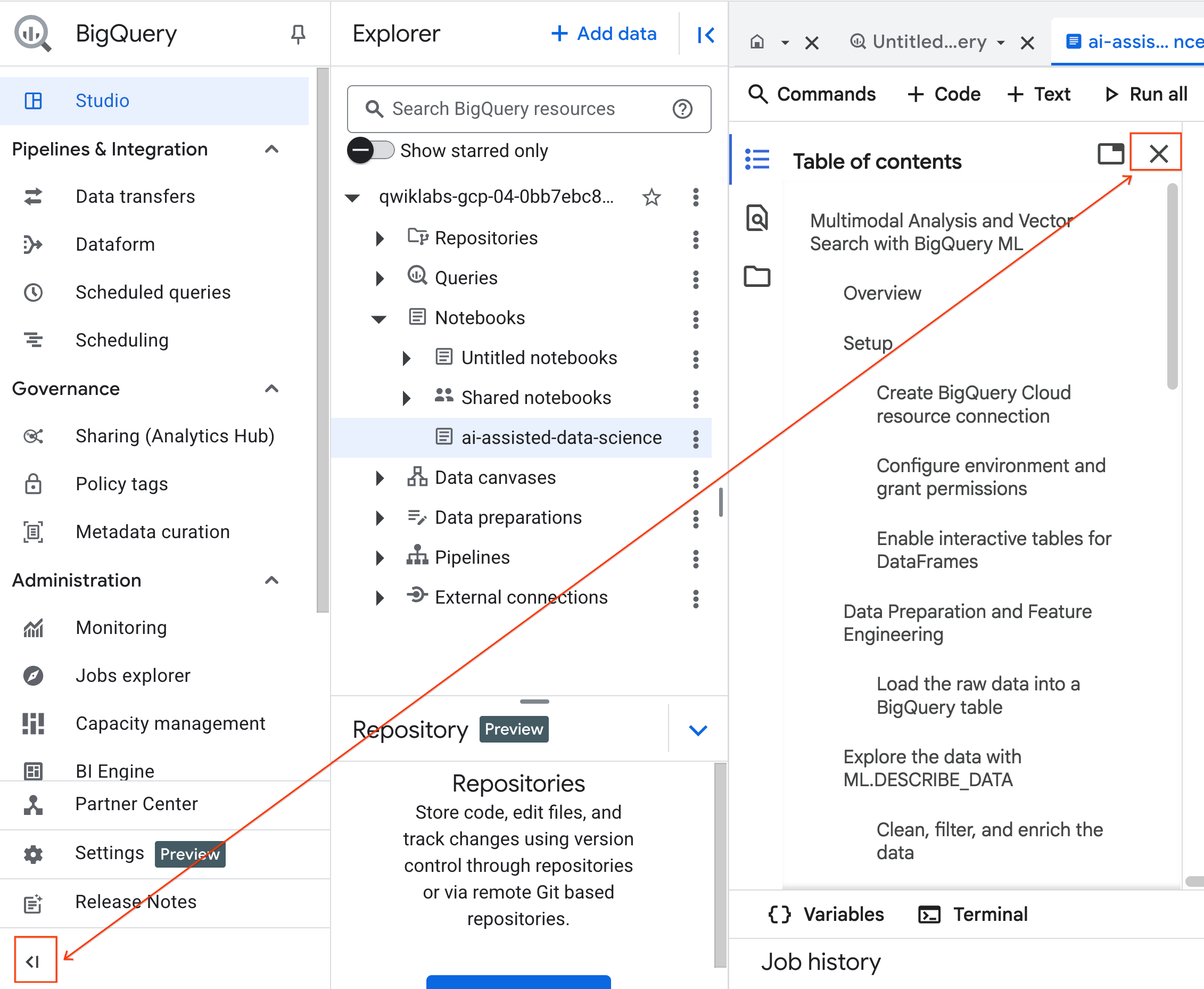
- (ไม่บังคับ) ยุบเมนูการนำทาง BigQuery และสารบัญของ Notebook เพื่อให้มีพื้นที่มากขึ้น
4. เชื่อมต่อกับรันไทม์และเรียกใช้โค้ดการตั้งค่า
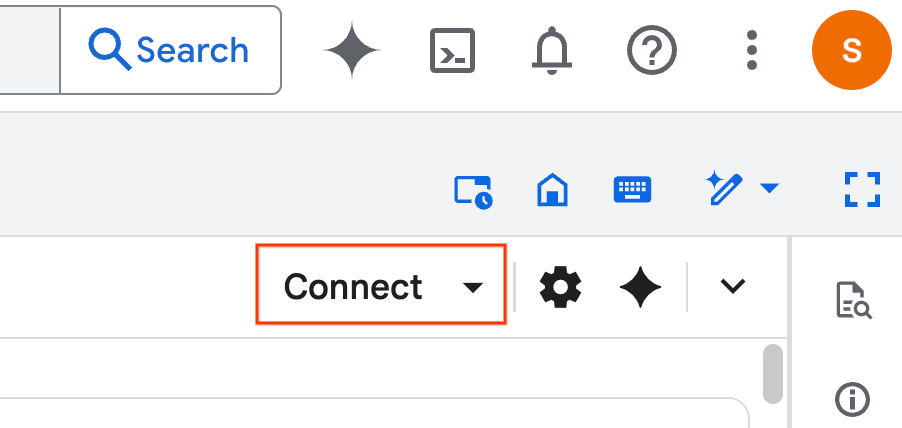
- คลิกเชื่อมต่อ หากป๊อปอัปปรากฏขึ้น ให้ให้สิทธิ์ Colab Enterprise แก่ผู้ใช้ สมุดบันทึกจะเชื่อมต่อกับรันไทม์โดยอัตโนมัติ การดำเนินการนี้อาจใช้เวลาสักครู่จึงจะเสร็จสมบูรณ์
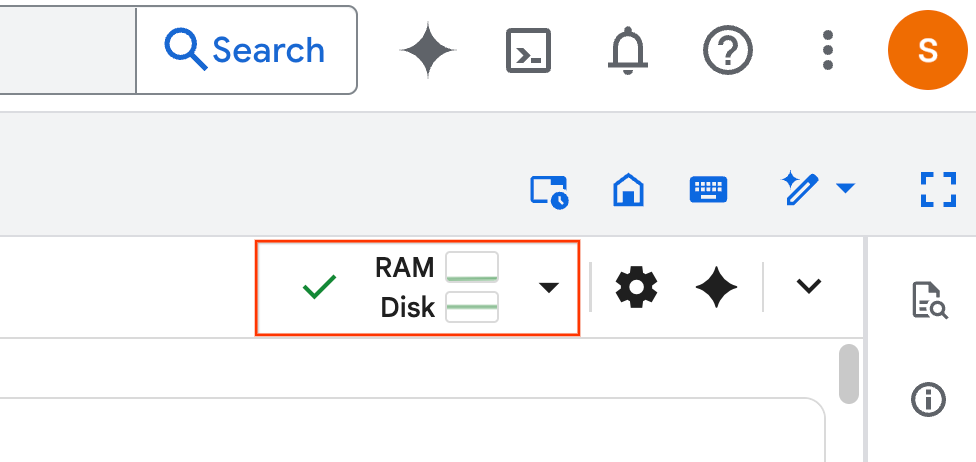
- เมื่อกำหนดระยะเวลาการทำงานแล้ว คุณจะเห็นข้อมูลต่อไปนี้
- เลื่อนไปที่ส่วนการตั้งค่าใน Notebook คลิกปุ่ม "เรียกใช้" ข้างเซลล์ที่ซ่อนอยู่ ซึ่งจะเป็นการสร้างทรัพยากร 2-3 รายการที่จำเป็นสำหรับแล็บในโปรเจ็กต์ ขั้นตอนนี้อาจใช้เวลาสักครู่ คุณสามารถตรวจสอบเซลล์ในส่วนการตั้งค่าได้ในระหว่างนี้
5. การจัดเตรียมข้อมูลและการสร้างฟีเจอร์
ในส่วนนี้ คุณจะได้ทำตามขั้นตอนแรกที่สำคัญในโปรเจ็กต์วิทยาศาสตร์ข้อมูล นั่นคือการเตรียมข้อมูล คุณเริ่มต้นด้วยการสร้างชุดข้อมูล BigQuery เพื่อจัดระเบียบงาน จากนั้นโหลดข้อมูลอสังหาริมทรัพย์ / ที่อยู่อาศัยดิบจากไฟล์ CSV ใน Cloud Storage ลงในตารางใหม่
จากนั้นคุณจะเปลี่ยนข้อมูลดิบนี้ให้เป็นตารางที่ทำความสะอาดแล้วซึ่งมีฟีเจอร์ใหม่ ซึ่งรวมถึงการกรองข้อมูล การสร้างproperty_ageฟีเจอร์ใหม่ และการเตรียมข้อมูลรูปภาพสำหรับการวิเคราะห์แบบมัลติโมดัล
6. การเพิ่มคุณค่าแบบมัลติโมดัลด้วยฟังก์ชัน AI
ตอนนี้คุณจะเพิ่มคุณค่าให้กับข้อมูลโดยใช้พลังของ Generative AI ในส่วนนี้ คุณจะใช้ฟังก์ชัน AI ในตัวของ BigQuery เพื่อวิเคราะห์รูปภาพสำหรับข้อมูลบ้านแต่ละหลัง
การเชื่อมต่อ BigQuery กับโมเดล Gemini จะช่วยให้คุณดึงฟีเจอร์ใหม่ๆ ที่มีประโยชน์จากรูปภาพ (เช่น พร็อพเพอร์ตี้อยู่ใกล้น้ำหรือไม่ และคำอธิบายสั้นๆ ของบ้าน) ได้โดยตรงด้วย SQL
7. การฝึกโมเดลด้วยการจัดกลุ่ม K-Means
เมื่อมีชุดข้อมูลที่เพิ่มคุณค่าใหม่แล้ว คุณก็พร้อมที่จะสร้างโมเดลแมชชีนเลิร์นนิง เป้าหมายของคุณคือการแบ่งกลุ่มข้อมูลบ้านเป็นกลุ่มที่แตกต่างกัน และคุณจะทำเช่นนี้ได้โดยการฝึกโมเดลการจัดกลุ่ม K-means โดยตรงใน BigQuery โดยใช้ BigQuery Machine Learning (BQML) ในขั้นตอนเดียวนี้ คุณยังลงทะเบียนโมเดลในModel Registry ของแพลตฟอร์มเอเจนต์ AIด้วย ซึ่งจะทำให้โมเดลพร้อมใช้งานได้ทันทีภายในระบบนิเวศ MLOps ที่กว้างขึ้นใน Google Cloud
หากต้องการยืนยันว่าลงทะเบียนโมเดลเรียบร้อยแล้ว คุณจะดูโมเดลได้ใน Model Registry แพลตฟอร์ม Agent โดยทำตามขั้นตอนต่อไปนี้
- ในคอนโซล Google Cloud ให้คลิกเมนูการนำทาง (☰) ที่มุมซ้ายบน
- เลื่อนไปที่ส่วนแพลตฟอร์มตัวแทน แล้วคลิกโมเดล
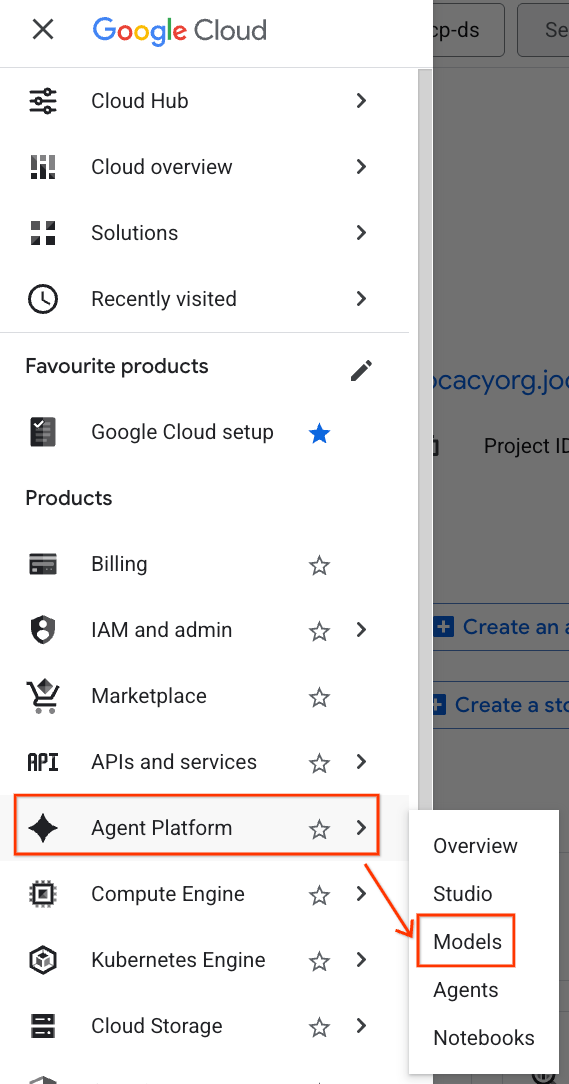
- คลิกปุ่มModel Registryที่ไฮไลต์ในภาพหน้าจอ
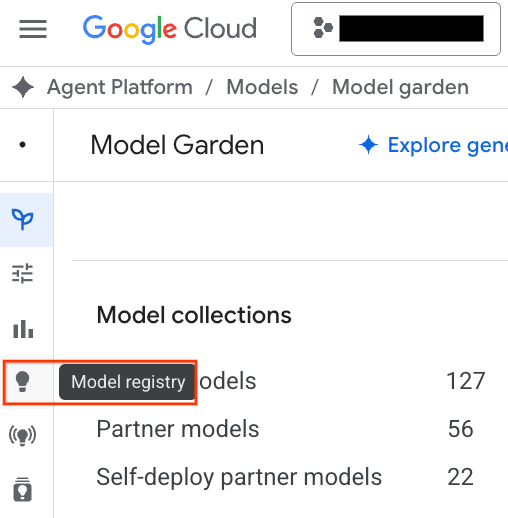
- คุณจะเห็นโมเดล BQML แสดงอยู่ข้างโมเดลที่กำหนดเองอื่นๆ ทั้งหมด ค้นหาโมเดลชื่อ housing_clustering ในรายการโมเดล คุณสามารถทำขั้นตอนถัดไปเพื่อทำให้ใช้งานได้กับอุปกรณ์ปลายทาง ซึ่งจะทำให้โมเดลพร้อมใช้งานสำหรับการคาดการณ์แบบเรียลไทม์ทางออนไลน์ภายนอกสภาพแวดล้อม BigQuery
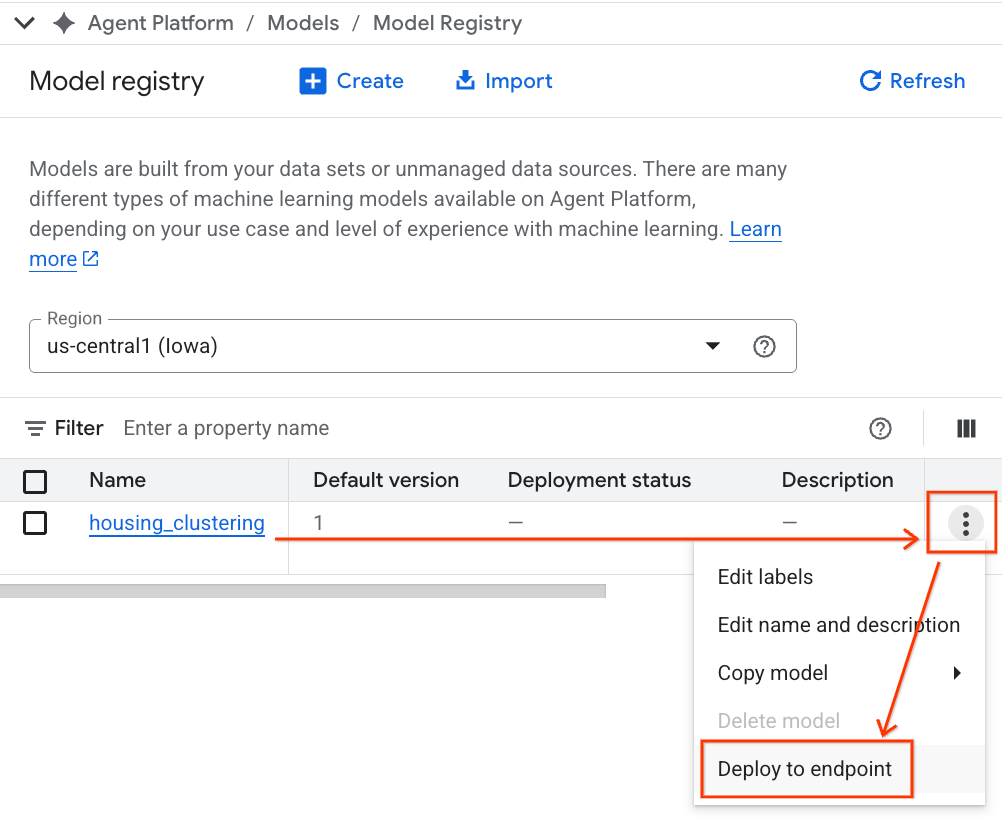
หลังจากสำรวจ Model Registry แล้ว คุณจะกลับไปที่ Colab Notebook ใน BigQuery ได้โดยทำตามขั้นตอนต่อไปนี้
- ในเมนูการนำทาง (☰) ให้ไปที่ BigQuery > Studio
- ขยายเมนูในแผงสำรวจเพื่อค้นหา Notebook แล้วเปิด
8. การประเมินและการคาดการณ์โมเดล
หลังจากฝึกโมเดลแล้ว ขั้นตอนถัดไปคือการทําความเข้าใจคลัสเตอร์ที่โมเดลสร้างขึ้น ในที่นี้ คุณใช้ฟังก์ชันแมชชีนเลิร์นนิงของ BigQuery เช่น ML.EVALUATE และ ML.CENTROIDS เพื่อวิเคราะห์คุณภาพของโมเดลและลักษณะที่กำหนดของแต่ละกลุ่ม
จากนั้นใช้ ML.PREDICT เพื่อกำหนดบ้านแต่ละหลังให้กับคลัสเตอร์ การเรียกใช้การค้นหานี้ด้วยคำสั่ง Magic %%bigquery df จะจัดเก็บผลลัพธ์ใน Pandas DataFrame ที่ชื่อ df ซึ่งจะทำให้ข้อมูลพร้อมใช้งานทันทีสำหรับขั้นตอน Python ที่ตามมา ซึ่งแสดงให้เห็นถึงความสามารถในการทำงานร่วมกันระหว่าง SQL และ Python ใน Colab Enterprise
9. แสดงภาพและตีความคลัสเตอร์
เมื่อโหลดการคาดการณ์ลงใน DataFrame แล้ว คุณจะสร้างภาพเพื่อทำให้ข้อมูลมีชีวิตชีวาได้ ในส่วนนี้ คุณจะได้ใช้ไลบรารียอดนิยมของ Python เช่น Matplotlib เพื่อสำรวจความแตกต่างระหว่างกลุ่มที่อยู่อาศัย
คุณจะสร้างแผนภาพกล่องและแผนภูมิแท่งเพื่อเปรียบเทียบฟีเจอร์หลักๆ เช่น ราคาและอายุของที่พักด้วยภาพ ซึ่งจะช่วยให้เข้าใจแต่ละคลัสเตอร์ได้อย่างง่ายดาย
10. สร้างคำอธิบายคลัสเตอร์ด้วยโมเดล Gemini
แม้ว่าจุดศูนย์กลางเชิงตัวเลขและแผนภูมิจะมีประสิทธิภาพ แต่ Generative AI จะช่วยให้คุณก้าวไปอีกขั้นและสร้างลักษณะตัวตนเชิงคุณภาพที่สมบูรณ์สำหรับกลุ่มที่อยู่อาศัยแต่ละกลุ่ม ซึ่งจะช่วยให้คุณเข้าใจไม่เพียงสิ่งที่คลัสเตอร์เป็น แต่ยังเข้าใจผู้ที่คลัสเตอร์เป็นตัวแทนด้วย
ในส่วนนี้ คุณจะรวบรวมสถิติเฉลี่ยของแต่ละคลัสเตอร์ก่อน เช่น ราคาและพื้นที่ใช้สอย จากนั้นคุณจะส่งข้อมูลนี้ไปยังพรอมต์สำหรับโมเดล Gemini จากนั้นสั่งให้โมเดลทำหน้าที่เป็นผู้เชี่ยวชาญด้านอสังหาริมทรัพย์และสร้างข้อมูลสรุปโดยละเอียด ซึ่งรวมถึงลักษณะสำคัญและผู้ซื้อเป้าหมายสำหรับแต่ละกลุ่ม ผลลัพธ์คือชุดคำอธิบายที่ชัดเจนและมนุษย์อ่านได้ ซึ่งทำให้คลัสเตอร์เข้าใจได้ทันทีและทีมการตลาดนำไปใช้ได้
คุณสามารถปรับเปลี่ยนพรอมต์ได้ตามต้องการและทดลองกับผลลัพธ์
11. สร้างโมเดลอัตโนมัติด้วย Data Science Agent
ตอนนี้คุณจะได้สำรวจเวิร์กโฟลว์ทางเลือกที่มีประสิทธิภาพ แทนที่จะเขียนโค้ดด้วยตนเอง คุณจะใช้ Data Science Agent ที่ผสานรวมเพื่อสร้างเวิร์กโฟลว์โมเดลการจัดกลุ่มที่สมบูรณ์โดยอัตโนมัติจากพรอมต์ภาษาธรรมชาติเดียว
ทำตามขั้นตอนต่อไปนี้เพื่อสร้างและเรียกใช้โมเดลโดยใช้เอเจนต์
- ในแผง BigQuery Studio ให้คลิกปุ่มลูกศรเมนูแบบเลื่อนลง วางเมาส์เหนือ Notebook แล้วเลือก Notebook ว่าง ซึ่งจะช่วยให้มั่นใจได้ว่าโค้ดของเอเจนต์จะไม่รบกวนสมุดบันทึกในห้องทดลองเดิม
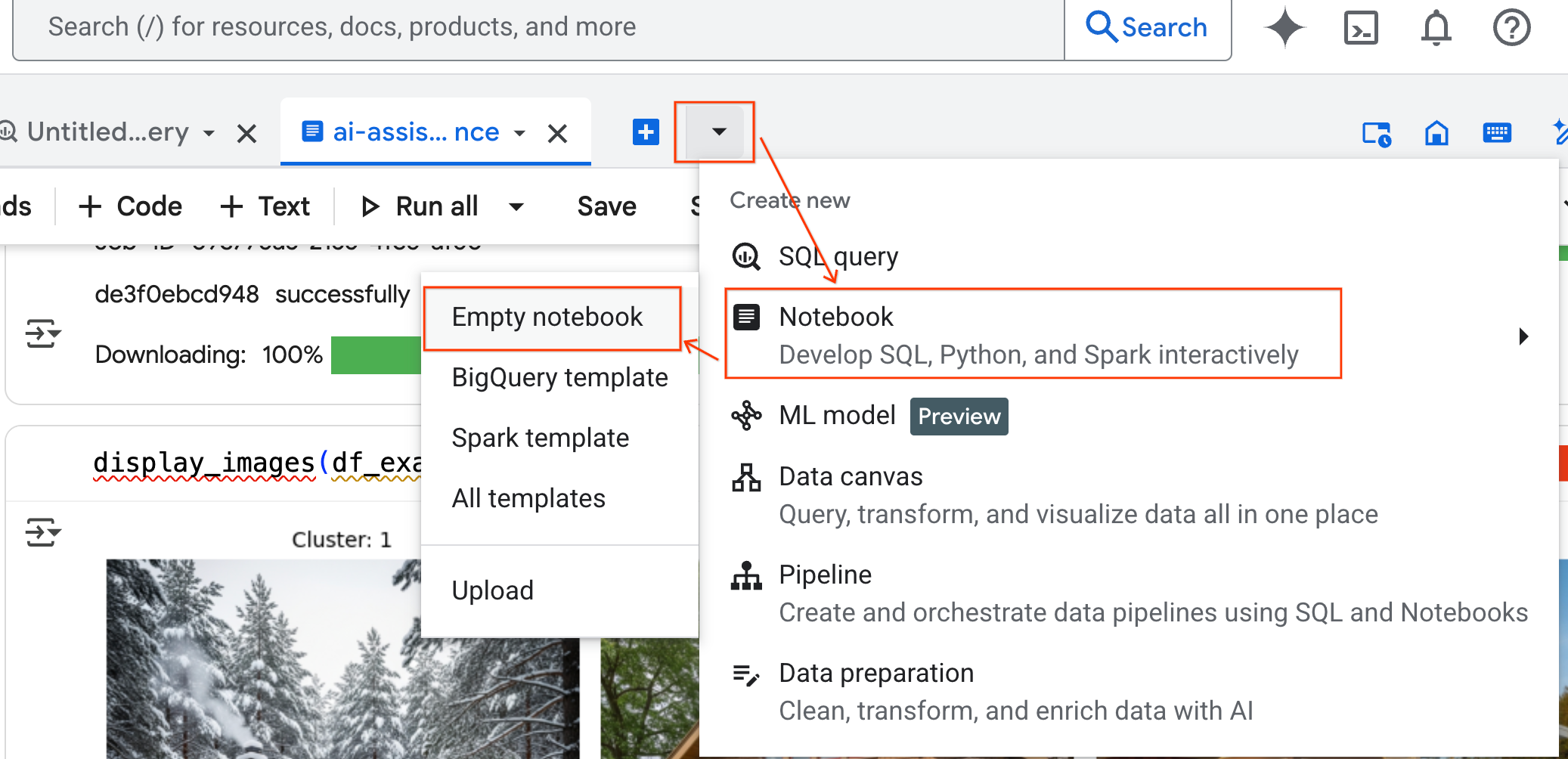
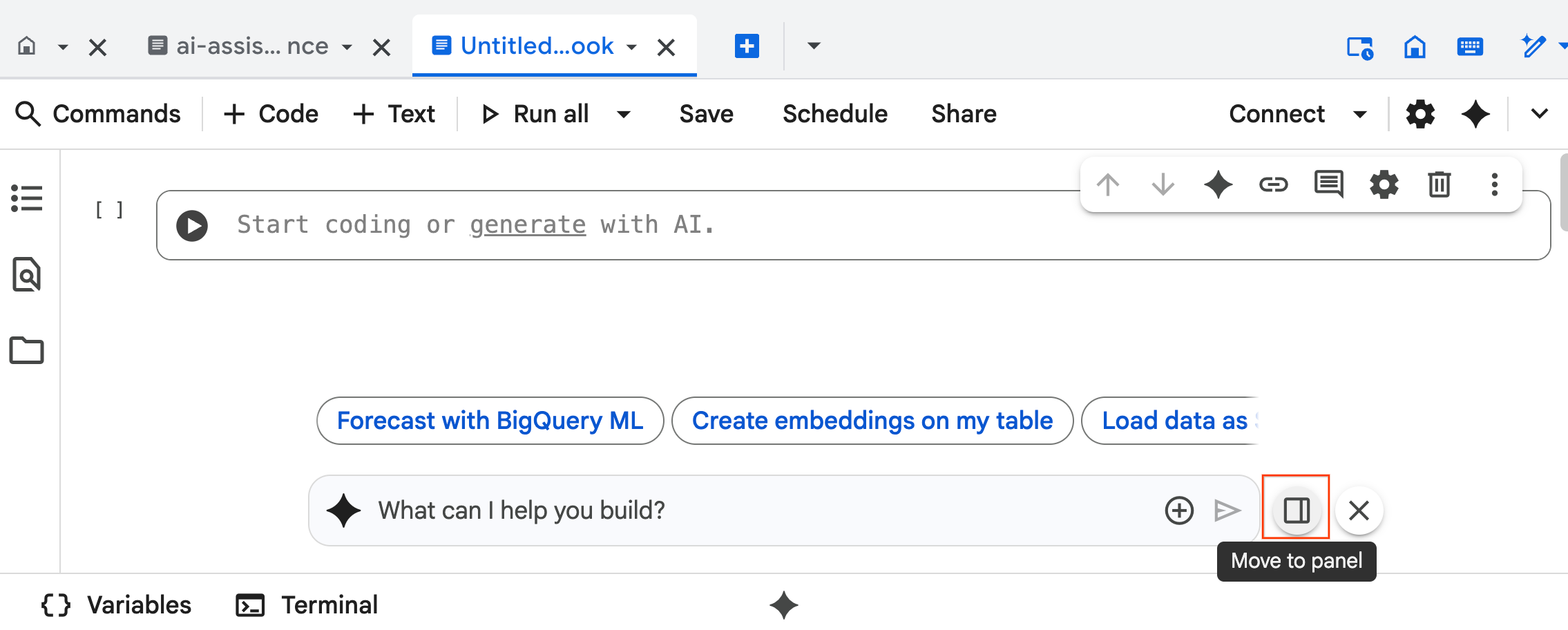
- อินเทอร์เฟซแชทของ Data Science Agent จะเปิดขึ้นที่ด้านล่างของ Notebook คลิกปุ่มย้ายไปที่แผงเพื่อปักหมุดแชทไว้ทางด้านขวา
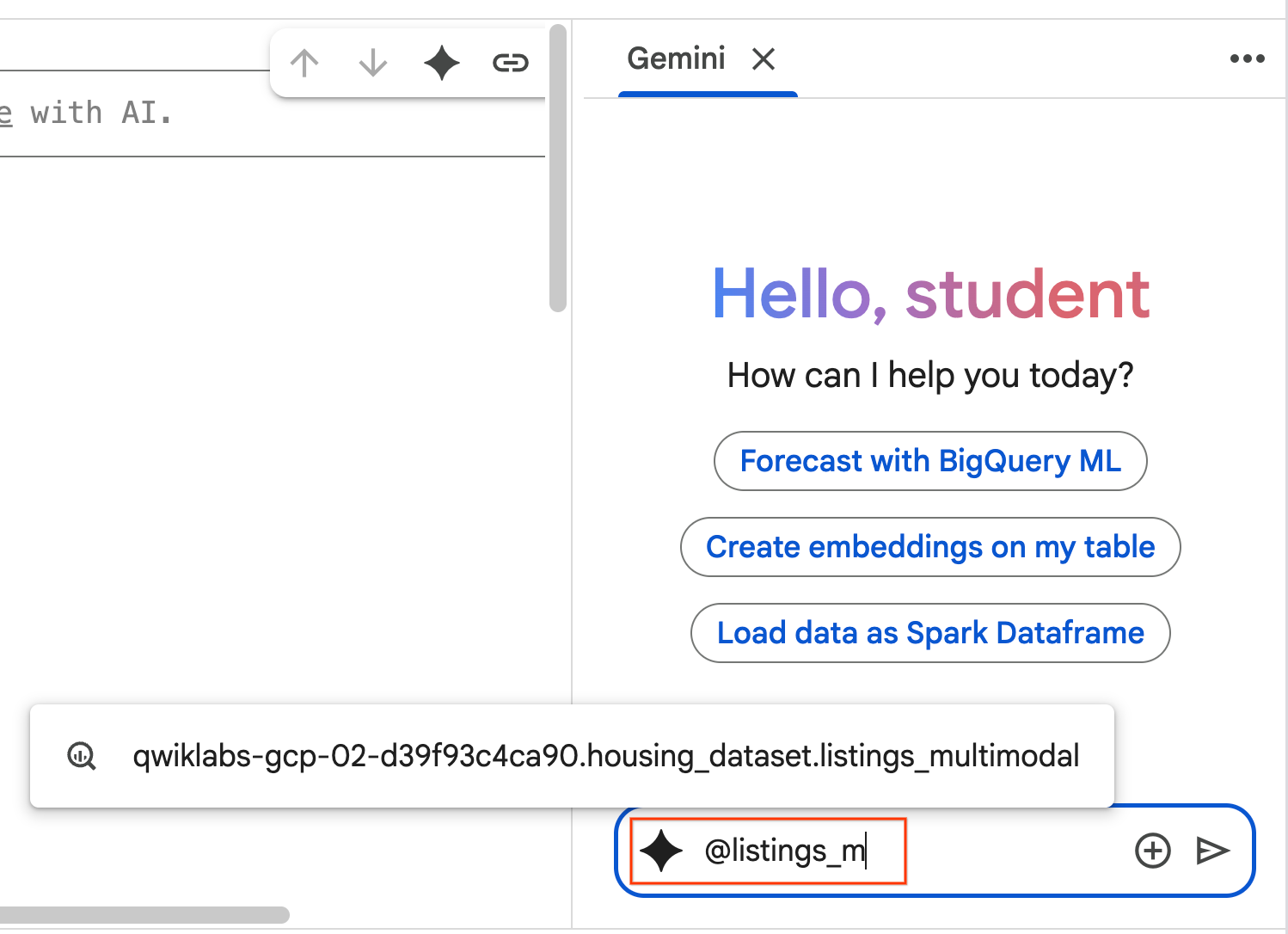
- เริ่มพิมพ์
@listing_multimodalในแผงแชท แล้วคลิกตาราง ซึ่งจะกำหนดlistings_multimodalตารางเป็นบริบทอย่างชัดเจน
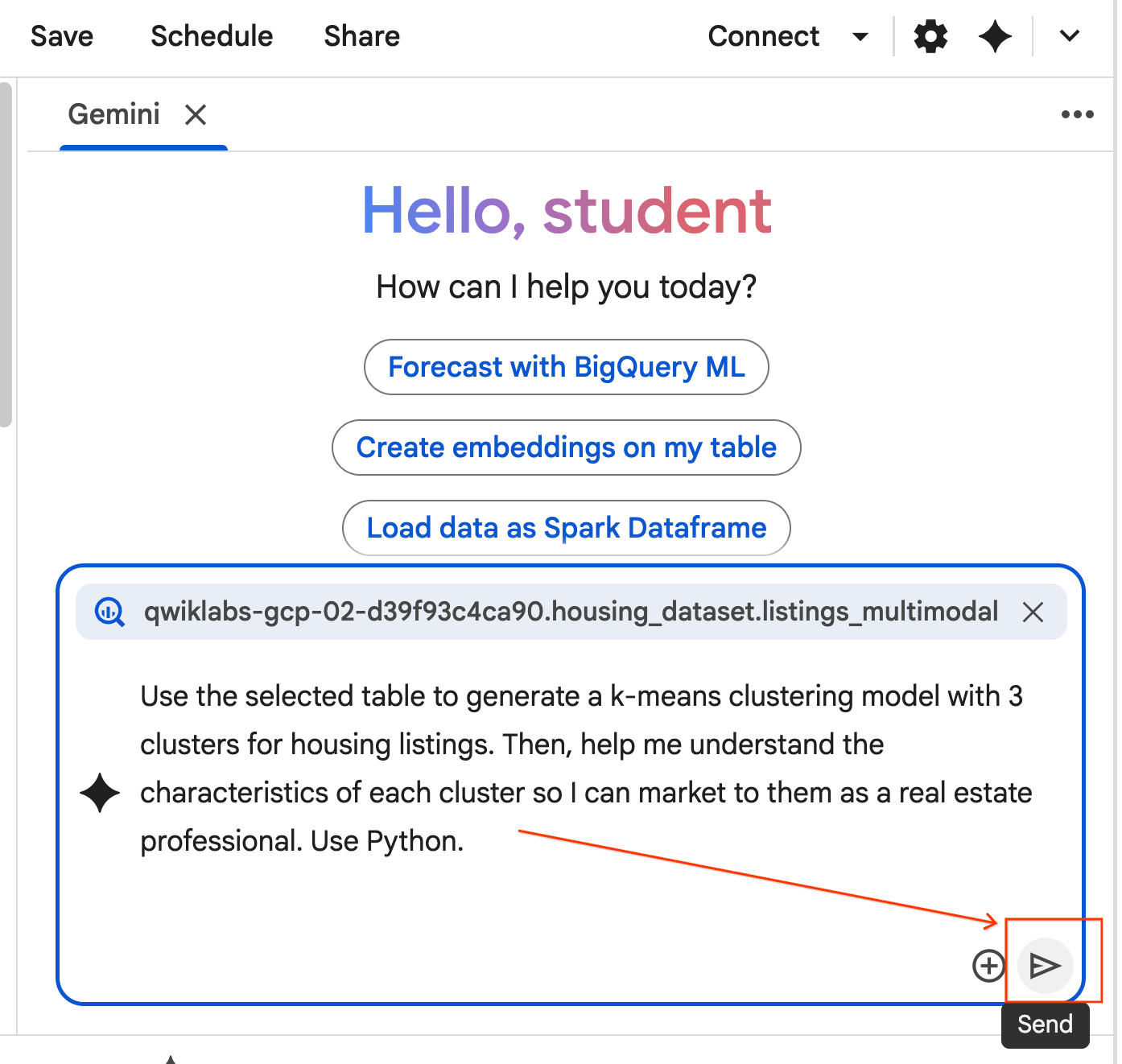
- คัดลอกพรอมต์ด้านล่างแล้วป้อนลงในช่องแชทของเอเจนต์ หลังจากนั้น ให้คลิกส่งเพื่อส่งพรอมต์ไปยังเอเจนต์
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
- เอเจนต์จะคิดและวางแผน หากคุณพอใจกับแผนนี้ ให้คลิกยอมรับและเรียกใช้ Agent จะสร้างโค้ด Python ในเซลล์ใหม่อย่างน้อย 1 เซลล์
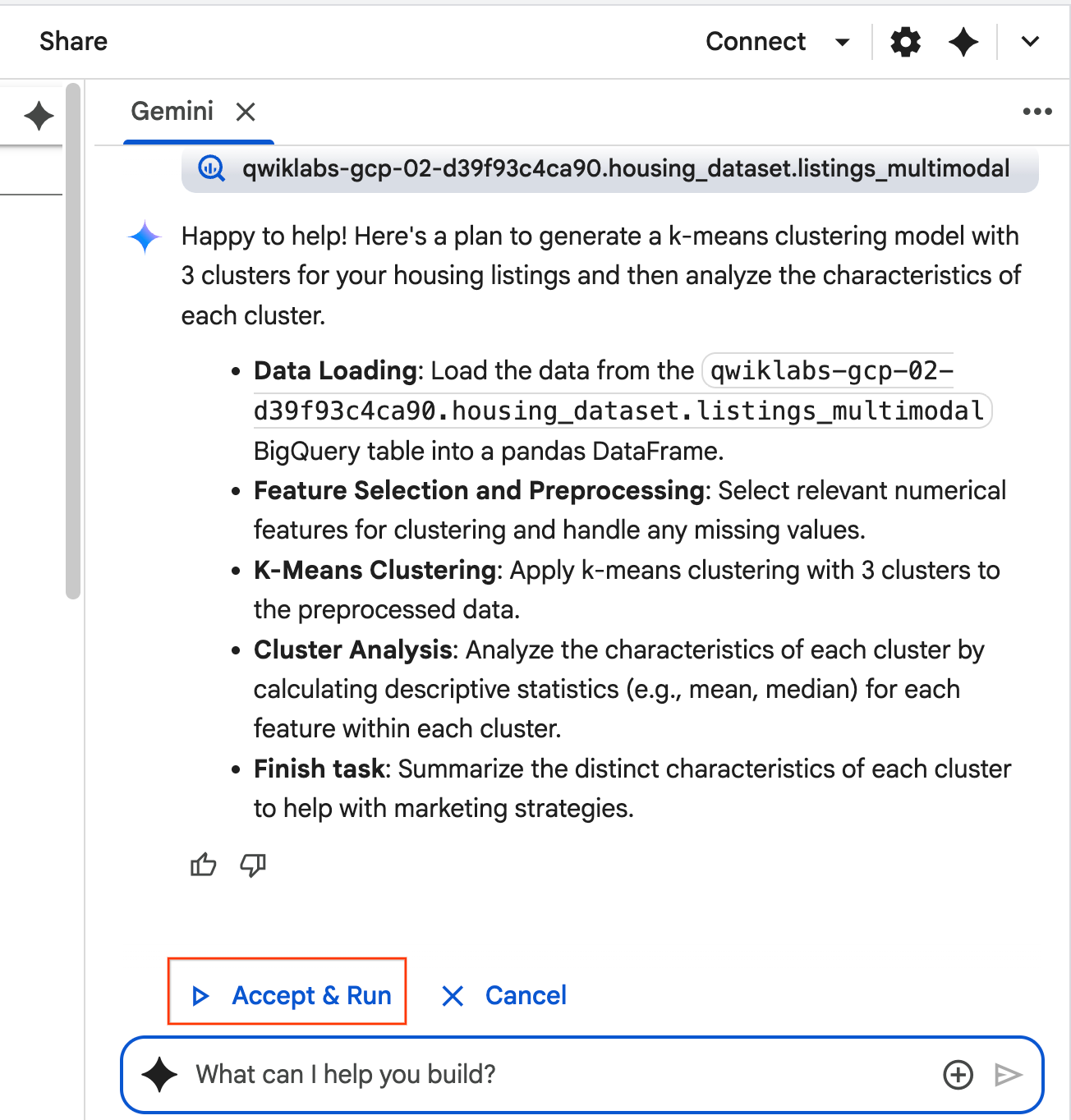
- Agent จะขอให้คุณยอมรับและเรียกใช้โค้ดแต่ละบล็อกที่สร้างขึ้น ซึ่งจะช่วยให้มีมนุษย์เข้ามาเกี่ยวข้องในกระบวนการ คุณสามารถตรวจสอบหรือแก้ไขโค้ดและทำตามแต่ละขั้นตอนจนกว่าจะเสร็จสิ้น
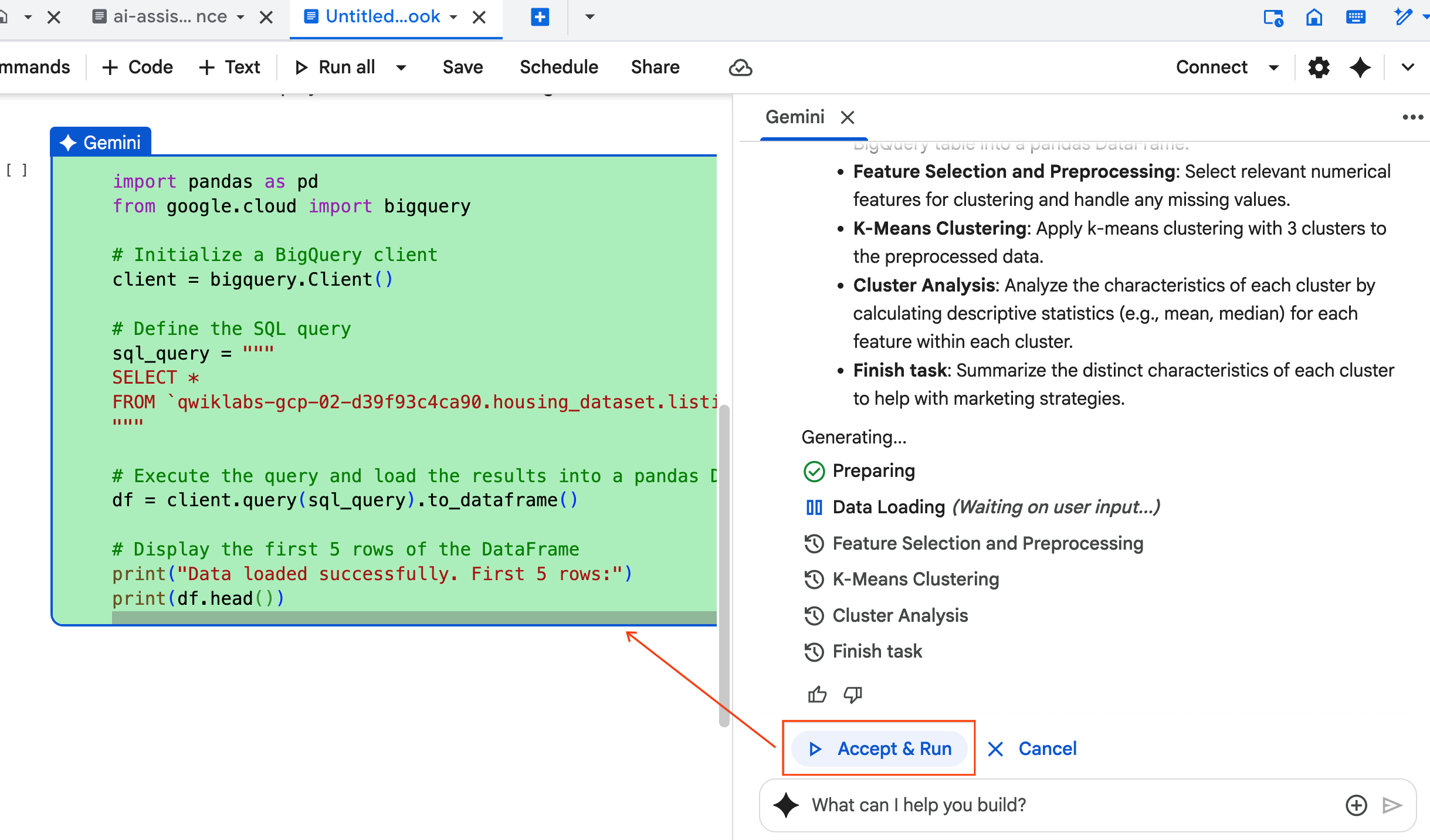
- เมื่อเสร็จแล้ว เพียงปิดแท็บ Notebook ใหม่นี้แล้วกลับไปที่แท็บ
ai-assisted-data-science.ipynbเดิมเพื่อดำเนินการต่อในส่วนสุดท้ายของ Lab
12. การค้นหาหลายโมดัลด้วยการฝังและการค้นหาเวกเตอร์
ในส่วนสุดท้ายนี้ คุณจะใช้การค้นหาแบบมัลติโมดอลภายใน BigQuery โดยตรง ซึ่งช่วยให้ค้นหาได้อย่างเป็นธรรมชาติ เช่น การค้นหาบ้านตามคำอธิบายข้อความ หรือการค้นหาบ้านที่มีลักษณะคล้ายกับรูปภาพตัวอย่าง
กระบวนการนี้ทำงานโดยแปลงรูปภาพบ้านแต่ละหลังเป็นตัวแทนที่เป็นตัวเลขที่เรียกว่าการฝังก่อน การฝังจะบันทึกความหมายเชิงความหมายของรูปภาพ ซึ่งช่วยให้คุณค้นหารายการที่คล้ายกันได้โดยการเปรียบเทียบเวกเตอร์ตัวเลขของรายการเหล่านั้น
คุณจะใช้โมเดล multimodalembedding เพื่อสร้างเวกเตอร์เหล่านี้สำหรับข้อมูลทั้งหมด หลังจากสร้างดัชนีเวกเตอร์เพื่อเร่งการค้นหาแล้ว คุณจะทำการค้นหาความคล้ายกัน 2 ประเภท ได้แก่ ข้อความต่อรูปภาพ (ค้นหาบ้านที่ตรงกับคำอธิบาย) และรูปภาพต่อรูปภาพ (ค้นหาบ้านที่มีลักษณะคล้ายกับรูปภาพตัวอย่าง)
คุณจะทําทั้งหมดนี้ใน BigQuery โดยใช้ฟังก์ชันต่างๆ เช่น ML.GENERATE_EMBEDDING เพื่อสร้างการฝัง หรือ VECTOR_SEARCH เพื่อค้นหาความคล้ายคลึง
13. การล้างข้อมูล
หากต้องการล้างข้อมูลทรัพยากร Google Cloud ทั้งหมดที่ใช้ในโปรเจ็กต์นี้ คุณสามารถลบโปรเจ็กต์ Google Cloud ได้
หรือจะลบทรัพยากรแต่ละรายการที่คุณสร้างขึ้นโดยเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่ใน Notebook ก็ได้
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
สุดท้าย คุณสามารถลบ Notebook เองได้โดยทำดังนี้
- ในแผง Explorer ของ BigQuery Studio ให้ขยายโปรเจ็กต์และโหนด Notebooks
- คลิกจุดแนวตั้ง 3 จุดข้าง
ai-assisted-data-scienceNotebook - เลือกลบ
14. ยินดีด้วย
ขอแสดงความยินดีที่ทำ Codelab เสร็จสมบูรณ์
สิ่งที่เราได้พูดถึงไปแล้ว
- เตรียมชุดข้อมูลดิบของข้อมูลอสังหาริมทรัพย์เพื่อการวิเคราะห์ผ่าน Feature Engineering
- เพิ่มคุณค่าให้ข้อมูลโดยใช้ฟังก์ชัน AI ของ BigQuery เพื่อวิเคราะห์รูปภาพบ้านสำหรับฟีเจอร์ภาพที่สำคัญ
- สร้างและประเมินโมเดล K-means ด้วยแมชชีนเลิร์นนิงของ BigQuery (BQML) เพื่อแบ่งกลุ่มพร็อพเพอร์ตี้เป็นคลัสเตอร์ที่แตกต่างกัน
- สร้างโมเดลโดยอัตโนมัติโดยใช้ Data Science Agent เพื่อสร้างโมเดลการจัดกลุ่มด้วย Python
- สร้างการฝังสำหรับรูปภาพบ้านเพื่อขับเคลื่อนเครื่องมือค้นหาด้วยภาพ โดยค้นหาบ้านที่คล้ายกันด้วยข้อความหรือการค้นหาด้วยรูปภาพ