
1. Introducción
En este codelab, aprenderás a usar BigQuery Graph para crear una visión global de los clientes y un motor de recomendaciones para Cymbal Pets, una empresa de venta minorista ficticia. Aprovecharás el poder de SQL para crear, consultar y analizar datos de grafos directamente en BigQuery, combinándolos con la búsqueda de vectores para obtener recomendaciones de productos avanzadas.
BigQuery Graph te permite modelar las relaciones entre tus entidades de datos (como clientes, productos y pedidos) como un grafo, lo que facilita responder preguntas complejas sobre el comportamiento de los clientes y las afinidades de los productos.

Actividades
- Crea un conjunto de datos y un esquema de BigQuery para el grafo de Cymbal Pets.
- Carga datos de muestra (clientes, productos, pedidos, tiendas) desde Cloud Storage.
- Crea un grafo de propiedades en BigQuery que conecte estas entidades.
- Visualiza el historial de compras de los clientes con consultas de grafos.
- Compila un sistema de recomendación de productos con la búsqueda de vectores.
- Mejora las recomendaciones con las relaciones de grafos "Comprados juntos" y la similitud de Jaccard.
Requisitos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con la facturación habilitada.
Este codelab está dirigido a desarrolladores de todos los niveles, incluidos principiantes.
2. Antes de comenzar
Cómo crear un proyecto de Google Cloud
- En la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud.
Inicie Cloud Shell
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Verifica la autenticación:
gcloud auth list
- Confirma tu proyecto:
gcloud config get project
- Configúralo si es necesario:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Habilita las APIs
Ejecuta este comando para habilitar la API de BigQuery requerida:
gcloud services enable bigquery.googleapis.com
3. Define el esquema
Primero, debes crear un conjunto de datos para almacenar tus tablas relacionadas con el grafo y definir el esquema de tus nodos y aristas.
- Para este codelab, ejecutaremos comandos de SQL. Puedes ejecutar estos comandos en el BigQuery Studio > Editor de SQL o usar el comando
bq queryen Cloud Shell. Supondremos que usas el Editor de SQL de BigQuery para obtener una mejor experiencia con las instrucciones de creación de varias líneas.
Supondremos que usas el Editor de SQL de BigQuery para obtener una mejor experiencia con las instrucciones de creación de varias líneas. - Crea el conjunto de datos
cymbal_pets_demo:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- Crea las tablas para
order_items,products,orders,stores,customersyco_related_products_for_angelica. Estas tablas servirán como datos de origen para nuestro grafo.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
Ahora definiste la estructura de tus datos de grafos.
4. Carga los datos
Ahora, propaga las tablas con datos de muestra de Cloud Storage.
Ejecuta las siguientes instrucciones LOAD DATA en el editor de SQL de BigQuery:
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
Deberías ver un mensaje de confirmación que indica que se cargaron filas en cada tabla.
5. Crea el grafo de propiedades
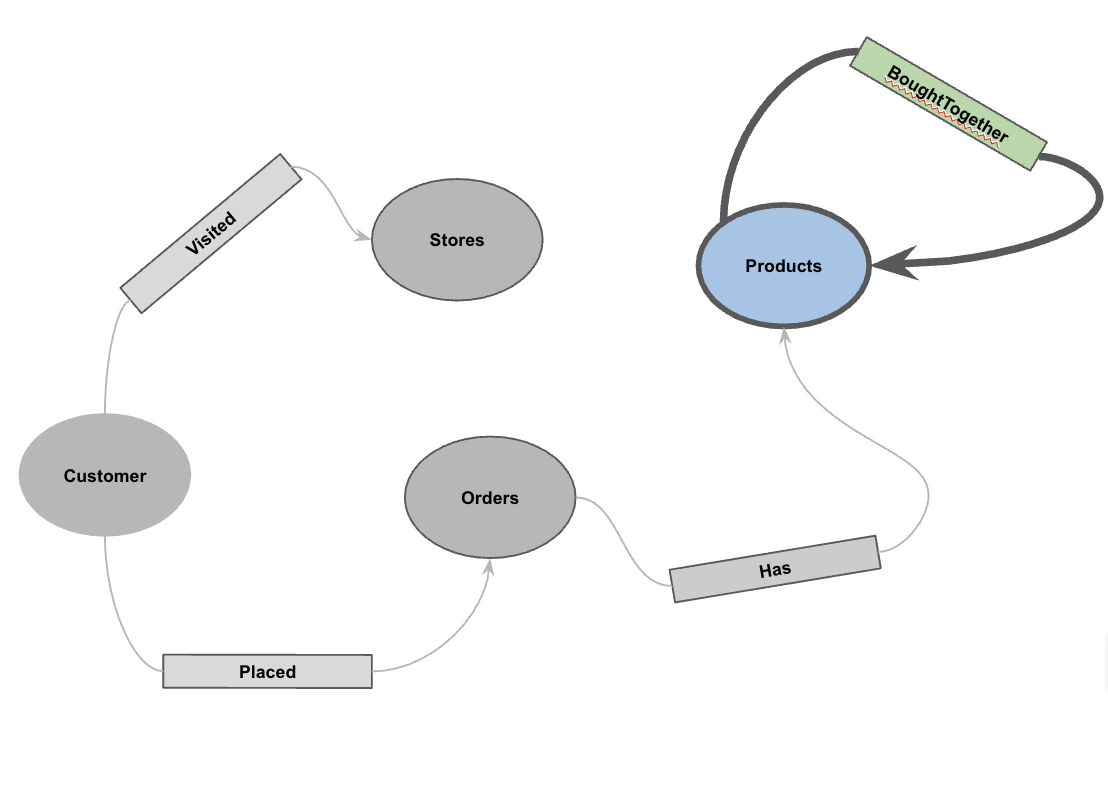
Con los datos cargados, ahora puedes definir el grafo de propiedades. Esto le indica a BigQuery qué tablas representan nodos (entidades como clientes y productos) y qué tablas representan aristas (relaciones como "Visitó", "Realizó" y "Tiene").
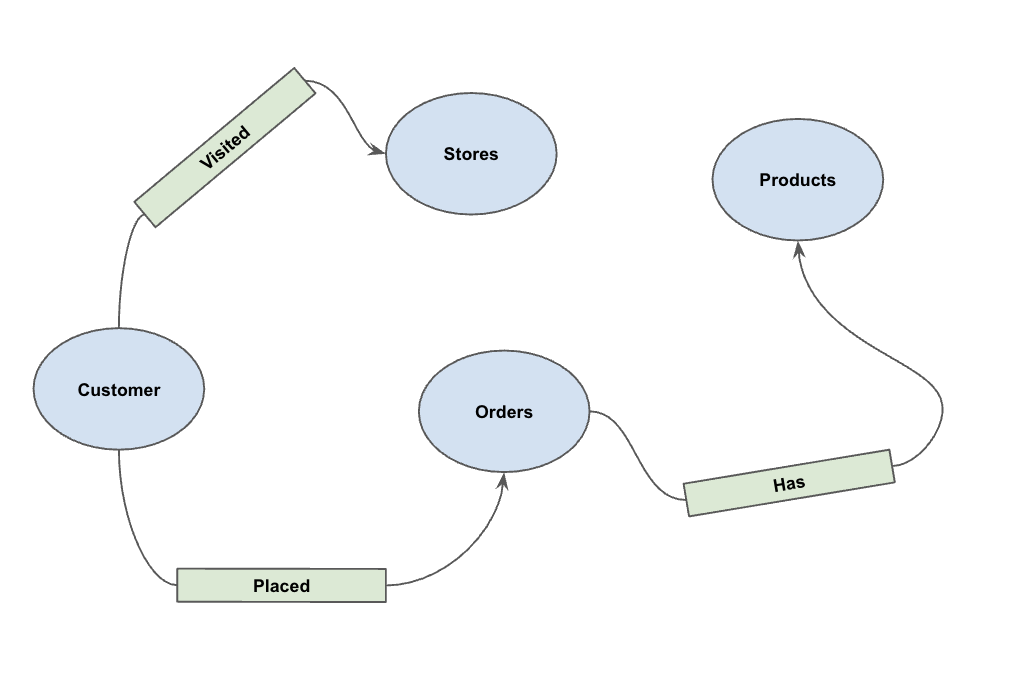
Ejecuta la siguiente sentencia de DDL:
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
Esto crea el grafo PetsOrderGraph, que nos permite realizar recorridos de grafos con el operador GRAPH_TABLE.
6. Visualiza el historial de compras de todos los clientes
Para las partes de visualización y recomendación de este codelab, usaremos la visualización de grafos nativa en BigQuery Studio. Esto nos permite visualizar fácilmente los resultados del grafo.
Como alternativa, puedes visualizar en BigQuery Graph Notebook con IPython Magics. Si agregas el comando mágico %%bigquery con la función TO_JSON, puedes visualizar los resultados como se muestra en las siguientes secciones.
Supongamos que Cymbal Pets quiere obtener una visualización de 360 grados de todos los clientes y las compras que realizaron en un período específico.
Ejecuta lo siguiente en una nueva pestaña de BigQuery Studio:
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
Para visualizar los resultados, en el panel Resultados de la consulta, haz clic en Gráfico.

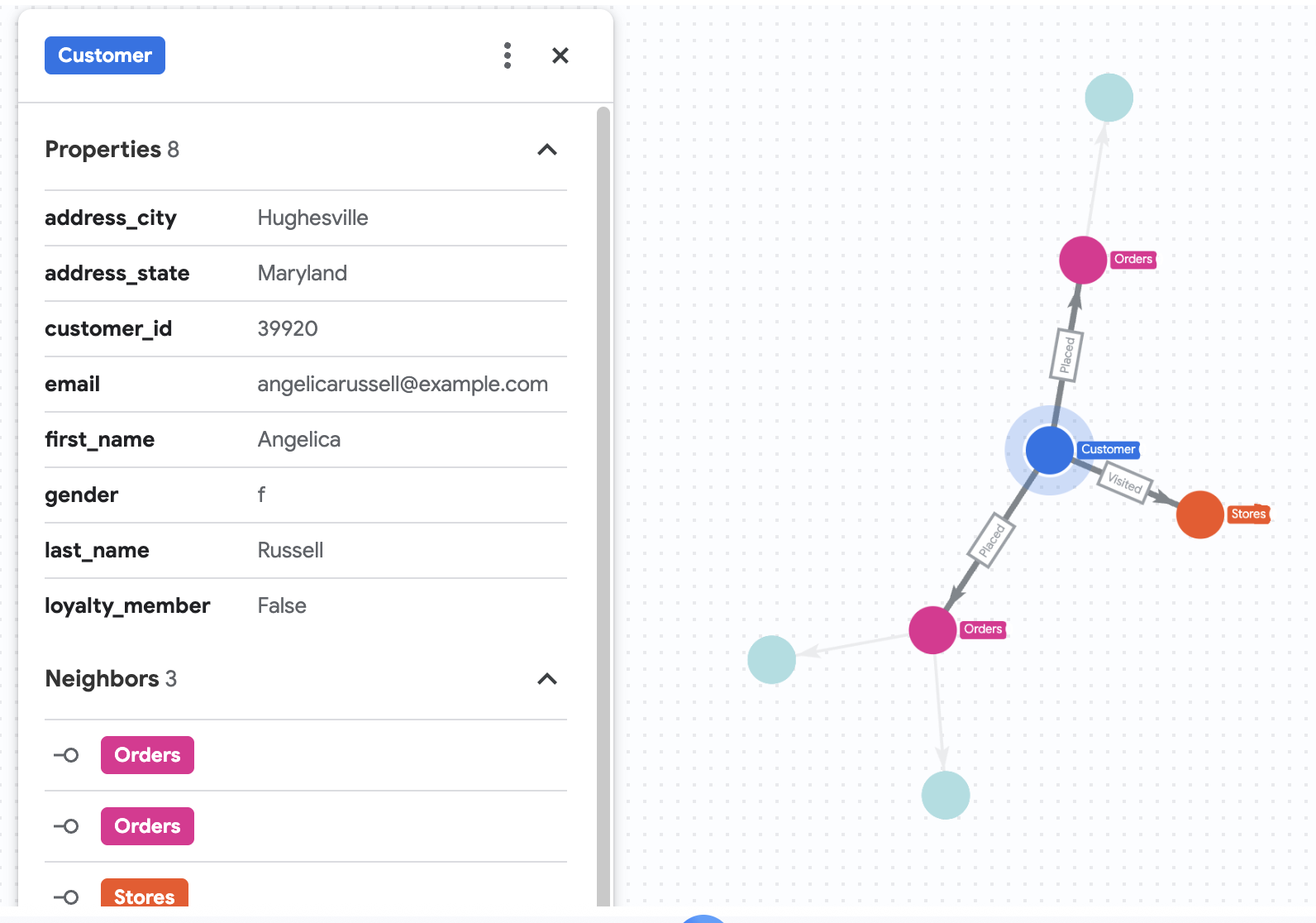
7. Visualiza el historial de compras de Angelica
Supongamos que Cymbal Pets quiere profundizar en un cliente llamado Angelica Russell. Quieren analizar los productos que compró Angelica en los últimos 3 meses y las tiendas que visitó la clienta.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
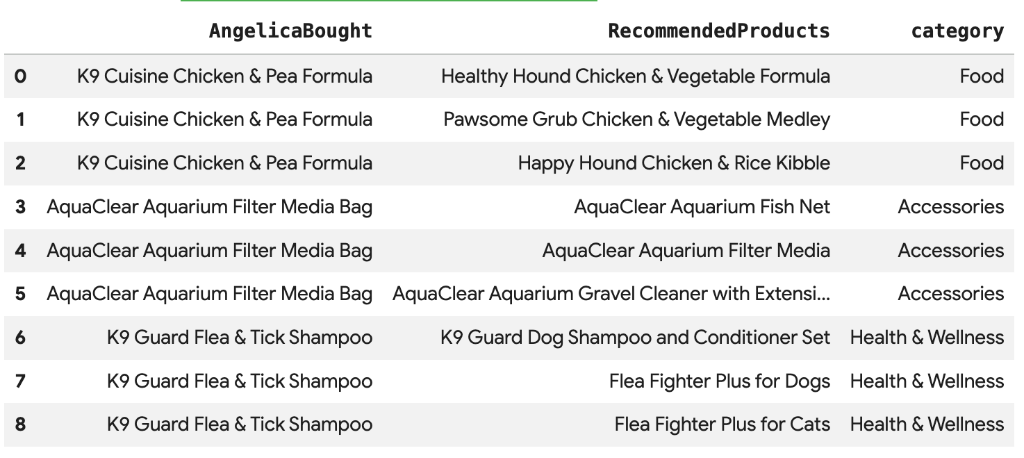
8. Recomendación de productos con la búsqueda de vectores
Cymbal Pets quiere recomendar productos a Angelica en función de lo que compró recientemente. Podemos usar la búsqueda de vectores para encontrar productos con incorporaciones similares a sus compras anteriores.
Ejecuta la siguiente secuencia de comandos de SQL en una celda nueva de Colab. Esta secuencia de comandos hace lo siguiente:
- Identifica los productos que compró Angelica recientemente.
- Usa
VECTOR_SEARCHpara encontrar los 4 productos similares principales de la tablaproducts.
Nota: En este paso, se supone que ya ejecutaste AI.GENERATE_EMBEDDINGS para crear una columna de incorporaciones en la tabla de productos.
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
Deberías ver una lista de productos recomendados que son semánticamente similares a lo que compró Angelica.
9. Recomendación con "Comprados juntos" y la similitud de Jaccard
Otra técnica de recomendación potente es el "filtrado colaborativo", que recomienda productos que otros usuarios compran con frecuencia juntos.
Para encontrar estos productos, podemos recorrer el grafo desde un cliente hasta los productos que compró, luego a otros clientes que compraron esos productos y, por último, a los otros productos que compraron esos clientes.
Cómo superar el sesgo de popularidad con la similitud de Jaccard
Si bien los recuentos de compras conjuntas sin procesar son útiles, pueden estar sesgados hacia los productos populares. Un producto muy popular podría comprarse con muchas cosas solo por casualidad.
La similitud de Jaccard lleva las recomendaciones un paso más allá, ya que normaliza el recuento de compras conjuntas. Mide la similitud entre dos conjuntos (en este caso, los conjuntos de pedidos que contienen cada producto).
La fórmula para la similitud de Jaccard es la siguiente:

Donde:
- A intersect B es la cantidad de pedidos que contienen el producto A y el producto B (recuento de compras conjuntas).
- A es la cantidad total de pedidos que contienen el producto A.
- B es la cantidad total de pedidos que contienen el producto B.
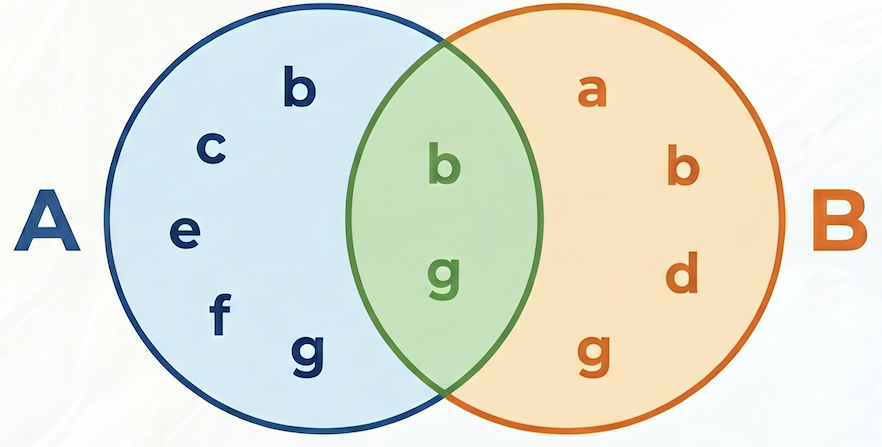
En el siguiente ejemplo, el conjunto A = {b,c,e,f,g}, el conjunto B = {a,d,b,g}, su intersección A⋂B = {b,g}, su unión A⋃B = {a,b,c,d,e,f,g}, por lo que la similitud de Jaccard entre A y B es 2 / 7 = 0.285714
Generación de candidatos y nueva clasificación
En los sistemas de recomendación del mundo real que operan en conjuntos de datos masivos, a menudo no es práctico calcular puntuaciones de similitud complejas (como Jaccard) para todos los pares de productos posibles. En cambio, un patrón común es usar un enfoque de dos etapas:
- Generación de candidatos: Usa una métrica simple y rápida (como el recuento de compras conjuntas sin procesar) para filtrar el espacio de búsqueda y encontrar una cantidad manejable de candidatos (p.ej., los 10 principales).
- Nueva clasificación: Aplica una métrica más precisa, pero más pesada desde el punto de vista computacional (como la similitud de Jaccard), para clasificar ese pequeño conjunto de candidatos y seleccionar las recomendaciones principales finales.
En este codelab, seguiremos este patrón:
- Etapa 1: Ejecuta una consulta para encontrar los 10 productos principales comprados juntos para cada producto, según el recuento de compras conjuntas sin procesar, y almacénalos en una tabla.
- Etapa 2: Usa una consulta de grafos para recuperar estos candidatos, clasificarlos por similitud de Jaccard y mostrar los 3 principales.
[!WARNING] Desventaja: Si filtras por recuento sin procesar en la etapa 1, es posible que perdamos la "recuperación" de las compras conjuntas muy específicas, pero de baja frecuencia. Si un producto es muy similar a otro, pero ambos se compran con poca frecuencia, es posible que no llegue a los 10 candidatos principales y se pierda.
Ejecuta la siguiente consulta para calcular el recuento de compras conjuntas sin procesar y la similitud de Jaccard, y almacena los 10 candidatos principales por recuento sin procesar:
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
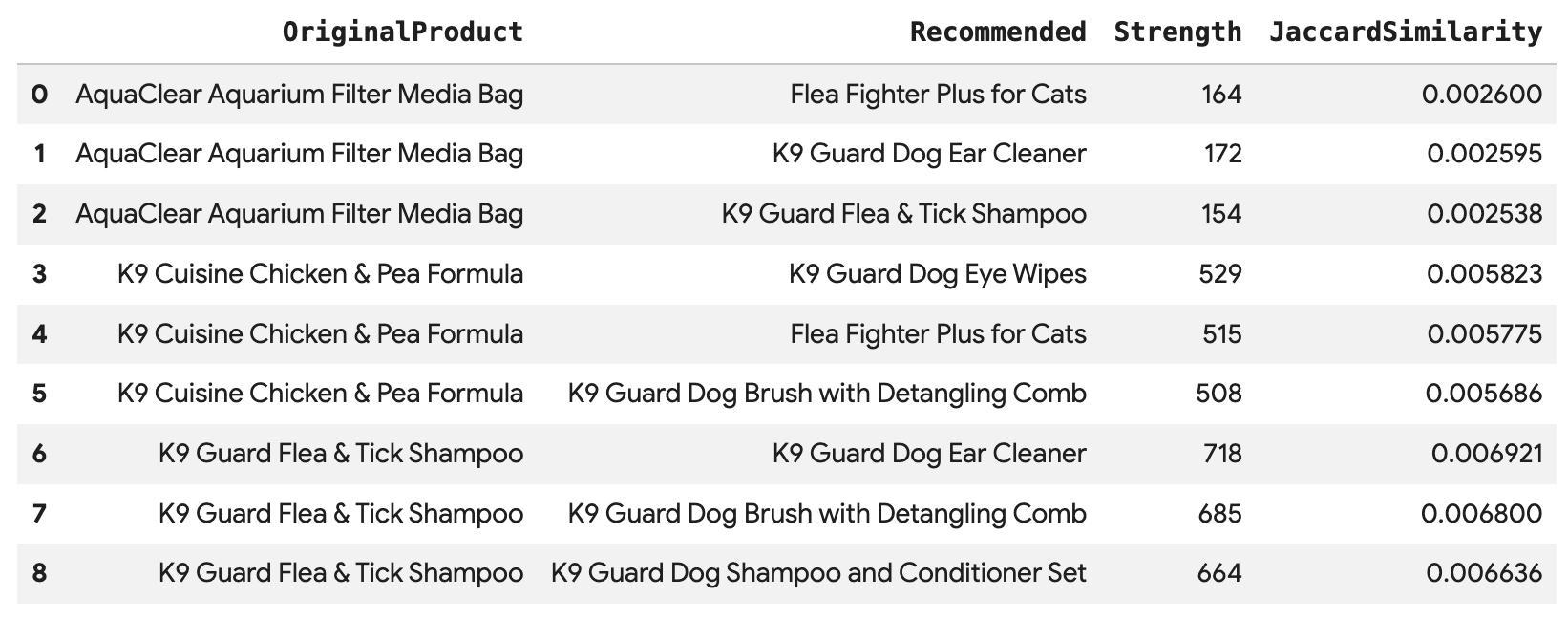
Ejecuta esta consulta para recomendar los 3 productos principales para cada una de las compras de Angelica, conectados directamente a través de la arista BoughtTogether, que muestra el recuento de compras conjuntas y la similitud de Jaccard:
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
Esta consulta recorre Cliente -> Pedido -> Producto -> (Comprados juntos) -> Producto recomendado, lo que te muestra recomendaciones basadas en el comportamiento de compra colectivo y recupera sus puntuaciones de similitud.
10. Limpia
Para evitar cargos continuos en tu cuenta de Google Cloud, borra los recursos creados durante este codelab.
Borra el conjunto de datos y todas las tablas:
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
Si creaste un proyecto nuevo para este codelab, también puedes borrarlo:
gcloud projects delete $PROJECT_ID
11. Felicitaciones
¡Felicitaciones! Creaste correctamente una visión global de los clientes y un motor de recomendaciones con BigQuery Graph.
Qué aprendiste
- Cómo crear un grafo de propiedades en BigQuery
- Cómo cargar datos en nodos y aristas de grafos
- Cómo consultar patrones de grafos con
GRAPH_TABLEyMATCH - Cómo combinar consultas de grafos con la búsqueda de vectores para obtener recomendaciones híbridas
Próximos pasos
- Explora la documentación de BigQuery Graph.
- Obtén más información sobre la búsqueda de vectores en BigQuery.