
1. 소개
이 실습에서는 BigQuery의 SQL을 사용하여 최근 거래가 사기인지 여부를 예측하는 선형 회귀 모델을 만듭니다. 각 카드 거래와 사기를 가장 잘 나타낸다고 결정한 일부 속성(예: 고객 집에서의 거리, 시간대, 거래 금액)이 포함된 학습 데이터 세트를 만듭니다.
그런 다음 BQML을 사용하여 로지스틱 회귀 모델을 빌드하여 학습 데이터를 기반으로 거래가 사기인지 예측합니다. BQ ML의 장점 중 하나는 과적합을 처리하여 학습 데이터가 새 데이터에 대한 모델 성능에 영향을 미치지 않는다는 것입니다. 마지막으로 특성이 서로 다른 샘플 거래 3개를 만들고 허위 거래인지 모델을 사용하지 않는지 예측합니다.
학습할 내용
이 실습에서는 다음 작업을 수행하는 방법을 알아봅니다.
- Google Cloud Storage 버킷에서 데이터 세트 로드
- 학습 데이터 만들기
- 로지스틱 회귀 모델 만들기 및 학습
- 모델을 사용하여 샘플 거래가 사기인지 아닌지 예측
- 지리정보 분석을 사용해 우편번호로 사기 거래 식별
2. GCS 버킷에서 데이터 세트 로드
이 작업에서는 bq_demo라는 데이터 세트를 만들고 GCS 버킷의 소매 뱅킹 데이터로 로드합니다. 그러면 테이블에 이미 있는 기존 데이터가 모두 삭제됩니다.
Cloud Shell 열기
- Cloud 콘솔의 오른쪽 상단 툴바에서 'Cloud Shell 활성화' 버튼을 클릭합니다.
- Cloud Shell이 로드되면 다음을 입력합니다.
bq rm -r -f -d bq_demo
bq rm -r -f -d bq_demo_shared
bq mk --dataset bq_demo
bq load --replace --autodetect --source_format=CSV bq_demo.account gs://retail-banking-looker/account
bq load --replace --autodetect --source_format=CSV bq_demo.base_card gs://retail-banking-looker/base_card
bq load --replace --autodetect --source_format=CSV bq_demo.card gs://retail-banking-looker/card
bq load --replace --autodetect --source_format=CSV bq_demo.card_payment_amounts gs://retail-banking-looker/card_payment_amounts
bq load --replace --autodetect --source_format=CSV bq_demo.card_transactions gs://retail-banking-looker/card_transactions
bq load --replace --autodetect --source_format=CSV bq_demo.card_type_facts gs://retail-banking-looker/card_type_facts
bq load --replace --autodetect --source_format=CSV bq_demo.client gs://retail-banking-looker/client
bq load --replace --autodetect --source_format=CSV bq_demo.disp gs://retail-banking-looker/disp
bq load --replace --autodetect --source_format=CSV bq_demo.loan gs://retail-banking-looker/loan
bq load --replace --autodetect --source_format=CSV bq_demo.order gs://retail-banking-looker/order
bq load --replace --autodetect --source_format=CSV bq_demo.trans gs://retail-banking-looker/trans
- 완료되면 X를 클릭하여 Cloud Shell 터미널을 닫습니다. Google Cloud Storage 버킷에서 데이터 세트를 로드했습니다.
3. 학습 데이터 만들기
카드 유형별 허위 거래 쿼리
학습 데이터를 만들기 전에 허위 거래가 카드 유형별로 어떻게 분포되어 있는지 분석해 보겠습니다. Google의 소매 뱅킹 데이터베이스에는 고객이 자신의 계정에서 사기 거래가 신고되었음을 나타내는 플래그가 포함되어 있습니다. 이 쿼리에는 카드 유형별로 사기 거래 수가 표시됩니다.
[경쟁력 요점: 특정 경쟁사와 달리 BigQuery는 데이터 웨어하우스의 데이터를 스토리지 버킷으로 내보내고 머신러닝 알고리즘을 실행한 후 결과를 데이터베이스로 다시 복사할 필요가 없습니다. 이 모든 작업을 수행할 수 있으므로 데이터 보안이 유지되고 '데이터 급증'이 발생하지 않습니다.]
- BigQuery 콘솔을 엽니다.
Google Cloud 콘솔에서 탐색 메뉴 > BigQuery를 선택합니다.
- 'Cloud 콘솔의 BigQuery에 오신 것을 환영합니다.'라는 메시지 상자가 열립니다. 이 메시지 상자에서는 빠른 시작 가이드 및 출시 노트로 연결되는 링크가 제공됩니다.
완료를 클릭합니다.
BigQuery 콘솔이 열립니다.
- 쿼리 편집기에서 쿼리를 실행합니다.
SELECT c.type, count(trans_id) as fraud_transactions
FROM bq_demo.card_transactions AS t
JOIN bq_demo.card c ON t.cc_number = c.card_number
WHERE t.is_fraud=1
GROUP BY type
하지만 고객이 눈치채기도 전에 이 데이터를 사용해 사기 거래를 예측할 수 있다면 어떨까요? ML은 전문가만을 위한 것이 아닙니다. BigQuery를 사용하면 분석가가 SQL을 통해 데이터 웨어하우스 데이터에서 세계적 수준의 ML 모델을 바로 실행할 수 있습니다.
학습 데이터 만들기
각 카드 거래와 사기를 가장 잘 나타낸다고 판단되는 속성(예: 고객 집에서의 거리, 시간대, 거래 금액)이 포함된 학습 데이터 세트를 만듭니다.
쿼리 편집기에서 쿼리를 실행합니다.
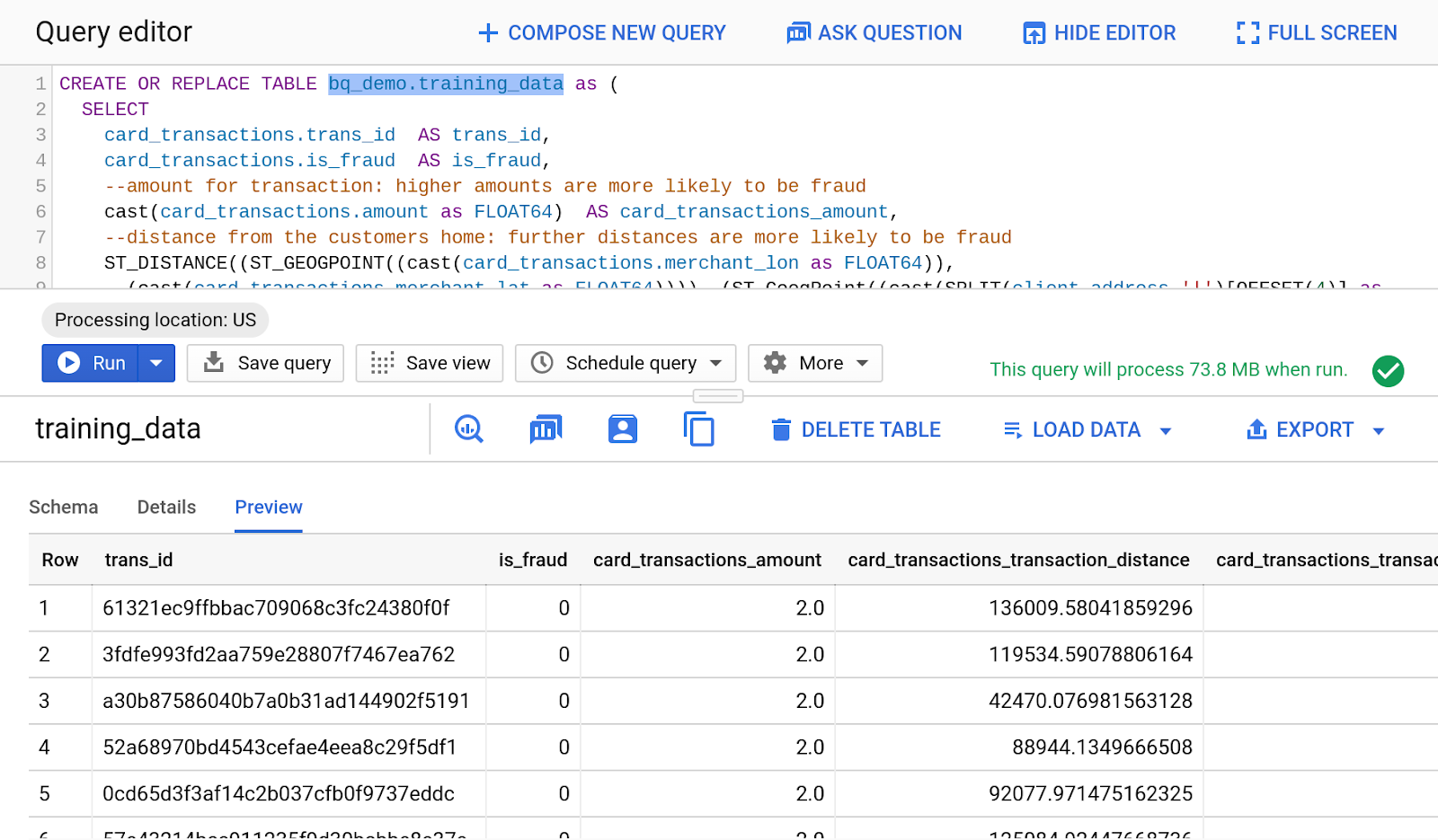
CREATE OR REPLACE TABLE bq_demo.training_data as (
SELECT
card_transactions.trans_id AS trans_id,
card_transactions.is_fraud AS is_fraud,
--amount for transaction: higher amounts are more likely to be fraud
cast(card_transactions.amount as FLOAT64) AS card_transactions_amount,
--distance from the customers home: further distances are more likely to be fraud
ST_DISTANCE((ST_GEOGPOINT((cast(card_transactions.merchant_lon as FLOAT64)),
(cast(card_transactions.merchant_lat as FLOAT64)))), (ST_GeogPoint((cast(SPLIT(client.address,'|')[OFFSET(4)] as float64)),
(cast(SPLIT(client.address,'|')[OFFSET(3)] as float64))))) AS card_transactions_transaction_distance,
--hour that transaction occured: fraud occurs in middle of night (usually between midnight and 4 am)
EXTRACT(HOUR FROM TIMESTAMP(CONCAT(card_transactions.trans_date,' ',card_transactions.trans_time)) ) AS card_transactions_transaction_hour_of_day
FROM bq_demo.card_transactions AS card_transactions
LEFT JOIN bq_demo.card AS card ON card.card_number = card_transactions.cc_number
LEFT JOIN bq_demo.disp AS disp ON card.disp_id = disp.disp_id
LEFT JOIN bq_demo.client AS client ON disp.client_id = client.client_id );
'결과'에서 '표로 이동'을 클릭하세요. 다음과 같은 결과가 표시됩니다.
4. 모델 생성 및 학습
BQML을 사용하여 이전 단계에서 만든 학습 데이터를 기반으로 거래가 사기인지 예측하는 로지스틱 회귀 모델을 만듭니다. BQML의 장점 중 하나는 과적합을 처리하여 학습 데이터가 새 데이터에 대한 모델 성능에 영향을 미치지 않는다는 것입니다.
쿼리 편집기에서 쿼리를 실행합니다.
CREATE OR REPLACE MODEL bq_demo.fraud_prediction
OPTIONS(model_type='logistic_reg', labels=['is_fraud']) AS
SELECT * EXCEPT(trans_id)
FROM bq_demo.training_data
WHERE (is_fraud = 1) OR
(is_fraud = 0 AND rand() <=
(SELECT SUM(is_fraud)/COUNT(*) FROM bq_demo.training_data));
모델 세부정보 보기
'결과'에서 '모델로 이동'을 클릭합니다.
스키마, 학습, 평가 탭이 표시됩니다.
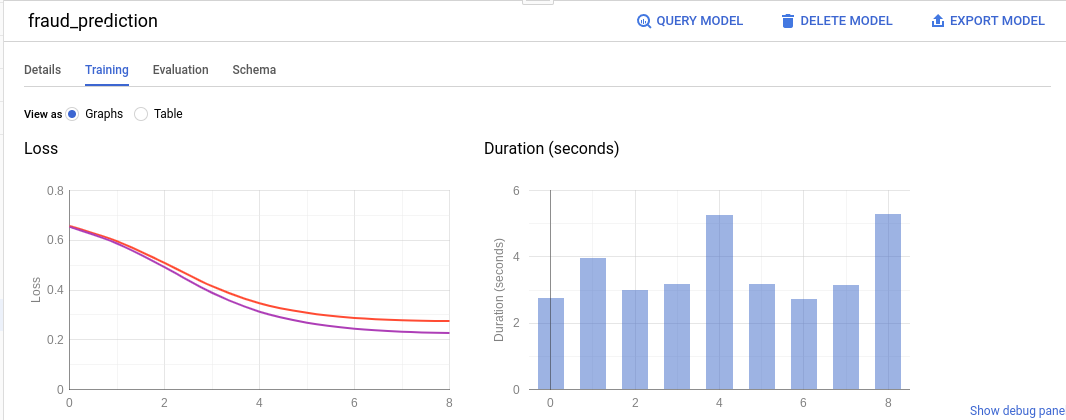
'학습 탭'에 다음과 같이 표시됩니다.
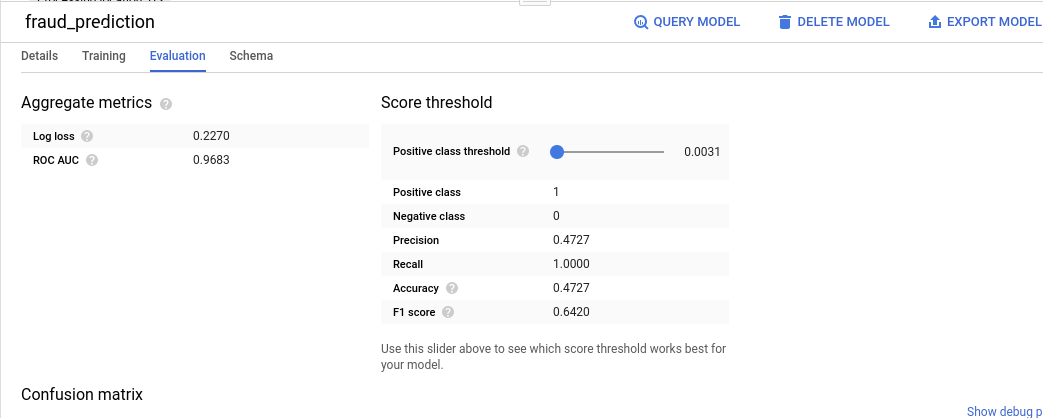
'평가 탭'에 다음과 같이 표시됩니다.
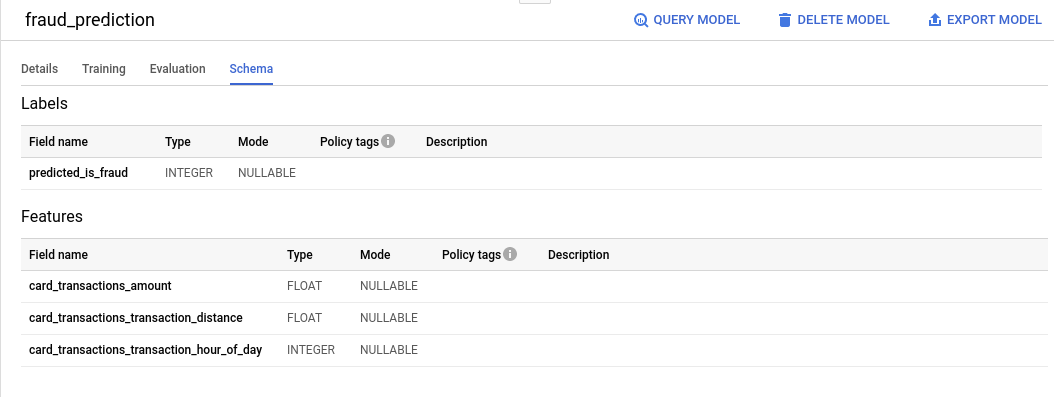
'스키마 탭' 아래에 다음과 같이 표시됩니다.
5. 모델을 사용하여 사기 예측
이제 모델을 사용하여 거래가 사기일 가능성이 있는지 예측해 보겠습니다. 서로 다른 특성의 샘플 트랜잭션 3개를 만들어 보겠습니다.
쿼리 편집기에서 다음 쿼리를 실행합니다.
SELECT * FROM ML.PREDICT(MODEL bq_demo.fraud_prediction, (
SELECT '001' as trans_id, 500.00 as card_transactions_amount, 600 as card_transactions_transaction_distance, 2 as card_transactions_transaction_hour_of_day
UNION ALL
SELECT '002' as trans_id, 5.25 as card_transactions_amount, 2 as card_transactions_transaction_distance, 13 as card_transactions_transaction_hour_of_day
UNION ALL
SELECT '003' as trans_id, 175.50 as card_transactions_amount, 45 as card_transactions_transaction_distance, 10 as card_transactions_transaction_hour_of_day
), STRUCT(0.55 AS threshold)
);
다음과 같은 결과가 나타납니다.
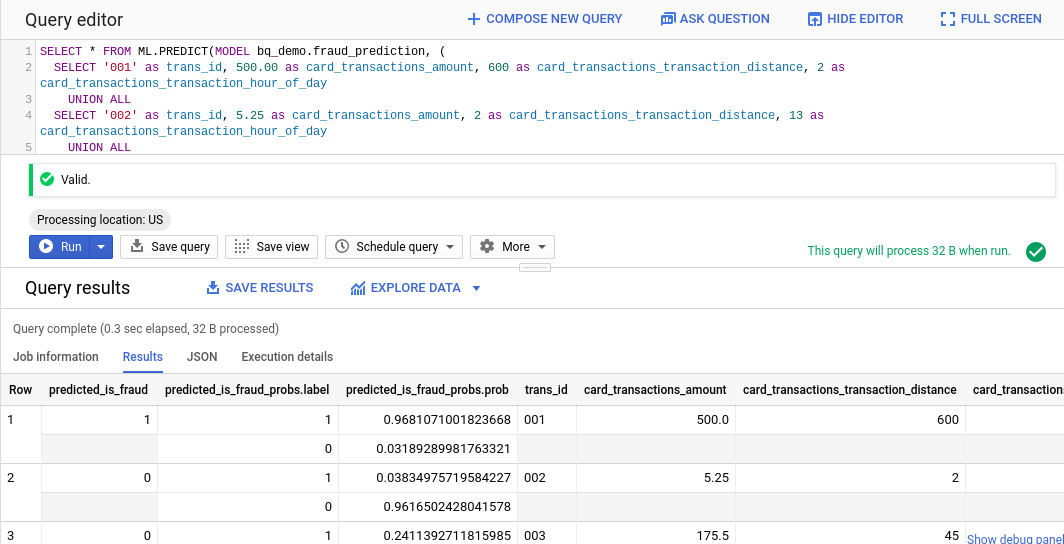
보시다시피 첫 번째 거래는 모델에 따라 사기일 가능성이 거의 있지만 두 번째 및 세 번째 거래는 사기가 아닐 것으로 예측됩니다. 기준치를 기본값인 50%에서 55%로 설정했습니다. 추가 데이터로 모델을 학습시키거나 속성을 추가하여 정확도를 개선할 수 있습니다.
6. 지리정보 분석을 사용해 우편번호로 사기 거래 식별
BigQuery는 지리정보 데이터를 풍부하게 지원합니다. 다음은 우편번호 경계의 공개 데이터 세트를 사용하여 판매자 거래의 위도와 경도를 고려하여 GIS 함수 ST_WITHIN을 사용하여 우편번호를 확인하는 예입니다.
쿼리 편집기에서 다음 코드를 실행합니다.
WITH trans_by_zip as (
SELECT
card_transactions.trans_id,
zip_code AS merchant_zip,
city as merchant_city,
county as merchant_county,
state_name as merchant_state
FROM
bq_demo.card_transactions AS card_transactions,
bigquery-public-data.geo_us_boundaries.zip_codes AS zip_codes
WHERE ST_Within(ST_GEOGPOINT((cast(card_transactions.merchant_lon as FLOAT64)),(cast(card_transactions.merchant_lat as FLOAT64))),zip_codes.zip_code_geom)
)
SELECT merchant_zip, 1.0 * (SUM(is_fraud)) / nullif((COUNT(*)),0) AS percent_transactions_fraud
FROM bq_demo.card_transactions t, trans_by_zip
WHERE t.trans_id = trans_by_zip.trans_id
GROUP BY merchant_zip
ORDER BY percent_transactions_fraud DESC;
다음과 같은 결과가 표시됩니다.
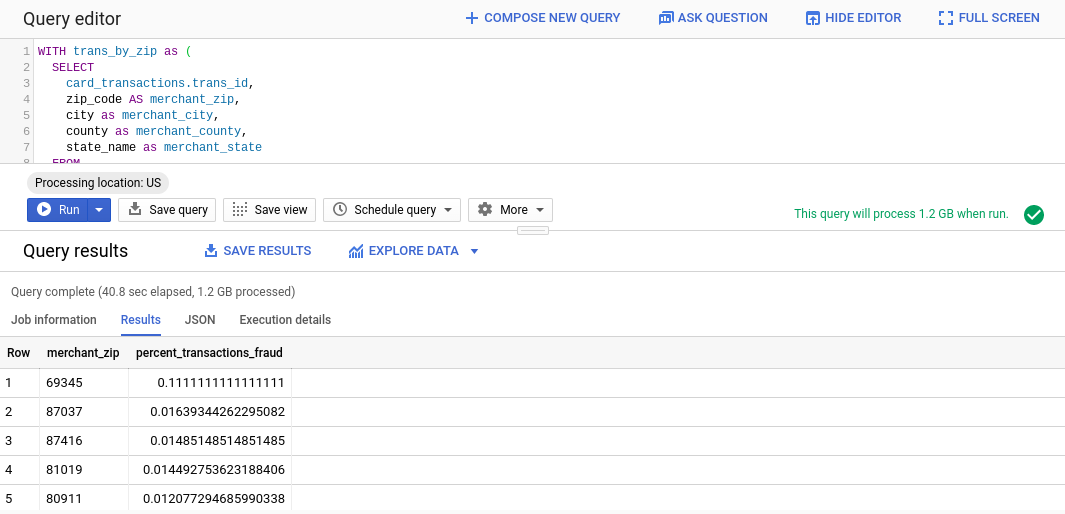
보시다시피 대부분의 우편번호에서 사기 비율은 상대적으로 작지만 (2% 미만) 69345의 사기 비율은 놀라운 11%입니다. 이는 Google에서 조사해야 할 부분일 수 있습니다.