
1. Übersicht
In diesem Codelab erfahren Sie, wie Sie eine LangChain-App bereitstellen, die Gemini verwendet, damit Sie Fragen zu den Cloud Run-Versionshinweisen stellen können.
Hier ist ein Beispiel für die Funktionsweise der App: Wenn Sie die Frage „Kann ich einen Cloud Storage-Bucket als Volume in Cloud Run einbinden?“ stellen, antwortet die App mit „Ja, seit dem 19. Januar 2024“ oder ähnlich.
Um fundierte Antworten zu liefern, ruft die App zuerst Cloud Run-Versionshinweise ab, die der Frage ähneln, und gibt dann sowohl die Frage als auch die Versionshinweise an Gemini weiter. Dies ist ein Muster, das häufig als RAG bezeichnet wird. Hier sehen Sie ein Diagramm der App-Architektur:
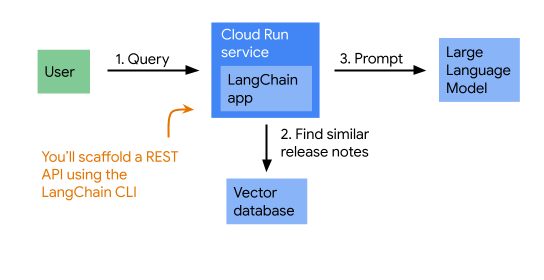
2. Einrichtung und Anforderungen
Prüfen wir zuerst, ob Ihre Entwicklungsumgebung richtig eingerichtet ist.
- Sie benötigen ein Google Cloud-Projekt, um die für die App erforderlichen Ressourcen bereitzustellen.
- Damit Sie die App bereitstellen können, muss gcloud auf Ihrem lokalen Computer installiert, authentifiziert und für die Verwendung des Projekts konfiguriert sein.
gcloud auth logingcloud config set project
- Wenn Sie die Anwendung auf Ihrem lokalen Computer ausführen möchten, was ich empfehle, müssen Sie darauf achten, dass Ihre Standardanmeldedaten für Anwendungen richtig eingerichtet sind, einschließlich Festlegen des Kontingentprojekts.
gcloud auth application-default logingcloud auth application-default set-quota-project
- Außerdem muss die folgende Software installiert sein:
- Python (Version 3.11 oder höher ist erforderlich)
- Die LangChain CLI
- Poetry für die Abhängigkeitsverwaltung
- pipx zum Installieren und Ausführen der LangChain CLI und Poetry in isolierten virtuellen Umgebungen
In diesem Blog erfahren Sie, wie Sie die für diese Anleitung erforderlichen Tools installieren.
Cloud Workstations
Anstelle Ihres lokalen Computers können Sie auch Cloud Workstations in Google Cloud verwenden. Ab April 2024 wird eine Python-Version unter 3.11 ausgeführt. Möglicherweise müssen Sie Python also aktualisieren, bevor Sie loslegen.
Cloud APIs aktivieren
Führen Sie zuerst den folgenden Befehl aus, um sicherzustellen, dass Sie das richtige Google Cloud-Projekt konfiguriert haben:
gcloud config list project
Wenn das richtige Projekt nicht angezeigt wird, können Sie es mit diesem Befehl festlegen:
gcloud config set project <PROJECT_ID>
Aktivieren Sie nun die folgenden APIs:
gcloud services enable \ bigquery.googleapis.com \ sqladmin.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ run.googleapis.com \ secretmanager.googleapis.com
Region auswählen
Google Cloud ist weltweit an vielen Standorten verfügbar. Sie müssen einen auswählen, um die Ressourcen bereitzustellen, die Sie für dieses Lab verwenden. Legen Sie die Region als Umgebungsvariable in Ihrer Shell fest. Diese Variable wird in späteren Befehlen verwendet:
export REGION=us-central1
3. Vektordatenbankinstanz erstellen
Ein wichtiger Teil dieser App ist das Abrufen von Versionshinweisen, die für die Nutzerfrage relevant sind. Wenn Sie beispielsweise eine Frage zu Cloud Storage stellen, soll die folgende Versionshinweis dem Prompt hinzugefügt werden:
Sie können Texteinbettungen und eine Vektordatenbank verwenden, um semantisch ähnliche Versionshinweise zu finden.
Ich zeige Ihnen, wie Sie PostgreSQL in Cloud SQL als Vektordatenbank verwenden. Das Erstellen einer neuen Cloud SQL-Instanz dauert einige Zeit. Wir beginnen jetzt damit.
gcloud sql instances create sql-instance \ --database-version POSTGRES_14 \ --tier db-f1-micro \ --region $REGION
Sie können diesen Befehl ausführen lassen und mit den nächsten Schritten fortfahren. Irgendwann müssen Sie eine Datenbank erstellen und einen Nutzer hinzufügen, aber wir wollen jetzt nicht auf den Spinner warten.
PostgreSQL ist ein relationaler Datenbankserver. In jeder neuen Cloud SQL-Instanz ist die Erweiterung pgvector standardmäßig installiert. Sie können sie also auch als Vektordatenbank verwenden.
4. LangChain-App erstellen
Um fortzufahren, müssen Sie die LangChain CLI installiert haben und Poetry zum Verwalten von Abhängigkeiten verwenden. So installieren Sie sie mit pipx:
pipx install langchain-cli poetry
Erstellen Sie die LangChain-App mit dem folgenden Befehl. Geben Sie bei entsprechender Aufforderung run-rag als Namen für den Ordner ein und überspringen Sie die Installation von Paketen, indem Sie die Eingabetaste drücken:
langchain app new
Wechseln Sie in das Verzeichnis run-rag und installieren Sie die Abhängigkeiten.
poetry install
Sie haben gerade eine LangServe-App erstellt. LangServe umschließt eine LangChain-Kette mit FastAPI. Es enthält einen integrierten Playground, mit dem Sie ganz einfach Prompts senden und die Ergebnisse, einschließlich aller Zwischenschritte, prüfen können. Öffnen Sie den Ordner run-rag in Ihrem Editor und sehen Sie sich an, was sich darin befindet.
5. Indexierungsjob erstellen
Bevor Sie mit der Entwicklung der Web-App beginnen, sollten Sie prüfen, ob die Cloud Run-Versionshinweise in der Cloud SQL-Datenbank indexiert sind. In diesem Abschnitt erstellen Sie einen Indexierungsjob, der Folgendes ausführt:
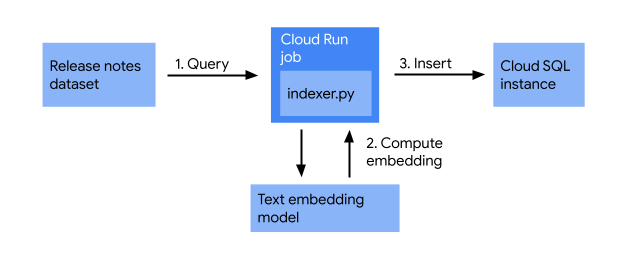
Der Indexierungsjob verwendet Versionshinweise, wandelt sie mit einem Texteinbettungsmodell in Vektoren um und speichert sie in einer Vektordatenbank. So können Sie effizient nach ähnlichen Versionshinweisen suchen, die auf ihrer semantischen Bedeutung basieren.
Erstellen Sie im Ordner run-rag/app eine Datei indexer.py mit folgendem Inhalt:
import os
from google.cloud.sql.connector import Connector
import pg8000
from langchain_community.vectorstores.pgvector import PGVector
from langchain_google_vertexai import VertexAIEmbeddings
from google.cloud import bigquery
# Retrieve all Cloud Run release notes from BigQuery
client = bigquery.Client()
query = """
SELECT
CONCAT(FORMAT_DATE("%B %d, %Y", published_at), ": ", description) AS release_note
FROM `bigquery-public-data.google_cloud_release_notes.release_notes`
WHERE product_name= "Cloud Run"
ORDER BY published_at DESC
"""
rows = client.query(query)
print(f"Number of release notes retrieved: {rows.result().total_rows}")
# Set up a PGVector instance
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
store = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
),
pre_delete_collection=True
)
# Save all release notes into the Cloud SQL database
texts = list(row["release_note"] for row in rows)
ids = store.add_texts(texts)
print(f"Done saving: {len(ids)} release notes")
Fügen Sie die erforderlichen Abhängigkeiten hinzu:
poetry add \ "cloud-sql-python-connector[pg8000]" \ langchain-google-vertexai==1.0.5 \ langchain-community==0.2.5 \ pgvector
Datenbank und Nutzer erstellen
Erstellen Sie eine Datenbank release-notes in der Cloud SQL-Instanz sql-instance:
gcloud sql databases create release-notes --instance sql-instance
Erstellen Sie einen Datenbanknutzer mit dem Namen app:
gcloud sql users create app --instance sql-instance --password "myprecious"
Indexierungsjob bereitstellen und ausführen
Stellen Sie den Job nun bereit und führen Sie ihn aus:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run jobs deploy indexer \ --source . \ --command python \ --args app/indexer.py \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --execute-now
Das ist ein langer Befehl. Sehen wir uns an, was passiert:
Mit dem ersten Befehl wird der Verbindungsname (eine eindeutige ID im Format project:region:instance) abgerufen und als Umgebungsvariable DB_INSTANCE_NAME festgelegt.
Mit dem zweiten Befehl wird der Cloud Run-Job bereitgestellt. Das bewirken die Flags:
--source .: Gibt an, dass sich der Quellcode für den Job im aktuellen Arbeitsverzeichnis befindet (dem Verzeichnis, in dem Sie den Befehl ausführen).--command python: Legt den Befehl fest, der im Container ausgeführt werden soll. In diesem Fall ist es die Ausführung von Python.--args app/indexer.py: Stellt die Argumente für den Python-Befehl bereit. Dadurch wird das Skript „indexer.py“ im App-Verzeichnis ausgeführt.--set-env-vars: Legt Umgebungsvariablen fest, auf die das Python-Skript während der Ausführung zugreifen kann.--region=$REGION: Gibt die Region an, in der der Job bereitgestellt werden soll.--execute-now: Weist Cloud Run an, den Job unmittelbar nach der Bereitstellung zu starten.
So prüfen Sie, ob der Job erfolgreich abgeschlossen wurde:
- Lesen Sie die Logs der Jobausführung über die Webkonsole. Es sollte „Done saving: xxx release notes“ (Speichern abgeschlossen: xxx Versionshinweise) angezeigt werden, wobei „xxx“ die Anzahl der gespeicherten Versionshinweise ist.
- Sie können auch in der Webkonsole zur Cloud SQL-Instanz navigieren und mit Cloud SQL Studio die Anzahl der Datensätze in der Tabelle
langchain_pg_embeddingabfragen.
6. Webanwendung schreiben
Öffnen Sie die Datei app/server.py in einem Editor. Suchen Sie nach einer Zeile mit folgendem Inhalt:
# Edit this to add the chain you want to add
Ersetzen Sie diesen Kommentar durch das folgende Snippet:
# (1) Initialize VectorStore
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
vectorstore = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
)
)
# (2) Build retriever
def concatenate_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
notes_retriever = vectorstore.as_retriever() | concatenate_docs
# (3) Create prompt template
prompt_template = PromptTemplate.from_template(
"""You are a Cloud Run expert answering questions.
Use the retrieved release notes to answer questions
Give a concise answer, and if you are unsure of the answer, just say so.
Release notes: {notes}
Here is your question: {query}
Your answer: """)
# (4) Initialize LLM
llm = VertexAI(
model_name="gemini-1.0-pro-001",
temperature=0.2,
max_output_tokens=100,
top_k=40,
top_p=0.95
)
# (5) Chain everything together
chain = (
RunnableParallel({
"notes": notes_retriever,
"query": RunnablePassthrough()
})
| prompt_template
| llm
| StrOutputParser()
)
Außerdem müssen Sie diese Importe hinzufügen:
import pg8000
import os
from google.cloud.sql.connector import Connector
from langchain_google_vertexai import VertexAI
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.vectorstores.pgvector import PGVector
Ändern Sie schließlich die Zeile mit „NotImplemented“ in:
# add_routes(app, NotImplemented)
add_routes(app, chain)
7. Webanwendung in Cloud Run bereitstellen
Verwenden Sie im Verzeichnis run-rag den folgenden Befehl, um die App in Cloud Run bereitzustellen:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run deploy run-rag \ --source . \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --allow-unauthenticated
Mit diesem Befehl wird Folgendes ausgeführt:
- Quellcode in Cloud Build hochladen
- Führen Sie „docker build“ aus.
- Übertragen Sie das resultierende Container-Image per Push an Artifact Registry.
- Erstellen Sie einen Cloud Run-Dienst mit dem Container-Image.
Wenn der Befehl abgeschlossen ist, wird eine HTTPS-URL in der run.app-Domain aufgeführt. Dies ist die öffentliche URL Ihres neuen Cloud Run-Dienstes.
8. Playground ausprobieren
Öffnen Sie die Cloud Run-Dienst-URL und rufen Sie /playground auf. Ein Textfeld wird angezeigt. Sie können damit Fragen zu den Cloud Run-Versionshinweisen stellen, wie hier:
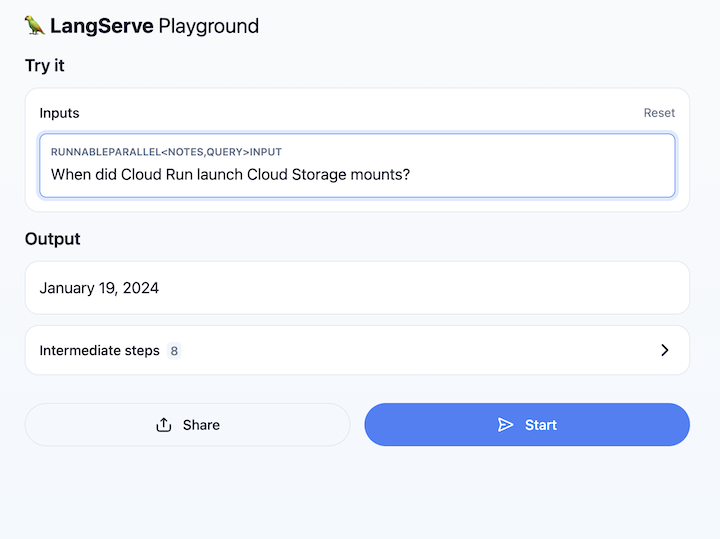
9. Glückwunsch
Sie haben erfolgreich eine LangChain-App in Cloud Run erstellt und bereitgestellt. Gut gemacht!
Hier sind die wichtigsten Konzepte:
- Verwendung des LangChain-Frameworks zum Erstellen einer RAG-Anwendung (Retrieval Augmented Generation).
- PostgreSQL in Cloud SQL als Vektordatenbank mit pgvector verwenden. pgvector ist standardmäßig in Cloud SQL installiert.
- Führen Sie einen länger laufenden Indexierungsjob als Cloud Run-Job und eine Webanwendung als Cloud Run-Dienst aus.
- Verpacken Sie eine LangChain-Kette mit LangServe in einer FastAPI-Anwendung, um eine praktische Schnittstelle für die Interaktion mit Ihrer RAG-Anwendung zu erhalten.
Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud Platform-Konto die in dieser Anleitung verwendeten Ressourcen berechnet werden:
- Wechseln Sie in der Cloud Console zur Seite „Ressourcen verwalten“.
- Wählen Sie in der Projektliste Ihr Projekt aus und klicken Sie auf „Löschen“.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf „Beenden“, um das Projekt zu löschen.
Wenn Sie das Projekt behalten möchten, löschen Sie die folgenden Ressourcen:
- Cloud SQL-Instanz
- Cloud Run-Dienst
- Cloud Run-Job