
1. 소개
이 Codelab에서는 BigQuery 그래프를 사용하여 가상의 소매 회사인 Cymbal Pets를 위한 다각적인 고객 파악 뷰와 추천 엔진을 빌드하는 방법을 알아봅니다. SQL의 기능을 활용하여 BigQuery 내에서 직접 그래프 데이터를 만들고, 쿼리하고, 분석하고, 벡터 검색과 결합하여 고급 제품 추천을 구현합니다.
BigQuery 그래프를 사용하면 고객, 제품, 주문과 같은 데이터 항목 간의 관계를 그래프로 모델링하여 고객 행동 및 제품 선호도에 관한 복잡한 질문에 쉽게 답할 수 있습니다.

실습할 내용
- Cymbal Pets 그래프의 BigQuery 데이터 세트 및 스키마 만들기
- Cloud Storage에서 샘플 데이터 (고객, 제품, 주문, 매장) 로드
- 이러한 항목을 연결하는 BigQuery의 속성 그래프 만들기
- 그래프 쿼리를 사용하여 고객 구매 내역 시각화
- 벡터 검색을 사용하여 제품 추천 시스템 빌드
- '함께 구매한 상품' 그래프 관계 및 Jaccard 유사성을 사용하여 추천 개선
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트
이 Codelab은 초보자를 포함한 모든 수준의 개발자를 대상으로 합니다.
2. 시작하기 전에
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다.
Cloud Shell 시작
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.
- 인증을 확인합니다.
gcloud auth list
- 프로젝트를 확인합니다.
gcloud config get project
- 필요한 경우 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API 사용 설정
다음 명령어를 실행하여 필요한 BigQuery API를 사용 설정합니다.
gcloud services enable bigquery.googleapis.com
3. 스키마 정의
먼저 그래프 관련 테이블을 저장할 데이터 세트를 만들고 노드와 에지의 스키마를 정의해야 합니다.
- 이 Codelab에서는 SQL 명령어를 실행합니다. BigQuery Studio > SQL 편집기에서 이러한 명령어를 실행하거나 Cloud Shell에서
bq query명령어를 사용할 수 있습니다. 여러 줄로 된 생성 문을 더 효과적으로 사용하려면 BigQuery SQL 편집기를 사용하는 것이 좋습니다.
여러 줄로 된 생성 문을 더 효과적으로 사용하려면 BigQuery SQL 편집기를 사용하는 것이 좋습니다. cymbal_pets_demo데이터 세트를 만듭니다.
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
order_items,products,orders,stores,customers,co_related_products_for_angelica의 테이블을 만듭니다. 이 테이블은 그래프의 소스 데이터로 사용됩니다.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
이제 그래프 데이터의 구조를 정의했습니다.
4. 데이터 로드
이제 Cloud Storage의 샘플 데이터로 테이블을 채웁니다.
BigQuery SQL 편집기에서 다음 LOAD DATA 문을 실행합니다.
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
각 테이블에 행이 로드되었다는 확인 메시지가 표시됩니다.
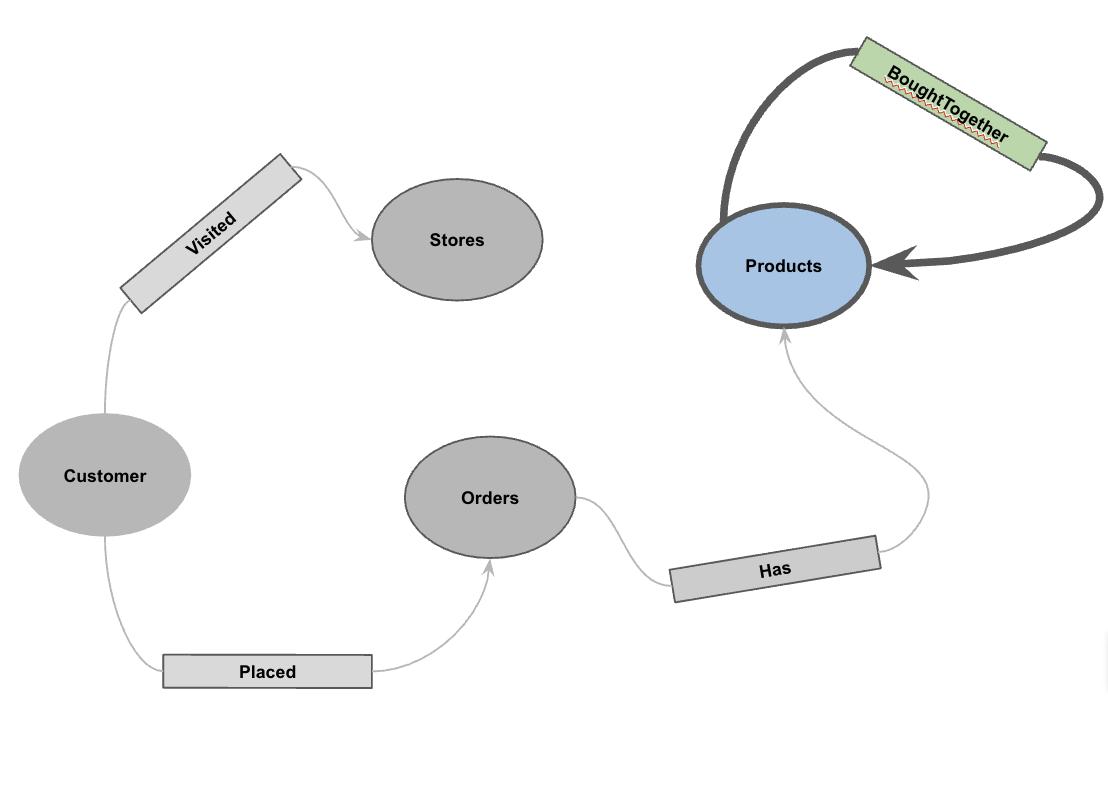
5. 속성 그래프 만들기
데이터가 로드되면 이제 속성 그래프를 정의할 수 있습니다. 이를 통해 BigQuery는 노드 (고객, 제품과 같은 항목)를 나타내는 테이블과 에지('방문함', '배치됨', '보유함'과 같은 관계)를 나타내는 테이블을 구분할 수 있습니다.
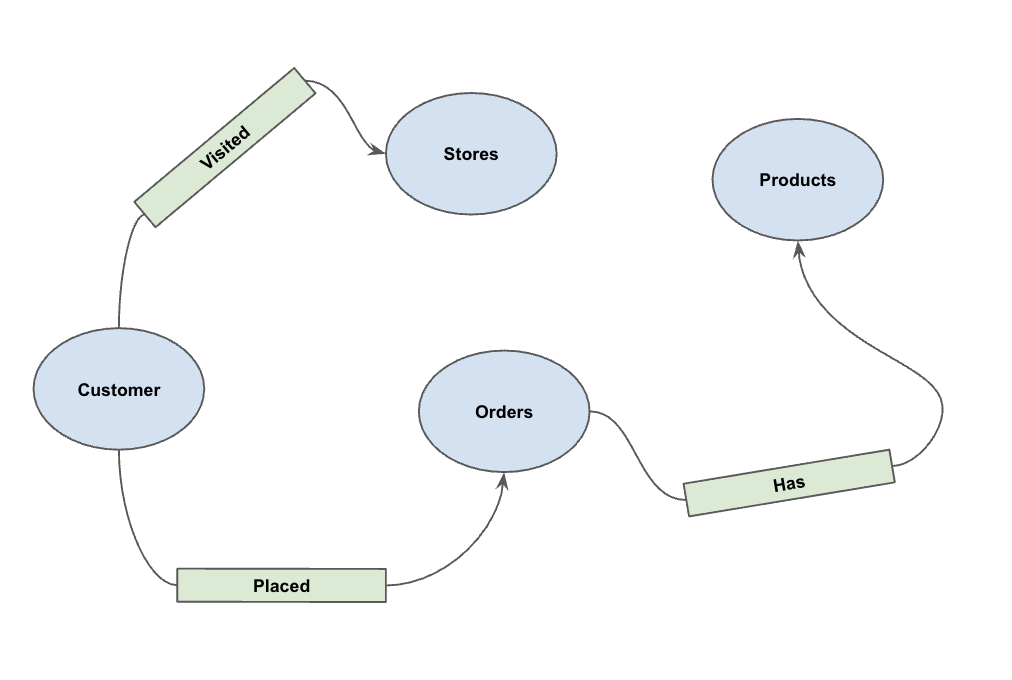
다음 DDL 문을 실행합니다.
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
이렇게 하면 GRAPH_TABLE 연산자를 사용하여 그래프 순회를 실행할 수 있는 그래프 PetsOrderGraph가 생성됩니다.
6. 모든 고객의 구매 내역 시각화
이 Codelab의 시각화 및 추천 부분에서는 BigQuery Studio의 기본 그래프 시각화를 사용합니다. 이를 통해 그래프 결과를 쉽게 시각화할 수 있습니다.
또는 IPython 매직을 사용하여 BigQuery 그래프 노트북에서 시각화할 수 있습니다. TO_JSON 함수와 함께 %%bigquery 매직 명령어를 추가하면 다음 섹션에 표시된 대로 결과를 시각화할 수 있습니다.
Cymbal Pets에서 특정 기간에 모든 고객과 구매 내역을 360도 시각화하려고 한다고 가정해 보겠습니다.
새 BigQuery Studio 탭에서 다음을 실행합니다.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
결과를 시각화하려면 쿼리 결과 창에서 그래프를 클릭합니다.

7. 안젤리카의 구매 내역 시각화
Cymbal Pets에서 Angelica Russell이라는 고객을 자세히 살펴보고 싶다고 가정해 보겠습니다. 지난 3개월 동안 Angelica가 구매한 제품과 고객이 방문한 매장을 분석하고 싶어 합니다.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
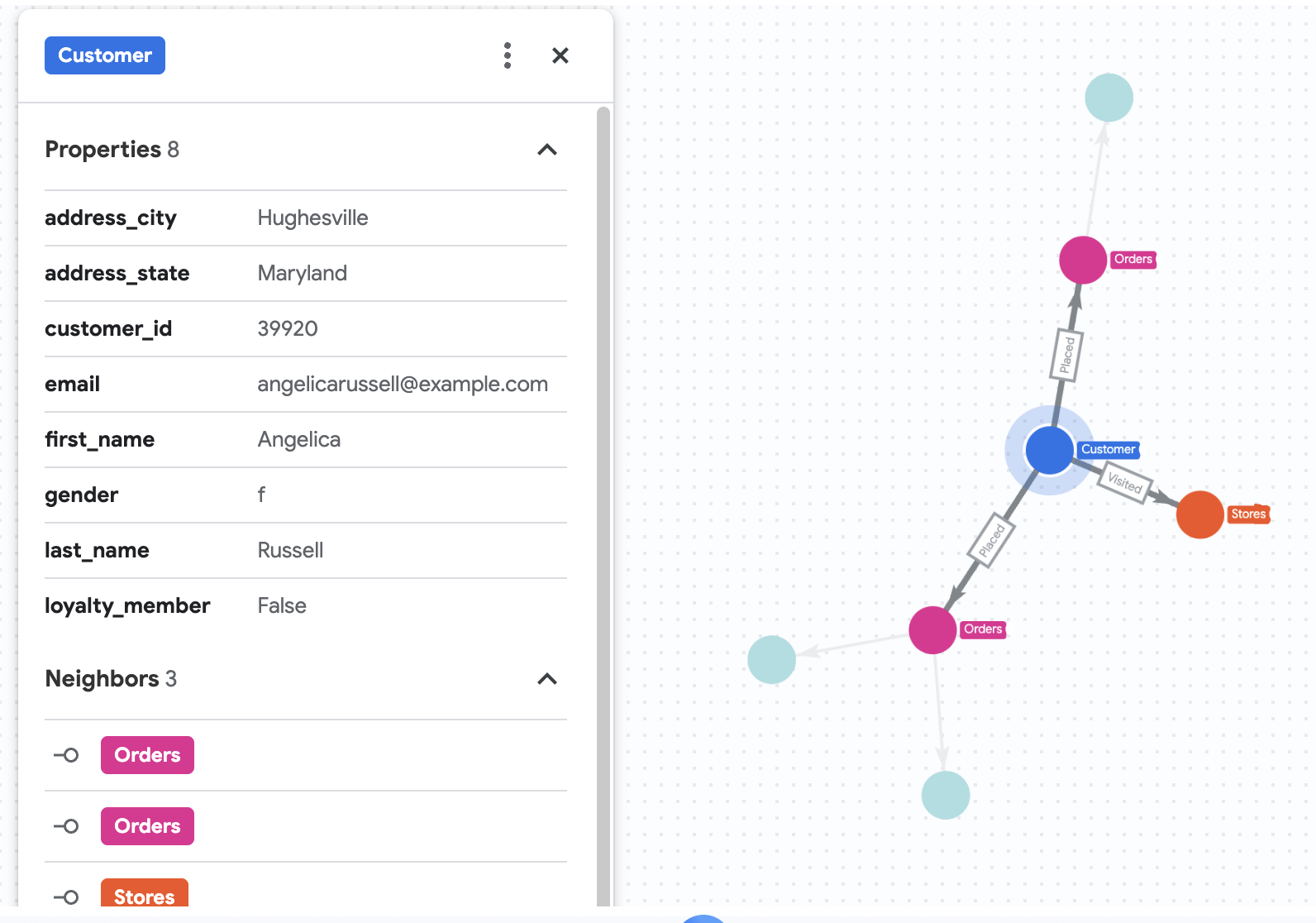
8. 벡터 검색을 사용한 제품 추천
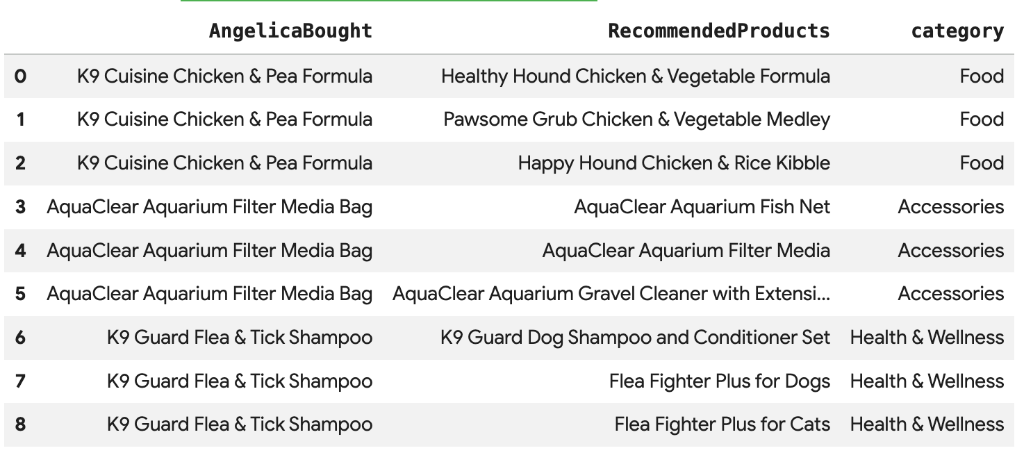
Cymbal Pets는 최근에 Angelica가 구매한 제품을 기반으로 제품을 추천하고자 합니다. 벡터 검색을 사용하여 과거 구매와 임베딩이 유사한 제품을 찾을 수 있습니다.
새 Colab 셀에서 다음 SQL 스크립트를 실행합니다. 이 스크립트는 다음을 수행합니다.
- Angelica가 최근에 구매한 제품을 식별합니다.
VECTOR_SEARCH를 사용하여products표에서 유사한 상위 4개 제품을 찾습니다.
참고: 이 단계에서는 AI.GENERATE_EMBEDDINGS를 실행하여 제품 테이블에 임베딩 열을 만들었다고 가정합니다.
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
Angelica가 구매한 제품과 의미적으로 유사한 추천 제품 목록이 표시됩니다.
9. '함께 구매한 상품' 및 Jaccard 유사성을 사용하는 추천
또 다른 강력한 추천 기법은 '협업 필터링'입니다. 다른 사용자가 함께 자주 구매하는 제품을 추천하는 것입니다.
고객에서 구매한 제품으로, 구매한 제품에서 해당 제품을 구매한 다른 고객으로, 다른 고객에서 해당 고객이 구매한 다른 제품으로 그래프를 이동하여 이러한 제품을 찾을 수 있습니다.
Jaccard 유사성을 사용하여 인기 편향 극복하기
원시 동시 구매 수는 유용하지만 인기 제품에 편향될 수 있습니다. 인기 제품은 우연히 여러 가지와 함께 구매될 수 있습니다.
Jaccard 유사도는 공동 구매 수를 정규화하여 추천을 한 단계 더 발전시킵니다. 두 집합 (이 경우 각 제품을 포함하는 주문 집합) 간의 유사성을 측정합니다.
Jaccard 유사성 공식은 다음과 같습니다.

각 항목의 의미는 다음과 같습니다.
- A 교집합 B는 제품 A와 제품 B가 모두 포함된 주문 수 (동시 구매 수)입니다.
- A는 제품 A가 포함된 총 주문 수입니다.
- B는 제품 B가 포함된 총 주문 수입니다.
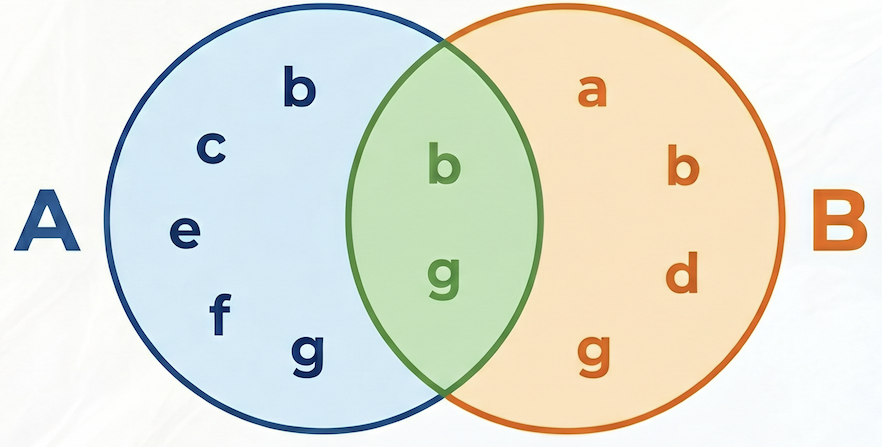
다음 예에서 A = {b,c,e,f,g}, B = {a,d,b,g}이면 교집합 A⋂B = {b,g}, 합집합 A⋃B = {a,b,c,d,e,f,g}이므로 A와 B 사이의 Jaccard 유사도는 2 / 7 = 0.285714입니다.
후보군 생성 및 재정렬
대규모 데이터 세트에서 작동하는 실제 추천 시스템에서는 가능한 모든 제품 쌍에 대해 복잡한 유사도 점수 (예: Jaccard)를 계산하는 것이 비실용적인 경우가 많습니다. 대신 일반적인 패턴은 2단계 접근 방식을 사용하는 것입니다.
- 후보 생성: 간단하고 빠른 측정항목 (예: 원시 동시 구매 수)을 사용하여 검색 공간을 필터링하고 관리 가능한 수의 후보 (예: 상위 10개)를 찾습니다.
- 재순위 지정: 더 정확하지만 계산량이 많은 측정항목 (예: Jaccard 유사도)을 적용하여 작은 후보 집합의 순위를 지정하고 최종 상위 추천을 선택합니다.
이 Codelab에서는 다음 패턴을 따릅니다.
- 1단계: 원시 동시 구매 수를 기반으로 각 제품에 대해 동시 구매된 상위 10개 제품을 찾는 쿼리를 실행하고 이를 테이블에 저장합니다.
- 2단계: 그래프 쿼리를 사용하여 이러한 후보를 검색하고, Jaccard 유사성으로 순위를 지정하고, 상위 3개를 반환합니다.
[!WARNING] 단점: 1단계에서 원시 개수를 기준으로 필터링하면 매우 구체적이지만 빈도가 낮은 동시 구매의 '재현율'이 손실될 수 있습니다. 제품이 다른 제품과 매우 유사하지만 둘 다 거의 구매하지 않는 경우 상위 10개 후보에 포함되지 않아 누락될 수 있습니다.
다음 쿼리를 실행하여 원시 동시 구매 수와 Jaccard 유사도를 모두 계산하고 원시 수별로 상위 10개 후보를 저장합니다.
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
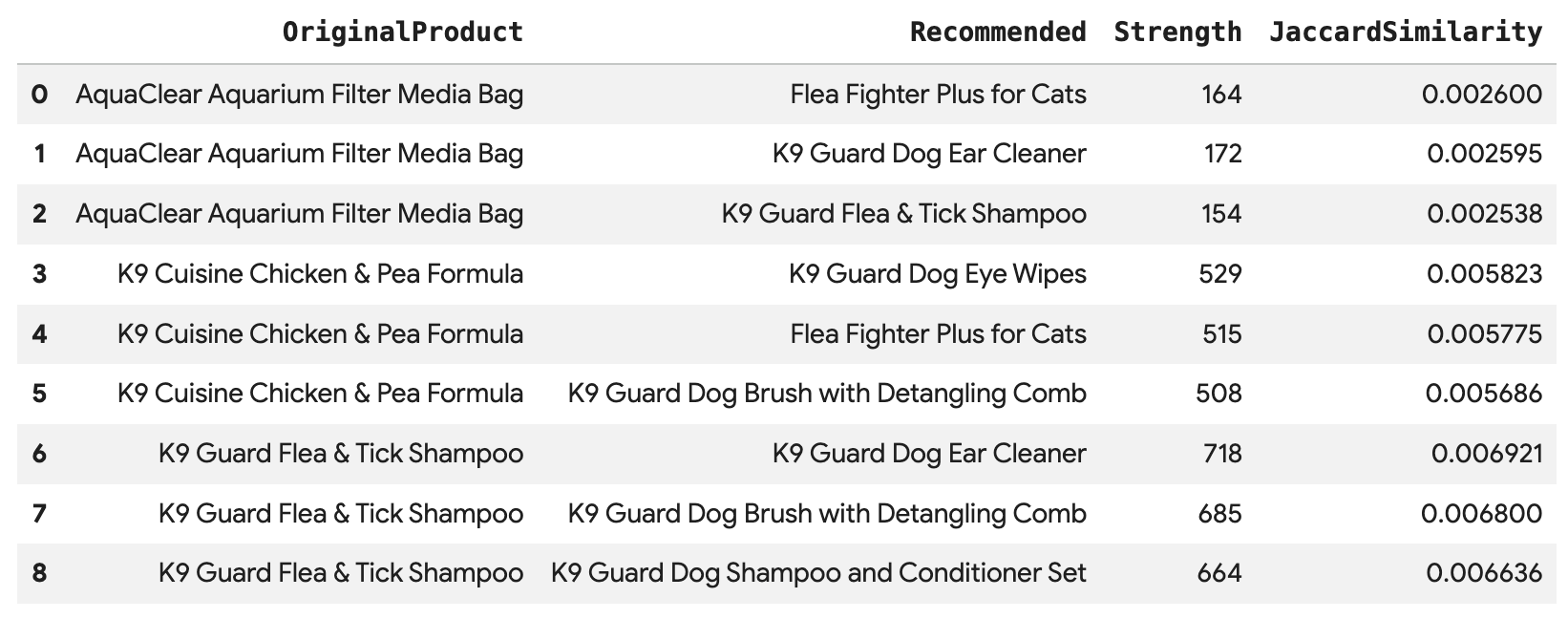
이 쿼리를 실행하여 BoughtTogether 에지를 통해 직접 연결된 Angelica의 각 구매에 대해 상위 3개 제품을 추천하고 공동 구매 수와 Jaccard 유사도를 모두 표시합니다.
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
이 쿼리는 Customer -> Order -> Product -> (BoughtTogether) -> Recommended Product로 이동하여 집단 구매 행동을 기반으로 추천을 표시하고 유사성 점수를 가져옵니다.
10. 삭제
Google Cloud 계정에 지속적으로 비용이 청구되지 않도록 하려면 이 Codelab 중에 생성된 리소스를 삭제하세요.
데이터 세트와 모든 테이블을 삭제합니다.
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
이 Codelab용으로 새 프로젝트를 만든 경우 프로젝트를 삭제할 수도 있습니다.
gcloud projects delete $PROJECT_ID
11. 마무리
축하합니다. BigQuery 그래프를 사용하여 다각적인 고객 파악 뷰와 추천 엔진을 빌드했습니다.
학습한 내용
- BigQuery에서 속성 그래프를 만드는 방법을 설명합니다.
- 그래프 노드 및 에지에 데이터를 로드하는 방법
GRAPH_TABLE및MATCH을 사용하여 그래프 패턴을 쿼리하는 방법- 그래프 쿼리와 벡터 검색을 결합하여 하이브리드 추천을 제공하는 방법
다음 단계
- BigQuery 그래프 문서를 살펴봅니다.
- BigQuery의 벡터 검색에 대해 자세히 알아보세요.