
1. はじめに
この Codelab では、BigQuery グラフを使用して、架空の小売企業である Cymbal Pets の顧客の 360 度ビューとレコメンデーション エンジンを構築する方法を学びます。SQL の機能を活用して、BigQuery 内でグラフデータの作成、クエリ、分析を直接行い、ベクトル検索と組み合わせて高度な商品レコメンデーションを実現します。
BigQuery Graph を使用すると、データ エンティティ(顧客、商品、注文など)間の関係をグラフとしてモデル化できるため、顧客の行動や商品の関連性に関する複雑な質問に簡単に回答できます。

演習内容
- Cymbal Pets グラフの BigQuery データセットとスキーマを作成する
- Cloud Storage からサンプルデータ(顧客、商品、注文、店舗)を読み込む
- これらのエンティティを接続する BigQuery でプロパティ グラフを作成する
- グラフクエリを使用して顧客の購入履歴を可視化する
- ベクトル検索を使用して商品レコメンデーション システムを構築する
- 「一緒に購入された商品」グラフの関係とジャカード類似度を使用してレコメンデーションを強化する
必要なもの
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
この Codelab は、初心者を含むあらゆるレベルのデベロッパーを対象としています。
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトで課金が有効になっていることを確認します。
Cloud Shell の起動
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
- 認証を確認します。
gcloud auth list
- プロジェクトを確認します。
gcloud config get project
- 必要に応じて設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API を有効にする
次のコマンドを実行して、必要な BigQuery API を有効にします。
gcloud services enable bigquery.googleapis.com
3. スキーマを定義する
まず、グラフ関連のテーブルを保存するデータセットを作成し、ノードとエッジのスキーマを定義する必要があります。
- この Codelab では、SQL コマンドを実行します。これらのコマンドは、[BigQuery Studio] > [SQL エディタ] で実行するか、Cloud Shell で
bq queryコマンドを使用します。 複数行の CREATE ステートメントをより快適に使用するために、BigQuery SQL エディタを使用していることを前提とします。
複数行の CREATE ステートメントをより快適に使用するために、BigQuery SQL エディタを使用していることを前提とします。 cymbal_pets_demoデータセットを作成します。
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
order_items、products、orders、stores、customers、co_related_products_for_angelicaのテーブルを作成します。これらのテーブルは、グラフのソースデータとして使用されます。
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date DATE,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
)
PARTITION BY order_date
CLUSTER BY order_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
これで、グラフデータの構造が定義されました。
4. データを読み込む
次に、Cloud Storage のサンプルデータを使用してテーブルにデータを入力します。
BigQuery SQL エディタで次の LOAD DATA ステートメントを実行します。
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
各テーブルに行が読み込まれたことを示す確認メッセージが表示されます。
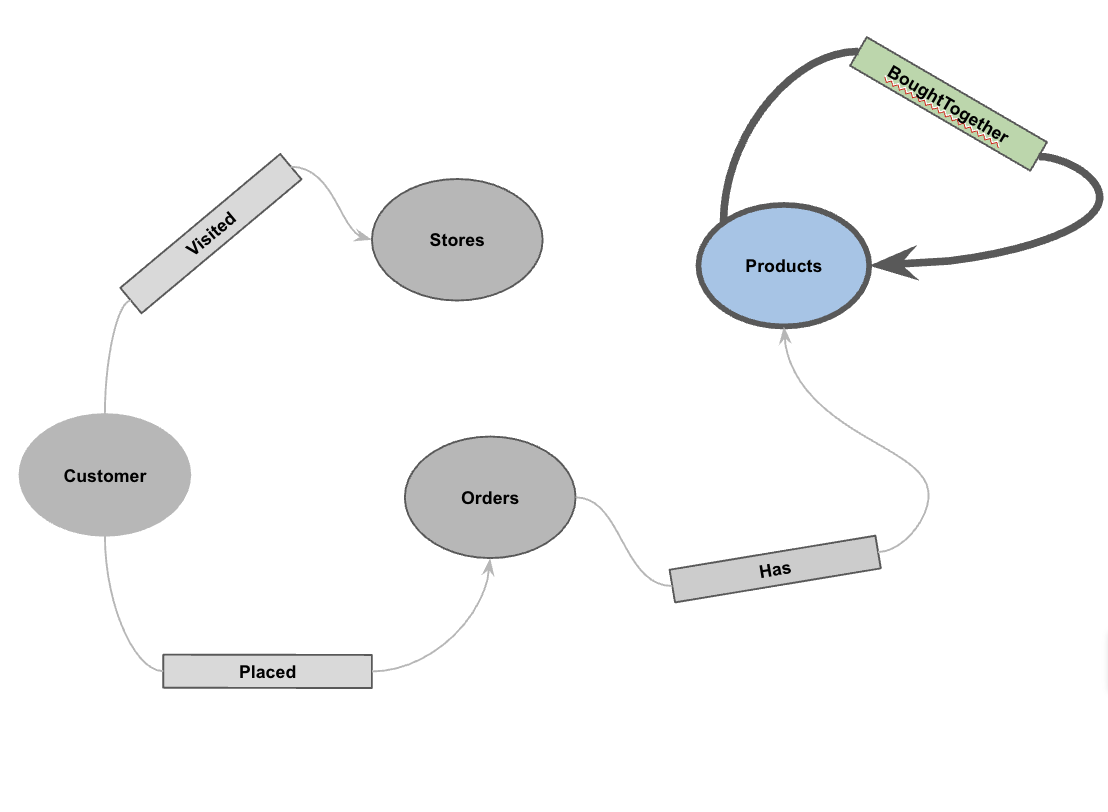
5. プロパティ グラフを作成する
データを読み込んだら、プロパティ グラフを定義できます。これにより、どのテーブルがノード(顧客、商品などのエンティティ)を表し、どのテーブルがエッジ(「アクセスした」、「注文した」、「所有している」などの関係)を表すかを BigQuery に伝えます。
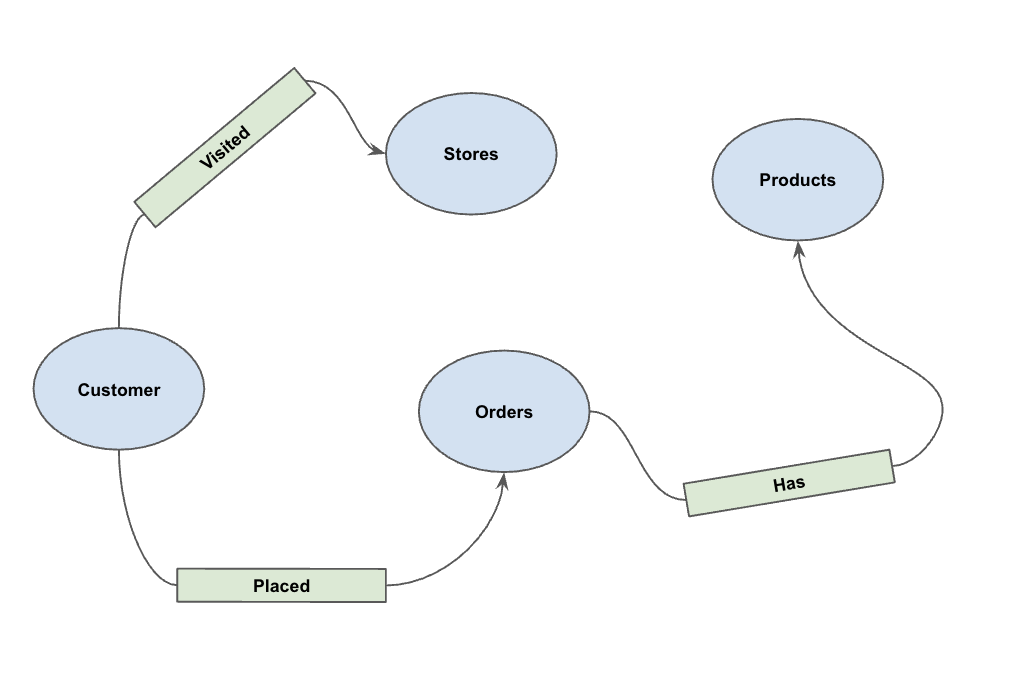
次の DDL ステートメントを実行します。
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
これにより、GRAPH_TABLE 演算子を使用してグラフ走査を実行できるグラフ PetsOrderGraph が作成されます。
6. すべての顧客の購入履歴を可視化する
BigQuery Studio で [新しいノートブック] を開きます。
この Codelab の可視化と推奨事項の部分では、BigQuery Studio の Google Colab ノートブックを使用します。これにより、グラフの結果を簡単に可視化できます。
次のコードをコードセルに貼り付けます。
!pip install bigquery-magics==0.12.1
BigQuery Graph Notebook は IPython Magics として実装されています。TO_JSON 関数で %%bigquery マジック コマンドを追加すると、次のセクションに示すように結果を可視化できます。
たとえば、Cymbal Pets が、特定の期間内に購入したすべての顧客の 360 度の可視化を取得したいとします。
新しいセルで以下を実行します。
%%bigquery --graph
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
グラフの結果が視覚的に表示されます。

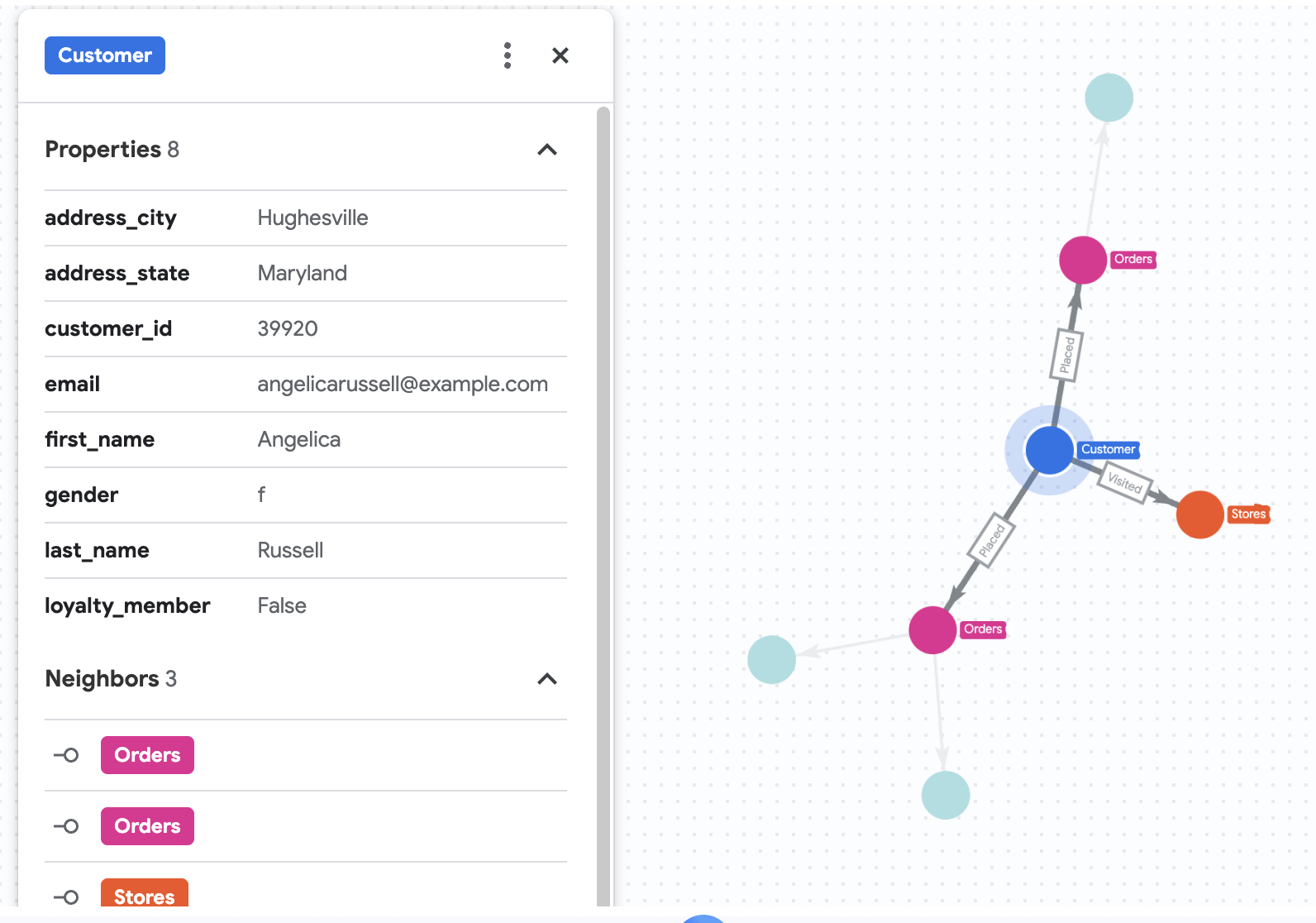
7. Angelica の購入履歴を可視化する
Cymbal Pets は、Angelica Russell という顧客について詳しく調べたいと考えています。Angelica が過去 3 か月以内に購入した商品と、お客様が来店した店舗を分析したいと考えています。
%%bigquery --graph
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
8. ベクトル検索を使用した商品レコメンデーション
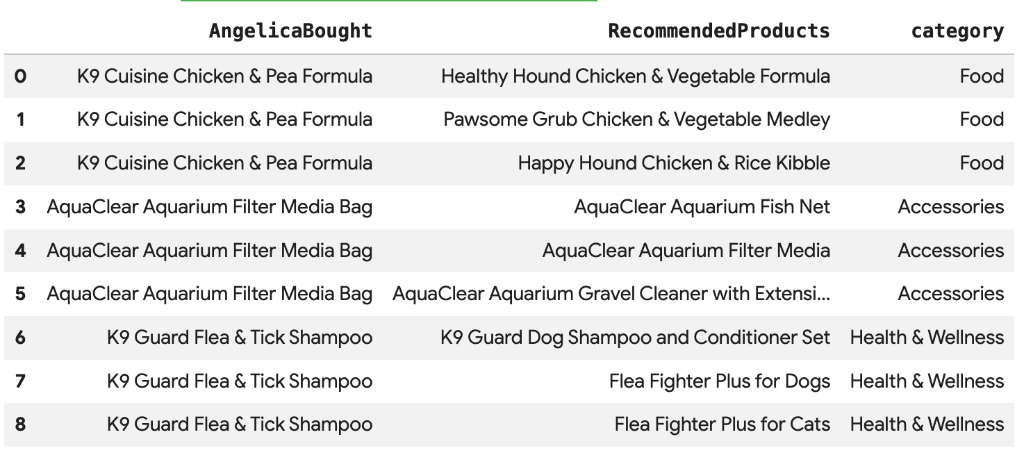
Cymbal Pets は、Angelica が最近購入した商品に基づいて、おすすめの商品を提案したいと考えています。ベクトル検索を使用して、過去の購入履歴と類似したエンベディングを持つ商品を検索できます。
新しい Colab セルで次の SQL スクリプトを実行します。このスクリプトは次のようになります。
- Angelica が最近購入した商品を特定します。
VECTOR_SEARCHを使用して、productsテーブルから上位 4 つの類似商品を検索します。
注: この手順では、AI.GENERATE_EMBEDDINGS を実行して、商品テーブルにエンベディング列を作成済みであることを前提としています。
%%bigquery
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
Angelica が購入した商品と意味的に類似した推奨商品のリストが表示されます。
9. 「一緒に購入された商品」とジャカード類似度を使用したおすすめ
もう 1 つの強力なレコメンデーション手法は「協調フィルタリング」です。これは、他のユーザーがよく一緒に購入する商品を推奨する手法です。
これらの商品は、顧客から購入した商品、その商品を購入した他の顧客、その顧客が購入した他の商品へとグラフをたどることで見つけることができます。
ジャカード類似度による人気バイアスの克服
同時購入の生カウントは有用ですが、人気商品に偏る可能性があります。非常に人気のある商品は、偶然にも多くの商品と一緒に購入される可能性があります。
ジャカード類似度では、同時購入数を正規化することで、レコメンデーションをさらに一歩進めています。2 つのセット(この場合は、各商品を含む注文のセット)間の類似度を測定します。
ジャカード類似度の式は次のとおりです。

各要素の意味は次のとおりです。
- A intersect B は、商品 A と商品 B の両方を含む注文の数(同時購入数)です。
- A は、商品 A を含む注文の合計数です。
- B は、商品 B を含む注文の合計数です。
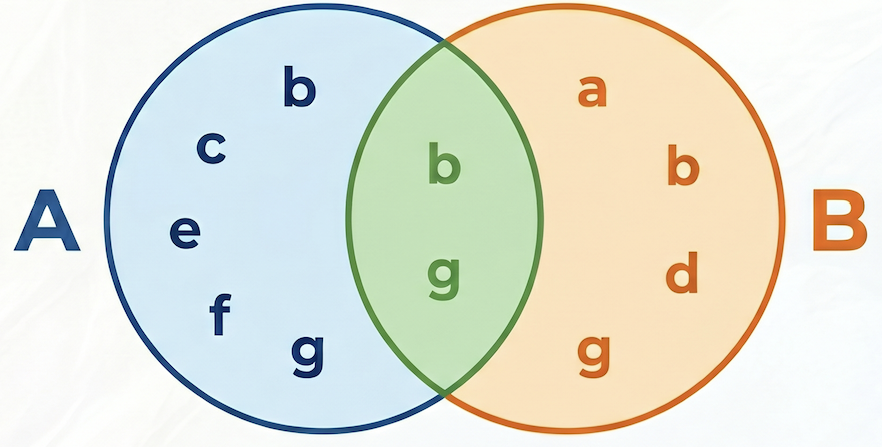
次の例では、集合 A = {b,c,e,f,g}、集合 B = {a,d,b,g}、それらの積集合 A⋂B = {b,g}、それらの和集合 A⋃B = {a,b,c,d,e,f,g} であるため、A と B の間の Jaccard 類似度は 2 / 7 = 0.285714 になります。
候補の生成と再ランキング
大規模なデータセットで動作する実際のレコメンデーション システムでは、考えられるすべての商品のペアに対して複雑な類似度スコア(Jaccard など)を計算することは非現実的であることがよくあります。代わりに、一般的なパターンは 2 段階のアプローチを使用することです。
- 候補の生成: 単純で高速な指標(同時購入の生カウントなど)を使用して検索スペースをフィルタし、管理可能な数の候補(上位 10 個など)を見つけます。
- 再ランキング: より正確だが計算負荷の高い指標(ジャカード類似度など)を適用して、候補の小さなセットをランク付けし、最終的な上位の推奨事項を選択します。
この Codelab では、次のパターンを使用します。
- ステージ 1: クエリを実行して、各商品の同時購入数の生データに基づいて、同時購入された上位 10 個の商品を特定し、テーブルに保存します。
- ステージ 2: グラフクエリを使用してこれらの候補を取得し、ジャカード類似度でランク付けして、上位 3 件を返します。
[!WARNING] 欠点: ステージ 1 で生カウントをフィルタリングすると、非常に具体的で頻度の低い同時購入の「再現率」が低下する可能性があります。ある商品が別の商品と非常に類似しているものの、どちらも購入される頻度が低い場合、上位 10 個の候補に選ばれず、見逃される可能性があります。
次のクエリを実行して、未加工の同時購入数と Jaccard 類似度の両方を計算し、未加工の数で上位 10 件の候補を保存します。
%%bigquery
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
このクエリを実行すると、BoughtTogether エッジを介して直接接続された Angelica の購入ごとに上位 3 つの商品が推奨され、同時購入数と Jaccard 類似度の両方が表示されます。
%%bigquery
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
このクエリは、顧客 -> 注文 -> 商品 -> (同時購入) -> おすすめ商品という順に移動し、購入行動の集合に基づいておすすめを表示し、類似度スコアを取得します。

10. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、この Codelab で作成したリソースを削除します。
データセットとすべてのテーブルを削除します。
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
この Codelab 用に新しいプロジェクトを作成した場合は、そのプロジェクトを削除することもできます。
gcloud projects delete $PROJECT_ID
11. 完了
おめでとうございます!BigQuery グラフを使用して、顧客の 360 度ビューとレコメンデーション エンジンを正常に構築できました。
学習した内容
- BigQuery でプロパティ グラフを作成する方法。
- グラフのノードとエッジにデータを読み込む方法。
GRAPH_TABLEとMATCHを使用してグラフパターンをクエリする方法。- グラフクエリとベクトル検索を組み合わせてハイブリッド レコメンデーションを行う方法。
次のステップ
- BigQuery Graph のドキュメントをご覧ください。
- BigQuery のベクトル検索の詳細を確認する。