
1. Introduction
In this lab, you create a linear regression model to predict whether or not recent transactions are fraudulent using SQL in BigQuery. You create a training dataset that contains each card transaction and some of the attributes that we have decided best indicate fraud, such as distance from the customer home, time of day, and transaction amount.
Then you use BQML to build a logistic regression model to predict whether a transaction is fraudulent based on our training data. One of the nice features of BQ ML is that it takes care of overfitting, so that our training data will not impact the performance of the model on new data. Finally you create three sample transactions with different characteristics and predict if they're fraudulent or not using the model.
What you will learn
In this lab, you learn how to perform the following tasks:
- Load dataset from a Google Cloud Storage bucket
- Create training data
- Create and train logistic regression model
- Use the model to predict if sample transactions are fraudulent or not
- Identify fraud transaction by zip code using geospatial analysis
2. Load dataset from a GCS bucket
In this task, you create a dataset called bq_demo and load it with retail banking data from a GCS bucket. It will delete any existing data that is already in your tables.
Open Cloud Shell
- In the Cloud Console, in the top right toolbar, click the Activate Cloud Shell button.
- Once the cloud shell loads, type:
bq rm -r -f -d bq_demo
bq rm -r -f -d bq_demo_shared
bq mk --dataset bq_demo
bq load --replace --autodetect --source_format=CSV bq_demo.account gs://retail-banking-looker/account
bq load --replace --autodetect --source_format=CSV bq_demo.base_card gs://retail-banking-looker/base_card
bq load --replace --autodetect --source_format=CSV bq_demo.card gs://retail-banking-looker/card
bq load --replace --autodetect --source_format=CSV bq_demo.card_payment_amounts gs://retail-banking-looker/card_payment_amounts
bq load --replace --autodetect --source_format=CSV bq_demo.card_transactions gs://retail-banking-looker/card_transactions
bq load --replace --autodetect --source_format=CSV bq_demo.card_type_facts gs://retail-banking-looker/card_type_facts
bq load --replace --autodetect --source_format=CSV bq_demo.client gs://retail-banking-looker/client
bq load --replace --autodetect --source_format=CSV bq_demo.disp gs://retail-banking-looker/disp
bq load --replace --autodetect --source_format=CSV bq_demo.loan gs://retail-banking-looker/loan
bq load --replace --autodetect --source_format=CSV bq_demo.order gs://retail-banking-looker/order
bq load --replace --autodetect --source_format=CSV bq_demo.trans gs://retail-banking-looker/trans
- Once completed, click the X to close the cloud shell terminal. You have successfully loaded a dataset from a Google Cloud Storage bucket.
3. Create training data
Query for fraudulent transactions per card type
Before we create training data, let's analyze how fraudulent transactions are distributed among card types. Our retail banking database contains a flag that indicates when a customer has reported a fraudulent transaction on their account. This query shows the number of fraudulent transactions by card type.
[Competitive Talking Point: Unlike certain competitors, BigQuery does not require you to export the data in your data warehouse to a storage bucket, run machine learning algorithms, then copy the results back to the database. All of this can be done in place, which preserves data security and doesn't lead to "data sprawl".]
- Open BigQuery Console:
In the Google Cloud Console, select Navigation menu > BigQuery.
- The Welcome to BigQuery in the Cloud Console message box opens. This message box provides a link to the quickstart guide and the release notes.
Click Done.
The BigQuery console opens.
- Run the query in Query Editor:
SELECT c.type, count(trans_id) as fraud_transactions
FROM bq_demo.card_transactions AS t
JOIN bq_demo.card c ON t.cc_number = c.card_number
WHERE t.is_fraud=1
GROUP BY type
But what if we could use this data to predict fraudulent transactions even before the customer notices? ML is not just for experts. With BigQuery, analysts can run world class ML models directly on data warehouse data via SQL.
Create training data
Create a training data set that contains each card transaction and some of the attributes that we have decided best indicate fraud, such as distance from the customer home, time of day, and transaction amount.
Run the query in Query Editor:
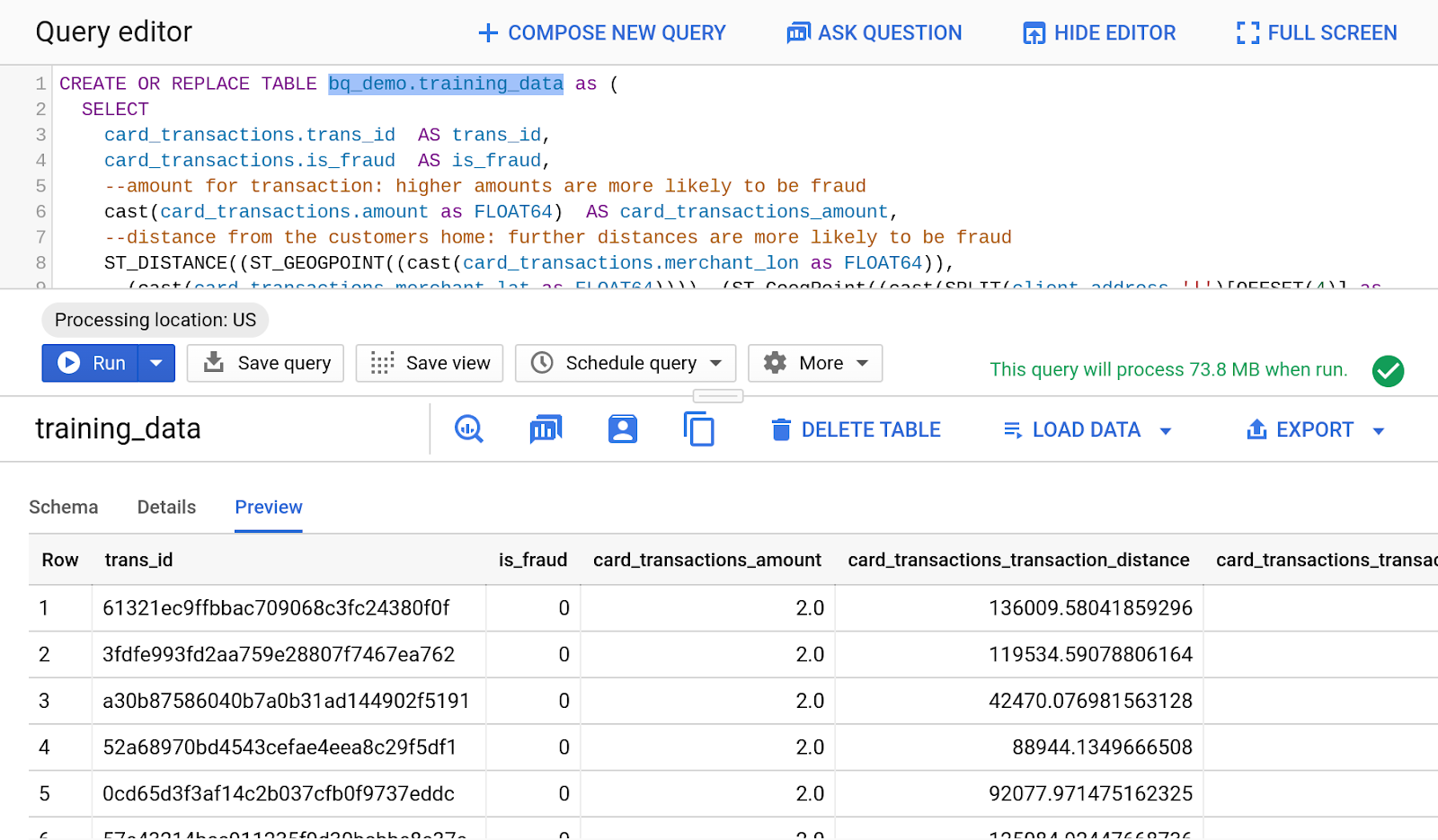
CREATE OR REPLACE TABLE bq_demo.training_data as (
SELECT
card_transactions.trans_id AS trans_id,
card_transactions.is_fraud AS is_fraud,
--amount for transaction: higher amounts are more likely to be fraud
cast(card_transactions.amount as FLOAT64) AS card_transactions_amount,
--distance from the customers home: further distances are more likely to be fraud
ST_DISTANCE((ST_GEOGPOINT((cast(card_transactions.merchant_lon as FLOAT64)),
(cast(card_transactions.merchant_lat as FLOAT64)))), (ST_GeogPoint((cast(SPLIT(client.address,'|')[OFFSET(4)] as float64)),
(cast(SPLIT(client.address,'|')[OFFSET(3)] as float64))))) AS card_transactions_transaction_distance,
--hour that transaction occured: fraud occurs in middle of night (usually between midnight and 4 am)
EXTRACT(HOUR FROM TIMESTAMP(CONCAT(card_transactions.trans_date,' ',card_transactions.trans_time)) ) AS card_transactions_transaction_hour_of_day
FROM bq_demo.card_transactions AS card_transactions
LEFT JOIN bq_demo.card AS card ON card.card_number = card_transactions.cc_number
LEFT JOIN bq_demo.disp AS disp ON card.disp_id = disp.disp_id
LEFT JOIN bq_demo.client AS client ON disp.client_id = client.client_id );
Under "Results" click on "go to table" and you should see the following result:
4. Create and train the model
Use BQML to build a logistic regression model to predict whether a transaction is fraudulent based on our training data created in the previous step. One of the nice features of BQML is that it takes care of overfitting, so that our training data will not impact the performance of the model on new data.
Run the query in Query Editor:
CREATE OR REPLACE MODEL bq_demo.fraud_prediction
OPTIONS(model_type='logistic_reg', labels=['is_fraud']) AS
SELECT * EXCEPT(trans_id)
FROM bq_demo.training_data
WHERE (is_fraud = 1) OR
(is_fraud = 0 AND rand() <=
(SELECT SUM(is_fraud)/COUNT(*) FROM bq_demo.training_data));
View model details
Under "Results", click on "Go to Model".
You should see Schema, Training and Evaluation tabs.
Under "Training tab", you should see this:
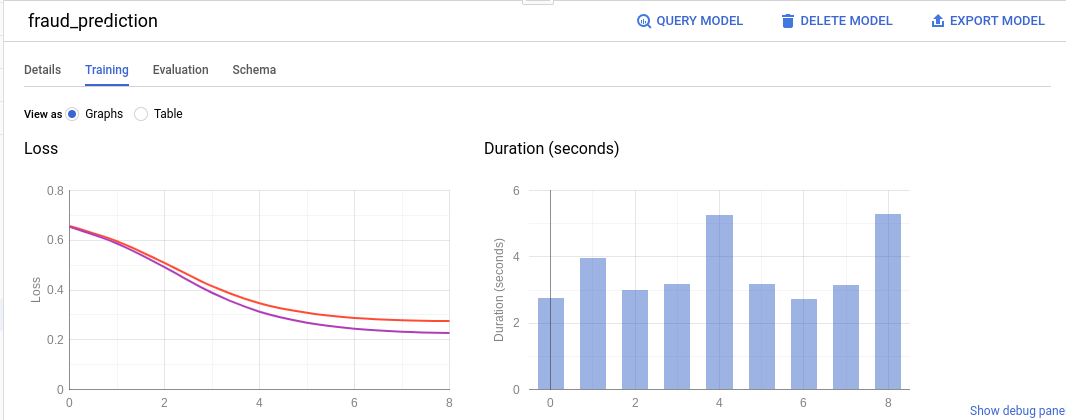
Under "Evaluation tab", you should see this:
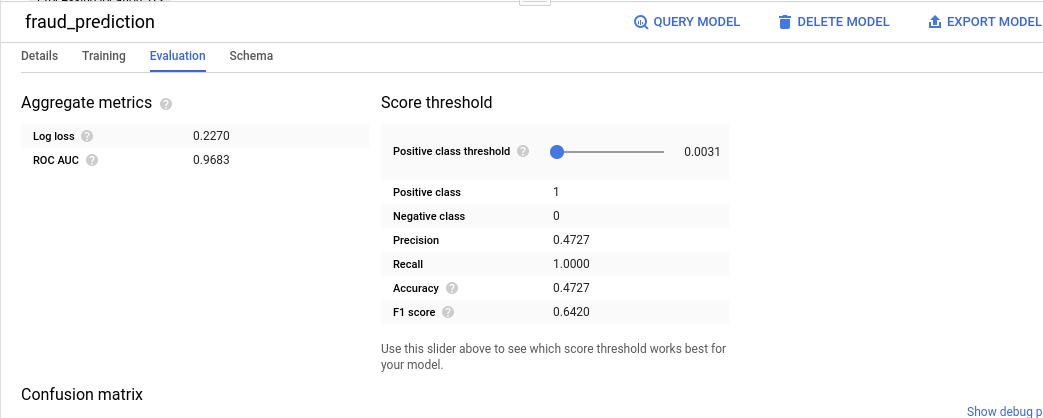
Under "Schema tab", you should see this:
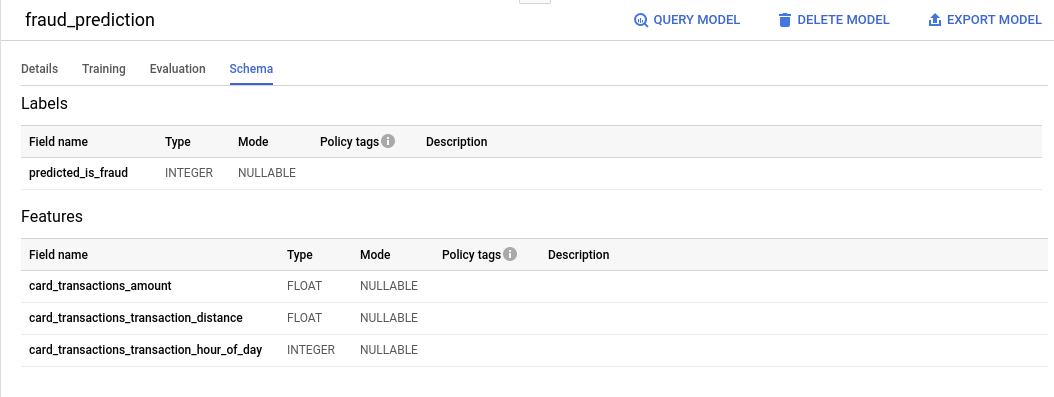
5. Use model to predict fraud
Now let's use our model to predict whether a transaction is potentially fraudulent. We will create 3 sample transactions with different characteristics.
Run following query in query editor:
SELECT * FROM ML.PREDICT(MODEL bq_demo.fraud_prediction, (
SELECT '001' as trans_id, 500.00 as card_transactions_amount, 600 as card_transactions_transaction_distance, 2 as card_transactions_transaction_hour_of_day
UNION ALL
SELECT '002' as trans_id, 5.25 as card_transactions_amount, 2 as card_transactions_transaction_distance, 13 as card_transactions_transaction_hour_of_day
UNION ALL
SELECT '003' as trans_id, 175.50 as card_transactions_amount, 45 as card_transactions_transaction_distance, 10 as card_transactions_transaction_hour_of_day
), STRUCT(0.55 AS threshold)
);
You should see results like this:
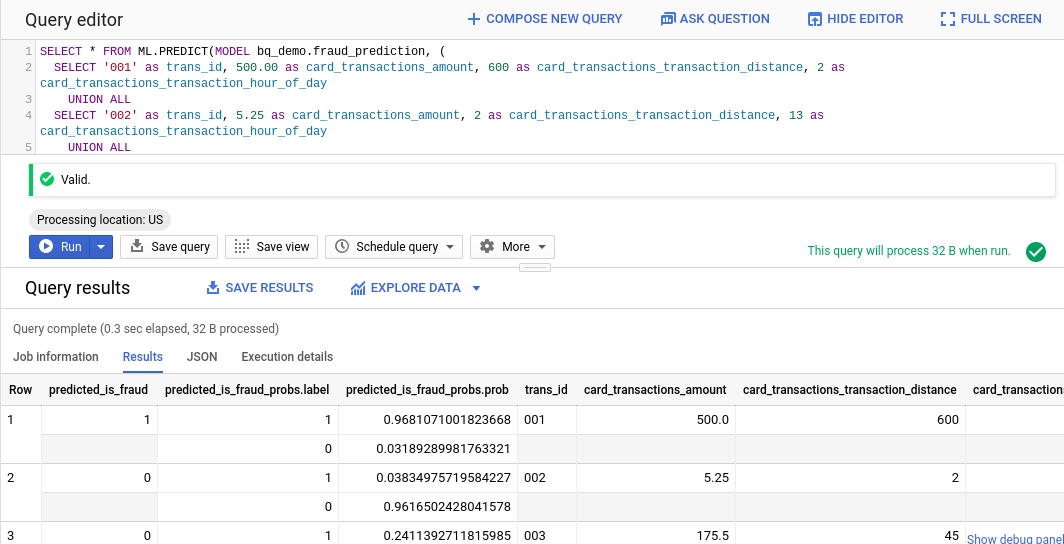
As you can see, the first transaction is almost certainly fraudulent based on our model while the 2nd and 3rd transactions are predicted not to be fraudulent. We've set the threshold to 55%, up from the default of 50%. We could train our model with additional data or add additional attributes to improve the accuracy.
6. Identify fraud transaction by zip code using geospatial analysis
BigQuery has rich support for geospatial data. Here's an example that uses the GIS function ST_WITHIN to determine the zip code given the latitude and longitude of merchant transactions using a public data set of zip code boundaries.
Run the following code in Query Editor:
WITH trans_by_zip as (
SELECT
card_transactions.trans_id,
zip_code AS merchant_zip,
city as merchant_city,
county as merchant_county,
state_name as merchant_state
FROM
bq_demo.card_transactions AS card_transactions,
bigquery-public-data.geo_us_boundaries.zip_codes AS zip_codes
WHERE ST_Within(ST_GEOGPOINT((cast(card_transactions.merchant_lon as FLOAT64)),(cast(card_transactions.merchant_lat as FLOAT64))),zip_codes.zip_code_geom)
)
SELECT merchant_zip, 1.0 * (SUM(is_fraud)) / nullif((COUNT(*)),0) AS percent_transactions_fraud
FROM bq_demo.card_transactions t, trans_by_zip
WHERE t.trans_id = trans_by_zip.trans_id
GROUP BY merchant_zip
ORDER BY percent_transactions_fraud DESC;
You should see following results:
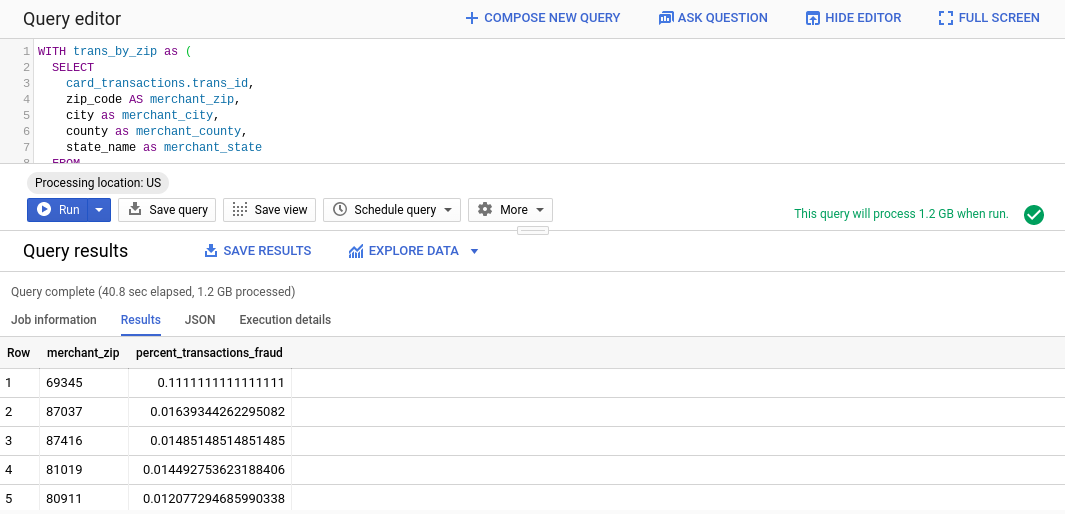
As you can see, the fraud rate in most postal codes is relatively small (under 2%) but the fraud rate in 69345 is a surprising 11%. This is probably something we want to investigate.