
1. はじめに
このラボでは、BigQuery で SQL を使用して、最近の取引が不正であるかどうかを予測するための線形回帰モデルを作成します。あなたは、各カード トランザクションと、不正行為を最もよく表す属性(顧客の自宅からの距離、時間帯、取引金額など)のいくつかを含むトレーニング データセットを作成します。
次に、BQML を使用してロジスティック回帰モデルを構築し、トレーニング データに基づいて取引が不正であるかどうかを予測します。BQ ML の優れた機能の一つは、過学習に対処できることです。そのため、トレーニング データが新しいデータに対するモデルのパフォーマンスに影響を与えません。最後に、特性の異なるサンプル トランザクションを 3 つ作成し、トランザクションが不正であるかどうか、モデルを使用していないかどうかを予測します。
学習内容
このラボでは、次のタスクの実行方法について学びます。
- Google Cloud Storage バケットからデータセットを読み込む
- トレーニング データを作成する
- ロジスティック回帰モデルを作成してトレーニングする
- モデルを使用してサンプル取引が不正であるかどうかを予測する
- 地理空間分析を使用して郵便番号別に不正取引を特定する
2. GCS バケットからデータセットを読み込む
このタスクでは、bq_demo というデータセットを作成し、GCS バケットからリテール バンキング データとともに読み込みます。テーブルにすでに存在する既存のデータはすべて削除されます。
Cloud Shell を開く
- Google Cloud コンソールの右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
- Cloud Shell が読み込まれたら、次のように入力します。
bq rm -r -f -d bq_demo
bq rm -r -f -d bq_demo_shared
bq mk --dataset bq_demo
bq load --replace --autodetect --source_format=CSV bq_demo.account gs://retail-banking-looker/account
bq load --replace --autodetect --source_format=CSV bq_demo.base_card gs://retail-banking-looker/base_card
bq load --replace --autodetect --source_format=CSV bq_demo.card gs://retail-banking-looker/card
bq load --replace --autodetect --source_format=CSV bq_demo.card_payment_amounts gs://retail-banking-looker/card_payment_amounts
bq load --replace --autodetect --source_format=CSV bq_demo.card_transactions gs://retail-banking-looker/card_transactions
bq load --replace --autodetect --source_format=CSV bq_demo.card_type_facts gs://retail-banking-looker/card_type_facts
bq load --replace --autodetect --source_format=CSV bq_demo.client gs://retail-banking-looker/client
bq load --replace --autodetect --source_format=CSV bq_demo.disp gs://retail-banking-looker/disp
bq load --replace --autodetect --source_format=CSV bq_demo.loan gs://retail-banking-looker/loan
bq load --replace --autodetect --source_format=CSV bq_demo.order gs://retail-banking-looker/order
bq load --replace --autodetect --source_format=CSV bq_demo.trans gs://retail-banking-looker/trans
- 完了したら、[X] をクリックして Cloud Shell ターミナルを閉じます。Google Cloud Storage バケットからデータセットを読み込むことができました。
3. トレーニング データを作成する
カードタイプごとの不正取引のクエリ
トレーニング データを作成する前に、不正なトランザクションがカードタイプ間でどのように分散されているかを分析しましょう。Google のリテール バンキング データベースには、お客様がアカウントで不正な取引を報告したことを示すフラグが含まれています。このクエリでは、不正取引の件数をカードの種類別に表示します。
[競争力のある説明: 一部の競合他社とは異なり、BigQuery では、データ ウェアハウスのデータをストレージ バケットにエクスポートし、ML アルゴリズムを実行してから、その結果をデータベースにコピーする必要はありません。これらすべてをインプレースで実施できるため、データ セキュリティが維持され、「データの無秩序な拡散」につながることはありません。]
- BigQuery コンソールを開きます。
Google Cloud コンソールのナビゲーション メニューで、BigQuery
- [Cloud Console の BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
[完了] をクリックします。
BigQuery コンソールが開きます。
- Query Editor でクエリを実行します。
SELECT c.type, count(trans_id) as fraud_transactions
FROM bq_demo.card_transactions AS t
JOIN bq_demo.card c ON t.cc_number = c.card_number
WHERE t.is_fraud=1
GROUP BY type
しかし、このデータを使用して、顧客が気づく前に不正な取引を予測できるとしたらどうでしょうか。ML は専門家だけのものではありません。BigQuery を使用すると、アナリストは SQL 経由でデータ ウェアハウスのデータに対して世界クラスの ML モデルを直接実行できます。
トレーニング データを作成する
各カード取引と、不正行為を最もよく表す属性(顧客の自宅からの距離、時間帯、取引金額など)のいくつかを含むトレーニング データセットを作成します。
Query Editor でクエリを実行します。
CREATE OR REPLACE TABLE bq_demo.training_data as (
SELECT
card_transactions.trans_id AS trans_id,
card_transactions.is_fraud AS is_fraud,
--amount for transaction: higher amounts are more likely to be fraud
cast(card_transactions.amount as FLOAT64) AS card_transactions_amount,
--distance from the customers home: further distances are more likely to be fraud
ST_DISTANCE((ST_GEOGPOINT((cast(card_transactions.merchant_lon as FLOAT64)),
(cast(card_transactions.merchant_lat as FLOAT64)))), (ST_GeogPoint((cast(SPLIT(client.address,'|')[OFFSET(4)] as float64)),
(cast(SPLIT(client.address,'|')[OFFSET(3)] as float64))))) AS card_transactions_transaction_distance,
--hour that transaction occured: fraud occurs in middle of night (usually between midnight and 4 am)
EXTRACT(HOUR FROM TIMESTAMP(CONCAT(card_transactions.trans_date,' ',card_transactions.trans_time)) ) AS card_transactions_transaction_hour_of_day
FROM bq_demo.card_transactions AS card_transactions
LEFT JOIN bq_demo.card AS card ON card.card_number = card_transactions.cc_number
LEFT JOIN bq_demo.disp AS disp ON card.disp_id = disp.disp_id
LEFT JOIN bq_demo.client AS client ON disp.client_id = client.client_id );
[結果] の下[テーブルに移動]をクリックし次のような結果が表示されます。
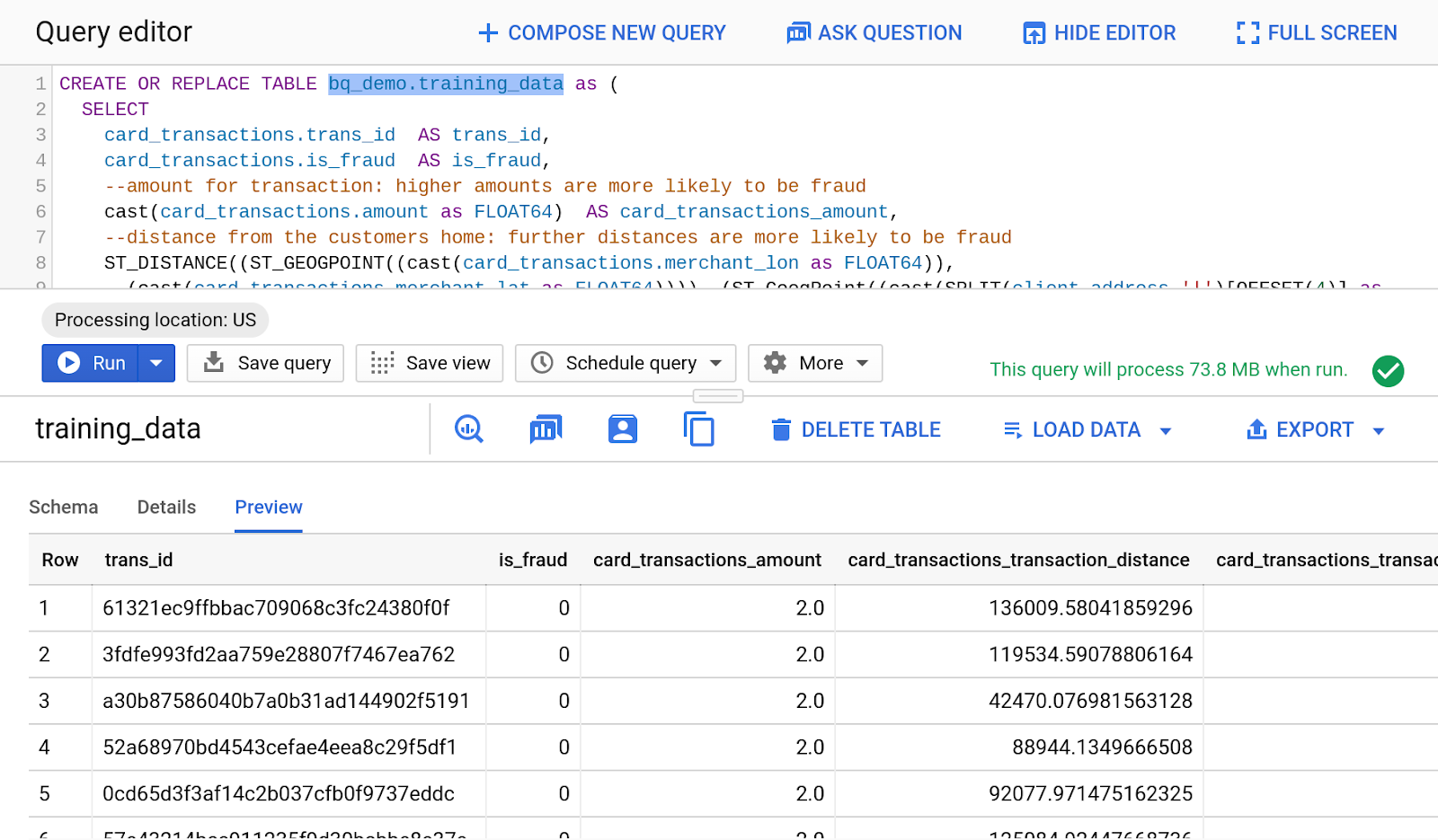
4. モデルを作成してトレーニングする
BQML を使用してロジスティック回帰モデルを構築し、前のステップで作成したトレーニング データに基づいて、取引が不正であるかどうかを予測します。BQML の優れた機能の一つは、過学習に対処できることです。そのため、トレーニング データが新しいデータに対するモデルのパフォーマンスに影響を与えません。
Query Editor でクエリを実行します。
CREATE OR REPLACE MODEL bq_demo.fraud_prediction
OPTIONS(model_type='logistic_reg', labels=['is_fraud']) AS
SELECT * EXCEPT(trans_id)
FROM bq_demo.training_data
WHERE (is_fraud = 1) OR
(is_fraud = 0 AND rand() <=
(SELECT SUM(is_fraud)/COUNT(*) FROM bq_demo.training_data));
モデルの詳細を表示
[結果] で [モデルに移動] をクリックします。
[スキーマ]、[トレーニング]、[評価] の各タブが表示されます。
[トレーニング] タブに次のように表示されます。
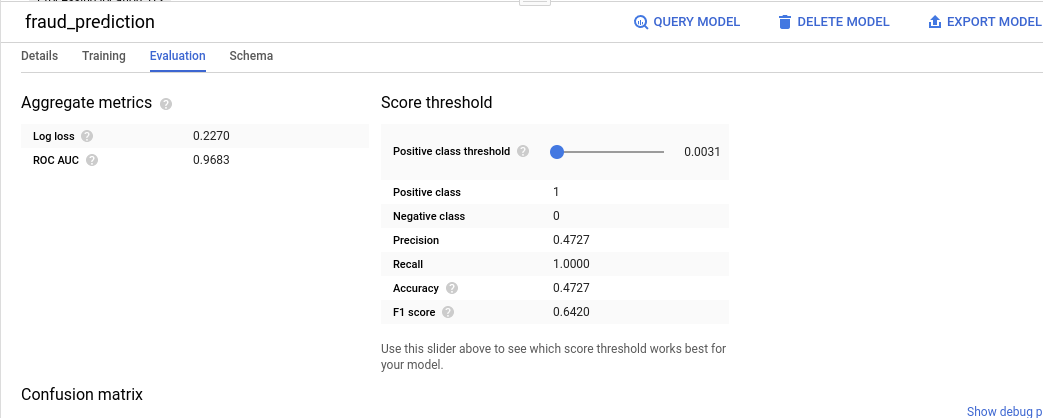
[評価] タブに次のように表示されます。
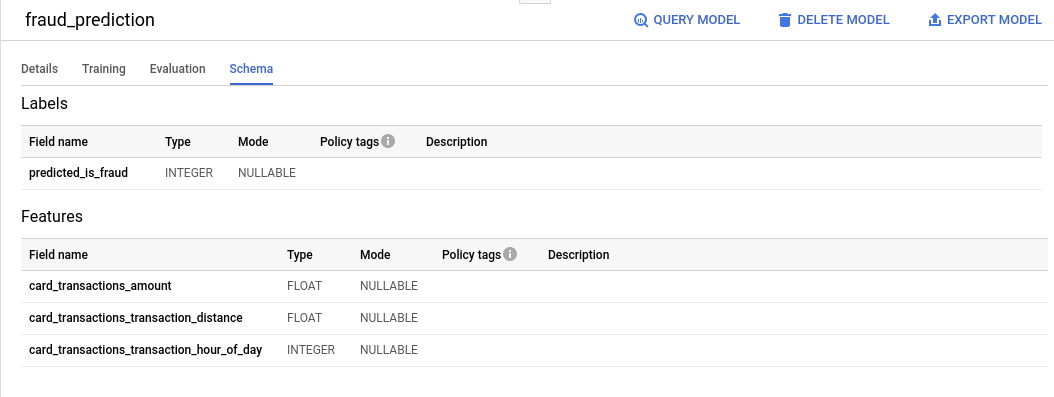
[スキーマ] タブに次のように表示されます。
5. モデルを使用して不正行為を予測する
それでは、モデルを使用して、不正取引の可能性を予測してみましょう。特徴の異なる 3 つのサンプル トランザクションを作成します。
クエリエディタで次のクエリを実行します。
SELECT * FROM ML.PREDICT(MODEL bq_demo.fraud_prediction, (
SELECT '001' as trans_id, 500.00 as card_transactions_amount, 600 as card_transactions_transaction_distance, 2 as card_transactions_transaction_hour_of_day
UNION ALL
SELECT '002' as trans_id, 5.25 as card_transactions_amount, 2 as card_transactions_transaction_distance, 13 as card_transactions_transaction_hour_of_day
UNION ALL
SELECT '003' as trans_id, 175.50 as card_transactions_amount, 45 as card_transactions_transaction_distance, 10 as card_transactions_transaction_hour_of_day
), STRUCT(0.55 AS threshold)
);
次のような結果が表示されます。
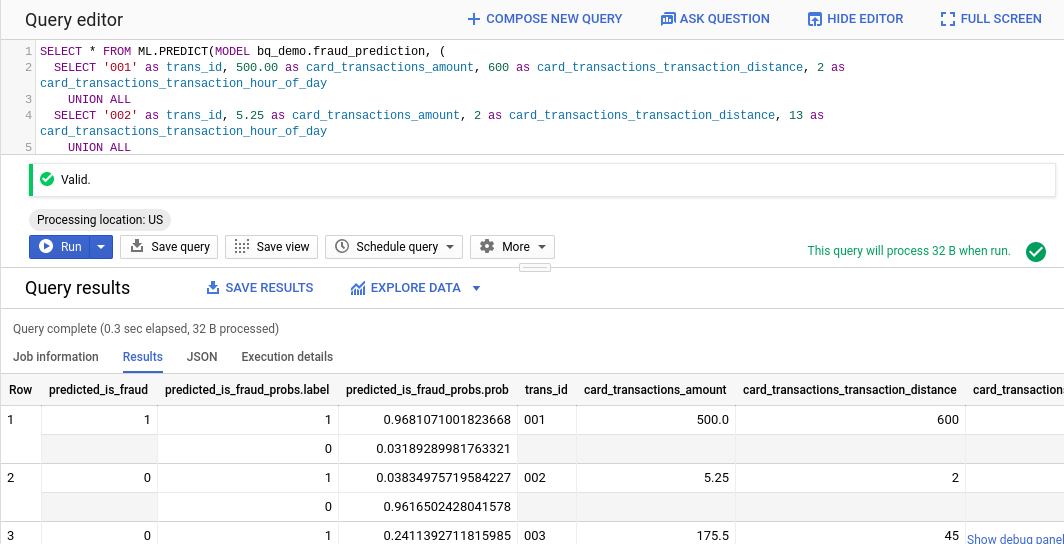
ご覧のとおり、Google のモデルに基づいて、最初の取引はほぼ確実に不正であるのに対し、2 番目と 3 番目の取引は不正ではないと予測されています。しきい値はデフォルトの 50% から 55% に設定されています。データをさらに追加してモデルをトレーニングしたり、別の属性を追加して精度を高めたりすることもできます。
6. 地理空間分析を使用して郵便番号別に不正取引を特定する
BigQuery は地理空間データを豊富にサポートしています。次の例では、GIS 関数 ST_WITHIN を使って、郵便番号の境界に関する公開データセットを使って、販売者の取引の緯度と経度を指定して、郵便番号を特定します。
Query Editor で次のコードを実行します。
WITH trans_by_zip as (
SELECT
card_transactions.trans_id,
zip_code AS merchant_zip,
city as merchant_city,
county as merchant_county,
state_name as merchant_state
FROM
bq_demo.card_transactions AS card_transactions,
bigquery-public-data.geo_us_boundaries.zip_codes AS zip_codes
WHERE ST_Within(ST_GEOGPOINT((cast(card_transactions.merchant_lon as FLOAT64)),(cast(card_transactions.merchant_lat as FLOAT64))),zip_codes.zip_code_geom)
)
SELECT merchant_zip, 1.0 * (SUM(is_fraud)) / nullif((COUNT(*)),0) AS percent_transactions_fraud
FROM bq_demo.card_transactions t, trans_by_zip
WHERE t.trans_id = trans_by_zip.trans_id
GROUP BY merchant_zip
ORDER BY percent_transactions_fraud DESC;
次のような結果が表示されます。
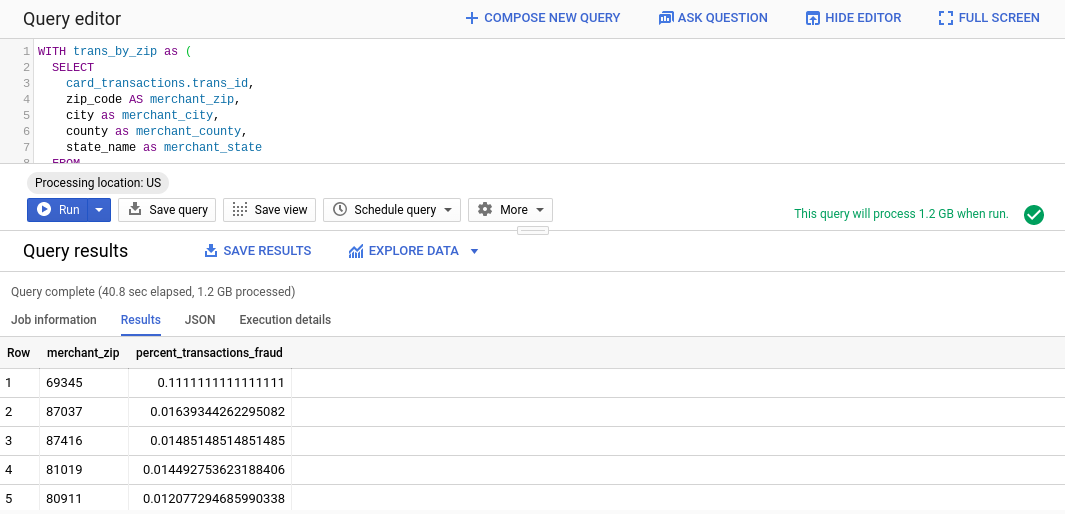
ご覧のとおり、ほとんどの郵便番号の不正率は比較的小さく(2% 未満)、69345 の不正率は驚くべき 11% となっています。この問題については、調査が必要と思われます。