
1. Einführung
In diesem Codelab erfahren Sie, wie Sie mit BigQuery Graph eine 360-Grad-Kundenansicht und ein Empfehlungssystem für Cymbal Pets, ein fiktives Einzelhandelsunternehmen, erstellen. Sie nutzen die Leistungsfähigkeit von SQL, um Graphdaten direkt in BigQuery zu erstellen, abzufragen und zu analysieren und sie mit der Vektorsuche zu kombinieren, um erweiterte Produktempfehlungen zu erhalten.
Mit BigQuery Graph können Sie Beziehungen zwischen Ihren Datenentitäten (z. B. Kunden, Produkte und Bestellungen) als Graph modellieren. So lassen sich komplexe Fragen zum Kundenverhalten und zu Produktpräferenzen ganz einfach beantworten.

Aufgaben
- BigQuery-Dataset und -Schema für den Cymbal Pets-Graph erstellen
- Beispieldaten (Kunden, Produkte, Bestellungen, Geschäfte) aus Cloud Storage laden
- Attributgraph in BigQuery erstellen, der diese Entitäten verbindet
- Bisherige Käufe von Kunden mit Graphabfragen visualisieren
- Produktempfehlungssystem mit der Vektorsuche erstellen
- Empfehlungen mit Graphbeziehungen vom Typ „Häufig zusammen gekauft“ und der Jaccard-Ähnlichkeit verbessern
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
Dieses Codelab richtet sich an Entwickler aller Erfahrungsstufen, auch an Anfänger.
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein.
Cloud Shell starten
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Authentifizierung überprüfen:
gcloud auth list
- Bestätigen Sie Ihr Projekt:
gcloud config get project
- Legen Sie es bei Bedarf fest:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
APIs aktivieren
Führen Sie diesen Befehl aus, um die erforderliche BigQuery API zu aktivieren:
gcloud services enable bigquery.googleapis.com
3. Schema definieren
Zuerst müssen Sie ein Dataset erstellen, um Ihre graphenbezogenen Tabellen zu speichern, und das Schema für Ihre Knoten und Kanten definieren.
- In diesem Codelab führen wir SQL-Befehle aus. Sie können diese Befehle im BigQuery Studio > SQL-Editor ausführen oder den
bq queryBefehl in Cloud Shell verwenden. Wir gehen davon aus, dass Sie den BigQuery SQL-Editor verwenden, um mehrzeilige Erstellungsanweisungen besser verarbeiten zu können.
Wir gehen davon aus, dass Sie den BigQuery SQL-Editor verwenden, um mehrzeilige Erstellungsanweisungen besser verarbeiten zu können. - Erstellen Sie das Dataset
cymbal_pets_demo:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- Erstellen Sie die Tabellen für
order_items,products,orders,stores,customers, undco_related_products_for_angelica. Diese Tabellen dienen als Quelldaten für unseren Graph.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
Sie haben jetzt die Struktur für Ihre Graphdaten definiert.
4. Daten laden
Füllen Sie die Tabellen nun mit Beispieldaten aus Cloud Storage.
Führen Sie die folgenden LOAD DATA-Anweisungen im BigQuery SQL-Editor aus:
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
Sie sollten eine Bestätigung sehen, dass Zeilen in jede Tabelle geladen wurden.
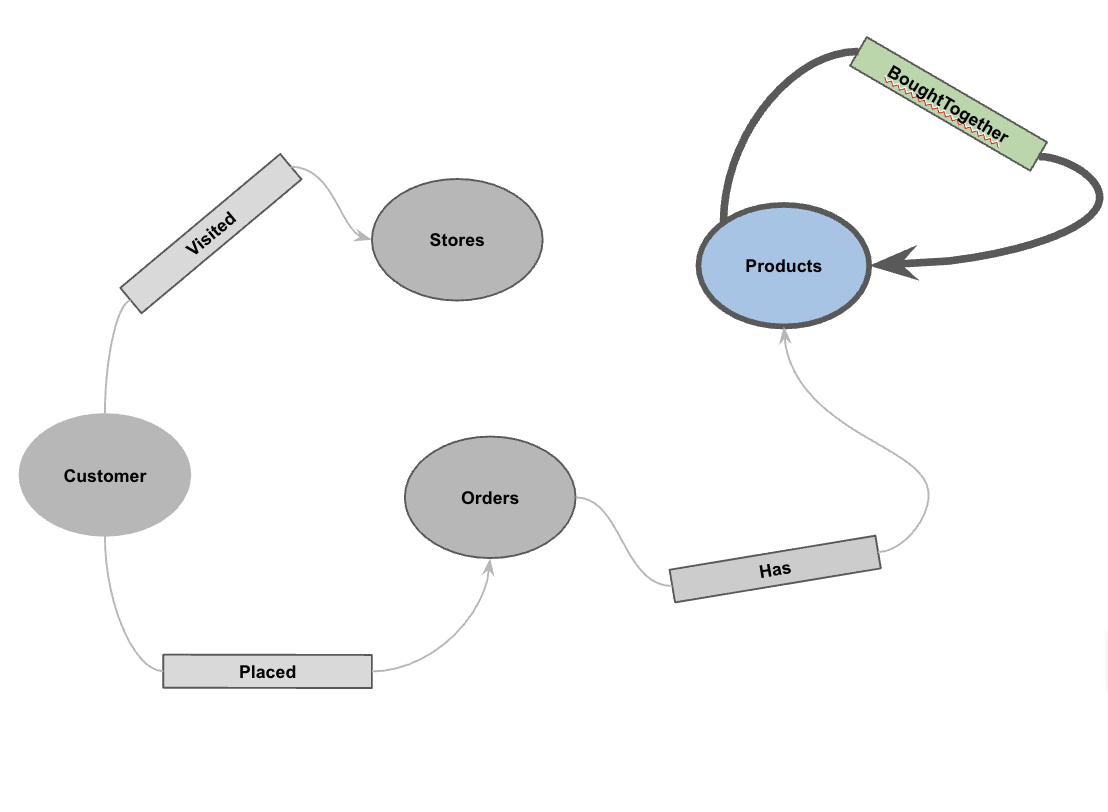
5. Attributgraph erstellen
Nachdem die Daten geladen wurden, können Sie jetzt den Attributgraph definieren. Dadurch wird BigQuery mitgeteilt, welche Tabellen Knoten (Entitäten wie Kunden, Produkte) und welche Tabellen Kanten (Beziehungen wie „Besucht“, „Platziert“, „Hat“) darstellen.
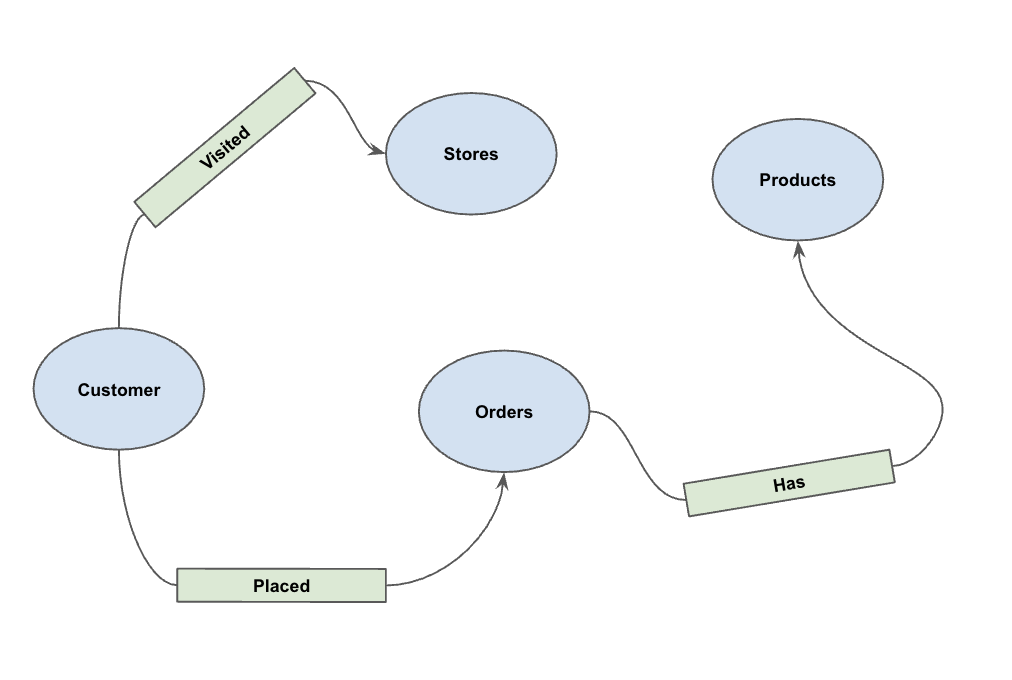
Führen Sie die folgende DDL-Anweisung aus:
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
Dadurch wird der Graph PetsOrderGraph erstellt, mit dem wir Graphdurchläufe mit dem Operator GRAPH_TABLE ausführen können.
6. Bisherige Käufe aller Kunden visualisieren
Für die Visualisierungs- und Empfehlungsteile dieses Codelabs verwenden wir die native Graphvisualisierung in BigQuery Studio. So können wir die Graphergebnisse ganz einfach visualisieren.
Alternativ können Sie die Visualisierung in BigQuery Graph Notebook mit IPython Magics durchführen. Wenn Sie den magischen Befehl %%bigquery mit der Funktion TO_JSON hinzufügen, können Sie die Ergebnisse wie in den folgenden Abschnitten gezeigt visualisieren.
Angenommen, Cymbal Pets möchte eine 360-Grad-Visualisierung aller Kunden und ihrer Käufe in einem bestimmten Zeitraum erhalten.
Führen Sie die folgende Abfrage auf einem neuen BigQuery Studio-Tab aus:
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
Wenn Sie die Ergebnisse visualisieren möchten, klicken Sie im Bereich „Abfrageergebnisse“ auf „Graph“.

7. Bisherige Käufe von Angelica visualisieren
Angenommen, Cymbal Pets möchte sich die Daten einer Kundin namens Angelica Russell genauer ansehen. Das Unternehmen möchte die Produkte analysieren, die Angelica in den letzten drei Monaten gekauft hat, und die Geschäfte, die sie besucht hat.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
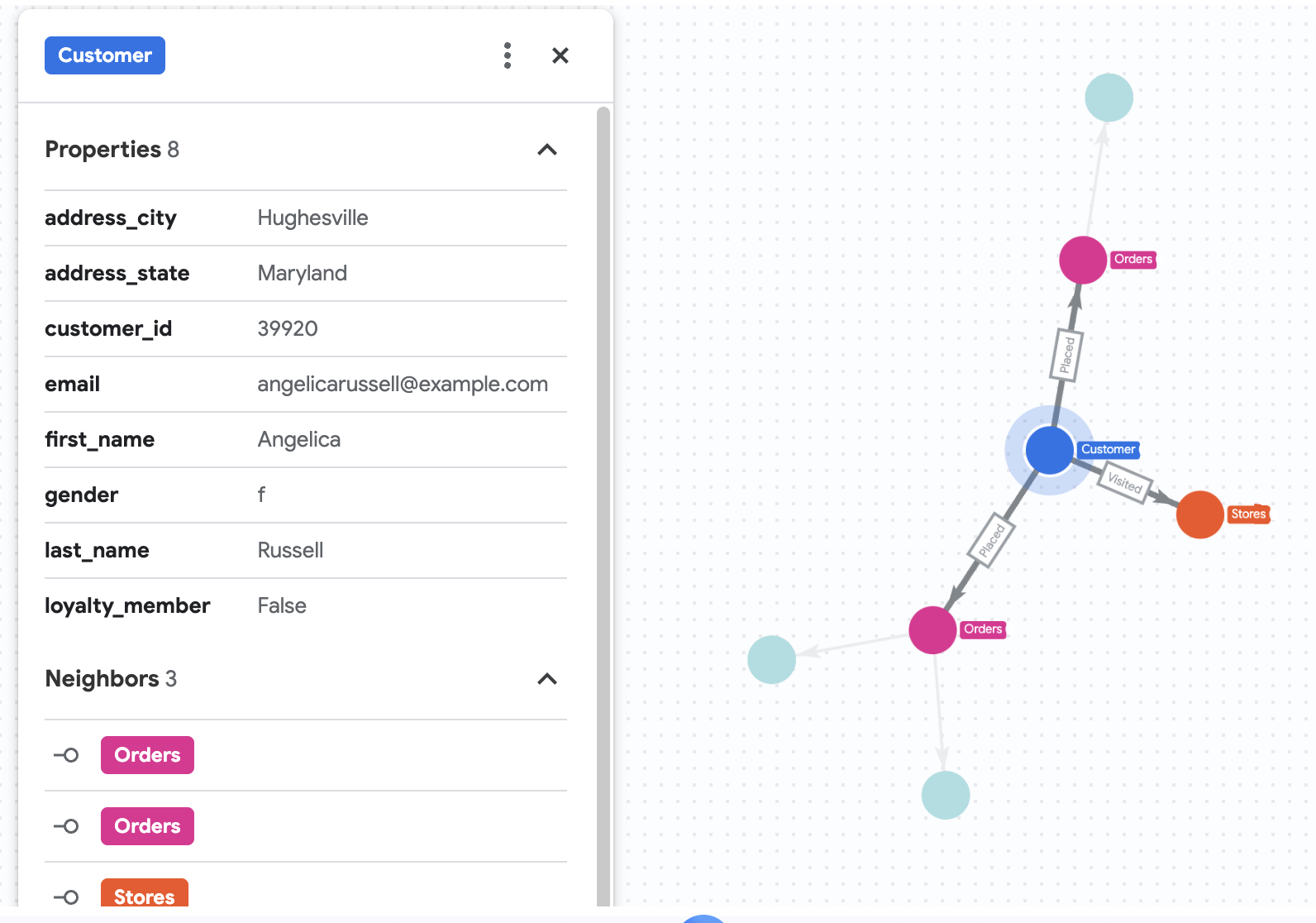
8. Produktempfehlung mit der Vektorsuche
Cymbal Pets möchte Angelica Produkte empfehlen, die auf ihren letzten Käufen basieren. Wir können die Vektorsuche verwenden, um Produkte mit ähnlichen Einbettungen wie ihre bisherigen Käufe zu finden.
Führen Sie das folgende SQL-Skript in einer neuen Colab-Zelle aus: Dieses Skript:
- Identifiziert Produkte, die Angelica kürzlich gekauft hat.
- Verwendet
VECTOR_SEARCH, um die vier ähnlichsten Produkte aus der Tabelleproductszu finden.
Hinweis: Bei diesem Schritt wird davon ausgegangen, dass Sie bereits AI.GENERATE_EMBEDDINGS ausgeführt haben, um eine Einbettungsspalte in der Tabelle „products“ zu erstellen.
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
Sie sollten eine Liste mit empfohlenen Produkten sehen, die semantisch ähnlich zu dem sind, was Angelica gekauft hat.
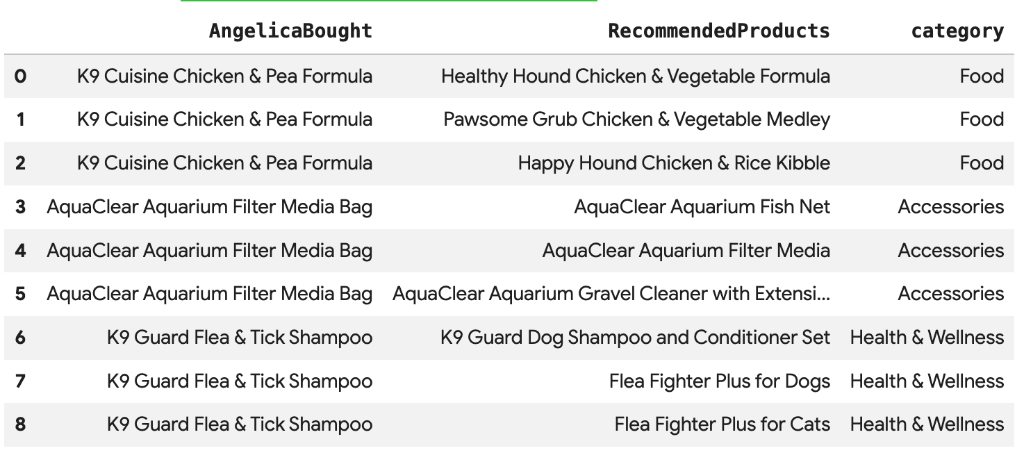
9. Empfehlung mit „Häufig zusammen gekauft“ und der Jaccard-Ähnlichkeit
Eine weitere leistungsstarke Empfehlungstechnik ist die kollaborative Filterung. Dabei werden Produkte empfohlen, die häufig von anderen Nutzern zusammen gekauft werden.
Wir können diese Produkte finden, indem wir den Graph von einem Kunden zu den von ihm gekauften Produkten, dann zu anderen Kunden, die diese Produkte gekauft haben, und schließlich zu den anderen Produkten durchlaufen, die diese Kunden gekauft haben.
Popularitätsbias mit der Jaccard-Ähnlichkeit überwinden
Die Anzahl der gemeinsamen Käufe ist zwar nützlich, kann aber durch beliebte Produkte verzerrt sein. Ein sehr beliebtes Produkt wird möglicherweise nur zufällig mit vielen anderen Produkten gekauft.
Die Jaccard-Ähnlichkeit geht bei den Empfehlungen noch einen Schritt weiter, indem sie die Anzahl der gemeinsamen Käufe normalisiert. Sie misst die Ähnlichkeit zwischen zwei Mengen (in diesem Fall die Mengen der Bestellungen, die jedes Produkt enthalten).
Die Formel für die Jaccard-Ähnlichkeit lautet:

Dabei gilt:
- A ∩ B ist die Anzahl der Bestellungen, die sowohl Produkt A als auch Produkt B enthalten (Anzahl der gemeinsamen Käufe).
- A ist die Gesamtzahl der Bestellungen, die Produkt A enthalten.
- B ist die Gesamtzahl der Bestellungen, die Produkt B enthalten.
Im folgenden Beispiel ist Menge A = {b,c,e,f,g}, Menge B = {a,d,b,g}, ihre Schnittmenge A ∩ B = {b,g} und ihre Vereinigungsmenge A ∪ B = {a,b,c,d,e,f,g}. Die Jaccard-Ähnlichkeit zwischen A und B beträgt also 2 / 7 = 0,285714.
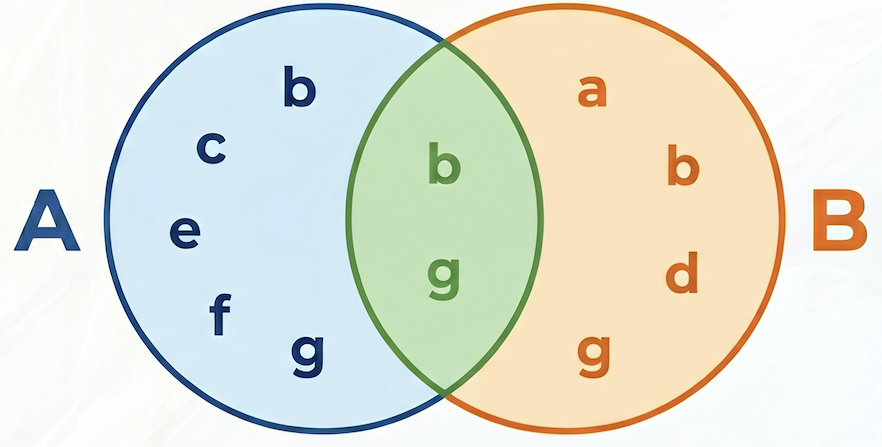
Kandidatengenerierung und erneutes Ranking
In Empfehlungssystemen, die mit riesigen Datasets arbeiten, ist es oft unpraktisch, komplexe Ähnlichkeitswerte (wie die Jaccard-Ähnlichkeit) für alle möglichen Produktpaare zu berechnen. Stattdessen wird häufig ein zweistufiger Ansatz verwendet:
- Kandidatengenerierung: Verwenden Sie einen einfachen, schnellen Messwert (z. B. die Anzahl der gemeinsamen Käufe), um den Suchraum zu filtern und eine überschaubare Anzahl von Kandidaten zu finden (z. B. die Top 10).
- Erneutes Ranking: Wenden Sie einen genaueren, aber rechenintensiveren Messwert (z. B. die Jaccard-Ähnlichkeit) an, um diese kleine Menge von Kandidaten zu bewerten und die endgültigen Top-Empfehlungen auszuwählen.
In diesem Codelab folgen wir diesem Muster:
- Stufe 1: Führen Sie eine Abfrage aus, um die Top 10 der gemeinsam gekauften Produkte für jedes Produkt basierend auf der Anzahl der gemeinsamen Käufe zu finden und in einer Tabelle zu speichern.
- Stufe 2: Rufen Sie diese Kandidaten mit einer Graphabfrage ab, bewerten Sie sie nach der Jaccard-Ähnlichkeit und geben Sie die Top 3 zurück.
[!WARNING] Nachteil: Wenn wir in Stufe 1 nach der Anzahl filtern, verlieren wir möglicherweise die „Trefferquote“ für sehr spezifische, aber selten vorkommende gemeinsame Käufe. Wenn ein Produkt einem anderen sehr ähnlich ist, aber beide selten gekauft werden, wird es möglicherweise nicht unter den Top 10 der Kandidaten aufgeführt.
Führen Sie die folgende Abfrage aus, um sowohl die Anzahl der gemeinsamen Käufe als auch die Jaccard-Ähnlichkeit zu berechnen und die Top 10 der Kandidaten nach der Anzahl zu speichern:
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
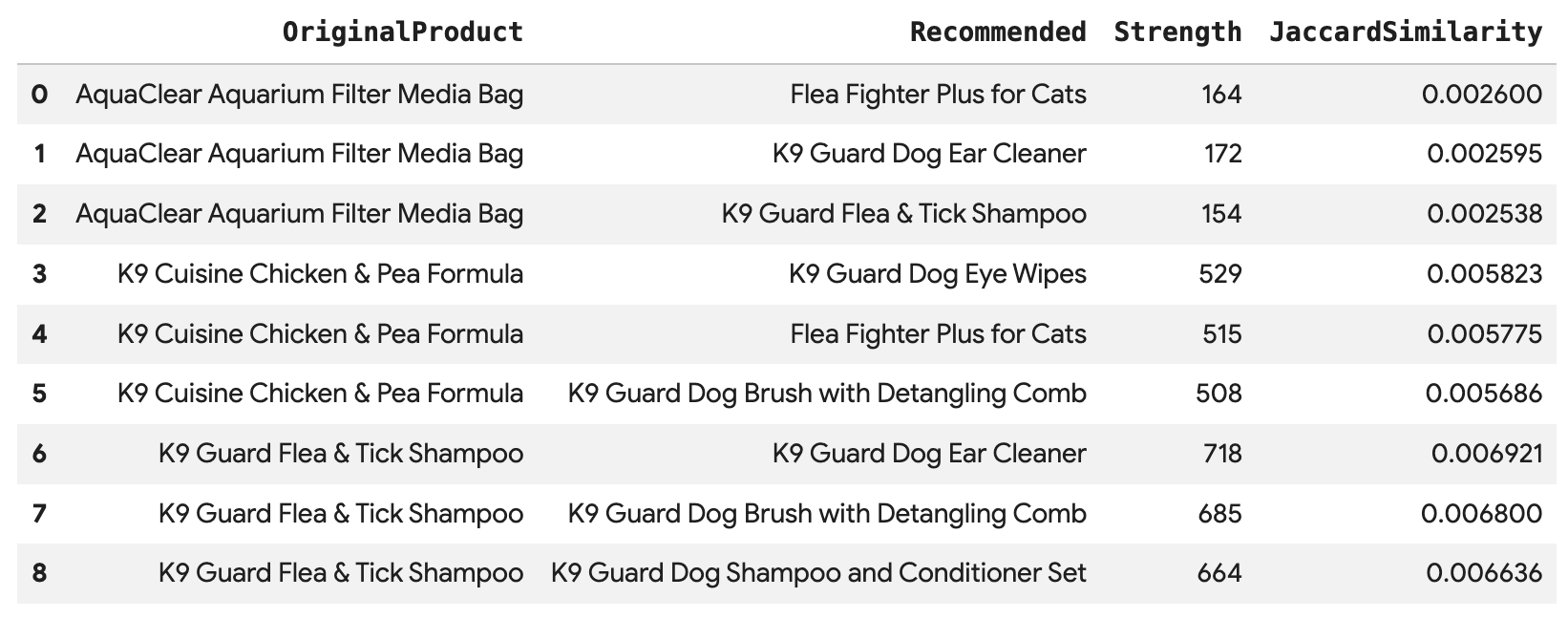
Führen Sie diese Abfrage aus, um die Top 3 der Produkte für jeden Kauf von Angelica zu empfehlen, die direkt über die Kante BoughtTogether verbunden sind. Dabei werden sowohl die Anzahl der gemeinsamen Käufe als auch die Jaccard-Ähnlichkeit angezeigt:
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
Diese Abfrage durchläuft den Graph von „Kunde“ -> „Bestellung“ -> „Produkt“ -> „(Häufig zusammen gekauft)“ -> „Empfohlenes Produkt“. So erhalten Sie Empfehlungen, die auf dem kollektiven Kaufverhalten basieren, und die entsprechenden Ähnlichkeitswerte.
10. Bereinigen
Löschen Sie die in diesem Codelab erstellten Ressourcen, damit Ihrem Google Cloud-Konto keine laufenden Gebühren in Rechnung gestellt werden.
Dataset und alle Tabellen löschen:
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
Wenn Sie für dieses Codelab ein neues Projekt erstellt haben, können Sie es auch löschen:
gcloud projects delete $PROJECT_ID
11. Glückwunsch
Glückwunsch! Sie haben mit BigQuery Graph erfolgreich eine 360-Grad-Kundenansicht und ein Empfehlungssystem erstellt.
Das haben Sie gelernt
- Attributgraph in BigQuery erstellen
- Daten in Graphknoten und -kanten laden
- Graphmuster mit
GRAPH_TABLEundMATCHabfragen - Graphabfragen mit der Vektorsuche für hybride Empfehlungen kombinieren
Nächste Schritte
- BigQuery Graph-Dokumentation ansehen
- Weitere Informationen zur Vektorsuche in BigQuery.