
1. מבוא
בשיעור Codelab הזה תלמדו איך להשתמש ב-BigQuery Graph כדי ליצור תצוגת 360 מעלות של לקוח ומערכת המלצות בשביל Cymbal Pets, חברת קמעונאות פיקטיבית. תשתמשו בעוצמה של SQL כדי ליצור נתוני תרשים, לשלוח שאילתות לגביהם ולנתח אותם ישירות ב-BigQuery, ותשלבו אותם עם חיפוש וקטורי כדי ליצור המלצות מתקדמות למוצרים.
BigQuery Graph מאפשר לכם ליצור מודלים של קשרים בין ישויות הנתונים שלכם (כמו לקוחות, מוצרים והזמנות) כתרשים, וכך לענות בקלות על שאלות מורכבות לגבי התנהגות לקוחות והעדפות מוצרים.

הפעולות שתבצעו:
- יצירת מערך נתונים וסכימה ב-BigQuery לגרף Cymbal Pets
- טעינת נתוני דוגמה (לקוחות, מוצרים, הזמנות, חנויות) מ-Cloud Storage
- יצירת גרף נכסים ב-BigQuery שמקשר בין הישויות האלה
- הצגה חזותית של היסטוריית הרכישות של הלקוחות באמצעות שאילתות גרף
- יצירת מערכת להמלצות על מוצרים באמצעות חיפוש וקטורי
- שיפור ההמלצות באמצעות קשרים גרפיים מסוג 'נרכשו יחד' ודמיון ג'קארד
הדרישות
- דפדפן אינטרנט כמו Chrome
- פרויקט ב-Google Cloud שהחיוב בו מופעל
שיעור ה-Codelab הזה מיועד למפתחים בכל הרמות, כולל מתחילים.
2. לפני שמתחילים
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בוחרים פרויקט או יוצרים פרויקט חדש ב-Google Cloud.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud.
הפעלת Cloud Shell
- לוחצים על Activate Cloud Shell בחלק העליון של מסוף Google Cloud.
- אימות האימות:
gcloud auth list
- מאשרים את הפרויקט:
gcloud config get project
- מגדירים אותו לפי הצורך:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
הפעלת ממשקי ה-API
מריצים את הפקודה הבאה כדי להפעיל את BigQuery API הנדרש:
gcloud services enable bigquery.googleapis.com
3. הגדרת הסכימה
קודם כול, צריך ליצור מערך נתונים לאחסון הטבלאות שקשורות לגרף ולהגדיר את הסכימה של הצמתים והקשתות.
- ב-codelab הזה נריץ פקודות SQL. אפשר להריץ את הפקודות האלה ב-BigQuery Studio > SQL Editor, או להשתמש בפקודה
bq queryב-Cloud Shell. כדי לקבל חוויה טובה יותר עם הצהרות יצירה מרובות שורות, אנחנו מניחים שאתם משתמשים בעורך SQL של BigQuery.
כדי לקבל חוויה טובה יותר עם הצהרות יצירה מרובות שורות, אנחנו מניחים שאתם משתמשים בעורך SQL של BigQuery. - יוצרים את מערך הנתונים
cymbal_pets_demo:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- יוצרים את הטבלאות עבור
order_items,products,orders,stores,customersו-co_related_products_for_angelica. הטבלאות האלה ישמשו כמקור הנתונים לגרף שלנו.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date DATE,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
)
PARTITION BY order_date
CLUSTER BY order_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
הגדרתם את המבנה של נתוני הגרף.
4. טעינת הנתונים
עכשיו מאכלסים את הטבלאות בנתונים לדוגמה מ-Cloud Storage.
מריצים את ההצהרות הבאות ב-BigQuery SQL dditor:LOAD DATA
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
אמור להופיע אישור לכך שהשורות נטענו לכל טבלה.
5. יצירת גרף הנכסים
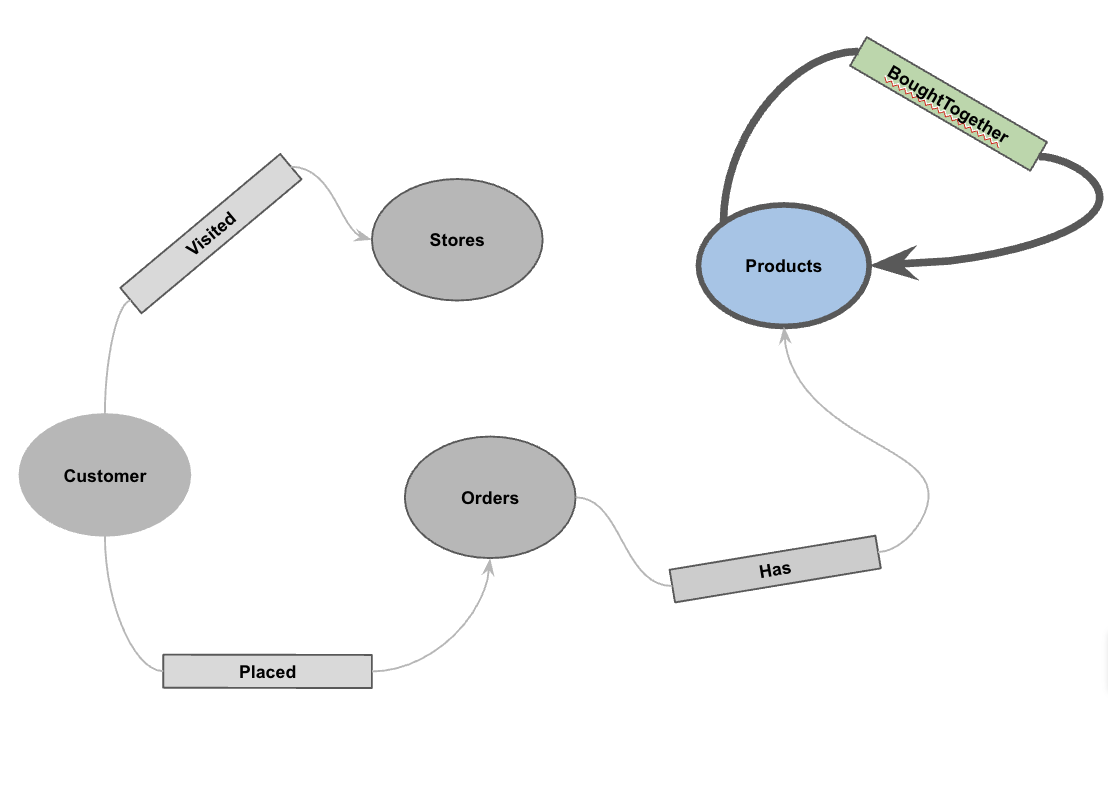
אחרי שהנתונים נטענים, אפשר להגדיר את גרף הנכסים. הפרמטר הזה מציין ל-BigQuery אילו טבלאות מייצגות צמתים (ישויות כמו לקוחות, מוצרים) ואילו טבלאות מייצגות קשתות (יחסים כמו 'ביקר', 'הזמין', 'יש לו').
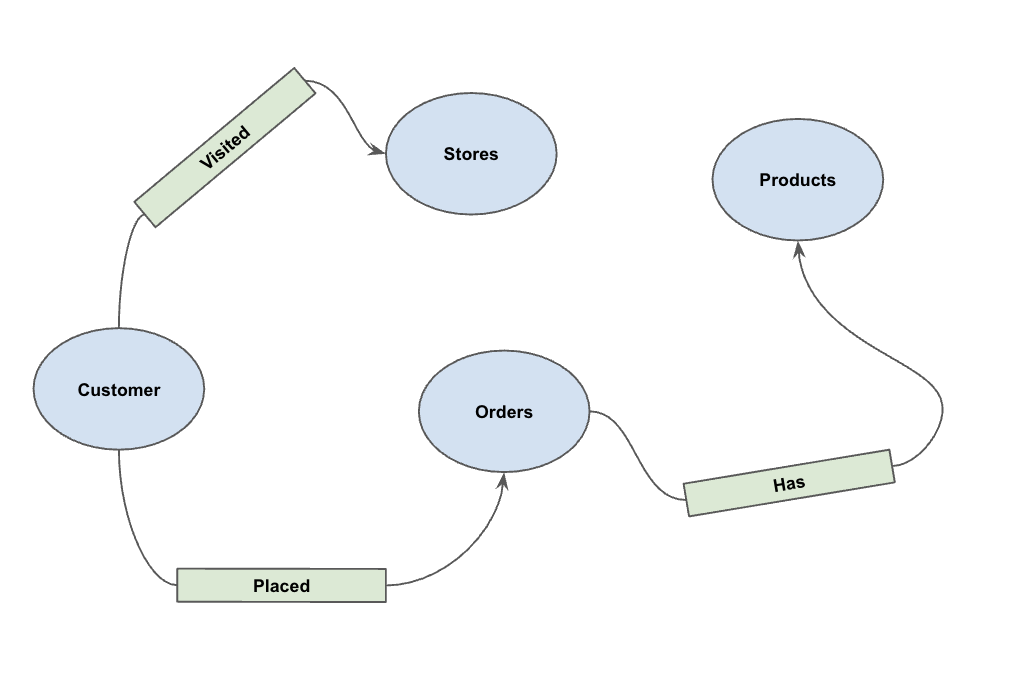
מריצים את הצהרת ה-DDL הבאה:
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
הפעולה הזו יוצרת את הגרף PetsOrderGraph, שמאפשר לנו לבצע מעברים בגרף באמצעות האופרטור GRAPH_TABLE.
6. הצגה חזותית של היסטוריית הרכישות של כל הלקוחות
פותחים מחברת חדשה ב-BigQuery Studio.
כדי ליצור את התצוגה החזותית וההמלצות בשיעור Codelab הזה, נשתמש ב-Notebook של Google Colab ב-BigQuery Studio. כך אפשר לראות בקלות את תוצאות הגרף.
מדביקים את הקוד הבא בתא קוד:
!pip install bigquery-magics==0.12.1
BigQuery Graph Notebook מיושם כ-IPython Magics. אם מוסיפים את פקודת הקסם %%bigquery עם הפונקציה TO_JSON, אפשר להציג את התוצאות באופן חזותי כמו בדוגמאות שמופיעות בקטעים הבאים.
נניח שחברת Cymbal Pets רוצה לקבל תצוגה חזותית של כל הלקוחות והרכישות שהם ביצעו בחלון זמן ספציפי.
מריצים את הפקודה הבאה בתא חדש:
%%bigquery --graph
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
אמור להופיע ייצוג חזותי של תוצאת הגרף.

7. הדמיה של היסטוריית הרכישות של אנג'ליקה
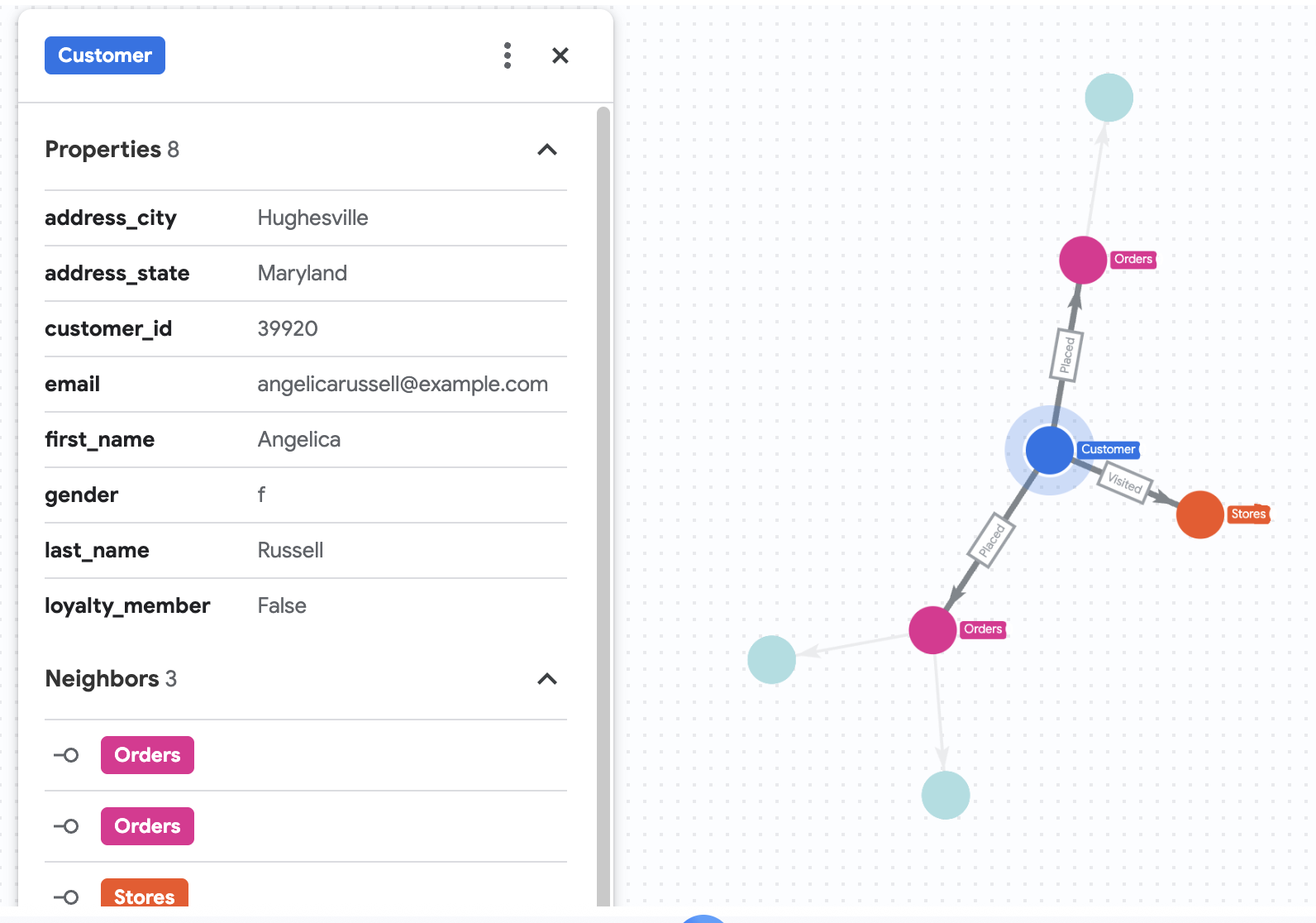
נניח שחברת Cymbal Pets רוצה לקבל מידע מפורט על לקוחה בשם אנג'ליקה ראסל. הם רוצים לנתח את המוצרים שאנג'ליקה קנתה ב-3 החודשים האחרונים, ואת החנויות שהלקוחה ביקרה בהן.
%%bigquery --graph
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
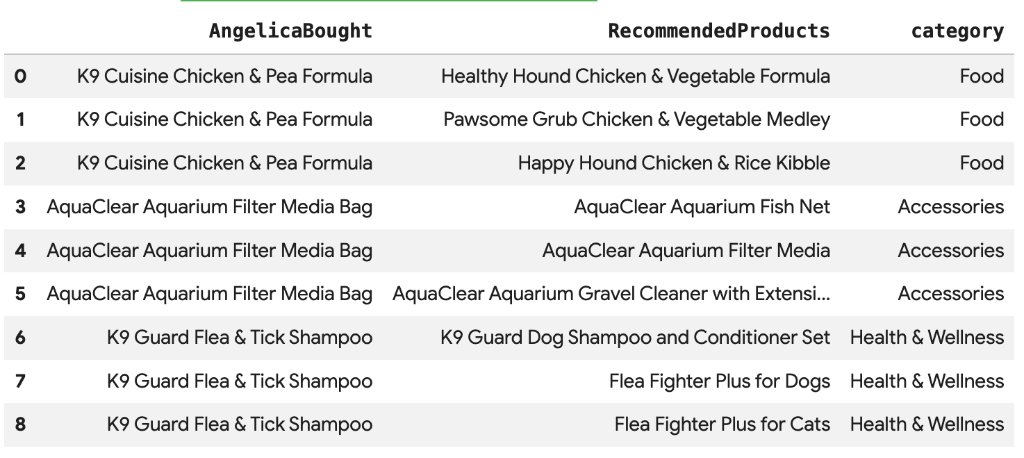
8. המלצה על מוצר באמצעות חיפוש וקטורי
חברת Cymbal Pets רוצה להמליץ לאנג'ליקה על מוצרים על סמך מה שהיא קנתה לאחרונה. אנחנו יכולים להשתמש בחיפוש וקטורי כדי למצוא מוצרים עם הטמעות דומות לרכישות הקודמות שלה.
מריצים את סקריפט ה-SQL הבא בתא חדש ב-Colab. הסקריפט הזה:
- מזהה מוצרים שאנג'ליקה קנתה לאחרונה.
- משתמשים ב-
VECTOR_SEARCHכדי למצוא את 4 המוצרים הדומים המובילים מהטבלהproducts.
הערה: בשלב הזה מניחים שכבר הפעלתם את AI.GENERATE_EMBEDDINGS כדי ליצור עמודת הטמעה בטבלת המוצרים.
%%bigquery
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
אמורה להופיע רשימה של מוצרים מומלצים שדומים מבחינה סמנטית למוצר שאנג'ליקה קנתה.
9. המלצה באמצעות 'נרכשו יחד' ודמיון ג'קארד
טכניקת המלצה יעילה נוספת היא 'סינון שיתופי' – המלצה על מוצרים שמשתמשים אחרים קונים לעיתים קרובות ביחד.
אנחנו יכולים למצוא את המוצרים האלה על ידי מעבר בתרשים מלקוח למוצרים שהוא רכש, אחר כך ללקוחות אחרים שרכשו את המוצרים האלה, ולבסוף למוצרים האחרים שהלקוחות האלה רכשו.
איך מתמודדים עם הטיית פופולריות באמצעות דמיון ג'קארד
ספירות גולמיות של רכישות משותפות הן שימושיות, אבל הן עלולות להיות מוטות לטובת מוצרים פופולריים. יכול להיות שמוצר פופולרי מאוד ייקנה עם הרבה דברים רק במקרה.
דמיון ג'קארד לוקח את ההמלצות צעד אחד קדימה על ידי נרמול של מספר הרכישות המשותפות. המדד הזה מודד את הדמיון בין שתי קבוצות (במקרה הזה, קבוצות ההזמנות שמכילות כל מוצר).
הנוסחה לחישוב דמיון ג'קארד היא:

איפה:
- A intersect B הוא מספר ההזמנות שמכילות גם את מוצר א' וגם את מוצר ב' (מספר הרכישות המשותפות).
- A הוא המספר הכולל של ההזמנות שכוללות את מוצר א'.
- B הוא המספר הכולל של ההזמנות שמכילות את מוצר ב'.
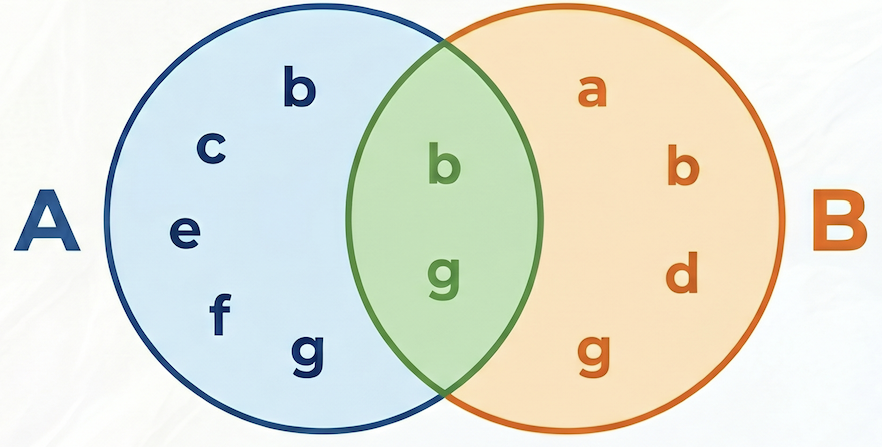
בדוגמה הבאה, קבוצה A = {b,c,e,f,g}, קבוצה B = {a,d,b,g}, החיתוך שלהן A⋂B = {b,g}, האיחוד שלהן A⋃B = {a,b,c,d,e,f,g}, ולכן דמיון ג'קארד בין A ל-B הוא 2 / 7 = 0.285714
יצירת מועמדים ודירוג מחדש
במערכות המלצה מהעולם האמיתי שפועלות על מערכי נתונים עצומים, לעיתים קרובות לא מעשי לחשב ציוני דמיון מורכבים (כמו Jaccard) לכל זוג מוצרים אפשרי. במקום זאת, דפוס נפוץ הוא שימוש בגישה דו-שלבית:
- יצירת מועמדים: משתמשים במדד פשוט ומהיר (כמו ספירה גולמית של רכישות משותפות) כדי לסנן את מרחב החיפוש ולמצוא מספר מועמדים שאפשר לנהל (למשל, 10 המוצרים המובילים).
- דירוג מחדש: החלת מדד מדויק יותר, אבל כבד יותר מבחינת חישובים (כמו דמיון ג'קארד), כדי לדרג את קבוצת המועמדים הקטנה הזו ולבחור את ההמלצות הסופיות המובילות.
ב-Codelab הזה נשתמש בתבנית הבאה:
- שלב 1: מריצים שאילתה כדי למצוא את 10 המוצרים הכי נרכשים ביחד לכל מוצר, על סמך מספר הרכישות המשותפות הגולמי, ושומרים אותם בטבלה.
- שלב 2: משתמשים בשאילתת גרף כדי לאחזר את המועמדים האלה, לדרג אותם לפי דמיון ג'קארד ולהחזיר את 3 המועמדים המובילים.
[!WARNING] חיסרון: כשמסננים לפי מספר גולמי בשלב 1, יכול להיות שנפספס נתונים על רכישות משותפות ספציפיות מאוד אבל לא תדירות. אם מוצר מסוים דומה מאוד למוצר אחר, אבל שניהם נרכשים לעיתים רחוקות, יכול להיות שהמוצר לא ייכלל ב-10 המועמדים המובילים ולא יוצג.
מריצים את השאילתה הבאה כדי לחשב את מספר הרכישות המשותפות ואת דמיון ג'קארד, ולאחסן את 10 המועמדים המובילים לפי מספר הרכישות המשותפות:
%%bigquery
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
מריצים את השאילתה הזו כדי לקבל המלצה על 3 המוצרים המובילים לכל רכישה של אנג'ליקה, שמקושרים ישירות דרך קצה BoughtTogether, ומוצגים גם מספר הרכישות המשותפות וגם דמיון ג'קארד:
%%bigquery
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
השאילתה הזו עוברת מ-Customer (לקוח) -> Order (הזמנה) -> Product (מוצר) -> (BoughtTogether) -> Recommended Product (מוצר מומלץ), ומציגה המלצות שמבוססות על התנהגות רכישה קולקטיבית, ומאחזרת את ציוני הדמיון שלהן.

10. הסרת המשאבים
כדי להימנע מחיובים שוטפים בחשבון Google Cloud, מוחקים את המשאבים שנוצרו במהלך ה-codelab הזה.
מחיקת מערך הנתונים וכל הטבלאות:
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
אם יצרתם פרויקט חדש בשביל ה-Codelab הזה, אתם יכולים גם למחוק את הפרויקט:
gcloud projects delete $PROJECT_ID
11. מזל טוב
מעולה! יצרתם בהצלחה תצוגת 360 מעלות של לקוח ומערכת המלצות באמצעות BigQuery Graph.
מה למדתם
- איך יוצרים גרף נכסים ב-BigQuery.
- איך טוענים נתונים לצמתים ולקשתות של גרף.
- איך שולחים שאילתות לגבי דפוסי גרפים באמצעות
GRAPH_TABLEו-MATCH. - איך משלבים שאילתות גרף עם חיפוש וקטורי כדי לקבל המלצות היברידיות.