
۱. مقدمه
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه از BigQuery Graph برای ساخت یک نمای مشتری ۳۶۰ درجه و یک موتور پیشنهاد برای Cymbal Pets، یک شرکت خرده فروشی خیالی، استفاده کنید. شما از قدرت SQL برای ایجاد، پرس و جو و تجزیه و تحلیل دادههای نموداری مستقیماً در BigQuery استفاده خواهید کرد و آن را با جستجوی برداری برای توصیههای پیشرفته محصول ترکیب خواهید کرد.
BigQuery Graph به شما امکان میدهد روابط بین موجودیتهای دادهای خود (مانند مشتریان، محصولات و سفارشات) را به صورت یک نمودار مدلسازی کنید و پاسخ به سوالات پیچیده در مورد رفتار مشتری و شباهتهای محصول را آسان کنید.

کاری که انجام خواهید داد
- ایجاد یک مجموعه داده و طرحواره BigQuery برای گراف Cymbal Pets
- بارگذاری دادههای نمونه (مشتریان، محصولات، سفارشات، فروشگاهها) از فضای ذخیرهسازی ابری
- یک نمودار ویژگی در BigQuery ایجاد کنید که این موجودیتها را به هم متصل میکند.
- نمایش تاریخچه خرید مشتری با استفاده از نمودارهای کوئری
- ساخت سیستم پیشنهاد محصول با استفاده از جستجوی برداری
- بهبود توصیهها با استفاده از روابط گراف «خریداری شده با هم» و شباهت جاکارد
آنچه نیاز دارید
- یک مرورگر وب مانند کروم
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
این آزمایشگاه کد برای توسعهدهندگان در تمام سطوح، از جمله مبتدیان، مناسب است.
۲. قبل از شروع
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، یک پروژه گوگل کلود انتخاب یا ایجاد کنید .
- مطمئن شوید که پرداخت برای پروژه ابری شما فعال است.
شروع پوسته ابری
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- تأیید اعتبار:
gcloud auth list
- پروژه خود را تایید کنید:
gcloud config get project
- در صورت نیاز آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
فعال کردن APIها
برای فعال کردن API مورد نیاز BigQuery، این دستور را اجرا کنید:
gcloud services enable bigquery.googleapis.com
۳. طرحواره را تعریف کنید
ابتدا، باید یک مجموعه داده برای ذخیره جداول مربوط به نمودار خود ایجاد کنید و طرحواره گرهها و لبههای خود را تعریف کنید.
- برای این آزمایشگاه کد، ما دستورات SQL را اجرا خواهیم کرد. میتوانید این دستورات را در BigQuery Studio > SQL Editor اجرا کنید، یا از دستور
bq queryدر Cloud Shell استفاده کنید. ما فرض میکنیم که شما برای تجربه بهتر با دستورات create چندخطی، از ویرایشگر BigQuery SQL استفاده میکنید.
ما فرض میکنیم که شما برای تجربه بهتر با دستورات create چندخطی، از ویرایشگر BigQuery SQL استفاده میکنید. - مجموعه داده
cymbal_pets_demoرا ایجاد کنید:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- جداول مربوط به
order_items،products،orders،stores،customersوco_related_products_for_angelicaرا ایجاد کنید. این جداول به عنوان دادههای منبع برای نمودار ما عمل خواهند کرد.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
اکنون ساختار دادههای نمودار خود را تعریف کردهاید.
۴. بارگذاری دادهها
اکنون، جداول را با دادههای نمونه از Cloud Storage پر کنید.
دستورات LOAD DATA زیر را در ویرایشگر BigQuery SQL اجرا کنید:
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
شما باید تأییدیهای مبنی بر بارگذاری ردیفها در هر جدول مشاهده کنید.
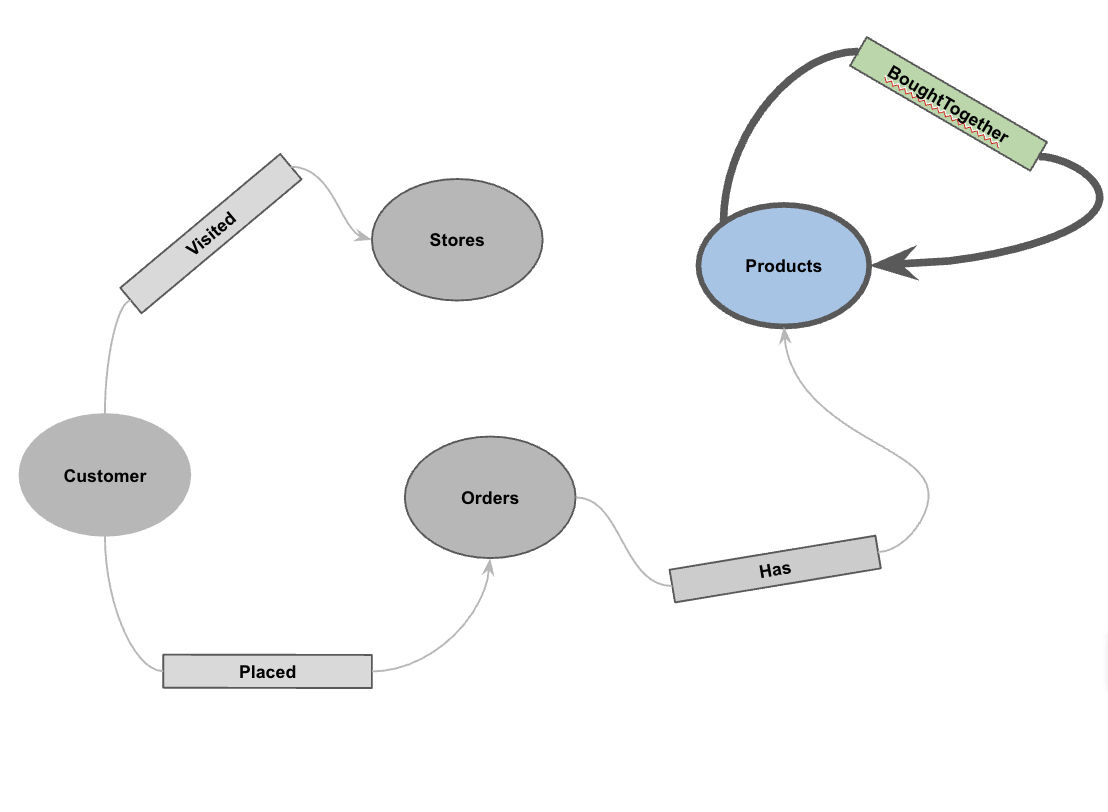
۵. نمودار ویژگیها را ایجاد کنید
با بارگذاری دادهها، اکنون میتوانید نمودار ویژگیها را تعریف کنید. این به BigQuery میگوید که کدام جداول نشاندهنده گرهها (موجودیتهایی مانند مشتریان، محصولات) و کدام جداول نشاندهنده لبهها (روابطی مانند "بازدید شده"، "قرار داده شده"، "دارای") هستند.
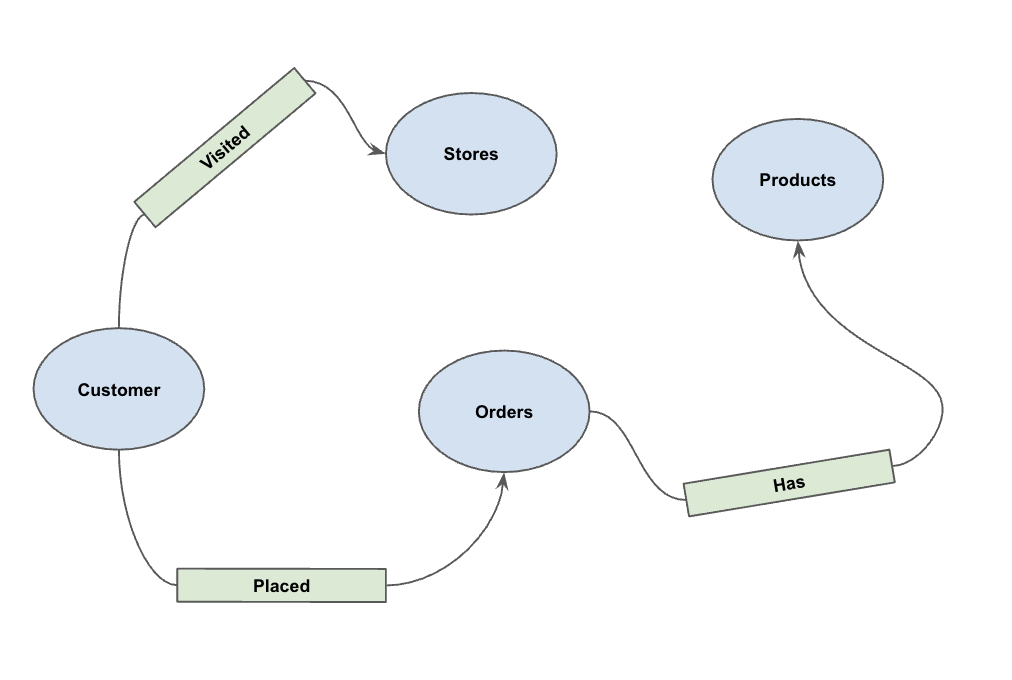
دستور DDL زیر را اجرا کنید:
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
این کار گراف PetsOrderGraph ایجاد میکند که به ما امکان میدهد پیمایش گراف را با استفاده از عملگر GRAPH_TABLE انجام دهیم.
۶. تاریخچه خرید همه مشتریان را تجسم کنید
برای بخشهای تجسم و توصیه این آزمایشگاه کد، از تجسم نمودار بومی در BigQuery Studio استفاده خواهیم کرد. این به ما امکان میدهد تا به راحتی نتایج نمودار را تجسم کنیم.
به عنوان یک روش جایگزین، میتوانید با استفاده از IPython Magics در BigQuery Graph Notebook نمودارها را مصورسازی کنید. با اضافه کردن دستور جادویی %%bigquery به همراه تابع TO_JSON ، میتوانید نتایج را همانطور که در بخشهای بعدی نشان داده شده است، مصورسازی کنید.
فرض کنید که Cymbal Pets میخواهد یک تصویر ۳۶۰ درجه از تمام مشتریان و خریدهایی که در یک بازه زمانی خاص انجام دادهاند، داشته باشد.
دستور زیر را در یک تب جدید BigQuery Studio اجرا کنید:
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
برای تجسم نتایج خود، در قسمت نتایج پرس و جو، روی نمودار کلیک کنید.

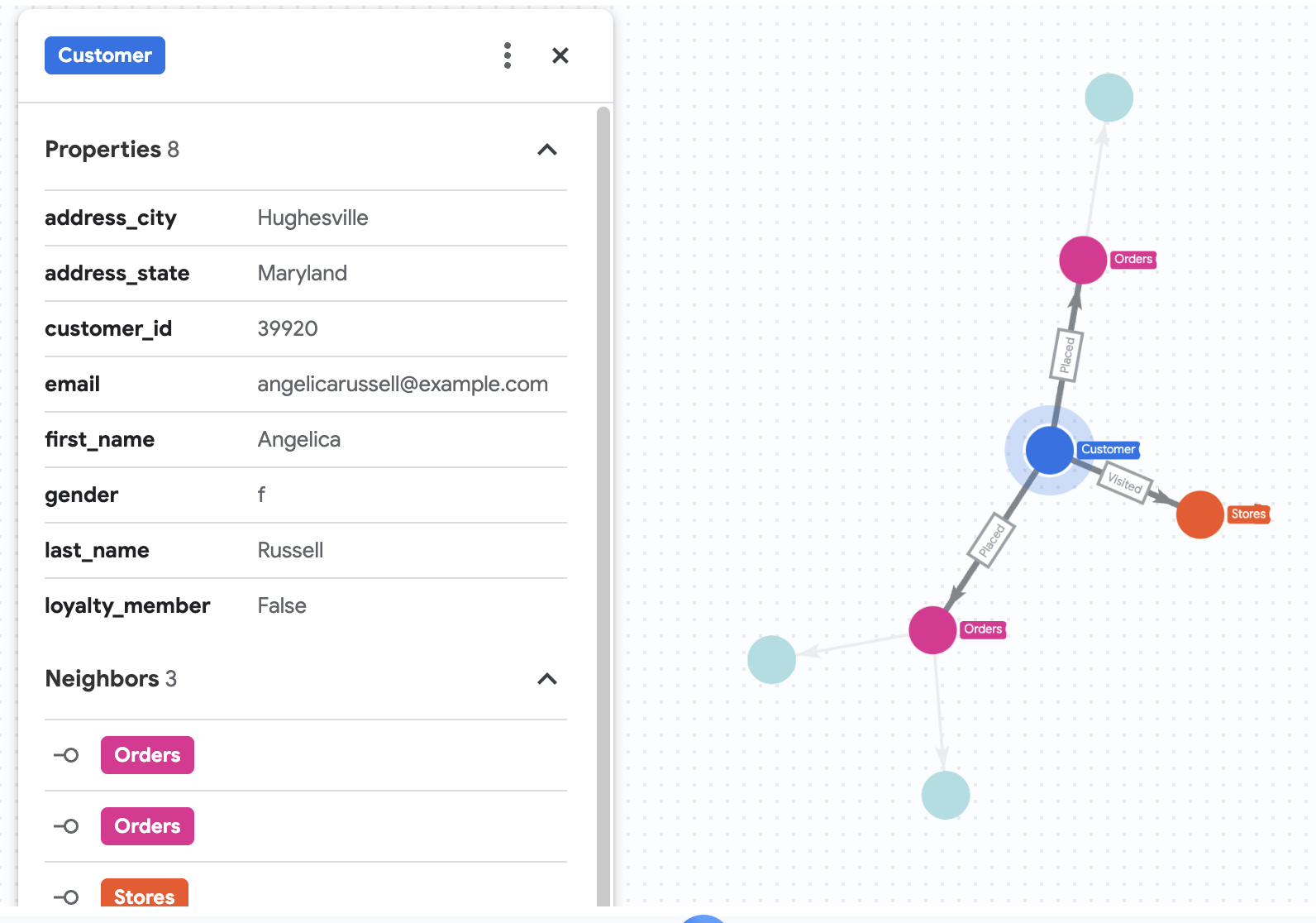
۷. تاریخچه خرید آنجلیکا را تجسم کنید
فرض کنید شرکت Cymbal Pets میخواهد عمیقاً به سراغ مشتریای به نام Angelica Russell برود. آنها میخواهند محصولاتی را که Angelica در ۳ ماه گذشته خریداری کرده و فروشگاههایی را که مشتری از آنها بازدید کرده است، تجزیه و تحلیل کنند.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
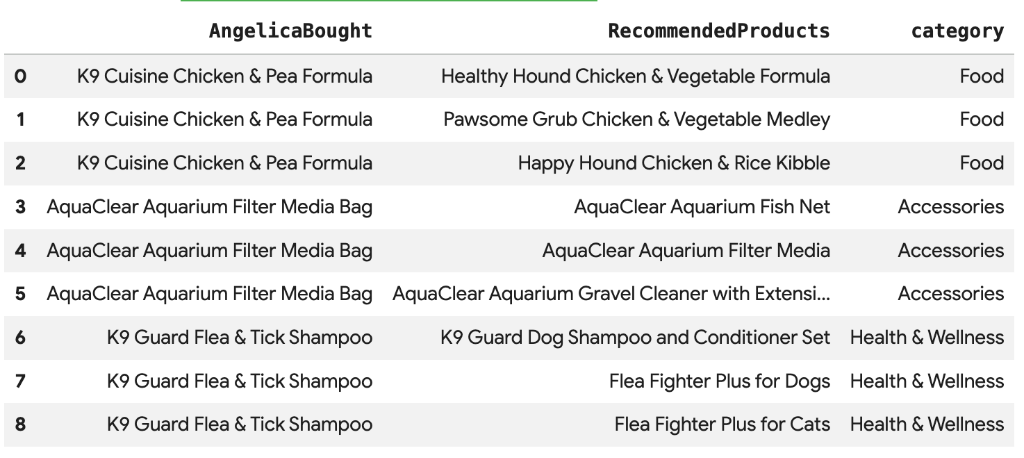
۸. پیشنهاد محصول با استفاده از جستجوی برداری
Cymbal Pets میخواهد بر اساس خریدهای اخیر آنجلیکا، محصولاتی را به او پیشنهاد دهد. ما میتوانیم از جستجوی برداری برای یافتن محصولاتی با جاسازیهای مشابه خریدهای قبلی او استفاده کنیم.
اسکریپت SQL زیر را در یک سلول جدید Colab اجرا کنید. این اسکریپت:
- محصولاتی را که آنجلیکا اخیراً خریداری کرده است، شناسایی میکند.
- از
VECTOR_SEARCHبرای یافتن ۴ محصول مشابه برتر از جدولproductsاستفاده میکند.
نکته: این مرحله فرض میکند که شما قبلاً AI.GENERATE_EMBEDDINGS را برای ایجاد ستون جاسازیها در جدول محصولات اجرا کردهاید.
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
شما باید لیستی از محصولات پیشنهادی را ببینید که از نظر معنایی مشابه آنچه آنجلیکا خریداری کرده است، هستند.
۹. توصیه با استفاده از «خریداری شده با هم» و شباهت جاکارد
یکی دیگر از تکنیکهای قدرتمند پیشنهاد، «فیلترینگ مشارکتی» است - پیشنهاد محصولاتی که اغلب توسط سایر کاربران با هم خریداری میشوند.
ما میتوانیم این محصولات را با پیمایش نمودار از یک مشتری به محصولات خریداری شده توسط او، سپس به سایر مشتریانی که آن محصولات را خریداری کردهاند و در نهایت به سایر محصولاتی که آن مشتریان خریداری کردهاند، پیدا کنیم.
غلبه بر سوگیری محبوبیت با استفاده از شباهت جاکارد
اگرچه تعداد خریدهای مشترک خام مفید است، اما میتواند به سمت محصولات محبوب متمایل باشد. یک محصول بسیار محبوب ممکن است به طور اتفاقی با چیزهای زیادی خریداری شود.
ابزار Jaccard Similarity با نرمالسازی تعداد خریدهای مشترک، توصیهها را یک گام فراتر میبرد. این ابزار، شباهت بین دو مجموعه (در این مورد، مجموعه سفارشهای حاوی هر محصول) را اندازهگیری میکند.
فرمول تشابه جاکارد به صورت زیر است:

کجا:
- نقطه تقاطع B تعداد سفارشهایی است که شامل هر دو محصول A و B هستند (تعداد خرید مشترک).
- A تعداد کل سفارشهای حاوی محصول A است.
- B تعداد کل سفارشهای حاوی محصول B است.
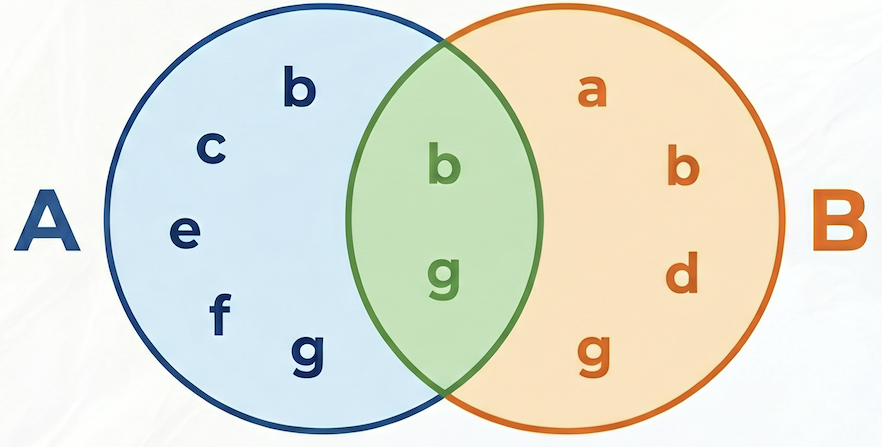
در مثال زیر، مجموعه A = {b,c,e,f,g}، مجموعه B = {a,d,b,g}، اشتراک آنها A⋂B = {b,g}، اجتماع آنها A⋃B = {a,b,c,d,e,f,g}، بنابراین شباهت جاکارد بین A و B برابر با 2 / 7 = 0.285714 است.
تولید کاندیدا و رتبهبندی مجدد
در سیستمهای توصیهگر دنیای واقعی که بر روی مجموعه دادههای عظیم کار میکنند، اغلب محاسبه امتیازهای شباهت پیچیده (مانند Jaccard) برای همه جفتهای ممکن محصولات غیرعملی است. در عوض، یک الگوی رایج استفاده از یک رویکرد دو مرحلهای است:
- تولید کاندیدا : از یک معیار ساده و سریع (مانند تعداد خام خریدهای مشترک) برای فیلتر کردن فضای جستجو و یافتن تعداد قابل مدیریت کاندیداها (مثلاً 10 کاندیدای برتر) استفاده کنید.
- رتبهبندی مجدد : از یک معیار دقیقتر، اما از نظر محاسباتی سنگینتر (مانند Jaccard Similarity) برای رتبهبندی آن مجموعه کوچک از نامزدها و انتخاب توصیههای برتر نهایی استفاده کنید.
در این آزمایشگاه کد، ما از این الگو پیروی خواهیم کرد:
- مرحله ۱ : یک پرسوجو اجرا کنید تا ۱۰ محصول برتر خریداریشده مشترک برای هر محصول را بر اساس تعداد خام خرید مشترک پیدا کنید و آنها را در یک جدول ذخیره کنید.
- مرحله ۲ : از یک پرسوجوی گراف برای بازیابی این نامزدها استفاده کنید، آنها را بر اساس شباهت جاکارد رتبهبندی کنید و ۳ مورد برتر را برگردانید.
[!هشدار] ایراد : با فیلتر کردن تعداد خام در مرحله ۱، ممکن است «به خاطر آوردن» خریدهای مشترک بسیار خاص اما با فراوانی کم را از دست بدهیم. اگر محصولی بسیار شبیه به محصول دیگر باشد اما هر دو به ندرت خریداری شوند، ممکن است در بین ۱۰ کاندیدای برتر قرار نگیرد و از قلم بیفتد.
برای محاسبه تعداد خام خرید مشترک و شباهت جاکارد، کوئری زیر را اجرا کنید و 10 کاندیدای برتر را بر اساس تعداد خام ذخیره کنید:
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
این کوئری را اجرا کنید تا ۳ محصول برتر برای هر یک از خریدهای آنجلیکا را که مستقیماً از طریق لبه BoughtTogether به هم متصل شدهاند، پیشنهاد دهد و هم تعداد خریدهای مشترک و هم شباهت Jaccard را نشان دهد:
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
این پرسوجو از مسیر مشتری -> سفارش -> محصول -> (BoughtTogether) -> محصول پیشنهادی عبور میکند و توصیههایی را بر اساس رفتار خرید جمعی به شما نشان میدهد و امتیاز شباهت آنها را بازیابی میکند.

۱۰. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابع ایجاد شده در طول این codelab را حذف کنید.
مجموعه دادهها و تمام جداول را حذف کنید:
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
اگر برای این codelab یک پروژه جدید ایجاد کردهاید، میتوانید پروژه را نیز حذف کنید:
gcloud projects delete $PROJECT_ID
۱۱. تبریک
تبریک! شما با موفقیت یک موتور نمایش و پیشنهاد مشتری ۳۶۰ درجه با استفاده از BigQuery Graph ساختید.
آنچه آموختهاید
- نحوه ایجاد نمودار ویژگی در BigQuery.
- نحوه بارگذاری دادهها در گرهها و لبههای گراف.
- نحوه پرس و جو از الگوهای نمودار با استفاده از
GRAPH_TABLEوMATCH - چگونه میتوان پرسوجوهای گراف را با جستجوی برداری برای توصیههای ترکیبی ترکیب کرد؟
مراحل بعدی
- مستندات BigQuery Graph را بررسی کنید.
- درباره جستجوی برداری در BigQuery بیشتر بدانید.