
1. 簡介
總覽
在本實驗室中,您將以房地產情境為架構,在 BigQuery 中探索多模態資料科學工作流程。您會先取得房屋資訊和圖片的原始資料集,然後使用 AI 擷取視覺特徵來擴充資料、建構分群模型來發掘不同的市場區隔,最後使用向量嵌入建立強大的影像搜尋工具。
您將使用 資料科學代理,透過簡單的文字提示自動生成以 Python 為基礎的分群模型,並比較這個 SQL 原生工作流程與現代生成式 AI 方法。
課程內容
- 準備房地產資訊的原始資料集,透過特徵工程進行分析。
- 使用 BigQuery 的 AI 函式分析房屋相片,找出主要視覺特徵,豐富房源資訊。
- 建構及評估 BigQuery Machine Learning (BQML) 的 K-means 模型,將房源劃分為不同群組。
- 使用資料科學代理程式以 Python 產生叢集模型,自動建立模型。
- 生成房屋圖片的嵌入內容,為影像搜尋工具提供支援,透過文字或圖片查詢尋找相似房屋。
必要條件
進入這個實驗室前,您應已熟悉下列概念:
- 基本的 SQL 和 Python 程式設計。
- 在 Jupyter 筆記本執行 Python 程式碼。
2. 事前準備
建立 Google Cloud 專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
使用 Cloud Shell 啟用 API
Cloud Shell 是在 Google Cloud 中運作的指令列環境,已預先載入必要工具。
- 在 Google Cloud 控制台頂端點選「啟用 Cloud Shell」:

- 連線至 Cloud Shell 後,請執行下列指令,在 Cloud Shell 中驗證您的身分:
gcloud auth list
- 執行下列指令,確認專案已設定為搭配 gcloud 使用:
gcloud config list project
- 如果未設定專案,請使用下列指令來設定:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
啟用 API
- 執行下列指令,啟用所有必要 API 和服務:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- 成功執行指令後,您應該會看到類似下方的訊息:
Operation "operations/..." finished successfully.
- 退出 Cloud Shell。
3. 在 BigQuery Studio 開啟實驗室筆記本
瀏覽使用者介面:
- 在 Google Cloud 控制台中,依序前往「導覽選單」 >「BigQuery」。
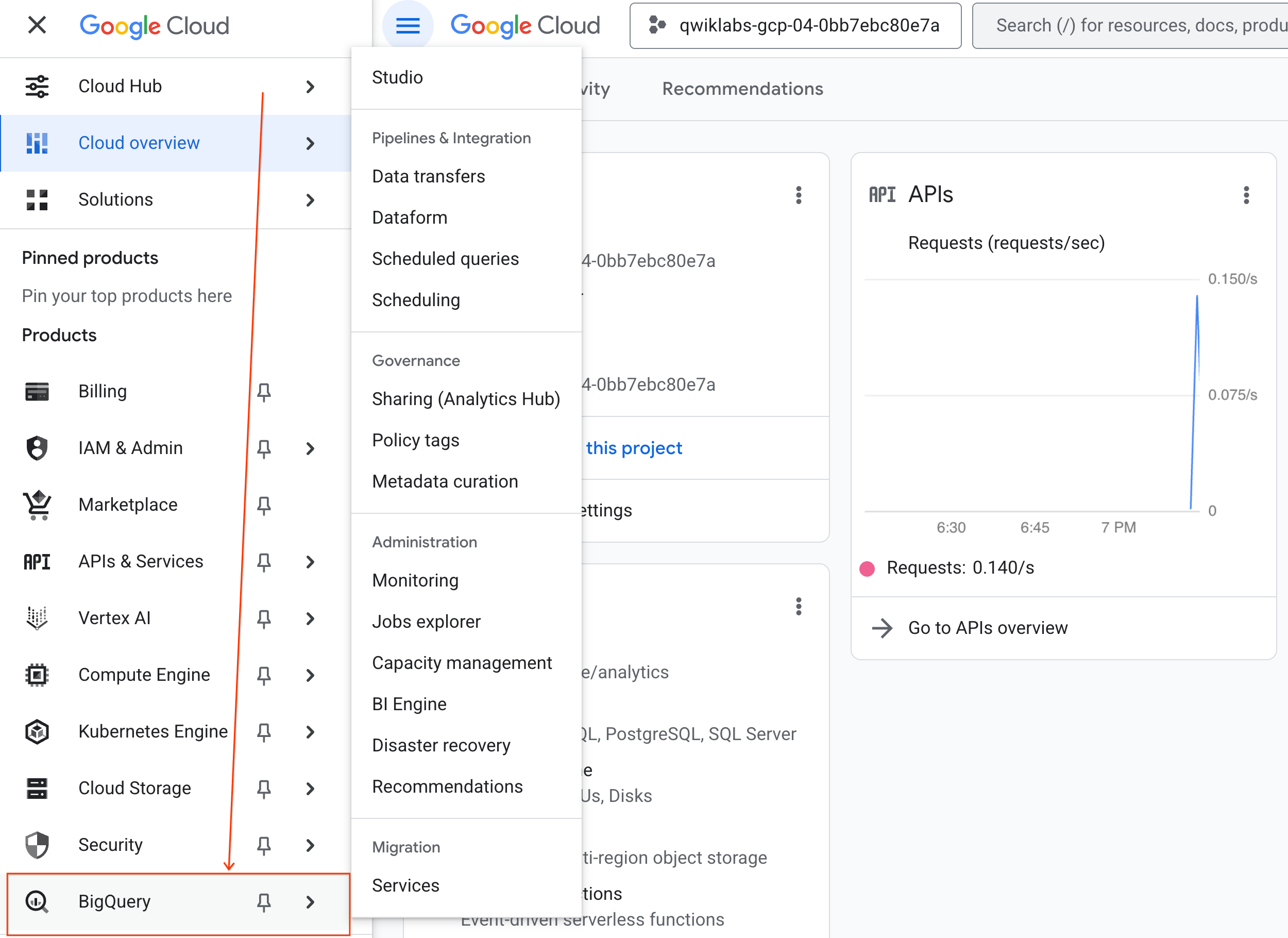
- 在「BigQuery Studio」窗格中,按一下下拉式箭頭按鈕,將游標懸停在「筆記本」上,然後選取「上傳」。
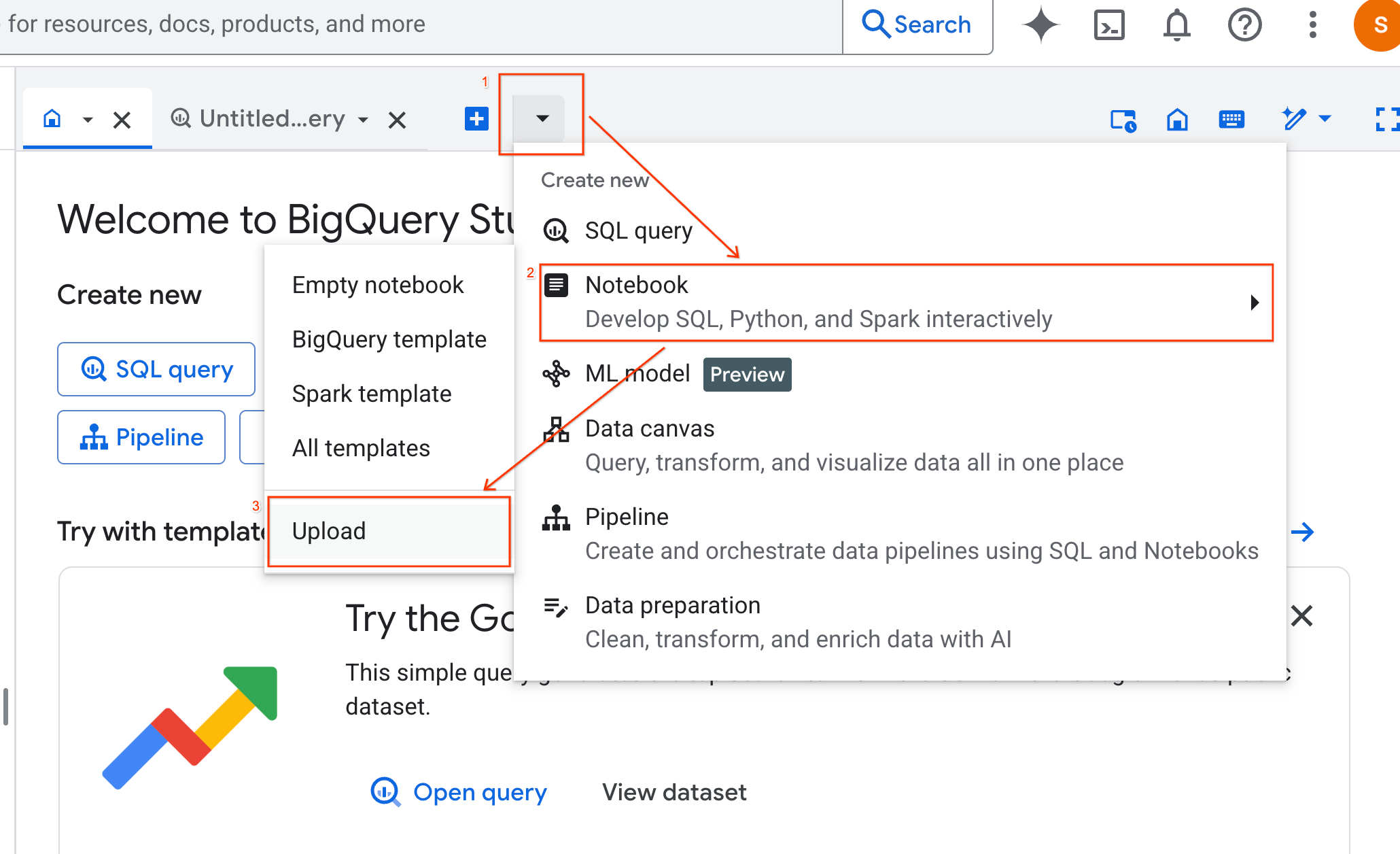
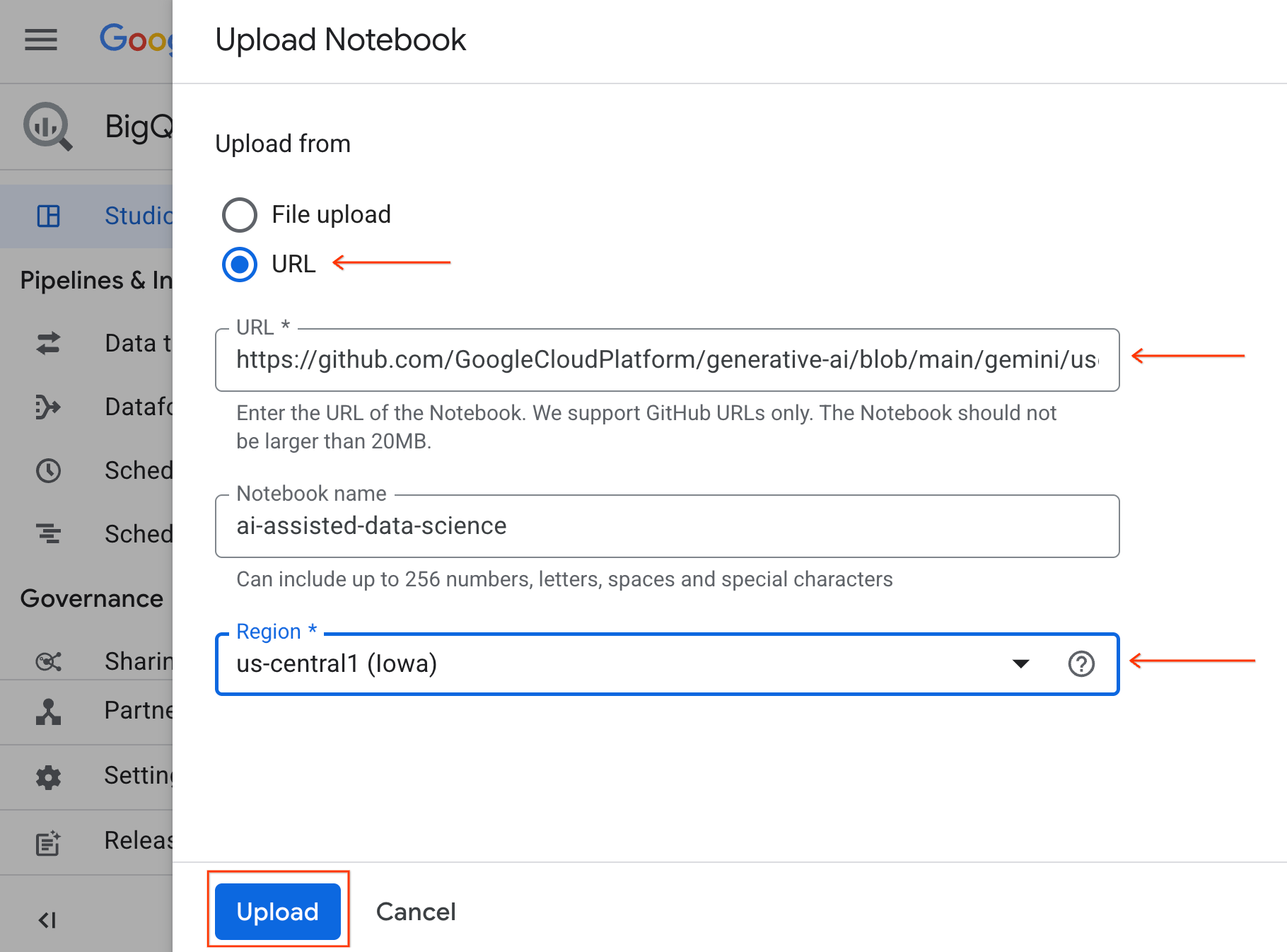
- 選取「網址」圓形按鈕,然後輸入下列網址:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- 將區域設為
us-central1,然後按一下「上傳」。
- 如要開啟筆記本,請點選「Explorer」窗格中包含專案 ID 的下拉式箭頭。然後點選「筆記本」的下拉式選單。按一下筆記本
ai-assisted-data-science。
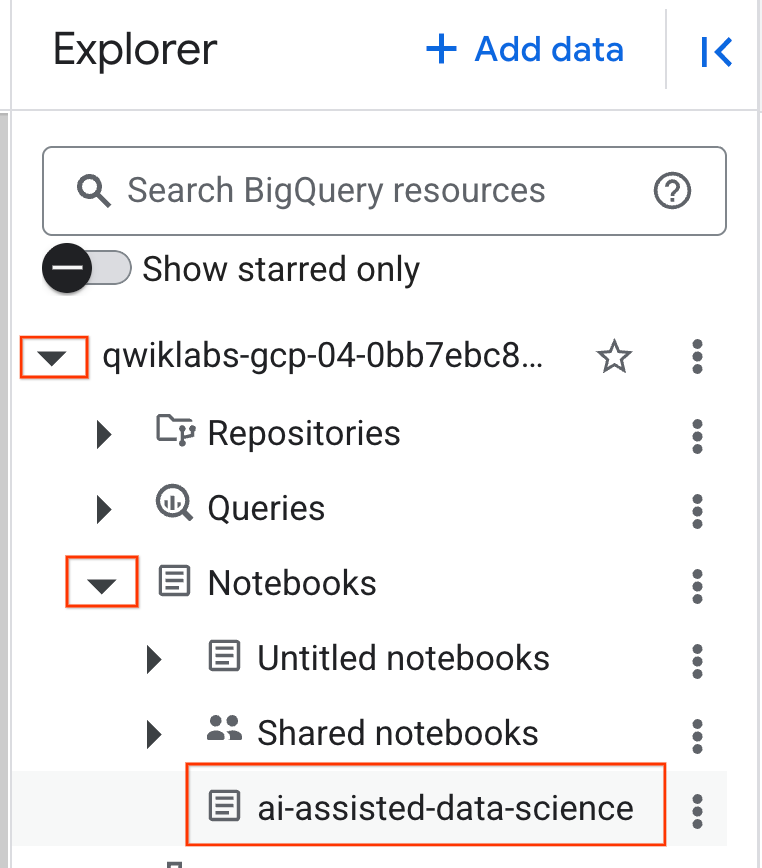
- (選用) 收合 BigQuery 導覽選單和 Notebook 的目錄,爭取更多空間。
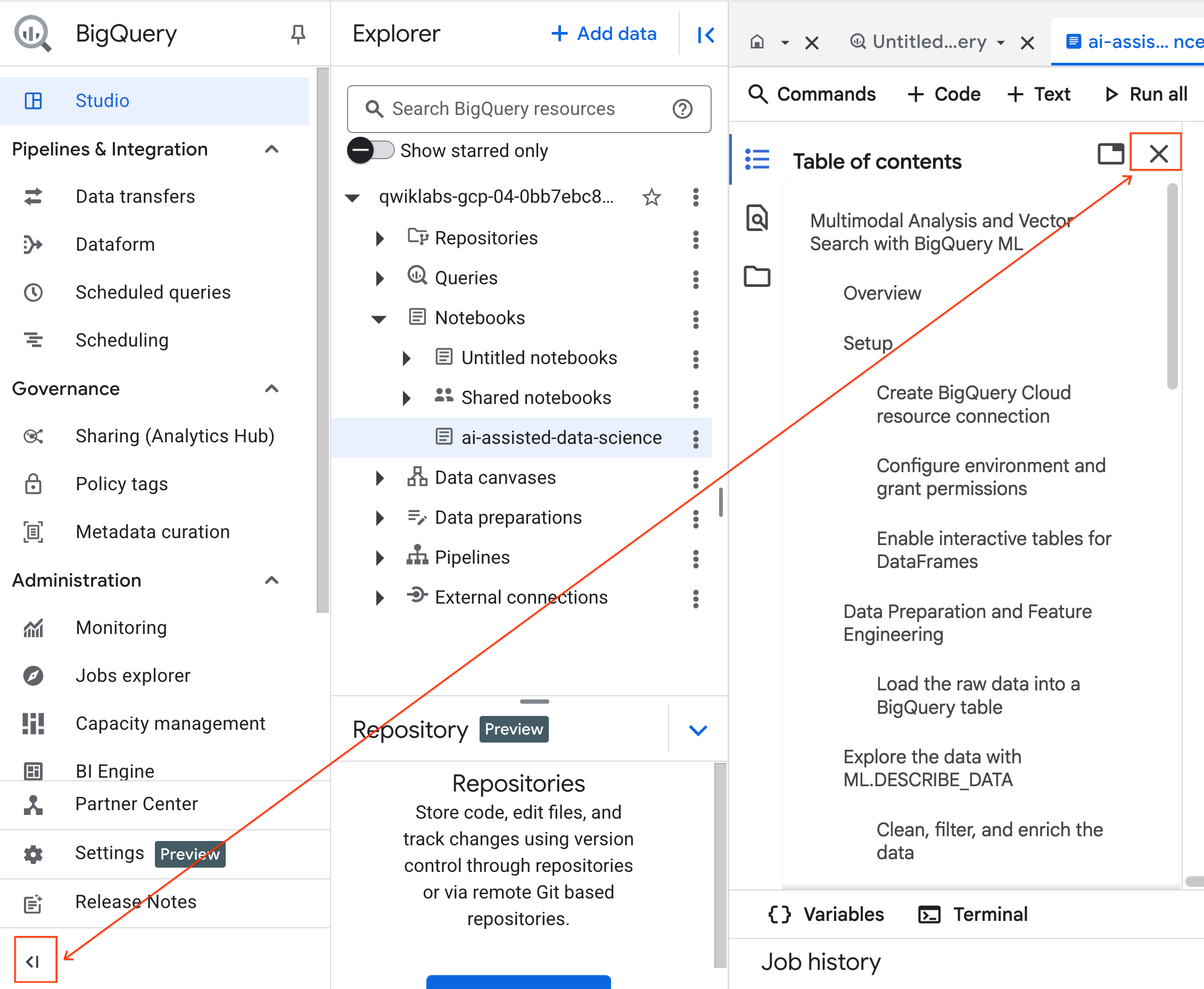
4. 連線至執行階段並執行設定程式碼
- 按一下「連結」,如果出現彈出式視窗,請使用您的使用者授權 Colab Enterprise。筆記本會自動連線至執行階段。這項作業可能需要幾分鐘才能完成。
- 建立執行階段後,您會看到下列內容:
- 在筆記本中,捲動至「設定」部分。按一下隱藏儲存格旁的「執行」按鈕。這會在專案中建立實驗室所需的幾項資源。這項程序可能需要一分鐘才能完成。在此期間,歡迎查看「設定」下方的儲存格。
5. 資料準備與特徵工程
在本節中,您將完成資料科學專案的第一個重要步驟:準備資料。首先,請建立 BigQuery 資料集來整理工作,然後將 Cloud Storage 中 CSV 檔案的原始房地產 / 房屋資料載入新資料表。
接著,您會將原始資料轉換為含有新特徵的清理後資料表。包括篩選房源資訊、建立新的 property_age 特徵,以及準備用於多模態分析的圖片資料。
6. 使用 AI 函式進行多模態擴充
現在,您將運用生成式 AI 的強大功能充實資料。在本節中,您會使用 BigQuery 的內建 AI 函式分析每個房屋物件的圖片。
將 BigQuery 連結至 Gemini 模型,即可直接透過 SQL 從圖片中擷取新的實用特徵 (例如房產是否靠近水域,以及房屋的簡短說明)。
7. 使用 K-means 分群模型訓練模型
現在您已擁有經過擴增的資料集,可以開始建構機器學習模型。您的目標是將房屋物件分成不同群組,方法是使用 BigQuery 機器學習 (BQML) 直接在 BigQuery 中訓練 k-means 分群模型。在這個單一步驟中,您也會在 Agent Platform AI Model Registry 中註冊模型,讓模型立即在 Google Cloud 的廣泛 MLOps 生態系統中可用。
如要確認模型是否已成功註冊,請按照下列步驟在 Agent Platform Model Registry 中尋找模型:
- 前往 Google Cloud 控制台,點選左上角的「導覽選單」圖示 (☰)。
- 捲動至「代理程式平台」部分,然後點選「模型」。
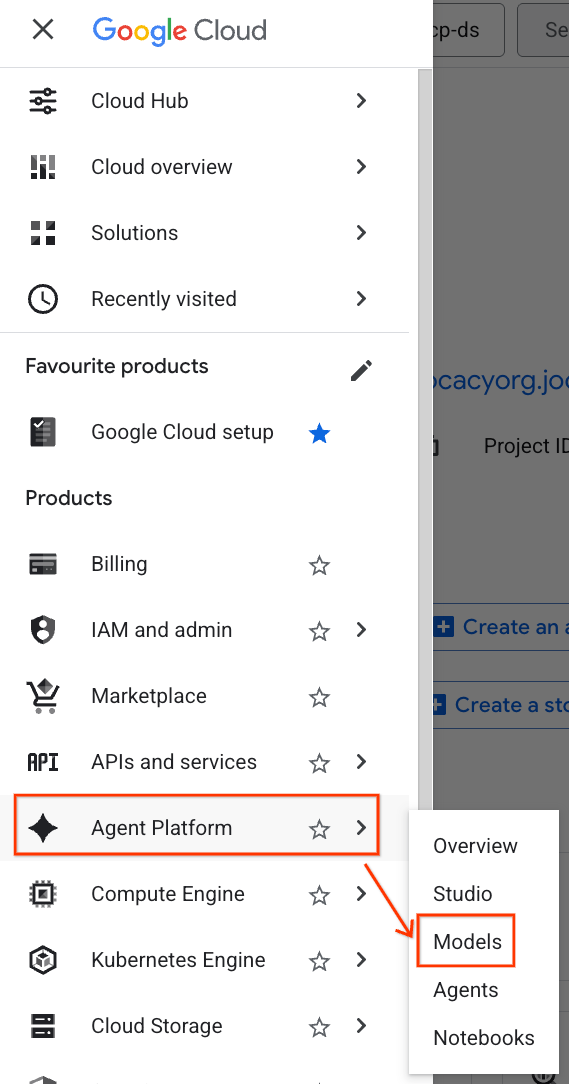
- 按一下螢幕截圖中標示的「Model Registry」按鈕。
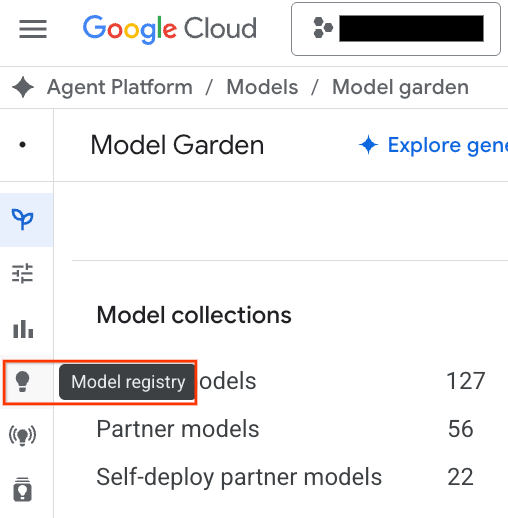
- 您會看到 BQML 模型與所有其他自訂模型一起列出。在模型清單中,找出名為「housing_clustering」housing_clustering的模型。您可以採取下一步,部署至端點,讓模型在 BigQuery 環境以外提供即時線上預測。
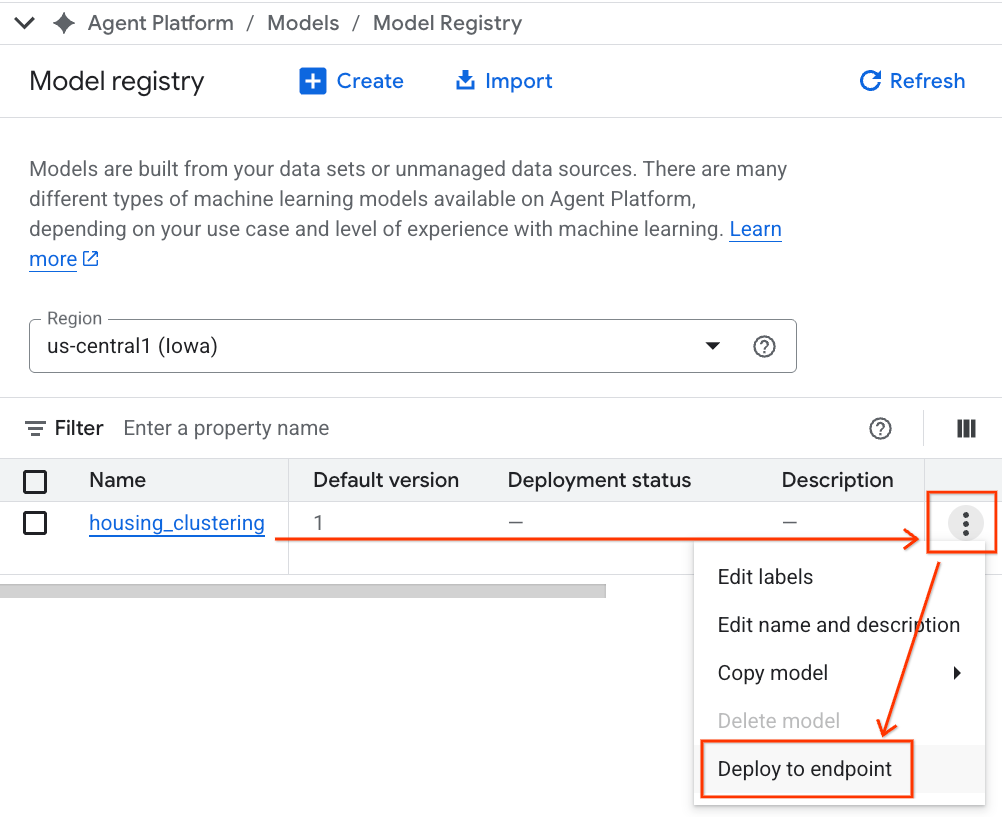
探索 Model Registry 後,您可以按照下列步驟返回 BigQuery 中的 Colab 筆記本:
- 在「導覽選單」 (☰) 中,依序前往「BigQuery」 >「Studio」。
- 展開「探索」窗格中的選單,找出並開啟筆記本。
8. 模型評估與預測
訓練模型後,下一步是瞭解模型建立的叢集。您可以使用 ML.EVALUATE 和 ML.CENTROIDS 等 BigQuery 機器學習函式,分析模型的品質和各區隔的定義特徵。
然後使用 ML.PREDICT 將每個住家指派給叢集。使用 %%bigquery df magic 指令執行這項查詢,即可將結果儲存在名為 df 的 pandas DataFrame 中。這樣一來,後續的 Python 步驟就能立即使用資料。這凸顯了 Colab Enterprise 中 SQL 和 Python 之間的互通性。
9. 視覺化及解讀叢集
預測結果現在已載入 DataFrame,您可以建立視覺化效果,讓資料變得生動有趣。在本節中,您將使用 Matplotlib 等熱門 Python 程式庫,探索不同房屋區隔之間的差異。
您將建立盒鬚圖和長條圖,以視覺化方式比較價格和房產屋齡等重要特徵,輕鬆直覺地瞭解每個叢集。
10. 使用 Gemini 模型生成叢集說明
雖然數值重心和圖表功能強大,但生成式 AI 可讓您更進一步,為每個房屋區隔建立豐富的質性人物角色。這有助於瞭解叢集內容,以及叢集代表的對象。
在本節中,您會先彙整每個叢集的平均統計資料,例如價格和面積。接著,您會將這項資料傳遞至 Gemini 模型的提示。接著,指示模型扮演房地產專業人士,生成詳細摘要,包括各區隔的主要特徵和目標買家。結果會是一組清楚易懂的說明,行銷團隊可立即瞭解並採取行動。
您可以視需要修改提示,並嘗試生成結果!
11. 使用資料科學代理自動建立模型
現在,我們將探索強大的替代工作流程。您不必手動編寫程式碼,只要使用整合式 資料科學代理,就能透過單一自然語言提示,自動產生完整的叢集模型工作流程。
請按照下列步驟,使用代理程式生成及執行模型:
- 在 BigQuery Studio 窗格中,按一下下拉式箭頭按鈕,將游標懸停在「Notebook」上,然後選取「Empty Notebook」。這樣可確保代理程式的程式碼不會干擾原始實驗室筆記本。
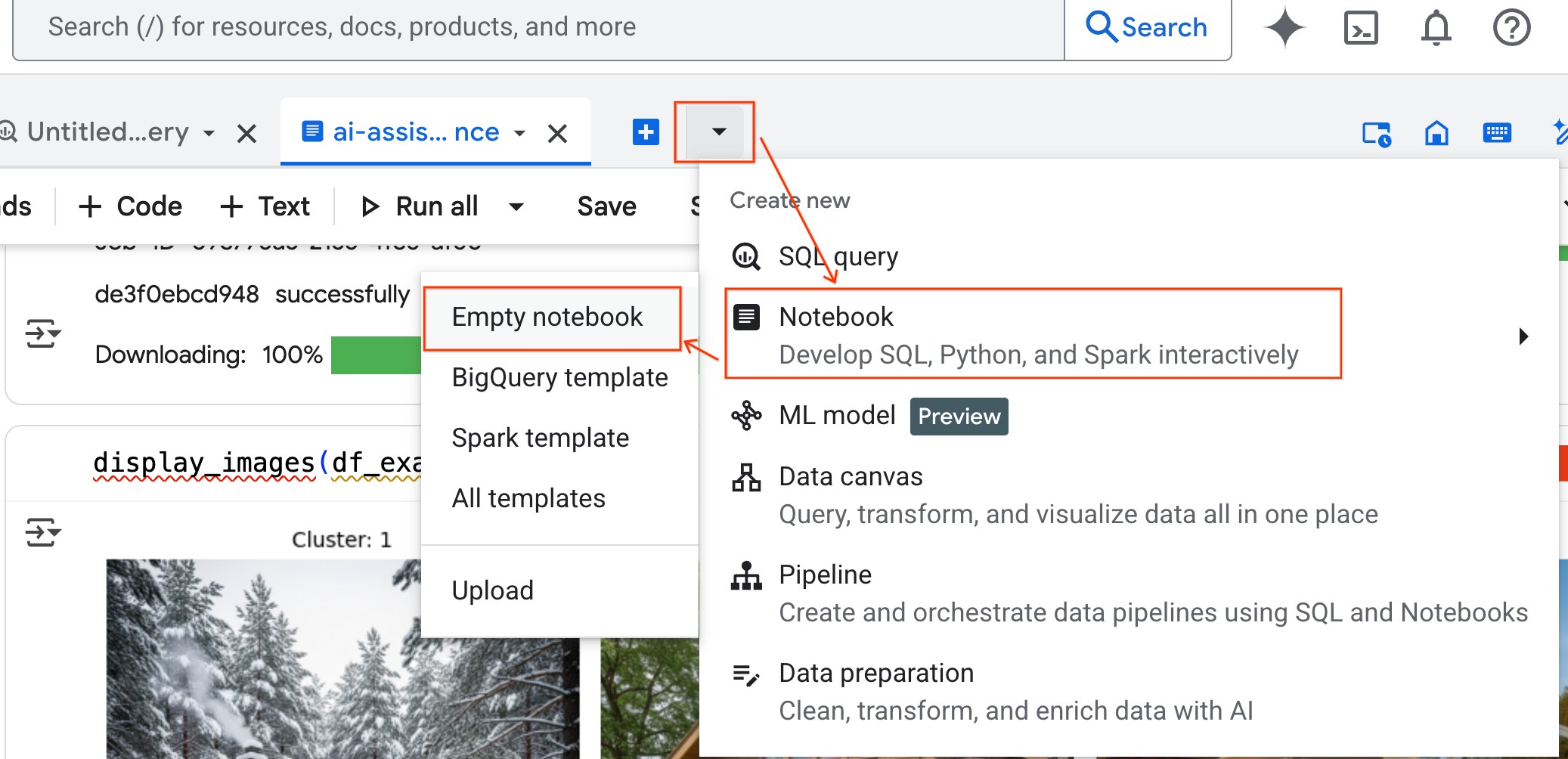
- 資料科學代理的即時通訊介面會在筆記本底部開啟。按一下「移至面板」按鈕,將對話固定在右側。
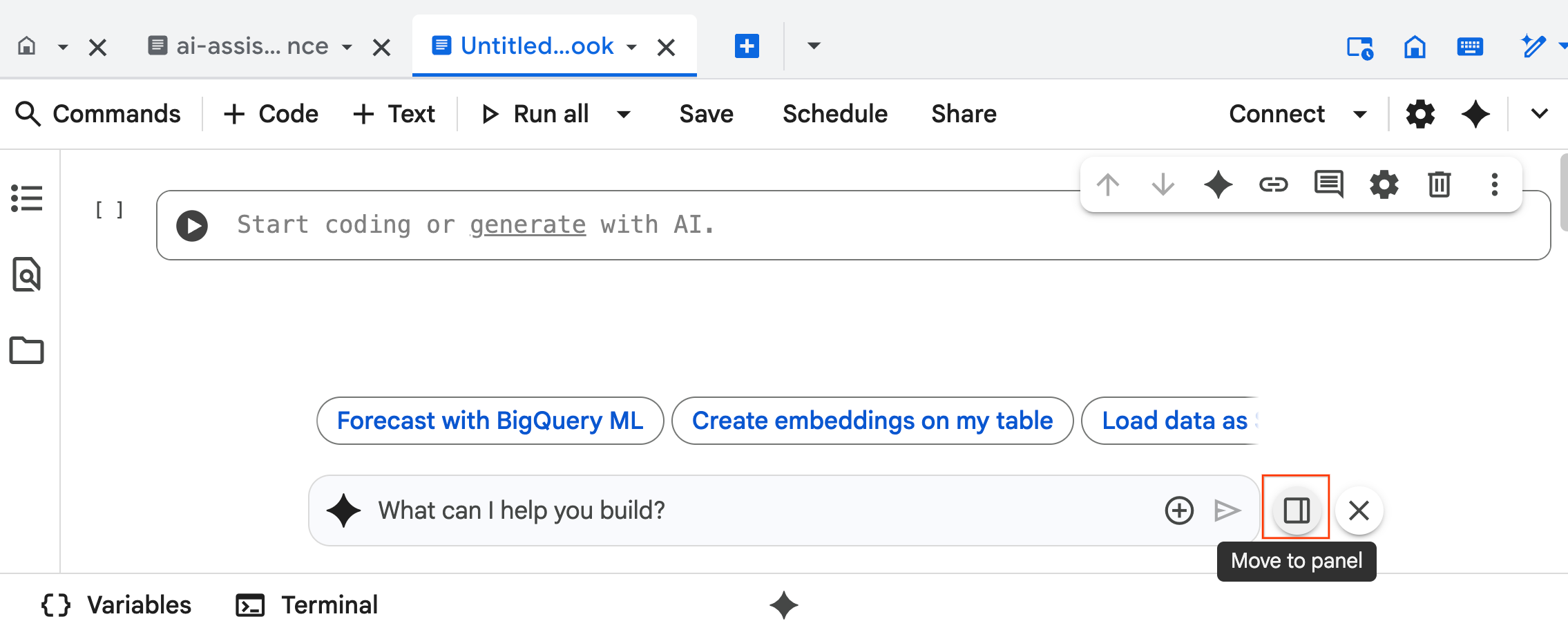
- 在即時通訊窗格中輸入
@listing_multimodal,然後按一下資料表。這會明確將listings_multimodal資料表設為脈絡。
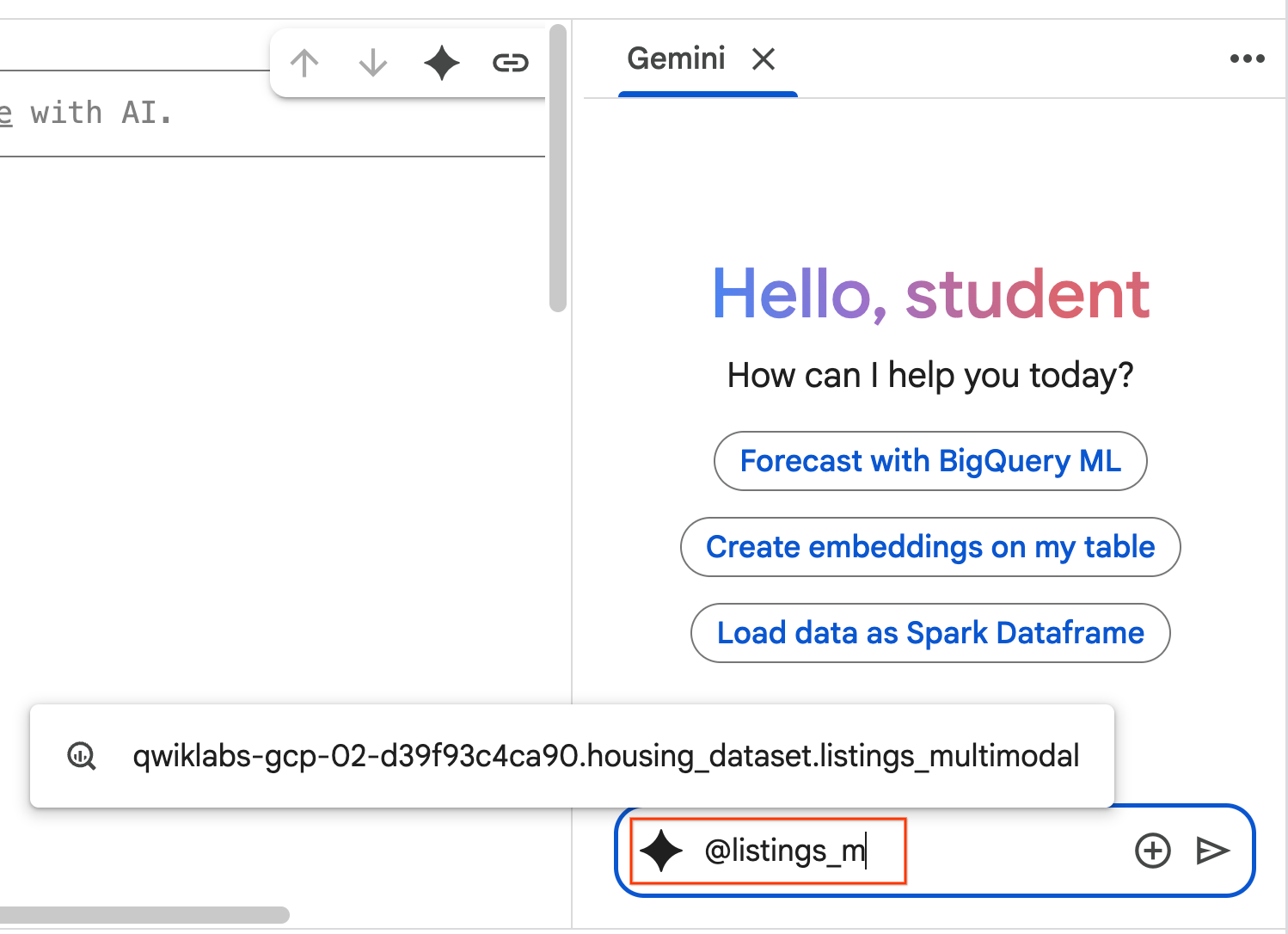
- 複製下列提示詞並輸入至 Agent Chat 方塊。然後按一下「傳送」,將提示詞提交給 Agent。
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.
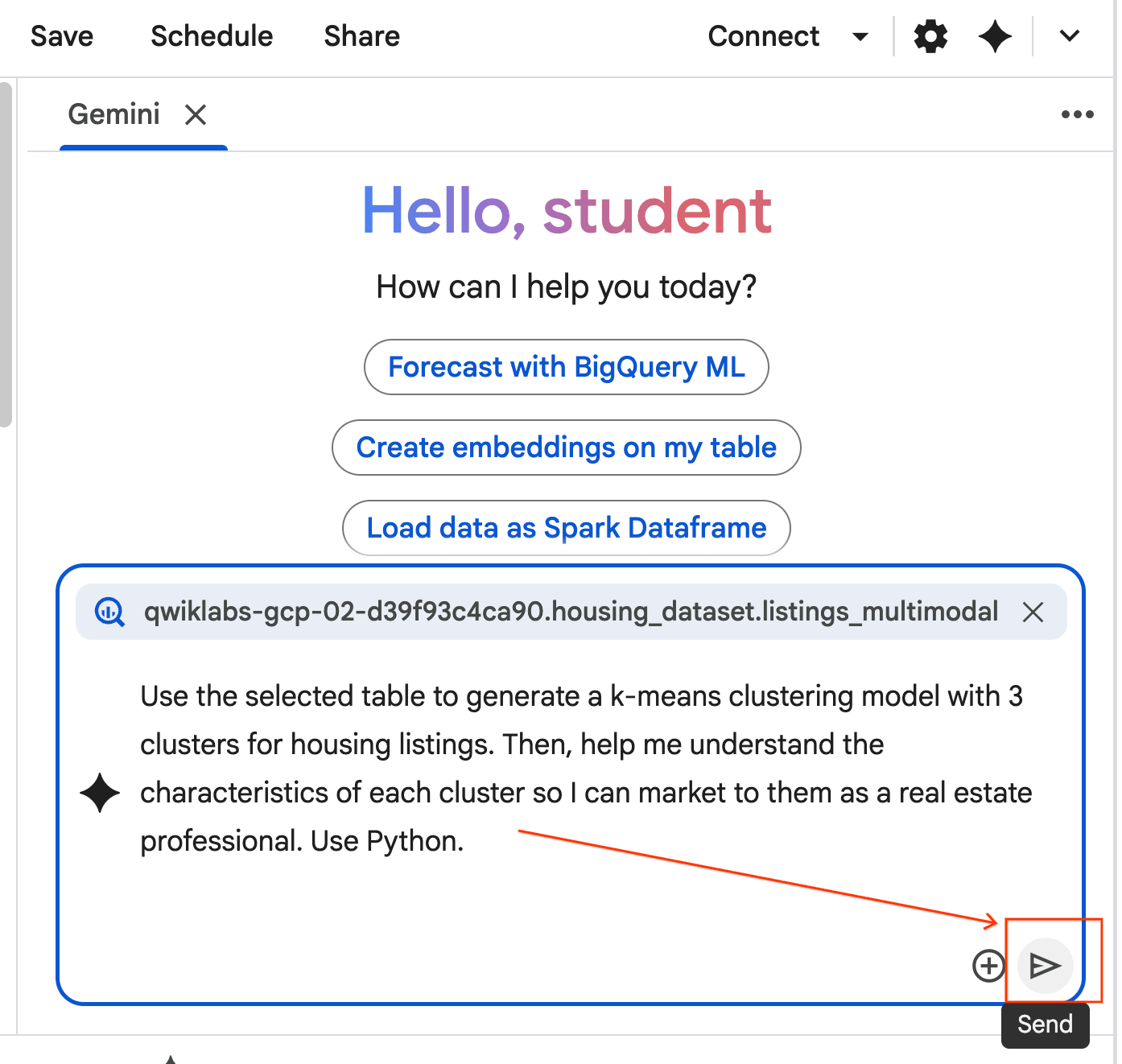
- 代理程式會思考並制定計畫。如果對這項計畫沒有異議,請按一下「接受並執行」。代理會在一個或多個新儲存格中生成 Python 程式碼。
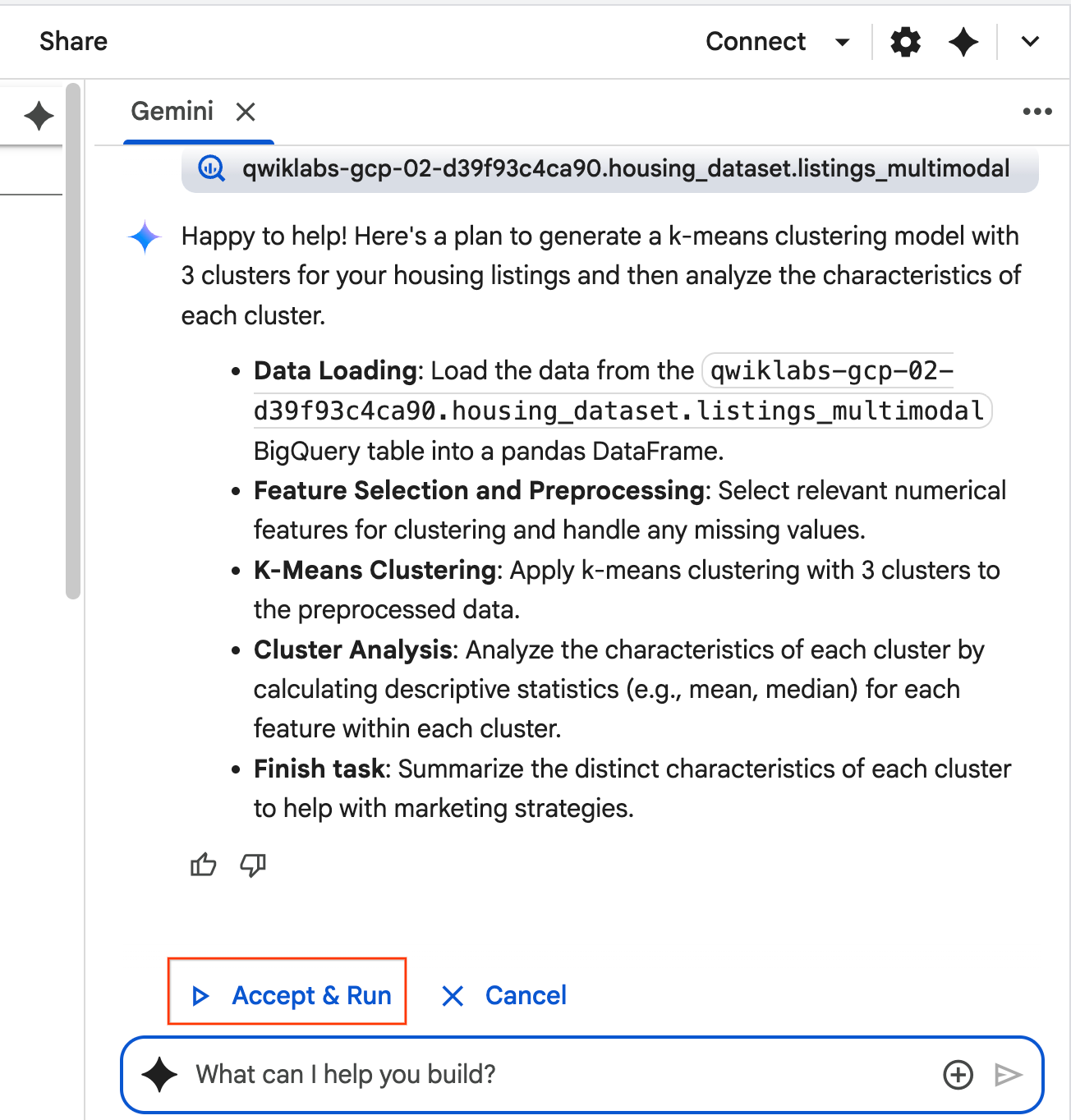
- 代理程式會要求你接受並執行生成的每個程式碼區塊。這樣一來,就能維持人機迴圈。您可以隨意檢查或編輯程式碼,並繼續完成每個步驟。
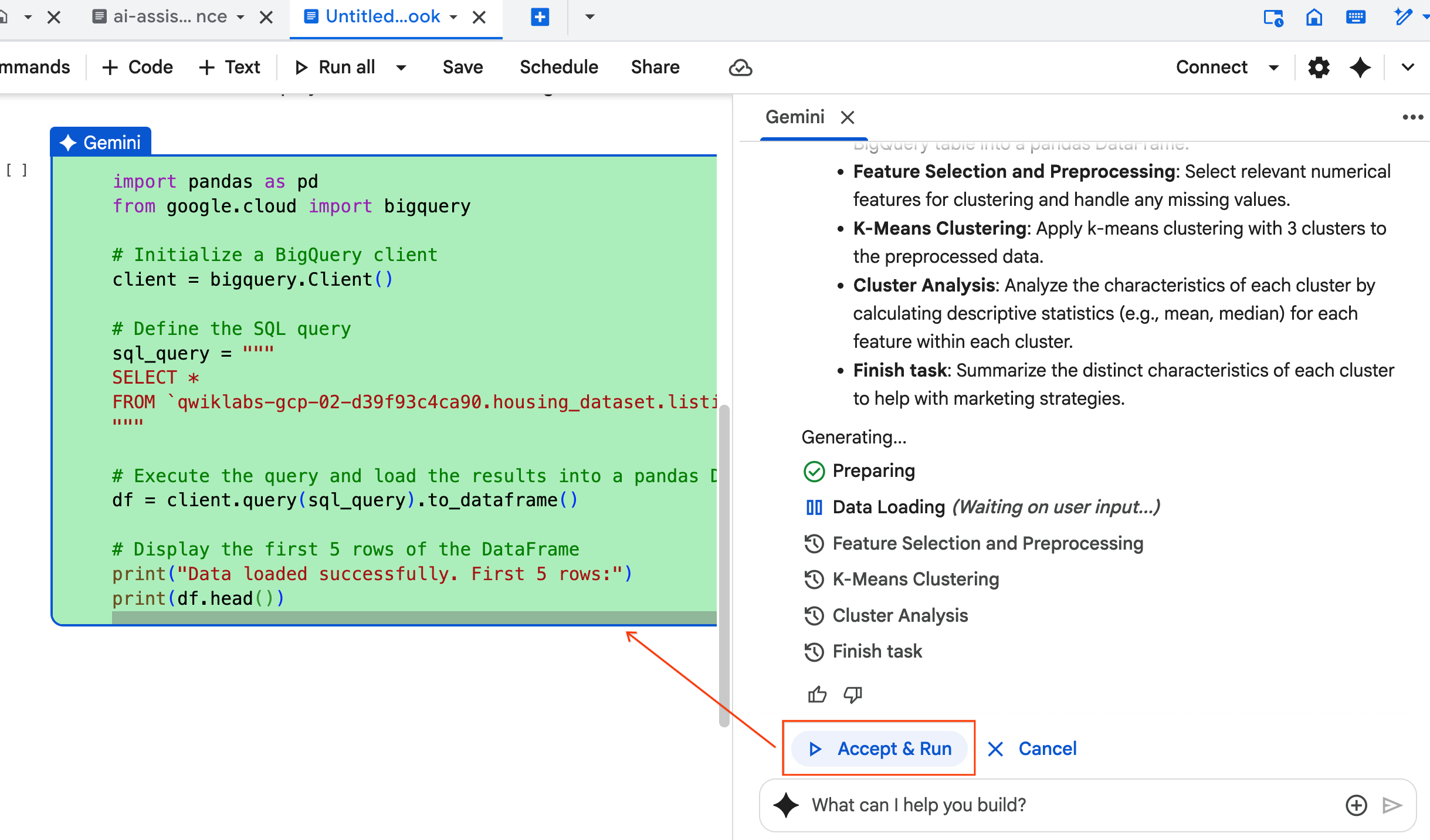
- 完成後,只要關閉這個新筆記本分頁,然後返回原始的
ai-assisted-data-science.ipynb分頁,即可繼續完成實驗室的最後一個部分。
12. 使用嵌入和向量搜尋功能進行多模態搜尋
在最後一節中,您將直接在 BigQuery 中導入多模態搜尋功能。因此可以進行直覺式搜尋,例如根據文字說明尋找房屋,或是尋找與範例圖片相似的房屋。
這個程序會先將每張房屋圖片轉換為稱為「嵌入」的數字表示法,嵌入會擷取圖片的語意,讓您透過比較數值向量找出相似項目。
您將使用 multimodalembedding 模型,為所有商店資訊產生這些向量。建立向量索引來加快查詢速度後,您就可以執行兩種相似度搜尋:文字轉圖像 (尋找符合描述的房屋) 和圖像轉圖像 (尋找與範例圖片相似的房屋)。
您將在 BigQuery 中完成所有作業,使用 ML.GENERATE_EMBEDDING 等函式生成嵌入,或使用 VECTOR_SEARCH 執行相似度搜尋。
13. 清除
如要清理此專案中使用的所有 Google Cloud 資源,請刪除 Google Cloud 專案。
或者,您也可以在筆記本的新儲存格中執行下列程式碼,刪除您建立的個別資源:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
最後,你可以刪除筆記本本身:
- 在 BigQuery Studio 的「Explorer」窗格中,展開專案和「Notebooks」節點。
- 按一下
ai-assisted-data-science筆記本旁的三個垂直圓點。 - 選取 [刪除]。
14. 恭喜!
恭喜您完成本程式碼研究室!
涵蓋內容
- 準備房地產資訊的原始資料集,透過特徵工程進行分析。
- 使用 BigQuery 的 AI 函式分析房屋相片,找出主要視覺特徵,豐富房源資訊。
- 使用 BigQuery Machine Learning (BQML) 建構及評估 K-means 模型,將房源劃分為不同叢集。
- 使用資料科學代理程式以 Python 產生叢集模型,自動建立模型。
- 生成房屋圖片的嵌入內容,為影像搜尋工具提供支援,透過文字或圖片查詢尋找相似房屋。