
1. บทนำ
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีใช้ BigQuery Graph เพื่อสร้างมุมมองข้อมูลลูกค้าแบบครบ 360 องศาและเครื่องมือแนะนำสำหรับ Cymbal Pets ซึ่งเป็นบริษัทค้าปลีกสมมติ คุณจะใช้ประโยชน์จากความสามารถของ SQL เพื่อสร้าง ค้นหา และวิเคราะห์ข้อมูลกราฟได้โดยตรงภายใน BigQuery โดยรวมเข้ากับการค้นหาแบบเวกเตอร์เพื่อการแนะนำผลิตภัณฑ์ขั้นสูง
BigQuery Graph ช่วยให้คุณสร้างความสัมพันธ์ระหว่างเอนทิตีข้อมูล (เช่น ลูกค้า ผลิตภัณฑ์ และคำสั่งซื้อ) เป็นกราฟได้ ซึ่งจะช่วยให้ตอบคำถามที่ซับซ้อนเกี่ยวกับพฤติกรรมของลูกค้าและความสัมพันธ์ของผลิตภัณฑ์ได้ง่าย

สิ่งที่คุณต้องทำ
- สร้างชุดข้อมูลและสคีมา BigQuery สำหรับกราฟสัตว์เลี้ยง Cymbal
- โหลดข้อมูลตัวอย่าง (ลูกค้า ผลิตภัณฑ์ คำสั่งซื้อ ร้านค้า) จาก Cloud Storage
- สร้างกราฟพร็อพเพอร์ตี้ใน BigQuery ที่เชื่อมต่อเอนทิตีเหล่านี้
- แสดงภาพประวัติการซื้อของลูกค้าโดยใช้การค้นหากราฟ
- สร้างระบบการแนะนำผลิตภัณฑ์โดยใช้การค้นหาเวกเตอร์
- ปรับปรุงสินค้าแนะนำโดยใช้ความสัมพันธ์ของกราฟ "ซื้อด้วยกัน" และความคล้ายคลึงของ Jaccard
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ เช่น Chrome
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
Codelab นี้มีไว้สำหรับนักพัฒนาซอฟต์แวร์ทุกระดับ รวมถึงผู้เริ่มต้น
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว
เริ่มต้น Cloud Shell
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
- ยืนยันการตรวจสอบสิทธิ์
gcloud auth list
- ยืนยันโปรเจ็กต์
gcloud config get project
- ตั้งค่าหากจำเป็น
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
เปิดใช้ API
เรียกใช้คำสั่งนี้เพื่อเปิดใช้ BigQuery API ที่จำเป็น
gcloud services enable bigquery.googleapis.com
3. กำหนดสคีมา
ก่อนอื่น คุณต้องสร้างชุดข้อมูลเพื่อจัดเก็บตารางที่เกี่ยวข้องกับกราฟ และกำหนดสคีมาสำหรับโหนดและขอบ
- สำหรับ Codelab นี้ เราจะเรียกใช้คำสั่ง SQL คุณเรียกใช้คำสั่งเหล่านี้ได้ใน BigQuery Studio > เครื่องมือแก้ไข SQL หรือใช้คำสั่ง
bq queryใน Cloud Shell เราจะถือว่าคุณใช้โปรแกรมแก้ไข SQL ของ BigQuery เพื่อให้ได้รับประสบการณ์การใช้งานที่ดียิ่งขึ้นกับคำสั่งสร้างแบบหลายบรรทัด
เราจะถือว่าคุณใช้โปรแกรมแก้ไข SQL ของ BigQuery เพื่อให้ได้รับประสบการณ์การใช้งานที่ดียิ่งขึ้นกับคำสั่งสร้างแบบหลายบรรทัด - สร้าง
cymbal_pets_demoชุดข้อมูล
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- สร้างตารางสำหรับ
order_items,products,orders,stores,customersและco_related_products_for_angelicaตารางเหล่านี้จะใช้เป็นข้อมูลต้นทางสำหรับกราฟของเรา
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
ตอนนี้คุณได้กำหนดโครงสร้างสำหรับข้อมูลกราฟแล้ว
4. โหลดข้อมูล
ตอนนี้ ให้ป้อนข้อมูลตัวอย่างจาก Cloud Storage ลงในตาราง
เรียกใช้LOAD DATAคำสั่งต่อไปนี้ในโปรแกรมแก้ไข SQL ของ BigQuery
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
คุณจะเห็นข้อความยืนยันว่าระบบได้โหลดแถวลงในแต่ละตารางแล้ว
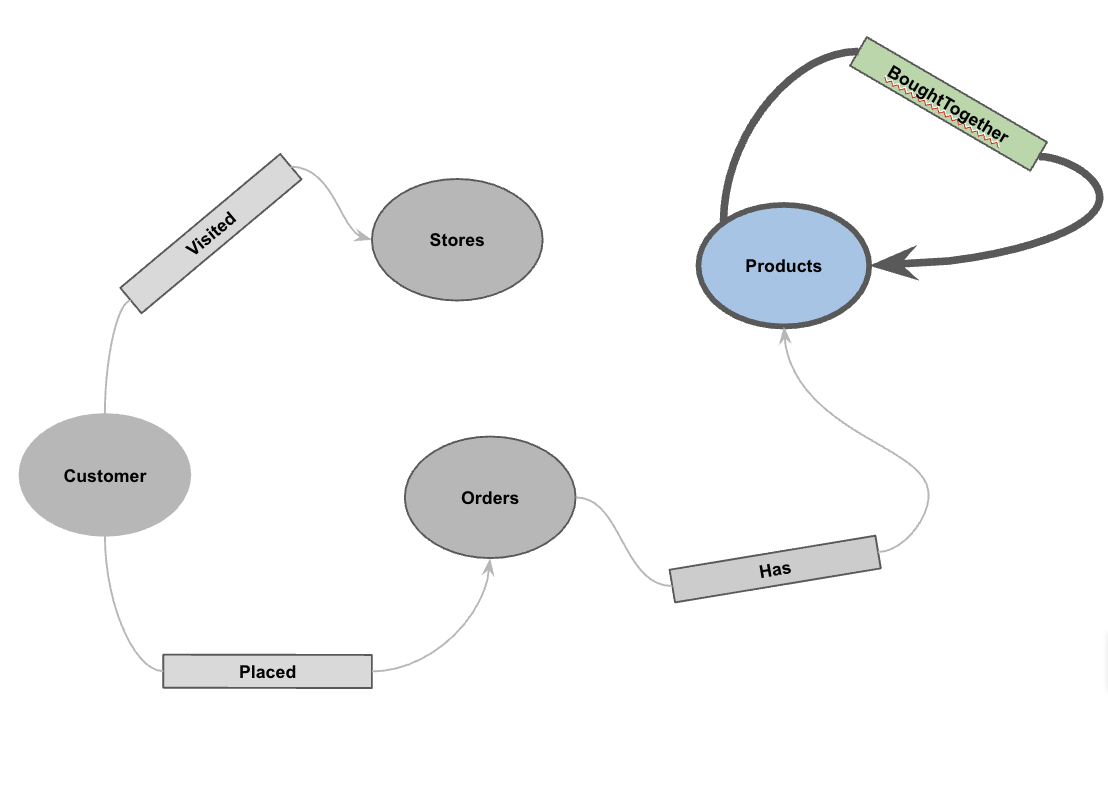
5. สร้างกราฟพร็อพเพอร์ตี้
เมื่อโหลดข้อมูลแล้ว คุณจะกำหนดกราฟเชิงคุณสมบัติได้ ซึ่งจะบอก BigQuery ว่าตารางใดแสดงโหนด (เอนทิตี เช่น ลูกค้า ผลิตภัณฑ์) และตารางใดแสดงขอบ (ความสัมพันธ์ เช่น "เข้าชม" "สั่งซื้อ" "มี")
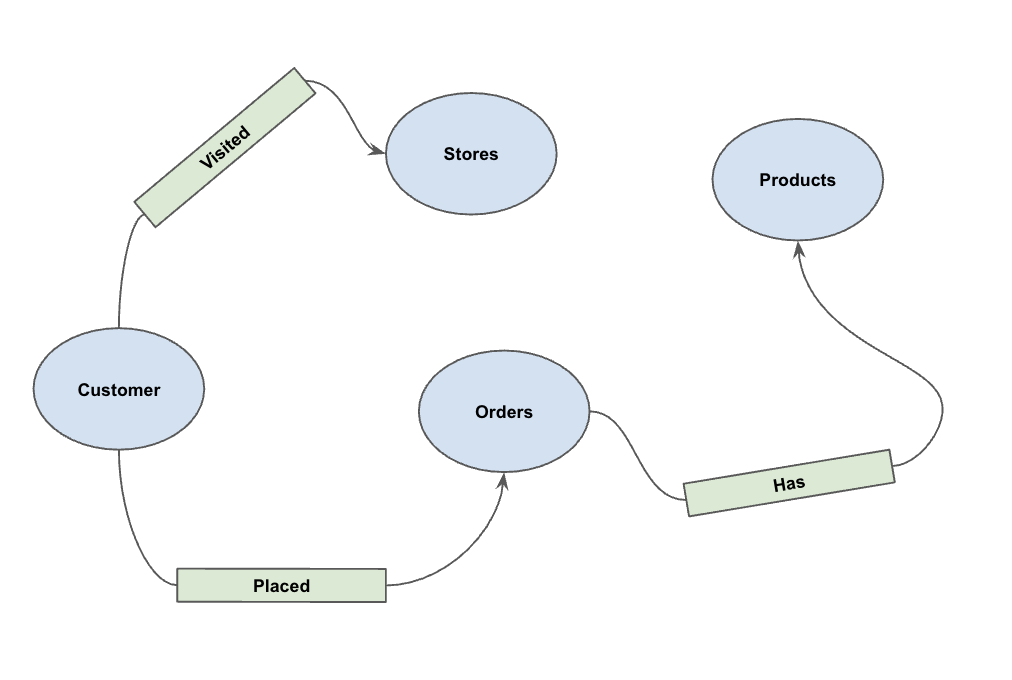
เรียกใช้คำสั่ง DDL ต่อไปนี้
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
ซึ่งจะสร้างกราฟ PetsOrderGraph ที่ช่วยให้เราสามารถดำเนินการกราฟทราเวอร์ซโดยใช้ตัวดำเนินการ GRAPH_TABLE ได้
6. แสดงภาพประวัติการซื้อของลูกค้าทั้งหมด
สำหรับส่วนการแสดงภาพและคำแนะนำของ Codelab นี้ เราจะใช้การแสดงภาพกราฟแบบเนทีฟใน BigQuery Studio ซึ่งช่วยให้เราเห็นภาพผลลัพธ์ของกราฟได้อย่างง่ายดาย
หรือจะแสดงภาพในสมุดบันทึกกราฟ BigQuery โดยใช้ IPython Magics ก็ได้ การเพิ่ม%%bigqueryคำสั่ง Magic ด้วยฟังก์ชัน TO_JSON จะช่วยให้คุณเห็นภาพผลลัพธ์ได้ตามที่แสดงในส่วนต่อไปนี้
สมมติว่า Cymbal Pets ต้องการดูภาพรวม 360 องศาของลูกค้าทั้งหมดและการซื้อที่ลูกค้าทำในช่วงเวลาที่เฉพาะเจาะจง
เรียกใช้คำสั่งต่อไปนี้ในแท็บ BigQuery Studio ใหม่
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
หากต้องการแสดงผลลัพธ์เป็นภาพ ให้คลิกกราฟในแผงผลการค้นหา

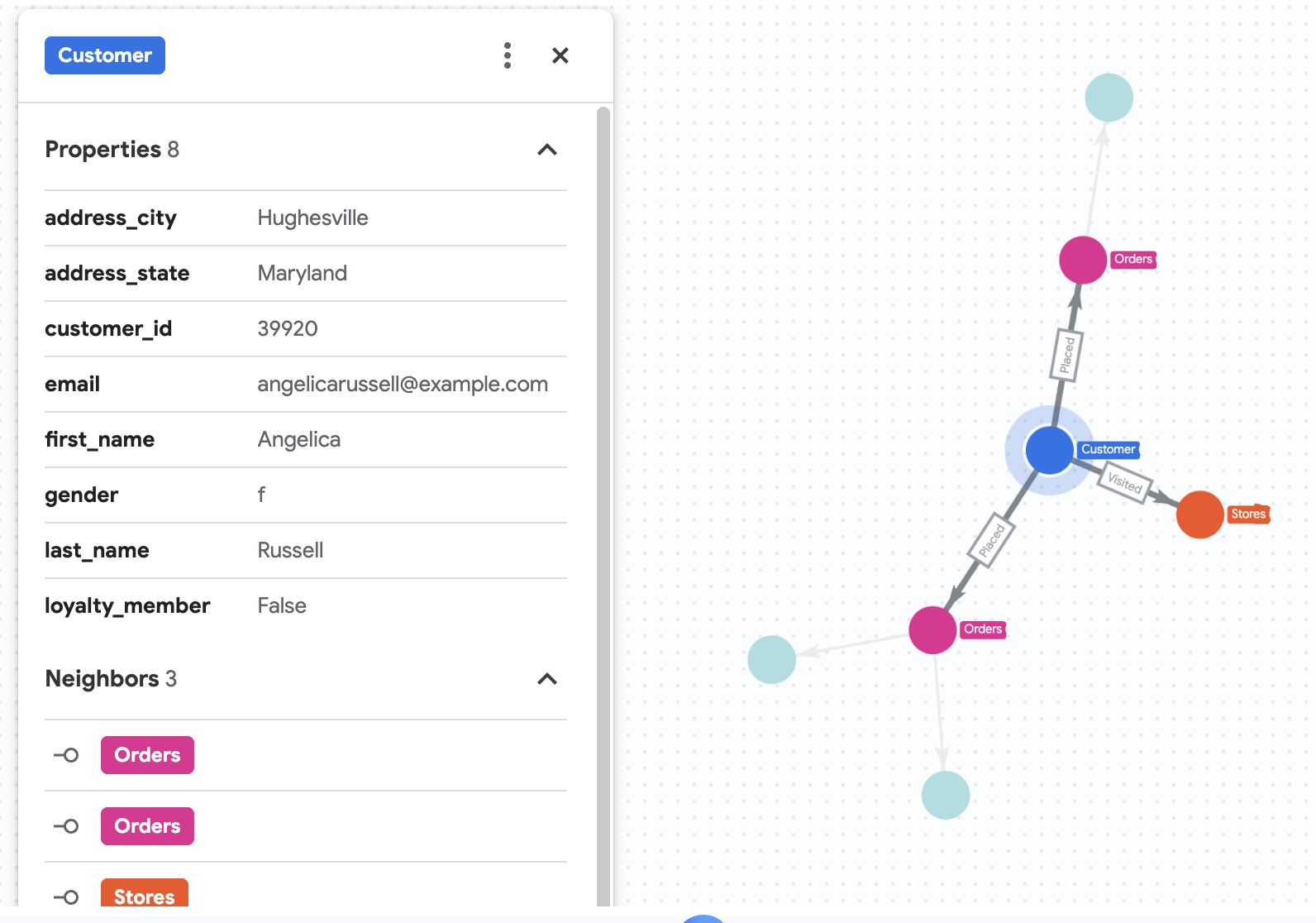
7. แสดงภาพประวัติการซื้อของ Angelica
สมมติว่า Cymbal Pets ต้องการเจาะลึกข้อมูลลูกค้าชื่อ Angelica Russell โดยต้องการวิเคราะห์ผลิตภัณฑ์ที่แอนเจลิกาซื้อในช่วง 3 เดือนที่ผ่านมา และร้านค้าที่ลูกค้าเข้าชม
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
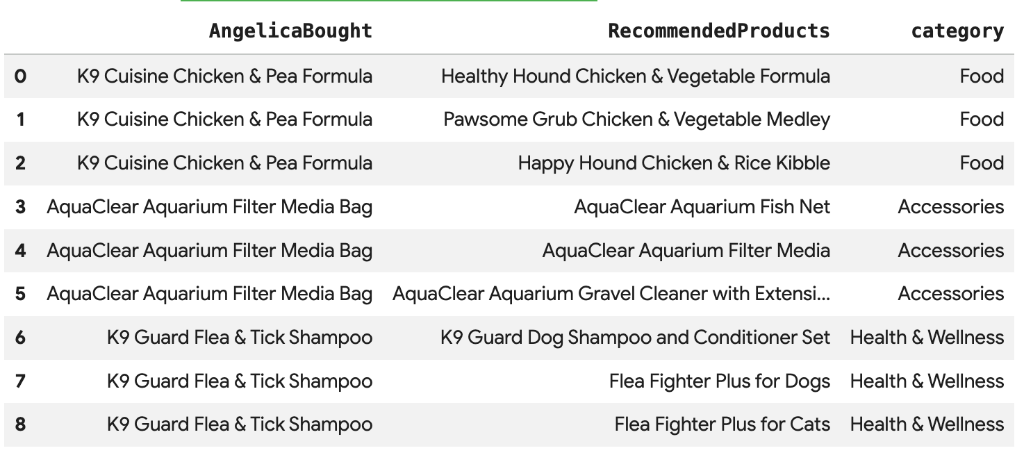
8. การแนะนำผลิตภัณฑ์โดยใช้การค้นหาเวกเตอร์
Cymbal Pets ต้องการแนะนำผลิตภัณฑ์ให้ Angelica โดยอิงตามสิ่งที่เธอซื้อล่าสุด เราสามารถใช้การค้นหาเวกเตอร์เพื่อค้นหาผลิตภัณฑ์ที่มีการฝังคล้ายกับการซื้อที่ผ่านมาของเธอ
เรียกใช้สคริปต์ SQL ต่อไปนี้ในเซลล์ Colab ใหม่ สคริปต์นี้จะทำสิ่งต่อไปนี้
- ระบุผลิตภัณฑ์ที่แอนเจลิกาซื้อเมื่อเร็วๆ นี้
- ใช้
VECTOR_SEARCHเพื่อค้นหาผลิตภัณฑ์ที่คล้ายกัน 4 รายการแรกจากตารางproducts
หมายเหตุ: ขั้นตอนนี้ถือว่าคุณได้เรียกใช้ AI.GENERATE_EMBEDDINGS เพื่อสร้างคอลัมน์การฝังในตารางผลิตภัณฑ์แล้ว
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
คุณควรเห็นรายการผลิตภัณฑ์แนะนำที่มีความหมายคล้ายกับสิ่งที่แอนเจลิกาซื้อ
9. สินค้าแนะนำโดยใช้ "ซื้อด้วยกัน" และความคล้ายคลึงของ Jaccard
เทคนิคการแนะนำที่มีประสิทธิภาพอีกอย่างคือ "การกรองร่วม" ซึ่งเป็นการแนะนำผลิตภัณฑ์ที่ผู้ใช้รายอื่นมักซื้อพร้อมกัน
เราค้นหาผลิตภัณฑ์เหล่านี้ได้โดยการสำรวจกราฟจากลูกค้าไปยังผลิตภัณฑ์ที่ซื้อ จากนั้นไปยังลูกค้ารายอื่นๆ ที่ซื้อผลิตภัณฑ์เหล่านั้น และสุดท้ายไปยังผลิตภัณฑ์อื่นๆ ที่ลูกค้าเหล่านั้นซื้อ
การเอาชนะอคติที่เกิดจากความนิยมด้วยความคล้ายคลึงของ Jaccard
แม้ว่าจำนวนการซื้อร่วมแบบดิบจะมีประโยชน์ แต่ก็อาจเอนเอียงไปทางผลิตภัณฑ์ยอดนิยม ผลิตภัณฑ์ที่ได้รับความนิยมอย่างมากอาจถูกซื้อร่วมกับสิ่งต่างๆ มากมายโดยบังเอิญ
ความคล้ายคลึงของ Jaccard จะทำให้คำแนะนำก้าวหน้าไปอีกขั้นด้วยการปรับจำนวนการซื้อร่วมกันให้เป็นมาตรฐาน โดยจะวัดความคล้ายคลึงกันระหว่าง 2 ชุด (ในกรณีนี้คือชุดคำสั่งซื้อที่มีผลิตภัณฑ์แต่ละรายการ)
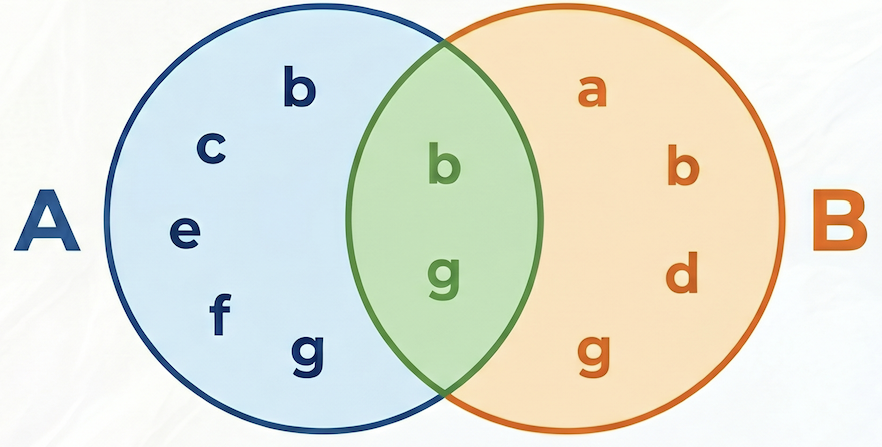
สูตรสำหรับความคล้ายคลึงของ Jaccard คือ

สถานที่:
- A intersect B คือจำนวนคำสั่งซื้อที่มีทั้งผลิตภัณฑ์ A และผลิตภัณฑ์ B (จำนวนการซื้อร่วมกัน)
- A คือจำนวนคำสั่งซื้อทั้งหมดที่มีผลิตภัณฑ์ A
- B คือจำนวนคำสั่งซื้อทั้งหมดที่มีผลิตภัณฑ์ B
ในตัวอย่างต่อไปนี้ กำหนดให้ A = {b,c,e,f,g}, B = {a,d,b,g} ดังนั้นส่วนที่ตัดกันของ A และ B คือ A⋂B = {b,g} ส่วนที่รวมกันของ A และ B คือ A⋃B = {a,b,c,d,e,f,g} ดังนั้นความคล้ายกันของ Jaccard ระหว่าง A และ B คือ 2 / 7 = 0.285714
การสร้างและการจัดอันดับใหม่ของผู้สมัคร
ในระบบการแนะนำในโลกแห่งความเป็นจริงที่ทำงานกับชุดข้อมูลขนาดใหญ่ การคำนวณคะแนนความคล้ายที่ซับซ้อน (เช่น Jaccard) สำหรับคู่ผลิตภัณฑ์ที่เป็นไปได้ทั้งหมดมักจะทำได้ยาก แต่รูปแบบที่ใช้กันโดยทั่วไปคือการใช้แนวทาง 2 ขั้นตอน ดังนี้
- การสร้างรายการตัวเลือก: ใช้เมตริกที่เรียบง่ายและรวดเร็ว (เช่น จำนวนการซื้อร่วมแบบดิบ) เพื่อกรองพื้นที่การค้นหาและค้นหาจำนวนตัวเลือกที่จัดการได้ (เช่น 10 อันดับแรก)
- การจัดอันดับใหม่: ใช้เมตริกที่แม่นยำยิ่งขึ้นแต่ต้องใช้การคำนวณที่หนักกว่า (เช่น ความคล้ายคลึงของ Jaccard) เพื่อจัดอันดับชุดแอปเทียบเท่าขนาดเล็กนั้นและเลือกแอปที่แนะนำอันดับต้นๆ สุดท้าย
ในโค้ดแล็บนี้ เราจะใช้รูปแบบต่อไปนี้
- ขั้นตอนที่ 1: เรียกใช้การค้นหาเพื่อค้นหาสินค้าที่ซื้อร่วมกัน 10 อันดับแรกสำหรับสินค้าแต่ละรายการ โดยอิงตามจำนวนการซื้อร่วมกันดิบ และจัดเก็บไว้ในตาราง
- ขั้นตอนที่ 2: ใช้การค้นหากราฟเพื่อดึงข้อมูลผู้สมัครเหล่านี้ จัดอันดับตามความคล้ายคลึงของ Jaccard และแสดงผล 3 อันดับแรก
[!WARNING] ข้อเสีย: การกรองตามจำนวนดิบในระยะที่ 1 อาจทำให้เราสูญเสีย "การเรียกคืน" การซื้อร่วมที่มีความเฉพาะเจาะจงสูงแต่มีความถี่ต่ำ หากผลิตภัณฑ์มีความคล้ายคลึงกับผลิตภัณฑ์อื่นมาก แต่ทั้ง 2 ผลิตภัณฑ์ไม่ค่อยมีการซื้อ ระบบอาจไม่นำผลิตภัณฑ์ดังกล่าวไปพิจารณาเป็น 10 อันดับแรกและอาจพลาดไป
เรียกใช้การค้นหาต่อไปนี้เพื่อคำนวณทั้งจำนวนการซื้อร่วมแบบดิบและความคล้ายคลึงของ Jaccard และจัดเก็บผู้สมัคร10 อันดับแรกตามจำนวนดิบ
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
เรียกใช้การค้นหานี้เพื่อแนะนำผลิตภัณฑ์ 3 อันดับแรกสำหรับการซื้อแต่ละครั้งของ Angelica ซึ่งเชื่อมต่อโดยตรงผ่านBoughtTogetherขอบ โดยแสดงทั้งจำนวนการซื้อร่วมและความคล้ายคลึงของ Jaccard
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
คำค้นหานี้จะย้อนรอยจากลูกค้า -> คำสั่งซื้อ -> ผลิตภัณฑ์ -> (ซื้อร่วมกัน) -> ผลิตภัณฑ์ที่แนะนำ ซึ่งจะแสดงคำแนะนำตามพฤติกรรมการซื้อโดยรวมและดึงคะแนนความคล้ายคลึง

10. ล้างข้อมูล
โปรดลบทรัพยากรที่สร้างขึ้นระหว่างการทำ Codelab นี้เพื่อหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่องกับบัญชี Google Cloud
ลบชุดข้อมูลและตารางทั้งหมด
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
หากสร้างโปรเจ็กต์ใหม่สำหรับ Codelab นี้ คุณก็ลบโปรเจ็กต์ได้เช่นกัน โดยทำดังนี้
gcloud projects delete $PROJECT_ID
11. ขอแสดงความยินดี
ยินดีด้วย คุณสร้างมุมมองข้อมูลลูกค้าแบบครบ 360 องศาและเครื่องมือแนะนำโดยใช้ BigQuery Graph ได้สำเร็จแล้ว
สิ่งที่คุณได้เรียนรู้
- วิธีสร้างกราฟพร็อพเพอร์ตี้ใน BigQuery
- วิธีโหลดข้อมูลลงในโหนดและขอบของกราฟ
- วิธีค้นหารูปแบบกราฟโดยใช้
GRAPH_TABLEและMATCH - วิธีรวมการค้นหากราฟกับการค้นหาเวกเตอร์เพื่อรับคำแนะนำแบบไฮบริด
ขั้นตอนถัดไป
- ดูเอกสารประกอบของ BigQuery Graph
- ดูข้อมูลเพิ่มเติมเกี่ยวกับการค้นหาเวกเตอร์ใน BigQuery