
1. 简介
在此 Codelab 中,您将学习如何使用 BigQuery Graph 为虚构的零售公司 Cymbal Pets 构建 Customer 360 视图和推荐引擎。您将利用 SQL 的强大功能直接在 BigQuery 中创建、查询和分析图数据,并将其与向量搜索相结合,实现高级商品推荐功能。
借助 BigQuery Graph,您可以将数据实体(例如客户、产品和订单)之间的关系建模为图,从而轻松回答有关客户行为和产品关联性的复杂问题。

您将执行的操作
- 为 Cymbal Pets 图创建 BigQuery 数据集和架构
- 从 Cloud Storage 加载示例数据(客户、产品、订单、商店)
- 在 BigQuery 中创建连接这些实体的属性图
- 使用图表查询直观呈现客户交易记录
- 使用向量搜索构建商品推荐系统
- 使用“一起购买”图关系和 Jaccard 相似度来增强推荐功能
所需条件
- 网络浏览器,例如 Chrome
- 启用了结算功能的 Google Cloud 项目
本 Codelab 适合各种水平的开发者,包括新手。
2. 准备工作
创建 Google Cloud 项目
- 在 Google Cloud 控制台中,选择或创建 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。
启动 Cloud Shell
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell。
- 验证身份验证:
gcloud auth list
- 确认您的项目:
gcloud config get project
- 根据需要进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
启用 API
运行以下命令以启用所需的 BigQuery API:
gcloud services enable bigquery.googleapis.com
3. 定义架构
首先,您需要创建一个数据集来存储与图相关的表,并为节点和边定义架构。
- 在此 Codelab 中,我们将执行 SQL 命令。您可以在 BigQuery Studio > SQL 编辑器中运行这些命令,也可以在 Cloud Shell 中使用
bq query命令。 为了获得更好的多行创建语句体验,我们将假设您使用的是 BigQuery SQL 编辑器。
为了获得更好的多行创建语句体验,我们将假设您使用的是 BigQuery SQL 编辑器。 - 创建
cymbal_pets_demo数据集:
CREATE SCHEMA IF NOT EXISTS cymbal_pets_demo;
- 为
order_items、products、orders、stores、customers和co_related_products_for_angelica创建表。这些表格将作为图表的源数据。
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.order_items
(
order_id INT64,
product_id INT64,
order_item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_id, product_id, order_item_id) NOT ENFORCED
)
CLUSTER BY order_item_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.products
(
product_id INT64,
product_name STRING,
brand STRING,
category STRING,
subcategory INT64,
animal_type INT64,
search_keywords INT64,
price FLOAT64,
description STRING,
inventory_level INT64,
supplier_id INT64,
average_rating FLOAT64,
uri STRING,
embedding ARRAY<FLOAT64>,
PRIMARY KEY (product_id) NOT ENFORCED
)
CLUSTER BY product_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.orders
(
customer_id INT64,
order_id INT64,
shipping_address_city STRING,
store_id INT64,
order_date STRING,
order_type STRING,
payment_method STRING,
PRIMARY KEY (order_id) NOT ENFORCED
);
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.stores
(
store_id INT64,
store_name STRING,
address_state STRING,
address_city STRING,
latitude FLOAT64,
longitude FLOAT64,
opening_hours STRUCT<Monday STRING, Tuesday STRING, Wednesday STRING, Thursday STRING, Friday STRING, Saturday STRING, Sunday STRING>,
manager_id INT64,
PRIMARY KEY (store_id) NOT ENFORCED
)
CLUSTER BY store_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.customers
(
customer_id INT64,
first_name STRING,
last_name STRING,
email STRING,
gender STRING,
address_city STRING,
address_state STRING,
loyalty_member BOOL,
PRIMARY KEY (customer_id) NOT ENFORCED
)
CLUSTER BY customer_id;
CREATE TABLE IF NOT EXISTS cymbal_pets_demo.co_related_products_for_angelica
(
angelica_product_id INT64,
other_product_id INT64,
co_purchase_count INT64,
jaccard_similarity FLOAT64
);
您现在已定义图表数据的结构。
4. 加载数据
现在,使用 Cloud Storage 中的示例数据填充表格。
在 BigQuery SQL 编辑器中运行以下 LOAD DATA 语句:
LOAD DATA INTO `cymbal_pets_demo.customers`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/customers/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.order_items`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/order_items/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.orders`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/orders/*.avro'],
enable_logical_types = true
);
-- 1. Create a new partitioned and clustered table from your current data
CREATE TABLE cymbal_pets_demo.orders_temp
PARTITION BY order_date
CLUSTER BY order_id
AS
SELECT
customer_id,
order_id,
shipping_address_city,
store_id,
-- Parse the string to a DATE type. Adjust format string ('%Y-%m-%d') if necessary.
PARSE_DATE('%Y-%m-%d', order_date) AS order_date,
order_type,
payment_method
FROM
cymbal_pets_demo.orders;
-- 2. Drop the original, non-partitioned table
DROP TABLE cymbal_pets_demo.orders;
-- 3. Rename the temporary table to the original table name
ALTER TABLE cymbal_pets_demo.orders_temp RENAME TO orders;
LOAD DATA INTO `cymbal_pets_demo.products`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/products/*.avro'],
enable_logical_types = true
);
LOAD DATA INTO `cymbal_pets_demo.stores`
FROM FILES (
format = 'AVRO',
uris = ['gs://sample-data-and-media/cymbal-pets/tables/stores/*.avro'],
enable_logical_types = true
);
您应该会看到确认消息,表明行已加载到每个表中。
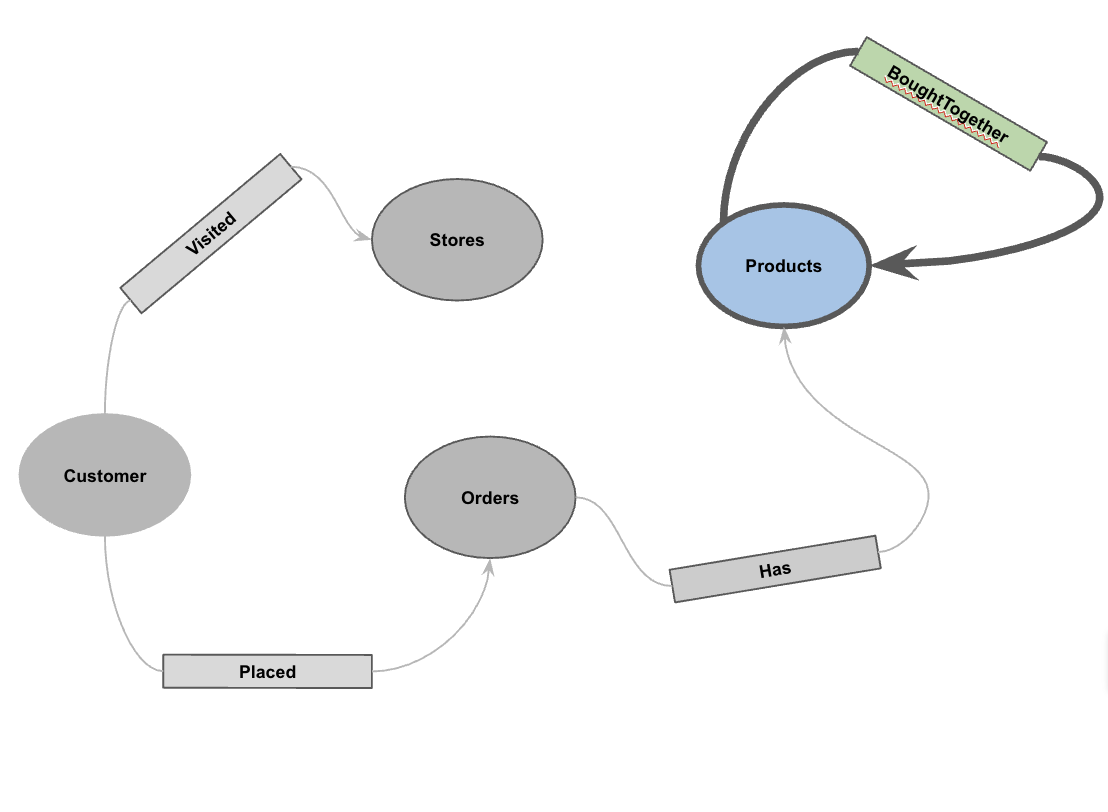
5. 创建属性图
加载数据后,您现在可以定义属性图了。这会告知 BigQuery 哪些表表示节点(例如客户、产品等实体),哪些表表示边(例如“访问过”“放置过”“拥有”等关系)。
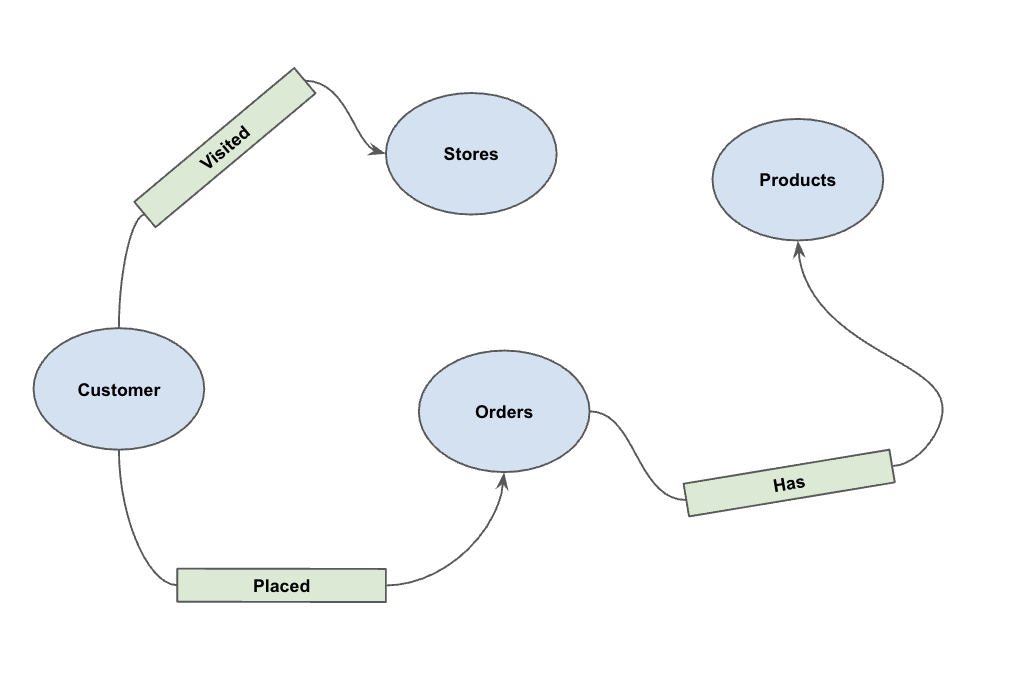
运行以下 DDL 语句:
CREATE OR REPLACE PROPERTY GRAPH cymbal_pets_demo.PetsOrderGraph
NODE TABLES (
cymbal_pets_demo.customers KEY(customer_id) LABEL Customer,
cymbal_pets_demo.products KEY(product_id) LABEL Products,
cymbal_pets_demo.stores KEY(store_id) LABEL Stores,
cymbal_pets_demo.orders KEY(order_id) LABEL Orders
)
EDGE TABLES (
cymbal_pets_demo.orders as customer_to_store_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (store_id) references stores(store_id)
LABEL Visited
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.order_items
KEY (order_item_id)
SOURCE KEY (order_id) references orders(order_id)
DESTINATION KEY (product_id) references products(product_id)
LABEL Has
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.orders as customer_to_orders_edge
KEY (order_id)
SOURCE KEY (customer_id) references customers(customer_id)
DESTINATION KEY (order_id) references orders(order_id)
LABEL Placed
PROPERTIES ALL COLUMNS,
cymbal_pets_demo.co_related_products_for_angelica
KEY (angelica_product_id)
SOURCE KEY (angelica_product_id) references products(product_id)
DESTINATION KEY (other_product_id) references products(product_id)
LABEL BoughtTogether
PROPERTIES ALL COLUMNS
);
这会创建图 PetsOrderGraph,使我们能够使用 GRAPH_TABLE 运算符执行图遍历。
6. 直观呈现所有客户的购买历史记录
在本 Codelab 的可视化和推荐部分,我们将使用 BigQuery Studio 中的原生图表可视化功能。这样一来,我们就可以轻松直观呈现图表结果。
或者,您也可以使用 IPython 魔法命令在 BigQuery Graph Notebook 中直观呈现结果。通过添加带有 TO_JSON 函数的 %%bigquery 魔法命令,您可以直观呈现结果,如以下部分所示。
假设 Cymbal Pets 想要获得所有客户及其在特定时间窗口内所做购买的 360 度可视化视图。
在新的 BigQuery Studio 标签页中运行以下命令:
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship
MATCH (customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# # This line finds all the Products nodes that are connected to the
# # filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer)-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
LIMIT 40
RETURN
TO_JSON(p) as paths
如需直观呈现结果,请在“查询结果”窗格中点击“图表”。

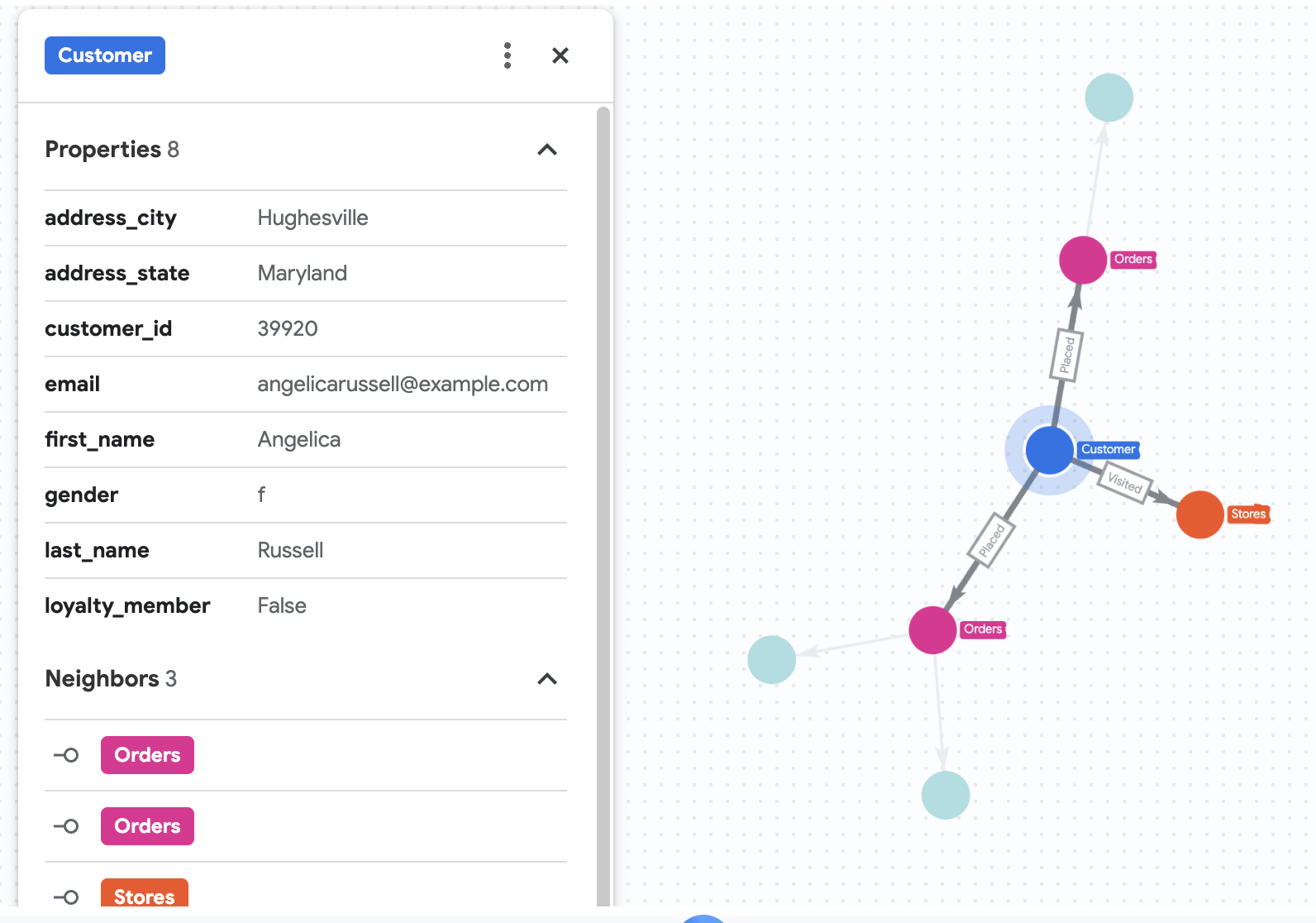
7. 直观呈现 Angelica 的购买历史记录
假设 Cymbal Pets 想要深入了解一位名为 Angelica Russell 的客户。他们想要分析 Angelica 在过去 3 个月内购买的商品以及该客户访问过的商店。
GRAPH cymbal_pets_demo.PetsOrderGraph
# finds the customer node with the name "Angelica Russell" and then finds all
# the Orders nodes that are connected to that customer through the
# Placed relationship and all the Products nodes that are connected to the
# filtered Orders nodes through the Has relationship.
MATCH p=(customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)-[has:Has]->(product:Products)
# filters the Orders nodes to only include those where the
# order_date is within the last 3 months.
WHERE ordr.order_date >= date('2024-11-27')
# finds the Stores nodes where Angelica placed order from
MATCH p2=(customer)-[visited:Visited]->(store:Stores)
RETURN
TO_JSON(p) as path, TO_JSON(p2) as path2
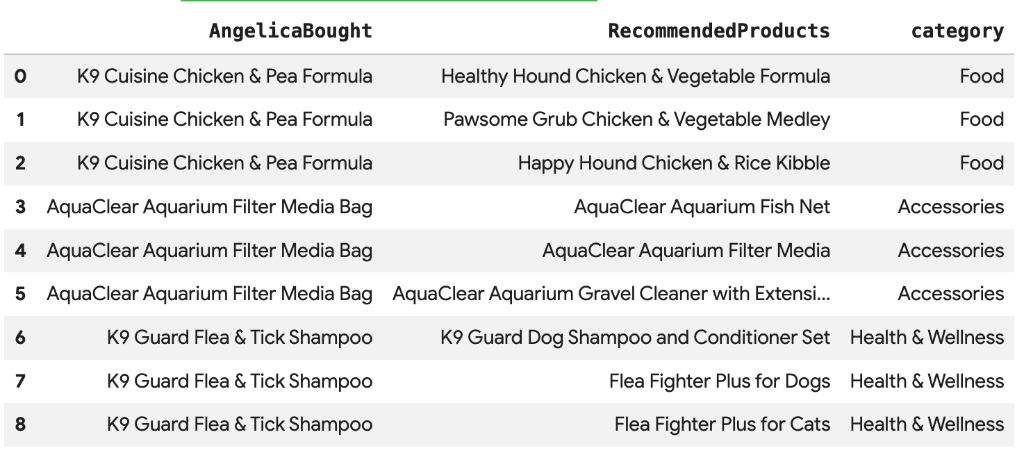
8. 使用 Vector Search 进行产品推荐
Cymbal Pets 希望根据 Angelica 最近购买的商品向她推荐产品。我们可以使用向量搜索来查找与她过去购买的商品具有相似嵌入的商品。
在新的 Colab 单元格中运行以下 SQL 脚本。此脚本:
- 识别 Angelica 最近购买的产品。
- 使用
VECTOR_SEARCH从products表格中找到前 4 个类似产品。
注意:此步骤假定您已运行 AI.GENERATE_EMBEDDINGS 以在 products 表中创建嵌入列。
DECLARE products_bought_by_angelica ARRAY<INT64>;
-- 1. Get IDs of products bought by Angelica
SET products_bought_by_angelica = (
SELECT ARRAY_AGG(product_id) FROM
GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (c:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(o:Orders)
WHERE o.order_date >= date('2024-11-27')
MATCH (o)-[has_edge:Has]->(p:Products)
RETURN DISTINCT p.product_id as product_id
));
-- 2. Find similar products using vector search
SELECT
query.product_name as AngelicaBought,
base.product_name as RecommendedProducts,
base.category
FROM
VECTOR_SEARCH(
TABLE cymbal_pets_demo.products,
'embedding',
(SELECT * FROM cymbal_pets_demo.products
WHERE product_id IN UNNEST(products_bought_by_angelica)),
'embedding',
top_k => 4)
WHERE query.product_name <> base.product_name;
您应该会看到一份推荐商品列表,其中包含与 Angelica 购买的商品在语义上相似的商品。
9. 使用“一起购买”和 Jaccard 相似度的推荐
另一种强大的推荐技术是“协同过滤”,即推荐其他用户经常一起购买的商品。
我们可以通过以下方式找到这些商品:从客户遍历图到其购买的商品,然后到购买了这些商品的其他客户,最后到这些客户购买的其他商品。
利用 Jaccard 相似度克服热门度偏差
虽然原始的共同购买次数很有用,但可能会偏向热门商品。非常受欢迎的商品可能只是偶然地与许多其他商品一起购买。
Jaccard 相似度通过对共同购买次数进行归一化处理,使推荐更进一步。它用于衡量两组之间的相似度(在本例中,是指包含每件商品的订单组)。
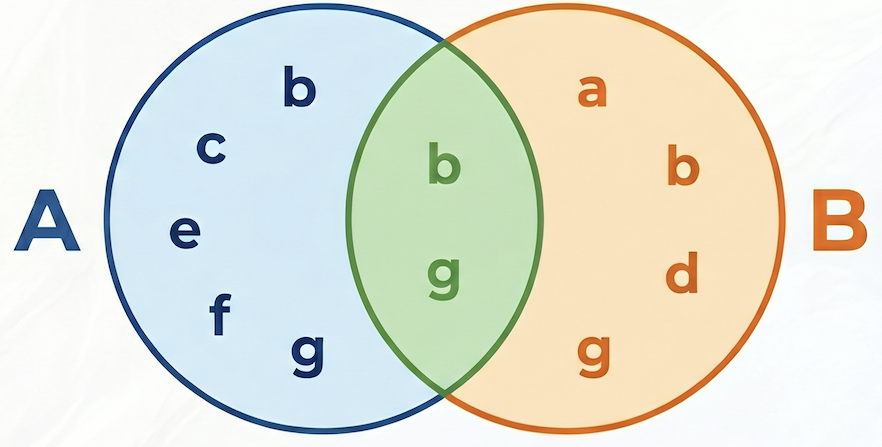
Jaccard 相似度的公式为:

地点:
- A 交集 B 是包含商品 A 和商品 B 的订单数量(共同购买次数)。
- A 是包含商品 A 的订单总数。
- B 是包含商品 B 的订单总数。
在以下示例中,如果集合 A = {b,c,e,f,g},集合 B = {a,d,b,g},则它们的交集 A⋂B = {b,g},它们的并集 A⋃B = {a,b,c,d,e,f,g},因此 A 和 B 之间的 Jaccard 相似度为 2 / 7 = 0.285714
候选集生成和重排序
在处理海量数据集的实际推荐系统中,计算所有可能的商品对之间的复杂相似度得分(例如 Jaccard)通常是不切实际的。相反,一种常见的模式是使用两阶段方法:
- 候选生成:使用简单快速的指标(例如原始共同购买次数)过滤搜索空间,并找到数量可控的候选商品(例如前 10 名)。
- 重新排名:应用更精确但计算量更大的指标(例如 Jaccard 相似度)对少量候选内容进行排名,并选择最终的顶部推荐内容。
在此 Codelab 中,我们将遵循以下模式:
- 第 1 阶段:运行查询,根据原始的共同购买次数,找出每种商品的前 10 个共同购买商品,并将它们存储在一个表中。
- 第 2 阶段:使用图查询检索这些候选对象,按 Jaccard 相似度对其进行排名,并返回前 3 个。
[!WARNING] 缺点:通过在第 1 阶段按原始计数进行过滤,我们可能会丢失高度具体但低频的共同购买的“召回率”。如果某商品与另一商品高度相似,但两者都很少被购买,那么该商品可能无法进入前 10 个候选商品,从而被遗漏。
运行以下查询,计算原始共同购买次数和 Jaccard 相似度,并按原始次数存储前 10 名候选商品:
CREATE OR REPLACE TABLE cymbal_pets_demo.co_related_products_for_angelica AS
-- Calculate the total number of orders for each product
WITH ProductOrderCounts AS (
SELECT product_id, COUNT(DISTINCT order_id) as total_count
FROM cymbal_pets_demo.order_items
GROUP BY product_id
),
-- Calculate the intersection of each product pairs
CoPurchases AS (
SELECT
angelicaProduct.product_id AS angelica_product_id,
otherProduct.product_id AS other_product_id,
count(DISTINCT otherOrder.order_id) AS co_purchase_count
FROM
GRAPH_TABLE (cymbal_pets_demo.PetsOrderGraph
MATCH (angelica:Customer {first_name: 'Angelica', last_name: 'Russell'})-[:Placed]->(o:Orders)-[:Has]->(angelicaProduct:Products)
WHERE o.order_date >= date('2024-11-27')
WITH angelica, angelicaProduct
MATCH (otherCustomer:Customer)-[:Placed]->(otherOrder:Orders)-[:Has]->(angelicaProduct)
WHERE otherCustomer <> angelica
WITH angelicaProduct, otherOrder
MATCH (otherOrder)-[:HAS]->(otherProduct:Products)
WHERE angelicaProduct <> otherProduct
RETURN angelicaProduct, otherProduct, otherOrder
)
GROUP BY
angelicaProduct.product_id, otherProduct.product_id
)
SELECT * FROM (
SELECT
cp.angelica_product_id,
cp.other_product_id,
cp.co_purchase_count,
-- The Jaccard calculation, which is the intersection of A and B divided by (A + B - intersection)
SAFE_DIVIDE(cp.co_purchase_count, (poc1.total_count + poc2.total_count - cp.co_purchase_count)) AS jaccard_similarity,
ROW_NUMBER() OVER (PARTITION BY cp.angelica_product_id ORDER BY cp.co_purchase_count DESC) AS rn
FROM CoPurchases cp
JOIN ProductOrderCounts poc1 ON cp.angelica_product_id = poc1.product_id
JOIN ProductOrderCounts poc2 ON cp.other_product_id = poc2.product_id
)
WHERE rn <= 10;
运行以下查询,直接通过 BoughtTogether 边为 Angelica 的每次购买推荐 3 款热门商品,同时显示共同购买次数和 Jaccard 相似度:
SELECT * FROM GRAPH_TABLE(
cymbal_pets_demo.PetsOrderGraph
MATCH (customer:Customer {first_name: 'Angelica', last_name: 'Russell'})-[placed:Placed]->(ordr:Orders)
WHERE ordr.order_date >= date('2024-11-27')
MATCH (ordr)-[has:Has]->(product:Products)
MATCH (product)-[bought_together:BoughtTogether]->(recommended_product:Products)
RETURN
product.product_name AS OriginalProduct,
recommended_product.product_name AS Recommended,
bought_together.co_purchase_count AS Strength,
bought_together.jaccard_similarity AS JaccardSimilarity
)
-- Rank product recommendations by Jaccard Similarity
QUALIFY ROW_NUMBER() OVER (PARTITION BY OriginalProduct ORDER BY JaccardSimilarity DESC) <= 3
ORDER BY OriginalProduct;
此查询从 Customer -> Order -> Product -> (BoughtTogether) -> Recommended Product 进行遍历,根据集体购买行为显示推荐,并检索相似度得分。

10. 清理
为避免系统向您的 Google Cloud 账号持续收取费用,请删除在此 Codelab 中创建的资源。
删除数据集和所有表:
DROP SCHEMA IF EXISTS cymbal_pets_demo CASCADE;
如果您为此 Codelab 创建了一个新项目,还可以删除该项目:
gcloud projects delete $PROJECT_ID
11. 恭喜
恭喜!您已成功使用 BigQuery Graph 构建了 Customer 360 视图和推荐引擎。
您学到的内容
- 如何在 BigQuery 中创建属性图。
- 如何将数据加载到图节点和边缘中。
- 如何使用
GRAPH_TABLE和MATCH查询图表模式。 - 如何将图查询与向量搜索相结合,以实现混合推荐。
后续步骤
- 探索 BigQuery 图文档。
- 详细了解 BigQuery 中的向量搜索功能。