
1. Giriş
Bu codelab'de Cloud Dataflow ve Java HBase istemcisi ile veri yazma ve okuma yoluyla çeşitli sanat eserleri oluşturmak için Cloud Bigtable'ın izleme araçlarını kullanacaksınız.
Neler öğreneceksiniz?
- Cloud Dataflow'u kullanarak Bigtable'a büyük miktarlarda veri yükleme
- Verileriniz beslenirken Bigtable örneklerini ve tablolarını izleyin
- Dataflow işi kullanarak Bigtable'ı sorgulama
- Şema tasarımınız nedeniyle hotspot'ları bulmak için kullanılabilecek temel görselleştirici aracını keşfedin
- Tuş görselleştiriciyi kullanarak poster oluşturun
Cloud Bigtable kullanım deneyiminizi nasıl değerlendirirsiniz?
Bu eğiticiden nasıl yararlanacaksınız?
2. Bigtable veritabanınızı oluşturma
Cloud Bigtable, Google'ın NoSQL Büyük Veri veritabanı hizmetidir. Bu hizmet; Arama, Analytics, Haritalar ve Gmail dahil olmak üzere birçok temel Google hizmetini destekleyen veritabanıdır. Büyük analitik iş yüklerini çalıştırmak ve düşük gecikme süreli uygulamalar oluşturmak için idealdir. Kapsamlı bir giriş için Cloud Bigtable Codelab'e Giriş sayfasına göz atın.
Proje oluşturma
İlk olarak yeni bir proje oluşturun. "Cloud Shell'i etkinleştir"i tıklayarak açabileceğiniz yerleşik Cloud Shell'i kullanın. düğmesini tıklayın.

Codelab komutlarının kopyalanıp yapıştırılmasını kolaylaştırmak için aşağıdaki ortam değişkenlerini ayarlayın:
BIGTABLE_PROJECT=$GOOGLE_CLOUD_PROJECT INSTANCE_ID="keyviz-art-instance" CLUSTER_ID="keyviz-art-cluster" TABLE_ID="art" CLUSTER_NUM_NODES=1 CLUSTER_ZONE="us-central1-c" # You can choose a zone closer to you
Cloud Shell'de bu codelab'de kullanacağınız araçlar, gcloud komut satırı aracı, cbt komut satırı arayüzü ve Maven halihazırda yüklüdür.
Bu komutu çalıştırarak Cloud Bigtable API'lerini etkinleştirin.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
Aşağıdaki komutu çalıştırarak bir örnek oluşturun:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
Örneği oluşturduktan sonra cbt yapılandırma dosyasını doldurun ve ardından aşağıdaki komutları çalıştırarak tablo ve sütun ailesi oluşturun:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
3. Öğrenin: Dataflow ile Bigtable'da Kod Yazma
Yazmayla ilgili temel bilgiler
Cloud Bigtable'a yazarken CloudBigtableTableConfiguration yapılandırma nesnesi sağlamanız gerekir. Bu nesne, tablonuzun proje kimliğini ve örnek kimliğini ve tablonun adını belirtir:
CloudBigtableTableConfiguration bigtableTableConfig =
new CloudBigtableTableConfiguration.Builder()
.withProjectId(PROJECT_ID)
.withInstanceId(INSTANCE_ID)
.withTableId(TABLE_ID)
.build();
Ardından ardışık düzeniniz, Put ve Delete dahil olmak üzere HBase Mutation nesnelerini iletebilir.
p.apply(Create.of("hello", "world"))
.apply(
ParDo.of(
new DoFn<String, Mutation>() {
@ProcessElement
public void processElement(@Element String rowkey, OutputReceiver<Mutation> out) {
long timestamp = System.currentTimeMillis();
Put row = new Put(Bytes.toBytes(rowkey));
row.addColumn(...);
out.output(row);
}
}))
.apply(CloudBigtableIO.writeToTable(bigtableTableConfig));
LoadData Dataflow işi
Sonraki sayfada LoadData işini nasıl çalıştıracağınız gösterilecek, ancak burada ardışık düzenin önemli bölümlerini anlatacağım.
Veri üretmek için, birkaç megabayt rastgele veri içeren bir dizi satır yazmak amacıyla GenerateSequence sınıfını (for döngüye benzer şekilde) kullanan bir ardışık düzen oluşturacaksınız. Satır anahtarı, doldurulan ve ters çevrilmiş sıra numarası olacağından 250, 0000000052 olur.
LoadData.java
String numberFormat = "%0" + maxLength + "d";
p.apply(GenerateSequence.from(0).to(max))
.apply(
ParDo.of(
new DoFn<Long, Mutation>() {
@ProcessElement
public void processElement(@Element Long rowkey, OutputReceiver<Mutation> out) {
String paddedRowkey = String.format(numberFormat, rowkey);
// Reverse the rowkey for more efficient writing
String reversedRowkey = new StringBuilder(paddedRowkey).reverse().toString();
Put row = new Put(Bytes.toBytes(reversedRowkey));
// Generate random bytes
byte[] b = new byte[(int) rowSize];
new Random().nextBytes(b);
long timestamp = System.currentTimeMillis();
row.addColumn(Bytes.toBytes(COLUMN_FAMILY), Bytes.toBytes("C"), timestamp, b);
out.output(row);
}
}))
.apply(CloudBigtableIO.writeToTable(bigtableTableConfig));
4. Bigtable'da veri oluşturun ve girişi izleyin
Aşağıdaki komutlar, tablonuza 40 GB'lık veri oluşturan bir dataflow işi çalıştırır. Bu, Key Visualizer'ın etkinleştirmesi için yeterli değildir:
Cloud Dataflow API'yi etkinleştirme
gcloud services enable dataflow.googleapis.com
Kodu github'dan alın ve dizine değiştirin
git clone https://github.com/GoogleCloudPlatform/java-docs-samples.git cd java-docs-samples/bigtable/beam/keyviz-art
Verileri oluşturun (Komut dosyasının tamamlanması yaklaşık 15 dakika sürer)
mvn compile exec:java -Dexec.mainClass=keyviz.LoadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT"
İçe aktarmayı izleme
İşi Cloud Dataflow kullanıcı arayüzünde izleyebilirsiniz. Ayrıca izleme kullanıcı arayüzü ile Cloud Bigtable örneğinizdeki yükü görüntüleyebilirsiniz.
Dataflow kullanıcı arayüzünde iş grafiğinin yanı sıra işlenen öğeler, mevcut vCPU'lar ve işleme hızı dahil çeşitli iş metriklerini görebilirsiniz.


Bigtable; örnek, küme ve tablo düzeyinde okuma/yazma işlemleri, kullanılan depolama alanı, hata oranı ve daha fazlası için standart izleme araçlarına sahiptir. Bunun yanı sıra, Bigtable'da en az 30 GB veri oluşturulduktan sonra kullanılacak satır tuşlarına göre kullanımınızı ayıran Temel Görselleştirici de vardır.

5. Öğrenin: Dataflow ile Bigtable'dan okuma
Okuma ile ilgili temel bilgiler
Cloud Bigtable'dan okuma yaparken bir CloudBigtableTableScanConfiguration yapılandırma nesnesi sağlamanız gerekir. CloudBigtableTableConfiguration parametresine benzerdir ancak taranacak ve okunacak satırları belirtebilirsiniz.
Scan scan = new Scan();
scan.setCacheBlocks(false);
scan.setFilter(new FirstKeyOnlyFilter());
CloudBigtableScanConfiguration config =
new CloudBigtableScanConfiguration.Builder()
.withProjectId(options.getBigtableProjectId())
.withInstanceId(options.getBigtableInstanceId())
.withTableId(options.getBigtableTableId())
.withScan(scan)
.build();
Ardından ardışık düzeninizi başlatmak için bunu kullanın:
p.apply(Read.from(CloudBigtableIO.read(config)))
.apply(...
Ancak ardışık düzeninizin bir parçası olarak okuma yapmak isterseniz AbstractCloudBigtableTableDoFn öğesini genişleten doFn öğesine CloudBigtableTableConfiguration aktarabilirsiniz.
p.apply(GenerateSequence.from(0).to(10))
.apply(ParDo.of(new ReadFromTableFn(bigtableTableConfig, options)));
Ardından yapılandırmanızla birlikte super() adlı kuruluşu, dağıtılmış bağlantı almak için de getConnection() çağrısı yapın.
public static class ReadFromTableFn extends AbstractCloudBigtableTableDoFn<Long, Void> {
public ReadFromTableFn(CloudBigtableConfiguration config, ReadDataOptions readDataOptions) {
super(config);
}
@ProcessElement
public void processElement(PipelineOptions po) {
Table table = getConnection().getTable(TableName.valueOf(options.getBigtableTableId()));
ResultScanner imageData = table.getScanner(scan);
}
}
ReadData Dataflow işi
Bu codelab için saniyede bir tablodan okuma yapmanız gerekir. Böylece ardışık düzeninizi, girilen bir CSV dosyasının süresine göre birden fazla okuma aralığını tetikleyen, oluşturulmuş bir sıra ile başlatabilirsiniz.
Belirli bir zamanda hangi satır aralıklarının taranacağını belirlemek için matematik işlemleri yapmak gerekir, ancak daha fazla bilgi edinmek isterseniz dosya adını tıklayarak kaynak kodu görüntüleyebilirsiniz.
ReadData.java
p.apply(GenerateSequence.from(0).withRate(1, new Duration(1000)))
.apply(ParDo.of(new ReadFromTableFn(bigtableTableConfig, options)));
ReadData.java
public static class ReadFromTableFn extends AbstractCloudBigtableTableDoFn<Long, Void> {
List<List<Float>> imageData = new ArrayList<>();
String[] keys;
public ReadFromTableFn(CloudBigtableConfiguration config, ReadDataOptions readDataOptions) {
super(config);
keys = new String[Math.toIntExact(getNumRows(readDataOptions))];
downloadImageData(readDataOptions.getFilePath());
generateRowkeys(getNumRows(readDataOptions));
}
@ProcessElement
public void processElement(PipelineOptions po) {
// Determine which column will be drawn based on runtime of job.
long timestampDiff = System.currentTimeMillis() - START_TIME;
long minutes = (timestampDiff / 1000) / 60;
int timeOffsetIndex = Math.toIntExact(minutes / KEY_VIZ_WINDOW_MINUTES);
ReadDataOptions options = po.as(ReadDataOptions.class);
long count = 0;
List<RowRange> ranges = getRangesForTimeIndex(timeOffsetIndex, getNumRows(options));
if (ranges.size() == 0) {
return;
}
try {
// Scan with a filter that will only return the first key from each row. This filter is used
// to more efficiently perform row count operations.
Filter rangeFilters = new MultiRowRangeFilter(ranges);
FilterList firstKeyFilterWithRanges = new FilterList(
rangeFilters,
new FirstKeyOnlyFilter(),
new KeyOnlyFilter());
Scan scan =
new Scan()
.addFamily(Bytes.toBytes(COLUMN_FAMILY))
.setFilter(firstKeyFilterWithRanges);
Table table = getConnection().getTable(TableName.valueOf(options.getBigtableTableId()));
ResultScanner imageData = table.getScanner(scan);
} catch (Exception e) {
System.out.println("Error reading.");
e.printStackTrace();
}
}
/**
* Download the image data as a grid of weights and store them in a 2D array.
*/
private void downloadImageData(String artUrl) {
...
}
/**
* Generates an array with the rowkeys that were loaded into the specified Bigtable. This is
* used to create the correct intervals for scanning equal sections of rowkeys. Since Bigtable
* sorts keys lexicographically if we just used standard intervals, each section would have
* different sizes.
*/
private void generateRowkeys(long maxInput) {
...
}
/**
* Get the ranges to scan for the given time index.
*/
private List<RowRange> getRangesForTimeIndex(@Element Integer timeOffsetIndex, long maxInput) {
...
}
}
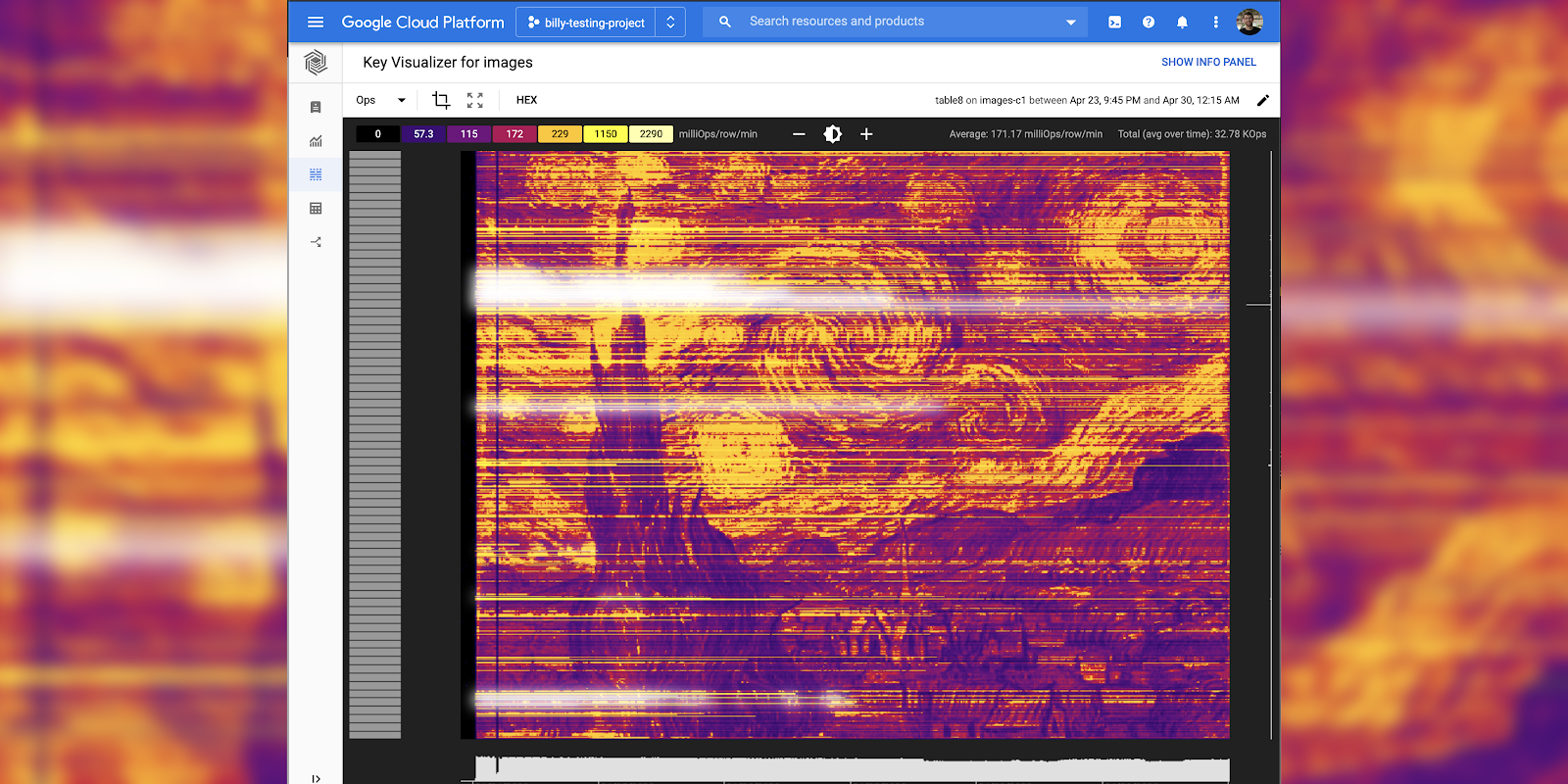
6. Başyapıtınızı oluşturma

Artık Bigtable'a veri yüklemeyi ve Dataflow ile buradan veri okumayı öğrendiğinize göre 8 saatte Mona Lisa'nın resmini oluşturan son komutu çalıştırabilirsiniz.
mvn compile exec:java -Dexec.mainClass=keyviz.ReadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT"
Kullanabileceğiniz mevcut resimlerin bulunduğu bir paket vardır. Alternatif olarak, bu aracı kullanarak kendi görüntülerinizden bir giriş dosyası oluşturabilir ve bunları herkese açık bir GCS paketine yükleyebilirsiniz.
Dosya adları gs://keyviz-art/[painting]_[hours]h.txt örneğinden alınmıştır: gs://keyviz-art/american_gothic_4h.txt
boyama seçenekleri:
- american_gothic
- mona_lisa
- pearl_earring
- persistence_of_memory
- starry_night
- sunday_afternoon
- the_scream
saat seçenekleri: 1, 4, 8, 12, 24, 48, 72, 96, 120, 144
allUsers kullanıcısına Storage Object Viewer rolünü vererek GCS paketinizi veya dosyanızı herkese açık hale getirin.

Resminizi seçtikten sonra, bu komuttaki --file-path parametresini değiştirmeniz yeterlidir:
mvn compile exec:java -Dexec.mainClass=keyviz.ReadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT \ --filePath=gs://keyviz-art/american_gothic_4h.txt"
7. Daha sonra tekrar kontrol edin
Resmin tam olarak görünmesi birkaç saat sürebilir ancak 30 dakika sonra tuş görselleştiricide etkinlik görmeye başlamanız gerekir. Kullanabileceğiniz çeşitli parametreler vardır: yakınlaştırma, parlaklık ve metrik. Farenizdeki kaydırma tekerleğini kullanarak veya tuş görselleştirici ızgarasında bir dikdörtgen sürükleyerek yakınlaştırabilirsiniz.
Parlaklık, resmin ölçeklendirmesini değiştirir. Bu özellik, çok sıcak bir alanı ayrıntılı olarak incelemek istediğinizde kullanışlıdır.

Hangi metriğin görüntüleneceğini de ayarlayabilirsiniz. OP, okuma baytı istemci, yazma baytları istemci gibi bazı yöntemleri bulunur. "İstemcinin baytını oku" "Ops" sırasında akıcı görüntüler üretiyor gibi görünüyor. bazı resimlerde çok güzel görünebilecek daha fazla çizgi içeren resimler üretir.

8. Sonlandır
Ücret almamak için yer açın
Bu codelab'de kullanılan kaynaklar için Google Cloud Platform hesabınızın ücretlendirilmesini önlemek amacıyla örneğinizi silmeniz gerekir.
gcloud bigtable instances delete $INSTANCE_ID
İşlediklerimiz
- Dataflow ile Bigtable'da yazma
- Dataflow ile Bigtable'dan okuma (Ardışık düzeninizin başında, Ardışık düzeninizin ortasında)
- Dataflow izleme araçlarını kullanma
- Key Visualizer dahil olmak üzere Bigtable izleme araçlarını kullanma
Sonraki adımlar
- Anahtar Görselleştirici görselinin nasıl oluşturulduğu hakkında daha fazla bilgi edinin.
- Belgelerden Cloud Bigtable hakkında daha fazla bilgi edinin.
- Diğer Google Cloud Platform özelliklerini kendiniz deneyin. Eğiticilerimize göz atın.