
1. Wprowadzenie
BigQuery to bezserwerowa, wysoce skalowalna i ekonomiczna hurtownia danych. Wystarczy, że przeniesiesz swoje dane do BigQuery i całą ciężką pracę pozwolisz wykonać nam, aby móc skupić się na tym, co naprawdę ważne, czyli na prowadzeniu firmy. Możesz kontrolować opcje dostępu zarówno do projektu, jak i do danych w zależności od wymagań Twojej firmy (takich jak potrzeba umożliwienia innym przeglądania danych lub wysyłania w związku z nimi zapytań).
W tym module poznasz możliwości analityczne BigQuery. Dowiesz się, jak zaimportować zbiór danych z zasobnika Cloud Storage w Google Cloud Storage i zapoznać się z interfejsem BigQuery, pracując ze zbiorem danych dotyczących bankowości detalicznej. W tym module dowiesz się też, jak odkrywać kluczowe funkcje BigQuery, które znacznie ułatwiają codzienną analizę, takie jak eksportowanie wyników zapytań do arkusza kalkulacyjnego, wyświetlanie i uruchamianie zapytań z historii zapytań, sprawdzanie wydajności zapytań oraz tworzenie widoków tabel do użytku przez inne zespoły i działy.
Czego się nauczysz
Z tego modułu nauczysz się, jak:
- Wczytywanie nowych danych do BigQuery
- Zapoznaj się z interfejsem BigQuery
- Uruchamianie zapytań w BigQuery
- Wyświetlanie skuteczności zapytania
- Tworzenie widoków w BigQuery
- Bezpieczne udostępnianie zbiorów danych innym osobom
2. Wprowadzenie: poznawanie interfejsu BigQuery
W tej sekcji dowiesz się, jak poruszać się po interfejsie BigQuery, wyświetlać dostępne zbiory danych i uruchamiać proste zapytania.
Wczytywanie interfejsu BQ
- Wpisz „BigQuery” u góry konsoli Google Cloud Platform.
- Na liście opcji wybierz BigQuery. Wybierz opcję z logo BigQuery, czyli lupą.
Wyświetlanie zbiorów danych i uruchamianie zapytań
- W panelu po lewej stronie, w sekcji Zasoby, kliknij projekt BigQuery.
- Kliknij
bq_demo, aby wyświetlić tabele w tym zbiorze danych. - W polu wyszukiwania wpisz „karta”, aby wyświetlić listę tabel i zbiorów danych, które zawierają w nazwie słowo „karta”.
- Na liście wyników wyszukiwania wybierz tabelę „card_transactions”.
- Aby wyświetlić metadane tej tabeli, w panelu
card_transactionskliknij kartę Szczegóły. - Kliknij kartę Podgląd, aby wyświetlić podgląd tabeli.
[Competitive Talking Point]: Integracja z Data Catalog Google oznacza, że metadanymi BigQuery można zarządzać wraz z innymi źródłami danych, takimi jak jeziora danych czy operacyjne źródła danych. To jeden z przykładów pokazujących, że Google Cloud to nie tylko relacyjna hurtownia danych, ale cała platforma danych analitycznych.
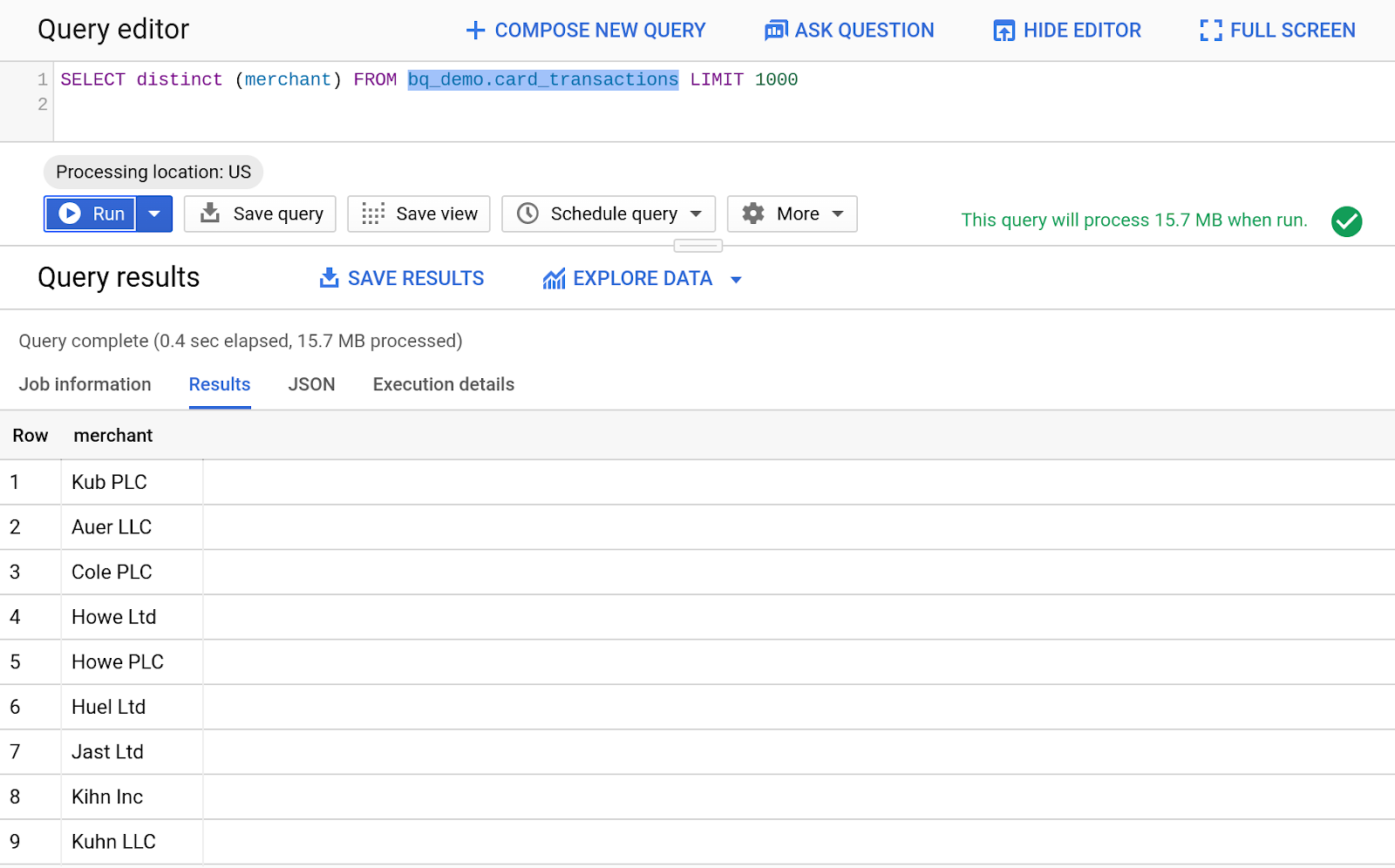
- Kliknij ikonę lupy, aby wysłać zapytanie do tabeli „card_transactions”. W edytorze zapytań BigQuery pojawi się wygenerowany automatycznie tekst.
- Wpisz poniższy kod, aby wyświetlić różnych sprzedawców z tabeli Card_Transactions.
SELECT distinct (merchant) FROM bq_demo.card_transactions LIMIT 1000
- Aby uruchomić zapytanie, kliknij przycisk Uruchom.
3. Tworzenie zbiorów danych i udostępnianie widoków
Udostępnianie danych i zarządzanie nimi jest kluczowe. Można to zrobić w intuicyjny sposób w interfejsie BigQuery. Z tej sekcji dowiesz się, jak utworzyć nowy zbiór danych, wypełnić go widokiem i udostępnić go.
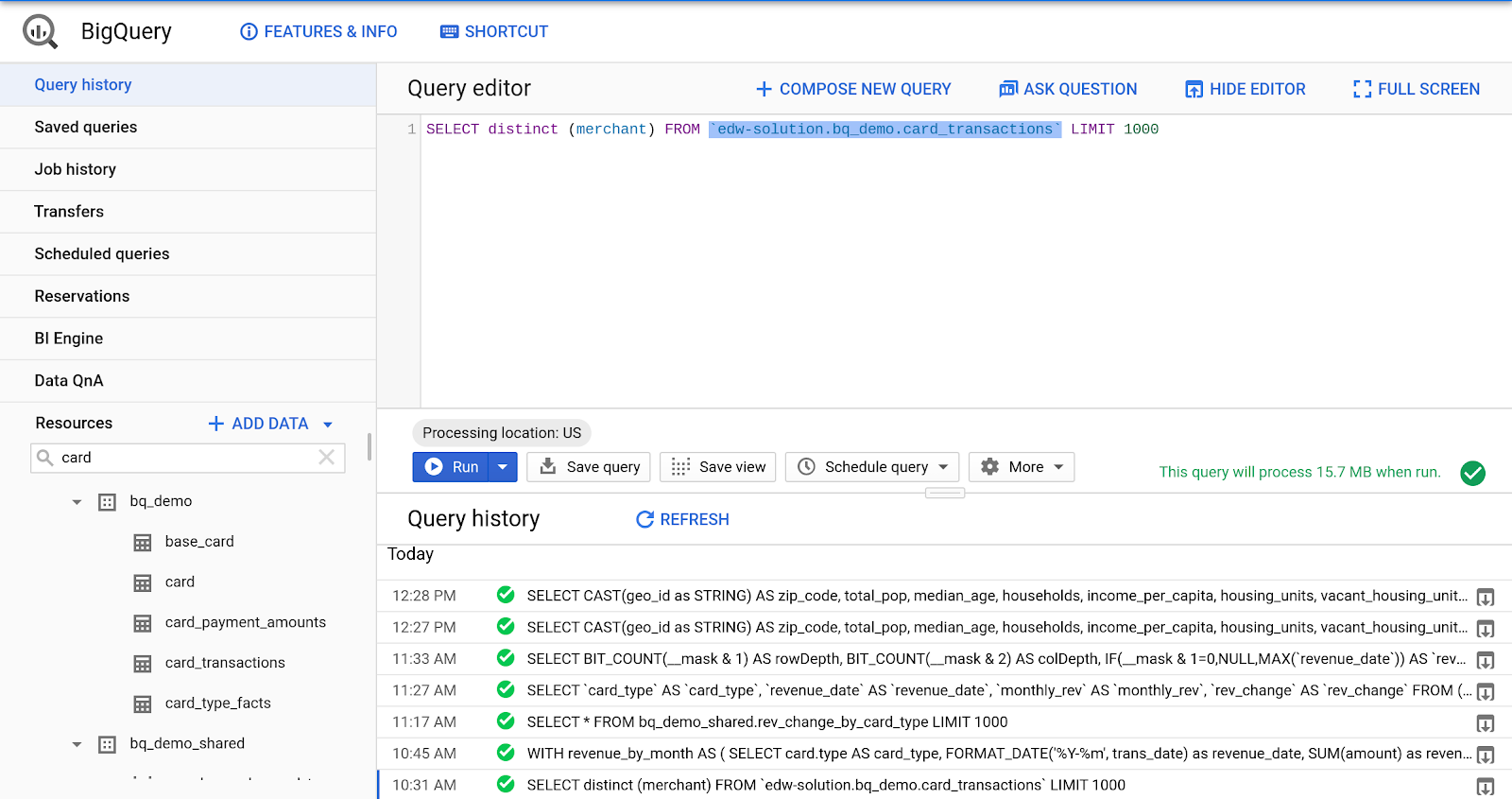
Wyświetlanie historii zapytań
- W okienku po lewej stronie konsoli GCP kliknij „Historia zapytań”.
- Kliknij odśwież w panelu Historia zapytań.
- Aby wyświetlić wyniki zapytania, kliknij ikonę pobierania lub strzałkę po prawej stronie zapytania.
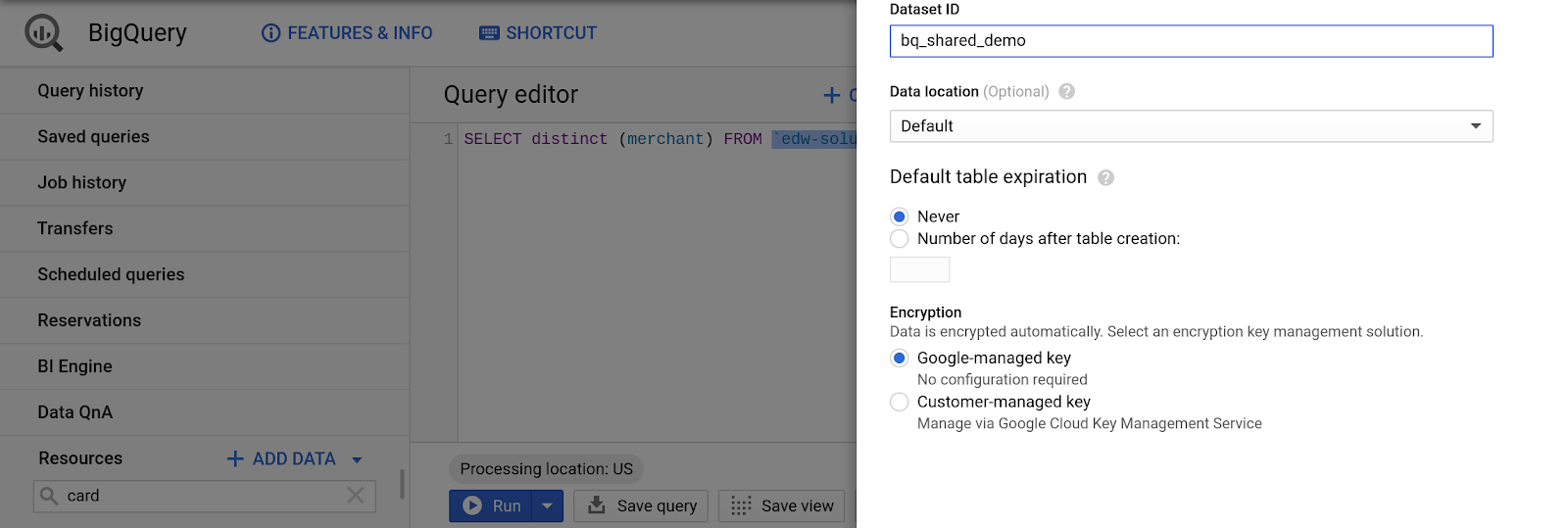
Tworzenie nowego zbioru danych
- W panelu zasobów interfejsu BigQuery wybierz [nazwa projektu].
- W panelu informacji o projekcie kliknij „Utwórz nowy zbiór danych”.
- W przypadku identyfikatora zbioru danych:
bq_demo_shared
- W pozostałych polach pozostaw wartości domyślne.
- Kliknij „Utwórz zbiór danych”.
Tworzenie widoków
[Competitive Talking Point]: BigQuery jest w pełni zgodna ze standardem ANSI SQL i obsługuje zarówno proste, jak i złożone złączenia wielu tabel oraz zaawansowane funkcje analityczne. Stale udostępniamy ulepszone funkcje obsługi typowych typów danych i funkcji SQL używanych w tradycyjnych hurtowniach danych, aby ułatwić proces migracji.
- U góry panelu Edytor zapytań kliknij „Utwórz nowe zapytanie”.
- Wklej do edytora zapytań ten kod:
WITH revenue_by_month AS (
SELECT
card.type AS card_type,
FORMAT_DATE('%Y-%m', trans_date) as revenue_date,
SUM(amount) as revenue
FROM bq_demo.card_transactions
JOIN bq_demo.card ON card_transactions.cc_number = card.card_number
WHERE trans_date DATE_ADD(CURRENT_DATE, INTERVAL -1 YEAR)
GROUP BY card_type, revenue_date
)
SELECT
card_type,
revenue_date,
revenue as monthly_rev,
revenue - LAG(revenue) OVER (ORDER BY card_type, revenue_date ASC) as rev_change
FROM revenue_by_month
ORDER BY card_type, revenue_date ASC;
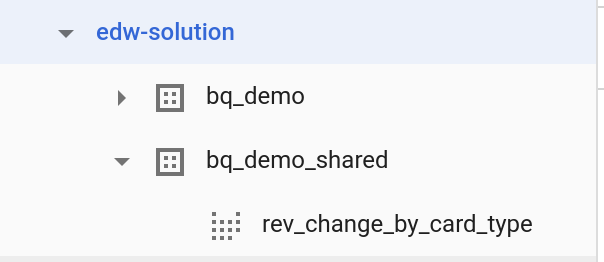
- Kliknij „Zapisz widok”.
- Wybierz bieżący projekt jako nazwę projektu.
- Wybierz nowo utworzony zbiór danych:
bq_demo_shared
- W przypadku nazwy tabeli:
rev_change_by_card_type
- Kliknij Zapisz.
Udostępnianie widoków i zbiorów danych
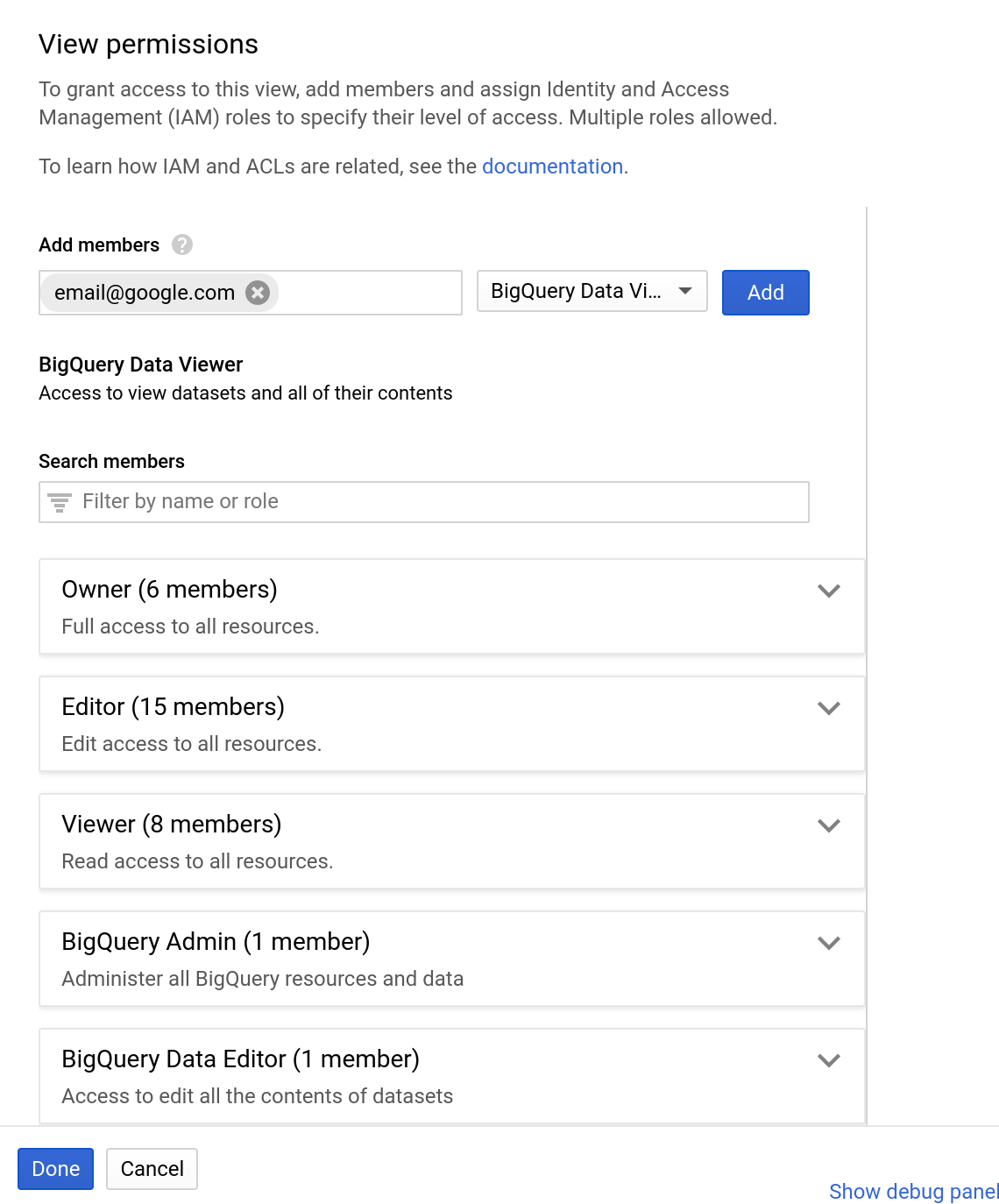
- Wybierz zbiór danych „bq_demo_shared” w lewym okienku zasobów w interfejsie BigQuery.
- W panelu informacji o zbiorze danych kliknij „Udostępnij zbiór danych”.
- Wpisz adres e-mail
- W menu Rola wybierz „Wyświetlający dane BigQuery”.
- Kliknij „Dodaj”
- Kliknij Gotowe.
Przeglądanie danych w Arkuszach
[Competitive Talking Point]: Kolejną zaletą BigQuery w porównaniu z konkurencją jest silnik analityki biznesowej. Silnik analizy biznesowej może sprawić, że zapytania podsumowujące typu BI będą zwracać wyniki w czasie krótszym niż sekunda dzięki silnikowi buforowania w pamięci. Jest to obecnie obsługiwane przez Google Studio danych, ale wkrótce będzie dostępne, aby przyspieszyć wszystkie zapytania w BigQuery.
Na przykład:
Snowflake korzysta z narzędzi BI innych firm do tworzenia paneli i wizualizacji danych, a GCP oferuje szereg zintegrowanych narzędzi BI, w tym Połączone arkusze, Studio danych i Looker.
- Wybierz widok „rev_change_by_card_type” w lewym okienku zasobów w interfejsie BigQuery.
- Kliknij lupę, aby wysłać zapytanie dotyczące widoku.

- Typ:
WYBIERZ *
FROM bq_demo_shared.rev_change_by_card_type
- Kliknij Uruchom.
- Kliknij ikonę „Eksportuj” w panelu wyników.
- Wybierz „Eksploruj dane w Arkuszach”.
- Kliknij „Rozpocznij analizę”.
- Wybierz „Tabela przestawna”.
- Wybierz „Nowy arkusz”.
- Kliknąć przycisk „Utwórz”.
- W sekcji Wiersz w Edytorze tabeli przestawnej po prawej stronie okna Arkuszy dodaj „revenue_date”.
- W sekcji Kolumna w Edytorze tabeli przestawnej dodaj „card_type”.
- W sekcji Kolumna w Edytorze tabeli przestawnej dodaj „monthly_rev”.
- Kliknij przycisk Zastosuj
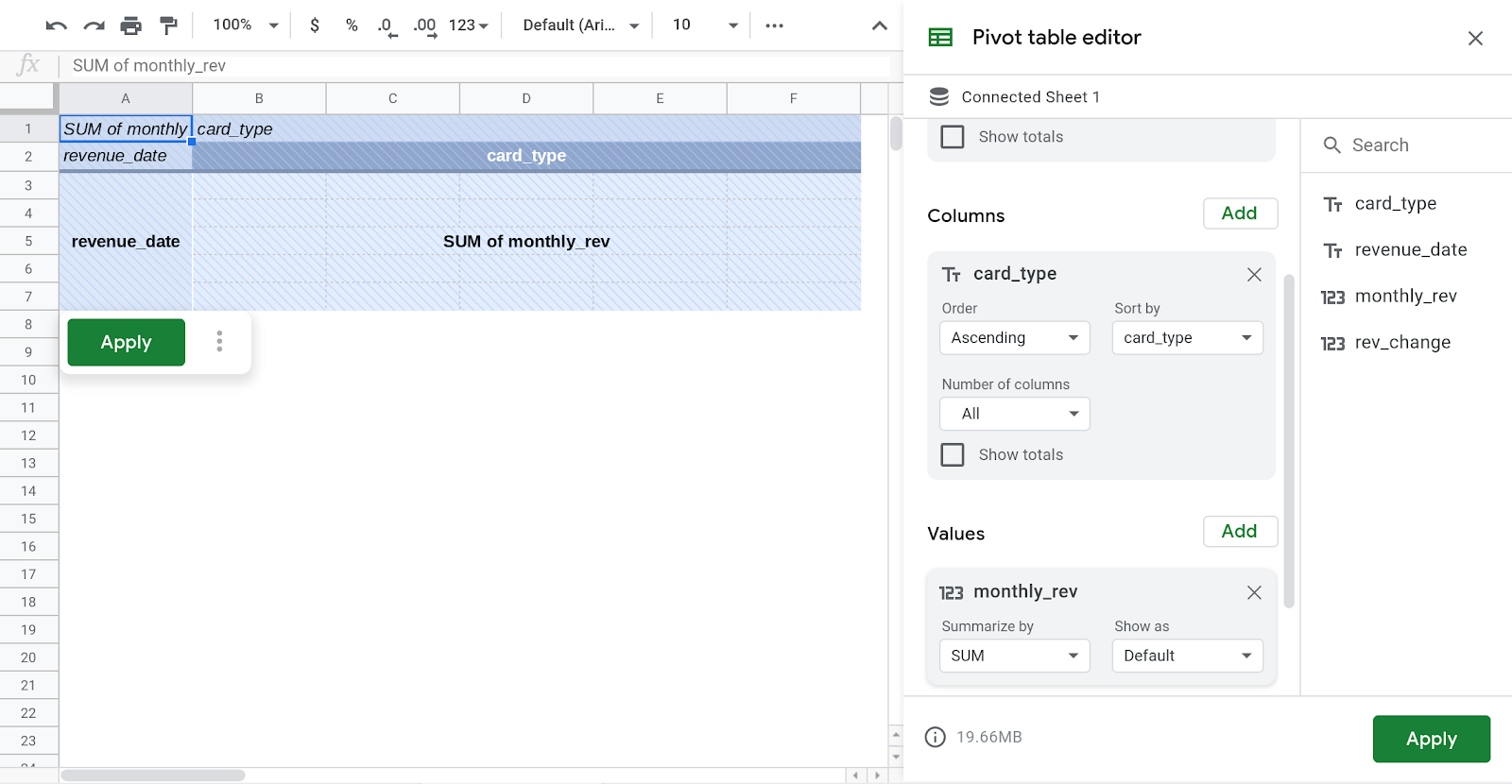
- Przejdź do górnego paska w interfejsie Arkuszy i kliknij Wstaw Wykres.
4. Konfiguracja: integracja danych
Z tej sekcji dowiesz się, jak utworzyć nową tabelę i wykonać złączenia na jednym z wielu publicznych zbiorów danych dostępnych w Google Cloud.
[Competitive Talking Point]:
BigQuery obsługuje udostępnione zbiory danych od lat. Klienci w dowolnym projekcie mogą wysyłać zapytania zarówno do publicznych zbiorów danych, jak i do zbiorów danych w innych projektach, które zostały im udostępnione.
BigQuery może obsługiwać jeziora danych w GCS za pomocą tabel zewnętrznych. Oprócz wczytywania zbiorczego BigQuery obsługuje przesyłanie strumieniowe danych do bazy danych z szybkością ponad setek MB na sekundę. Snowflake nie obsługuje przesyłania strumieniowego danych.
Importowanie danych do nowej tabeli
- W panelu zasobów wybierz zbiór danych bq_demo.
- W panelu informacji o zbiorze danych wybierz „Utwórz tabelę”.
- Wybierz Google Cloud Storage jako źródło
- W polu tekstowym ścieżki pliku:
gs://retail-banking-looker/district
- Wybierz CSV jako format pliku.
- Wpisz „district” w polu Nazwa tabeli.
- Zaznacz pole wyboru Automatycznie wykrywaj schemat.
- Kliknij Utwórz tabelę.
Wykonywanie zapytań dotyczących publicznego zbioru danych
- W edytorze zapytań wpisz to zapytanie:
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
housing_units,
vacant_housing_units_for_sale,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
ROUND(SAFE_DIVIDE(bachelors_degree_or_higher_25_64, pop_25_64),4) AS rate_bachelors_degree_or_higher_25_64
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`;
- Kliknij Uruchom.
- Wyświetlanie wyników
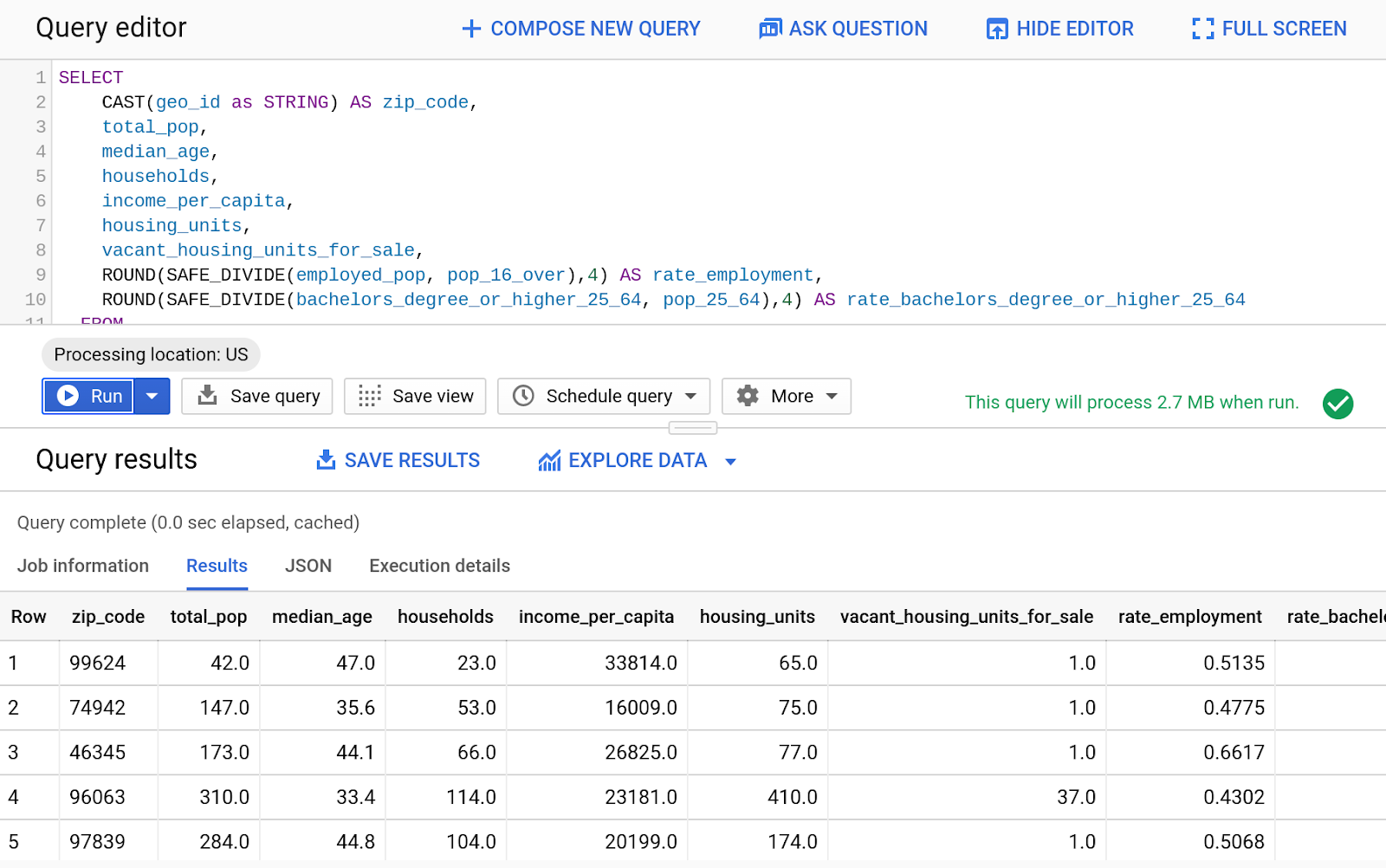
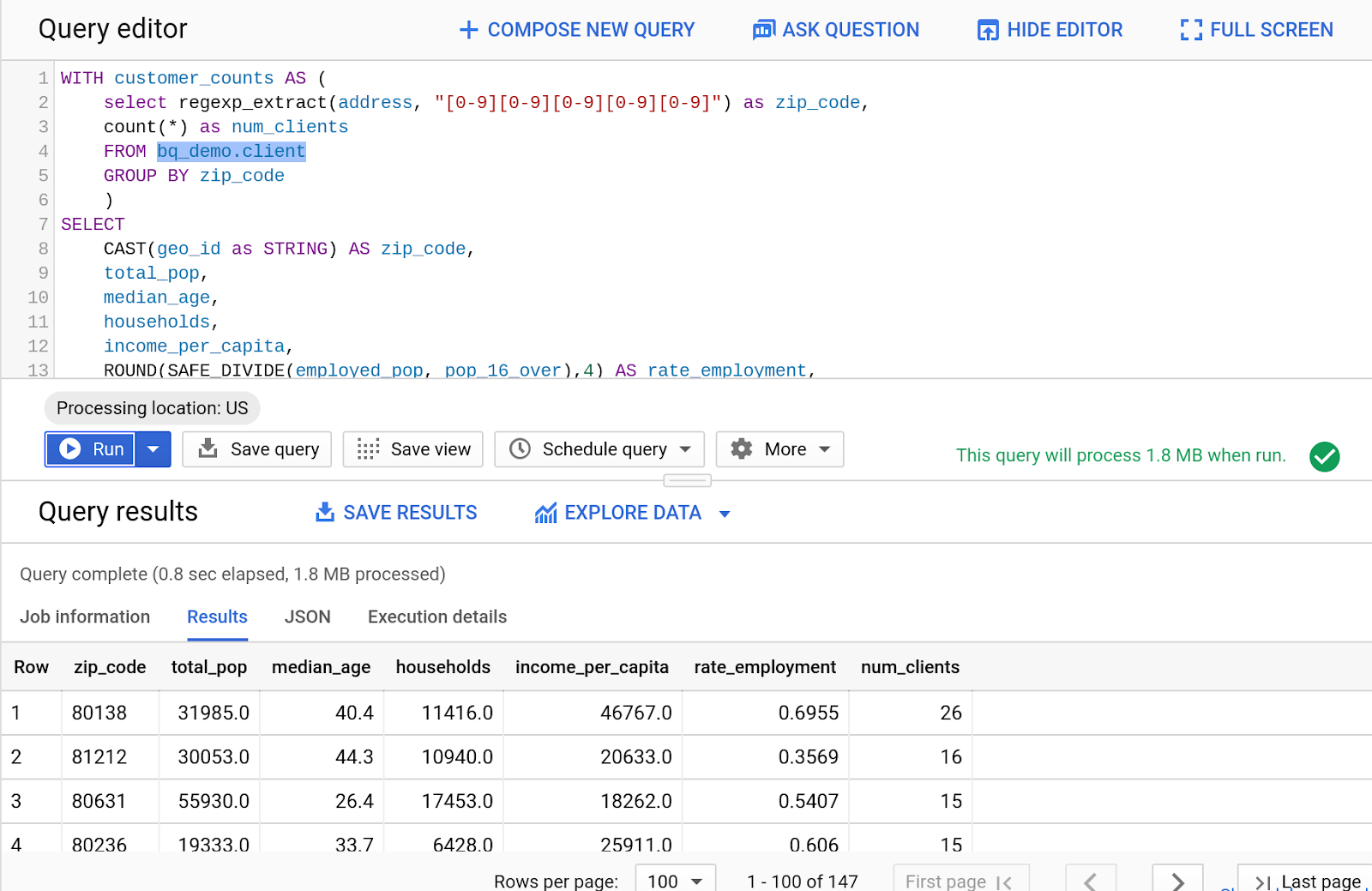
- Teraz połączymy te dane publiczne z innym zapytaniem. Wpisz w edytorze zapytań ten kod SQL:
WITH customer_counts AS (
select regexp_extract(address, "[0-9][0-9][0-9][0-9][0-9]") as zip_code,
count(*) as num_clients
FROM bq_demo.client
GROUP BY zip_code
)
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
num_clients
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`
JOIN customer_counts on zip_code = geo_id
ORDER BY num_clients DESC
- Kliknij Uruchom.
- Wyświetlanie wyników
5. Zarządzanie zasobami
Praca z miejscami i rezerwacjami
BQ oferuje kilka modeli cenowych, które spełnią Twoje potrzeby. Większość dużych klientów korzysta głównie ze stałej opłaty, aby mieć przewidywalne ceny i zarezerwowaną pojemność. Aby przekroczyć tę podstawową pojemność, BigQuery oferuje elastyczne przedziały, które umożliwiają dynamiczne zwiększanie pojemności, a następnie automatyczne zmniejszanie jej bez wpływu na wykonywane zapytania. BigQuery ma też model skanowania bajtów, który pozwala płacić tylko za uruchomione zapytania.
[Argument konkurencyjny: niektórzy konkurenci pracują wyłącznie w modelu o stałej pojemności, w którym klienci muszą przydzielać wirtualną hurtownię danych do każdego zadania w swojej organizacji. Oprócz modelu o niskich kosztach za zapytanie, który ułatwia rozpoczęcie korzystania z BigQuery, obsługujemy model cenowy oparty na stałej opłacie za moc obliczeniową, w którym nieużywana moc obliczeniowa może być współdzielona między zestawem zadań.]
- Otwórz kartę rezerwacji.
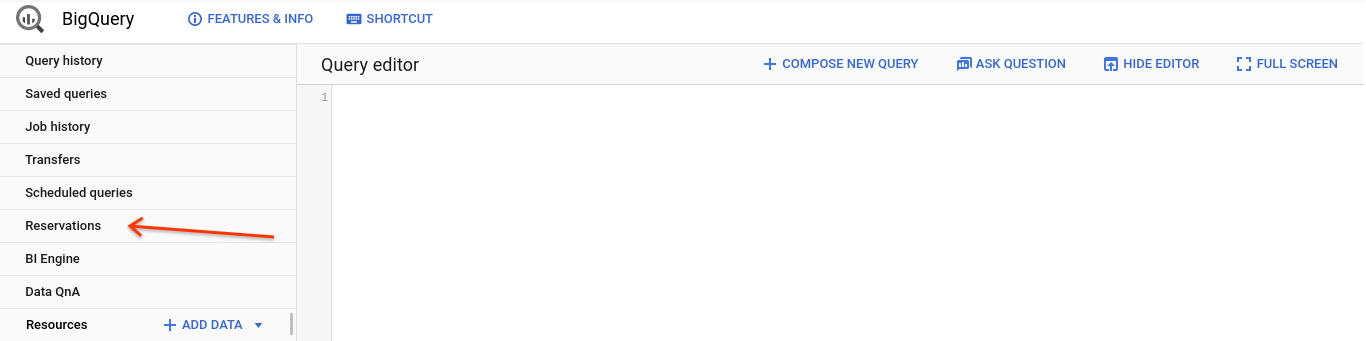
- Kliknij „Kup miejsca”.
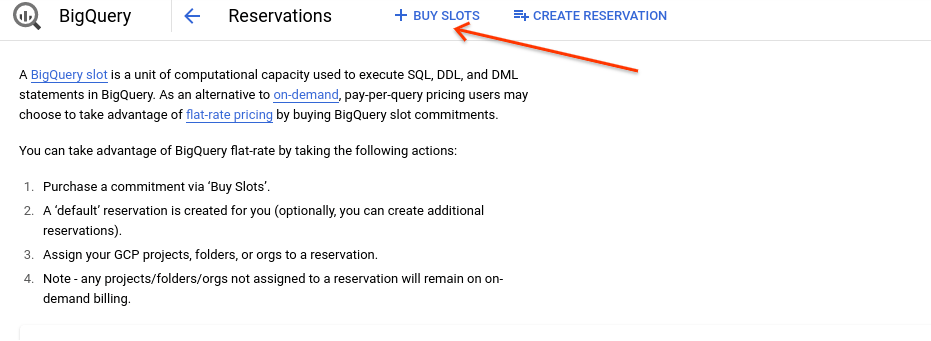
- Jako czas trwania wybierz „Elastyczny”.
- Wybierz 500 przedziałów czasu.
- Potwierdź zakup.
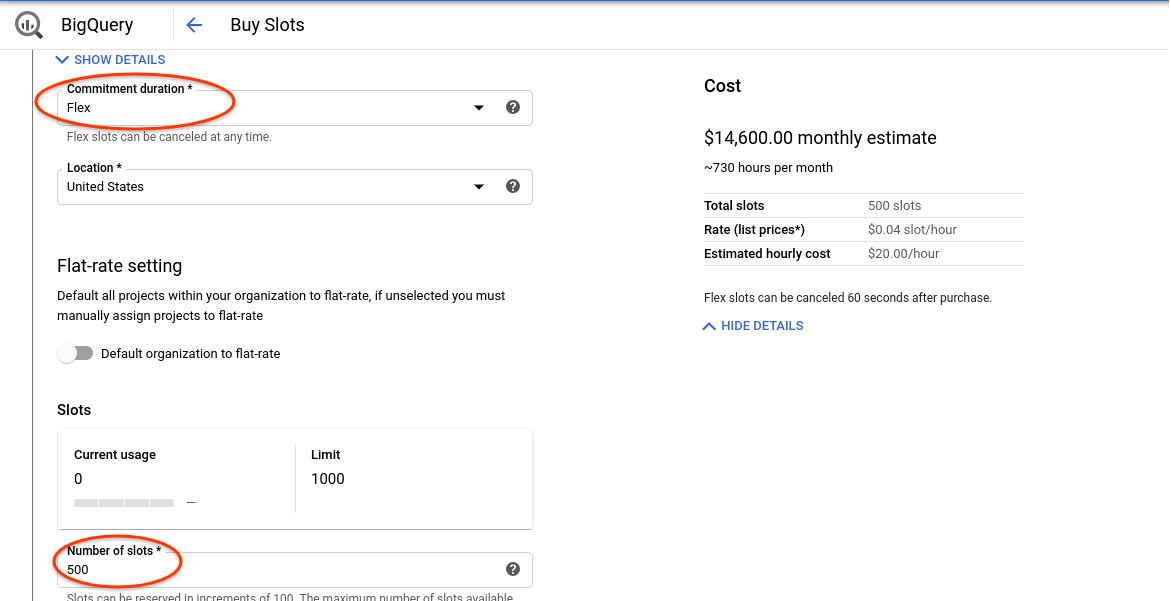
- Kliknij Wyświetl zobowiązania na przedział.
- Kliknij „Utwórz rezerwację”.
- Użytkownik „demo” jako nazwa rezerwacji
- Wybierz Stany Zjednoczone jako lokalizację.
- Wpisz 500 w przypadku wszystkich dostępnych miejsc.
- Kliknij Przypisania
- Wybieranie bieżącego projektu dla projektu organizacji
- Wybierz „demo” jako identyfikator rezerwacji.
- Kliknij Utwórz”.