
1. Введение
В этом практическом занятии вы научитесь использовать BigQuery Graph для создания представления «360 градусов о клиенте» и системы рекомендаций для вымышленной розничной компании Cymbal Pets. Вы будете использовать возможности SQL для создания, запроса и анализа данных графа непосредственно в BigQuery, сочетая его с векторным поиском для получения расширенных рекомендаций по товарам.
BigQuery Graph позволяет моделировать взаимосвязи между вашими сущностями данных (такими как клиенты, товары и заказы) в виде графа, что упрощает ответы на сложные вопросы о поведении клиентов и их предпочтениях в отношении товаров.

Что вы будете делать
- Создайте набор данных и схему BigQuery для графа Cymbal Pets.
- Загрузите примеры данных (клиенты, товары, заказы, магазины) из облачного хранилища.
- Создайте в BigQuery граф свойств, соединяющий эти сущности.
- Визуализация истории покупок клиентов с помощью графовых запросов.
- Создайте систему рекомендаций товаров с использованием векторного поиска.
- Улучшите рекомендации, используя взаимосвязи в графе "Покупаются вместе" и коэффициент сходства Жаккара.
Что вам понадобится
- Веб-браузер, например Chrome.
- Проект Google Cloud с включенной функцией выставления счетов.
Этот практический семинар предназначен для разработчиков всех уровней, включая начинающих.
2. Прежде чем начать
Создайте проект в Google Cloud.
- В консоли Google Cloud выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов.
Запустить Cloud Shell
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» .
- Проверка подлинности:
gcloud auth list
- Подтвердите свой проект:
gcloud config get project
- При необходимости установите значение:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Включить API
Выполните эту команду, чтобы включить необходимый API BigQuery:
gcloud services enable bigquery.googleapis.com
3. Определите схему.
Во-первых, вам необходимо создать набор данных для хранения таблиц, связанных с вашим графом, и определить схему для ваших узлов и ребер.
- В этом практическом занятии мы будем выполнять команды SQL. Вы можете запустить эти команды в BigQuery Studio > SQL Editor или использовать команду
bq queryв Cloud Shell. Для удобства работы с многострочными операторами создания запросов мы будем исходить из того, что вы используете редактор SQL BigQuery .
Для удобства работы с многострочными операторами создания запросов мы будем исходить из того, что вы используете редактор SQL BigQuery . - Создайте набор данных
cymbal_pets_demo:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- Создайте таблицы для
order_items,products,orders,stores,customersиco_related_products_for_angelica. Эти таблицы будут служить исходными данными для нашего графа.
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
Теперь вы определили структуру данных для вашего графа.
4. Загрузите данные
Теперь заполните таблицы примерами данных из облачного хранилища.
Выполните следующие операторы LOAD DATA в SQL-редакторе BigQuery:
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
Вы должны увидеть подтверждение того, что строки загружены в каждую таблицу.
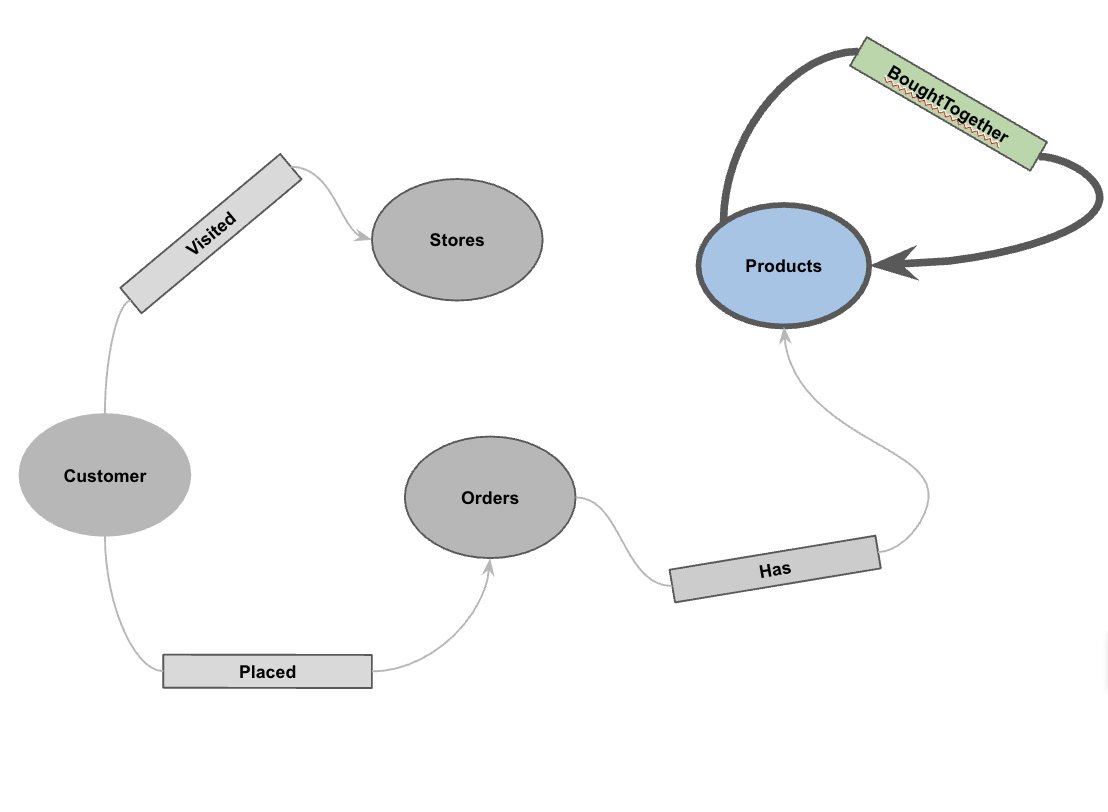
5. Создайте граф свойств.
После загрузки данных вы можете определить граф свойств . Это указывает BigQuery, какие таблицы представляют узлы (сущности, такие как «Клиенты», «Продукты»), а какие — ребра (связи, такие как «Посещено», «Размещено», «Имеет»).
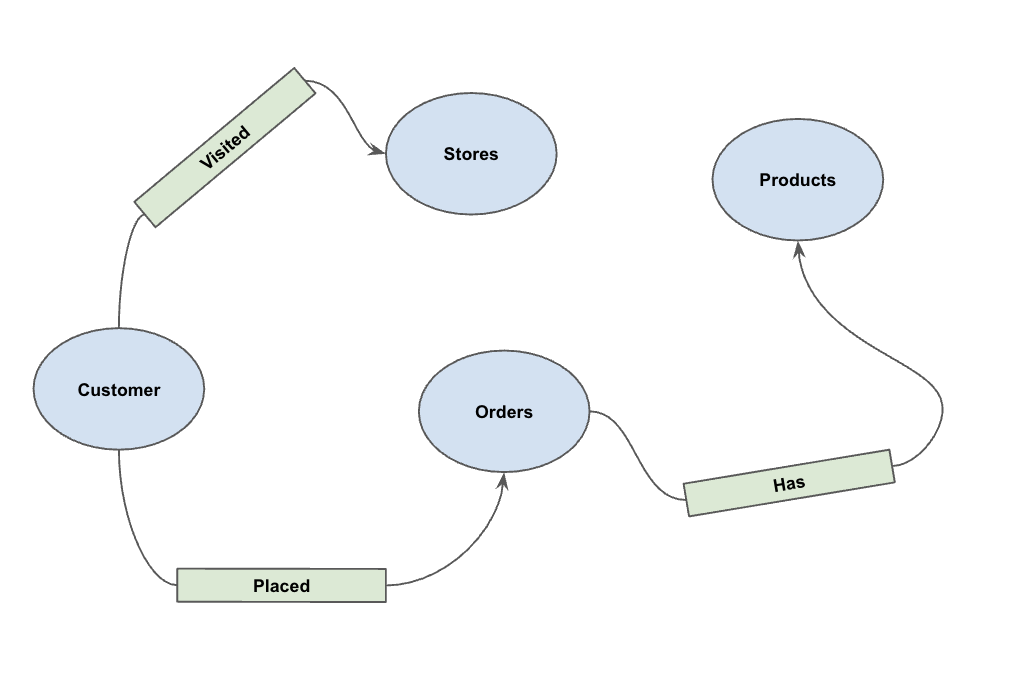
Выполните следующую инструкцию DDL:
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
Это создаёт граф PetsOrderGraph , который позволяет нам выполнять обход графа с помощью оператора GRAPH_TABLE .
6. Визуализация истории покупок всех клиентов.
Для визуализации и рекомендаций в рамках этого практического занятия мы будем использовать встроенную функцию визуализации графов в BigQuery Studio. Это позволит нам легко визуализировать результаты работы с графами.
В качестве альтернативы, вы можете визуализировать данные в BigQuery Graph Notebook, используя магические команды IPython. Добавив команду магической команды %%bigquery с функцией TO_JSON , вы можете визуализировать результаты, как показано в следующих разделах.
Допустим, компания Cymbal Pets хочет получить 360-градусную визуализацию всех клиентов и совершенных ими покупок за определенный промежуток времени.
Выполните следующие действия в новой вкладке BigQuery Studio:
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
Для визуализации результатов в панели «Результаты запроса» нажмите кнопку «График».

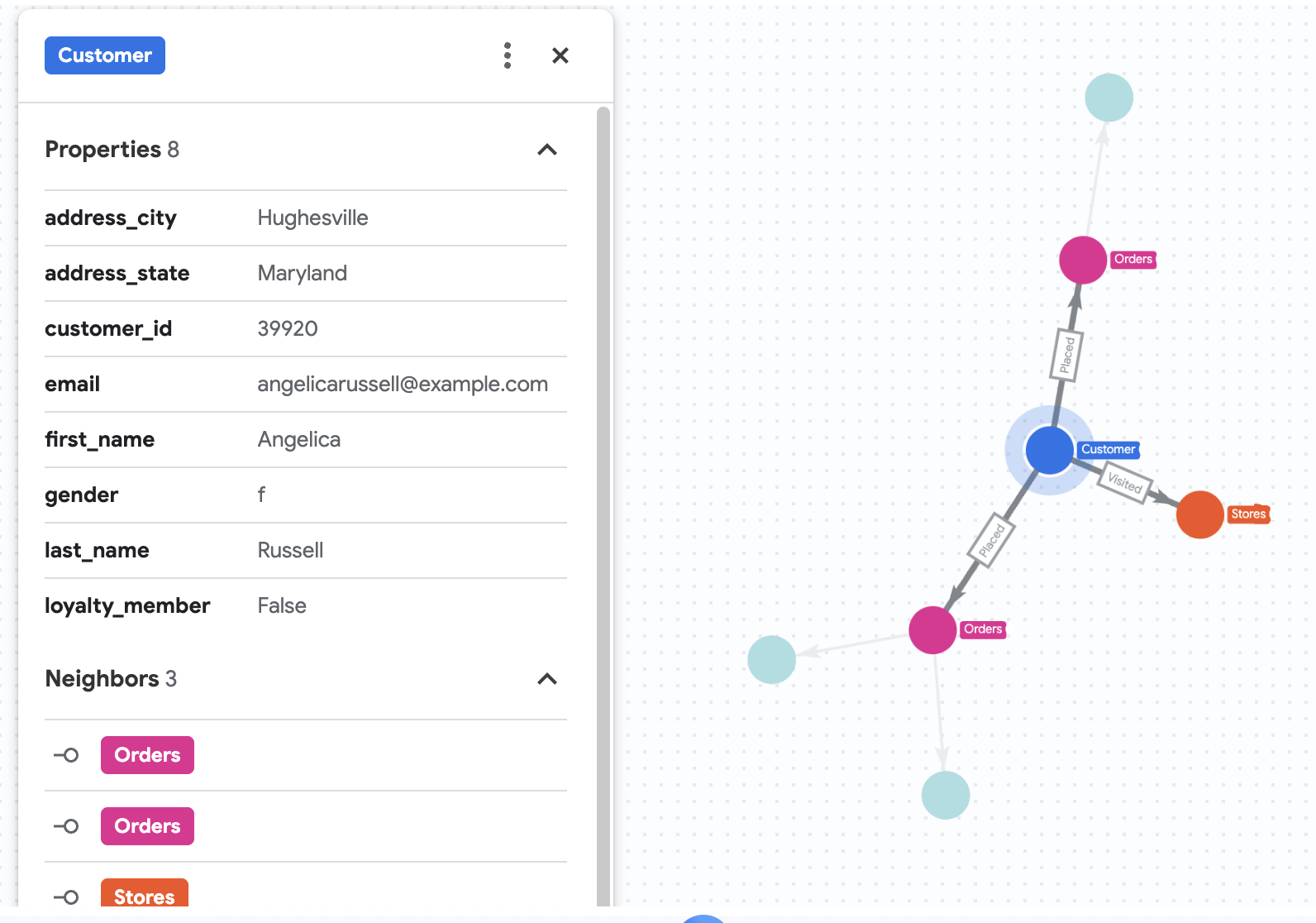
7. Визуализируйте историю покупок Анжелики.
Допустим, компания Cymbal Pets хочет детально изучить историю своей клиентки по имени Анжелика Рассел. Они хотят проанализировать товары, которые Анжелика покупала в течение последних 3 месяцев, и магазины, которые она посещала.
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
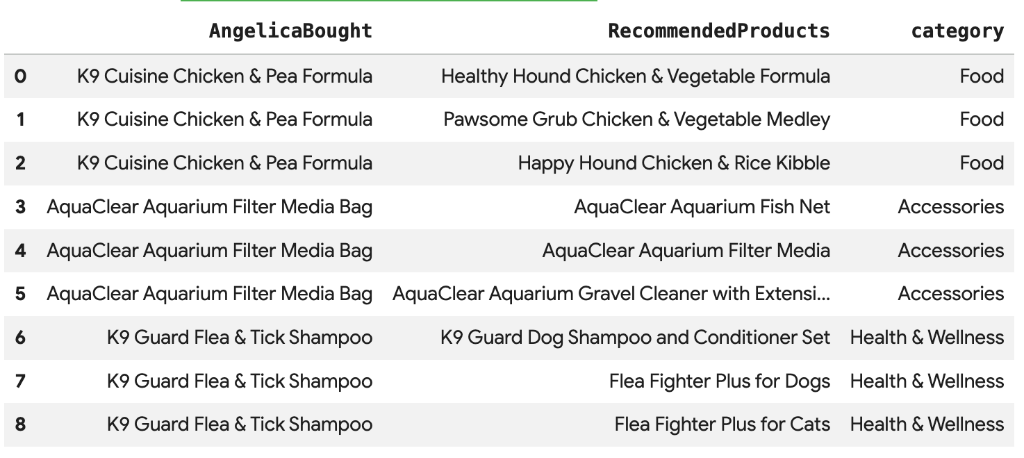
8. Рекомендации по товарам с использованием векторного поиска.
Компания Cymbal Pets хочет порекомендовать Анжелике товары, основываясь на том, что она недавно покупала. Мы можем использовать векторный поиск , чтобы найти товары с похожими характеристиками, как у ее предыдущих покупок.
Выполните следующий SQL-скрипт в новой ячейке Colab. Этот скрипт:
- Указывает на товары, которые Анжелика недавно приобрела.
- Использует
VECTOR_SEARCHдля поиска 4 наиболее похожих товаров в таблицеproducts.
Примечание: На этом шаге предполагается, что вы уже запустили AI.GENERATE_EMBEDDINGS для создания столбца с эмбеддингами в таблице продуктов.
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
Вы должны увидеть список рекомендованных товаров, семантически похожих на то, что купила Анжелика.
9. Рекомендация с использованием функции "Куплены вместе" и коэффициента сходства Жаккара.
Еще один эффективный метод рекомендаций — это «коллаборативная фильтрация», то есть рекомендация товаров, которые часто покупаются вместе другими пользователями.
Мы можем найти эти товары, пройдя по графу от покупателя к приобретенным им товарам, затем к другим покупателям, которые купили эти товары, и, наконец, к другим товарам, которые купили эти покупатели.
Преодоление предвзятости популярности с помощью коэффициента сходства Жаккара
Хотя общие данные о совместных покупках полезны, они могут быть предвзятыми в отношении популярных товаров. Очень популярный товар может быть куплен вместе со многими другими товарами совершенно случайно.
Коэффициент сходства Жаккара делает рекомендации еще на шаг вперед, нормализуя количество совместных покупок. Он измеряет сходство между двумя наборами (в данном случае, наборами заказов, содержащих каждый продукт).
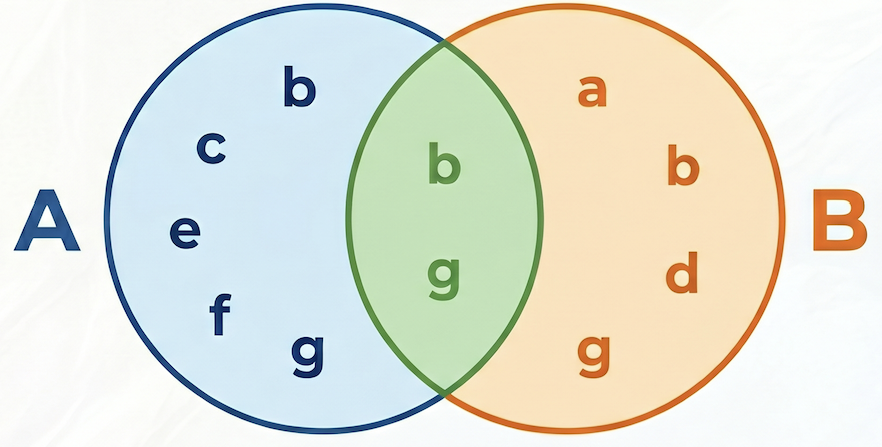
Формула для коэффициента сходства Жаккара выглядит следующим образом:

Где:
- Пересечение B — это количество заказов, содержащих как продукт A, так и продукт B (количество совместных покупок).
- А — это общее количество заказов, содержащих товар А.
- B — это общее количество заказов, содержащих продукт B.
В следующем примере множество A = {b,c,e,f,g}, множество B = {a,d,b,g}, их пересечение A⋂B = {b,g}, их объединение A⋃B = {a,b,c,d,e,f,g}, следовательно, коэффициент сходства Жаккара между A и B равен 2 / 7 = 0,285714
Формирование и переранжирование кандидатов
В реальных системах рекомендаций, работающих с огромными массивами данных, часто нецелесообразно вычислять сложные коэффициенты сходства (например, коэффициент Жаккара) для всех возможных пар товаров. Вместо этого часто используется двухэтапный подход:
- Генерация кандидатов : Используйте простой и быстрый показатель (например, общее количество совместных покупок), чтобы отфильтровать область поиска и найти приемлемое количество кандидатов (например, топ-10).
- Переранжирование : Примените более точный, но более ресурсоемкий с вычислительной точки зрения показатель (например, коэффициент Жаккара) для ранжирования этого небольшого набора кандидатов и выбора окончательных лучших рекомендаций.
В этом практическом занятии мы будем следовать следующему шаблону:
- Этап 1 : Выполните запрос для поиска 10 наиболее часто покупаемых совместно товаров для каждого продукта, основываясь на общем количестве совместных покупок, и сохраните их в таблице.
- Этап 2 : Используйте запрос к графу для получения этих кандидатов, ранжируйте их по коэффициенту сходства Жаккара и верните 3 лучших.
[!ПРЕДУПРЕЖДЕНИЕ] Недостаток : Фильтрация по общему количеству на первом этапе может привести к потере «узнаваемости» высокоспецифичных, но редко совершаемых совместных покупок. Если продукт очень похож на другой, но оба покупаются редко, он может не попасть в топ-10 кандидатов и будет пропущен.
Выполните следующий запрос, чтобы рассчитать как общее количество совместных покупок, так и коэффициент сходства Жаккара, и сохраните 10 лучших кандидатов по общему количеству:
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
Выполните этот запрос, чтобы порекомендовать 3 лучших товара для каждой из покупок Анжелики, напрямую связанных через BoughtTogether , с указанием количества совместных покупок и коэффициента сходства Жаккара:
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
Этот запрос проходит по последовательности действий: Клиент -> Заказ -> Продукт -> (Купленные вместе) -> Рекомендуемый продукт, отображая рекомендации, основанные на коллективном покупательском поведении, и извлекает показатели их сходства.

10. Уборка
Чтобы избежать дальнейших списаний средств с вашего аккаунта Google Cloud, удалите ресурсы, созданные в ходе этого практического занятия.
Удалите набор данных и все таблицы:
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
Если вы создали новый проект для этого практического занятия, вы также можете удалить существующий проект:
gcloud projects delete $PROJECT_ID
11. Поздравляем!
Поздравляем! Вы успешно создали систему представления данных о клиенте (Customer 360) и систему рекомендаций с использованием BigQuery Graph.
Что вы узнали
- Как создать граф свойств в BigQuery.
- Как загрузить данные в узлы и ребра графа.
- Как выполнять запросы к шаблонам графа с помощью
GRAPH_TABLEиMATCH. - Как объединить запросы к графам с векторным поиском для создания гибридных рекомендаций.
Следующие шаги
- Изучите документацию BigQuery Graph .
- Узнайте больше о векторном поиске в BigQuery .