
1. Ringkasan
Dalam codelab ini, Anda akan mempelajari cara men-deploy aplikasi LangChain yang menggunakan Gemini untuk memungkinkan Anda mengajukan pertanyaan tentang catatan rilis Cloud Run.
Berikut contoh cara kerja aplikasi: Jika Anda mengajukan pertanyaan "Dapatkah saya memasang bucket Cloud Storage sebagai volume di Cloud Run?", aplikasi akan merespons dengan "Ya, sejak 19 Januari 2024", atau yang serupa.
Untuk menampilkan respons yang memiliki rujukan, aplikasi terlebih dahulu mengambil catatan rilis Cloud Run yang mirip dengan pertanyaan, lalu meminta Gemini dengan pertanyaan dan catatan rilis tersebut. (Ini adalah pola yang umumnya disebut RAG.) Berikut adalah diagram yang menunjukkan arsitektur aplikasi:
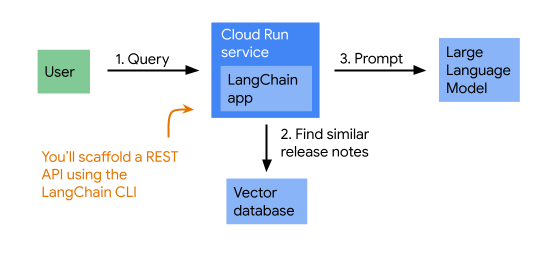
2. Penyiapan dan persyaratan
Pertama, pastikan lingkungan pengembangan Anda telah disiapkan dengan benar.
- Anda memerlukan project Google Cloud untuk men-deploy resource yang diperlukan untuk aplikasi.
- Untuk men-deploy aplikasi, Anda harus menginstal gcloud di mesin lokal, mengautentikasi, dan mengonfigurasi untuk menggunakan project.
gcloud auth logingcloud config set project
- Jika Anda ingin menjalankan aplikasi di mesin lokal, yang saya rekomendasikan, Anda harus memastikan kredensial default aplikasi Anda disiapkan dengan benar, termasuk menetapkan project kuota.
gcloud auth application-default logingcloud auth application-default set-quota-project
- Anda juga harus menginstal software berikut:
- Python (diperlukan versi 3.11 atau yang lebih baru)
- LangChain CLI
- poetry untuk pengelolaan dependensi
- pipx untuk menginstal dan menjalankan LangChain CLI dan poetry di lingkungan virtual terisolasi
Berikut adalah blog yang membantu Anda memulai penginstalan alat yang diperlukan untuk panduan ini.
Cloud Workstations
Selain komputer lokal, Anda juga dapat menggunakan Cloud Workstations di Google Cloud. Perhatikan bahwa pada April 2024, aplikasi ini menjalankan Python versi yang lebih rendah dari 3.11, jadi Anda mungkin perlu mengupgrade Python sebelum memulai.
Aktifkan Cloud API
Pertama, jalankan perintah berikut untuk memastikan Anda telah mengonfigurasi project Google Cloud yang benar untuk digunakan:
gcloud config list project
Jika project yang benar tidak ditampilkan, Anda dapat menyetelnya dengan perintah ini:
gcloud config set project <PROJECT_ID>
Sekarang aktifkan API berikut:
gcloud services enable \ bigquery.googleapis.com \ sqladmin.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ run.googleapis.com \ secretmanager.googleapis.com
Pilih wilayah
Google Cloud tersedia di banyak lokasi secara global, dan Anda perlu memilih salah satunya untuk men-deploy resource yang akan Anda gunakan untuk lab ini. Tetapkan region sebagai variabel lingkungan di shell Anda (perintah selanjutnya akan menggunakan variabel ini):
export REGION=us-central1
3. Membuat instance database vektor
Bagian penting dari aplikasi ini adalah mengambil catatan rilis yang relevan dengan pertanyaan pengguna. Agar lebih konkret, jika Anda mengajukan pertanyaan tentang Cloud Storage, Anda ingin catatan rilis berikut ditambahkan ke perintah:
Anda dapat menggunakan embedding teks dan database vektor untuk menemukan catatan rilis yang mirip secara semantik.
Saya akan menunjukkan cara menggunakan PostgreSQL di Cloud SQL sebagai database vektor. Membuat instance Cloud SQL baru memerlukan waktu beberapa saat, jadi mari kita lakukan sekarang.
gcloud sql instances create sql-instance \ --database-version POSTGRES_14 \ --tier db-f1-micro \ --region $REGION
Anda dapat membiarkan perintah ini berjalan dan melanjutkan ke langkah berikutnya. Pada suatu saat, Anda perlu membuat database dan menambahkan pengguna, tetapi jangan buang waktu dengan menonton spinner sekarang.
PostgreSQL adalah server database relasional, dan setiap instance baru Cloud SQL memiliki ekstensi pgvector yang diinstal secara default, yang berarti Anda juga dapat menggunakannya sebagai database vektor.
4. Buat scaffold aplikasi LangChain
Untuk melanjutkan, Anda harus menginstal LangChain CLI, dan poetry untuk mengelola dependensi. Berikut cara menginstalnya menggunakan pipx:
pipx install langchain-cli poetry
Buat kerangka aplikasi LangChain dengan perintah berikut. Saat ditanya, beri nama folder run-rag dan lewati penginstalan paket dengan menekan enter:
langchain app new
Ubah ke direktori run-rag dan instal dependensi
poetry install
Anda baru saja membuat aplikasi LangServe. LangServe membungkus FastAPI di sekitar rantai LangChain. Alat ini dilengkapi dengan playground bawaan yang memudahkan pengiriman perintah dan pemeriksaan hasilnya, termasuk semua langkah perantara. Sebaiknya Anda membuka folder run-rag di editor dan menjelajahi isinya.
5. Membuat tugas pengindeksan
Sebelum Anda mulai menyusun aplikasi web, pastikan catatan rilis Cloud Run diindeks dalam database Cloud SQL. Di bagian ini, Anda akan membuat tugas pengindeksan yang melakukan hal berikut:
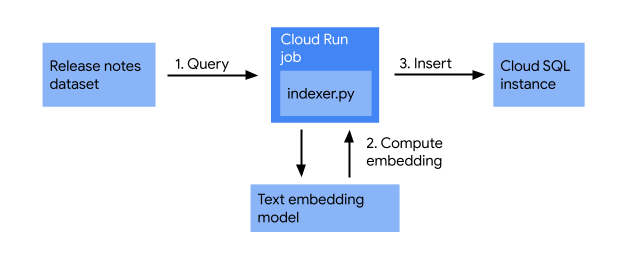
Tugas pengindeksan mengambil catatan rilis, mengonversinya menjadi vektor menggunakan model embedding teks, dan menyimpannya dalam database vektor. Hal ini memungkinkan penelusuran yang efisien untuk catatan rilis serupa berdasarkan makna semantiknya.
Di folder run-rag/app, buat file indexer.py dengan konten berikut:
import os
from google.cloud.sql.connector import Connector
import pg8000
from langchain_community.vectorstores.pgvector import PGVector
from langchain_google_vertexai import VertexAIEmbeddings
from google.cloud import bigquery
# Retrieve all Cloud Run release notes from BigQuery
client = bigquery.Client()
query = """
SELECT
CONCAT(FORMAT_DATE("%B %d, %Y", published_at), ": ", description) AS release_note
FROM `bigquery-public-data.google_cloud_release_notes.release_notes`
WHERE product_name= "Cloud Run"
ORDER BY published_at DESC
"""
rows = client.query(query)
print(f"Number of release notes retrieved: {rows.result().total_rows}")
# Set up a PGVector instance
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
store = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
),
pre_delete_collection=True
)
# Save all release notes into the Cloud SQL database
texts = list(row["release_note"] for row in rows)
ids = store.add_texts(texts)
print(f"Done saving: {len(ids)} release notes")
Tambahkan dependensi yang diperlukan:
poetry add \ "cloud-sql-python-connector[pg8000]" \ langchain-google-vertexai==1.0.5 \ langchain-community==0.2.5 \ pgvector
Buat database dan pengguna
Buat database release-notes di instance Cloud SQL sql-instance:
gcloud sql databases create release-notes --instance sql-instance
Buat pengguna database bernama app:
gcloud sql users create app --instance sql-instance --password "myprecious"
Men-deploy dan menjalankan tugas pengindeksan
Sekarang deploy dan jalankan tugas:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run jobs deploy indexer \ --source . \ --command python \ --args app/indexer.py \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --execute-now
Perintahnya panjang, mari kita lihat apa yang terjadi:
Perintah pertama mengambil nama koneksi (ID unik yang diformat sebagai project:region:instance) dan menyetelnya sebagai variabel lingkungan DB_INSTANCE_NAME.
Perintah kedua men-deploy tugas Cloud Run. Berikut fungsi flag:
--source .: Menentukan bahwa kode sumber untuk tugas berada di direktori kerja saat ini (direktori tempat Anda menjalankan perintah).--command python: Menetapkan perintah yang akan dieksekusi di dalam container. Dalam hal ini, tujuannya adalah untuk menjalankan Python.--args app/indexer.py: Menyediakan argumen ke perintah python. Perintah ini akan menjalankan pengindeks skrip indexer.py di direktori aplikasi.--set-env-vars: Menetapkan variabel lingkungan yang dapat diakses skrip Python selama eksekusi.--region=$REGION: Menentukan region tempat tugas harus di-deploy.--execute-now: Memberi tahu Cloud Run untuk memulai tugas segera setelah di-deploy.
Untuk memverifikasi bahwa tugas berhasil diselesaikan, Anda dapat melakukan hal berikut:
- Baca log eksekusi tugas melalui konsol web. Pesan ini akan melaporkan "Selesai menyimpan: xxx catatan rilis" (dengan xxx adalah jumlah catatan rilis yang disimpan).
- Anda juga dapat membuka instance Cloud SQL di konsol web, dan menggunakan Cloud SQL Studio untuk mengkueri jumlah data dalam tabel
langchain_pg_embedding.
6. Menulis aplikasi web
Buka file app/server.py di editor Anda. Anda akan menemukan baris yang bertuliskan berikut:
# Edit this to add the chain you want to add
Ganti komentar tersebut dengan cuplikan berikut:
# (1) Initialize VectorStore
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
vectorstore = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
)
)
# (2) Build retriever
def concatenate_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
notes_retriever = vectorstore.as_retriever() | concatenate_docs
# (3) Create prompt template
prompt_template = PromptTemplate.from_template(
"""You are a Cloud Run expert answering questions.
Use the retrieved release notes to answer questions
Give a concise answer, and if you are unsure of the answer, just say so.
Release notes: {notes}
Here is your question: {query}
Your answer: """)
# (4) Initialize LLM
llm = VertexAI(
model_name="gemini-1.0-pro-001",
temperature=0.2,
max_output_tokens=100,
top_k=40,
top_p=0.95
)
# (5) Chain everything together
chain = (
RunnableParallel({
"notes": notes_retriever,
"query": RunnablePassthrough()
})
| prompt_template
| llm
| StrOutputParser()
)
Anda juga perlu menambahkan impor ini:
import pg8000
import os
from google.cloud.sql.connector import Connector
from langchain_google_vertexai import VertexAI
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.vectorstores.pgvector import PGVector
Terakhir, ubah baris yang bertuliskan "NotImplemented" menjadi:
# add_routes(app, NotImplemented)
add_routes(app, chain)
7. Men-deploy aplikasi web ke Cloud Run
Dari direktori run-rag, gunakan perintah berikut untuk men-deploy aplikasi ke Cloud Run:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run deploy run-rag \ --source . \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --allow-unauthenticated
Perintah ini akan melakukan hal berikut:
- Mengupload kode sumber ke Cloud Build
- Jalankan build Docker.
- Kirim image container yang dihasilkan ke Artifact Registry.
- Buat layanan Cloud Run menggunakan image container.
Setelah perintah selesai, perintah akan mencantumkan URL HTTPS di domain run.app. Ini adalah URL publik layanan Cloud Run baru Anda
8. Menjelajahi playground
Buka URL layanan Cloud Run dan buka /playground. Kolom teks akan muncul. Gunakan untuk mengajukan pertanyaan terkait catatan rilis Cloud Run, seperti di sini:
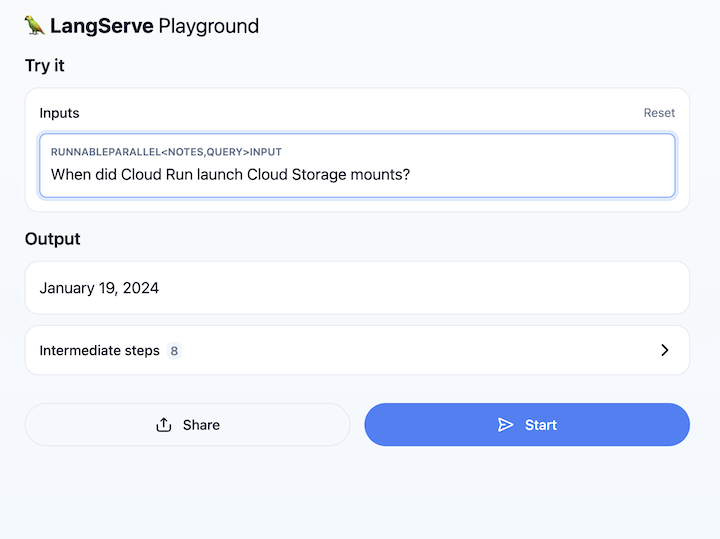
9. Selamat
Anda telah berhasil membangun dan men-deploy aplikasi LangChain di Cloud Run. Bagus!
Berikut adalah konsep utamanya:
- Menggunakan framework LangChain untuk membangun aplikasi Retrieval Augmented Generation (RAG).
- Menggunakan PostgreSQL di Cloud SQL sebagai database vektor dengan pgvector, yang diinstal secara default di Cloud SQL.
- Jalankan tugas pengindeksan yang berjalan lebih lama sebagai tugas Cloud Run dan aplikasi web sebagai layanan Cloud Run.
- Gabungkan rangkaian LangChain dalam aplikasi FastAPI dengan LangServe, yang menyediakan antarmuka yang mudah untuk berinteraksi dengan aplikasi RAG Anda.
Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Platform Anda untuk resource yang digunakan dalam tutorial ini:
- Di Cloud Console, buka halaman Mengelola resource.
- Dalam daftar project, pilih project Anda lalu klik Hapus.
- Pada dialog, ketik project ID, lalu klik Shut Down untuk menghapus project.
Jika Anda ingin mempertahankan project, pastikan untuk menghapus resource berikut:
- Instance Cloud SQL
- Layanan Cloud Run
- Tugas Cloud Run