
1. 简介
概览
在本实验中,您将探索 BigQuery 中的多模态数据科学工作流,该工作流以房地产场景为框架。您将从房屋房源及其图片的原始数据集入手,使用 AI 扩充此数据以提取视觉特征,构建聚类模型以发现不同的细分市场,最后使用向量嵌入创建强大的视觉搜索工具。
您将通过使用 数据科学智能体 从简单的文本提示自动生成基于 Python 的聚类模型,将此 SQL 原生工作流与现代生成式 AI 方法进行比较。
学习内容
- 准备原始数据集 ,其中包含房地产房源,以便通过特征工程进行分析。
- 使用 BigQuery 的 AI 函数分析房屋照片,以获取关键视觉特征,从而扩充房源 。
- 使用 BigQuery Machine Learning (BQML) 构建和评估 K-means 模型,将房产划分为不同的集群。
- 使用数据科学智能体生成 Python 聚类模型,从而自动创建模型 。
- 为房屋图片生成嵌入 ,以支持视觉搜索工具,通过文本或图片查询查找相似的房屋。
前提条件
在开始本实验之前,您应当熟悉以下内容:
- SQL 和 Python 编程基础知识。
- 在 Jupyter 笔记本中运行 Python 代码。
2. 准备工作
创建 Google Cloud 项目
- 在 Google Cloud 控制台 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的云项目已启用结算功能。了解如何检查项目是否已启用结算功能。
使用 Cloud Shell 启用 API
Cloud Shell 是在 Google Cloud 中运行的一个命令行环境,其中预加载了必要的工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell :

- 连接到 Cloud Shell 后,运行此命令以验证您在 Cloud Shell 中的身份验证:
gcloud auth list
- 运行以下命令,确认您的项目已配置为与 gcloud 搭配使用:
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
启用 API
- 运行此命令以启用所有必需的 API 和服务:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- 成功执行该命令后,您应该会看到类似如下所示的消息:
Operation "operations/..." finished successfully.
- 退出 Cloud Shell。
3. 在 BigQuery Studio 中打开实验笔记本
浏览界面:
- 在 Google Cloud 控制台中,依次前往导航菜单 > BigQuery 。
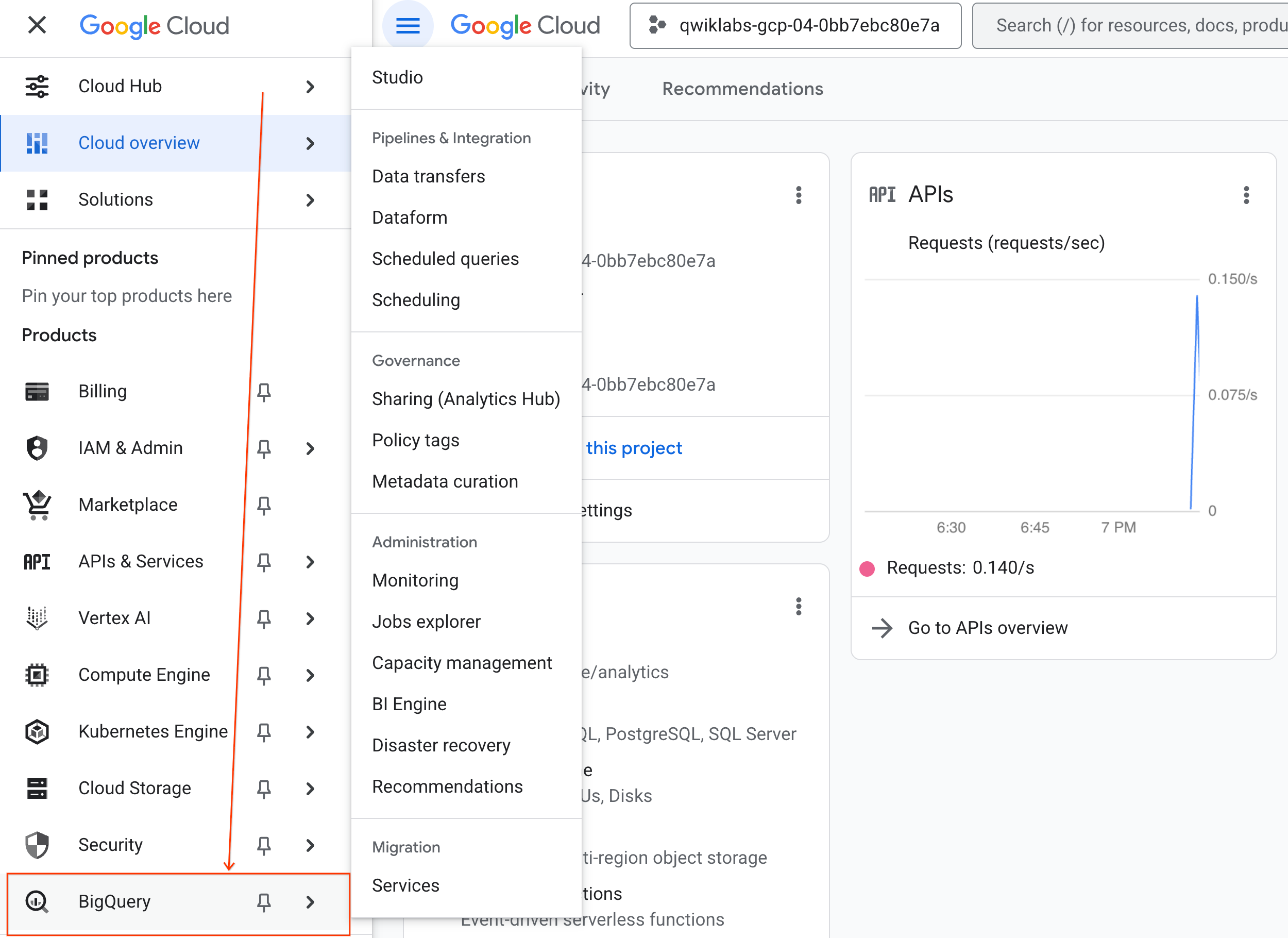
- 在 BigQuery Studio 窗格中,点击下拉箭头按钮,将鼠标悬停在 笔记本 上,然后选择 上传 。
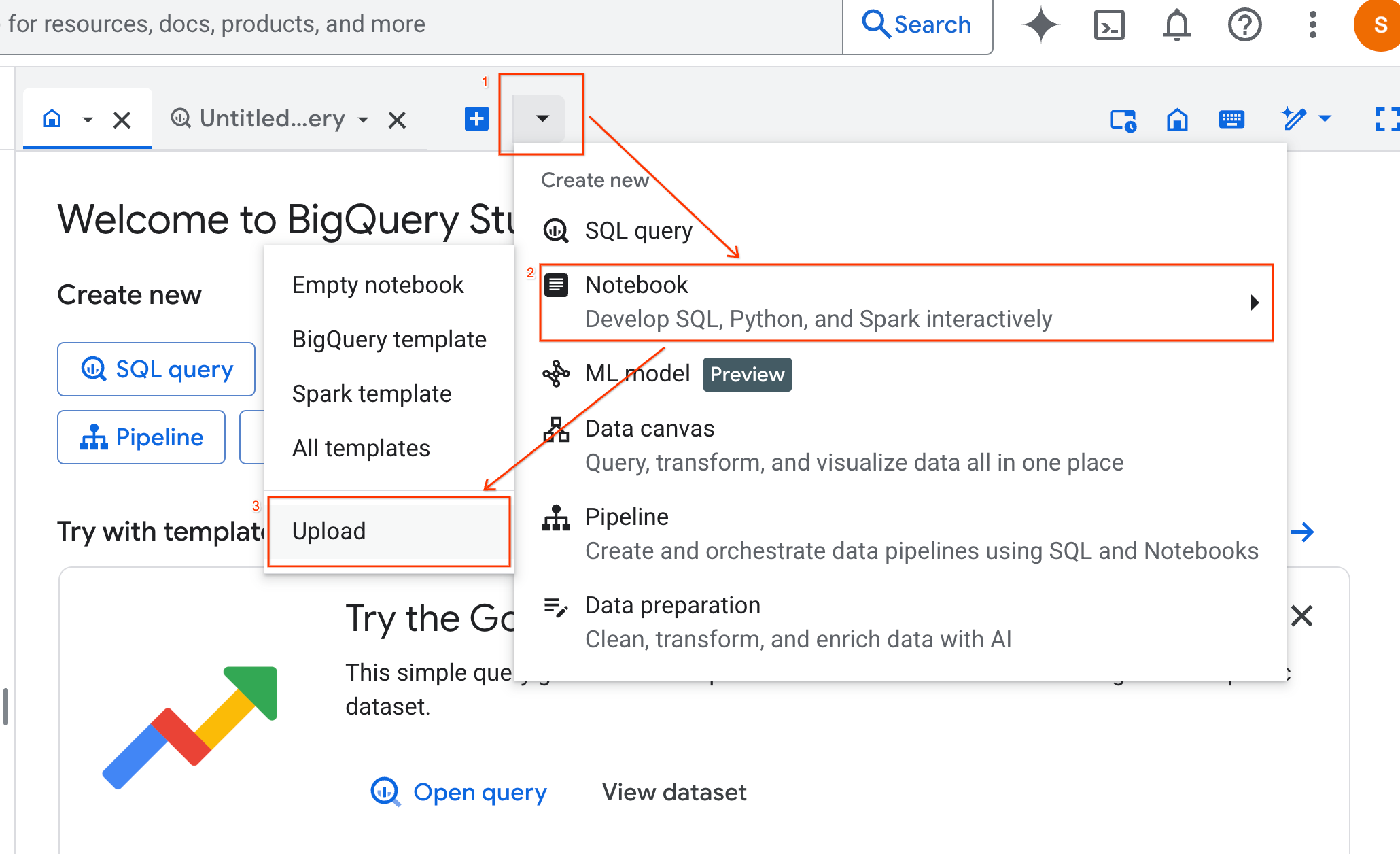
- 选择 网址 单选按钮,然后输入以下网址:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- 将区域设置为
us-central1,然后点击上传 。
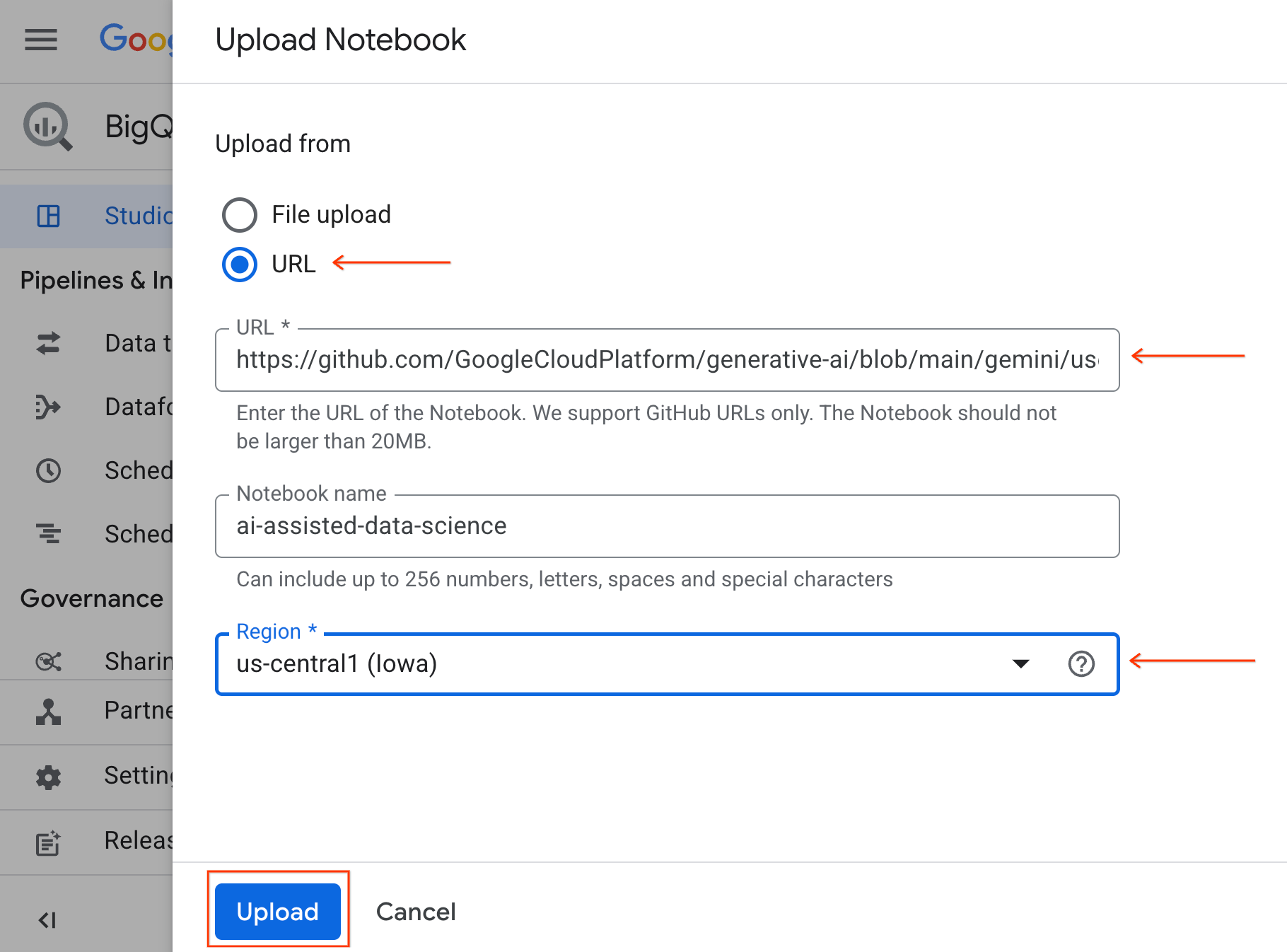
- 如需打开笔记本,请点击探索器 窗格中包含您的项目 ID 的下拉箭头。然后,点击笔记本 的下拉菜单。点击笔记本
ai-assisted-data-science。
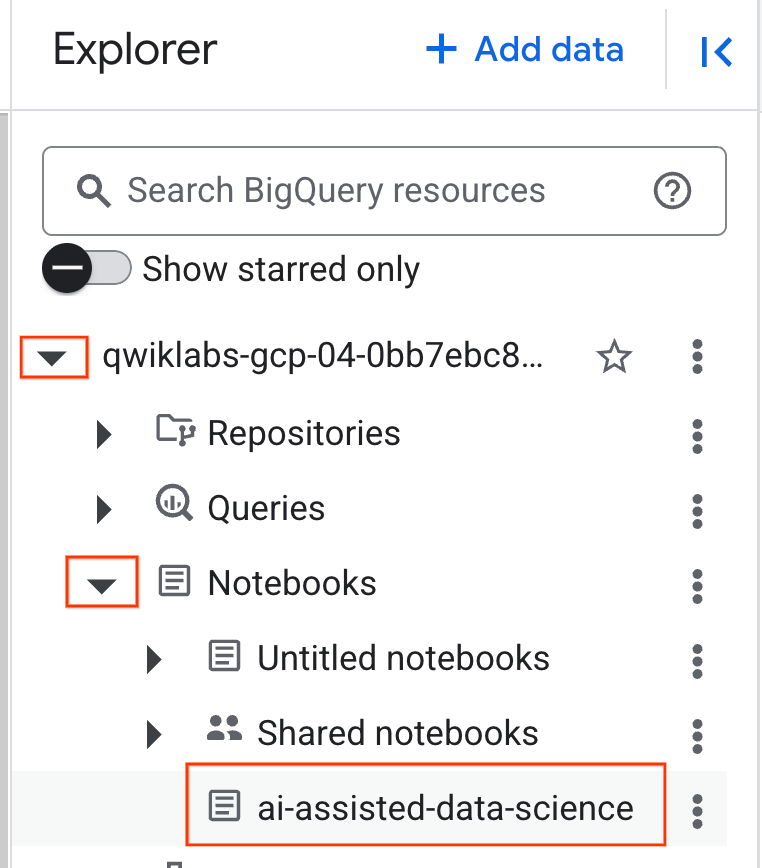
- (可选)收起 BigQuery 导航菜单 和笔记本的目录 ,以获得更多空间。
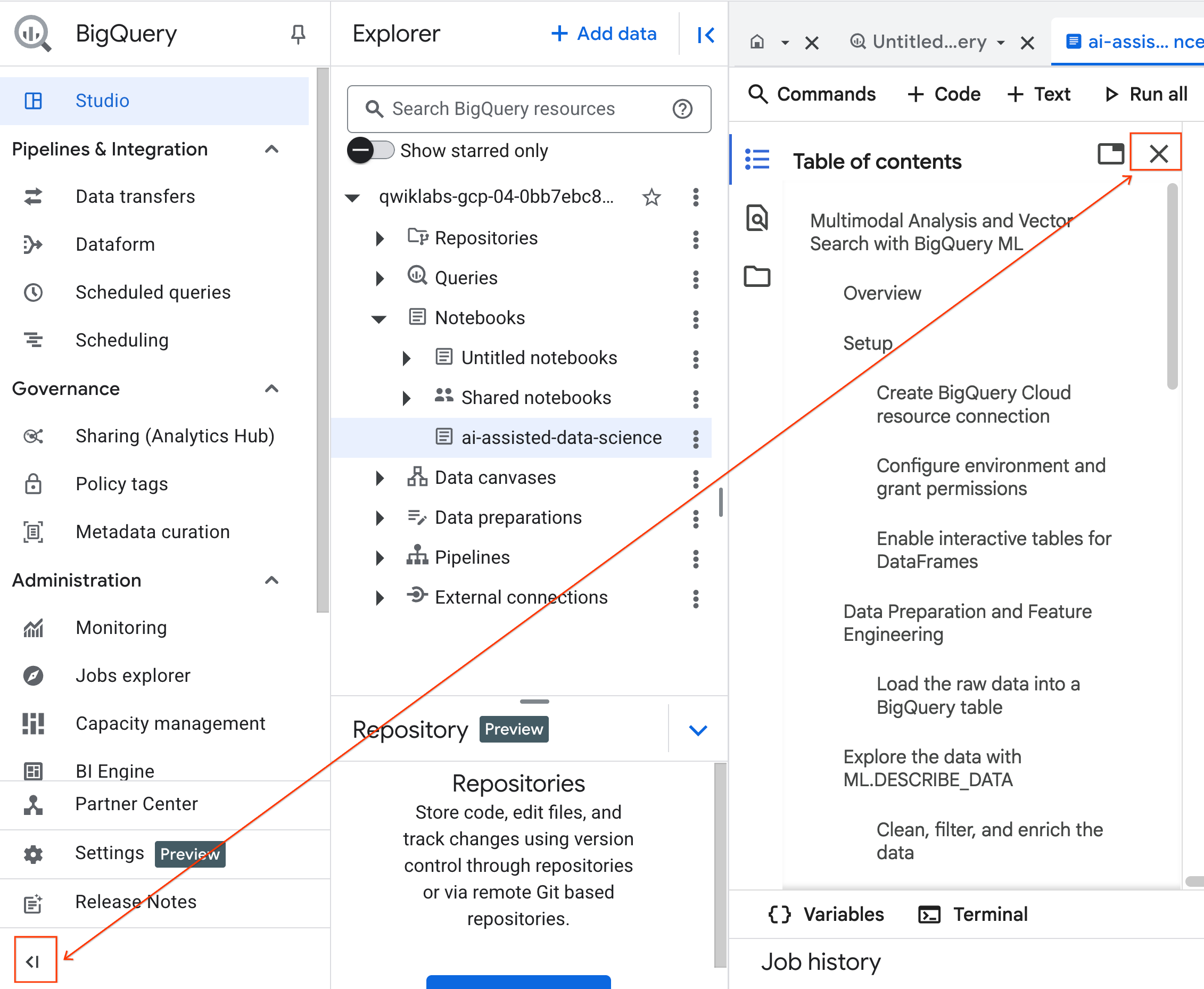
4. 连接到运行时并运行设置代码
- 点击连接 。如果出现弹出式窗口,请使用您的用户身份验证 Colab Enterprise。您的笔记本将自动连接到运行时。此过程可能需要几分钟才能完成。
- 运行时建立后,您将看到以下内容:
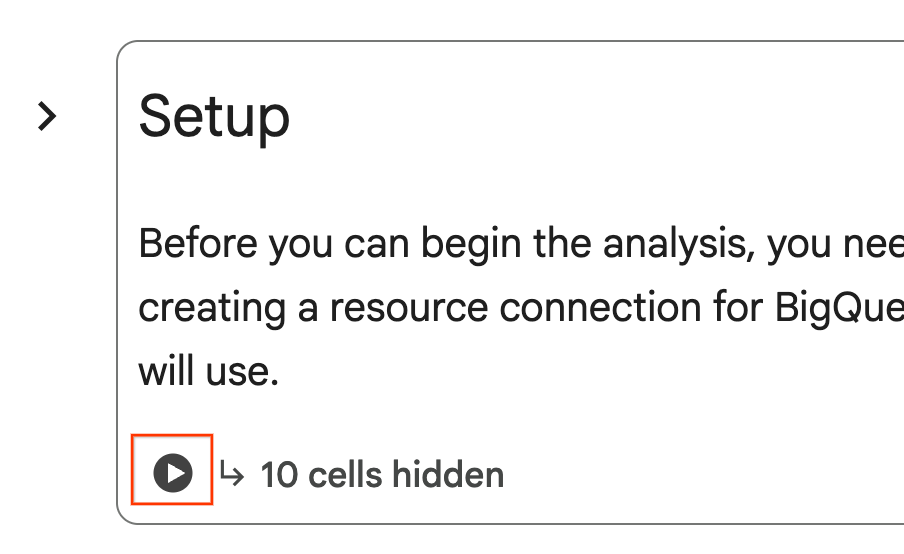
- 在笔记本中,滚动到设置 部分。点击隐藏单元格旁边的“运行”按钮。这会在您的项目中创建一些实验所需的资源。此过程可能需要一分钟才能完成。在此期间,您可以随意查看设置 下的单元格。
5. 数据准备和特征工程
在本部分中,您将完成任何数据科学项目的第一个重要步骤:准备数据。首先,您将创建一个 BigQuery 数据集来整理工作,然后将原始房地产 / 房屋数据从 Cloud Storage 中的 CSV 文件加载到新表中。
然后,您将此原始数据转换为包含新特征的清理后的表。这包括过滤房源、创建新的 property_age 特征,以及准备用于多模态分析的图片数据。
6. 使用 AI 函数进行多模态扩充
现在,您将使用生成式 AI 的强大功能来扩充数据。在本部分中,您将使用 BigQuery 的内置 AI 函数 来分析每个房屋房源的图片。
通过将 BigQuery 连接到 Gemini 模型,您可以直接使用 SQL 从图片中提取新的有价值的特征(例如房产是否靠近水域以及房屋的简要说明)。
7. 使用 K-means 聚类进行模型训练
有了新扩充的数据集,您就可以构建机器学习模型了。您的目标是将房屋房源划分为不同的组,您可以通过使用 BigQuery Machine Learning (BQML) 直接在 BigQuery 中训练 k-means 聚类模型来实现此目标。作为此单个步骤的一部分,您还会在 Agent Platform AI Model Registry 中注册该模型,使其在 Google Cloud 上更广泛的 MLOps 生态系统中立即可用。
如需确认模型已成功注册,您可以按照以下步骤在 Agent Platform Model Registry 中找到该模型:
- 在 Google Cloud 控制台中,点击左上角的导航菜单 (☰)。
- 滚动到 Agent Platform 部分,然后点击模型 。
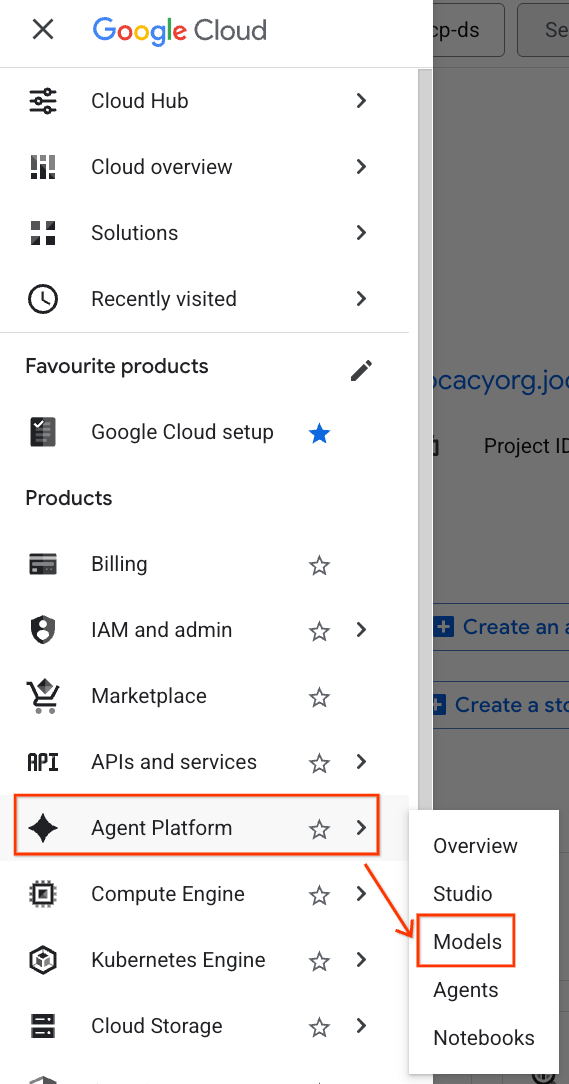
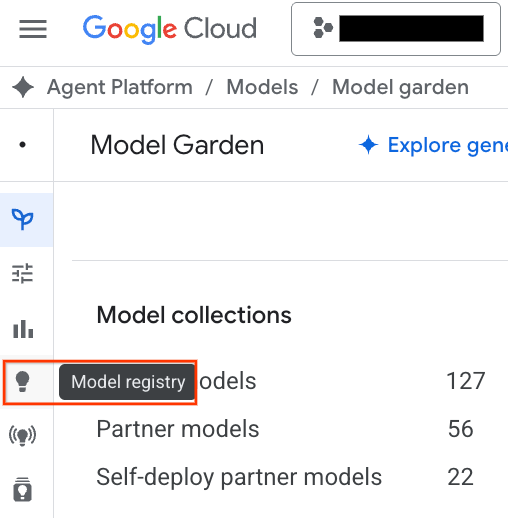
- 点击屏幕截图中突出显示的模型注册表 按钮。
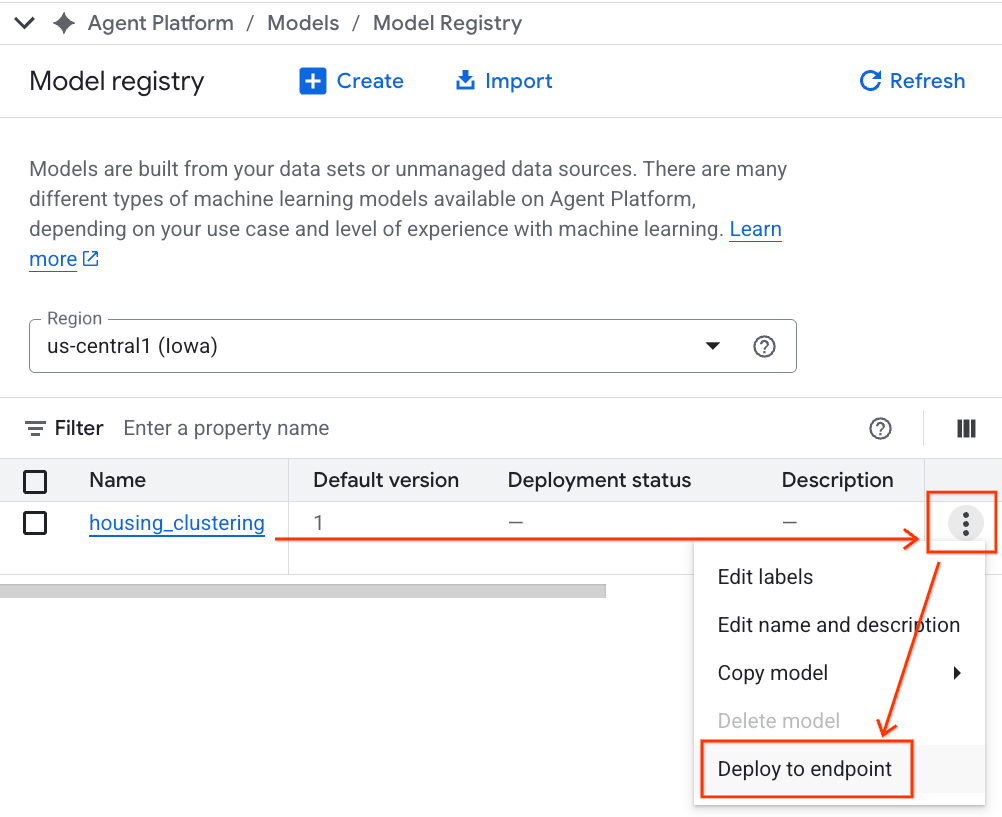
- 您将看到 BQML 模型与其他所有自定义模型一起列出。在模型列表中,找到名为 housing_clustering 的模型。您可以执行下一步部署到端点,这将使您的模型可在 BigQuery 环境之外进行实时在线预测。
探索 Model Registry 后,您可以按照以下步骤返回 BigQuery 中的 Colab 笔记本:
- 在导航菜单 (☰) 中,依次前往 BigQuery > Studio 。
- 展开探索 窗格中的菜单,找到您的笔记本并将其打开。
8. 模型评估和预测
训练模型后,下一步是了解模型创建的集群。在这里,您将使用 BigQuery Machine Learning 函数(例如 ML.EVALUATE 和 ML.CENTROIDS)来分析模型的质量以及每个细分受众群的定义特征。
然后,您将使用 ML.PREDICT 将每个房屋分配给一个集群。通过使用 %%bigquery df 魔法命令运行此查询,您可以将结果存储在名为 df 的 Pandas DataFrame 中。这样一来,数据便可立即用于后续的 Python 步骤。这突显了 Colab Enterprise 中 SQL 和 Python 之间的互操作性。
9. 直观呈现和解读集群
现在,预测结果已加载到 DataFrame 中,您可以创建可视化图表,让数据更加生动。在本部分中,您将使用热门 Python 库(例如 Matplotlib)来探索房屋细分受众群之间的差异。
您将创建箱线图和条形图,以直观地比较价格和房产年龄等关键特征,从而轻松直观地了解每个集群。
10. 使用 Gemini 模型生成集群说明
虽然数值形心和图表功能强大,但生成式 AI 可让您更进一步,为每个房屋细分受众群创建丰富且定性的用户画像。这有助于您了解集群不仅是 什么 ,而且还代表 谁 。
在本部分中,您将首先汇总每个集群的平均统计信息,例如价格和平方英尺。然后,您将此数据传递给 Gemini 模型的提示。接下来,您将指示模型充当房地产专业人士,并生成详细摘要,包括每个细分受众群的关键特征和目标买家。结果是一组清晰且人类可读的说明,使营销团队能够立即了解集群并采取行动。
您可以根据需要随意更改提示,并尝试不同的结果!
11. 使用数据科学智能体自动执行建模
现在,您将探索一个强大的替代工作流。您将使用集成的 数据科学智能体,而不是手动编写代码,从单个自然语言提示自动生成完整的聚类模型工作流。
按照以下步骤使用智能体生成和运行模型:
- 在 BigQuery Studio 窗格中,点击下拉箭头按钮,将鼠标悬停在 笔记本 上,然后选择 空笔记本 。这样可确保智能体的代码不会干扰您的原始实验笔记本。
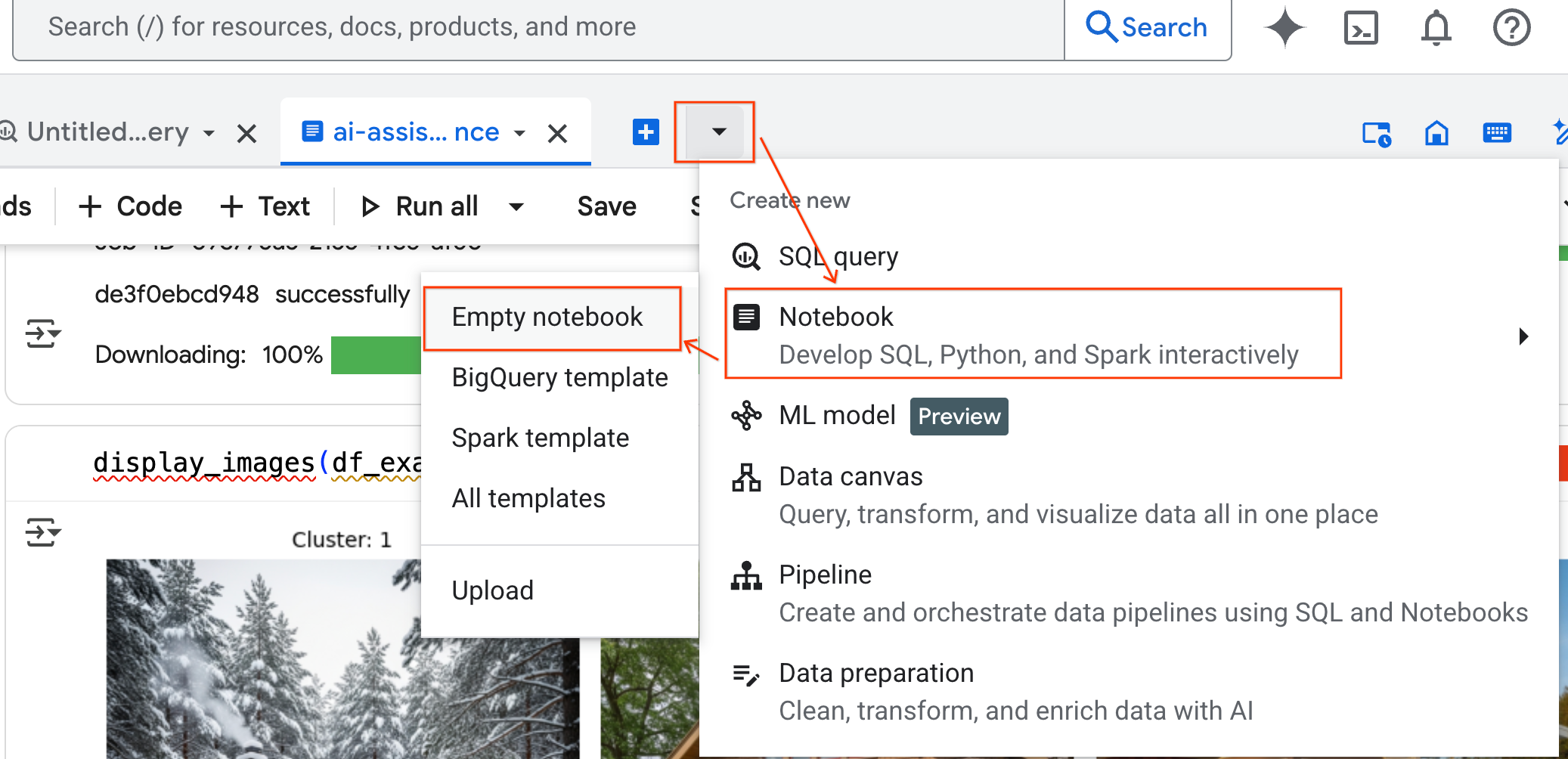
- 数据科学智能体聊天界面会在笔记本底部打开。点击移至面板 按钮,将聊天固定到右侧。
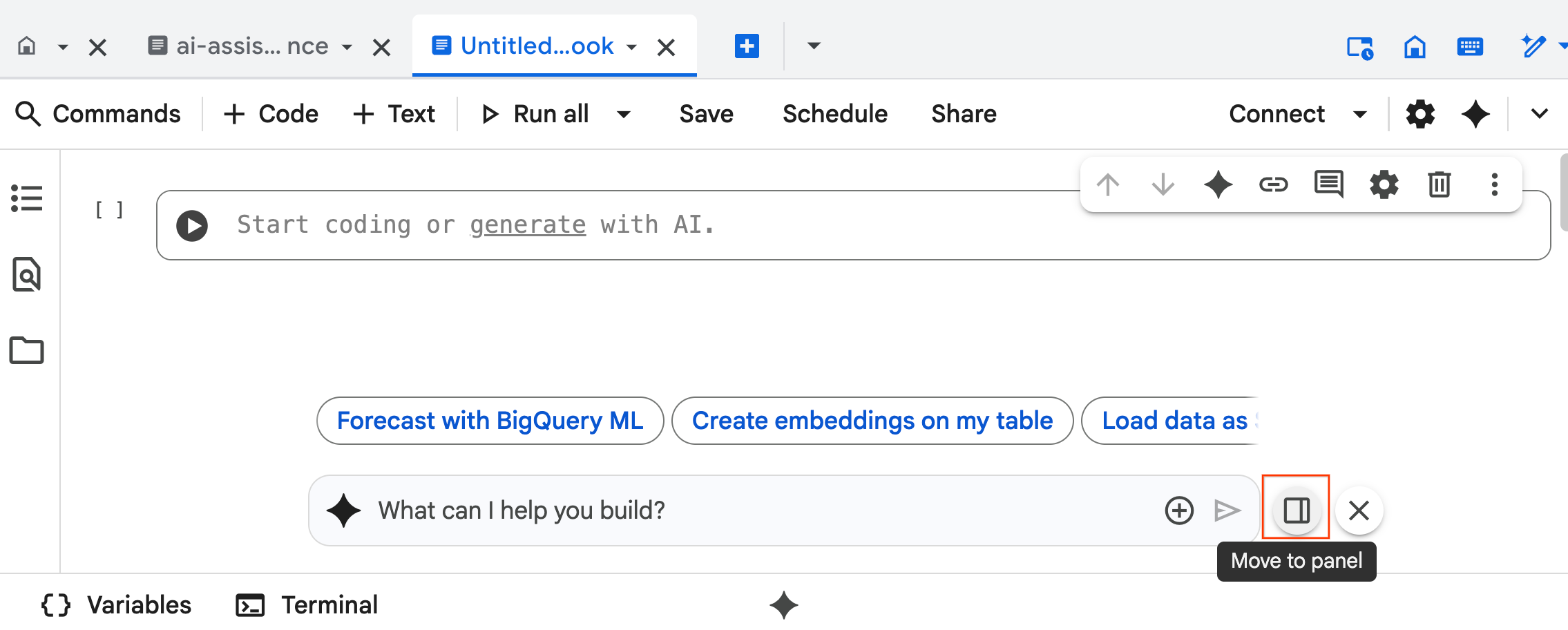
- 在聊天窗格中开始输入
@listing_multimodal,然后点击 表格。这会明确将listings_multimodal表设置为上下文。
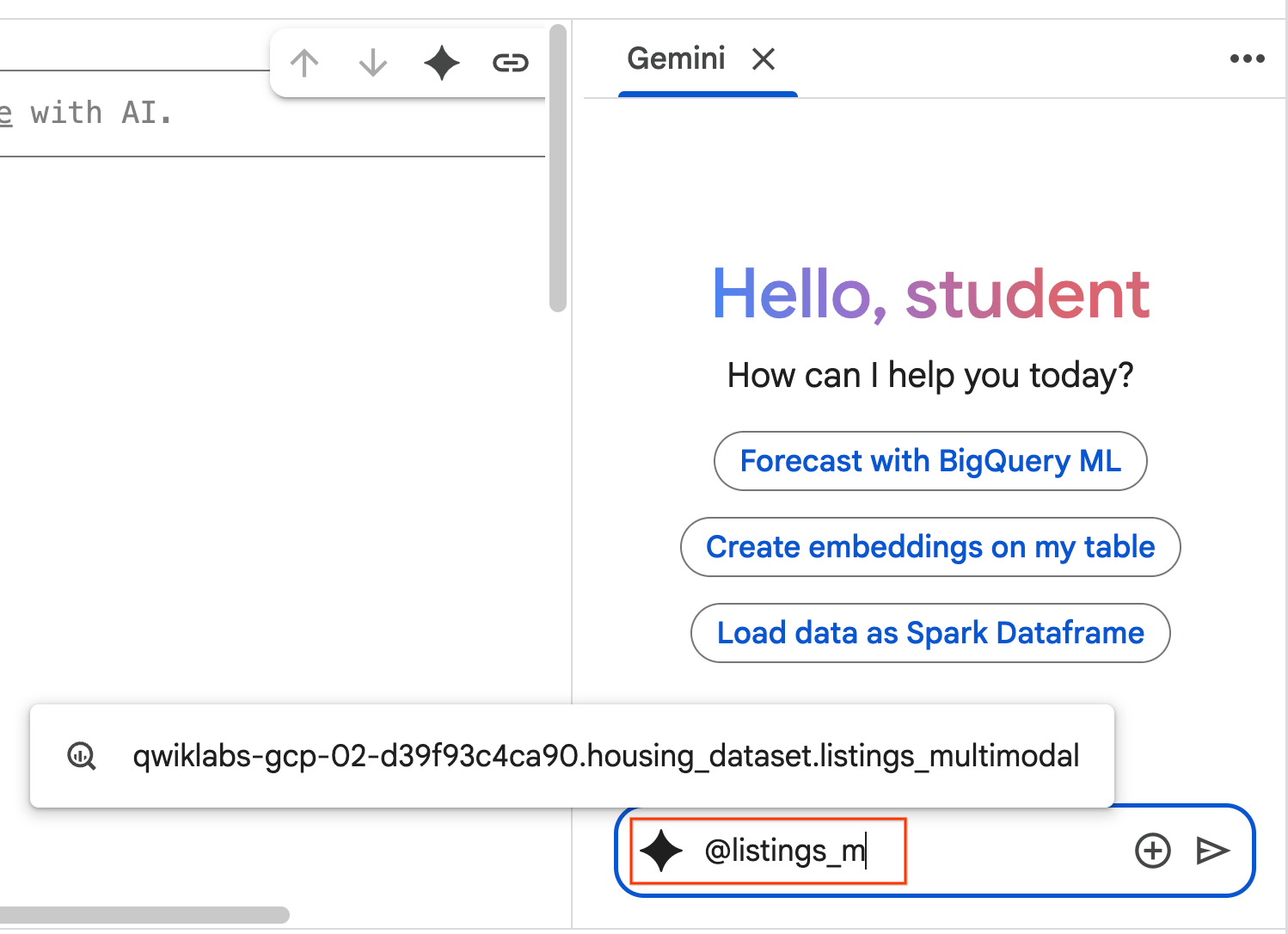
- 复制下面的提示,然后将其输入到智能体聊天框中。之后,点击发送 以将提示提交给智能体。
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
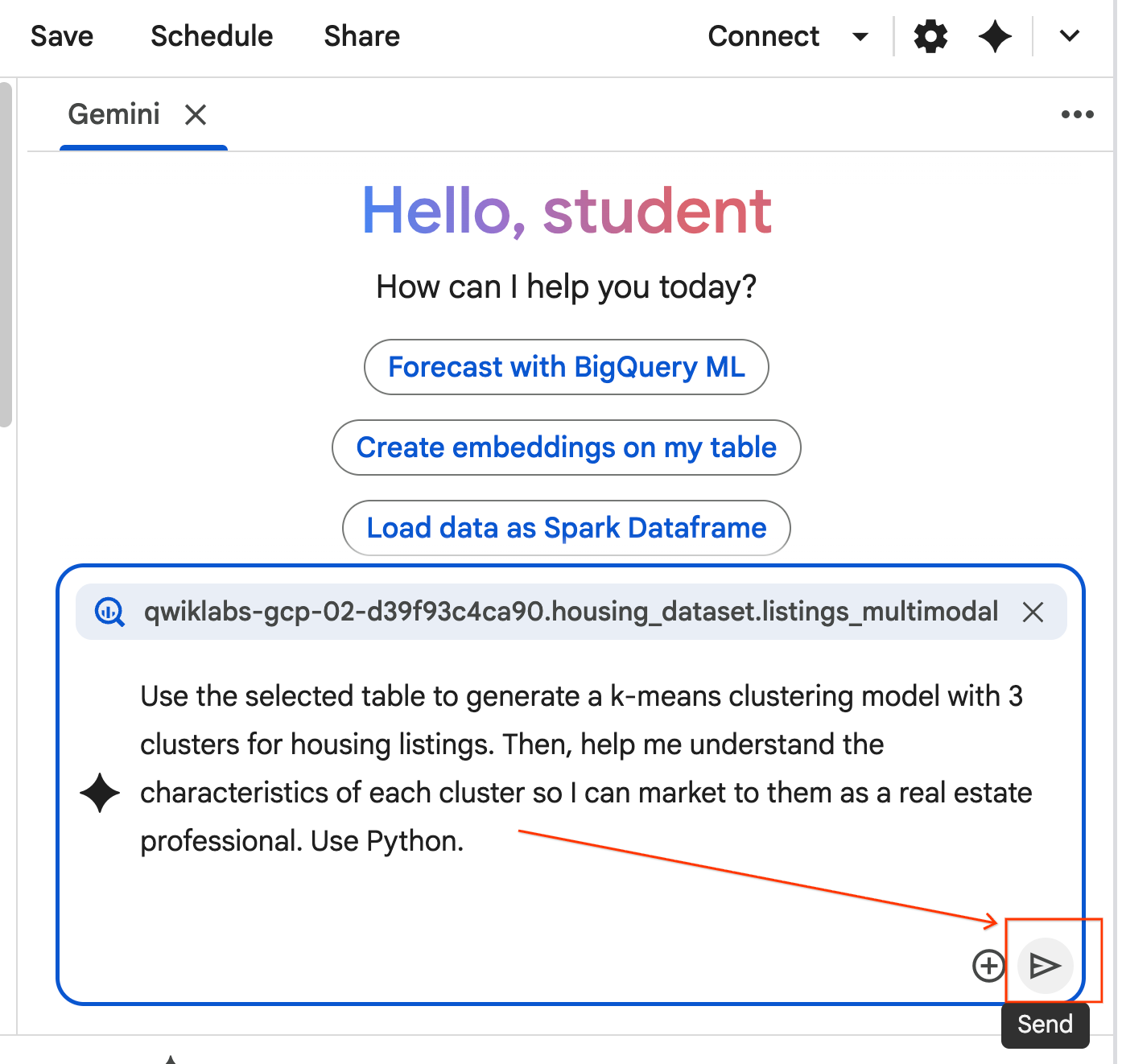
- 智能体会进行思考并制定计划。如果您对该计划没有异议,请点击接受并运行 。智能体将在一个或多个新单元格中生成 Python 代码。
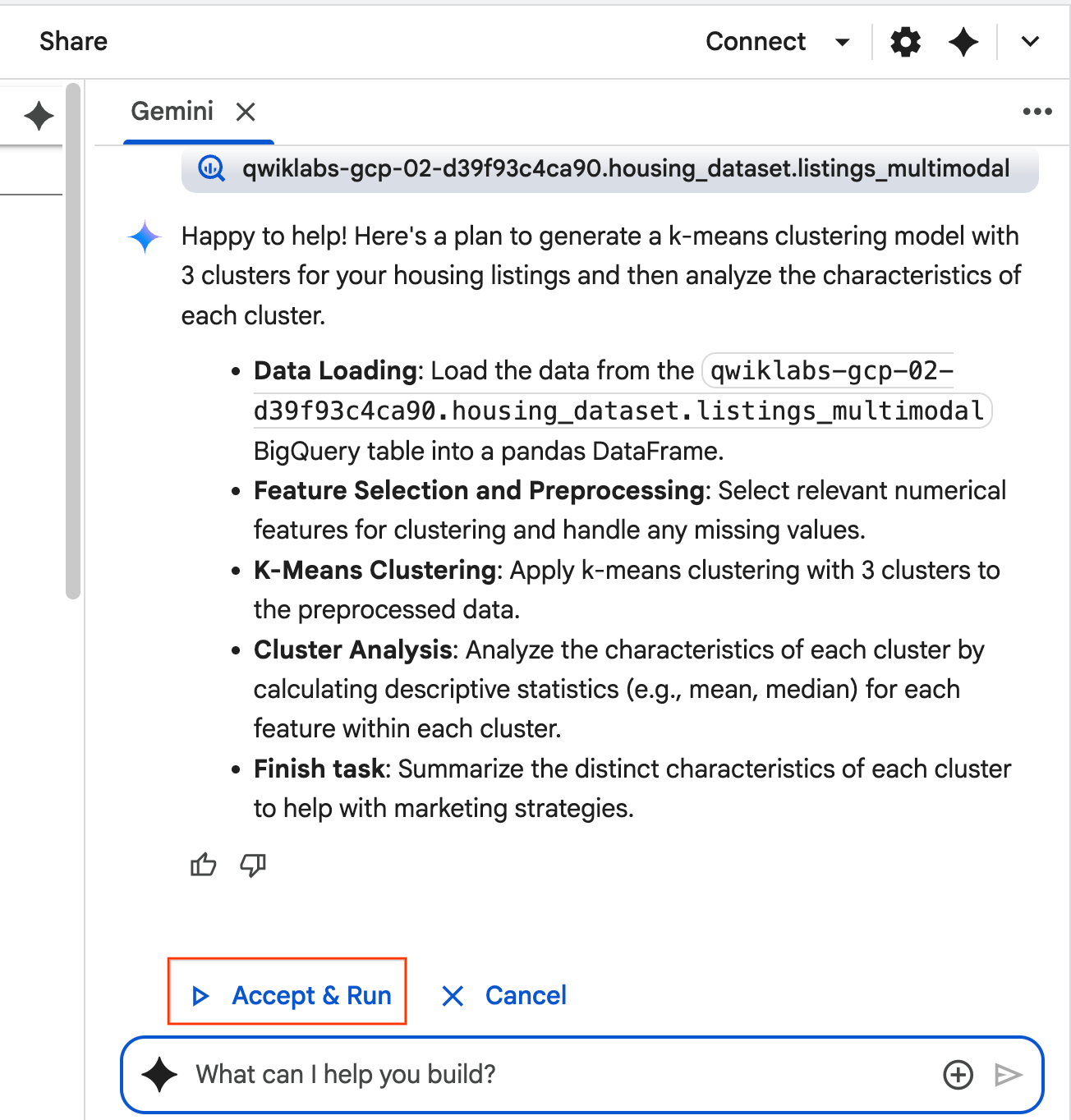
- 智能体会要求您接受并运行 它生成的每个代码块。这样可以保持人机协同。您可以随意查看或修改代码,并继续完成每个步骤,直到完成为止。
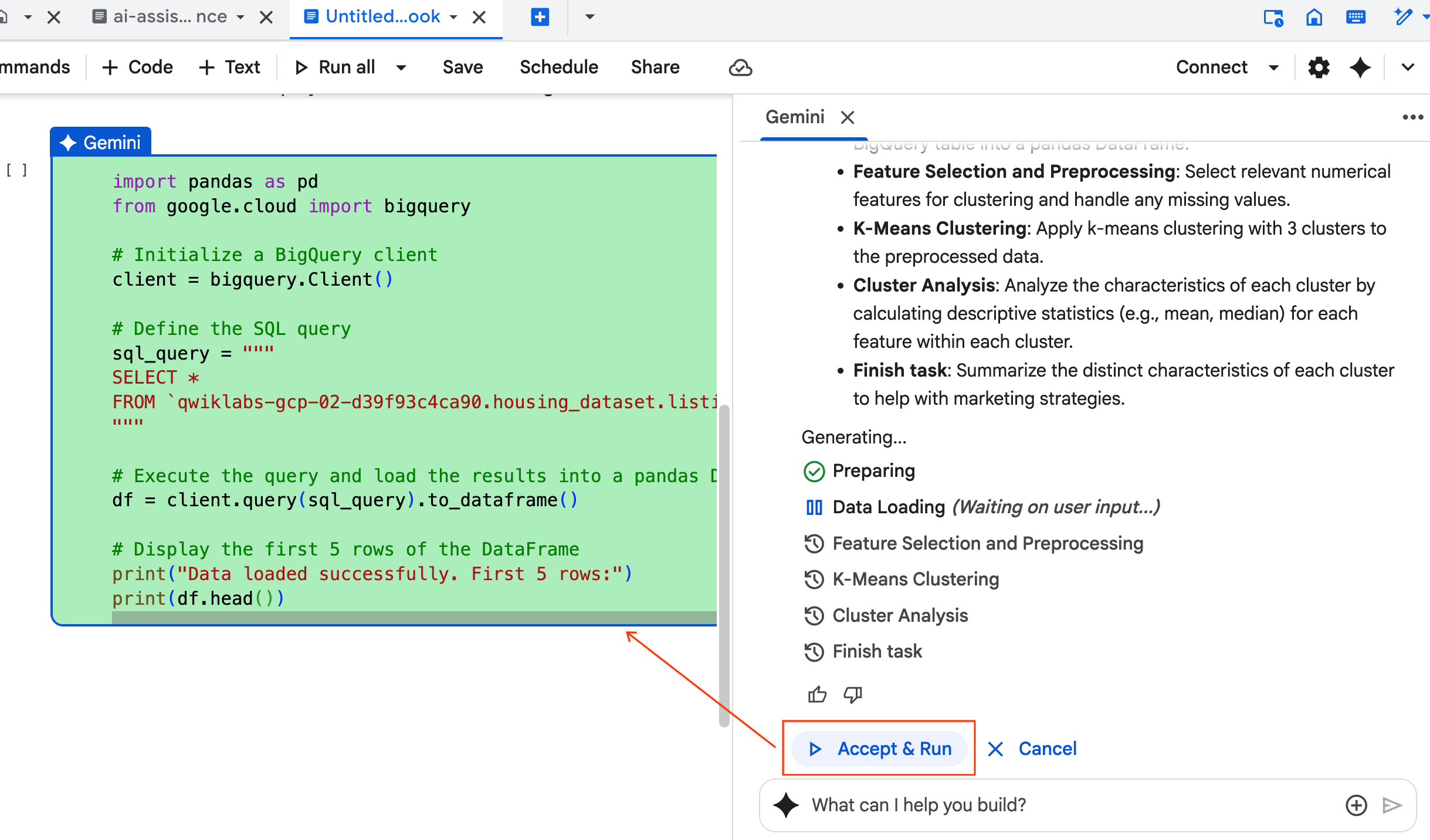
- 完成后,只需关闭此新笔记本标签页,然后返回原始
ai-assisted-data-science.ipynb标签页,继续完成实验的最后一部分。
12. 使用嵌入和向量搜索进行多模态搜索
在最后一部分中,您将直接在 BigQuery 中实现多模态搜索。这样可以进行直观的搜索,例如根据文本说明查找房屋,或查找看起来与示例图片相似的房屋。
该过程的工作原理是首先将每个房屋图片转换为数值表示形式,称为嵌入。嵌入可捕获图片的语义含义,让您可以通过比较数值向量来查找相似项。
您将使用 multimodalembedding 模型 为所有房源生成这些向量。创建向量索引以加快查找速度后,您将执行两种类型的相似性搜索:文生图(查找与说明匹配的房屋)和图片到图片(查找看起来与示例图片相似的房屋)。
您将在 BigQuery 中完成所有这些操作,使用 ML.GENERATE_EMBEDDING 等函数生成嵌入,或使用 VECTOR_SEARCH 进行相似性搜索。
13. 清理
如需清理此项目中使用的所有 Google Cloud 资源,您可以删除 Google Cloud 项目。
或者,您也可以通过在笔记本的新单元格中运行以下代码来删除您创建的各个资源:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
最后,您可以删除笔记本本身:
- 在 BigQuery Studio 的探索器 窗格中,展开您的项目和笔记本 节点。
- 点击
ai-assisted-data-science笔记本旁边的三个垂直点。 - 选择删除 。
14. 恭喜!
恭喜您完成此 Codelab!
所学内容
- 准备原始数据集 ,其中包含房地产房源,以便通过特征工程进行分析。
- 使用 BigQuery 的 AI 函数分析房屋照片,以获取关键视觉特征,从而扩充房源 。
- 使用 BigQuery Machine Learning (BQML) 构建和评估 K-means 模型,将房产划分为不同的集群。
- 使用数据科学智能体生成 Python 聚类模型,从而自动创建模型 。
- 为房屋图片生成嵌入 ,以支持视觉搜索工具,通过文本或图片查询查找相似的房屋。