
1. Introducción
En este codelab, usarás las herramientas de supervisión de Cloud Bigtable para crear varias obras de arte escribiendo y leyendo datos con Cloud Dataflow y el cliente de Java HBase.
Obtendrás información para hacer las siguientes acciones
- Cargar grandes cantidades de datos en Bigtable con Cloud Dataflow
- Supervisa las instancias y tablas de Bigtable mientras se transfieren tus datos.
- Consulta Bigtable con un trabajo de Dataflow
- Explora la herramienta Key Visualizer que se puede usar para encontrar hotspots debido al diseño de tu esquema
- Crea arte con Key Visualizer

¿Cómo calificarías tu experiencia en el uso de Cloud Bigtable?
¿Cómo usarás este instructivo?
2. Crea tu base de datos de Bigtable
Cloud Bigtable es el servicio de base de datos NoSQL de Google para trabajar con macrodatos. Es la misma base de datos que utilizan muchos de los servicios centrales de Google, como la Búsqueda, Analytics, Maps y Gmail. Es ideal para ejecutar grandes cargas de trabajo analíticas y compilar aplicaciones de baja latencia. Consulta el Codelab de Introducción a Cloud Bigtable y obtén una introducción detallada.
Crea un proyecto
Primero, crea un proyecto nuevo. Usar Cloud Shell integrado, que puedes abrir haciendo clic en "Activar Cloud Shell" en la esquina superior derecha.

Configura las siguientes variables de entorno para facilitar la copia y el pegado de los comandos del codelab:
BIGTABLE_PROJECT=$GOOGLE_CLOUD_PROJECT INSTANCE_ID="keyviz-art-instance" CLUSTER_ID="keyviz-art-cluster" TABLE_ID="art" CLUSTER_NUM_NODES=1 CLUSTER_ZONE="us-central1-c" # You can choose a zone closer to you
Cloud Shell ya incluye las herramientas que usarás en este codelab, la herramienta de línea de comandos de gcloud, la interfaz de línea de comandos de cbt y Maven, ya instalados.
Habilita las API de Cloud Bigtable mediante la ejecución de este comando.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
Ejecuta el siguiente comando para crear una instancia:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
Después de crear la instancia, propaga el archivo de configuración de cbt y, luego, crea una tabla y una familia de columnas con los siguientes comandos:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
3. Aprende a escribir en Bigtable con Dataflow
Conceptos básicos de escritura
Cuando escribes en Cloud Bigtable, debes proporcionar un objeto de configuración CloudBigtableTableConfiguration. Este objeto especifica el ID del proyecto y de la instancia de tu tabla, así como el nombre de la tabla en sí:
CloudBigtableTableConfiguration bigtableTableConfig =
new CloudBigtableTableConfiguration.Builder()
.withProjectId(PROJECT_ID)
.withInstanceId(INSTANCE_ID)
.withTableId(TABLE_ID)
.build();
Luego, tu canalización puede pasar objetos Mutation de HBase, que pueden incluir Put y Delete.
p.apply(Create.of("hello", "world"))
.apply(
ParDo.of(
new DoFn<String, Mutation>() {
@ProcessElement
public void processElement(@Element String rowkey, OutputReceiver<Mutation> out) {
long timestamp = System.currentTimeMillis();
Put row = new Put(Bytes.toBytes(rowkey));
row.addColumn(...);
out.output(row);
}
}))
.apply(CloudBigtableIO.writeToTable(bigtableTableConfig));
El trabajo de LoadData Dataflow
En la siguiente página, se mostrará cómo ejecutar el trabajo LoadData, pero aquí destacaré las partes importantes de la canalización.
Para generar datos, deberás crear una canalización que use la clase GenerateSequence (de manera similar a un bucle for) para escribir una cantidad de filas con algunos megabytes de datos aleatorios. La clave de fila será el número de secuencia con relleno y invertido, por lo que 250 se convierte en 0000000052.
LoadData.java
String numberFormat = "%0" + maxLength + "d";
p.apply(GenerateSequence.from(0).to(max))
.apply(
ParDo.of(
new DoFn<Long, Mutation>() {
@ProcessElement
public void processElement(@Element Long rowkey, OutputReceiver<Mutation> out) {
String paddedRowkey = String.format(numberFormat, rowkey);
// Reverse the rowkey for more efficient writing
String reversedRowkey = new StringBuilder(paddedRowkey).reverse().toString();
Put row = new Put(Bytes.toBytes(reversedRowkey));
// Generate random bytes
byte[] b = new byte[(int) rowSize];
new Random().nextBytes(b);
long timestamp = System.currentTimeMillis();
row.addColumn(Bytes.toBytes(COLUMN_FAMILY), Bytes.toBytes("C"), timestamp, b);
out.output(row);
}
}))
.apply(CloudBigtableIO.writeToTable(bigtableTableConfig));
4. Generar datos en Bigtable y supervisar las entradas
Los siguientes comandos ejecutarán un trabajo de Dataflow que genera 40 GB de datos en tu tabla, lo que es más que suficiente para que se active Key Visualizer:
Habilita la API de Cloud Dataflow
gcloud services enable dataflow.googleapis.com
Obtén el código de GitHub y cámbialo al directorio.
git clone https://github.com/GoogleCloudPlatform/java-docs-samples.git cd java-docs-samples/bigtable/beam/keyviz-art
Genera los datos (la secuencia de comandos tarda alrededor de 15 minutos)
mvn compile exec:java -Dexec.mainClass=keyviz.LoadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT"
Supervisa la importación
Puedes supervisar el trabajo en la IU de Cloud Dataflow. Además, puedes ver la carga en tu instancia de Cloud Bigtable con su IU de supervisión.
En la IU de Dataflow, podrás ver el gráfico del trabajo y las diversas métricas del trabajo, incluidos los elementos procesados, las CPU virtuales actuales y la capacidad de procesamiento.


Bigtable tiene herramientas de supervisión estándar para las operaciones de lectura y escritura, el almacenamiento utilizado, la tasa de errores y mucho más a nivel de instancia, clúster y tabla. Además, Bigtable también cuenta con Key Visualizer, que desglosa tu uso según las claves de fila que usaremos una vez que se hayan generado al menos 30 GB de datos.

5. Aprende a leer desde Bigtable con Dataflow
Conceptos básicos de lectura
Cuando lees desde Cloud Bigtable, debes proporcionar un objeto de configuración CloudBigtableTableScanConfiguration. Esto es similar a CloudBigtableTableConfiguration, pero puedes especificar las filas que se analizarán y leerán.
Scan scan = new Scan();
scan.setCacheBlocks(false);
scan.setFilter(new FirstKeyOnlyFilter());
CloudBigtableScanConfiguration config =
new CloudBigtableScanConfiguration.Builder()
.withProjectId(options.getBigtableProjectId())
.withInstanceId(options.getBigtableInstanceId())
.withTableId(options.getBigtableTableId())
.withScan(scan)
.build();
Luego, úsalo para iniciar tu canalización:
p.apply(Read.from(CloudBigtableIO.read(config)))
.apply(...
Sin embargo, si deseas realizar una lectura como parte de tu canalización, puedes pasar un CloudBigtableTableConfiguration a un doFn que extienda AbstractCloudBigtableTableDoFn.
p.apply(GenerateSequence.from(0).to(10))
.apply(ParDo.of(new ReadFromTableFn(bigtableTableConfig, options)));
Luego, llama a super() con tu configuración y a getConnection() para obtener una conexión distribuida.
public static class ReadFromTableFn extends AbstractCloudBigtableTableDoFn<Long, Void> {
public ReadFromTableFn(CloudBigtableConfiguration config, ReadDataOptions readDataOptions) {
super(config);
}
@ProcessElement
public void processElement(PipelineOptions po) {
Table table = getConnection().getTable(TableName.valueOf(options.getBigtableTableId()));
ResultScanner imageData = table.getScanner(scan);
}
}
El trabajo de Dataflow de ReadData
Para este codelab, deberás leer de la tabla cada segundo, de modo que puedas iniciar tu canalización con una secuencia generada que active varios rangos de lectura según la hora en que se ingresó un archivo CSV.
Se requieren cálculos matemáticos para determinar qué rangos de filas analizar según el tiempo, pero puedes hacer clic en el nombre del archivo para ver el código fuente si quieres obtener más información.
ReadData.java
p.apply(GenerateSequence.from(0).withRate(1, new Duration(1000)))
.apply(ParDo.of(new ReadFromTableFn(bigtableTableConfig, options)));
ReadData.java
public static class ReadFromTableFn extends AbstractCloudBigtableTableDoFn<Long, Void> {
List<List<Float>> imageData = new ArrayList<>();
String[] keys;
public ReadFromTableFn(CloudBigtableConfiguration config, ReadDataOptions readDataOptions) {
super(config);
keys = new String[Math.toIntExact(getNumRows(readDataOptions))];
downloadImageData(readDataOptions.getFilePath());
generateRowkeys(getNumRows(readDataOptions));
}
@ProcessElement
public void processElement(PipelineOptions po) {
// Determine which column will be drawn based on runtime of job.
long timestampDiff = System.currentTimeMillis() - START_TIME;
long minutes = (timestampDiff / 1000) / 60;
int timeOffsetIndex = Math.toIntExact(minutes / KEY_VIZ_WINDOW_MINUTES);
ReadDataOptions options = po.as(ReadDataOptions.class);
long count = 0;
List<RowRange> ranges = getRangesForTimeIndex(timeOffsetIndex, getNumRows(options));
if (ranges.size() == 0) {
return;
}
try {
// Scan with a filter that will only return the first key from each row. This filter is used
// to more efficiently perform row count operations.
Filter rangeFilters = new MultiRowRangeFilter(ranges);
FilterList firstKeyFilterWithRanges = new FilterList(
rangeFilters,
new FirstKeyOnlyFilter(),
new KeyOnlyFilter());
Scan scan =
new Scan()
.addFamily(Bytes.toBytes(COLUMN_FAMILY))
.setFilter(firstKeyFilterWithRanges);
Table table = getConnection().getTable(TableName.valueOf(options.getBigtableTableId()));
ResultScanner imageData = table.getScanner(scan);
} catch (Exception e) {
System.out.println("Error reading.");
e.printStackTrace();
}
}
/**
* Download the image data as a grid of weights and store them in a 2D array.
*/
private void downloadImageData(String artUrl) {
...
}
/**
* Generates an array with the rowkeys that were loaded into the specified Bigtable. This is
* used to create the correct intervals for scanning equal sections of rowkeys. Since Bigtable
* sorts keys lexicographically if we just used standard intervals, each section would have
* different sizes.
*/
private void generateRowkeys(long maxInput) {
...
}
/**
* Get the ranges to scan for the given time index.
*/
private List<RowRange> getRangesForTimeIndex(@Element Integer timeOffsetIndex, long maxInput) {
...
}
}
6. Crea tu obra maestra
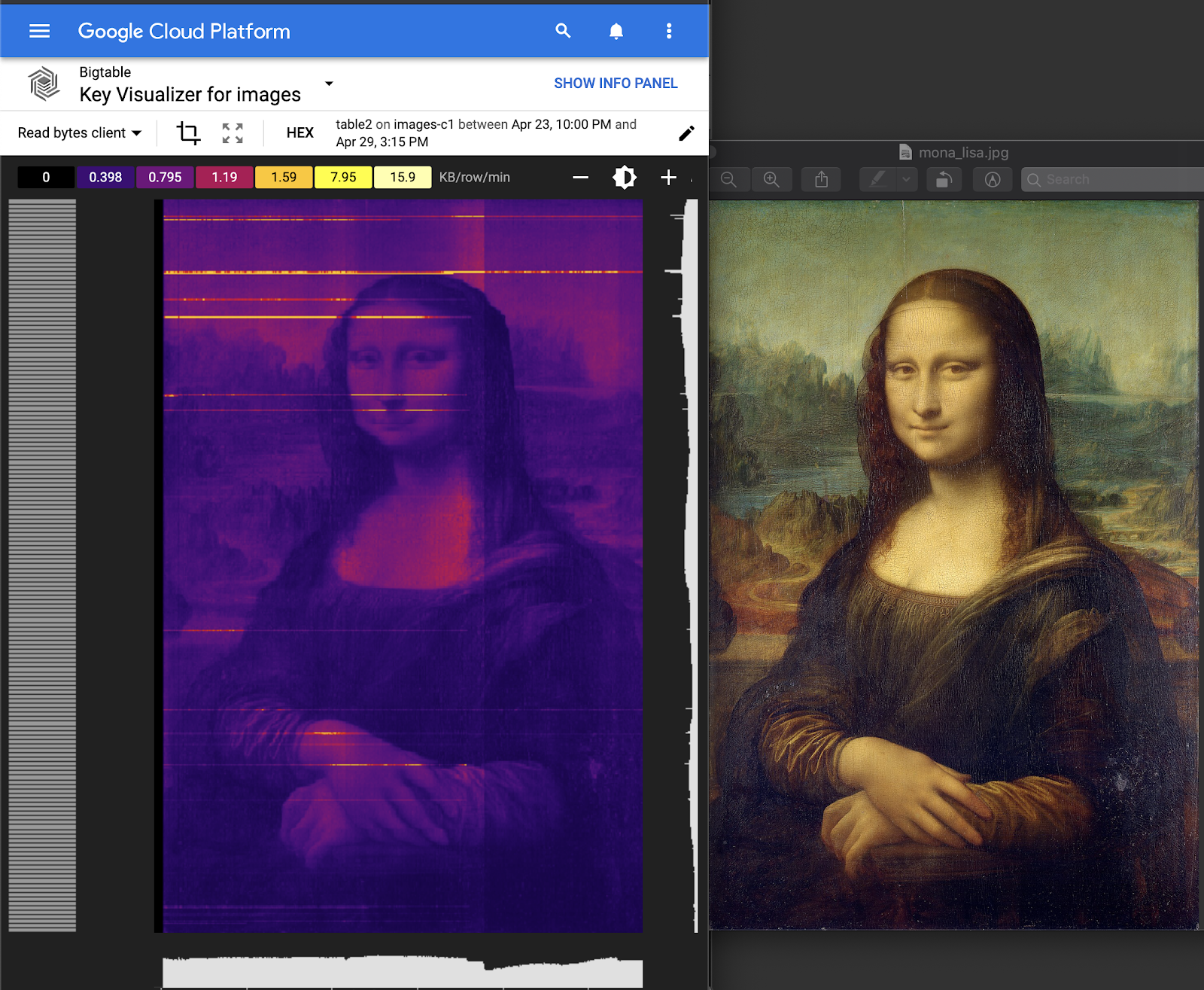
Ahora que sabes cómo cargar datos en Bigtable y leerlos con Dataflow, puedes ejecutar el comando final, que generará una imagen de la Mona Lisa en 8 horas.
mvn compile exec:java -Dexec.mainClass=keyviz.ReadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT"
Puedes usar un bucket con imágenes existentes. O bien, puedes crear un archivo de entrada a partir de cualquiera de tus imágenes con esta herramienta y, luego, subirlo a un bucket público de GCS.
Los nombres de los archivos se crean a partir del ejemplo de gs://keyviz-art/[painting]_[hours]h.txt: gs://keyviz-art/american_gothic_4h.txt
opciones de pintura:
- american_gothic
- mona_lisa
- pearl_earring
- persistence_of_memory
- starry_night
- sunday_afternoon
- the_scream
Opciones de hora: 1, 4, 8, 12, 24, 48, 72, 96, 120 y 144
Para hacer público tu archivo o bucket de GCS, asígnale a allUsers la función Storage Object Viewer.

Cuando hayas elegido tu imagen, simplemente cambia el parámetro --file-path en este comando:
mvn compile exec:java -Dexec.mainClass=keyviz.ReadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT \ --filePath=gs://keyviz-art/american_gothic_4h.txt"
7. Verifícalo más tarde
Es posible que la imagen completa tarde unas horas en cobrar vida, pero después de 30 minutos, deberías comenzar a ver actividad en el visualizador clave. Hay varios parámetros con los que puedes jugar: el zoom, el brillo y las métricas. Puedes hacer zoom con la rueda del mouse o arrastrando un rectángulo en la cuadrícula del visualizador clave.
El brillo cambia la escala de la imagen, lo que es útil si deseas obtener información detallada en un área muy calurosa.

También puedes ajustar la métrica que se muestra. Hay operaciones, cliente de lectura de bytes y cliente de escritura de bytes, por nombrar algunos. "Lee el cliente de bytes" produce imágenes fluidas, mientras que las operaciones produce imágenes con más líneas que pueden verse muy bien en algunas imágenes.

8. Terminar
Realiza una limpieza para evitar cargos
Para evitar que se apliquen cargos a tu cuenta de Google Cloud Platform por los recursos que usaste en este codelab, debes borrar tu instancia.
gcloud bigtable instances delete $INSTANCE_ID
Temas abordados
- Escribe en Bigtable con Dataflow
- Lee de Bigtable con Dataflow (al comienzo de tu canalización, en medio de tu canalización)
- Usa las herramientas de supervisión de Dataflow
- Usa las herramientas de supervisión de Bigtable, incluido Key Visualizer
Próximos pasos
- Obtén más información sobre cómo se creó el material gráfico de Key Visualizer.
- Obtén más información sobre Cloud Bigtable en la documentación.
- Prueba otras características de Google Cloud Platform tú mismo. Revisa nuestros instructivos.