
1. Introduzione
In questo codelab imparerai a utilizzare BigQuery Graph per creare una visualizzazione a 360° del cliente e un motore per suggerimenti per Cymbal Pets, un'azienda di vendita al dettaglio fittizia. Sfrutterai la potenza di SQL per creare, eseguire query e analizzare i dati dei grafici direttamente in BigQuery, combinandoli con la ricerca vettoriale per suggerimenti avanzati sui prodotti.
BigQuery Graph ti consente di modellare le relazioni tra le entità dei dati (come clienti, prodotti e ordini) come un grafico, semplificando la risposta a domande complesse sul comportamento dei clienti e sulle affinità dei prodotti.

In questo lab proverai a:
- Creare un set di dati e uno schema BigQuery per il grafico di Cymbal Pets
- Caricare dati di esempio (clienti, prodotti, ordini, negozi) da Cloud Storage
- Creare un grafico a proprietà in BigQuery che colleghi queste entità
- Visualizzare la cronologia degli acquisti dei clienti utilizzando le query sui grafici
- Creare un sistema di suggerimenti sui prodotti utilizzando la ricerca vettoriale
- Migliorare i suggerimenti utilizzando le relazioni dei grafici "Acquistati insieme" e la similarità di Jaccard
Che cosa ti serve
- Un browser web come Chrome
- Un progetto cloud Google Cloud con la fatturazione abilitata
Questo codelab è rivolto a sviluppatori di tutti i livelli, inclusi i principianti.
2. Prima di iniziare
Crea un progetto Google Cloud
- Nella console Google Cloud, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud.
Avvia Cloud Shell
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
- Verifica l'autenticazione:
gcloud auth list
- Conferma il progetto:
gcloud config get project
- Impostalo se necessario:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Abilita API
Esegui questo comando per abilitare l'API BigQuery richiesta:
gcloud services enable bigquery.googleapis.com
3. Definisci lo schema
Innanzitutto, devi creare un set di dati per archiviare le tabelle correlate ai grafici e definire lo schema per nodi e bordi.
- Per questo codelab, eseguiremo i comandi SQL. Puoi eseguire questi comandi in BigQuery Studio > Editor SQL oppure utilizzare il
bq querycomando in Cloud Shell. Supponiamo che tu stia utilizzando l'editor SQL di BigQuery per un'esperienza migliore con le istruzioni di creazione su più righe.
Supponiamo che tu stia utilizzando l'editor SQL di BigQuery per un'esperienza migliore con le istruzioni di creazione su più righe. - Crea il set di dati
cymbal_pets_demo:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- Crea le tabelle per
order_items,products,orders,stores,customerseco_related_products_for_angelica. Queste tabelle fungeranno da dati di origine per il nostro grafico.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
Ora hai definito la struttura dei dati del grafico.
4. Carica i dati
Ora, popola le tabelle con dati di esempio da Cloud Storage.
Esegui le seguenti istruzioni LOAD DATA nell'editor SQL di BigQuery:
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
Dovresti vedere una conferma che le righe sono state caricate in ogni tabella.
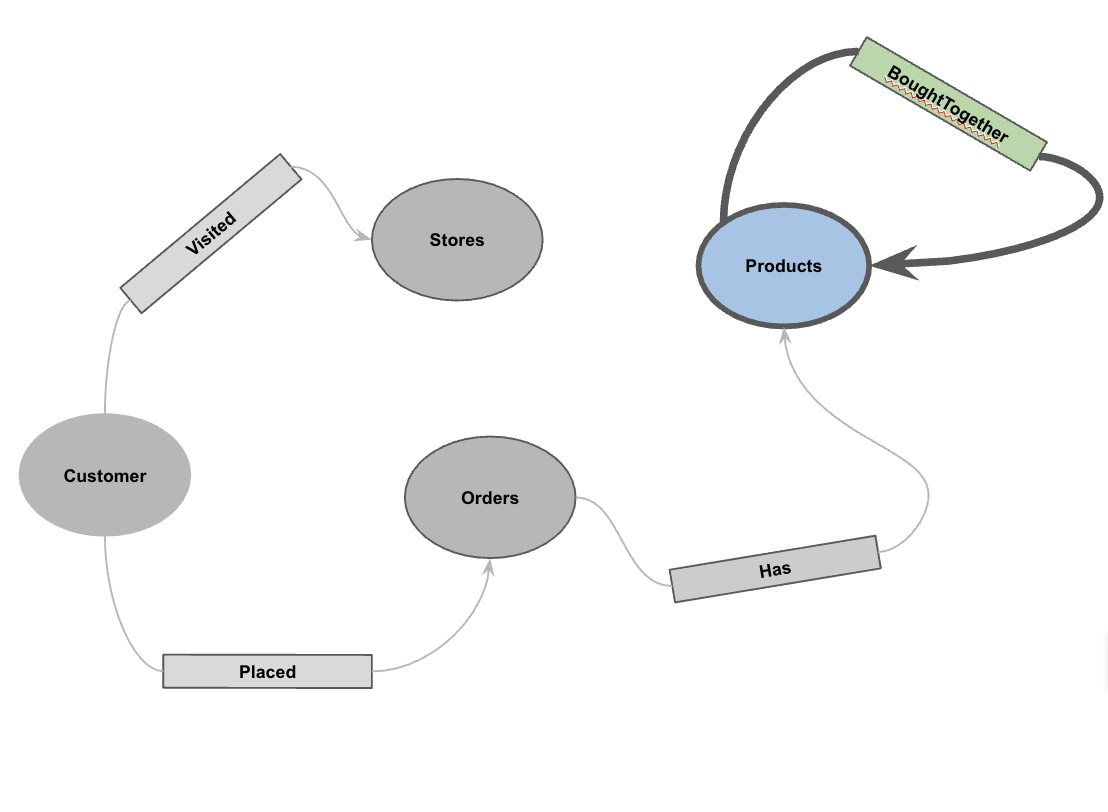
5. Crea il grafico a proprietà
Dopo aver caricato i dati, puoi definire il grafico a proprietà. In questo modo, BigQuery sa quali tabelle rappresentano i nodi (entità come clienti, prodotti) e quali tabelle rappresentano i bordi (relazioni come "Visitato", "Inserito", "Ha").
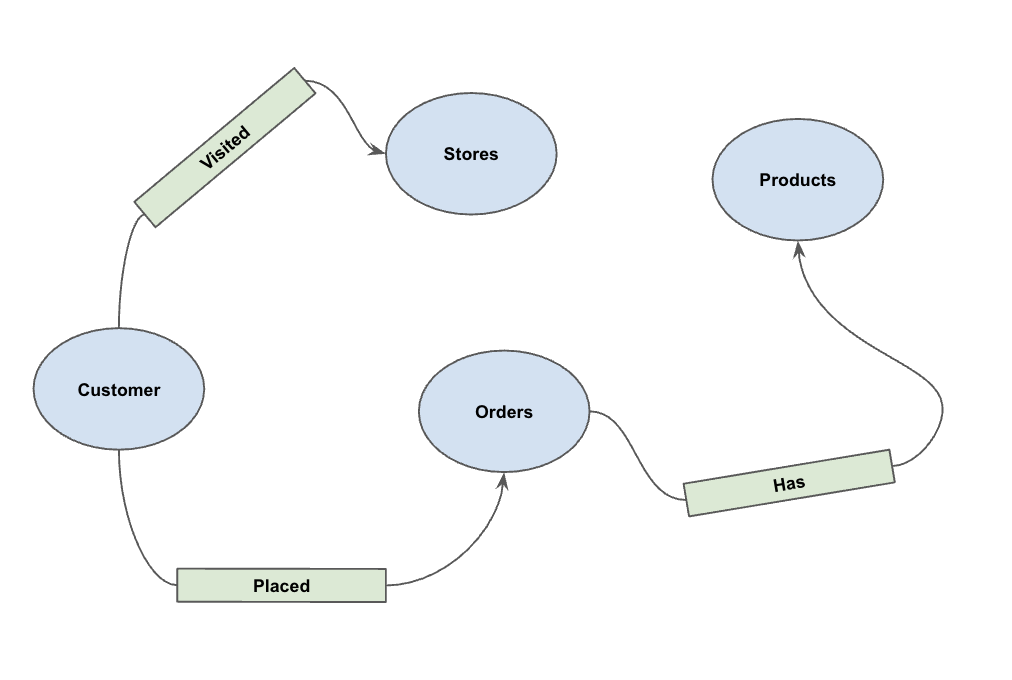
Esegui la seguente istruzione DDL:
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
In questo modo viene creato il grafico PetsOrderGraph, che ci consente di eseguire attraversamenti di grafici utilizzando l'operatore GRAPH_TABLE.
6. Visualizza la cronologia degli acquisti di tutti i clienti
Per le parti di visualizzazione e suggerimenti di questo codelab, utilizzeremo la visualizzazione dei grafici nativa in BigQuery Studio. In questo modo, possiamo visualizzare facilmente i risultati del grafico.
In alternativa, puoi visualizzare i risultati in BigQuery Graph Notebook utilizzando i comandi magici IPython. Aggiungendo il comando magico %%bigquery con la funzione TO_JSON, puoi visualizzare i risultati come mostrato nelle sezioni seguenti.
Supponiamo che Cymbal Pets voglia ottenere una visualizzazione a 360° di tutti i clienti e degli acquisti effettuati in una finestra temporale specifica.
Esegui quanto segue in una nuova scheda di BigQuery Studio:
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
Per visualizzare i risultati, fai clic su Grafico nel riquadro Risultati delle query.

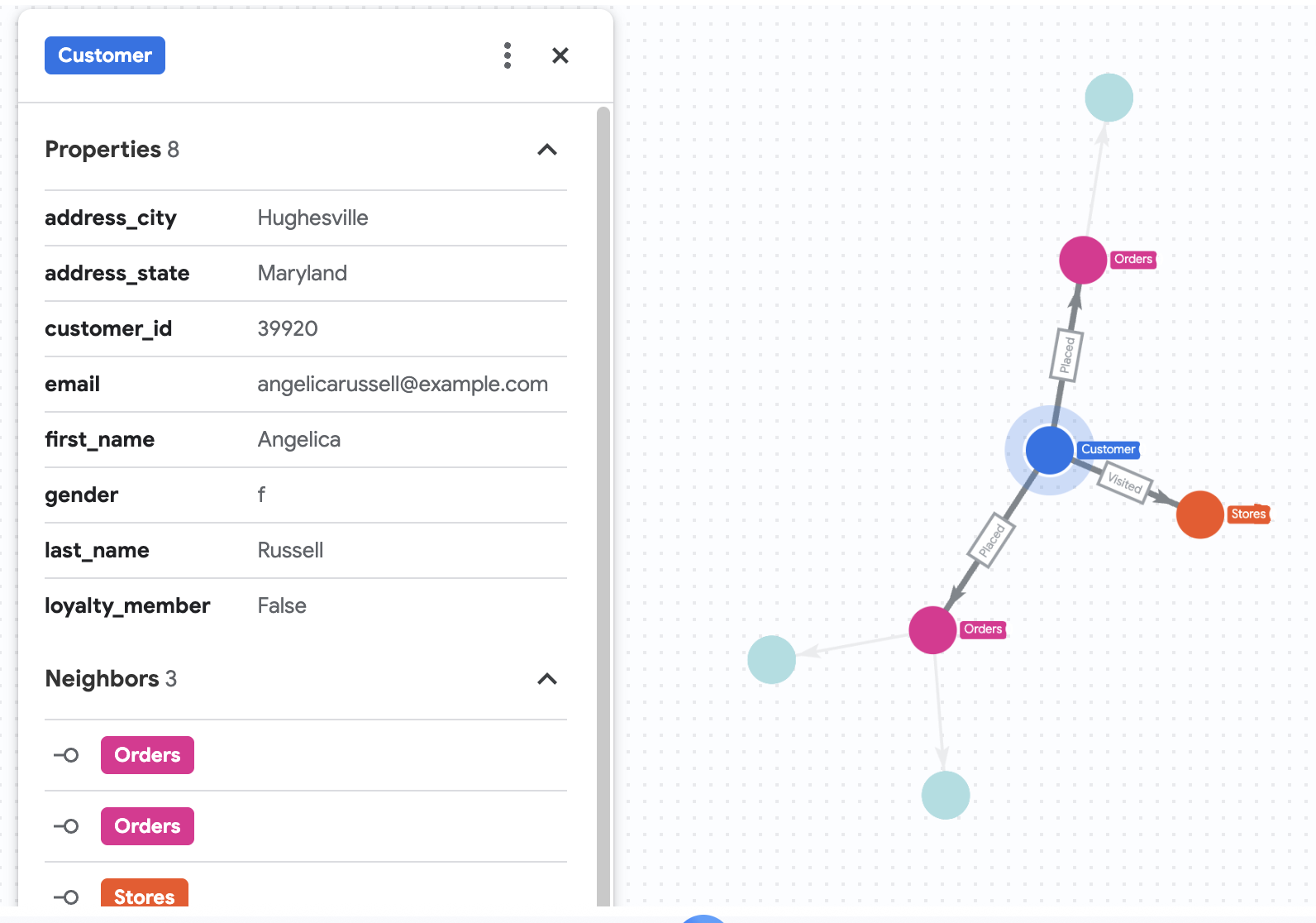
7. Visualizza la cronologia degli acquisti di Angelica
Supponiamo che Cymbal Pets voglia approfondire un cliente di nome Angelica Russell. Vuole analizzare i prodotti acquistati da Angelica negli ultimi 3 mesi e i negozi visitati dal cliente.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
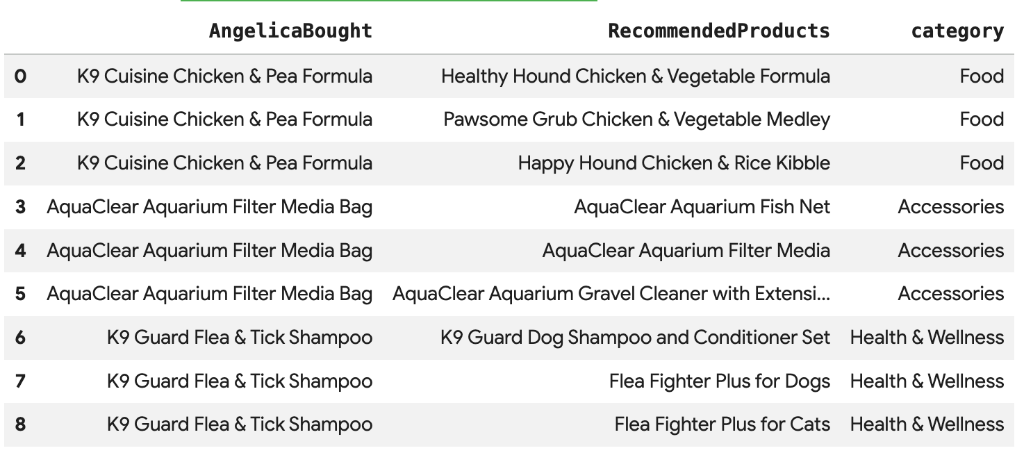
8. Suggerimenti sui prodotti utilizzando la ricerca vettoriale
Cymbal Pets vuole consigliare i prodotti ad Angelica in base a ciò che ha acquistato di recente. Possiamo utilizzare la ricerca vettoriale per trovare prodotti con embedding simili ai suoi acquisti passati.
Esegui il seguente script SQL in una nuova cella di Colab. Questo script:
- Identifica i prodotti acquistati di recente da Angelica.
- Utilizza
VECTOR_SEARCHper trovare i primi 4 prodotti simili dalla tabellaproducts.
Nota: questo passaggio presuppone che tu abbia già eseguito AI.GENERATE_EMBEDDINGS per creare una colonna di embedding nella tabella dei prodotti.
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
Dovresti vedere un elenco di prodotti consigliati semanticamente simili a quelli acquistati da Angelica.
9. Suggerimenti utilizzando "Acquistati insieme" e la similarità di Jaccard
Un'altra potente tecnica di suggerimento è il "filtraggio collaborativo", che consiste nel consigliare i prodotti acquistati spesso insieme da altri utenti.
Possiamo trovare questi prodotti attraversando il grafico da un cliente ai prodotti acquistati, poi ad altri clienti che hanno acquistato questi prodotti e infine agli altri prodotti acquistati da questi clienti.
Superare il bias di popolarità con la similarità di Jaccard
Sebbene i conteggi degli acquisti congiunti non elaborati siano utili, possono essere influenzati dai prodotti più diffusi. Un prodotto molto popolare potrebbe essere acquistato con molte cose per caso.
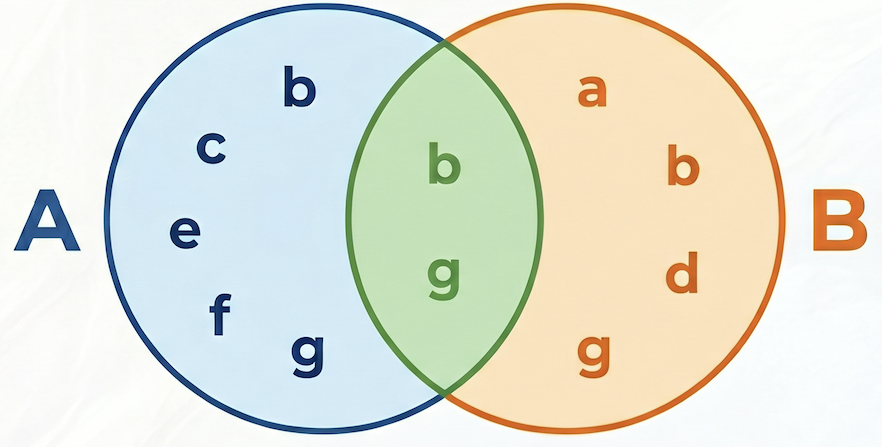
La similarità di Jaccard porta i suggerimenti un passo avanti normalizzando il conteggio degli acquisti congiunti. Misura la similarità tra due insiemi (in questo caso, gli insiemi di ordini contenenti ogni prodotto).
La formula per la similarità di Jaccard è:

Dove:
- A intersect B è il numero di ordini contenenti sia il prodotto A sia il prodotto B (conteggio degli acquisti congiunti).
- A è il numero totale di ordini contenenti il prodotto A.
- B è il numero totale di ordini contenenti il prodotto B.
Nell'esempio seguente, l'insieme A = {b,c,e,f,g}, l'insieme B = {a,d,b,g}, la loro intersezione A⋂B = {b,g}, la loro unione A⋃B = {a,b,c,d,e,f,g}, quindi la similarità di Jaccard tra A e B è 2 / 7 = 0,285714
Generazione e riordinamento dei candidati
Nei sistemi di suggerimenti reali che operano su set di dati di grandi dimensioni, spesso non è pratico calcolare punteggi di similarità complessi (come Jaccard) per tutte le possibili coppie di prodotti. Invece, un pattern comune è utilizzare un approccio a due fasi:
- Generazione dei candidati: utilizza una metrica semplice e veloce (come il conteggio degli acquisti congiunti non elaborati) per filtrare lo spazio di ricerca e trovare un numero gestibile di candidati (ad es. i primi 10).
- Riordinamento: applica una metrica più precisa, ma più pesante dal punto di vista computazionale (come la similarità di Jaccard) per classificare questo piccolo insieme di candidati e selezionare i primi suggerimenti finali.
In questo codelab seguiremo questo pattern:
- Fase 1: esegui una query per trovare i primi 10 prodotti acquistati congiuntamente per ogni prodotto, in base al conteggio degli acquisti congiunti non elaborati, e archiviali in una tabella.
- Fase 2: utilizza una query sui grafici per recuperare questi candidati, classificarli in base alla similarità di Jaccard e restituire i primi 3.
[!WARNING] Svantaggio: filtrando in base al conteggio non elaborato nella fase 1, potremmo perdere il "richiamo" degli acquisti congiunti altamente specifici ma a bassa frequenza. Se un prodotto è molto simile a un altro, ma entrambi vengono acquistati raramente, potrebbe non rientrare nei primi 10 candidati e verrà perso.
Esegui la seguente query per calcolare sia il conteggio degli acquisti congiunti non elaborati sia la similarità di Jaccard e archiviare i primi 10 candidati in base al conteggio non elaborato:
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
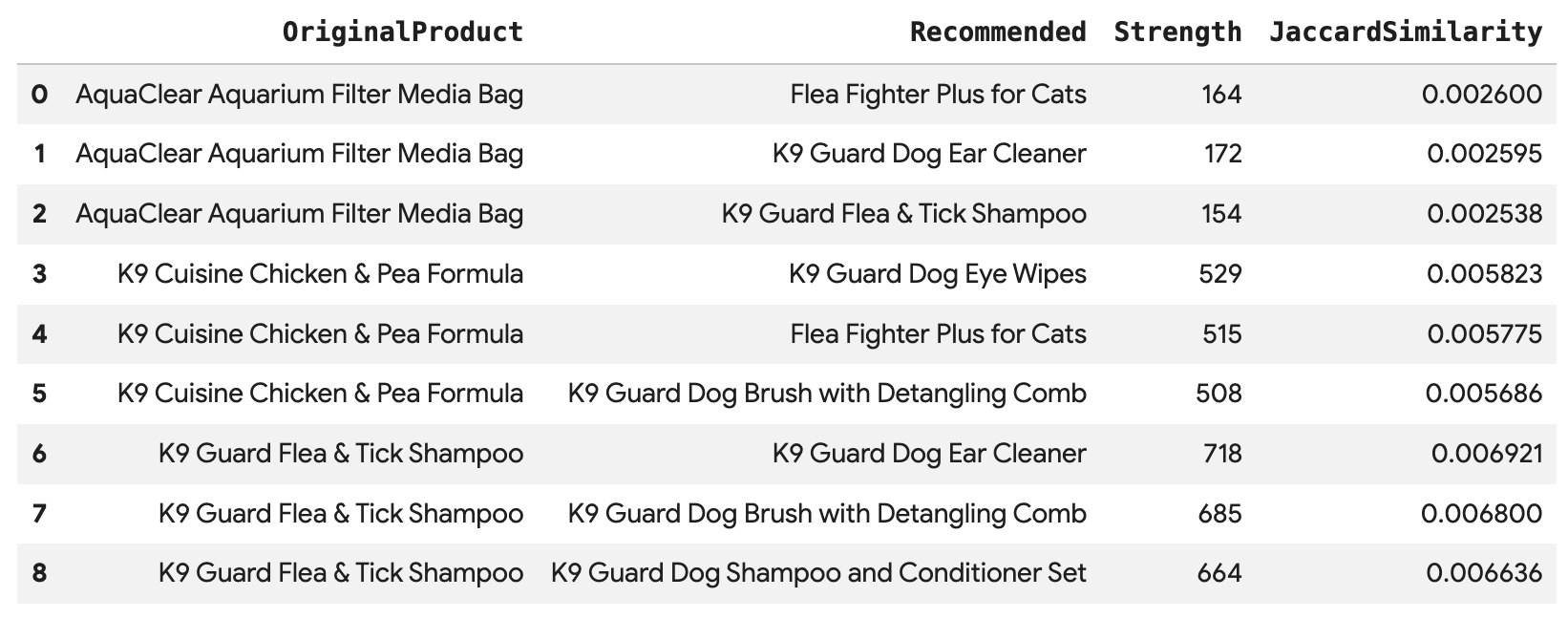
Esegui questa query per consigliare i primi 3 prodotti per ogni acquisto di Angelica, collegati direttamente tramite il bordo BoughtTogether, mostrando sia il conteggio degli acquisti congiunti sia la similarità di Jaccard:
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
Questa query attraversa da Cliente -> Ordine -> Prodotto -> (Acquistati insieme) -> Prodotto consigliato, mostrando i suggerimenti in base al comportamento di acquisto collettivo e recuperando i relativi punteggi di similarità.
10. Libera spazio
Per evitare addebiti continui sul tuo account Google Cloud, elimina le risorse create durante questo codelab.
Elimina il set di dati e tutte le tabelle:
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
Se hai creato un nuovo progetto per questo codelab, puoi anche eliminarlo:
gcloud projects delete $PROJECT_ID
11. Complimenti
Complimenti! Hai creato correttamente una visualizzazione a 360° del cliente e un motore per suggerimenti utilizzando BigQuery Graph.
Che cosa hai imparato
- Come creare un grafico a proprietà in BigQuery.
- Come caricare i dati nei nodi e nei bordi del grafico.
- Come eseguire query sui pattern dei grafici utilizzando
GRAPH_TABLEeMATCH. - Come combinare le query sui grafici con la ricerca vettoriale per suggerimenti ibridi.
Passaggi successivi
- Esplora la documentazione di BigQuery Graph.
- Scopri di più sulla ricerca vettoriale in BigQuery.