
1. Visão geral
Neste codelab, você vai aprender a implantar um app do LangChain que usa o Gemini para permitir que você faça perguntas sobre as notas da versão do Cloud Run.
Confira um exemplo de como o app funciona: se você perguntar "Posso montar um bucket do Cloud Storage como um volume no Cloud Run?", o app vai responder "Sim, desde 19 de janeiro de 2024" ou algo parecido.
Para retornar respostas embasadas, o app primeiro recupera notas da versão do Cloud Run semelhantes à pergunta e, em seguida, solicita ao Gemini a pergunta e as notas da versão. Esse é um padrão conhecido como RAG. Confira um diagrama que mostra a arquitetura do app:
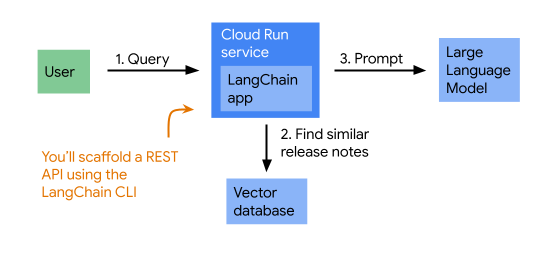
2. Configuração e requisitos
Primeiro, verifique se o ambiente de desenvolvimento está configurado corretamente.
- Você vai precisar de um projeto na nuvem do Google Cloud para implantar os recursos necessários para o app.
- Para implantar o app, é preciso ter a gcloud instalada na máquina local, autenticada e configurada para usar o projeto.
gcloud auth logingcloud config set project
- Se você quiser executar o aplicativo na sua máquina local, o que eu recomendo, verifique se as credenciais padrão do aplicativo estão configuradas corretamente, incluindo a definição do projeto de cota.
gcloud auth application-default logingcloud auth application-default set-quota-project
- Também é necessário ter instalado o seguinte software:
- Python (é necessário ter a versão 3.11 ou mais recente)
- A CLI do LangChain
- poetry para gerenciamento de dependências
- pipx para instalar e executar a CLI do LangChain e o poetry em ambientes virtuais isolados
Confira um blog que ajuda você a instalar as ferramentas necessárias para este tutorial.
Cloud Workstations
Em vez da máquina local, também é possível usar o Cloud Workstations no Google Cloud. Em abril de 2024, ele executa uma versão do Python anterior à 3.11. Portanto, talvez seja necessário fazer upgrade do Python antes de começar.
Ativar as APIs do Cloud
Primeiro, execute o comando a seguir para garantir que você configurou o projeto correto do Google Cloud para usar:
gcloud config list project
Se o projeto correto não estiver aparecendo, use este comando para configurá-lo:
gcloud config set project <PROJECT_ID>
Agora ative as seguintes APIs:
gcloud services enable \ bigquery.googleapis.com \ sqladmin.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ run.googleapis.com \ secretmanager.googleapis.com
Escolha uma região
O Google Cloud está disponível em muitos locais no mundo todo, e você precisa escolher um para implantar os recursos que vai usar neste laboratório. Defina a região como uma variável de ambiente no shell. Os comandos posteriores usam essa variável:
export REGION=us-central1
3. Criar a instância do banco de dados de vetores
Uma parte fundamental desse app é recuperar notas da versão relevantes para a pergunta do usuário. Para deixar isso mais concreto, se você estiver fazendo uma pergunta sobre o Cloud Storage, adicione a seguinte nota da versão ao comando:
Você pode usar embeddings de texto e um banco de dados vetorial para encontrar notas da versão semanticamente semelhantes.
Vou mostrar como usar o PostgreSQL no Cloud SQL como um banco de dados vetorial. A criação de uma instância do Cloud SQL leva algum tempo. Vamos fazer isso agora.
gcloud sql instances create sql-instance \ --database-version POSTGRES_14 \ --tier db-f1-micro \ --region $REGION
Deixe esse comando em execução e continue com as próximas etapas. Em algum momento, você vai precisar criar um banco de dados e adicionar um usuário, mas não vamos perder tempo assistindo o ícone de carregamento agora.
O PostgreSQL é um servidor de banco de dados relacional, e cada nova instância do Cloud SQL tem a extensão pgvector instalada por padrão. Isso significa que você também pode usá-lo como um banco de dados vetorial.
4. Criar o scaffold do app LangChain
Para continuar, você precisa ter a CLI do LangChain instalada e o poetry para gerenciar dependências. Veja como instalar usando o pipx:
pipx install langchain-cli poetry
Estruture o app LangChain com o seguinte comando. Quando solicitado, nomeie a pasta como run-rag e pule a instalação de pacotes pressionando Enter:
langchain app new
Mude para o diretório run-rag e instale as dependências.
poetry install
Você acabou de criar um app LangServe, que envolve o FastAPI em uma cadeia do LangChain. Ele vem com um playground integrado que facilita o envio de comandos e a inspeção dos resultados, incluindo todas as etapas intermediárias. Sugiro que você abra a pasta run-rag no editor e veja o que tem lá.
5. Criar o job de indexação
Antes de começar a criar o web app, verifique se as notas da versão do Cloud Run estão indexadas no banco de dados do Cloud SQL. Nesta seção, você vai criar um job de indexação que faz o seguinte:
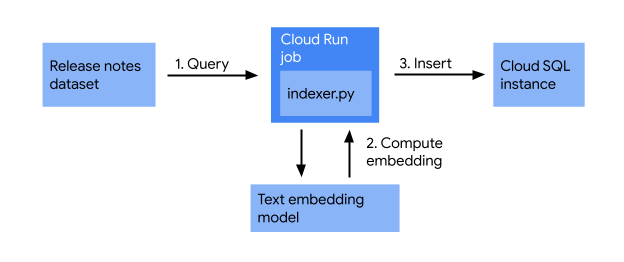
O job de indexação usa notas da versão, as converte em vetores usando um modelo de embedding de texto e as armazena em um banco de dados de vetores. Isso permite pesquisar de forma eficiente notas da versão semelhantes com base no significado semântico delas.
Na pasta run-rag/app, crie um arquivo indexer.py com o seguinte conteúdo:
import os
from google.cloud.sql.connector import Connector
import pg8000
from langchain_community.vectorstores.pgvector import PGVector
from langchain_google_vertexai import VertexAIEmbeddings
from google.cloud import bigquery
# Retrieve all Cloud Run release notes from BigQuery
client = bigquery.Client()
query = """
SELECT
CONCAT(FORMAT_DATE("%B %d, %Y", published_at), ": ", description) AS release_note
FROM `bigquery-public-data.google_cloud_release_notes.release_notes`
WHERE product_name= "Cloud Run"
ORDER BY published_at DESC
"""
rows = client.query(query)
print(f"Number of release notes retrieved: {rows.result().total_rows}")
# Set up a PGVector instance
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
store = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
),
pre_delete_collection=True
)
# Save all release notes into the Cloud SQL database
texts = list(row["release_note"] for row in rows)
ids = store.add_texts(texts)
print(f"Done saving: {len(ids)} release notes")
Adicione as dependências necessárias:
poetry add \ "cloud-sql-python-connector[pg8000]" \ langchain-google-vertexai==1.0.5 \ langchain-community==0.2.5 \ pgvector
Criar o banco de dados e um usuário
Crie um banco de dados release-notes na instância do Cloud SQL sql-instance:
gcloud sql databases create release-notes --instance sql-instance
Crie um usuário de banco de dados chamado app:
gcloud sql users create app --instance sql-instance --password "myprecious"
Implantar e executar o job de indexação
Agora implante e execute o job:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run jobs deploy indexer \ --source . \ --command python \ --args app/indexer.py \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --execute-now
Esse é um comando longo. Vamos analisar o que está acontecendo:
O primeiro comando recupera o nome da conexão (um ID exclusivo formatado como project:region:instance) e o define como a variável de ambiente DB_INSTANCE_NAME.
O segundo comando implanta o job do Cloud Run. Confira o que as flags fazem:
--source .: especifica que o código-fonte do job está no diretório de trabalho atual (o diretório em que você está executando o comando).--command python: define o comando a ser executado no contêiner. Neste caso, é para executar o Python.--args app/indexer.py: fornece os argumentos para o comando Python. Isso informa para executar o script indexer.py no diretório do app.--set-env-vars: define variáveis de ambiente que o script Python pode acessar durante a execução.--region=$REGION: especifica a região em que o job será implantado.--execute-now: instrui o Cloud Run a iniciar o job imediatamente após a implantação.
Para verificar se o job foi concluído com sucesso, faça o seguinte:
- Leia os registros da execução do job no console da Web. Ele vai informar "Concluído: xxx notas da versão", em que xxx é o número de notas da versão salvas.
- Também é possível navegar até a instância do Cloud SQL no console da Web e usar o Cloud SQL Studio para consultar o número de registros na tabela
langchain_pg_embedding.
6. Escrever o aplicativo da Web
Abra o arquivo app/server.py no editor. Você vai encontrar uma linha com o seguinte texto:
# Edit this to add the chain you want to add
Substitua esse comentário pelo seguinte snippet:
# (1) Initialize VectorStore
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
vectorstore = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
)
)
# (2) Build retriever
def concatenate_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
notes_retriever = vectorstore.as_retriever() | concatenate_docs
# (3) Create prompt template
prompt_template = PromptTemplate.from_template(
"""You are a Cloud Run expert answering questions.
Use the retrieved release notes to answer questions
Give a concise answer, and if you are unsure of the answer, just say so.
Release notes: {notes}
Here is your question: {query}
Your answer: """)
# (4) Initialize LLM
llm = VertexAI(
model_name="gemini-1.0-pro-001",
temperature=0.2,
max_output_tokens=100,
top_k=40,
top_p=0.95
)
# (5) Chain everything together
chain = (
RunnableParallel({
"notes": notes_retriever,
"query": RunnablePassthrough()
})
| prompt_template
| llm
| StrOutputParser()
)
Você também precisa adicionar estas importações:
import pg8000
import os
from google.cloud.sql.connector import Connector
from langchain_google_vertexai import VertexAI
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.vectorstores.pgvector import PGVector
Por fim, mude a linha "NotImplemented" para:
# add_routes(app, NotImplemented)
add_routes(app, chain)
7. Implantar o aplicativo da Web no Cloud Run
No diretório run-rag, use o seguinte comando para implantar o app no Cloud Run:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run deploy run-rag \ --source . \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --allow-unauthenticated
Este comando faz o seguinte:
- Fazer upload do código-fonte para o Cloud Build
- Execute "docker build".
- Envie a imagem do contêiner resultante para o Artifact Registry.
- Crie um serviço do Cloud Run usando a imagem do contêiner.
Quando o comando for concluído, ele vai listar um URL HTTPS no domínio run.app. Este é o URL público do novo serviço do Cloud Run.
8. Conheça o playground
Abra o URL do serviço do Cloud Run e navegue até /playground. Um campo de texto vai aparecer. Use-o para fazer perguntas sobre as notas da versão do Cloud Run, como aqui:
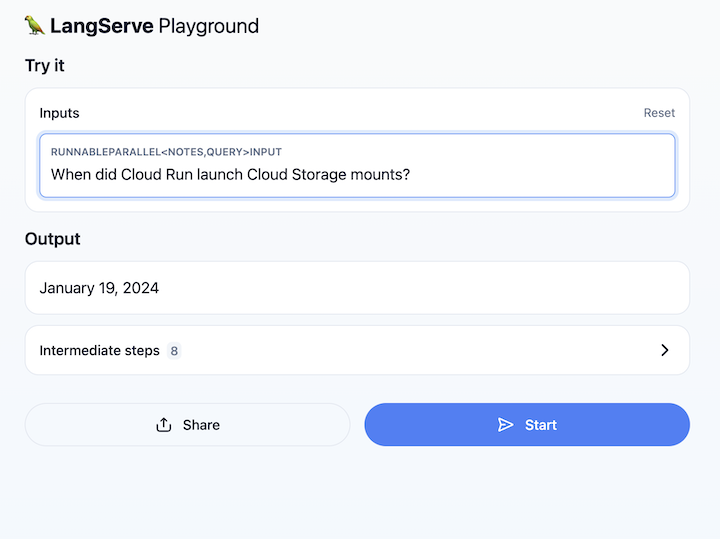
9. Parabéns
Você criou e implantou um app LangChain no Cloud Run. Muito bem!
Confira os principais conceitos:
- Usar o framework LangChain para criar um aplicativo de geração aumentada de recuperação (RAG).
- Usando o PostgreSQL no Cloud SQL como um banco de dados vetorial com pgvector, que é instalado por padrão no Cloud SQL.
- Execute um job de indexação de longa duração como um job do Cloud Run e um aplicativo da Web como um serviço do Cloud Run.
- Envolva uma cadeia do LangChain em um aplicativo FastAPI com o LangServe, oferecendo uma interface conveniente para interagir com seu app RAG.
Limpar
Para evitar que os recursos usados nesse tutorial sejam cobrados na sua conta do Google Cloud Platform:
- No Console do Cloud, acesse a página Gerenciar recursos:
- Na lista de projetos, selecione o projeto e clique em "Excluir".
- Na caixa de diálogo, digite o ID do projeto e clique em "Encerrar" para excluí-lo.
Se você quiser manter o projeto, exclua os seguintes recursos:
- Instância do Cloud SQL
- Serviço do Cloud Run
- Job do Cloud Run