
1. Overview
BigQuery is Google's fully managed, petabyte scale, low cost analytics data warehouse. BigQuery is NoOps—there is no infrastructure to manage and you don't need a database administrator—so you can focus on analyzing data to find meaningful insights, use familiar SQL, and take advantage of our pay-as-you-go model.
In this codelab, you will use the Google Cloud BigQuery Client Library to query BigQuery public datasets with Node.js.
What you'll learn
- How to use the Cloud Shell
- How to enable the BigQuery API
- How to Authenticate API requests
- How to install the BigQuery client library for Node.js
- How to query the works of Shakespeare
- How to query the GitHub dataset
- How to adjust caching and display statistics
What you'll need
Survey
How will you use this tutorial?
How would you rate your experience with Node.js?
How would you rate your experience with using Google Cloud Platform services?
2. Setup and Requirements
Self-paced environment setup
- Sign in to Cloud Console and create a new project or reuse an existing one. (If you don't already have a Gmail or G Suite account, you must create one.)


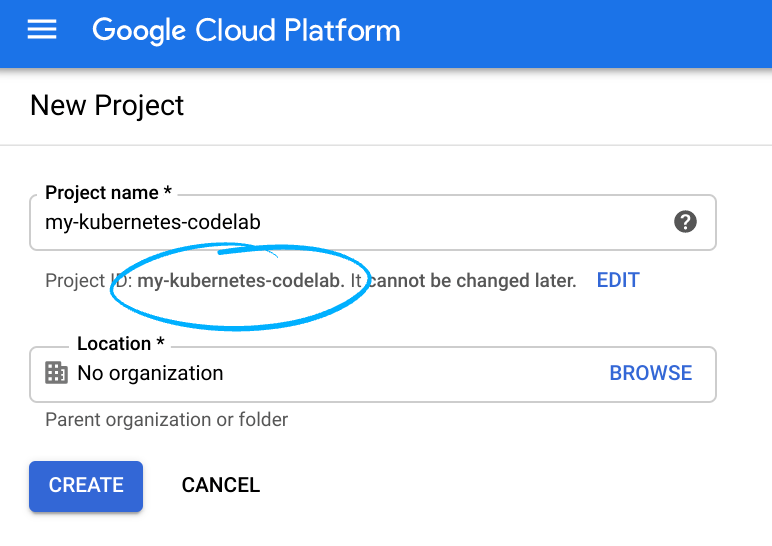
Remember the project ID, a unique name across all Google Cloud projects (the name above has already been taken and will not work for you, sorry!). It will be referred to later in this codelab as PROJECT_ID.
- Next, you'll need to enable billing in Cloud Console in order to use Google Cloud resources.
Running through this codelab shouldn't cost much, if anything at all. Be sure to to follow any instructions in the "Cleaning up" section which advises you how to shut down resources so you don't incur billing beyond this tutorial. New users of Google Cloud are eligible for the $300USD Free Trial program.
Start Cloud Shell
While the Cloud SDK command-line tool can be operated remotely from your laptop, in this codelab you will be using Google Cloud Shell, a command line environment running in the cloud.
Activate Cloud Shell
- From the Cloud Console, click Activate Cloud Shell
.

If you've never started Cloud Shell before, you're presented with an intermediate screen (below the fold) describing what it is. If that's the case, click Continue (and you won't ever see it again). Here's what that one-time screen looks like:

It should only take a few moments to provision and connect to Cloud Shell.

This virtual machine is loaded with all the development tools you need. It offers a persistent 5GB home directory and runs in Google Cloud, greatly enhancing network performance and authentication. Much, if not all, of your work in this codelab can be done with simply a browser or your Chromebook.
Once connected to Cloud Shell, you should see that you are already authenticated and that the project is already set to your project ID.
- Run the following command in Cloud Shell to confirm that you are authenticated:
gcloud auth list
Command output
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Command output
[core] project = <PROJECT_ID>
If it is not, you can set it with this command:
gcloud config set project <PROJECT_ID>
Command output
Updated property [core/project].
3. Enable the BigQuery API
BigQuery API should be enabled by default in all Google Cloud projects. You can check whether this is true with the following command in the Cloud Shell:
gcloud services list
You should see BigQuery listed:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
If the BigQuery API is not enabled, you can use the following command in the Cloud Shell to enable it:
gcloud services enable bigquery-json.googleapis.com
4. Authenticate API requests
In order to make requests to the BigQuery API, you need to use a Service Account. A Service Account belongs to your project, and it is used by the Google BigQuery Node.js client library to make BigQuery API requests. Like any other user account, a service account is represented by an email address. In this section, you will use the Cloud SDK to create a service account and then create credentials you will need to authenticate as the service account.
First, set an environment variable with your PROJECT_ID which you will use throughout this codelab:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
Next, create a new service account to access the BigQuery API by using:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
Next, create credentials that your Node.js code will use to login as your new service account. Create these credentials and save it as a JSON file "~/key.json" by using the following command:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Finally, set the GOOGLE_APPLICATION_CREDENTIALS environment variable, which is used by the BigQuery API C# library, covered in the next step, to find your credentials. The environment variable should be set to the full path of the credentials JSON file you created. Set the environment variable by using the following command:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
You can read more about authenticating the BigQuery API.
5. Setup Access Control
BigQuery uses Identity and Access Management (IAM) to manage access to resources. BigQuery has a number of predefined roles (user, dataOwner, dataViewer etc.) that you can assign to your service account you created in the previous step. You can read more about Access Control in the BigQuery documentation.
Before you can query the public datasets, you need to make sure the service account has at least the bigquery.user role. In Cloud Shell, run the following command to assign the bigquery.user role to the service account:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
You can run the following command to verify that the service account is assigned the user role:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Install the BigQuery client library for Node.js
First, create a BigQueryDemo folder and navigate to it:
mkdir BigQueryDemo
cd BigQueryDemo
Next, create a Node.js project that you will use to run BigQuery client library samples:
npm init -y
You should see the Node.js project created:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Install the BigQuery client library:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
Now, you're ready to use BigQuery Node.js client library!
7. Query the works of Shakespeare
A public dataset is any dataset that is stored in BigQuery and made available to the general public. There are many other public datasets available for you to query, some of which are also hosted by Google, but many more that are hosted by third parties. You can read more on the Public Datasets page.
In addition to the public datasets, BigQuery provides a limited number of sample tables that you can query. These tables are contained in the bigquery-public-data:samples dataset. One of those tables is called shakespeare. It contains a word index of the works of Shakespeare, giving the number of times each word appears in each corpus.
In this step, you will query the shakespeare table.
First, open the code editor from the top right side of the Cloud Shell:
Create a queryShakespeare.js file inside the BigQueryDemo folder :
touch queryShakespeare.js
Navigate to the queryShakespeare.js file and insert the following code:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
Take a minute or two to study the code and see how the table is queried.
Back in Cloud Shell, run the app:
node queryShakespeare.js
You should see a list of words and their occurrences:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. Query the GitHub dataset
To get more familiar with BigQuery, you'll now issue a query against the GitHub public dataset. You will find the most common commit messages on GitHub. You'll also use BigQuery 's web UI to preview and run ad-hoc queries.
To view the data, open the GitHub dataset in the BigQuery web UI:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
To get a quick preview of how the data looks, click the Preview tab:
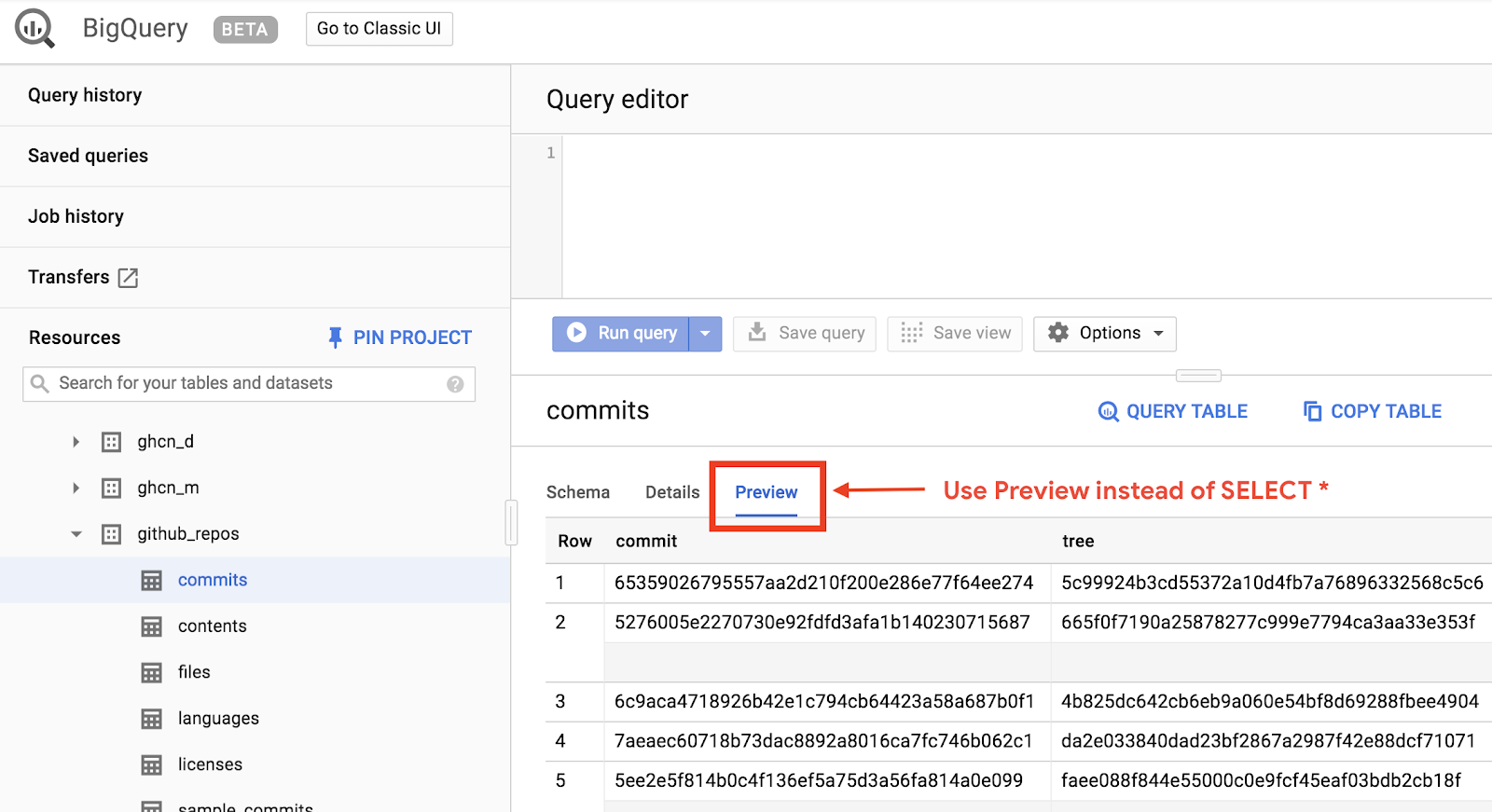
Create the queryGitHub.js file inside the BigQueryDemo folder:
touch queryGitHub.js
Navigate to the queryGitHub.js file and insert the following code:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
Take a minute or two to study the code and see how the table is queried for the most common commit messages.
Back in Cloud Shell, run the app:
node queryGitHub.js
You should see a list of commit messages and their occurrences:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. Caching and statistics
When you run a query, BigQuery caches the results. As a result, subsequent identical queries take much less time. It is possible to disable caching by using the query options. BigQuery also keeps track of some statistics about the queries such as creation time, end time, and total bytes processed.
In this step, you will disable caching and display some stats about the queries.
Navigate to the queryShakespeare.js file inside the BigQueryDemo folder and replace the code with the following:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
A couple of things to note about the code. First, caching is disabled by setting UseQueryCache to false inside the options object. Second, you accessed the statistics about the query from the job object.
Back in Cloud Shell, run the app:
node queryShakespeare.js
You should see a list of commit messages and their occurrences. In addition, you should also see some stats about the query:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. Loading data into BigQuery
If you want to query your own data, you need first load your data into BigQuery. BigQuery supports loading data from many sources such as Google Cloud Storage, other Google services, or a local, readable source. You can even stream your data. You can read more on the Loading Data into BigQuery page.
In this step, you will load a JSON file stored in Google Cloud Storage into a BigQuery table. The JSON file is located at: gs://cloud-samples-data/bigquery/us-states/us-states.json
If you're curious about the contents of the JSON file, you can use gsutil command line tool to download it in the Cloud Shell:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
You can see that it contains the list of US states, and each state is a JSON object on a separate line:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
To load this JSON file into BigQuery, create a createDataset.js file and a loadBigQueryJSON.js file inside the BigQueryDemo folder:
touch createDataset.js
touch loadBigQueryJSON.js
Install the Google Cloud Storage Node.js client library:
npm install --save @google-cloud/storage
Navigate to the createDataset.js file and insert the following code:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
Then, navigate to the loadBigQueryJSON.js file and insert the following code:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
Take a minute or two to study how the code loads the JSON file and creates a table (with a schema) in a dataset.
Back in Cloud Shell, run the app:
node createDataset.js
node loadBigQueryJSON.js
A dataset and a table are created in BigQuery:
Table my_states_table created.
Job [JOB ID] completed.
To verify that the dataset is created, you can go to the BigQuery web UI. You should see a new dataset and a table. If you switch to the table's Preview tab, you can see the actual data:
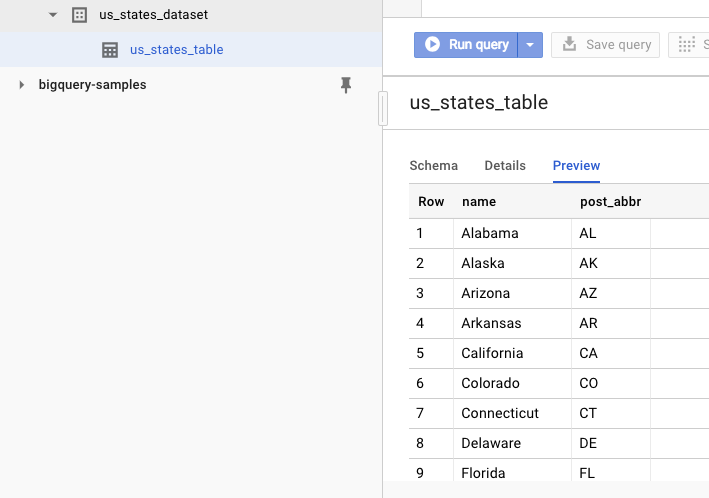
11. Congratulations!
You learned how to use BigQuery using Node.js!
Clean up
To avoid incurring charges to your Google Cloud Platform account for the resources used in this quickstart:
- Go to the Cloud Platform Console.
- Select the project you want to shut down, then click ‘Delete' at the top: this schedules the project for deletion.
Learn More
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js on Google Cloud Platform: https://cloud.google.com/nodejs/
- Google BigQuery Node.js client library: https://github.com/googleapis/nodejs-bigquery
License
This work is licensed under a Creative Commons Attribution 2.0 Generic License.