
1. Introduction
Dans cet atelier de programmation, vous allez apprendre à utiliser BigQuery Graph pour créer une vue client à 360 degrés et un moteur de recommandation pour Cymbal Pets, une entreprise fictive de vente au détail. Vous exploiterez la puissance de SQL pour créer, interroger et analyser des données graphiques directement dans BigQuery, en les combinant à la recherche vectorielle pour obtenir des recommandations de produits avancées.
BigQuery Graph vous permet de modéliser les relations entre vos entités de données (comme les clients, les produits et les commandes) sous forme de graphique. Vous pouvez ainsi répondre facilement à des questions complexes sur le comportement des clients et les affinités des produits.

Objectifs de l'atelier
- Créer un ensemble de données et un schéma BigQuery pour le graphique Cymbal Pets
- Charger des exemples de données (clients, produits, commandes, magasins) depuis Cloud Storage
- Créez un Property Graph dans BigQuery en associant ces entités.
- Visualiser l'historique des achats des clients à l'aide de requêtes graphiques
- Créer un système de recommandation de produits à l'aide de la recherche vectorielle
- Améliorer les recommandations à l'aide des relations du graphique "Acheté ensemble" et de la similarité de Jaccard
Prérequis
- Un navigateur Web (par exemple, Chrome)
- Un projet Google Cloud avec facturation activée
Cet atelier de programmation s'adresse aux développeurs de tous niveaux, y compris aux débutants.
2. Avant de commencer
Créer un projet Google Cloud
- Dans la console Google Cloud, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud.
Démarrer Cloud Shell
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
- Vérifiez l'authentification :
gcloud auth list
- Confirmez votre projet :
gcloud config get project
- Définissez-la si nécessaire :
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Activer les API
Exécutez la commande suivante pour activer l'API BigQuery requise :
gcloud services enable bigquery.googleapis.com
3. Définir le schéma
Vous devez d'abord créer un ensemble de données pour stocker vos tables liées aux graphiques et définir le schéma de vos nœuds et de vos arêtes.
- Pour cet atelier de programmation, nous allons exécuter des commandes SQL. Vous pouvez exécuter ces commandes dans BigQuery Studio > Éditeur SQL ou utiliser la commande
bq querydans Cloud Shell. Nous partons du principe que vous utilisez l'éditeur SQL BigQuery pour une meilleure expérience avec les instructions CREATE multilignes.
Nous partons du principe que vous utilisez l'éditeur SQL BigQuery pour une meilleure expérience avec les instructions CREATE multilignes. - Créez l'ensemble de données
cymbal_pets_demo:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- Créez les tables pour
order_items,products,orders,stores,customersetco_related_products_for_angelica. Ces tables serviront de données sources pour notre graphique.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
Vous avez maintenant défini la structure de vos données de graphique.
4. Charger les données
Maintenant, insérez des exemples de données provenant de Cloud Storage dans les tables.
Exécutez les instructions LOAD DATA suivantes dans l'éditeur SQL BigQuery :
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
Un message de confirmation doit vous indiquer que des lignes ont été chargées dans chaque table.
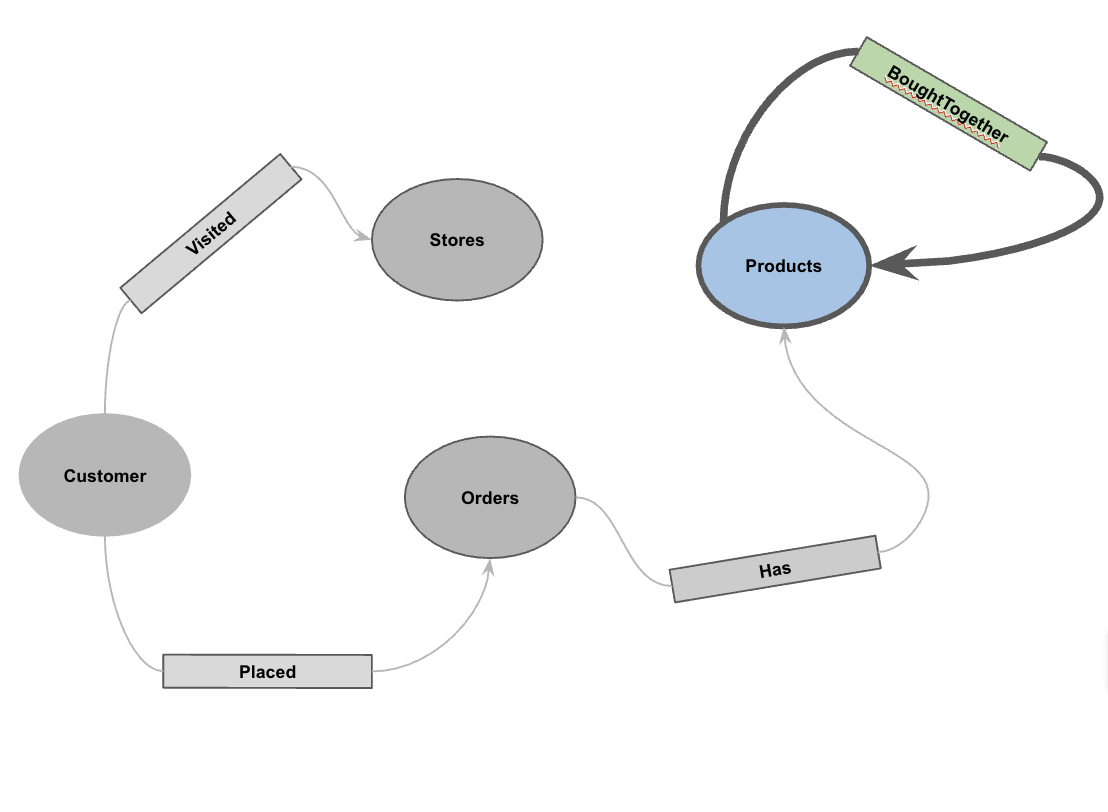
5. Créer le graphique de propriété
Une fois les données chargées, vous pouvez définir le graphique de propriétés. Cela indique à BigQuery quelles tables représentent des nœuds (entités telles que les clients et les produits) et quelles tables représentent des arêtes (relations telles que "A visité", "A passé" et "A").
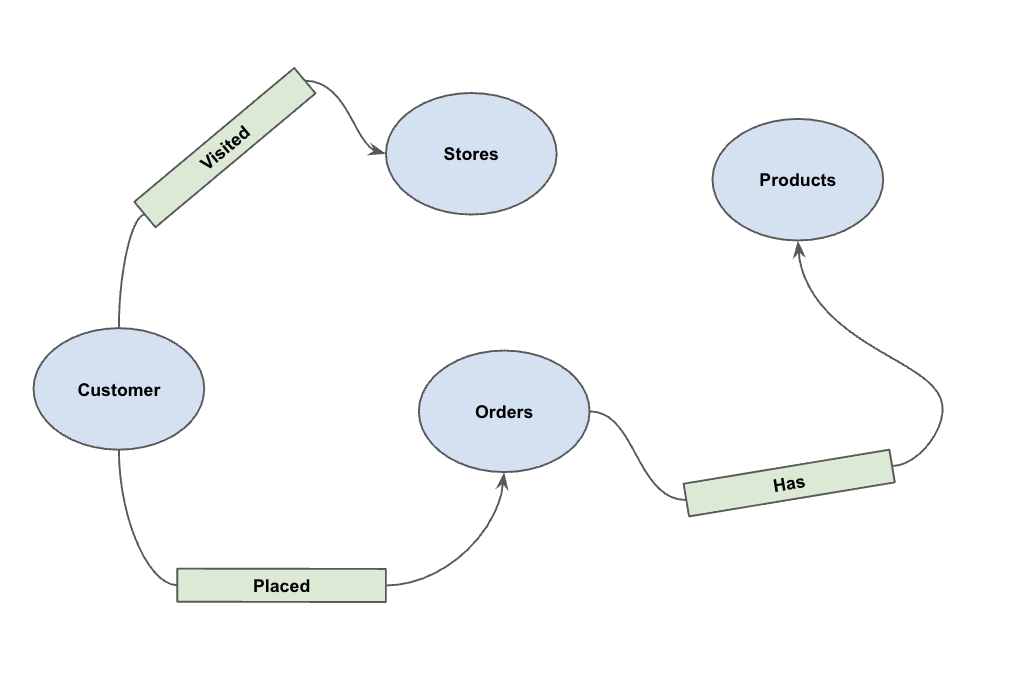
Exécutez l'instruction LDD suivante :
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
Cela crée le graphique PetsOrderGraph, qui nous permet d'effectuer des traversées de graphes à l'aide de l'opérateur GRAPH_TABLE.
6. Visualiser l'historique des achats de tous les clients
Pour les parties visualisation et recommandation de cet atelier de programmation, nous utiliserons la visualisation de graphiques native de BigQuery Studio. Cela nous permet de visualiser facilement les résultats du graphique.
Vous pouvez également visualiser les résultats dans BigQuery Graph Notebook à l'aide des commandes magiques IPython. En ajoutant la commande magique %%bigquery avec la fonction TO_JSON, vous pouvez visualiser les résultats comme indiqué dans les sections suivantes.
Imaginons que Cymbal Pets souhaite obtenir une visualisation à 360 degrés de tous les clients et des achats qu'ils ont effectués au cours d'une période spécifique.
Exécutez la requête suivante dans un nouvel onglet BigQuery Studio :
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
Pour visualiser vos résultats, cliquez sur "Graphique" dans le volet "Résultats de la requête".

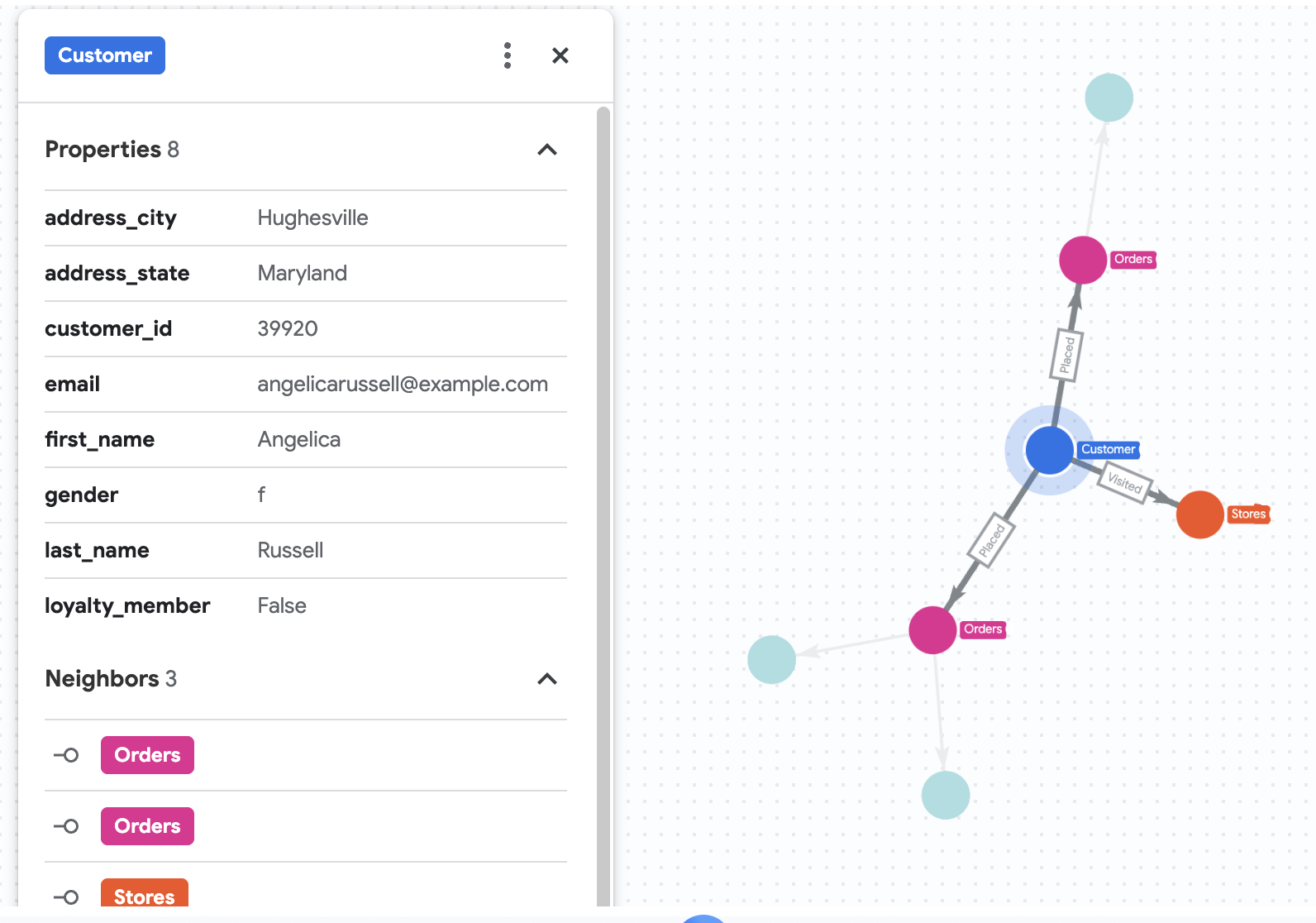
7. Visualiser l'historique des achats d'Angelica
Supposons que Cymbal Pets souhaite en savoir plus sur une cliente nommée Angelica Russell. L'entreprise veut analyser les produits qu'Angelica a achetés au cours des trois derniers mois et les magasins qu'elle a visités.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
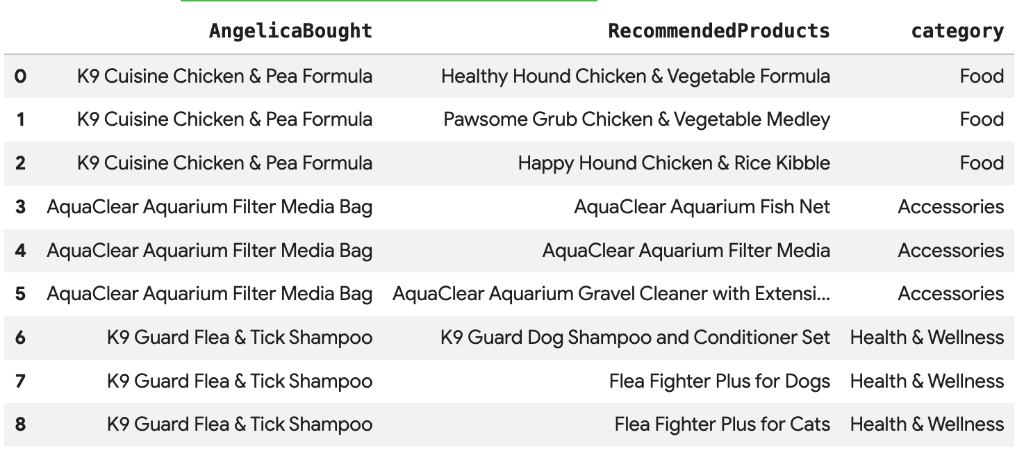
8. Recommandation de produits à l'aide de la recherche vectorielle
Cymbal Pets souhaite recommander des produits à Angelica en fonction de ses achats récents. Nous pouvons utiliser la recherche vectorielle pour trouver des produits dont les embeddings sont similaires à ceux de ses achats précédents.
Exécutez le script SQL suivant dans une nouvelle cellule Colab. Ce script :
- Identifie les produits qu'Angelica a achetés récemment.
- Utilise
VECTOR_SEARCHpour trouver les quatre produits similaires les plus populaires dans le tableauproducts.
Remarque : Cette étape suppose que vous avez déjà exécuté AI.GENERATE_EMBEDDINGS pour créer une colonne d'embeddings dans la table "products".
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
Une liste de produits recommandés sémantiquement semblables à ceux achetés par Angelica devrait s'afficher.
9. Recommandation utilisant "Achetés ensemble" et la similarité de Jaccard
Le filtrage collaboratif est une autre technique de recommandation efficace. Il consiste à recommander des produits fréquemment achetés ensemble par d'autres utilisateurs.
Pour trouver ces produits, nous parcourons le graphique d'un client à ses produits achetés, puis à d'autres clients qui ont acheté ces produits, et enfin aux autres produits que ces clients ont achetés.
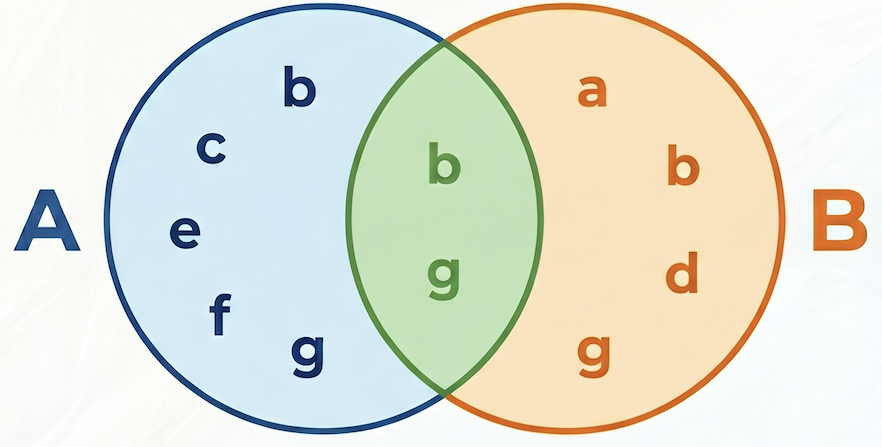
Surmonter le biais de popularité avec la similarité de Jaccard
Bien que les nombres bruts de co-achats soient utiles, ils peuvent être biaisés en faveur des produits populaires. Un produit très populaire peut être acheté avec de nombreux articles par hasard.
La similarité de Jaccard va encore plus loin en normalisant le nombre de co-achats. Elle mesure la similarité entre deux ensembles (dans ce cas, les ensembles de commandes contenant chaque produit).
La formule de similarité Jaccard est la suivante :

Où :
- A intersect B correspond au nombre de commandes contenant à la fois le produit A et le produit B (nombre de co-achats).
- A correspond au nombre total de commandes contenant le produit A.
- B correspond au nombre total de commandes contenant le produit B.
Dans l'exemple suivant, l'ensemble A = {b,c,e,f,g}, l'ensemble B = {a,d,b,g}, leur intersection A⋂B = {b,g}, leur union A⋃B = {a,b,c,d,e,f,g}, donc la similarité de Jaccard entre A et B est de 2 / 7 = 0,285714.
Génération et reclassification des candidats
Dans les systèmes de recommandation réels fonctionnant sur des ensembles de données volumineux, il est souvent impossible de calculer des scores de similarité complexes (comme Jaccard) pour toutes les paires de produits possibles. Au lieu de cela, un modèle courant consiste à utiliser une approche en deux étapes :
- Génération de candidats : utilisez une métrique simple et rapide (comme le nombre brut de co-achats) pour filtrer l'espace de recherche et trouver un nombre gérable de candidats (par exemple, les 10 premiers).
- Reclassement : appliquez une métrique plus précise, mais plus gourmande en ressources de calcul (comme la similarité de Jaccard), pour classer ce petit ensemble de candidats et sélectionner les meilleures recommandations finales.
Dans cet atelier de programmation, nous suivrons ce modèle :
- Étape 1 : Exécutez une requête pour trouver les 10 produits les plus souvent achetés ensemble pour chaque produit, en fonction du nombre brut de co-achats, et stockez-les dans un tableau.
- Étape 2 : Utilisez une requête de graphique pour récupérer ces candidats, les classer par similarité de Jaccard et renvoyer les trois premiers.
[!WARNING] Inconvénient : en filtrant sur le nombre brut à l'étape 1, nous risquons de perdre le "rappel" des achats groupés très spécifiques, mais peu fréquents. Si un produit est très similaire à un autre, mais que les deux sont rarement achetés, il est possible qu'il ne figure pas parmi les 10 candidats les plus pertinents et qu'il soit manqué.
Exécutez la requête suivante pour calculer le nombre brut de co-achats et la similarité de Jaccard, et stocker les 10 principaux candidats par nombre brut :
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
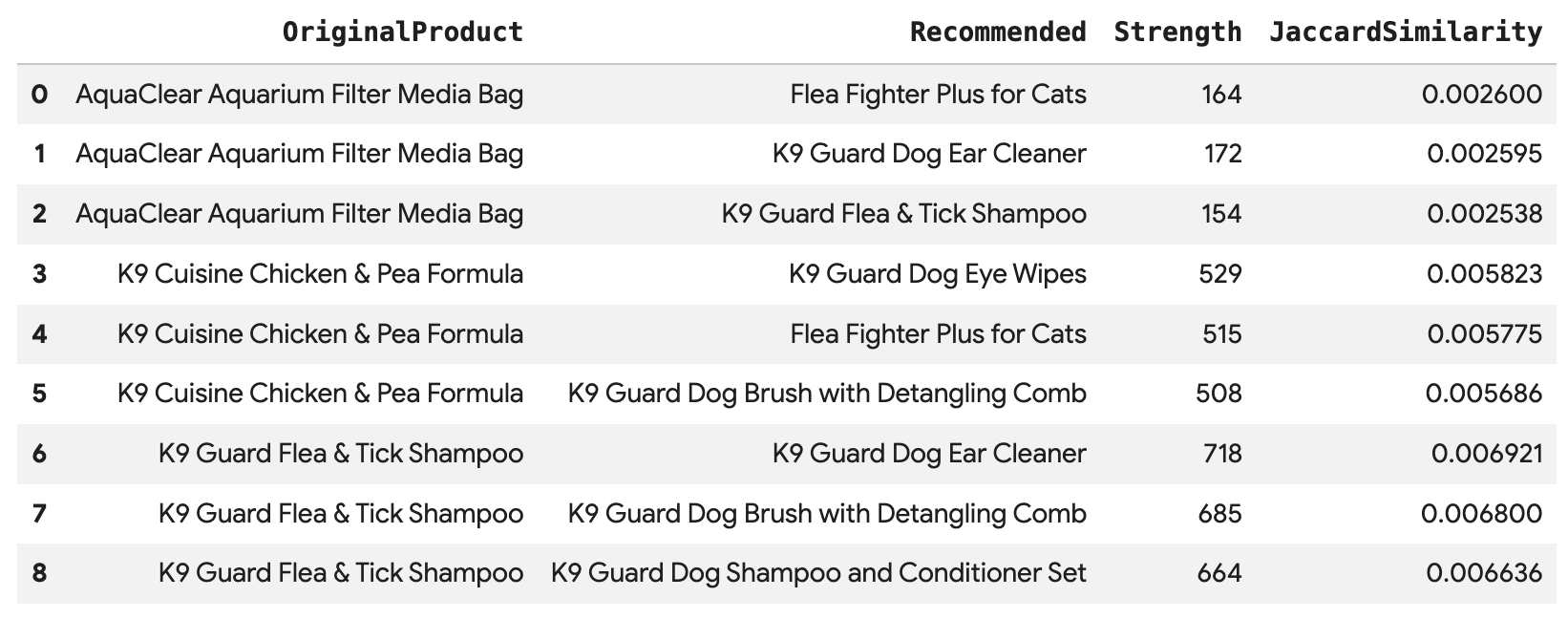
Exécutez cette requête pour recommander les trois principaux produits pour chacun des achats d'Angelica, directement connectés via l'arête BoughtTogether, en affichant à la fois le nombre de co-achats et la similarité de Jaccard :
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
Cette requête traverse les données de client > commande > produit > (AchetésEnsemble) > produit recommandé. Elle vous montre les recommandations basées sur le comportement d'achat collectif et récupère leurs scores de similarité.
10. Effectuer un nettoyage
Pour éviter que les ressources créées lors de cet atelier de programmation ne soient facturées en permanence sur votre compte Google Cloud, supprimez-les.
Supprimez l'ensemble de données et toutes les tables :
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
Si vous avez créé un projet pour cet atelier de programmation, vous pouvez également le supprimer :
gcloud projects delete $PROJECT_ID
11. Félicitations
Félicitations ! Vous avez créé une vue client à 360 degrés et un moteur de recommandation à l'aide de BigQuery Graph.
Connaissances acquises
- Comment créer un graphique de propriétés dans BigQuery.
- Comment charger des données dans les nœuds et les arêtes du graphique.
- Comment interroger des modèles de graphiques à l'aide de
GRAPH_TABLEetMATCH. - Découvrez comment combiner les requêtes graphiques avec la recherche vectorielle pour obtenir des recommandations hybrides.
Étapes suivantes
- Consultez la documentation BigQuery Graph.
- En savoir plus sur la recherche vectorielle dans BigQuery