
1. Wprowadzenie
W tym ćwiczeniu dowiesz się, jak używać BigQuery Graph do tworzenia widoku klienta 360 i silnika rekomendacji dla Cymbal Pets, fikcyjnej firmy handlowej. Wykorzystasz możliwości SQL do tworzenia, wysyłania zapytań i analizowania danych grafu bezpośrednio w BigQuery, łącząc je z wyszukiwaniem wektorowym w celu uzyskania zaawansowanych rekomendacji produktów.
BigQuery Graph umożliwia modelowanie relacji między encjami danych (takimi jak klienci, produkty i zamówienia) w postaci grafu, co ułatwia odpowiadanie na złożone pytania dotyczące zachowań klientów i powiązań między produktami.

Jakie zadania wykonasz
- Utworzysz zbiór danych i schemat BigQuery dla grafu Cymbal Pets.
- Wczytasz przykładowe dane (klienci, produkty, zamówienia, sklepy) z Cloud Storage.
- Utworzysz graf właściwości w BigQuery, łącząc te encje.
- Zwizualizujesz historię zakupów klientów za pomocą zapytań grafu.
- Utworzysz system rekomendacji produktów za pomocą wyszukiwania wektorowego.
- Ulepszysz rekomendacje za pomocą relacji grafu „Kupione razem” i podobieństwa Jaccarda.
Czego potrzebujesz
- Przeglądarka internetowa, np. Chrome.
- Projekt Google Cloud z włączonymi płatnościami.
To ćwiczenie jest przeznaczone dla deweloperów na wszystkich poziomach zaawansowania, w tym dla początkujących.
2. Zanim zaczniesz
Utwórz projekt Google Cloud
- W konsoli Google Cloud wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie w chmurze włączone są płatności.
Uruchamianie Cloud Shell
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.
- Sprawdź uwierzytelnianie:
gcloud auth list
- Potwierdź wybór projektu:
gcloud config get project
- W razie potrzeby ustaw projekt:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Włącz interfejsy API
Aby włączyć wymagany interfejs BigQuery API, uruchom to polecenie:
gcloud services enable bigquery.googleapis.com
3. Określ schemat
Najpierw musisz utworzyć zbiór danych, w którym będą przechowywane tabele związane z grafem, i określić schemat węzłów i krawędzi.
- W tym ćwiczeniu będziemy wykonywać polecenia SQL. Możesz uruchamiać te polecenia w BigQuery Studio > Edytorze SQL lub użyć polecenia
bq queryw Cloud Shell. Zakładamy, że używasz edytora SQL BigQuery , aby wygodniej tworzyć instrukcje wielowierszowe.
Zakładamy, że używasz edytora SQL BigQuery , aby wygodniej tworzyć instrukcje wielowierszowe. - Utwórz zbiór danych
cymbal_pets_demo:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- Utwórz tabele
order_items,products,orders,stores,customers, ico_related_products_for_angelica. Te tabele będą służyć jako źródło danych dla naszego grafu.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
Strukturę danych grafu masz już zdefiniowaną.
4. Wczytaj dane
Teraz wypełnij tabele przykładowymi danymi z Cloud Storage.
W edytorze SQL BigQuery uruchom te instrukcje LOAD DATA:
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
Powinno pojawić się potwierdzenie, że w każdym wierszu wczytano wiersze.
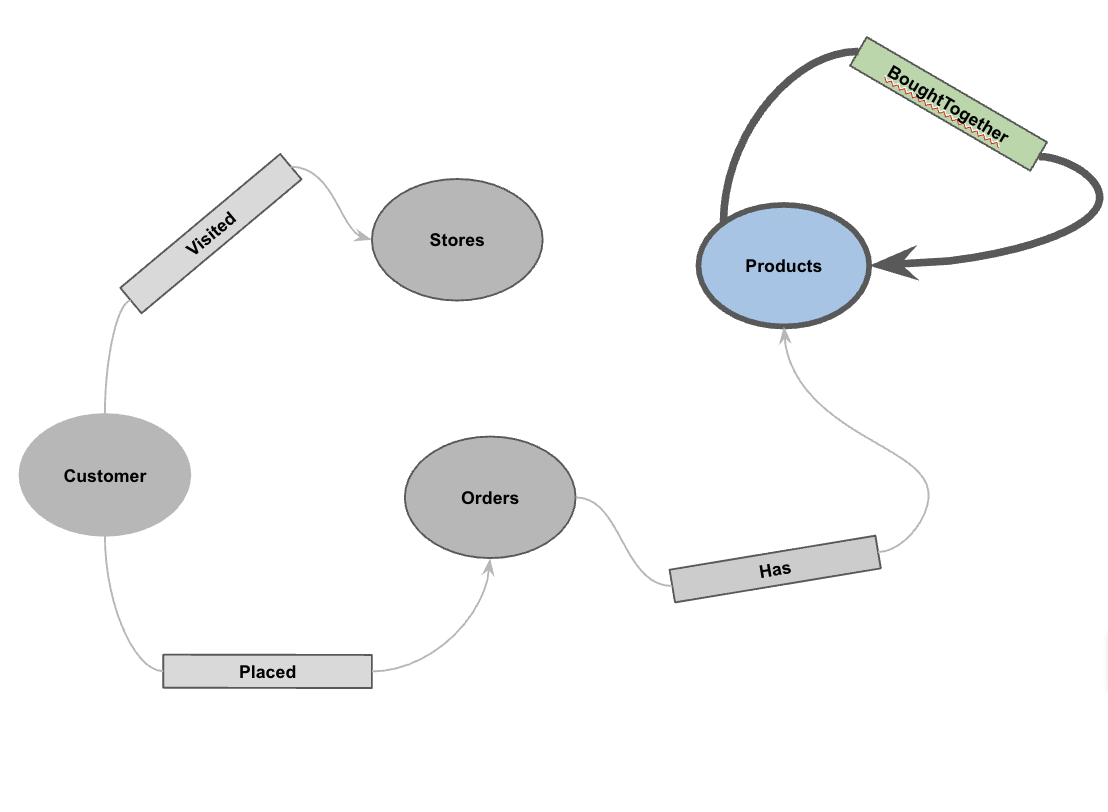
5. Utwórz graf właściwości
Po wczytaniu danych możesz zdefiniować graf właściwości. Informuje on BigQuery, które tabele reprezentują węzły (encje takie jak klienci i produkty), a które tabele reprezentują krawędzie (relacje takie jak „Odwiedził”, „Złożył”, „Ma”).
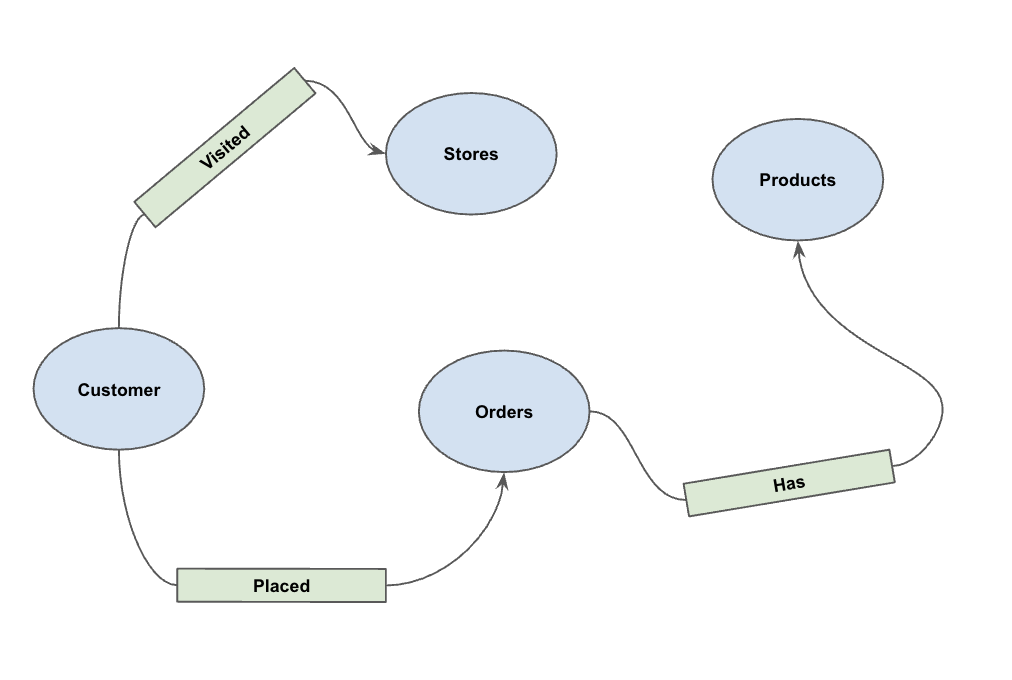
Uruchom tę instrukcję DDL:
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
Spowoduje to utworzenie grafu PetsOrderGraph, który umożliwia przechodzenie po grafie za pomocą operatora GRAPH_TABLE.
6. Wizualizacja historii zakupów wszystkich klientów
W części tego ćwiczenia dotyczącej wizualizacji i rekomendacji będziemy używać natywnej wizualizacji grafu w BigQuery Studio. Umożliwia to łatwe wizualizowanie wyników grafu.
Możesz też wizualizować dane w BigQuery Graph Notebook za pomocą IPython Magics. Dodając polecenie magiczne %%bigquery z funkcją TO_JSON, możesz wizualizować wyniki tak jak w sekcjach poniżej.
Załóżmy, że Cymbal Pets chce uzyskać wizualizację 360 stopni wszystkich klientów i ich zakupów w określonym przedziale czasu.
W nowej karcie BigQuery Studio uruchom to polecenie:
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
Aby wizualizować wyniki, w panelu Wyniki zapytania kliknij Graf.

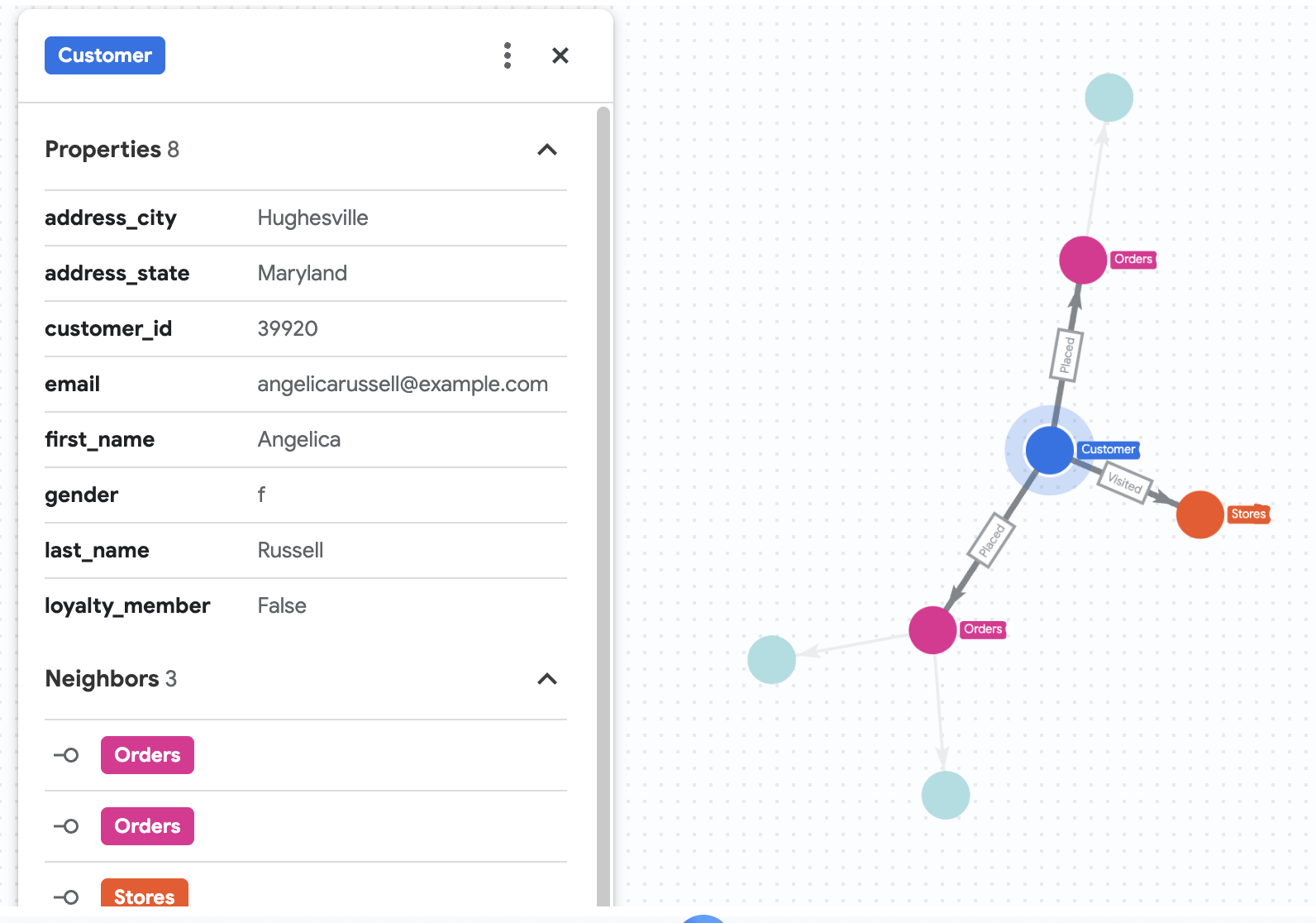
7. Wizualizacja historii zakupów Angeliki
Załóżmy, że Cymbal Pets chce szczegółowo przeanalizować dane klientki o imieniu Angelika Russell. Firma chce przeanalizować produkty, które Angelika kupiła w ciągu ostatnich 3 miesięcy, oraz sklepy, które odwiedziła.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
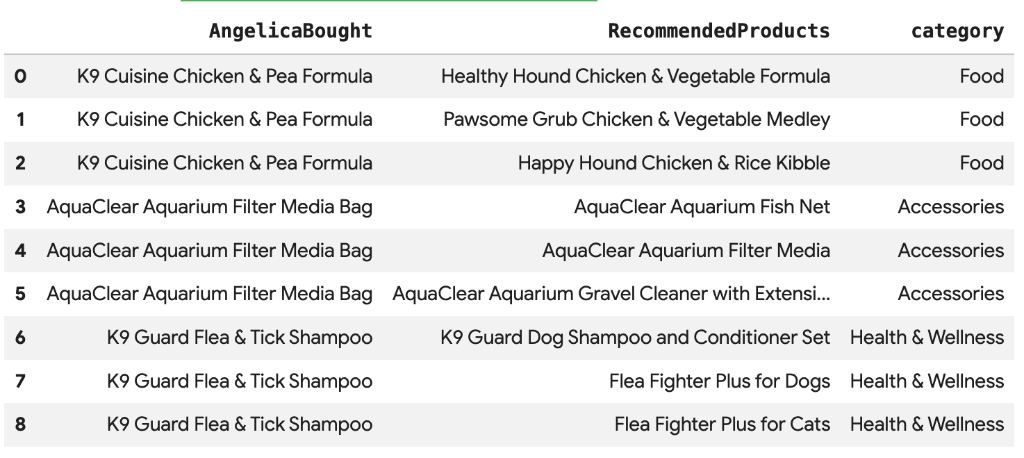
8. Rekomendacje produktów za pomocą wyszukiwania wektorowego
Cymbal Pets chce polecać Angelice produkty na podstawie tego, co ostatnio kupiła. Możemy użyć wyszukiwania wektorowego , aby znaleźć produkty z podobnymi wektorami dystrybucyjnymi do jej poprzednich zakupów.
W nowej komórce Colab uruchom ten skrypt SQL. Ten skrypt:
- Identyfikuje produkty, które Angelika kupiła ostatnio.
- Używa funkcji
VECTOR_SEARCHdo znajdowania 4 najbardziej podobnych produktów z tabeliproducts.
Uwaga: ten krok zakłada, że masz już uruchomioną funkcję AI.GENERATE_EMBEDDINGS, aby utworzyć kolumnę wektorów dystrybucyjnych w tabeli produktów.
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
Powinna się wyświetlić lista polecanych produktów, które są semantycznie podobne do tego, co kupiła Angelika.
9. Rekomendacje na podstawie „Kupionych razem” i podobieństwa Jaccarda
Inną skuteczną techniką rekomendacji jest „filtrowanie oparte na współpracy” – polecanie produktów, które są często kupowane razem przez innych użytkowników.
Możemy znaleźć te produkty, przechodząc po grafie od klienta do kupionych przez niego produktów, a następnie do innych klientów, którzy kupili te produkty, i wreszcie do innych produktów, które ci klienci kupili.
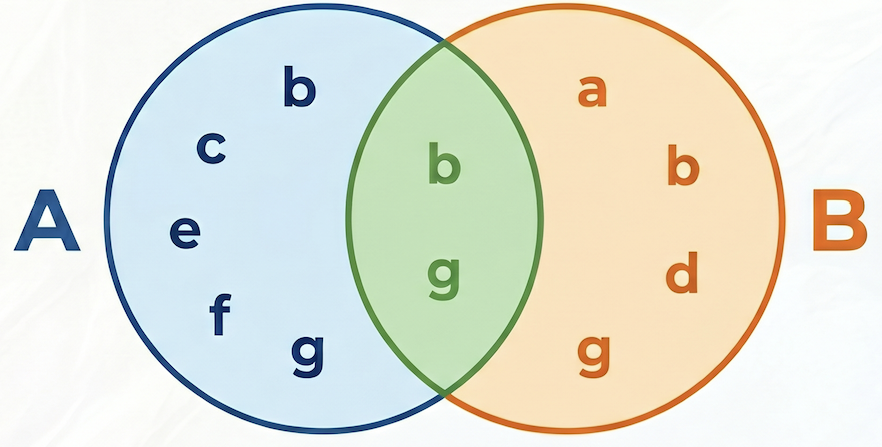
Eliminowanie błędu popularności za pomocą podobieństwa Jaccarda
Surowe liczby wspólnych zakupów są przydatne, ale mogą być obciążone w kierunku popularnych produktów. Bardzo popularny produkt może być kupowany z wieloma innymi produktami przypadkowo.
Podobieństwo Jaccarda przenosi rekomendacje na wyższy poziom, normalizując liczbę wspólnych zakupów. Mierzy podobieństwo między 2 zbiorami (w tym przypadku zbiorami zamówień zawierających każdy produkt).
Wzór na podobieństwo Jaccarda:

Gdzie:
- A intersect B to liczba zamówień zawierających zarówno produkt A, jak i produkt B (liczba wspólnych zakupów).
- A to łączna liczba zamówień zawierających produkt A.
- B to łączna liczba zamówień zawierających produkt B.
W tym przykładzie zbiór A = {b, c,e,f,g}, zbiór B = {a,d,b,g}, ich przecięcie A⋂B = {b,g}, ich suma A⋃B = {a,b,c,d,e,f,g}, a zatem podobieństwo Jaccarda między A i B wynosi 2 / 7 = 0,285714.
Generowanie kandydatów i ponowne ocenianie
W systemach rekomendacji działających na ogromnych zbiorach danych często nie można obliczyć złożonych wyników podobieństwa (takich jak Jaccard) dla wszystkich możliwych par produktów. Zamiast tego stosuje się zwykle podejście dwuetapowe:
- Generowanie kandydatów: użyj prostej i szybkiej miary (np.surowej liczby wspólnych zakupów), aby przefiltrować przestrzeń wyszukiwania i znaleźć odpowiednią liczbę kandydatów (np. 10 najlepszych).
- Ponowne ocenianie: zastosuj dokładniejszą, ale bardziej wymagającą obliczeniowo miarę (np. podobieństwo Jaccarda), aby ocenić ten niewielki zbiór kandydatów i wybrać ostateczne najlepsze rekomendacje.
W tym ćwiczeniu będziemy postępować zgodnie z tym wzorcem:
- Etap 1: uruchom zapytanie, aby znaleźć 10 najczęściej kupowanych razem produktów dla każdego produktu na podstawie surowej liczby wspólnych zakupów i zapisać je w tabeli.
- Etap 2: użyj zapytania grafu, aby pobrać tych kandydatów, ocenić ich według podobieństwa Jaccarda i zwrócić 3 najlepsze.
[!WARNING] Wada: filtrując według surowej liczby na etapie 1, możemy utracić "czułość" w przypadku bardzo konkretnych, ale rzadkich wspólnych zakupów. Jeśli produkt jest bardzo podobny do innego, ale oba są rzadko kupowane, może nie znaleźć się w 10 najlepszych kandydatach i zostanie pominięty.
Aby obliczyć zarówno surową liczbę wspólnych zakupów, jak i podobieństwo Jaccarda, i zapisać 10 najlepszych kandydatów według surowej liczby, uruchom to zapytanie:
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
Aby polecić 3 najlepsze produkty dla każdego zakupu Angeliki, połączone bezpośrednio krawędzią BoughtTogether, i wyświetlić zarówno liczbę wspólnych zakupów, jak i podobieństwo Jaccarda, uruchom to zapytanie:
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
To zapytanie przechodzi od klienta -> zamówienia -> produktu -> (Kupione razem) -> polecanego produktu, wyświetlając rekomendacje na podstawie zbiorowego zachowania zakupowego i pobierając wyniki podobieństwa.

10. Zwalnianie miejsca
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone podczas tego ćwiczenia.
Usuń zbiór danych i wszystkie tabele:
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
Jeśli na potrzeby tego ćwiczenia został przez Ciebie utworzony nowy projekt, możesz go też usunąć:
gcloud projects delete $PROJECT_ID
11. Gratulacje
Gratulacje! Udało Ci się utworzyć widok klienta 360 i silnik rekomendacji za pomocą BigQuery Graph.
Czego się nauczysz
- Jak utworzyć graf właściwości w BigQuery.
- Jak wczytywać dane do węzłów i krawędzi grafu.
- Jak wysyłać zapytania dotyczące wzorców grafu za pomocą funkcji
GRAPH_TABLEiMATCH. - Jak łączyć zapytania grafu z wyszukiwaniem wektorowym w celu uzyskania rekomendacji hybrydowych.
Dalsze kroki
- Zapoznaj się z dokumentacją BigQuery Graph.
- Dowiedz się więcej o wyszukiwaniu wektorowym w BigQuery.