
1. Introdução
Neste codelab, você vai aprender a usar o BigQuery Graph para criar uma visualização do Cliente 360 e um mecanismo de recomendação para a Cymbal Pets, uma empresa de varejo fictícia. Você vai aproveitar o poder do SQL para criar, consultar e analisar dados de gráficos diretamente no BigQuery, combinando-o com a pesquisa vetorial para recomendações avançadas de produtos.
O BigQuery Graph permite modelar relações entre entidades de dados (como clientes, produtos e pedidos) como um gráfico, facilitando a resposta a perguntas complexas sobre o comportamento do cliente e as afinidades de produtos.

Atividades deste laboratório
- Criar um conjunto de dados e um esquema do BigQuery para o gráfico da Cymbal Pets
- Carregar dados de amostra (clientes, produtos, pedidos, lojas) do Cloud Storage
- Criar um gráfico de propriedades no BigQuery conectando essas entidades
- Visualizar o histórico de compras do cliente usando consultas de gráficos
- Criar um sistema de recomendação de produtos usando a pesquisa vetorial
- Melhorar as recomendações usando relações de gráficos "Comprados juntos" e similaridade de Jaccard
O que é necessário
- Um navegador da web, como o Chrome
- Tenha um projeto na nuvem do Google Cloud com o faturamento ativado.
Este codelab é destinado a desenvolvedores de todos os níveis, incluindo iniciantes.
2. Antes de começar
Criar um projeto do Google Cloud
- No console do Google Cloud, selecione ou crie um projeto na nuvem.
- Verifique se o faturamento está ativado para seu projeto na nuvem.
Iniciar o Cloud Shell
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.
- Verificar a autenticação:
gcloud auth list
- Confirmar seu projeto:
gcloud config get project
- Defina, se necessário:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Ativar APIs
Execute este comando para ativar a API BigQuery necessária:
gcloud services enable bigquery.googleapis.com
3. Definir o esquema
Primeiro, você precisa criar um conjunto de dados para armazenar as tabelas relacionadas ao gráfico e definir o esquema dos nós e das arestas.
- Para este codelab, vamos executar comandos SQL. É possível executar esses comandos no BigQuery Studio > Editor de SQL ou usar o
bq querycomando no Cloud Shell. Vamos presumir que você está usando o Editor de SQL do BigQuery para uma melhor experiência com instruções de criação de várias linhas.
Vamos presumir que você está usando o Editor de SQL do BigQuery para uma melhor experiência com instruções de criação de várias linhas. - Crie o conjunto de dados
cymbal_pets_demo:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- Crie as tabelas para
order_items,products,orders,stores,customerseco_related_products_for_angelica. Essas tabelas vão servir como dados de origem para nosso gráfico.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
Agora você definiu a estrutura dos dados do gráfico.
4. Carregar os dados
Agora, preencha as tabelas com dados de amostra do Cloud Storage.
Execute as seguintes instruções LOAD DATA no editor de SQL do BigQuery:
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
Uma mensagem de confirmação indica que as linhas foram carregadas em cada tabela.
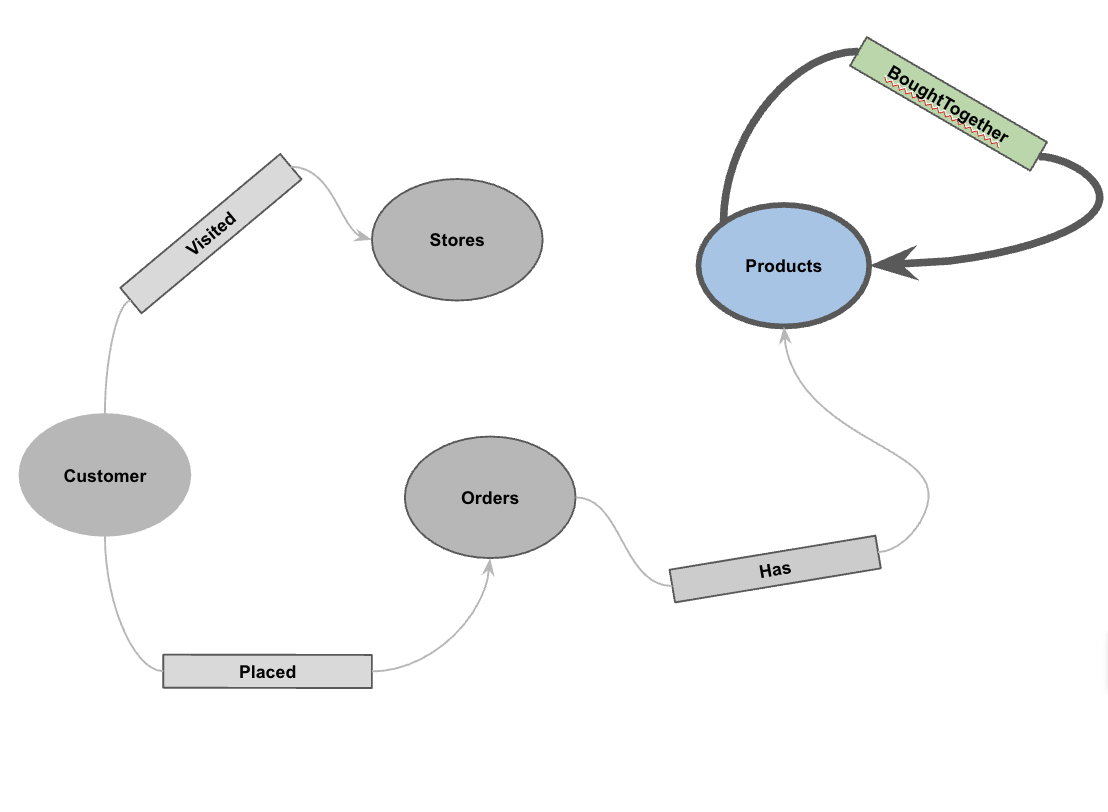
5. Criar o gráfico de propriedades
Com os dados carregados, agora você pode definir o gráfico de propriedades. Isso informa ao BigQuery quais tabelas representam nós (entidades como clientes, produtos) e quais tabelas representam arestas (relações como "Visitado", "Colocado", "Tem").
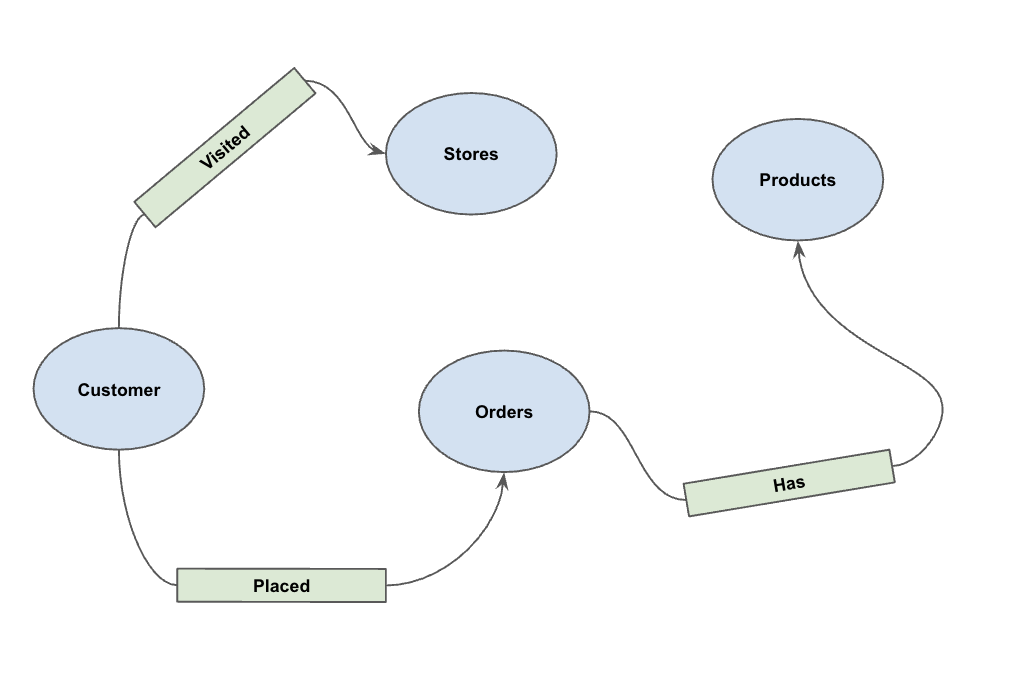
Execute a seguinte instrução DDL:
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
Isso cria o gráfico PetsOrderGraph, que permite realizar travessias de gráficos usando o operador GRAPH_TABLE.
6. Visualizar o histórico de compras de todos os clientes
Para as partes de visualização e recomendação deste codelab, vamos usar a visualização de gráfico nativa no BigQuery Studio. Isso permite visualizar facilmente os resultados do gráfico.
Como alternativa, você pode visualizar no BigQuery Graph Notebook usando comandos mágicos do IPython. Ao adicionar o comando mágico %%bigquery com a função TO_JSON, é possível visualizar os resultados conforme mostrado nas seções a seguir.
Suponha que a Cymbal Pets queira uma visualização de 360 graus de todos os clientes e as compras que eles fizeram em um período específico.
Execute o seguinte em uma nova guia do BigQuery Studio:
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
Para visualizar os resultados, no painel "Resultados da consulta", clique em "Gráfico".

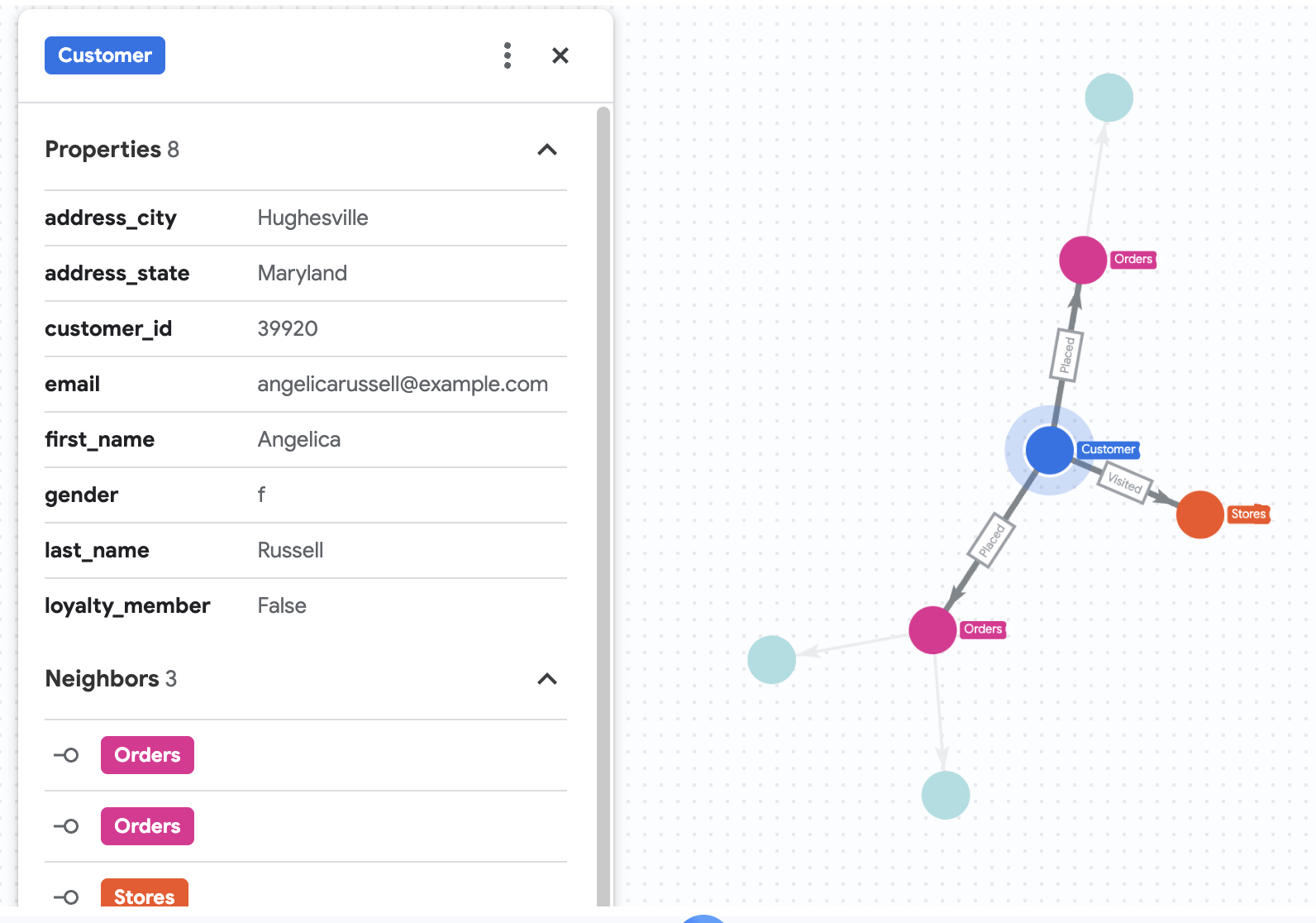
7. Visualizar o histórico de compras de Angelica
Suponha que a Cymbal Pets queira se aprofundar em uma cliente chamada Angelica Russell. Eles querem analisar os produtos que Angelica comprou nos últimos três meses e as lojas que a cliente visitou.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
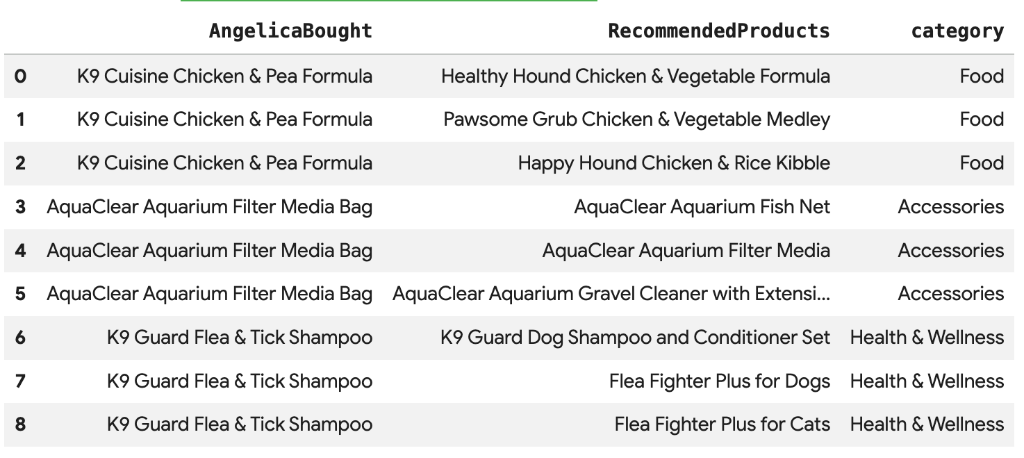
8. Recomendação de produtos usando a pesquisa vetorial
A Cymbal Pets quer recomendar produtos para Angelica com base no que ela comprou recentemente. Podemos usar a pesquisa vetorial para encontrar produtos com embeddings semelhantes às compras anteriores dela.
Execute o script SQL a seguir em uma nova célula do Colab. Este script:
- Identifica os produtos que Angelica comprou recentemente.
- Usa
VECTOR_SEARCHpara encontrar os quatro principais produtos semelhantes na tabelaproducts.
Observação: esta etapa pressupõe que você já executou AI.GENERATE_EMBEDDINGS para criar uma coluna de embeddings na tabela de produtos.
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
Você verá uma lista de produtos recomendados que são semanticamente semelhantes ao que Angelica comprou.
9. Recomendação usando "Comprados juntos" e similaridade de Jaccard
Outra técnica de recomendação poderosa é a "filtragem colaborativa", que recomenda produtos que são comprados com frequência por outros usuários.
Podemos encontrar esses produtos percorrendo o gráfico de um cliente para os produtos comprados, depois para outros clientes que compraram esses produtos e, por fim, para os outros produtos que esses clientes compraram.
Como superar o viés de popularidade com a similaridade de Jaccard
Embora as contagens brutas de compras conjuntas sejam úteis, elas podem ser tendenciosas em relação a produtos populares. Um produto muito popular pode ser comprado com muitas coisas apenas por acaso.
A similaridade de Jaccard leva as recomendações um passo adiante, normalizando a contagem de compras conjuntas. Ela mede a similaridade entre dois conjuntos (neste caso, os conjuntos de pedidos que contêm cada produto).
A fórmula para a similaridade de Jaccard é:

Em que:
- A intersect B é o número de pedidos que contêm o produto A e o produto B (contagem de compras conjuntas).
- A é o número total de pedidos que contêm o produto A.
- B é o número total de pedidos que contêm o produto B.
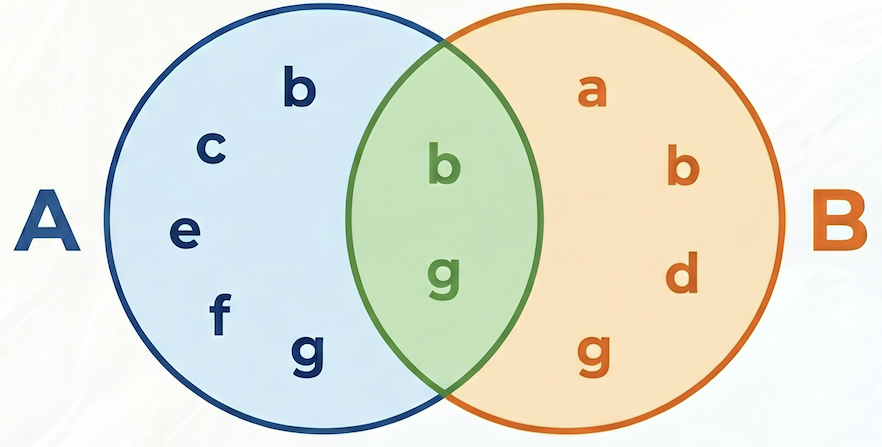
No exemplo a seguir, o conjunto A = {b,c,e,f,g}, o conjunto B = {a,d,b,g}, a interseção A⋂B = {b,g}, a união A⋃B = {a,b,c,d,e,f,g}, portanto, a similaridade de Jaccard entre A e B é 2 / 7 = 0,285714
Geração e reclassificação de candidatos
Em sistemas de recomendação do mundo real que operam em conjuntos de dados enormes, geralmente é impraticável calcular pontuações de similaridade complexas (como Jaccard) para todos os pares possíveis de produtos. Em vez disso, um padrão comum é usar uma abordagem de duas etapas:
- Geração de candidatos: use uma métrica simples e rápida (como a contagem bruta de compras conjuntas) para filtrar o espaço de pesquisa e encontrar um número gerenciável de candidatos (por exemplo, os 10 principais).
- Reclassificação: aplique uma métrica mais precisa, mas computacionalmente mais pesada (como a similaridade de Jaccard) para classificar esse pequeno conjunto de candidatos e selecionar as principais recomendações finais.
Neste codelab, vamos seguir este padrão:
- Etapa 1: execute uma consulta para encontrar os 10 principais produtos comprados juntos para cada produto, com base na contagem bruta de compras conjuntas, e armazene-os em uma tabela.
- Etapa 2: use uma consulta de gráfico para recuperar esses candidatos, classificar por similaridade de Jaccard e retornar os três principais.
[!WARNING] Desvantagem: ao filtrar a contagem bruta na etapa 1, podemos perder o "recall" de compras conjuntas altamente específicas, mas de baixa frequência. Se um produto for muito semelhante a outro, mas ambos forem comprados raramente, ele poderá não entrar nos 10 principais candidatos e será perdido.
Execute a consulta a seguir para calcular a contagem bruta de compras conjuntas e a similaridade de Jaccard e armazene os 10 principais candidatos por contagem bruta:
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
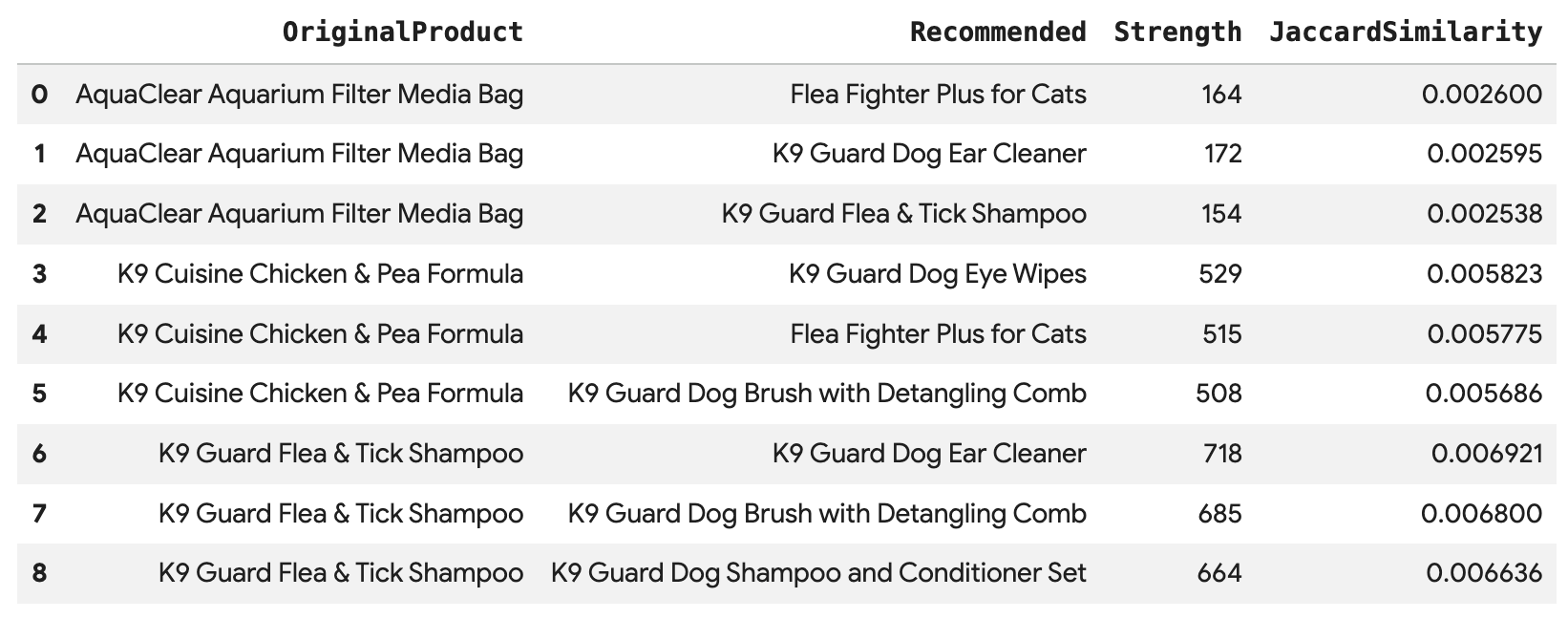
Execute esta consulta para recomendar os três principais produtos para cada compra de Angelica, conectados diretamente pela aresta BoughtTogether, mostrando a contagem de compras conjuntas e a similaridade de Jaccard:
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
Essa consulta percorre o caminho Cliente -> Pedido -> Produto -> (Comprados juntos) -> Produto recomendado, mostrando recomendações com base no comportamento de compra coletivo e recupera as pontuações de similaridade.
10. Limpar
Para evitar cobranças contínuas na sua conta do Google Cloud, exclua os recursos criados durante este codelab.
Exclua o conjunto de dados e todas as tabelas:
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
Se você criou um novo projeto para este codelab, também poderá excluí-lo:
gcloud projects delete $PROJECT_ID
11. Parabéns
Parabéns! Você criou uma visualização do Cliente 360 e um mecanismo de recomendação usando o BigQuery Graph.
O que você aprendeu
- Como criar um gráfico de propriedades no BigQuery.
- Como carregar dados em nós e arestas de gráficos.
- Como consultar padrões de gráficos usando
GRAPH_TABLEeMATCH. - Como combinar consultas de gráficos com a pesquisa vetorial para recomendações híbridas.
Próximas etapas
- Confira a documentação do BigQuery Graph.
- Saiba mais sobre a pesquisa vetorial no BigQuery.