
1. Pengantar
Dalam codelab ini, Anda akan menggunakan alat pemantauan Cloud Bigtable untuk membuat berbagai karya seni melalui penulisan dan pembacaan data dengan Cloud Dataflow dan klien Java HBase.
Anda akan mempelajari cara
- Memuat data dalam jumlah besar ke Bigtable menggunakan Cloud Dataflow
- Memantau instance dan tabel Bigtable saat data Anda ditransfer
- Mengkueri Bigtable menggunakan tugas Dataflow
- Mempelajari alat visualizer utama yang dapat digunakan untuk menemukan hotspot karena desain skema Anda
- Membuat karya seni menggunakan visualizer kunci

Bagaimana Anda menilai pengalaman Anda menggunakan Cloud Bigtable?
Bagaimana Anda akan menggunakan tutorial ini?
2. Membuat database Bigtable Anda
Cloud Bigtable adalah layanan database Big Data NoSQL dari Google. Cloud Bigtable merupakan database yang sama yang mendukung berbagai layanan inti milik Google, termasuk Penelusuran, Analytics, Maps, dan Gmail. Solusi ini ideal untuk menjalankan workload analisis besar dan membangun aplikasi berlatensi rendah. Lihat Pengantar Codelab Cloud Bigtable untuk pengantar yang mendalam.
Membuat project
Pertama, buat proyek baru. Gunakan Cloud Shell bawaan yang dapat Anda buka dengan mengklik tombol "Activate Cloud Shell" di sudut kanan atas.

Tetapkan variabel lingkungan berikut untuk mempermudah penyalinan dan penempelan perintah codelab:
BIGTABLE_PROJECT=$GOOGLE_CLOUD_PROJECT INSTANCE_ID="keyviz-art-instance" CLUSTER_ID="keyviz-art-cluster" TABLE_ID="art" CLUSTER_NUM_NODES=1 CLUSTER_ZONE="us-central1-c" # You can choose a zone closer to you
Cloud Shell dilengkapi dengan alat yang akan Anda gunakan dalam codelab ini, alat command line gcloud, antarmuka command line cbt, dan Maven, yang sudah terinstal.
Aktifkan Cloud Bigtable API dengan menjalankan perintah ini.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
Buat instance dengan menjalankan perintah berikut:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
Setelah Anda membuat instance, isi file konfigurasi cbt, lalu buat tabel dan grup kolom dengan menjalankan perintah berikut:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
3. Pelajari: Menulis ke Bigtable dengan Dataflow
Dasar-dasar penulisan
Saat menulis ke Cloud Bigtable, Anda harus memberikan objek konfigurasi CloudBigtableTableConfiguration. Objek ini menentukan project ID dan ID instance untuk tabel Anda, serta nama tabel itu sendiri:
CloudBigtableTableConfiguration bigtableTableConfig =
new CloudBigtableTableConfiguration.Builder()
.withProjectId(PROJECT_ID)
.withInstanceId(INSTANCE_ID)
.withTableId(TABLE_ID)
.build();
Kemudian, pipeline Anda dapat meneruskan objek Mutation HBase, yang dapat mencakup Put dan Delete.
p.apply(Create.of("hello", "world"))
.apply(
ParDo.of(
new DoFn<String, Mutation>() {
@ProcessElement
public void processElement(@Element String rowkey, OutputReceiver<Mutation> out) {
long timestamp = System.currentTimeMillis();
Put row = new Put(Bytes.toBytes(rowkey));
row.addColumn(...);
out.output(row);
}
}))
.apply(CloudBigtableIO.writeToTable(bigtableTableConfig));
Tugas Dataflow LoadData
Halaman berikutnya akan menunjukkan cara menjalankan tugas LoadData, tetapi di sini saya akan menyebutkan bagian-bagian penting pada pipeline.
Untuk menghasilkan data, Anda akan membuat pipeline yang menggunakan class GenerateSequence (serupa dengan loop for) untuk menulis sejumlah baris dengan beberapa megabyte data acak. Kunci baris akan berupa nomor urut dengan padding dan terbalik, sehingga 250 menjadi 0000000052.
LoadData.java
String numberFormat = "%0" + maxLength + "d";
p.apply(GenerateSequence.from(0).to(max))
.apply(
ParDo.of(
new DoFn<Long, Mutation>() {
@ProcessElement
public void processElement(@Element Long rowkey, OutputReceiver<Mutation> out) {
String paddedRowkey = String.format(numberFormat, rowkey);
// Reverse the rowkey for more efficient writing
String reversedRowkey = new StringBuilder(paddedRowkey).reverse().toString();
Put row = new Put(Bytes.toBytes(reversedRowkey));
// Generate random bytes
byte[] b = new byte[(int) rowSize];
new Random().nextBytes(b);
long timestamp = System.currentTimeMillis();
row.addColumn(Bytes.toBytes(COLUMN_FAMILY), Bytes.toBytes("C"), timestamp, b);
out.output(row);
}
}))
.apply(CloudBigtableIO.writeToTable(bigtableTableConfig));
4. Membuat data ke Bigtable dan memantau aliran masuk
Perintah berikut akan menjalankan tugas dataflow yang menghasilkan data sebesar 40 GB ke tabel Anda, lebih dari cukup untuk diaktifkan oleh Key Visualizer:
Mengaktifkan Cloud Dataflow API
gcloud services enable dataflow.googleapis.com
Dapatkan kode dari github dan ubah ke direktori
git clone https://github.com/GoogleCloudPlatform/java-docs-samples.git cd java-docs-samples/bigtable/beam/keyviz-art
Membuat data (skrip memerlukan waktu sekitar 15 menit)
mvn compile exec:java -Dexec.mainClass=keyviz.LoadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT"
Memantau impor
Anda dapat memantau tugas di UI Cloud Dataflow. Selain itu, Anda dapat melihat beban pada instance Cloud Bigtable dengan UI pemantauan.
Di UI Dataflow, Anda dapat melihat grafik tugas dan berbagai metrik tugas, termasuk elemen yang diproses, vCPU saat ini, dan throughput.

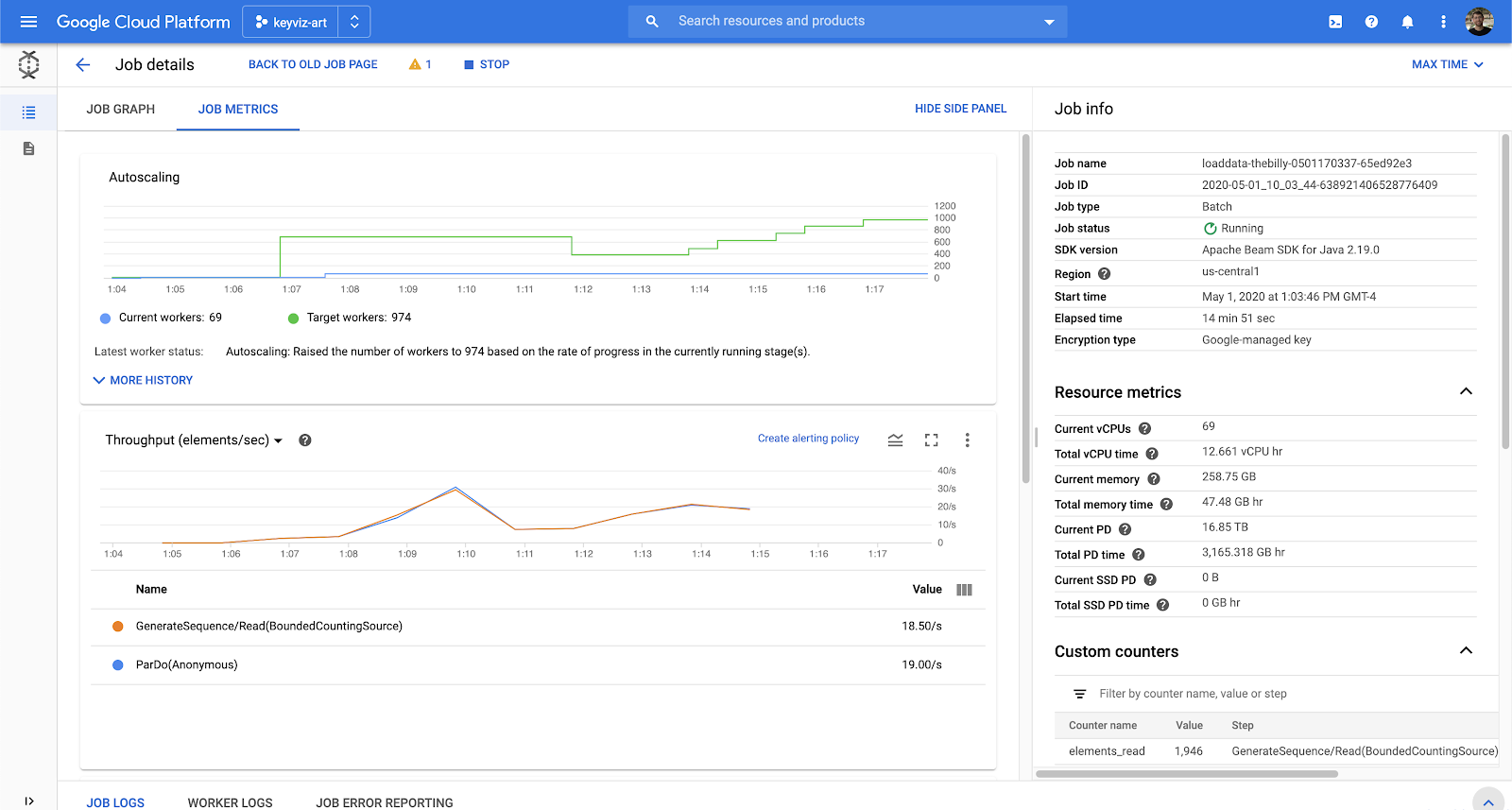
Bigtable memiliki alat pemantauan standar untuk operasi baca/tulis, penyimpanan yang digunakan, tingkat error, dan masih banyak lagi pada tingkat instance, cluster, dan tabel. Selain itu, Bigtable juga memiliki Key Visualizer yang mengelompokkan penggunaan Anda berdasarkan kunci baris yang akan kita gunakan setelah setidaknya 30 GB data dihasilkan.

5. Belajar: Membaca dari Bigtable dengan Dataflow
Dasar-dasar membaca
Saat membaca dari Cloud Bigtable, Anda harus memberikan objek konfigurasi CloudBigtableTableScanConfiguration. Ini mirip dengan CloudBigtableTableConfiguration, tetapi Anda dapat menentukan baris yang akan dipindai dan dibaca.
Scan scan = new Scan();
scan.setCacheBlocks(false);
scan.setFilter(new FirstKeyOnlyFilter());
CloudBigtableScanConfiguration config =
new CloudBigtableScanConfiguration.Builder()
.withProjectId(options.getBigtableProjectId())
.withInstanceId(options.getBigtableInstanceId())
.withTableId(options.getBigtableTableId())
.withScan(scan)
.build();
Kemudian gunakan untuk memulai pipeline Anda:
p.apply(Read.from(CloudBigtableIO.read(config)))
.apply(...
Namun, jika ingin melakukan pembacaan sebagai bagian dari pipeline, Anda dapat meneruskan CloudBigtableTableConfiguration ke doFn yang memperluas AbstractCloudBigtableTableDoFn.
p.apply(GenerateSequence.from(0).to(10))
.apply(ParDo.of(new ReadFromTableFn(bigtableTableConfig, options)));
Lalu, panggil super() dengan konfigurasi Anda dan getConnection() untuk mendapatkan koneksi terdistribusi.
public static class ReadFromTableFn extends AbstractCloudBigtableTableDoFn<Long, Void> {
public ReadFromTableFn(CloudBigtableConfiguration config, ReadDataOptions readDataOptions) {
super(config);
}
@ProcessElement
public void processElement(PipelineOptions po) {
Table table = getConnection().getTable(TableName.valueOf(options.getBigtableTableId()));
ResultScanner imageData = table.getScanner(scan);
}
}
Tugas Dataflow ReadData
Untuk codelab ini, Anda harus membaca dari tabel setiap detik, sehingga Anda dapat memulai pipeline dengan urutan yang dihasilkan yang memicu beberapa rentang baca berdasarkan waktu file CSV yang dimasukkan.
Ada sedikit perhitungan untuk menentukan rentang baris mana yang akan dipindai dengan mempertimbangkan waktu, tetapi Anda dapat mengklik nama file untuk melihat kode sumber jika Anda ingin mempelajari lebih lanjut.
ReadData.java
p.apply(GenerateSequence.from(0).withRate(1, new Duration(1000)))
.apply(ParDo.of(new ReadFromTableFn(bigtableTableConfig, options)));
ReadData.java
public static class ReadFromTableFn extends AbstractCloudBigtableTableDoFn<Long, Void> {
List<List<Float>> imageData = new ArrayList<>();
String[] keys;
public ReadFromTableFn(CloudBigtableConfiguration config, ReadDataOptions readDataOptions) {
super(config);
keys = new String[Math.toIntExact(getNumRows(readDataOptions))];
downloadImageData(readDataOptions.getFilePath());
generateRowkeys(getNumRows(readDataOptions));
}
@ProcessElement
public void processElement(PipelineOptions po) {
// Determine which column will be drawn based on runtime of job.
long timestampDiff = System.currentTimeMillis() - START_TIME;
long minutes = (timestampDiff / 1000) / 60;
int timeOffsetIndex = Math.toIntExact(minutes / KEY_VIZ_WINDOW_MINUTES);
ReadDataOptions options = po.as(ReadDataOptions.class);
long count = 0;
List<RowRange> ranges = getRangesForTimeIndex(timeOffsetIndex, getNumRows(options));
if (ranges.size() == 0) {
return;
}
try {
// Scan with a filter that will only return the first key from each row. This filter is used
// to more efficiently perform row count operations.
Filter rangeFilters = new MultiRowRangeFilter(ranges);
FilterList firstKeyFilterWithRanges = new FilterList(
rangeFilters,
new FirstKeyOnlyFilter(),
new KeyOnlyFilter());
Scan scan =
new Scan()
.addFamily(Bytes.toBytes(COLUMN_FAMILY))
.setFilter(firstKeyFilterWithRanges);
Table table = getConnection().getTable(TableName.valueOf(options.getBigtableTableId()));
ResultScanner imageData = table.getScanner(scan);
} catch (Exception e) {
System.out.println("Error reading.");
e.printStackTrace();
}
}
/**
* Download the image data as a grid of weights and store them in a 2D array.
*/
private void downloadImageData(String artUrl) {
...
}
/**
* Generates an array with the rowkeys that were loaded into the specified Bigtable. This is
* used to create the correct intervals for scanning equal sections of rowkeys. Since Bigtable
* sorts keys lexicographically if we just used standard intervals, each section would have
* different sizes.
*/
private void generateRowkeys(long maxInput) {
...
}
/**
* Get the ranges to scan for the given time index.
*/
private List<RowRange> getRangesForTimeIndex(@Element Integer timeOffsetIndex, long maxInput) {
...
}
}
6. Menciptakan karya terbaik Anda

Setelah memahami cara memuat data ke Bigtable dan membacanya dengan Dataflow, Anda dapat menjalankan perintah akhir yang akan menghasilkan gambar Mona Lisa selama 8 jam.
mvn compile exec:java -Dexec.mainClass=keyviz.ReadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT"
Anda dapat menggunakan bucket dengan gambar yang ada di sana. Atau, Anda dapat membuat file input dari gambar Anda sendiri dengan alat ini, lalu menguploadnya ke bucket GCS publik.
Nama file dibuat dari gs://keyviz-art/[painting]_[hours]h.txt contoh: gs://keyviz-art/american_gothic_4h.txt
opsi pengecatan:
- american_gothic
- mona_lisa
- pearl_earring
- persistence_of_memory
- starry_night
- sunday_afternoon
- the_scream
opsi jam: 1, 4, 8, 12, 24, 48, 72, 96, 120, 144
Jadikan bucket atau file GCS Anda bersifat publik dengan memberi allUsers peran Storage Object Viewer.

Setelah memilih gambar, cukup ubah parameter --file-path dalam perintah ini:
mvn compile exec:java -Dexec.mainClass=keyviz.ReadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT \ --filePath=gs://keyviz-art/american_gothic_4h.txt"
7. Periksa nanti
Mungkin perlu waktu beberapa jam untuk menampilkan gambar penuh, tetapi setelah 30 menit, Anda akan mulai melihat aktivitas di visualizer utama. Ada beberapa parameter yang dapat Anda ubah: zoom, kecerahan, dan metrik. Anda dapat melakukan zoom, menggunakan roda scroll di mouse, atau dengan menarik persegi panjang di petak visualizer utama.
Kecerahan mengubah penskalaan gambar, yang berguna jika Anda ingin melihat area yang sangat panas secara mendalam.

Anda juga dapat menyesuaikan metrik yang ditampilkan. Ada OP, klien{i> Read bytes<i}, {i>Writes bytes client<i}. "Baca klien byte" tampaknya menghasilkan gambar yang halus saat "Ops" menghasilkan gambar dengan lebih banyak garis yang dapat terlihat sangat keren pada beberapa gambar.

8. Selesaikan
Melakukan pembersihan untuk menghindari biaya
Agar tidak menimbulkan biaya pada akun Google Cloud Platform Anda untuk resource yang digunakan dalam codelab ini, Anda harus menghapus instance Anda.
gcloud bigtable instances delete $INSTANCE_ID
Yang telah kita bahas
- Menulis ke Bigtable dengan Dataflow
- Membaca dari Bigtable dengan Dataflow (Di awal pipeline, Di tengah pipeline)
- Menggunakan alat pemantauan Dataflow
- Menggunakan alat pemantauan Bigtable, termasuk Key Visualizer
Langkah berikutnya
- Baca selengkapnya tentang bagaimana poster Key Visualizer dibuat.
- Pelajari Cloud Bigtable lebih lanjut dalam dokumentasi.
- Cobalah sendiri fitur Google Cloud Platform lainnya. Lihat tutorial kami.