
1. Descripción general
BigQuery es el almacén de datos de estadísticas de bajo costo, completamente administrado y con escala de petabytes de Google. BigQuery es NoOps: no se debe administrar ninguna infraestructura y no necesitas un administrador de base de datos, de manera que puedes enfocarte en el análisis de datos para buscar estadísticas valiosas, usar el lenguaje SQL que conoces y sacar provecho de nuestro modelo prepago.
En este codelab, usarás la biblioteca cliente de Google Cloud BigQuery para consultar conjuntos de datos públicos de BigQuery con Node.js.
Qué aprenderás
- Cómo usar Cloud Shell
- Cómo habilitar la API de BigQuery
- Cómo autenticar solicitudes a la API
- Cómo instalar la biblioteca cliente de BigQuery para Node.js
- Cómo consultar las obras de Shakespeare
- Cómo consultar el conjunto de datos de GitHub
- Cómo ajustar el almacenamiento en caché y las estadísticas de visualización
Requisitos
- Un proyecto de Google Cloud Platform
- Un navegador como Chrome o Firefox
- Conocimiento del uso de Node.js
Encuesta
¿Cómo usarás este instructivo?
¿Cómo calificarías tu experiencia con Node.js?
¿Cómo calificarías tu experiencia con el uso de los servicios de Google Cloud Platform?
2. Configuración y requisitos
Configuración del entorno de autoaprendizaje
- Accede a la consola de Cloud y crea un proyecto nuevo o reutiliza uno existente. (Si todavía no tienes una cuenta de Gmail o de G Suite, debes crear una).


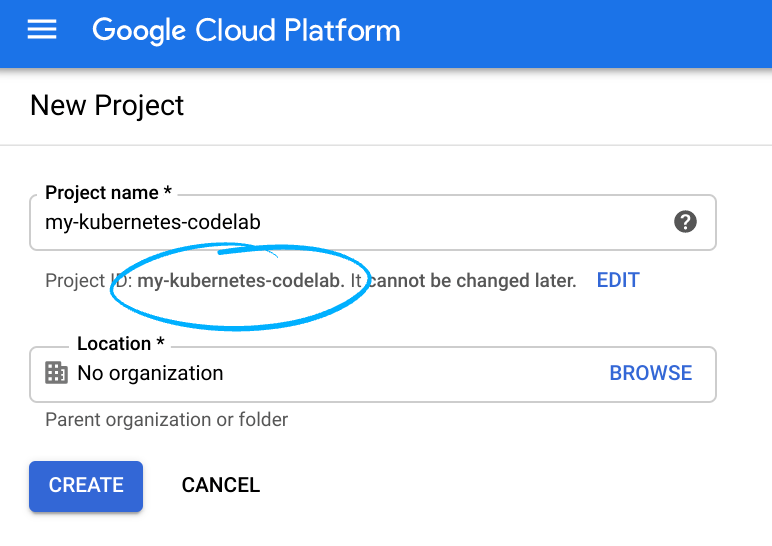
Recuerde el ID de proyecto, un nombre único en todos los proyectos de Google Cloud (el nombre anterior ya se encuentra en uso y no lo podrá usar). Se mencionará más adelante en este codelab como PROJECT_ID.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar los recursos de Google Cloud recursos.
Ejecutar este codelab no debería costar mucho, tal vez nada. Asegúrate de seguir las instrucciones de la sección “Realiza una limpieza”, en la que se aconseja cómo cerrar recursos para que no se te facture más allá de este instructivo. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicia Cloud Shell
Si bien la herramienta de línea de comandos del SDK de Cloud se puede operar de forma remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
Activar Cloud Shell
- En la consola de Cloud, haz clic en Activar Cloud Shell
.

Si nunca has iniciado Cloud Shell, aparecerá una pantalla intermedia (mitad inferior de la página) en la que se describirá qué es. Si ese es el caso, haz clic en Continuar (y no volverás a verla). Así es como se ve la pantalla única:

El aprovisionamiento y la conexión a Cloud Shell solo tomará unos minutos.

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitas. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Gran parte de tu trabajo en este codelab, si no todo, se puede hacer simplemente con un navegador o tu Chromebook.
Una vez conectado a Cloud Shell, debería ver que ya se autenticó y que el proyecto ya se configuró con tu ID del proyecto.
- En Cloud Shell, ejecuta el siguiente comando para confirmar que está autenticado:
gcloud auth list
Resultado del comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Resultado del comando
[core] project = <PROJECT_ID>
De lo contrario, puedes configurarlo con el siguiente comando:
gcloud config set project <PROJECT_ID>
Resultado del comando
Updated property [core/project].
3. Habilite la API de BigQuery
La API de BigQuery debería estar habilitada de forma predeterminada en todos los proyectos de Google Cloud. Puedes verificar si esto es cierto con el siguiente comando en Cloud Shell:
gcloud services list
Deberías ver BigQuery en la lista:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
Si la API de BigQuery no está habilitada, puedes usar el siguiente comando en Cloud Shell para habilitarla:
gcloud services enable bigquery-json.googleapis.com
4. Autentica solicitudes a la API
Para realizar solicitudes a la API de BigQuery, debes usar una cuenta de servicio. Una cuenta de servicio pertenece a tu proyecto y la biblioteca cliente de Google BigQuery Node.js la usa para realizar solicitudes a la API de BigQuery. Al igual que cualquier otra cuenta de usuario, una cuenta de servicio está representada por una dirección de correo electrónico. En esta sección, usarás el SDK de Cloud para crear una cuenta de servicio y, luego, crear las credenciales que necesitarás para autenticarte como la cuenta de servicio.
Primero, establece una variable de entorno con tu PROJECT_ID que utilizarás durante todo este codelab:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
A continuación, crea una cuenta de servicio nueva para acceder a la API de BigQuery con el siguiente comando:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
A continuación, crea credenciales que tu código de Node.js usará para acceder como tu cuenta de servicio nueva. Crea estas credenciales y guárdalas como un archivo JSON “~/key.json” mediante el siguiente comando:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Por último, configura la variable de entorno GOOGLE_APPLICATION_CREDENTIALS, que la biblioteca de C# de la API de BigQuery, que se explica en el siguiente paso, usa para encontrar tus credenciales. La variable de entorno se debe establecer en la ruta de acceso completa del archivo JSON de credenciales que creaste. Configura la variable de entorno con el siguiente comando:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
Puedes obtener más información para autenticar la API de BigQuery.
5. Configura el control de acceso
BigQuery usa Identity and Access Management (IAM) para administrar el acceso a los recursos. BigQuery tiene varios roles predefinidos (usuario, propietario de datos, visualizador de datos, etc.) que puedes asignar a la cuenta de servicio que creaste en el paso anterior. Puedes leer más sobre el Control de acceso en la documentación de BigQuery.
Antes de consultar los conjuntos de datos públicos, debes asegurarte de que la cuenta de servicio tenga al menos el rol bigquery.user. En Cloud Shell, ejecuta el siguiente comando para asignar el rol bigquery.user a la cuenta de servicio:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
Puedes ejecutar el siguiente comando para verificar que se haya asignado el rol de usuario a la cuenta de servicio:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Instala la biblioteca cliente de BigQuery para Node.js
Primero, crea una carpeta BigQueryDemo y navega a ella:
mkdir BigQueryDemo
cd BigQueryDemo
A continuación, crea un proyecto de Node.js que usarás para ejecutar muestras de la biblioteca cliente de BigQuery:
npm init -y
Deberías ver el proyecto de Node.js creado:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Instala la biblioteca cliente de BigQuery:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
Ahora, ya puedes usar la biblioteca cliente de BigQuery para Node.js.
7. Consultar las obras de Shakespeare
Un conjunto de datos públicos es un conjunto de datos que se almacena en BigQuery y está disponible para el público en general. Existen muchos otros conjuntos de datos públicos disponibles que puedes consultar, algunos también alojados por Google, pero muchos otros alojados por terceros. Puedes leer más en la página Conjuntos de datos públicos.
Además de los conjuntos de datos públicos, BigQuery proporciona una cantidad limitada de tablas de muestra que puedes consultar. Estas tablas se encuentran en bigquery-public-data:samples dataset. Una de esas tablas se llama shakespeare.. Contiene un índice de palabras de las obras de Shakespeare, que indica la cantidad de veces que aparece cada palabra en cada corpus.
En este paso, consultarás la tabla shakespeare.
Primero, abre el editor de código en la parte superior derecha de Cloud Shell:

Crea un archivo queryShakespeare.js dentro de la carpeta BigQueryDemo :
touch queryShakespeare.js
Navega al archivo queryShakespeare.js e inserta el siguiente código:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
Tómate uno o dos minutos para estudiar el código y ver cómo se consulta la tabla.
De regreso en Cloud Shell, ejecuta la app:
node queryShakespeare.js
Deberías ver una lista de palabras y sus ocurrencias:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. Consultar el conjunto de datos de GitHub
Para familiarizarte más con BigQuery, ahora ejecutarás una consulta en el conjunto de datos públicos de GitHub. Encontrarás los mensajes de confirmación más comunes en GitHub. También usarás la IU web de BigQuery para obtener una vista previa de las consultas ad hoc y ejecutarlas.
Para ver los datos, abre el conjunto de datos de GitHub en la IU web de BigQuery:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
Para obtener una vista previa rápida de cómo se ven los datos, haz clic en la pestaña Vista previa:

Crea el archivo queryGitHub.js dentro de la carpeta BigQueryDemo:
touch queryGitHub.js
Navega al archivo queryGitHub.js e inserta el siguiente código:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
Tómate uno o dos minutos para estudiar el código y ver cómo se consulta la tabla para obtener los mensajes de confirmación más comunes.
De regreso en Cloud Shell, ejecuta la app:
node queryGitHub.js
Deberías ver una lista de los mensajes de confirmación y sus ocurrencias:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. Almacenamiento en caché y estadísticas
Cuando ejecutas una consulta, BigQuery almacena en caché los resultados. Como resultado, las consultas idénticas posteriores tardan mucho menos tiempo. Es posible inhabilitar el almacenamiento en caché con las opciones de consulta. BigQuery también realiza un seguimiento de algunas estadísticas sobre las consultas, como la hora de creación, la hora de finalización y el total de bytes procesados.
En este paso, inhabilitarás el almacenamiento en caché y mostrarás algunas estadísticas sobre las búsquedas.
Navega al archivo queryShakespeare.js dentro de la carpeta BigQueryDemo y reemplaza el código por lo siguiente:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
Hay algunas cosas que debes tener en cuenta sobre el código. Primero, se inhabilita el almacenamiento en caché configurando UseQueryCache en false dentro del objeto options. En segundo lugar, accediste a las estadísticas sobre la consulta desde el objeto de trabajo.
De regreso en Cloud Shell, ejecuta la app:
node queryShakespeare.js
Deberías ver una lista de los mensajes de confirmación y sus ocurrencias. Además, también deberías ver algunas estadísticas sobre la búsqueda:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. Carga datos en BigQuery
Si deseas consultar tus propios datos, primero debes cargarlos en BigQuery. BigQuery admite la carga de datos desde muchas fuentes, como Google Cloud Storage, otros servicios de Google o una fuente local legible. Incluso puedes transmitir tus datos. Puedes obtener más información en la página Carga datos en BigQuery.
En este paso, cargarás un archivo JSON almacenado en Google Cloud Storage en una tabla de BigQuery. El archivo JSON se encuentra en la siguiente ubicación: gs://cloud-samples-data/bigquery/us-states/us-states.json
Si tienes curiosidad sobre el contenido del archivo JSON, puedes usar la herramienta de línea de comandos gsutil para descargarlo en Cloud Shell:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
Puedes ver que contiene la lista de estados de EE.UU., y cada estado es un objeto JSON en una línea separada:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
Para cargar este archivo JSON en BigQuery, crea un archivo createDataset.js y un archivo loadBigQueryJSON.js dentro de la carpeta BigQueryDemo:
touch createDataset.js
touch loadBigQueryJSON.js
Instala la biblioteca cliente de Google Cloud Storage para Node.js:
npm install --save @google-cloud/storage
Navega al archivo createDataset.js e inserta el siguiente código:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
Luego, navega al archivo loadBigQueryJSON.js y, luego, inserta el siguiente código:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
Dedica un minuto o dos a estudiar cómo el código carga el archivo JSON y crea una tabla (con un esquema) en un conjunto de datos.
De regreso en Cloud Shell, ejecuta la app:
node createDataset.js
node loadBigQueryJSON.js
Se crean un conjunto de datos y una tabla en BigQuery:
Table my_states_table created.
Job [JOB ID] completed.
Para verificar que se creó el conjunto de datos, puedes ir a la IU web de BigQuery. Deberías ver un nuevo conjunto de datos y una tabla. Si cambias a la pestaña Vista previa de la tabla, puedes ver los datos reales:

11. ¡Felicitaciones!
Aprendiste a usar BigQuery con Node.js.
Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud Platform por los recursos de esta guía de inicio rápido:
- Ve a Cloud Platform Console.
- Selecciona el proyecto que deseas cerrar y, luego, haz clic en "Borrar" en la parte superior para programar su eliminación.
Más información
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js en Google Cloud Platform: https://cloud.google.com/nodejs/
- Biblioteca cliente de Google BigQuery para Node.js: https://github.com/googleapis/nodejs-bigquery
Licencia
Este trabajo cuenta con una licencia Atribución 2.0 Genérica de Creative Commons.